文章目录
1. 概要
跳表是一种 随机性 的数据结构,随机性体现在跳表的层数是不固定的。跳表基于有序链表,可以在原始链表基础上创建多层索引架构,采用这种随机技术,跳表中的搜索、插入、删除操作的时间均为 O(logn)。
上面就是跳表的图示,注意 h 节点是头结点,n 节点是尾结点,从图片来看本质就是一个链表加了 n 层来进行索引,跳表的查询流程等后面会逐步介绍的。
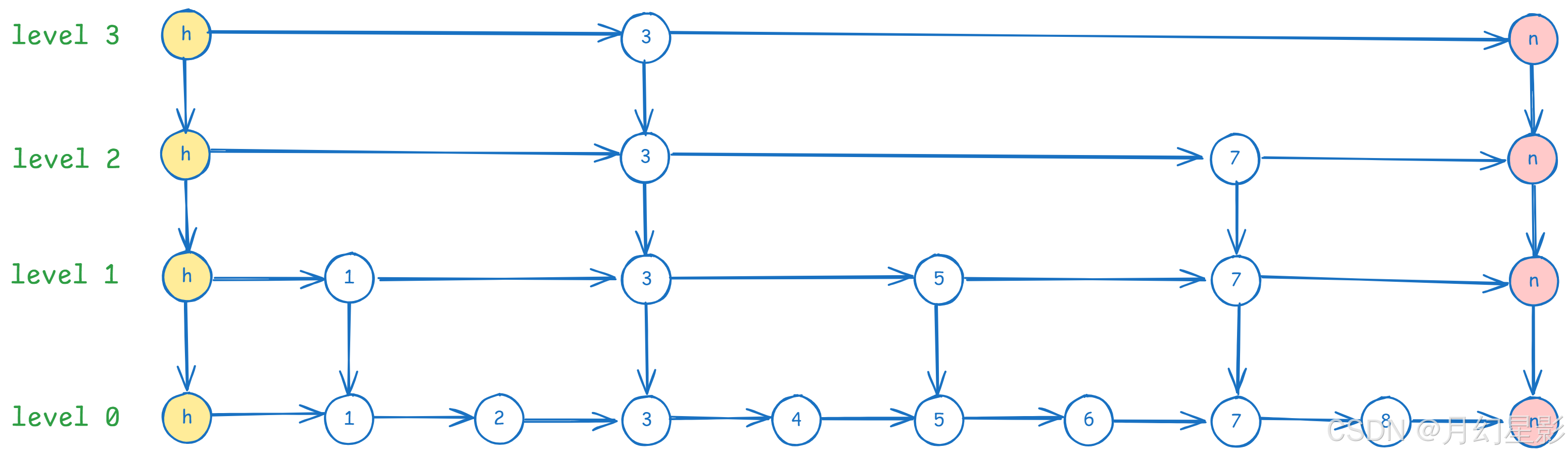
大家在看到上面图片的时候也能想象,如果去掉 level1、level2、level3,其实跳表也就是一个链表,或者说是一个数组,但是加上之后,在做增删改查的时候就可以从上往下逐层查询查询,性能大大提高,所以查询性能才比较高效。
当然了,前面我们也说了跳表的层数是随机的,不是固定的,所以最终跳表也可能只有一层,这种情况下增删改查的平均时间复杂度会退化成 O(n)。
2. 跳表的时间复杂度
我们上面也说了,跳表中的搜索、插入、删除操作的时间均为 O(logn),这个值是怎么算出来的呢?
在理想情况下, 假设 level0 的节点数为 n,接下来每一层的节点数是下一层的一半,那么结果就是:
- level1 节点数: n / 2 n / 2 n/2
- level2 节点数: n / 4 = n / 2 2 n / 4 = n / 2^{2} n/4=n/22
- level3 节点数: n / 8 = n / 2 3 n / 8 = n / 2^{3} n/8=n/23
- …
- levelm 节点数: n / 2 m n / 2^{m} n/2m
假设第 m 层(最顶层)节点数就 1 个,那么就是说
n
/
2
m
=
1
n / 2^{m} = 1
n/2m=1,求得
m
=
log
2
n
m = \log_{2}{n}
m=log2n,而时间复杂度等于 高度 * 每一层遍历的节点数,假设每一层遍历的节点数是 k,所以最终时间复杂度就是
k
log
2
n
k\log_{2}{n}
klog2n,由于 k 是常数级别,所以最终结果就是:
log
2
n
\log_{2}{n}
log2n。
那么为什么每一层遍历的节点数 k 是常数呢?
理想情况下我们会构建出例如上面图中的跳表,每一层相隔 2 个节点就会在上一层构建一个索引节点,假设我们要找 6,路径就是:
也就是说每一层只需要判断 2 个节点,就可以继续往下一层走,继续判断,最终到最底层,所以 k 在这里就是一个常数。
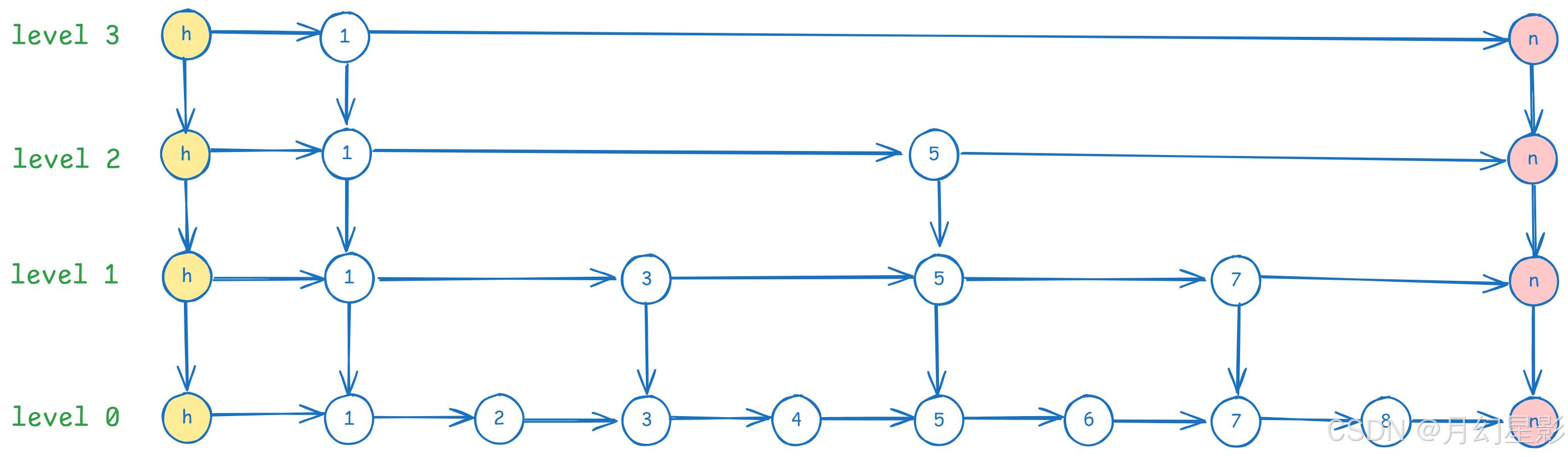
由于我们是随机生成层节点的,所以这里说的平均时间复杂度是 log 2 n \log_{2}{n} log2n,只是在极端情况下会退化成 O ( n ) O(n) O(n)。
3. 代码
3.1 跳表节点
跳表的概念上面就已经说过了,我们更需要关注的还是跳表的属性定义,首先就是跳表节点,跳表节点包括 key 和 value,我们添加的时候是使用 key 进行索引的。
class SkipListNode {
public int key;
public int value;
SkipListNode[] forward;
public SkipListNode(int key, int value, int level) {
this.key = key;
