概述
如果你只是需要快速使用工具来进行问题排查,包括但不限于函数调用栈跟踪、函数调用子函数流程、函数参数、函数返回结果,那么推荐你直接使用 BCC trace 或 Brendan Gregg 封装的 perf-tools 工具即可,本文尝试从手工操作 Ftrace 跟踪工具的方式展示在底层是如何通过 tracefs 实现这些能力的。如果你对某个跟踪主题感兴趣,建议直接跳转到相关的主题查看。
探针
为了捕捉程序运行情况,我们在程序中设置一些 “ 陷阱 ”,并设置处理程序,我们称之为探针。有的探针是在代码中预定义的,有的是在运行时动态添加的。
静态探针
静态探针是事先在程序中定义好,即代码中写死的,并编译到程序或者内核的探针。静态探针只有被开启时才会运行,不开启就不会运行,常见的静态探针包括内核中的跟踪点(tracepoints)和 USDT(Userland Statically Defined Tracing)探针。
tracepoints
tracepoints 在内核代码中埋下钩子,在运行时调用相连接的探针。它有“打开”(已连接探针)和“关闭”(未连接探针)两种状态。当跟踪点处于“关闭”状态时,它没有任何作用,只增加微小的时间损失(检查分支的条件)和空间损失。当跟踪点为“ 打开”时,每次在调用者的执行上下文中执行跟踪点时,都会调用相连接的探针。探针函数执行完后,将返回到调用方。 可以将 tracepoints 放置在代码中的重要位置, 用于应用观察和性能统计。
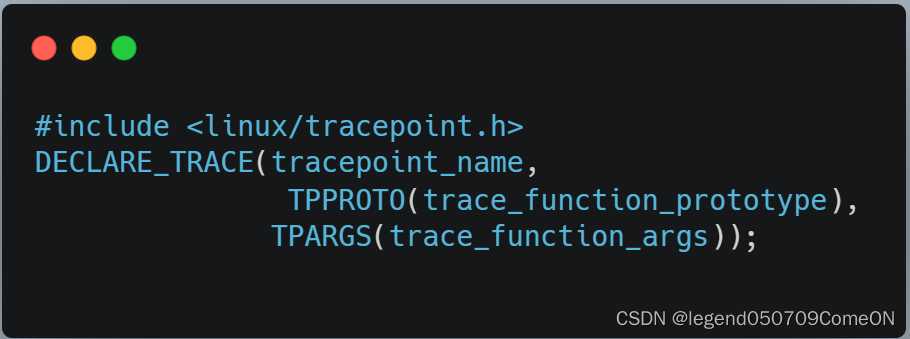
如果用户准备为 kernel 加入新的 tracepoint,每个 tracepoint 必须以下列格式声明:
上面的宏定义了一个新的 tracepoint 叫 tracepoint_name。与这个 tracepoint 关联的 probe 函数必须与 TPPROTO 宏定义的函数 prototype 一致,probe 函数的参数列表必须与TPARGS 宏定义的一致。
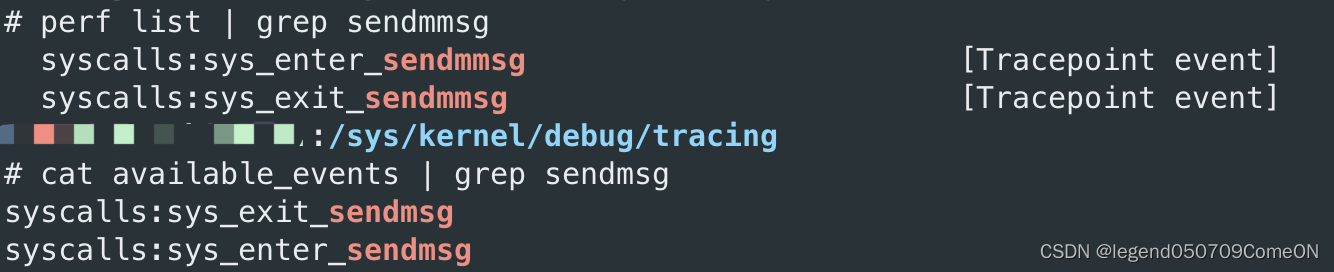
使用 perf list 查看内核中预定义的 tracepoints
USDT
USDT和tracepoint类似,只不过是用户态的。
动态探针
动态探针是应用程序没有定义,在程序运行时动态添加的探针。
kprobes
KProbes 是 Linux 内核的调试机制,也可以用于监视生产系统中的事件。您可以使用它来解决性能瓶颈,记录特定事件,跟踪问题等。
KProbe需要定义 pre-handler 和 post-handler,当被探测的指令要被执行时,先执行pre-handler程序。同样,当被探测指令执行之后立即执行post-handler。
uprobes
uprobes 是Linux提供用户态的动态探针,合并于2012年7月发布的 Linux 3.5 内核中。uprobes 和 kprobes 十分相似,只不过用在用户态而已。 uprobes 可以检测到用户态函数入口和出口的位置。uprobes 工作原理和 kprobes 差不多,它会在目标位置插入一个断点,这样当程序执行流执行到这个地方会去执行我们设置的 uprobe handle。
小结
快速说明:
-
kprobe
为内核中提供的动态跟踪机制,/proc/kallsyms 中的函数几乎都可以用于跟踪,但是内核函数可能随着版本演进而发生变化,为非稳定的跟踪机制,数量比较多。 -
uprobe
为用户空间提供的动态机制; -
tracepoint
是内核提供的静态跟踪点,为稳定的跟踪点,需要研发人员代码编写,数量有限; -
