Elasticsearch
什么是Elasticsearch?
Elasticsearch是一个分布式文档存储。Elasticsearch存储的是序列化为JSON文档的复杂数据结构,而不是以行列数据的形式存储的信息。当集群中有多个Elasticsearch节点时,存储的文档分布在整个集群中,可以立即从任何节点访问。
当存储文档时,它几乎是实时的——在1秒内就可以被索引和完全搜索。Elasticsearch使用一种名为倒排索引的数据结构,它支持非常快速的全文搜索。倒排索引列出任何文档中出现的每个唯一单词,并标识每个单词出现的所有文档。
可以将索引看作是文档的优化集合,每个文档都是一个字段的集合,这些字段是包含数据的键值对。默认情况下,Elasticsearch对每个字段中的所有数据进行索引,每个索引字段都有一个专用的、优化的数据结构。例如:文本字段存储在倒排索引中,数字和地理字段存储在BKD树中。使用每个字段的数据结构来组装和返回搜索结果的能力是Elasticsearch如此快速的原因。
Elasticsearch还具有无模式的能力,这意味着可以在不显示指定如何处理文档中可能出现的每个不同字段的情况下,对文档进行索引。当启用动态映射时,Elasticsearch会自动检测并添加新的字段到索引中。这种默认行为使得创建索引和浏览数据变得很容易——只要开始创建索引文档,Elasticsearch就会检测布尔值、浮点值和整数值、日期和字符串,并将其映射到适当的Elasticsearch数据类型。
下载安装 Elasticsearch
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-17-7
官网地址:https://www.elastic.co/cn/elasticsearch/
以Windows为例:
下载后,解压缩,双击bin目录下的elasticsearch.bat,打开即可
启动后,可能会发现一个警告,它告诉我们,需要配置一个JAVA_HOME或者使用ES_JAVA_HOME且建议我们最好使用Java 11,如果版本过低,可能有的功能不支持。(为什么需要配置Java环境变量?因为ELasticsearch是使用Java开发的。)
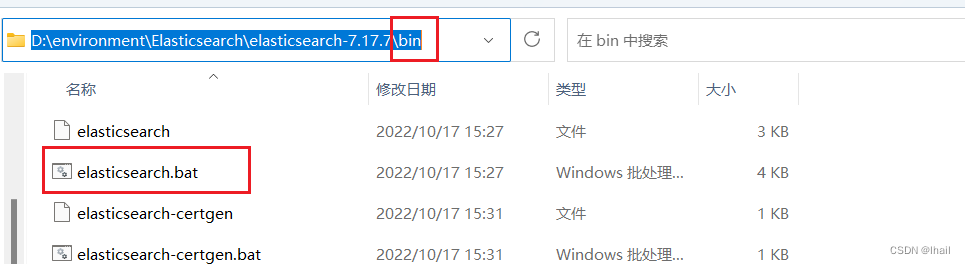

- 如何解决JDK版本支持问题?
我们自己开发可能使用的是JDK8或者其它版本,要想解决JDK版本问题,但又不想更改自己已配置的Java环境。我们就可以使用es自带的jdk,在环境变量中添加以下变量:(Elasticsearch解压包下的 jdk 目录)
关闭之前启动的,重新启动elasticsearch.bat即可,就没有警告了,如下图所示:
浏览器访问:http://localhost:9200
至此Elasticsearch下载安装完毕!