this.value = value;
this.forward = new SkipListNode[level + 1];
}
}
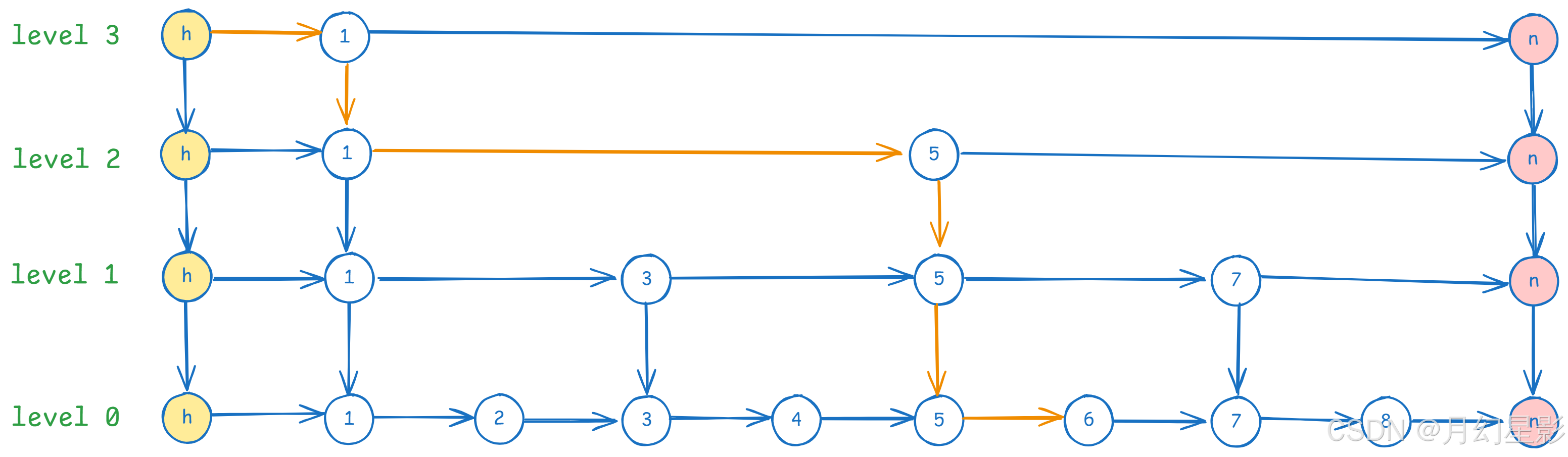
然后就是 forward,这个 forward 是一个数组,forward[i] 表示当前节点的前向指针,啥意思呢,举个例子:
圈红色的地方就是 key = h 的 forward 数组,大家先忽略 value,大家可以把 h 看成是头结点,n 看成是 null 指针,头结点的 forward 数组非空的部分大小是 4,也就是说 forward[0] ... forward[3] 都指向了 key = 1 的节点。接着 key = 1 的 forward 数组也是 4,而这时候 forward[0] = 2,forward[1] = 3,forward[2] = 5,forward[3] = null。
3.2 SkipList 参数
public static final double PROBABILITY = 0.5;
public static final int MAX_LEVEL = 15;
public int level;
public SkipListNode head;
public Random random;
首先就是 PROBABILITY,这个参数用于判断是否应该生成一层,比如添加节点 1 的时候,使用 random.nextDouble() < 0.5,那么这个节点的层数就 + 1,比如上面图中节点 1 在添加的时候生成的层数就是 4。
然后就是 MAX_LEVEL,上面说了节点需要通过随机数判断能否增加一层,但是层数也不是无限添加的,所以这里设置了一个上限,默认给的是 15。
接着就是 level,level 指的是跳表当前的最高层数,比如上面图默认就是 3。最后 head 就是上面图中的首节点了,刚刚已经介绍过了,这里就不多说。
3.3 SkipList 构造函数
构造函数很简单,就是初始化 head 和 random 两个参数,level 也顺便初始化,不过 int 类型默认就是 0,初始化不初始化都一样。
public SkipList() {
this.head = new SkipListNode(Integer.MIN_VALUE, Integer.MIN_VALUE, MAX_LEVEL);
this.random = new Random();
this.level = 0;
}
3.4 跳表查询
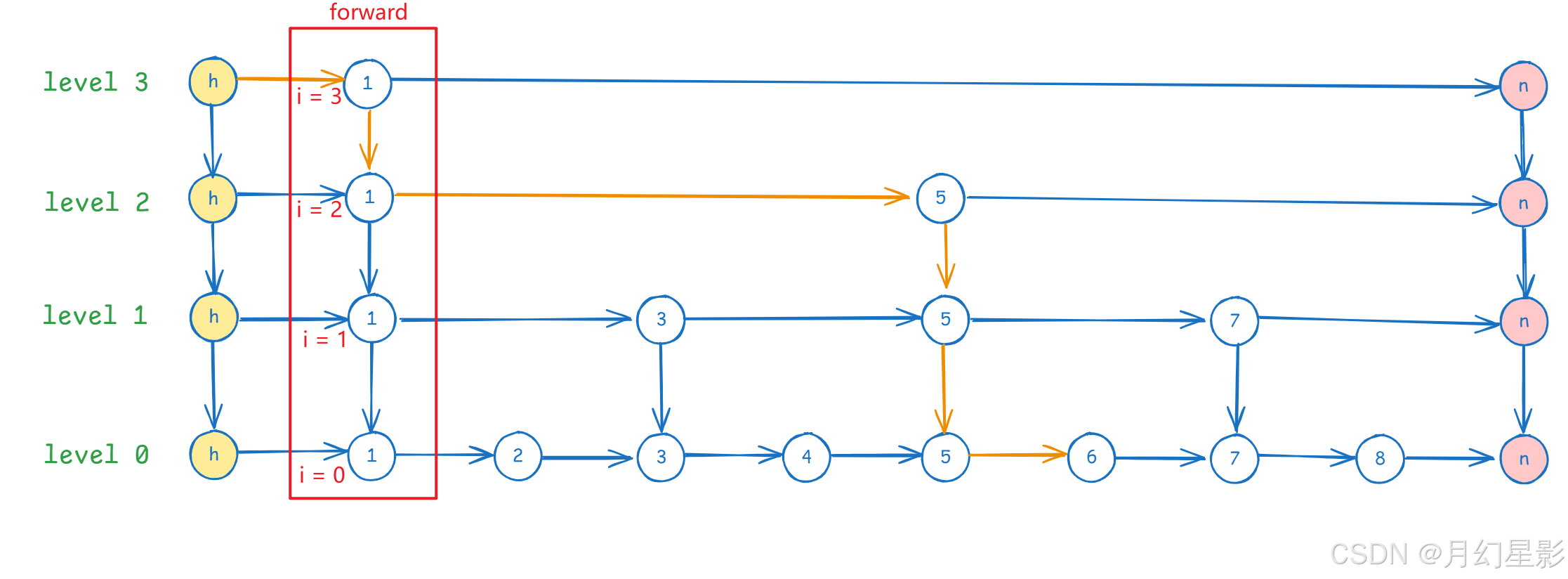
下面我们就来看下跳表的查询逻辑,还是以下面图为例子,节点里面的值就当成 key 即可,value 我没有标上去,因为增删查都是以 key 为主,看图也方便点,我们以查询 key = 6 为例子。
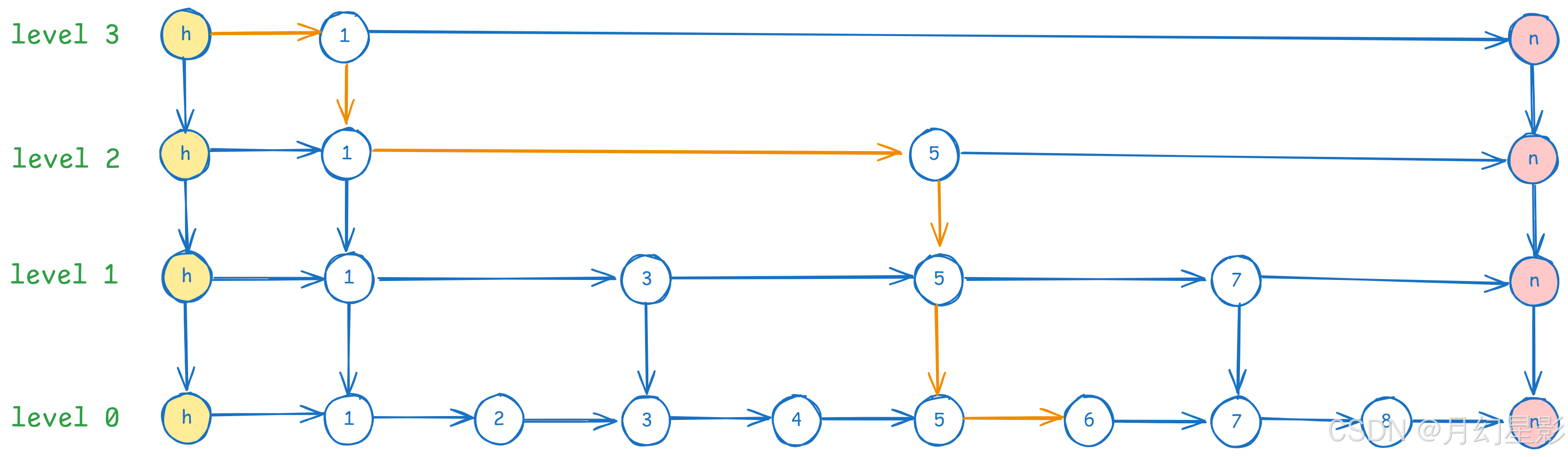
- 首先从最顶层 level3 开始遍历,首先是 head 节点的下一个节点
key = 1,发现 key = 1 < 6,时候 current 指针指向 key = 1 的位置。
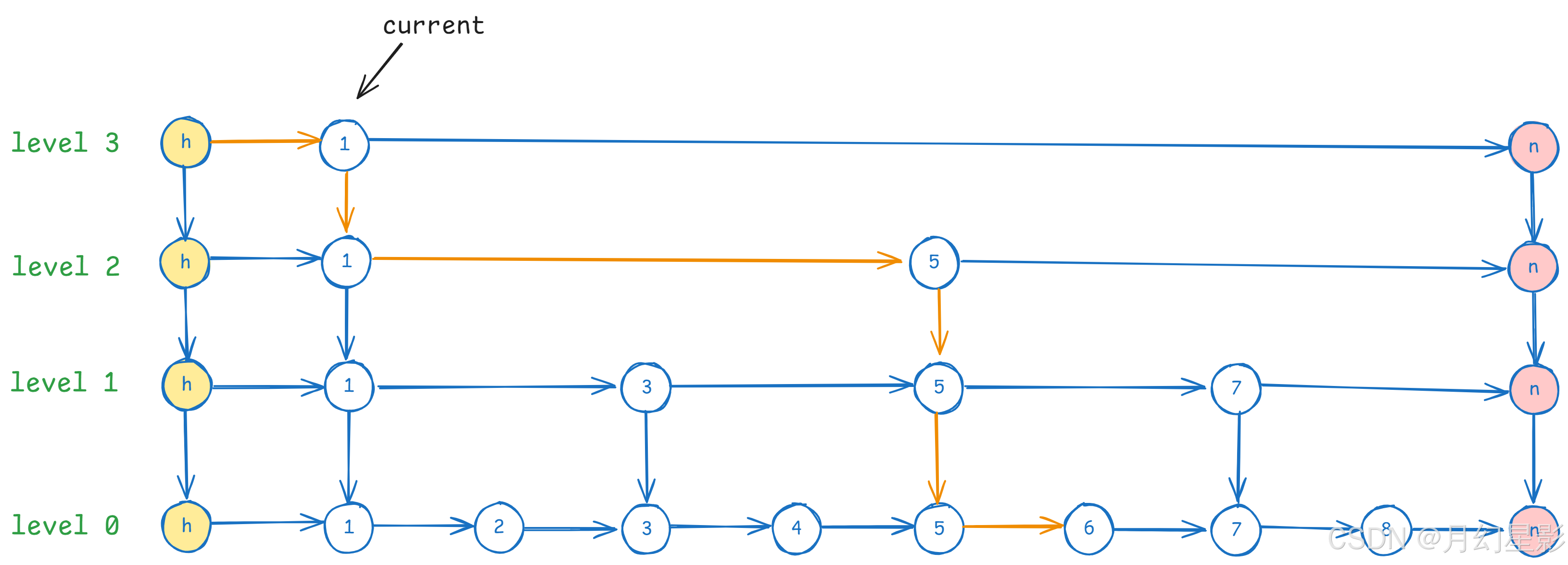
- 接着我们发现当前 current 指针指向的下一个已经是 null 了(节点 n),就去到下一层 level2。