usdt :(user-level statically defined tracing)用户态预定义静态跟踪
为用户空间提供的静态跟踪点 【本次暂不涉及】
ftrace 介绍
ftrace是一个linux内部的一个trace工具,用于帮助开发者和系统设计者知道内核当前正在干什么,从而更好的去分析性能问题。
ftrace的由来
ftrace是由Steven Rostedy和Ingo Molnar在内核2.6.27版本中引入的,那个时候,systemTap已经开始崭露头角,其它的trace工具包括LTTng等已经发展多年,那么为什么人们还需要开发一个trace工具呢?
SystemTap项目是 Linux 社区对 SUN Dtrace 的反应,目标是达到甚至超越 Dtrace 。因此 SystemTap 设计比较复杂,Dtrace 作为 SUN 公司的一个项目开发了多年才最终稳定发布,况且得到了 Solaris 内核中每个子系统开发人员的大力支持。 SystemTap 想要赶超 Dtrace,困难不仅是一样,而且更大,因此她始终处在不断完善自身的状态下,在真正的产品环境,人们依然无法放心的使用它。
不当的使用和 SystemTap 自身的不完善都有可能导致系统崩溃。
Ftrace的设计目标简单,本质上是一种静态代码插装(stub)技术,不需要支持某种编程接口让用户自定义 trace 行为。静态代码插装技术更加可靠,不会因为用户的不当使用而导致内核崩溃。 ftrace 代码量很小,稳定可靠。
同时Ftrace 有重大的创新:
- 函数入口:
Ftrace 只需要在函数入口插入一个外部调用:mcount/fentry- 函数出口:
Ftrace 巧妙的拦截了函数返回的地址,从而可以在运行时先跳到一个事先准备好的统一出口,记录各类信息,然后再返回原来的地址- ftrace 开销
Ftrace 在链接完成以后,把所有插入点地址都记录到一张表中,然后默认把所有插入点都替换成为空指令(nop),因此默认情况下 Ftrace 的开销几乎是 0- ftrace操作:
Ftrace 可以在运行时根据需要通过 Sysfs 接口使能和使用,即使在没有第三方工具的情况下也可以方便使用
ftrace 原理
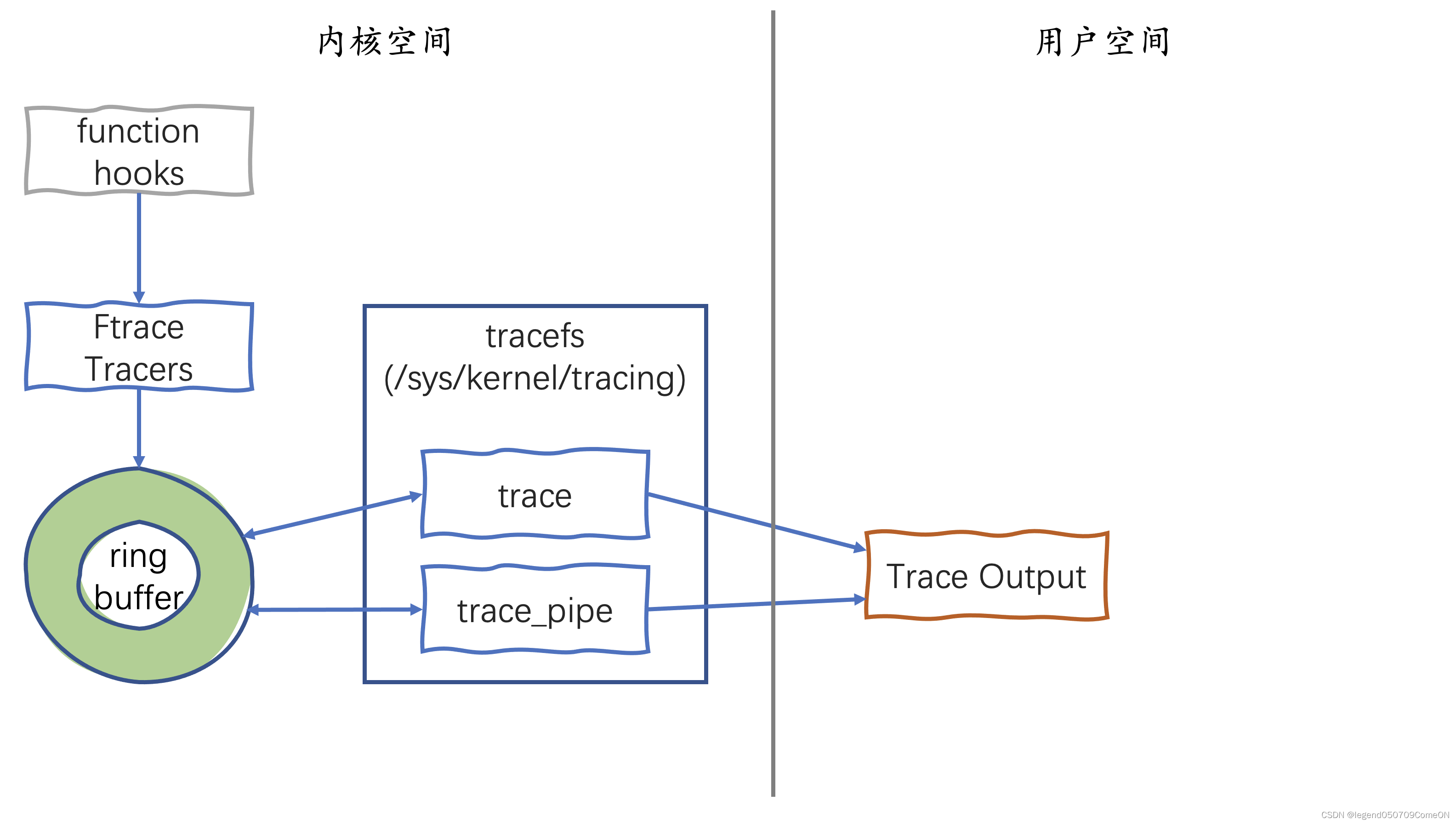
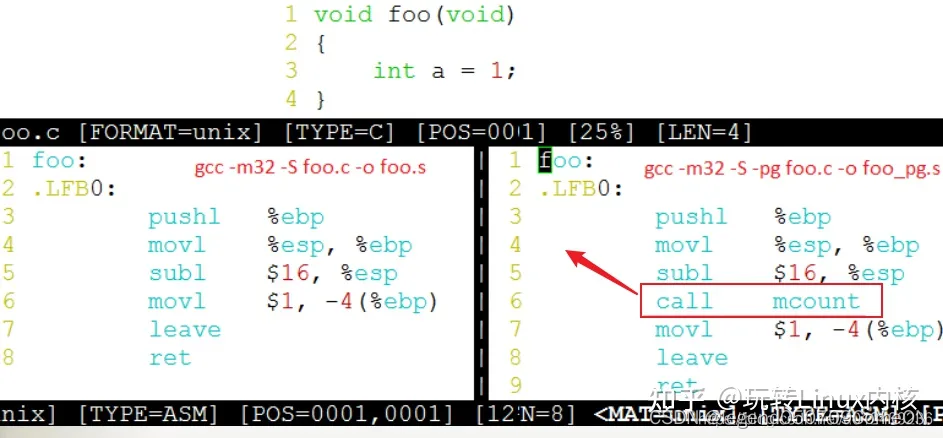
ftrace的名字由function trace而来。function trace是利用gcc编译器(gcc 的 -pg 选项)在编译时在每个函数的入口地址放置一个probe点,这个probe点会调用一个probe函数(gcc默认调用名为mcount/__fentry__的函数),如果跟踪功能被打开,这样这个 probe函数会对每个执行的内核函数进行跟踪(其实有少数几个内核函数不会被跟踪),并打印log到一个内核中的环形缓存(ring buffer)中,而用户可以通过debugfs来访问这个环形缓存中的内容。
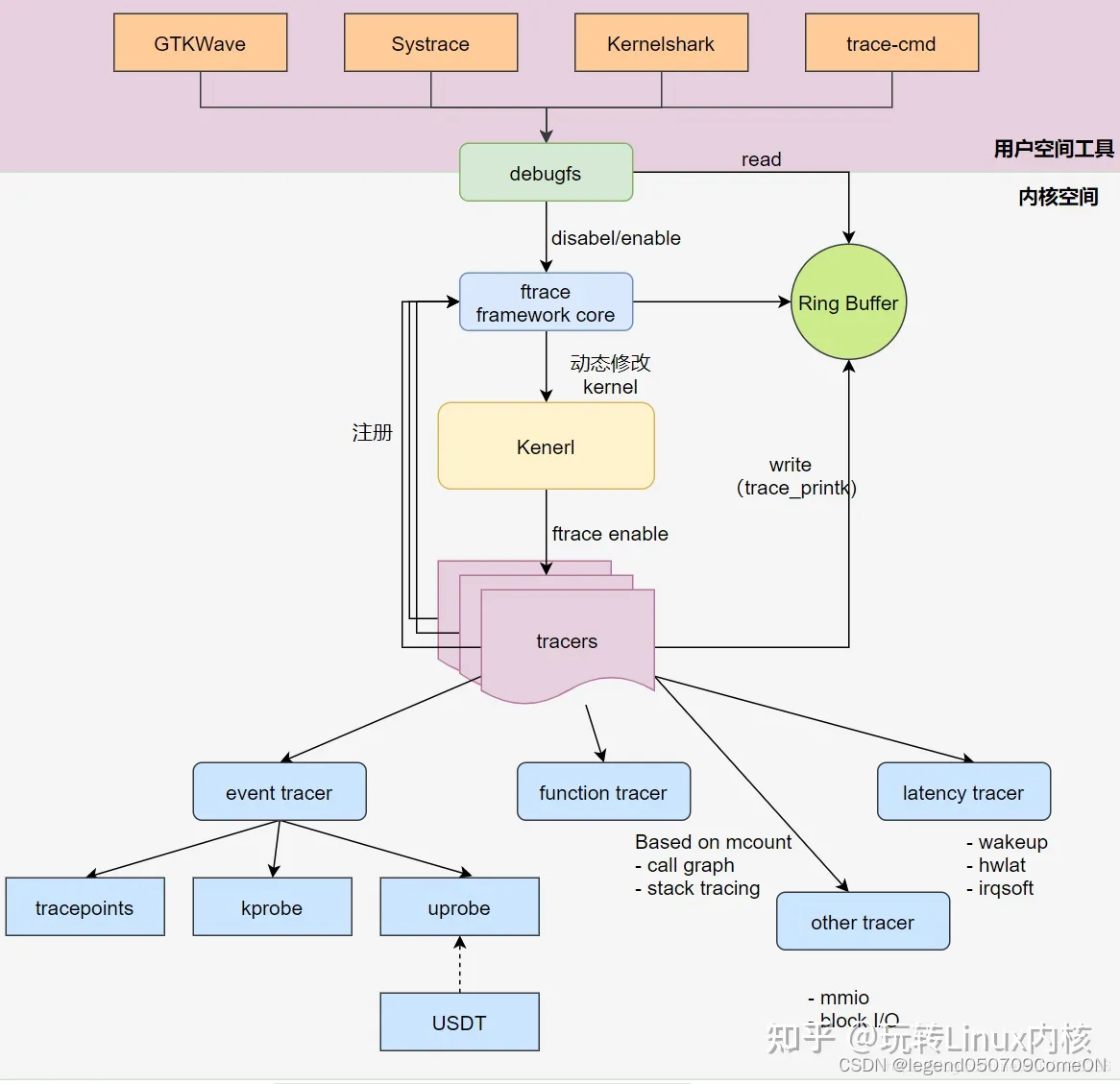
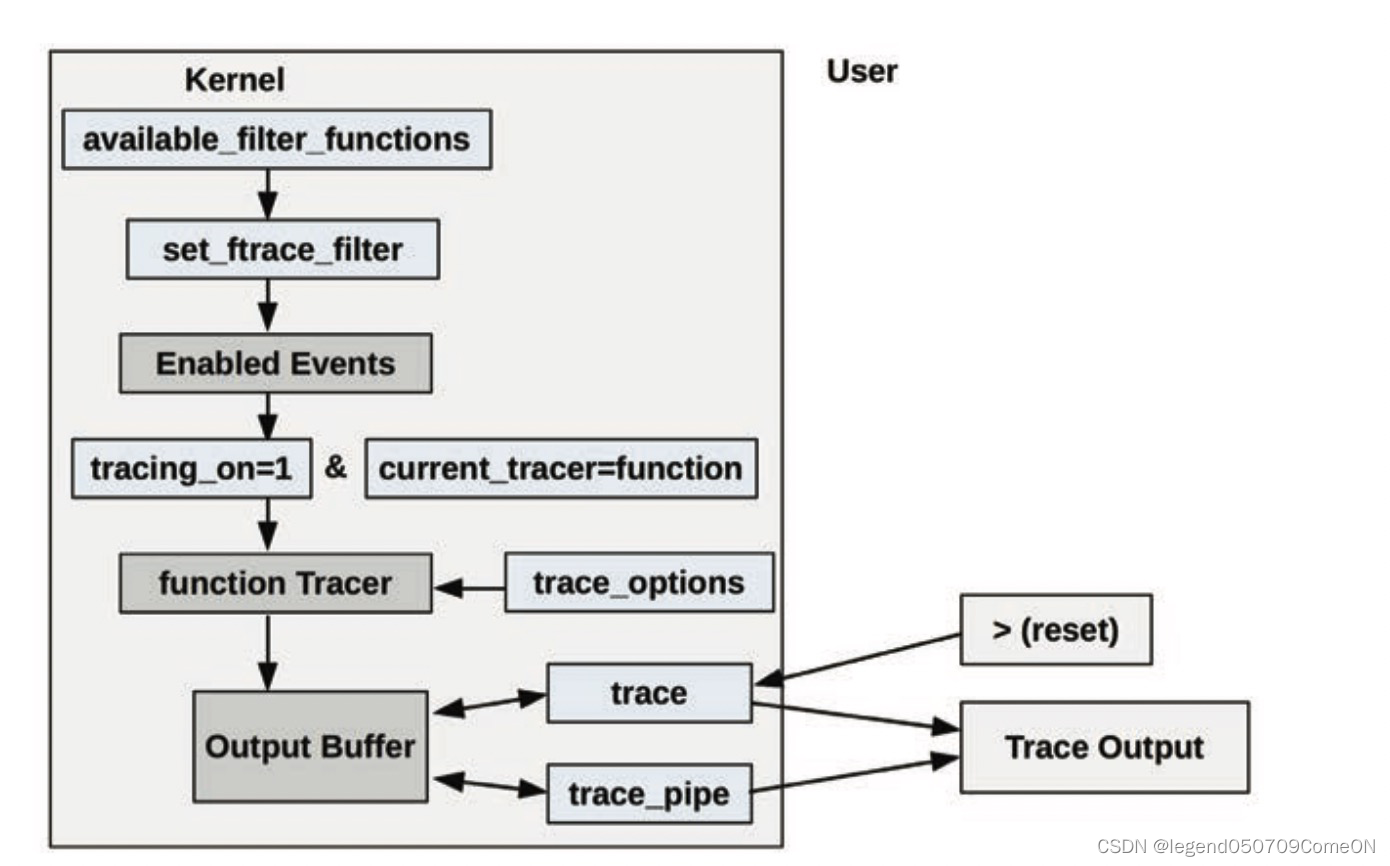
各类tracer往ftrace主框架注册,不同的trace则在不同的probe点把信息通过probe函数给送到ring buffer中,再由暴露在用户态debufs实现相关控制。其主要的框架图如下图所示
其主要由两部分构成:
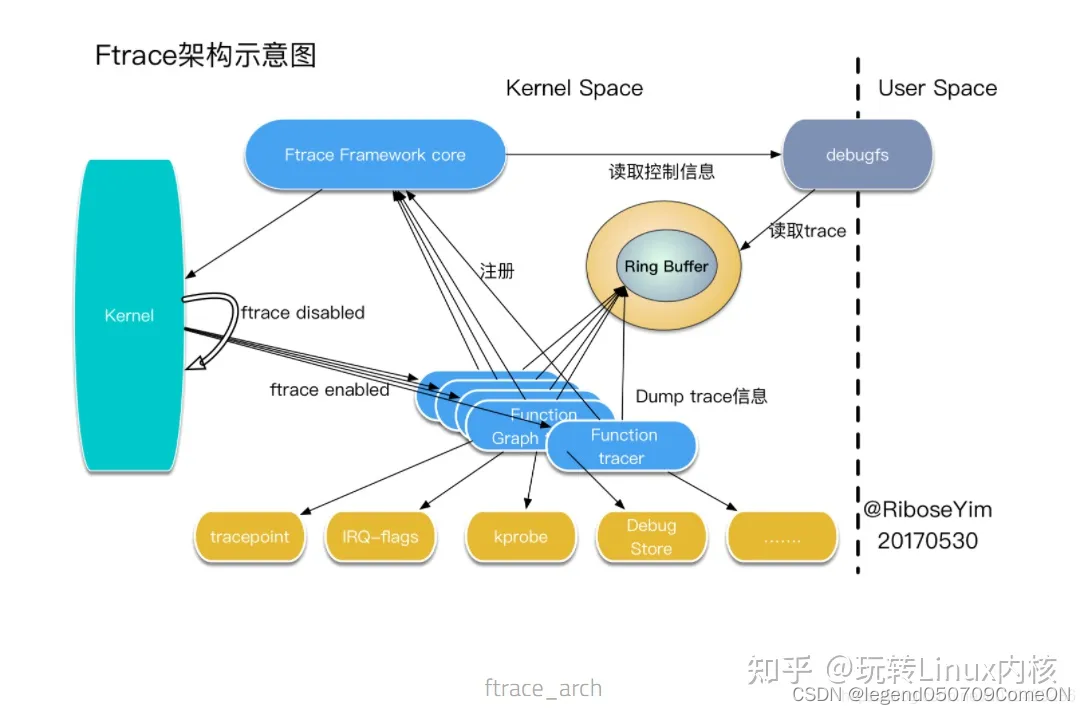
- ftrace Framework core:
其主要包括利用 debugfs 系统在 /debugfs 下建立 tracing 目录,对用户空间输出 trace 信息,并提供了一系列的控制文件 - 一系列的 tracer:
每个 tracer 完成不同的功能,ftrace 的 trace 信息保存在 ring buffer(内存缓冲区) 中,它们统一由 framework 管理。
从上图可以看出,Ftrace 提供的 function hooks 机制在内核函数入口处埋点,根据配置调用特定的 tracer, tracer将数据写入 ring buffer。Ftrace实现了一个无锁的ring buffer,所有的跟踪信息都存储在 ring buffer 中。用户通过 tracefs 文件系统接口访问函数跟踪的输出结果。
你可能已经意识到,如果每个内核函数入口都加入跟踪代码,必然会非常影响内核的性能,幸好Ftrace支持动态跟踪功能。如果启用了 CONFIG_DYNAMIC_FTRACE 选项,编译内核时所有的mcount/fentry调用点都会被收集记录。在内核的初始化启动过程中,会根据编译期记录的列表,将mcount/fentry调用点替换为 NOP 指令。NOP 就是 no-operation,不做任何事,直接转到下一条指令。因此在没有开启跟踪功能的情况下,Ftrace不会对内核性能产生任何影响。在开启追踪功能时,Ftrace才会将 NOP 指令替换为mcount/fentry。
Ftrace 跟踪工具组成
Ftrace 跟踪工具由性能分析器(profiler)和跟踪器(tracer)两部分组成:
- 性能分析器,用来提供统计和直方图数据(需要 CONFIG_ FUNCTION_PROFILER=y)
函数性能分析
直方图 - 跟踪器,提供跟踪事件的详情:
函数跟踪(function)
跟踪点(tracepoint)
kprobe
uprobe
函数调用关系(function_graph)
hwlat 等
除了操作原始的文件接口外,也有一些基于 Ftrace 的前端工具,比如 perf-tools 和 trace-cmd (界面 KernelShark)等。整体跟踪及前端工具架构图如下:
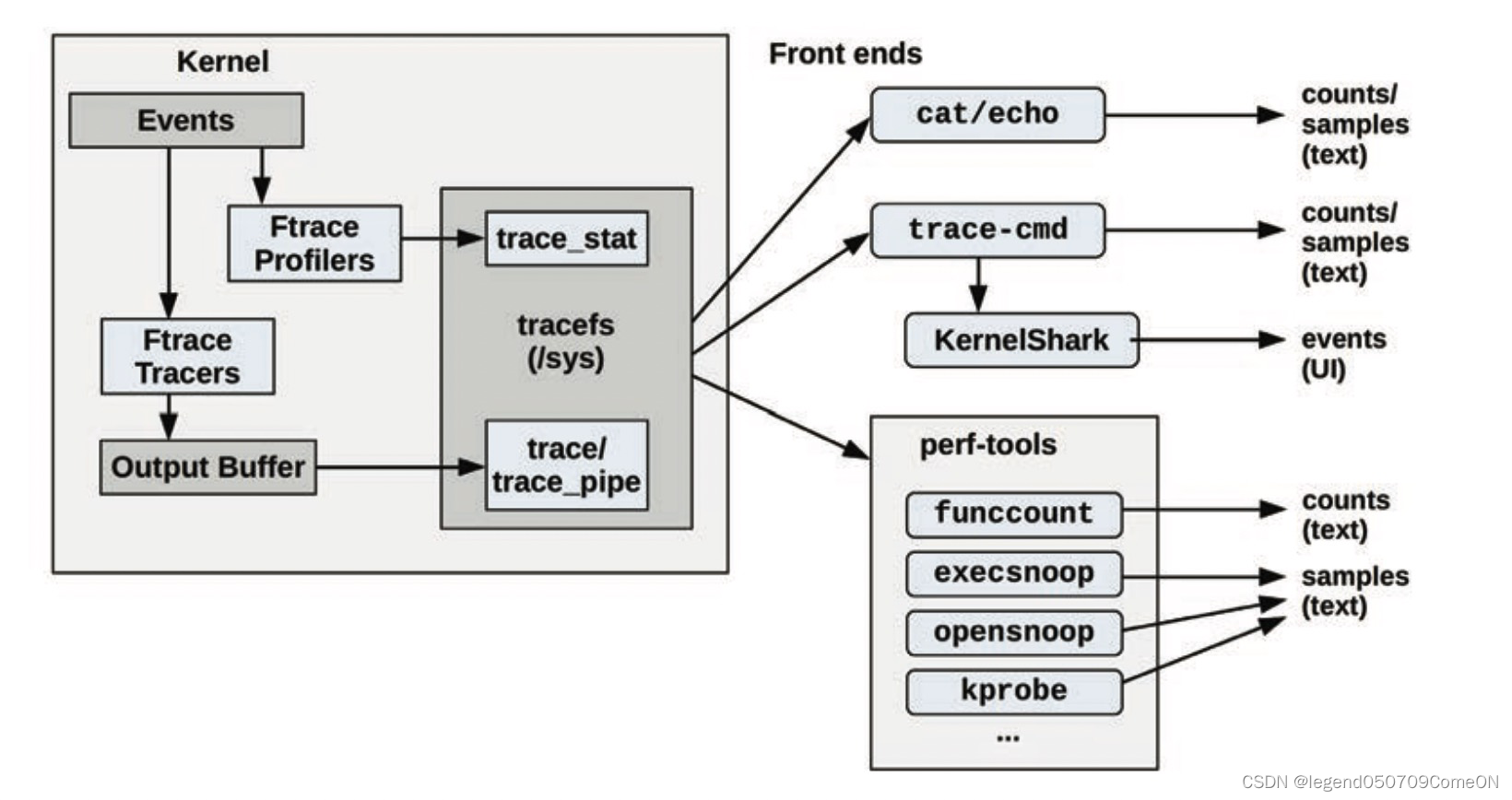
Ftrace 的使用的接口为 tracefs 文件系统,需要保证该文件系统进行加载:
$ sysctl -q kernel.ftrace_enabled=1
$ mount -t tracefs tracefs /sys/kernel/tracing
$ mount -t debugfs,tracefs
tracefs on /sys/kernel/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
debugfs on /sys/kernel/debug type debugfs (rw,nosuid,nodev,noexec,relatime)
tracefs on /sys/kernel/debug/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
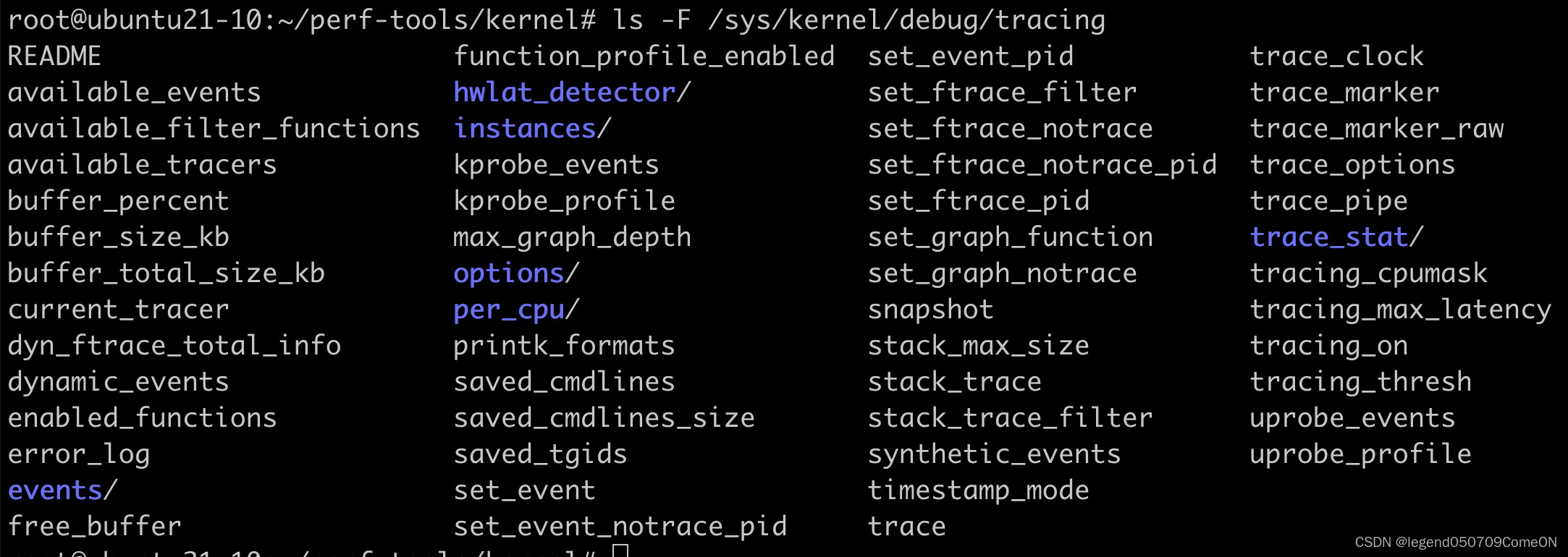
$ ls -F /sys/kernel/debug/tracing # 完整目录如下图

ftrace 的动态/静态探针
对于ftrace有两种主要的跟踪机制往缓冲区写数据:
-
动态探针