下载安装可视化工具
下载地址:https://www.elastic.co/cn/downloads/past-releases/kibana-7-17-7
下载解压即可
双击kibana.bat即可打开
浏览器访问:http://localhost:5601

ES集成整合IK分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
- 可选方式1:下载与之对应的版本:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.17.7
- 在 es 的目录下的 plugins 目录创建一个ik目录
cd your-es-root/plugins/ && mkdir ik
解压插件到当前目录中your-es-root/plugins/ik
- 在 es 的目录下的 plugins 目录创建一个ik目录
- 可选方式2:使用插件的方式安装:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip
- 然后重启es即可

示例:
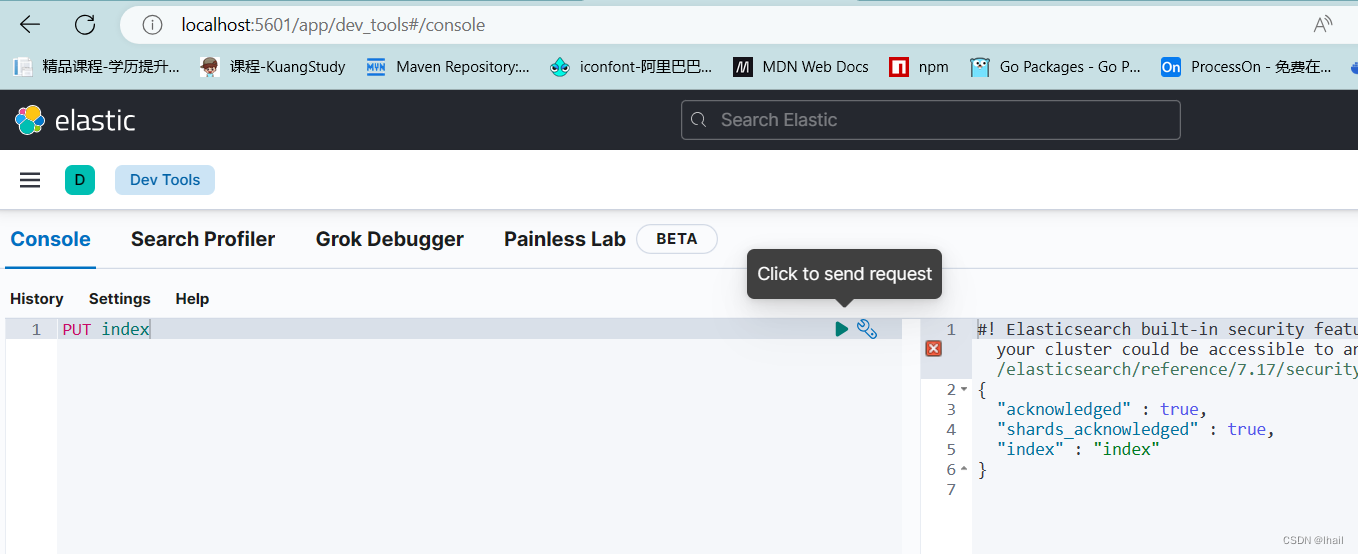
创建索引
PUT index
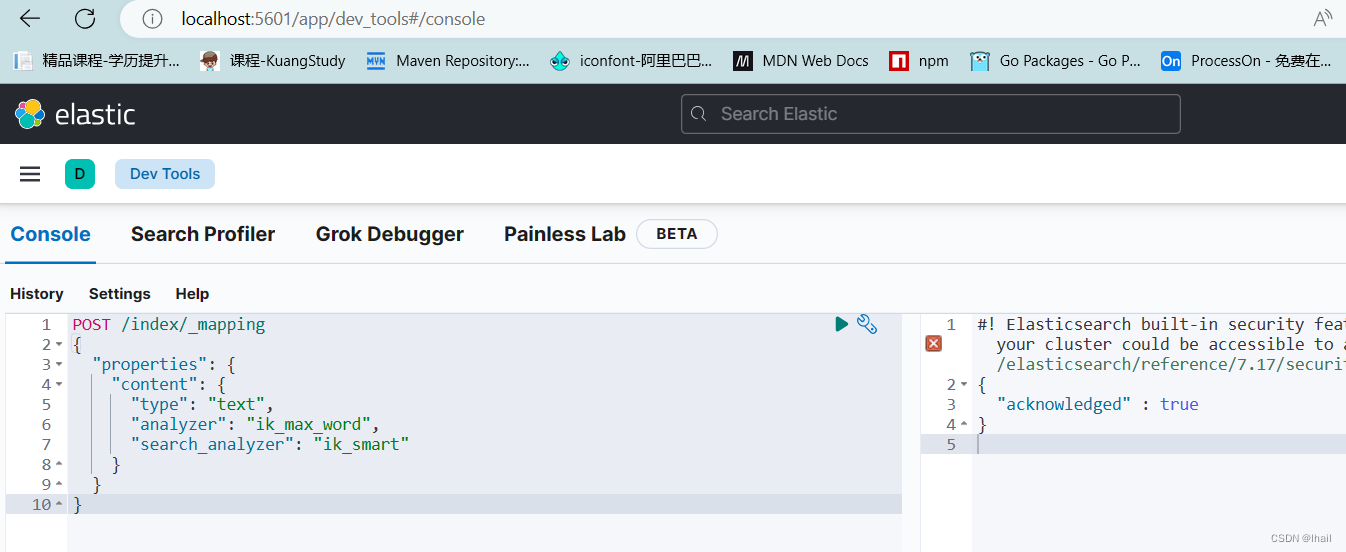
创建映射
POST /index/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
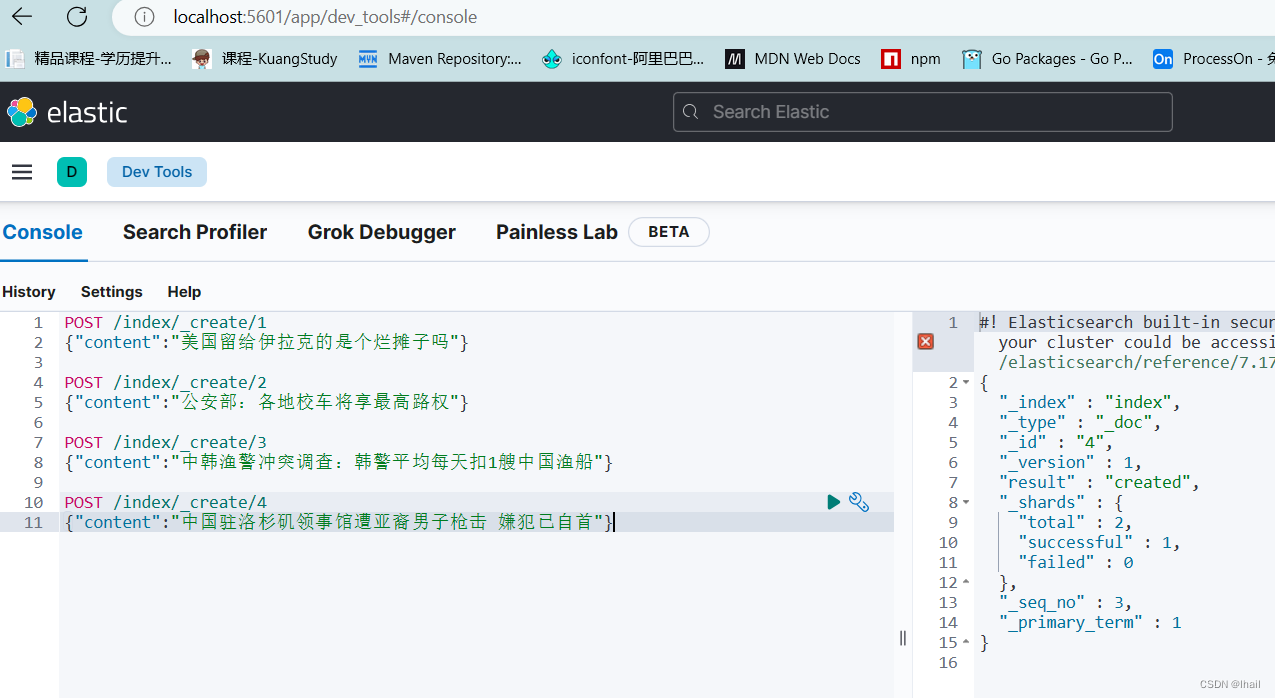
索引一些文档
POST /index/_create/1