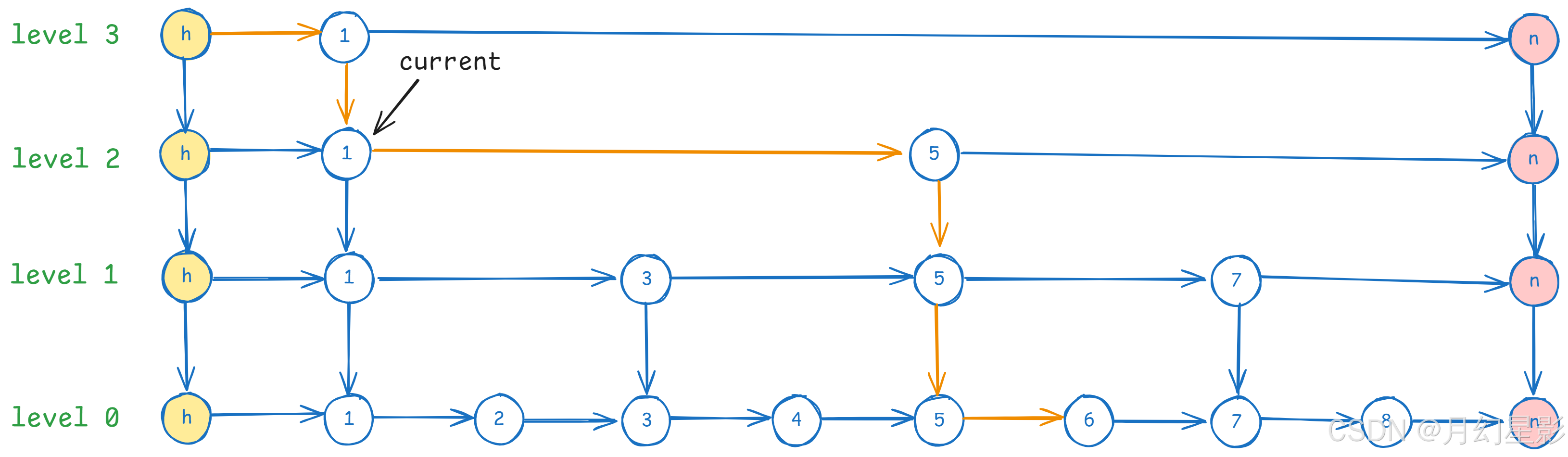
- 在 level2 发现 current 的下一个节点是 5,5 < 6,于是 current 指针移动到 5 的位置。
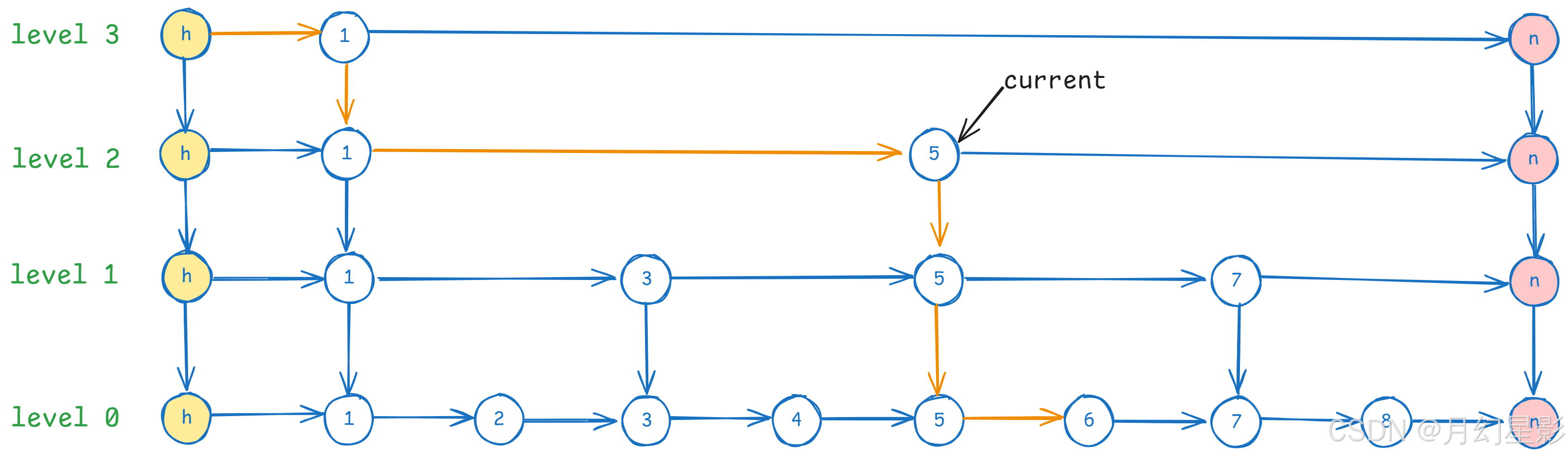
- 继续判断,发现 current 的下一个节点是空,移动到 level1,此时发现 current 的下一个节点是 7,而 6 < 7,说明这时候要查询的节点就在 current 和 current 的下一个节点之间,此时移动到 level0 去找。
- 最后发现 current 的下一个节点就是 6,就是我们要找的节点,到这里查询的逻辑就结束了。
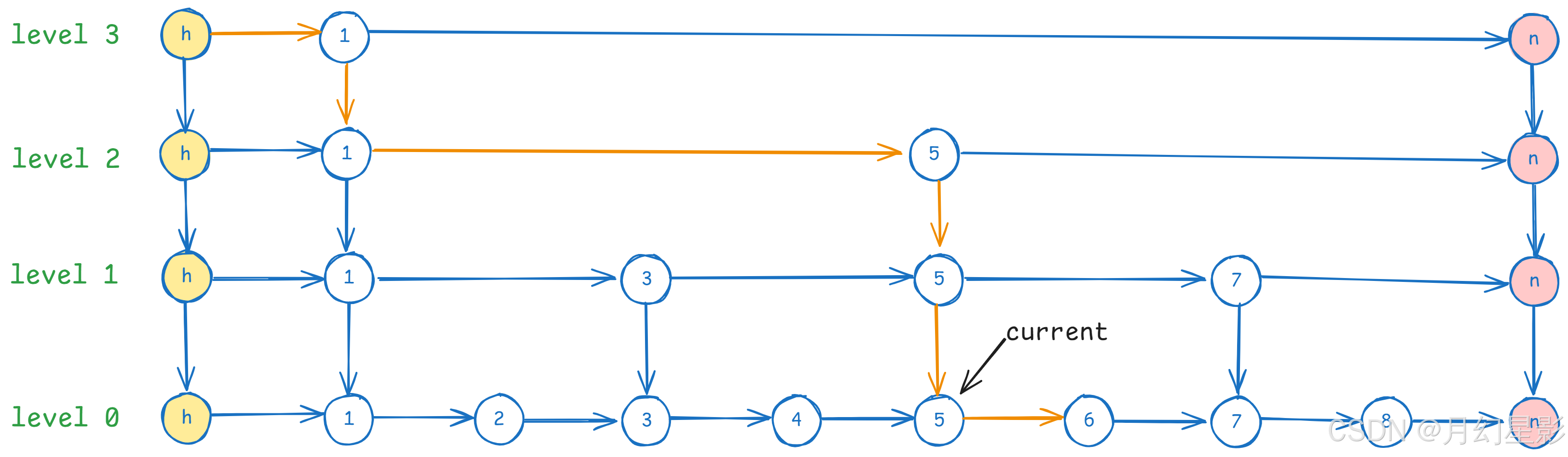
上面就是查询的基本逻辑了,从图片来看就很简单,但是我们实际是用数组存储当前节点每一层指向的下一个节点,所以从代码角度看起来就没有那么容易懂,这里我先给出所有代码。
public int searchBK(int key) {
SkipListNode node = search(key);
return node == null ? Integer.MIN_VALUE : node.value;
}
public SkipListNode search(int key) {
SkipListNode current = head;
for (int i = level; i >= 0; i--) {
while (current.forward[i] != null && current.forward[i].key < key) {
current = current.forward[i];
}
}
current = current.forward[0];
if (current != null && current.key == key) {
return current;
}
return null;
}
上面的 for 循环就是在遍历层级,while 循环是在不断更改 current 节点,综合起来的意思就是 while 循环会在每一层找到最后一个小于传入的 key 的节点,比如上面图中,在 level3 的时候由于节点 1 就是最后一个,所以这时候退出 while 循环来到 level2。
在 level2 继续遍历,current 也指向了 1,此时 current.forward[2] = 5 (节点 1 在 level2 的下一个节点是 5),然后接着 while 循环判断 current.forward[2] = 5 < 6,让 current 指向 5,由于 level2 中 5 是最后一个小于 6 的节点,所以 i–,来到 level1。
在 level1 由于 current.forward[1] = 7 > 6,所以继续往下来到 level0。在 level0 判断的时候 current.forward[0] = 6 不满足 < 6,所以就退出循环了。
最后 current = current.forward[0] 获取 5 在 level0 的下一个节点来判断是否满足 current.key == key。
3.4 跳表新增节点
下面先给出所有的代码逻辑。
public void insert(int key, int value) {