可以动态跟踪内核函数的调用栈,包括function trace,function graph trace两个tracer。其原理是利用mcount/__fentry__机制,在内核编译时,在每个函数入口保留数个字节,然后在使用ftrace时,将保留的字节替换为需要的指令,比如跳转到需要的执行探测操作的代码。 -
静态探针
是在内核代码中调用ftrace提供的相应接口实现,称之为静态是因为,是在内核代码中写死的,静态编译到内核代码中的,在内核编译后,就不能再动态修改。在开启ftrace相关的内核配置选项后,内核中已经在一些关键的地方设置了静态探测点,需要使用时,即可查看到相应的信息。
ftrace 动态探针利用gcc编译器的profile特性在所有函数入口处添加了一段插桩(stub)代码,ftrace重载这段代码来实现trace功能。gcc编译器的"-pg"选项会在每个函数入口处加入mcount/__fentry__的调用代码,原本mcount有libc实现,因为内核不会链接libc库,因此ftrace编写了自己的mcount stub函数。
ftrace 控制机制
在使用ftrace前,需要确保内核配置编译了其配置选项。
cat /boot/config-`uname -r` | grep -i ftrace
CONFIG_FTRACE=y
CONFIG_HAVE_FUNCTION_TRACER=y
CONFIG_HAVE_FUNCTION_GRAPH_TRACER=y
CONFIG_HAVE_DYNAMIC_FTRACE=y
CONFIG_FUNCTION_TRACER=y
CONFIG_IRQSOFF_TRACER=y
CONFIG_SCHED_TRACER=y
CONFIG_ENABLE_DEFAULT_TRACERS=y
CONFIG_FTRACE_SYSCALLS=y
CONFIG_PREEMPT_TRACER=y
ftrace通过debugfs文件系统向用户空间提供访问接口,因此需要修改系统启动时挂载debugfs,可以修改系统的/etc/fstab文件或手动挂载。
1> 挂载
mount -t debugfs debugfs /sys/kernel/debug
2> 查看
# mount | grep -i -e trace -e debug
debugfs on /sys/kernel/debug type debugfs (rw,relatime)
tracefs on /sys/kernel/debug/tracing type tracefs (rw,relatime)
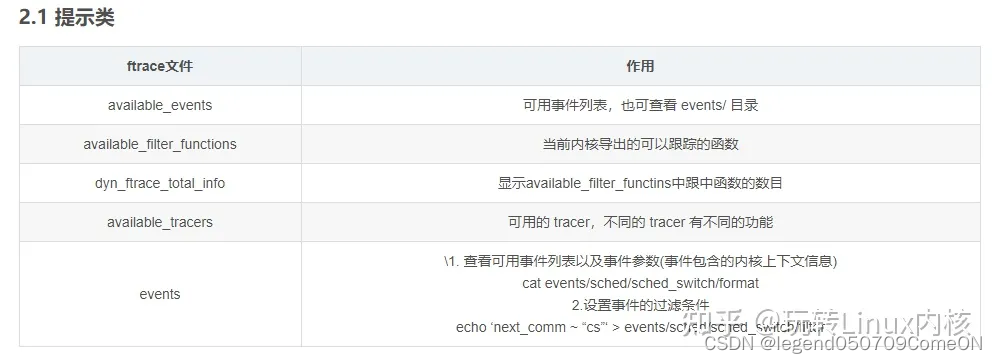
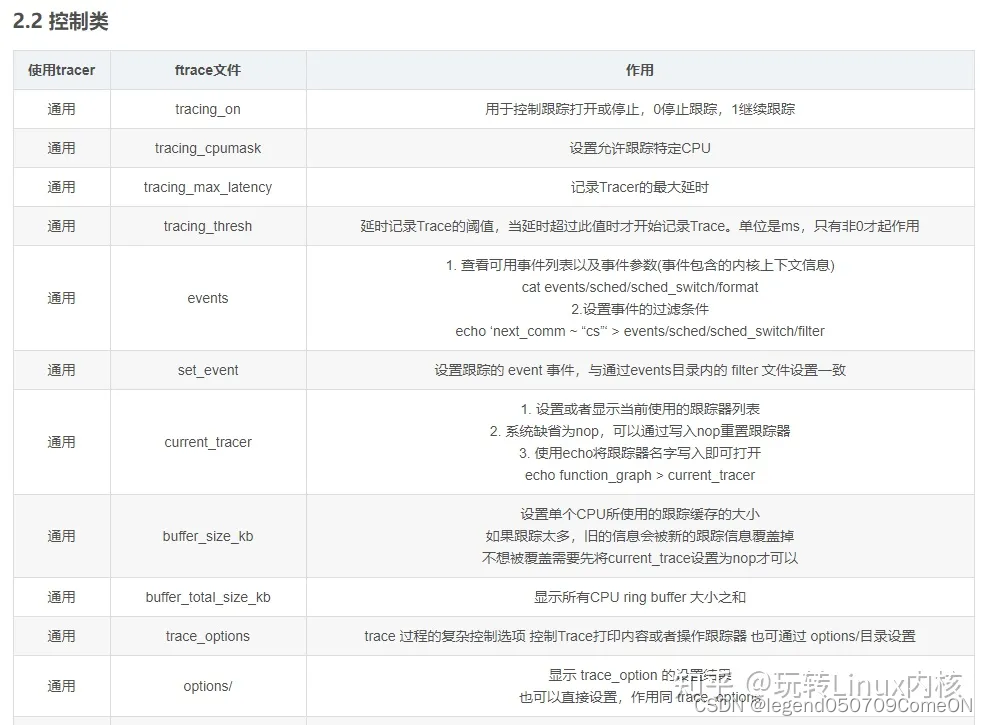
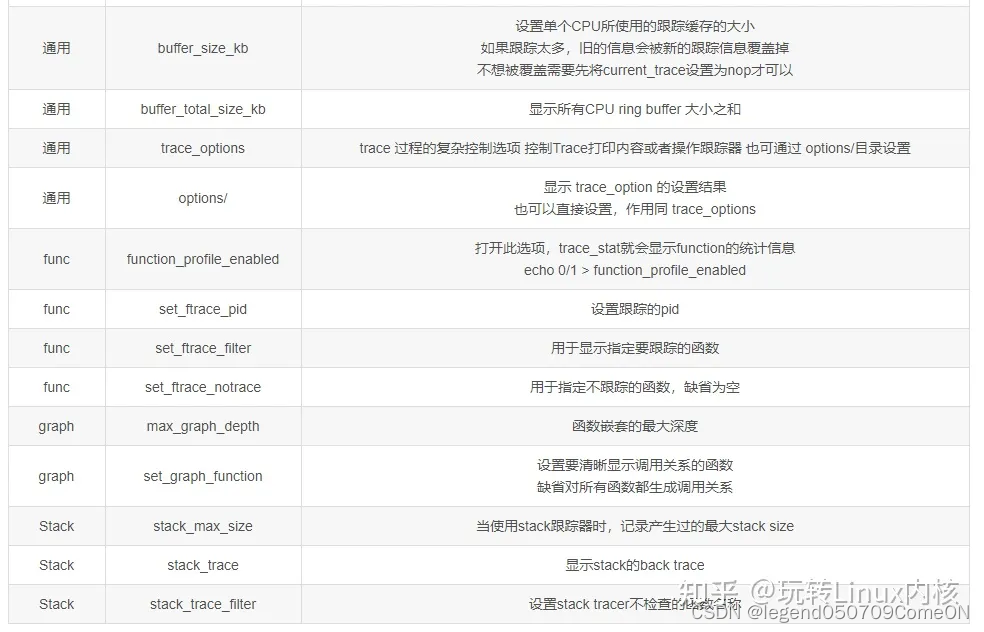
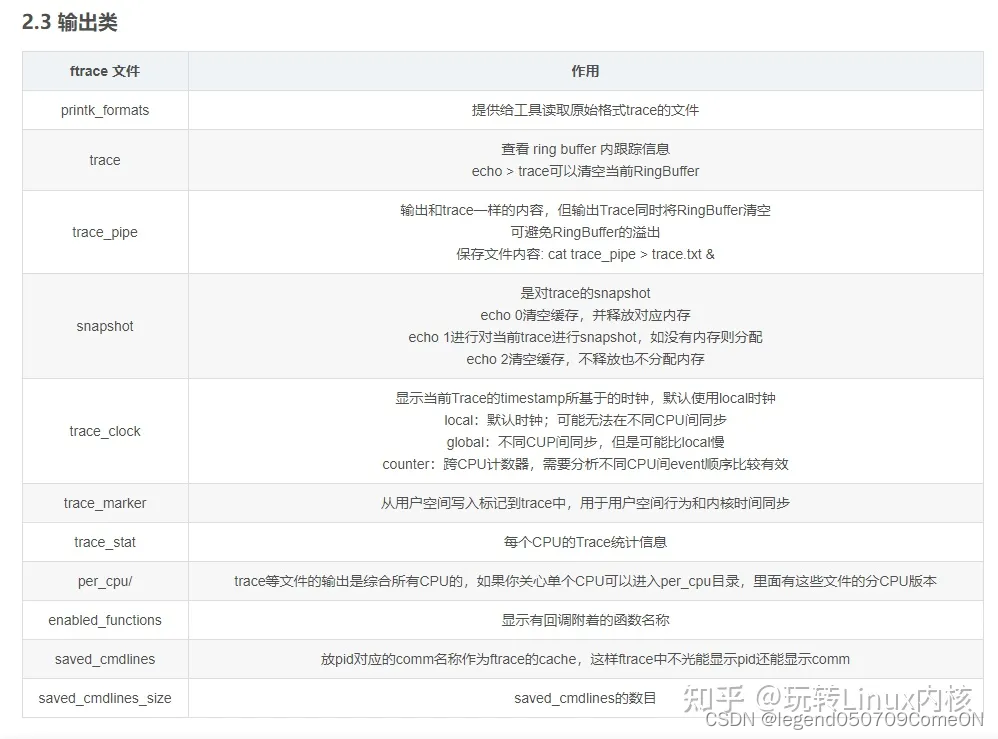
tracing 目录下的文件分成了下面四类:
- 提示类:显示当前系统可用的event,tracer 列表
- 控制类:控制 ftrace 的跟踪参数
- 显示类:显示 trace 信息
- 辅助类:一些不明或者不重要的辅助信息
ftrace 的使用
在/sys/kernel/debug/tracing目录下提供了各种跟踪器(tracer)和事件(event),一些常用的选项如下:
avaliable_tracers: 列出当前系统支持的跟踪器。
avalibale_events: 列出当前系统支持的event事件
current_tracer: 设置和显示当前正在使用的跟踪器。使用echo命令可以把跟踪器的名字写入该文件,即可以切换不同的跟踪器。默认为nop,即不做任何跟踪操作。