SkipListNode[] update = new SkipListNode[MAX_LEVEL + 1];
SkipListNode current = head;
for (int i = level; i >= 0; i--) {
while (current.forward[i] != null && current.forward[i].key < key) {
current = current.forward[i];
}
update[i] = current;
}
current = current.forward[0];
if (current != null && current.key == key) {
current.value = value;
} else {
int newLevel = randomLevel();
if (newLevel > level) {
for (int i = level + 1; i <= newLevel; i++) {
update[i] = head;
}
level = newLevel;
}
SkipListNode newNode = new SkipListNode(key, value, newLevel);
for (int i = 0; i <= newLevel; i++) {
newNode.forward[i] = update[i].forward[i];
update[i].forward[i] = newNode;
}
}
}
要解释上面的逻辑,我们以下面图为例子。
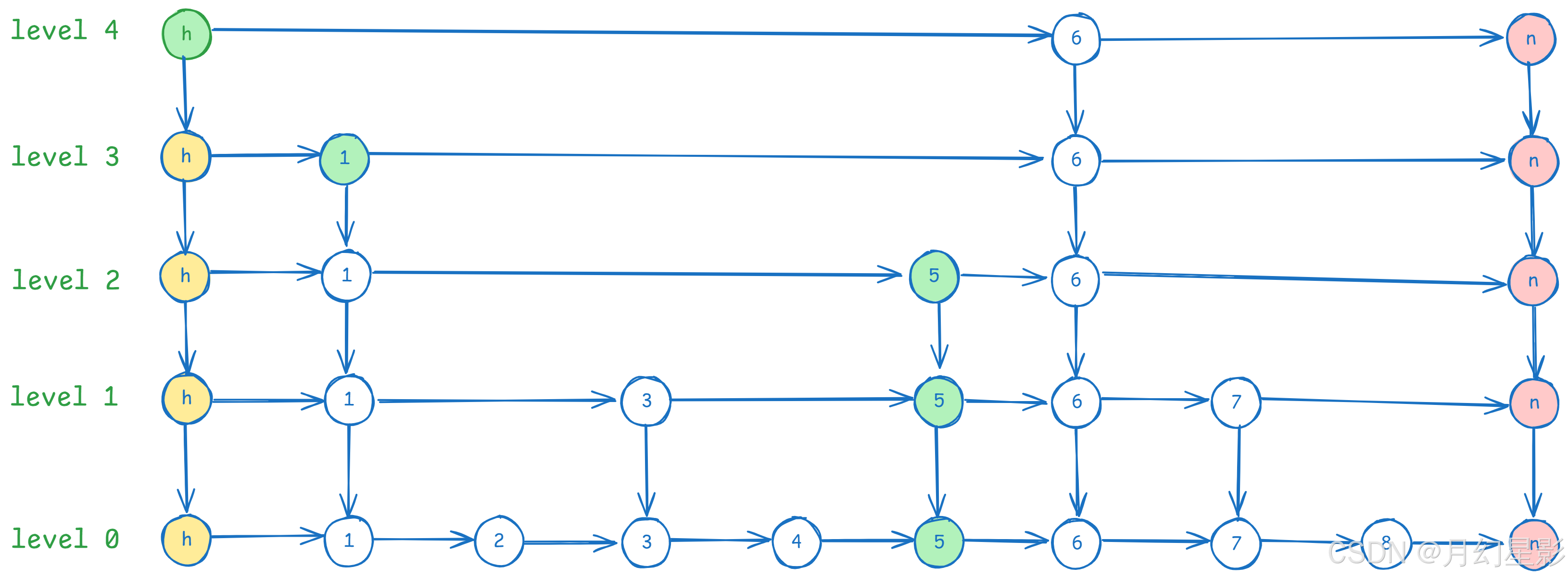
上图中的 1-8 节点缺了节点 6,所以我们要新增的就是节点(6,6),还是直接看 key。
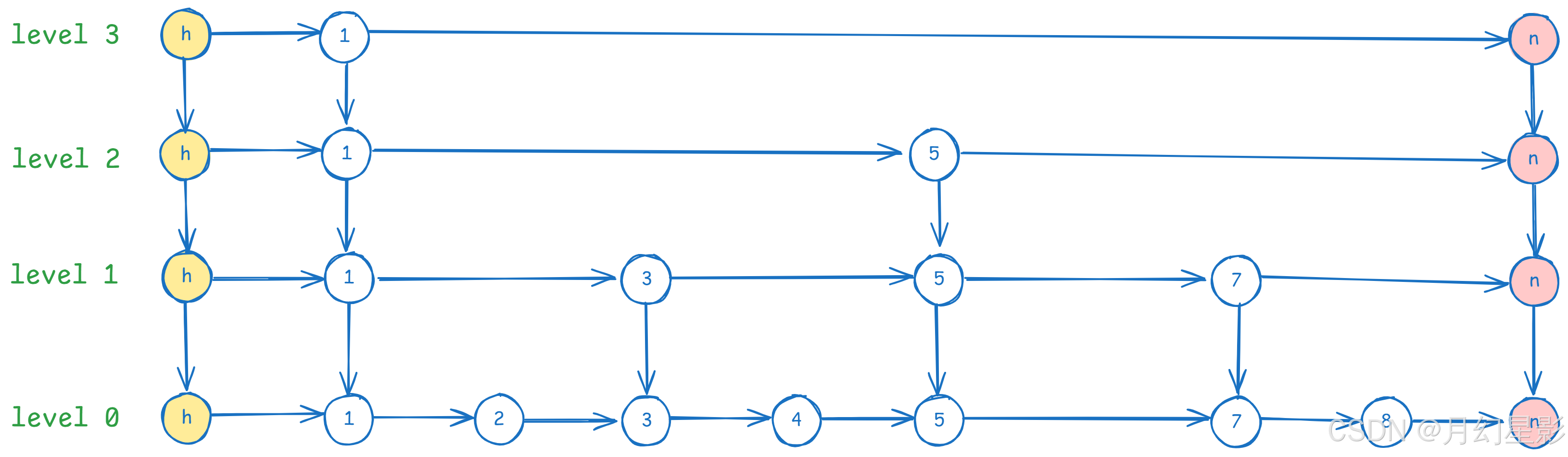
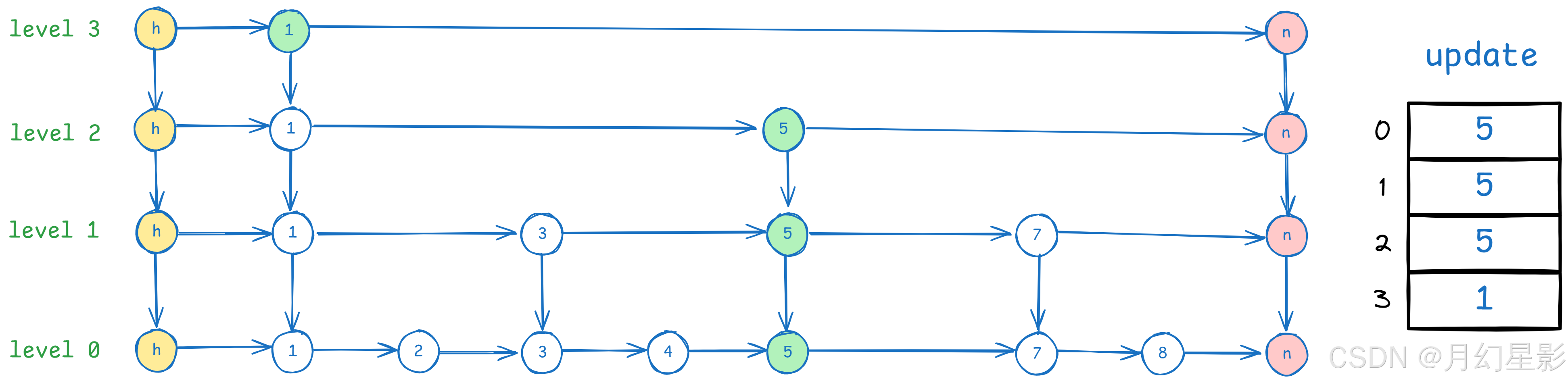
首先来看下 update[] 数组,这个数组的目的是在每一层找到最后一个比新增的 key 小的节点,比如上面图中当处理完 update 数组之后就是这样的。
至于如何处理 update 的,其实跟 search 逻辑一模一样,因为 search 会从上往下遍历每一层找到最后一个小于 key 的节点,而处理 update 只不过是在 search 的代码基础上加了一行 update[i] = current 来记录下来这些节点。而 update 数组创建传入的长度是 MAX_LEVEL + 1,这是因为 SkipList 构造函数对 head 节点创建的 forward 长度是 MAX_LEVEL + 1,而其他添加的节点创建的 forward 长度是 random 出来的层级。
head 节点默认创建 MAX_LEVEL + 1 的 forward 数组是因为如果后续的 level 超过原先最大的 level,就需要重新调整 head 的 forward 数组,就比如上面图中假设我们就只为 head 创建长度为 4 的 forward,那么如果后续要添加的节点层数超过 4,那么 head.forward 又要重新 new 一个,并且还要把原来的转移到新的上面,比较麻烦,所以干脆一早就创建好这么长的数组。