trace: 读取跟踪信息。通过cat命令查看ftrace记录下来的跟踪信息。
tracing_on: 用于开始或暂停跟踪
trace_options: 设置ftrace的一些相关选项
注:追踪器tracer和事件event是两个类别,平行的,一个是内核动态探针kprobe,一个是内核的静态探针tracepoint.
ftrace跟踪器tracer
ftrace当前包含多个跟踪器,很方便用户用来跟踪不同类型的信息,例如进程睡眠唤醒、抢占延迟的信息。查看avaliable_tracers可以知道当前系统支持哪些跟踪器。
常用的ftrace跟踪器如下:
- nop
不会跟踪任何内核活动,将 nop 写入 current_tracer 文件可以删除之前所使用的跟踪器,并清空之前收集到的跟踪信息,即刷新 trace 文件。- function
跟踪内核函数执行情况。- function_graph
可以显示类似C语言的函数调用关系图,比较直观- wakeup:
跟踪进程的调度延迟,即高优先级进程从进入 ready 状态到获得 CPU 的延迟时间。该 tracer 只针对实时进程。- irqsoff
当中断被禁止时,系统无法相应外部事件,比如键盘和鼠标,时钟也无法产生 tick 中断。这意味着系统响应延迟,irqsoff 这个 tracer 能够跟踪并记录内核中哪些函数禁止了中断,对于其中中断禁止时间最长的,irqsoff 将在 log 文件的第一行标示出来,从而使开发人员可以迅速定位造成响应延迟的罪魁祸首- preemptoff
和irqsoff类似,preemptoff tracer 跟踪并记录禁止内核抢占的函数,并清晰地显示出禁止抢占时间最长的内核函数。- preemptirqsoff
综合了irqoff和preemptoff两个功能;跟踪和记录禁止中断或者禁止抢占的内核函数,以及禁止时间最长的函数- sched_switch
对内核中的进程调度活动进行跟踪
tracer 使用三板斧
- 设置 tracer 类型
- 设置 tracer 参数
- 使能 tracer
irqsoff跟踪器
当中断被关闭(俗称关中断)了,CPU就不能响应其他的事件,如果这时有一个鼠标中断,要在下一次开中断时才能响应这个鼠标中断,这段延迟称为中断延迟。向current_tracer文件写入irqsoff字符串即可打开irqsoff来跟踪中断延迟。
# cd /sys/kernel/debug/tracing
# echo 0 > options/function-trace // 关闭function-trace可以减少一些延迟
# echo irqsoff > current_tracer
# echo 1 > tracing_on
[...等一会...]
# echo 0 > tracing_on
# cat trace
function跟踪器
function,函数调用追踪器, 跟踪函数调用,默认跟踪所有函数,如果设置set_ftrace_filter, 则跟踪过滤的函数,可以看出哪个函数何时调用;
如果只想跟踪某个进程,可以使用set_ftrace_pid。
# cd /sys/kernel/debug/tracing
# cat set_ftrace_pid
no pid
# echo 5945 > set_ftrace_pid
# cat set_ftrace_pid
5748
# echo function > current_tracer
# echo 1 > tracing_on
[...等一会...]