当然这样也有一个坏处就是占用内存空间比较多,如果是边新增边调整,这样就可以省下不少内存,所以不同的处理方式有不同的好处吧。
回到代码,这时候 current 指向了 level0 里面节点 5 的下一个节点 7,这时候会判断是不是更新。
if (current != null && current.key == key) {
current.value = value;
}
如果不是更新,那就是新增节点了,这时候就需要获取下这个新的节点的层数,简单来说就是通过随机数判断如果小于 0.5 就增加一层。
int newLevel = randomLevel();
if (newLevel > level) {
for (int i = level + 1; i <= newLevel; i++) {
update[i] = head;
}
level = newLevel;
}
当新的层数比原来的层数要大,这时候就要更新下 update 数组,将 update 数组新多出的这部分层数都设置为 head,同时更新 level,比如这时候算出来的 newLevel = 4,那么就更新 update[4] = head。
在这里再次提醒大家一次,update 数组中记录的是要插入的这个节点的前置节点。
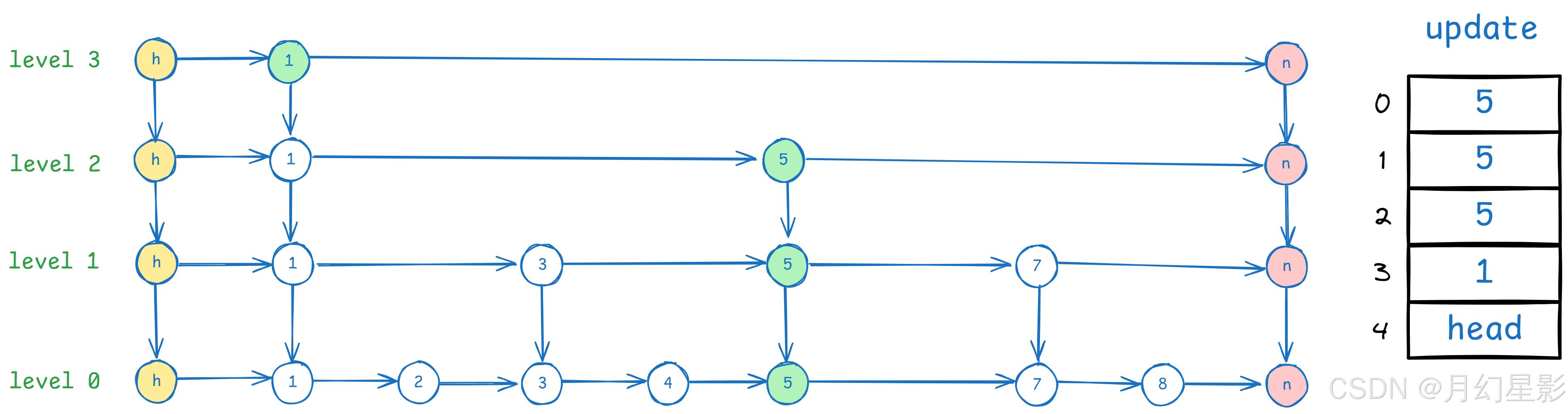
最后,我们更新新的节点的后继节点和 update[i] 的后继节点。
SkipListNode newNode = new SkipListNode(key, value, newLevel);
for (int i = 0; i <= newLevel; i++) {
newNode.forward[i] = update[i].forward[i];
update[i].forward[i] = newNode;
}
上面 update[i].forward[i] 意思是 第 i 层记录的节点在第 i 层的后继节点,newNode.forward[i] 意思自然就是 newNode 在第 i 层的后继节点,这样就比较好理解,总之处理完之后长这样。
3.5 跳表删除节点
看了上面增加的逻辑,delete 方法的逻辑和 update 差不多,首先也是一样要获取 update 数组。
SkipListNode[] update = new SkipListNode[MAX_LEVEL + 1];
SkipListNode current = head;
for (int i = level; i >= 0; i--) {
while (current.forward[i] != null && current.forward[i].key < key) {
current = current.forward[i];
}
update[i] = current;
}
assert current.forward != null;
接着判断跳表中是否存在这个节点,如果不存在就不删除了。
current = current.forward[0];
if (current != null && current.key != key) {
return;
}
如果存在,那么从最底层往上开始删除。
for (int i = 0; i <= level; i++) {
if (update[i].forward[i] != current) {
break;
}
update[i].forward[i] = current.forward[i];
}
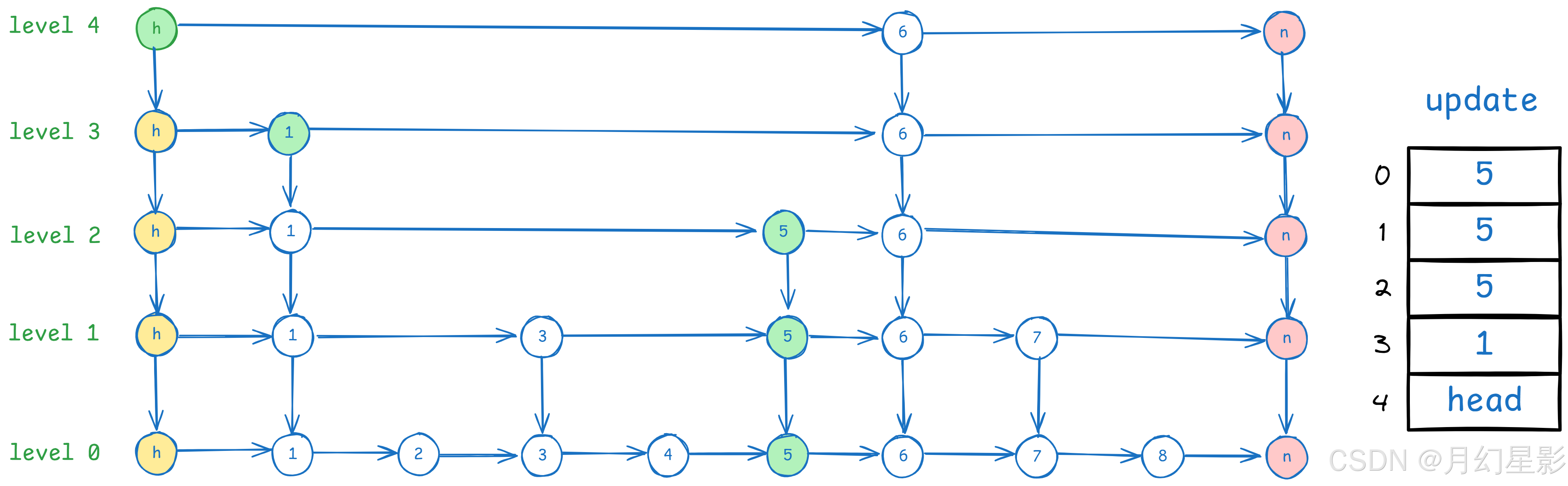
比如这个图要删除 6,就是从 update 下标 0 开始删除,将 6 的前置节点指向 6 的后继节点,注意如果遇到 update[i].forward[i] != current 就直接退出,比如上面图中要删除 5 的时候,update 数组是这样的。
当遍历到 level3 的时候,发现 1 的下一个节点是 6,不等于 5,这时候直接退出,因为 level3 找不到节点 5,那么 level4 也不会有。
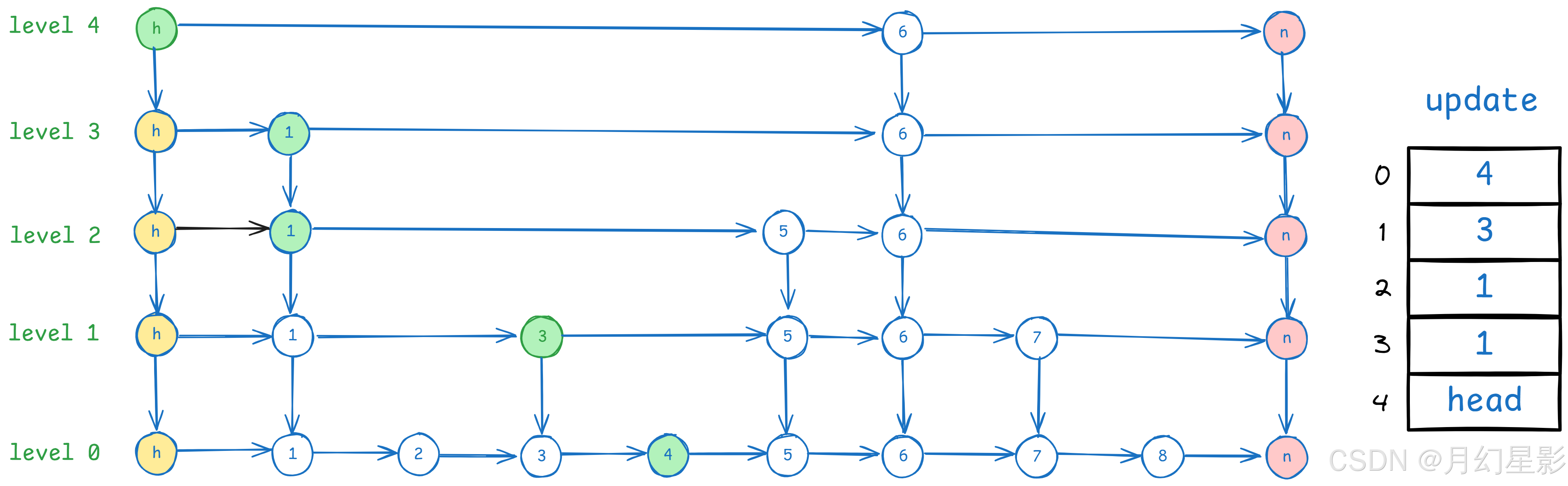
while (level > 0 && head.forward[level] == null) {
level--;
}
最后就是调整 level 了,因为删除了节点 6 之后,level4 就没有任何节点了,所以这时候 level 可以减少。
3.6 调整跳表
上面图中的跳表是理想情况下的结构,因为层数是随机的,所以大概率是不会出现这样的结构,这个方法就是用来调整跳表结构。
public void adjustDistinct() {
// 先将最底层的节点存储到一个列表中
List<SkipListNode> nodes = new ArrayList<>();
SkipListNode current = head.forward[0];
while (current != null) {
nodes.add(current);
current = current.forward[0];
}
// 清空原来的跳表结构
for (int i = 0; i <= MAX_LEVEL; i++) {
head.forward[i] = null;
}
level = 0;
// 重新构建跳表, currentLevel 表示当前构建的是哪一层
int currentLevel = 0;
while (!nodes.isEmpty()) {
List<SkipListNode> nextLevelNodes = new ArrayList<>();
SkipListNode pre = head;
int count = 0;
for (int i = 0; i < nodes.size(); i++) {
count++;
SkipListNode node = nodes.get(i);
// 设置 pre 在 currentLevel 层的后继节点为 node
pre.forward[currentLevel] = node;
// 再把 node 的后继节点设置为空
if(node.forward != null && node.forward.length > currentLevel){
node.forward[currentLevel] = null;
} else {
// 下面这里是重新生成 node 的 forward 数组
SkipListNode[] preNode = node.forward;
node.forward = new SkipListNode[currentLevel + 1];
for (int j = 0; j < preNode.length; j++) {