# echo 0 > tracing_on
# cat trace
available_filter_functions:列出当前可以跟踪的内核函数,不在该文件中列出的函数,无法跟踪其活动
enabled_functions:显示有回调附着的函数名称。
function_profile_enabled:打开此选项,在trace_stat中就会显示function的统计信息。
set_ftrace_filter:用于指定跟踪的函数
set_ftrace_notrace:用于指定不跟踪的函数
set_ftrace_pid:用于指定要跟踪特定进程的函数
此外,过滤器还支持如下通配符:
MATCH*:匹配所有match开头的函数
*MATCH:匹配所有match结尾的函数
*MATCH*:匹配所有包含match的函数
如果跟踪所有"hrtimer"开头的函数,可以"echo hrtimer_* > set_ftrace_filter"。
还有两个非常有用的操作符,">“表示会覆盖过滤器里的内容;”>>"表示新加的函数会增加到过滤器中,但不会覆盖。
function_graph 跟踪器
function_graph 跟踪器则可以提供类似 C 代码的函数调用关系信息。通过写文件 set_graph_function 可以显示指定要生成调用关系的函数,缺省会对所有可跟踪的内核函数生成函数调用关系图。

函数图跟踪器对函数的进入与退出进行跟踪,这对于跟踪它的执行时间很有用。
设置 function_graph 的方式如下:
设置 tracer 类型为 function_graph:
echo function_graph > current_tracer
set_graph_function 表示要跟踪的函数:
echo __do_fault > set_graph_function
echo 1 > tracing_on
捕捉到的 trace 内容:
我们跟踪的是 __do_fault 函数,但是 function_graph tracer 会跟踪函数内的调用关系和函数执行时间,可以协助我们确定代码执行流程。比如一个函数内部执行了很多函数指针,不能确定到底执行的是什么函数,可以用 function_graph tracer 跟踪一下。
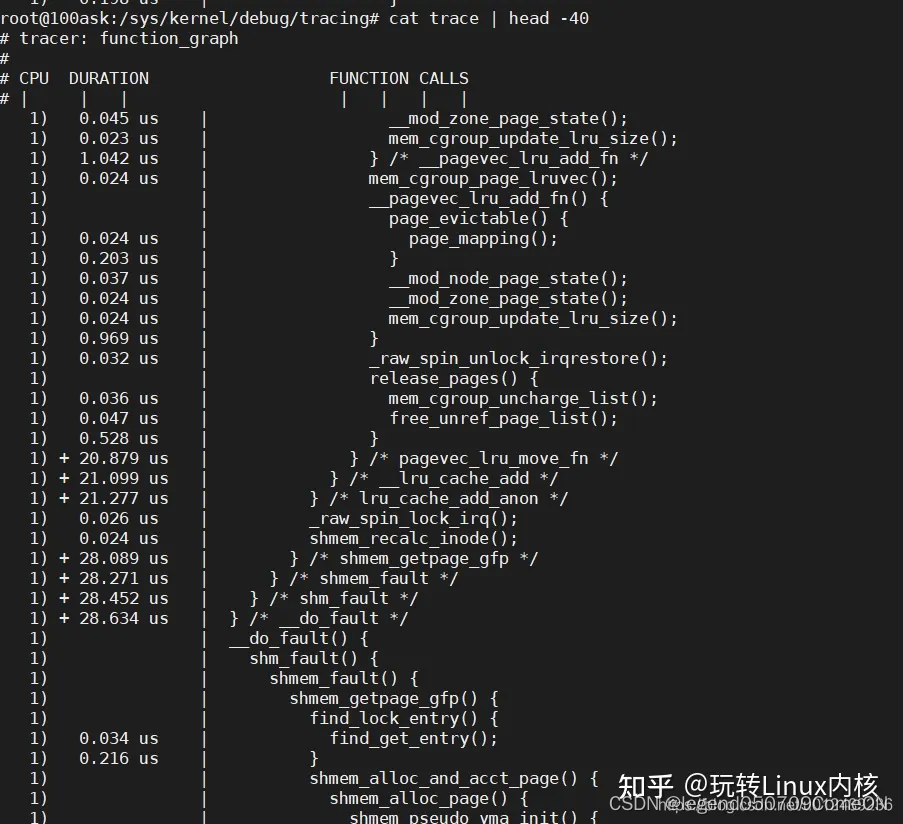
- CPU 字段给出了执行函数的 CPU 号,本例中都为 1 号 CPU。
- DURATION 字段给出了函数执行的时间长度,以 us 为单位。
- FUNCTION CALLS 则给出了调用的函数,并显示了调用流程。
需要注意的是:
对于不调用其它函数的函数,其对应行以“;”结尾,而且对应的 DURATION 字段给出其运行时长;
对于调用其它函数的函数,则在其“}”对应行给出了运行时长,该时间是一个累加值,包括了其内部调用的函数的执行时长。DURATION 字段给出的时长并不是精确的,它还包含了执行 ftrace 自身的代码所耗费的时间,所以示例中将内部函数时长累加得到的结果会与对应的外围调用函数的执行时长并不一致;不过通过该字段还是可以大致了解函数在时间上的运行开销的。
ftrace事件event
ftrace里的跟踪机制主要有两种,分别是函数和tracepoint。
tracepoint可以输出开发者想要的参数、局部变量等信息。tracepoint的位置比较固定,一般都是内核开发者添加上去的,可以把它理解为传统C语言中#if DEBUG部分。如果在运行中没有开启DEBUG,那么是不占用任何系统开销的。
trace event 就是利用 ftrace 框架,实现低性能损耗,对执行流无影响的一种信息输出机制。相比 printk,trace event:
- 不开启没有性能损耗
- 开启后不影响代码流程
- 不需要重新编译内核即可获取 debug 信息
阅读内核代码时经常会遇到以trace_开头的函数,例如CFS调度器里的update_curr()函数。
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
......
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cgroup_account_cputime(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
......
}
update_curr()函数使用了一个sched_stat_runtime的tracepoint,我们可以在avaliable_events文件中查到,把想要跟踪的事件添加到set_event文件中即可,该文件同样支持通配符。
# cd /sys/kernel/debug/tracing
# cat available_events | grep sched_stat_runtime
sched:sched_stat_runtime
# echo sched:sched_stat_runtime > set_event
# echo 1 > tracing_on
# cat trace
# echo sched:* > set_event // 支持通配符,跟踪所有sched开头的事件
# echo *:* > set_event // 跟踪系统所有事件
另外事件跟踪还支持另外一个强大的功能,可以设定跟踪条件,做到更精细化的设置。每个tracepoint都定义一个format格式,其中定义了该tracepoint支持的域。
# cd /sys/kernel/debug/tracing/events/sched/sched_stat_runtime
# cat format
name: sched_stat_runtime
ID: 246
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:char comm[16]; offset:8; size:16; signed:0;
field:pid_t pid; offset:24; size:4; signed:1;
field:u64 runtime; offset:32; size:8; signed:0;
field:u64 vruntime; offset:40; size:8; signed:0;
print fmt: "comm=%s pid=%d runtime=%Lu [ns] vruntime=%Lu [ns]", REC->comm, REC->pid, (unsigned long long)REC->runtime, (unsigned long long)REC->vruntime
例如,sched_stat_runtime这个tracepoint支持8个域,前4个是通用域,后4个是该tracepoint支持的域,comm是一个字符串域,其他都是数字域。
支持类似C语言表达式对事件进行过滤,对于数字域支持==, !=, <, <=, >, >=, &操作符,对于字符串域支持==, !=, ~操作符。
例如只想跟踪进程名字开头为sh的所有进程的sched_stat_runtime事件。
# cd /sys/kernel/debug/tracing/events/sched/sched_stat_runtime
# echo 'comm ~ "sh*"' > filter // 跟踪所有进程名字开头为sh的
echo 'pid==5658' > filter // 跟踪进程PID为5658的
输出如下:
#
# entries-in-buffer/entries-written: 474/51988245 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
Colors-5658 [003] d..2 18238.020119: sched_stat_runtime: comm=Colors pid=5658 runtime=1010360 [ns] vruntime=1531587993187 [ns]
Colors-5658 [003] dn.2 18238.023648: sched_stat_runtime: comm=Colors pid=5658 runtime=425020 [ns] vruntime=1531588418207 [ns]
Colors-5658 [003] dn.2 18238.023837: sched_stat_runtime: comm=Colors pid=5658 runtime=52780 [ns] vruntime=1531588470987 [ns]
Colors-5658 [003] dn.2 18238.024666: sched_stat_runtime: comm=Colors pid=5658 runtime=637600 [ns] vruntime=1531589108587 [ns]
ftrace的使用范例
跟踪内核函数调用、跟踪内核函数的参数、返回值;跟踪内核态中的延迟。
Ftrace 可用来快速排查以下相关问题:
- 特定内核函数调用的频次 (function)
- 内核函数在被调用的过程中流程(调用栈) (function + stack)
- 内核函数调用的子函数流程(子调用栈)(function graph)
- 由于抢占导致的高延时路径等
内核函数调用跟踪
基于 Ftrace 的内核函数调用跟踪整体架构如下所示:
这里我们尝试对于内核中的系统调用函数 __arm64_sys_openat 进行跟踪(前面两个下划线),需要注意的是 __arm64_sys_openat 是在 arm64 结构体系下 sys_openat 系统调用的包装,如果在 x86_64 架构下则为 __x64_sys_openat() ,由于我们本地的电脑是 M1 芯片,所以演示的样例以 arm64 为主。
在不同的体系结构下,可以在 /proc/kallsym 文件中搜索确认。
# 使用 function 跟踪器,并将其设置到 current_tracer
$ sudo echo function > current_tracer
# 将跟踪函数 __arm64_sys_openat 设置到 set_ftrace_filter 文件中
$ sudo echo __arm64_sys_openat > set_ftrace_filter
# 开启全局的跟踪使能
$ sudo echo 1 > tracing_on
# 运行 ls 命令触发 sys_openat 系统调用,新的内核版本中直接调用 sys_openat
$ ls -hl
# 关闭
$ sudo echo 0 > tracing_on
$ sudo echo nop > current_tracer
# 需要主要这里的 echo 后面有一个空格,即 “echo+ 空格>"
$ sudo echo > set_ftrace_filter
# 通过 cat trace 文件进行查看
$ sudo cat trace
# tracer: function
#
# entries-in-buffer/entries-written: 224/224 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
sudo-15099 [002] .... 29469.444400: __arm64_sys_openat <-invoke_syscall
sudo-15099 [002] .... 29469.444594: __arm64_sys_openat <-invoke_syscall
我们可以看到上述的结果表明了函数调用的任务名称、PID、CPU、标记位、时间戳及函数名字。
在 perf_tools 工具集中的前端封装工具为 functrace ,需要注意的是该工具默认不会设置 tracing_on 为 1, 需要在启动前进行设置,即 ”echo 1 > tracing_on“。