node.forward[j] = preNode[j];
}
node.forward[currentLevel] = null;
}
pre = node;
// 每一层隔 2 隔节点就把这个节点放到 nextLevelNodes 中用于构建下一层
if (count % 2 == 0) {
nextLevelNodes.add(node);
}
}
// 层数 + 1
if (!nextLevelNodes.isEmpty()) {
currentLevel++;
level = currentLevel;
}
nodes = nextLevelNodes;
}
}
上面的逻辑就不多说了,总体来说就是先把 level0 的节点存起来,然后遍历一层一层构建。
不过要注意中间有一段逻辑是重新构建 forward 数组的。
// 下面这里是重新生成 node 的 forward 数组
if(node.forward != null && node.forward.length > currentLevel){
node.forward[currentLevel] = null;
} else {
SkipListNode[] preNode = node.forward;
node.forward = new SkipListNode[currentLevel + 1];
for (int j = 0; j < preNode.length; j++) {
node.forward[j] = preNode[j];
}
node.forward[currentLevel] = null;
}
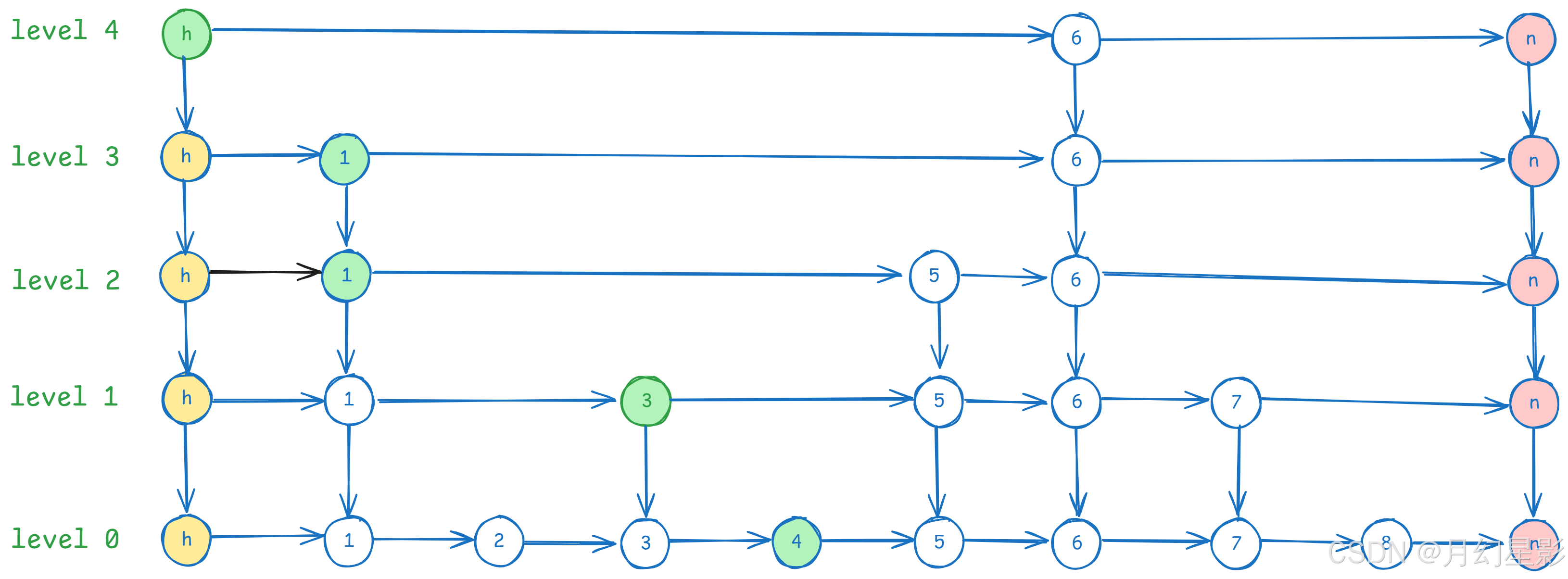
这个逻辑会重新生成 forward 数组,避免数组下标越界,举个例子,看下面图片。
由于上面代码重新构建跳表会使用偶数节点构建,也就是说 level0 是 1 - 8,level1 就是 2, 4, 6, 8,所以上面图中 2 节点原来 forward 的长度就是 1,因为节点 2 只在 level0 有后继节点。但是重新构建之后 2 在 level1 也有了后继节点,所以这种情况下就需要重新创建节点 2 的 forward 数组,将长度设置为 2,这样一来在构建 level1 的时候设置节点 2 的 forward[1] 就不会异常了。
3.7 打印跳表
这个方法用于打印跳表的结构。
public void printSkipList() {
for (int i = level; i >= 0; i--) {
SkipListNode node = head.forward[i];
System.out.print("Level " + i + ": ");
while (node != null) {
System.out.print("(" + node.key + ", " + node.value + ") ");
node = node.forward[i];
}
System.out.println();
}
}
3.8 测试方法
下面就是测试的 main 方法。
public class SkipLsit{
public static void main(String[] args) {
SkipList skipList = new SkipList();