perf_tools 工具集中 kprobe 也可以实现类似的效果,底层基于 kprobe 机制实现,ftrace 机制中的 kprobe 在后续章节会详细介绍。
函数被调用流程(栈)
有些场景我们更可能希望获取调用该内核函数的流程(即该函数是在何处被调用),这需要通过设置 options/func_stack_trace 选项实现。
$ sudo echo function > current_tracer
$ sudo echo __arm64_sys_openat > set_ftrace_filter
$ sudo echo 1 > options/func_stack_trace # 设置调用栈选项
$ sudo echo 1 > tracing_on
$ ls -hl
$ sudo echo 0 > tracing_on
$ sudo cat trace
# tracer: function
#
# entries-in-buffer/entries-written: 292/448 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
sudo-15134 [000] .... 29626.670430: __arm64_sys_openat <-invoke_syscall
sudo-15134 [000] .... 29626.670431: <stack trace>
=> __arm64_sys_openat
=> invoke_syscall
=> el0_svc_common.constprop.0
=> do_el0_svc
=> el0_svc
=> el0_sync_handler
=> el0_sync
# 关闭
$ sudo echo nop > current_tracer
$ sudo echo > set_ftrace_filter
$ sudo echo 0 > options/func_stack_trace
perf_tools 工具集中 kprobe 通过添加 ”-s“ 参数实现同样的功能,运行的命令如下:
./kprobe -s ‘p:__arm64_sys_openat’
函数调用子流程跟踪
如果想要分析内核函数调用的子流程(即本函数调用了哪些子函数,处理的流程如何),这时需要用到 function_graph 跟踪器,从字面意思就可看出这是函数调用关系跟踪。
基于 __arm64_sys_openat 子流程调用关系的跟踪的完整设置过程如下:
# 将当前 current_tracer 设置为 function_graph
$ sudo echo function_graph > current_tracer
$ sudo echo __arm64_sys_openat > set_graph_function
# 设置跟踪子函数的最大层级数
$ sudo echo 3 > max_graph_depth # 设置最大层级
$ sudo echo 1 > tracing_on
$ ls -hl
$ sudo echo 0 > tracing_on
#$ echo nop > set_graph_function
$ sudo cat trace
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
1) | __arm64_sys_openat() {
1) | do_sys_openat2() {
1) 0.875 us | getname();
1) 0.125 us | get_unused_fd_flags();
1) 2.375 us | do_filp_open();
1) 0.084 us | put_unused_fd();
1) 0.125 us | putname();
1) 4.083 us | }
1) 4.250 us | }
在本样例中 __arm64_sys_openat 函数的调用子流程仅包括 do_sys_openat2() 子函数,而 do_sys_openat2() 函数又调用了 getname()/get_unused_fd_flags() 等子函数。
这种完整的子函数调用关系,对于我们学习内核源码和分析线上的问题都提供了便利,排查问题时则可以顺藤摸瓜逐步缩小需要分析的范围。
内核跟踪点(tracepoint)跟踪
可基于 ftrace 跟踪内核静态跟踪点,可跟踪的完整列表可通过 available_events 查看。events 目录下查看到各分类的子目录,详见下图:
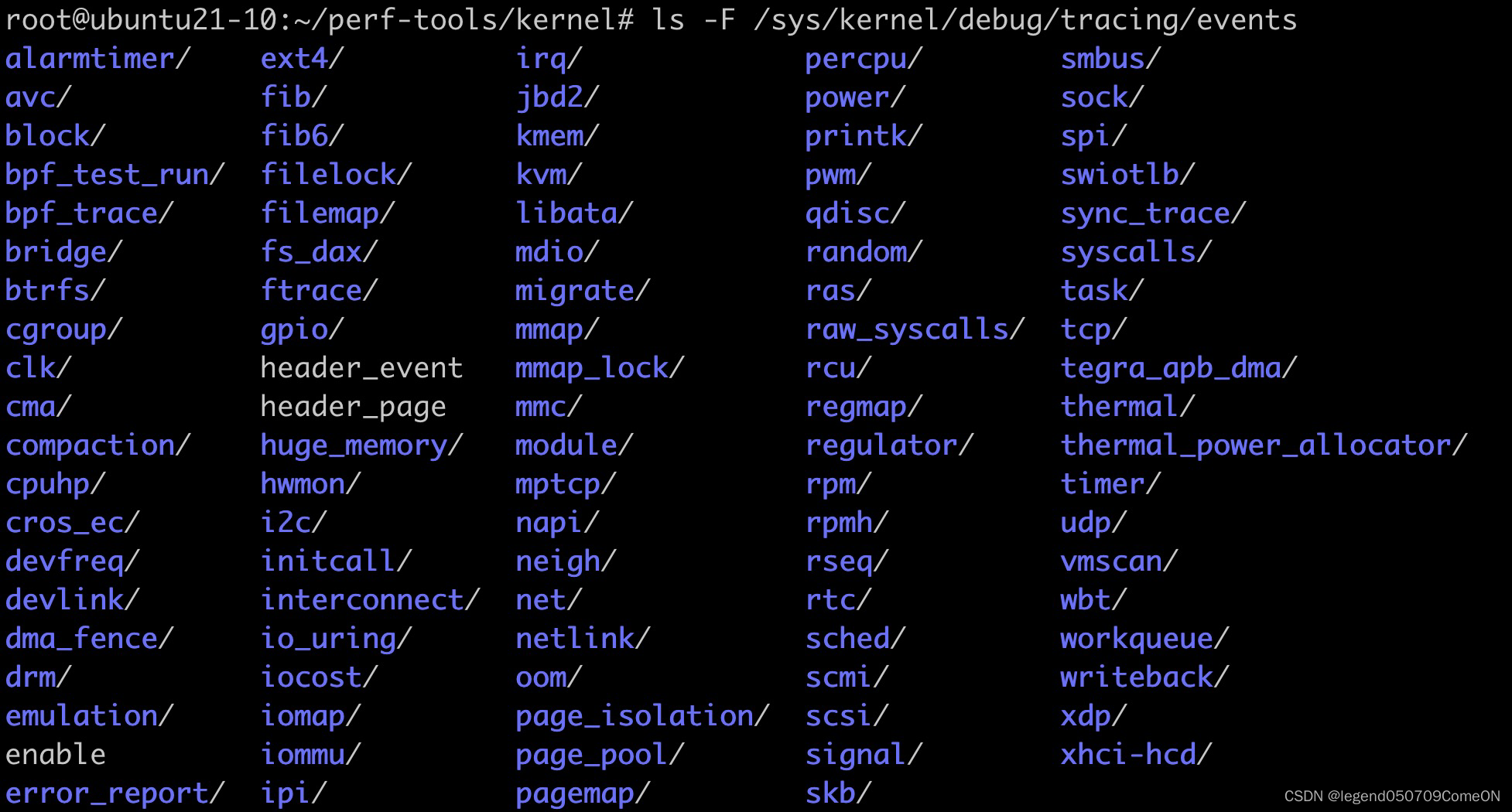
# available_events 文件中包括全部可用于跟踪的静态跟踪点
$ sudo grep openat available_events
syscalls:sys_exit_openat2
syscalls:sys_enter_openat2
syscalls:sys_exit_openat
syscalls:sys_enter_openat
# 我们可以在 events/syscalls/sys_enter_openat 中查看该跟踪点相关的选项
$ sudo ls -hl events/syscalls/sys_enter_openat
total 0
-rw-r----- 1 root root 0 Jan 1 1970 enable # 是否启用跟踪 1 启用
-rw-r----- 1 root root 0 Jan 1 1970 filter # 跟踪过滤
-r--r----- 1 root root 0 Jan 1 1970 format # 跟踪点格式
-r--r----- 1 root root 0 Jan 1 1970 hist
-r--r----- 1 root root 0 Jan 1 1970 id
--w------- 1 root root 0 Jan 1 1970 inject
-rw-r----- 1 root root 0 Jan 1 1970 trigger
$ sudo cat events/syscalls/sys_enter_openat/format
name: sys_enter_openat
ID: 555
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:int dfd; offset:16; size:8; signed:0;
field:const char * filename; offset:24; size:8; signed:0;
field:int flags; offset:32; size:8; signed:0;
field:umode_t mode; offset:40; size:8; signed:0;
print fmt: "dfd: 0x%08lx, filename: 0x%08lx, flags: 0x%08lx, mode: 0x%08lx", ((unsigned long)(REC->dfd)), ((unsigned long)(REC->filename)), ((unsigned long)(REC->flags)), ((unsigned long)(REC->mode))
这里直接使用 tracepoint 跟踪 sys_openat 系统调用,设置如下:
$ sudo echo 1 > events/syscalls/sys_enter_openat/enable
$ sudo echo 1 > tracing_on
$ sudo cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 19/19 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
cat-16961 [003] .... 47683.934082: sys_openat(dfd: ffffffffffffff9c, filename: ffff9abf20f0, flags: 80000, mode: 0)
cat-16961 [003] .... 47683.934326: sys_openat(dfd: ffffffffffffff9c, filename: ffff9ac09f20, flags: 80000, mode: 0)
cat-16961 [003] .... 47683.935468: sys_openat(dfd: ffffffffffffff9c, filename: ffff9ab75150, flags: 80000, mode: 0)
# 关闭
$ sudo echo 0 > events/syscalls/sys_enter_openat/enable
- Filter 跟踪记录条件过滤
关于 sys_enter_openat/filter 文件为跟踪记录的过滤条件设置,格式如下:
field operator value
其中:
field 为 sys_enter_openat/format 中的字段。
operator 为比较符
整数支持:==,!=,</、,<=,>= 和 & ,
字符串支持 ==,!=,~ 等,其中 ~ 支持 shell 脚本中通配符 *,?,[] 等操作。
不同的条件也支持 && 和 || 进行组合。
如需要通过 format 格式中的 mode 字段过滤:
format 中的mode字段:
field:umode_t mode; offset:40; size:8; signed:0;
进行如下设置即可:
sudo echo 'mode != 0' > events/syscalls/sys_enter_openat/filter
需要清除 filter,直接设置为 0 即可:
sudo echo 0 > events/syscalls/sys_enter_openat/filter
kprobe跟踪

kprobe 为内核提供的动态跟踪机制。与前面介绍的function tracer类似,但是 kprobe 机制允许我们跟踪函数任意位置,还可用于获取函数参数与结果返回值。
使用 kprobe 机制跟踪函数须是 available_filter_functions 列表中的子集。
kprobe 设置文件和相关文件如下所示,其中部分文件为设置 kprobe 跟踪函数后,Ftrace 自动创建:
- kprobe_events
设置 kprobe 跟踪的事件属性;
完整的设置格式如下,其中 GRP 用户可以直接定义,如果不设定默认为 kprobes:
p[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS] # 设置 probe 探测点
r[:[GRP/]EVENT] [MOD:]SYM[+0] [FETCHARGS] # 函数地址的返回跟踪
-:[GRP/]EVENT # 删除跟踪
p[:[GRP/][EVENT]] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS] : Set a probe
r[MAXACTIVE][:[GRP/][EVENT]] [MOD:]SYM[+0] [FETCHARGS] : Set a return probe
p[:[GRP/][EVENT]] [MOD:]SYM[+0]%return [FETCHARGS] : Set a return probe
-:[GRP/][EVENT] : Clear a probe
p: parameter;即参数:
r: retrun; 即返回值;
GRP : Group name. If omitted, use "kprobes" for it.
EVENT : Event name. If omitted, the event name is generated
based on SYM+offs or MEMADDR.
MOD : Module name which has given SYM.
SYM[+offs] : Symbol+offset where the probe is inserted.
SYM%return : Return address of the symbol
MEMADDR : Address where the probe is inserted.
MAXACTIVE : Maximum number of instances of the specified function that
can be probed simultaneously, or 0 for the default value
as defined in Documentation/trace/kprobes.rst section 1.3.1.
FETCHARGS : Arguments. Each probe can have up to 128 args.
%REG : Fetch register REG
@ADDR : Fetch memory at ADDR (ADDR should be in kernel)
@SYM[+|-offs] : Fetch memory at SYM +|- offs (SYM should be a data symbol)
$stackN : Fetch Nth entry of stack (N >= 0)
$stack : Fetch stack address.
$argN : Fetch the Nth function argument. (N >= 1) (\*1)
$retval : Fetch return value.(\*2)
$comm : Fetch current task comm.
+|-[u]OFFS(FETCHARG) : Fetch memory at FETCHARG +|- OFFS address.(\*3)(\*4)
\IMM : Store an immediate value to the argument.
NAME=FETCHARG : Set NAME as the argument name of FETCHARG.
FETCHARG:TYPE : Set TYPE as the type of FETCHARG. Currently, basic types
(u8/u16/u32/u64/s8/s16/s32/s64), hexadecimal types
(x8/x16/x32/x64), "string", "ustring" and bitfield
are supported.
(\*1) only for the probe on function entry (offs == 0).
(\*2) only for return probe.
(\*3) this is useful for fetching a field of data structures.
(\*4) "u" means user-space dereference. See :ref:`user_mem_access`.
-
kprobes/<GRP>/<EVENT>/enabled
设置后动态生成,用于控制是否启用该内核函数的跟踪; -
kprobes/<GRP>/<EVENT>/filter
设置后动态生成,kprobe 函数跟踪过滤器,与上述的跟踪点 fliter 类似; -
kprobes/<GRP>/<EVENT>/format
设置后动态生成,kprobe 事件显示格式; -
kprobe_profile
kprobe 事件统计性能数据;
Kprobe 跟踪过程可以指定函数参数的显示格式,这里我们先给出 sys_openat 函数原型:
SYSCALL_DEFINE4(openat, int, dfd, const char __user *, filename, int, flags,
umode_t, mode);
跟踪函数入口参数
这里仍然以 __arm64_sys_openat 函数为例,演示使用 kpboe 机制进行跟踪:
# p[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS]
# GRP=my_grp EVENT=arm64_sys_openat
# SYM=__arm64_sys_openat
# FETCHARGS = dfd=$arg1 flags=$arg3 mode=$arg4
$ sudo echo 'p:my_grp/arm64_sys_openat __arm64_sys_openat dfd=$arg1 flags=$arg3 mode=$arg4' >> kprobe_events
$ sudo cat events/my_grp/arm64_sys_openat/format
name: __arm64_sys_openat
ID: 1475
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:unsigned long __probe_ip; offset:8; size:8; signed:0;
print fmt: "(%lx)", REC->__probe_ip
events/my_grp/arm64_sys_openat/format
$ sudo echo 1 > events/my_grp/arm64_sys_openat/enable
# $ sudo echo 1 > options/stacktrace # 启用栈
$ cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 38/38 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
cat-17025 [002] d... 52539.651096: arm64_sys_openat: (__arm64_sys_openat+0x0/0xb4) dfd=0xffff8000141cbeb0 flags=0x1bf mode=0xffff800011141778
# 关闭,注意需要先 echo 0 > enable 停止跟踪
# 然后再使用 "-:my_grp/arm64_sys_openat" 停止,否则会正在使用或者忙的错误
$ sudo echo 0 > events/my_grp/arm64_sys_openat/enable
$ sudo echo '-:my_grp/arm64_sys_openat' >> kprobe_events
跟踪函数返回值
kprobe 可用于跟踪函数返回值,格式如下:
r[:[GRP/]EVENT] [MOD:]SYM[+offs]|MEMADDR [FETCHARGS]
例如:
sudo echo 'r:my_grp/arm64_sys_openat __arm64_sys_openat ret=$retval' >> kprobe_events
变量 $retval 参数表示函数返回值,其他的使用格式与 kprobe 类似。
uprobe 跟踪

uprobe 为用户空间的动态跟踪机制,格式和使用方式与 kprobe 的方式类似,但是由于是用户态程序跟踪需要指定跟踪的二进制文件和偏移量来确定函数符号。
p[:[GRP/]EVENT]] PATH:OFFSET [FETCHARGS] # 跟踪函数入口
r[:[GRP/]EVENT]] PATH:OFFSET [FETCHARGS] # 跟踪函数返回值
-:[GRP/]EVENT] # 删除跟踪点
p[:[GRP/][EVENT]] PATH:OFFSET [FETCHARGS] : Set a uprobe
r[:[GRP/][EVENT]] PATH:OFFSET [FETCHARGS] : Set a return uprobe (uretprobe)
p[:[GRP/][EVENT]] PATH:OFFSET%return [FETCHARGS] : Set a return uprobe (uretprobe)
-:[GRP/][EVENT] : Clear uprobe or uretprobe event
GRP : Group name. If omitted, "uprobes" is the default value.
EVENT : Event name. If omitted, the event name is generated based
on PATH+OFFSET.
PATH : Path to an executable or a library.
OFFSET : Offset where the probe is inserted.
OFFSET%return : Offset where the return probe is inserted.
FETCHARGS : Arguments. Each probe can have up to 128 args.
%REG : Fetch register REG
@ADDR : Fetch memory at ADDR (ADDR should be in userspace)
@+OFFSET : Fetch memory at OFFSET (OFFSET from same file as PATH)
$stackN : Fetch Nth entry of stack (N >= 0)
$stack : Fetch stack address.
$retval : Fetch return value.(\*1)
$comm : Fetch current task comm.
+|-[u]OFFS(FETCHARG) : Fetch memory at FETCHARG +|- OFFS address.(\*2)(\*3)
\IMM : Store an immediate value to the argument.
NAME=FETCHARG : Set NAME as the argument name of FETCHARG.
FETCHARG:TYPE : Set TYPE as the type of FETCHARG. Currently, basic types
(u8/u16/u32/u64/s8/s16/s32/s64), hexadecimal types
(x8/x16/x32/x64), "string" and bitfield are supported.
(\*1) only for return probe.
(\*2) this is useful for fetching a field of data structures.
(\*3) Unlike kprobe event, "u" prefix will just be ignored, becuse uprobe
events can access only user-space memory.
uprobe 跟踪是跟踪用户态的函数,因此需要指定二进制文件+符号偏移量才能进行跟踪。不同系统中的二进制版本或者编译方式不同,会导致函数符号表的位置不同,因此需要跟踪前进行确认。
Probe zfree function in /bin/zsh ,范例如下:
# cd /sys/kernel/debug/tracing/
# cat /proc/`pgrep zsh`/maps | grep /bin/zsh | grep r-xp
00400000-0048a000 r-xp 00000000 08:03 130904 /bin/zsh
# objdump -T /bin/zsh | grep -w zfree
0000000000446420 g DF .text 0000000000000012 Base zfree
0x46420(注意不是0x446420, 而是偏移量=0x446420-0x400000) is the offset of zfree in object /bin/zsh that is loaded at 0x00400000. Hence the command to uprobe would be:
# echo 'p:zfree_entry /bin/zsh:0x46420 %ip %ax' > uprobe_events
And the same for the uretprobe would be:
# echo 'r:zfree_exit /bin/zsh:0x46420 %ip %ax' >> uprobe_events
# cat uprobe_events
p:uprobes/zfree_entry /bin/zsh:0x00046420 arg1=%ip arg2=%ax
r:uprobes/zfree_exit /bin/zsh:0x00046420 arg1=%ip arg2=%ax
# cat events/uprobes/zfree_entry/format
name: zfree_entry
ID: 922
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int common_padding; offset:8; size:4; signed:1;
field:unsigned long __probe_ip; offset:12; size:4; signed:0;
field:u32 arg1; offset:16; size:4; signed:0;
field:u32 arg2; offset:20; size:4; signed:0;
print fmt: "(%lx) arg1=%lx arg2=%lx", REC->__probe_ip, REC->arg1, REC->arg2
# echo 1 > events/uprobes/zfree_entry/enable
# echo 1 > events/uprobes/zfree_exit/enable
# cat trace
# tracer: nop
#
# TASK-PID CPU# TIMESTAMP FUNCTION
# | | | | |
zsh-24842 [006] 258544.995456: zfree_entry: (0x446420) arg1=446420 arg2=79
zsh-24842 [007] 258545.000270: zfree_exit: (0x446540 <- 0x446420) arg1=446540 arg2=0
zsh-24842 [002] 258545.043929: zfree_entry: (0x446420) arg1=446420 arg2=79
zsh-24842 [004] 258547.046129: zfree_exit: (0x446540 <- 0x446420) arg1=446540 arg2=0
User has to explicitly calculate the offset of the probe-point in the object
其他技巧
参考
https://www.ebpf.top/post/ftrace_tools/
https://zhuanlan.zhihu.com/p/479833554
https://zhuanlan.zhihu.com/p/479823151
https://adtxl.com/index.php/archives/432.html
https://adtxl.com/index.php/archives/433.html
https://www.kernel.org/doc/html/latest/trace/kprobetrace.html
https://www.kernel.org/doc/html/latest/trace/uprobetracer.html