skipList.insert(1, 1);
skipList.insert(2, 2);
skipList.insert(3, 3);
skipList.insert(4, 4);
skipList.insert(5, 5);
skipList.insert(6, 6);
skipList.printSkipList();
System.out.println();
System.out.println(skipList.searchBK(5)); // 输出: 5
skipList.delete(5);
System.out.println(skipList.searchBK(5)); // 输出: Integer.MIN_VALUE
skipList.printSkipList();
System.out.println();
// 调整跳表层级
skipList.adjustDistinct();
skipList.printSkipList();
System.out.println();
skipList.insert(5, 5);
skipList.insert(7, 7);
skipList.insert(8, 8);
skipList.printSkipList();
System.out.println(skipList.searchBK(8)); // 输出: 8
System.out.println();
skipList.adjustDistinct();
skipList.printSkipList();
System.out.println();
}
}
输出结果:
Level 1: (4, 4)
Level 0: (1, 1) (2, 2) (3, 3) (4, 4) (5, 5) (6, 6)
5
-2147483648
Level 1: (4, 4)
Level 0: (1, 1) (2, 2) (3, 3) (4, 4) (6, 6)
Level 2: (4, 4)
Level 1: (2, 2) (4, 4)
Level 0: (1, 1) (2, 2) (3, 3) (4, 4) (6, 6)
Level 2: (4, 4) (7, 7)
Level 1: (2, 2) (4, 4) (7, 7)
Level 0: (1, 1) (2, 2) (3, 3) (4, 4) (5, 5) (6, 6) (7, 7) (8, 8)
8
Level 3: (8, 8)
Level 2: (4, 4) (8, 8)
Level 1: (2, 2) (4, 4) (6, 6) (8, 8)
Level 0: (1, 1) (2, 2) (3, 3) (4, 4) (5, 5) (6, 6) (7, 7) (8, 8)
4. 跳表使用
跳表特点就是时间复杂度较低,同时跳表的节点是有序的,非常适合用于快速查询的场景。Java 的 ConcurrentSkipListMap 就是用的跳表来作为底层结构,提供了线程安全的有序映射和有序集合的实现。
- Redis 的 Sorted Set 就使用了跳表来实现,可以根据 score 进行快速排序和查询。
- 一致性 hash 中,可以通过跳表来查询出当前传入的 key 对应的节点。
总的来说,对于需要用到有序集合的场景,都可以考虑选择跳表。
如有错误,欢迎指出!!!