{"content":"美国留给伊拉克的是个烂摊子吗"}
POST /index/_create/2
{"content":"公安部:各地校车将享最高路权"}
POST /index/_create/3
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
POST /index/_create/4
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
带突出显示的查询
POST /index/_search
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
查询结果
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.642793,
"hits" : [
{
"_index" : "index",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.642793,
"_source" : {
"content" : "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
},
"highlight" : {
"content" : [
"中韩渔警冲突调查:韩警平均每天扣1艘<tag1>中国</tag1>渔船"
]
}
},
{
"_index" : "index",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.642793,
"_source" : {
"content" : "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
},
"highlight" : {
"content" : [
"<tag1>中国</tag1>驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
]
}
}
]
}
}

字典配置
配置文件在 [你的Elasticsearch目录]/plugins/ik/config中的IKAnalyzer.cfg.xml
IKAnalyzer.cfg.xml的具体内容如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
当ik分词器提供的分词不能满足我们的实际使用时,我们可以在上面所说的字典配置文件(IKAnalyzer.cfg.xml)中扩展自己的字典
具体方式如下所示:
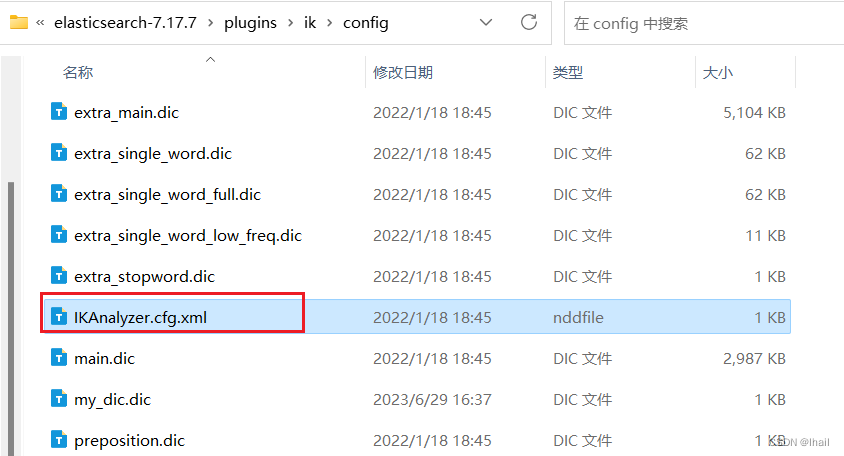
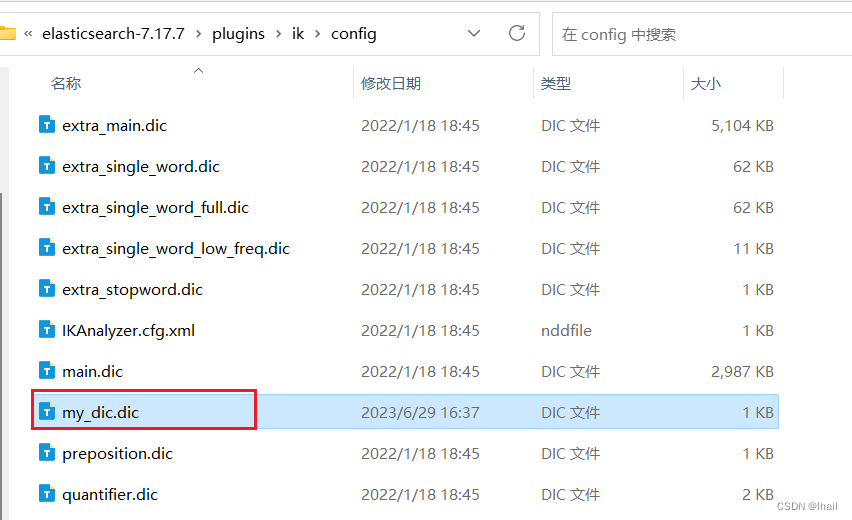
- 创建一个自己的字典文件,如下图所示,我创建了一个新的
my_dic.dic文件用于记录自己扩展的词
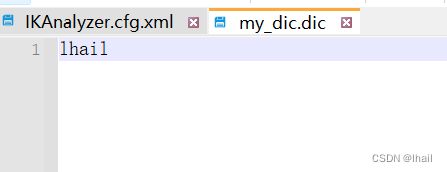
我在my_dic.dic中写入了一个词
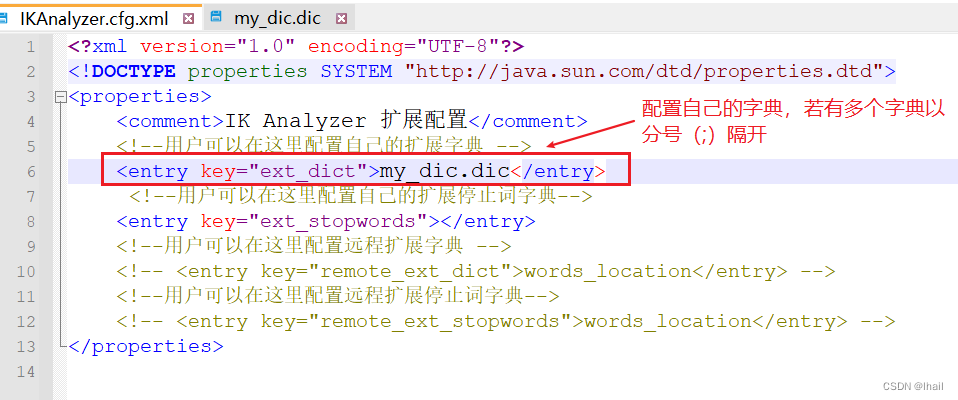
- 在
IKAnalyzer.cfg.xml中配置自己的字典my_dic.dic
- 重启es,即可生效
通过以下所示,可以看到自定义的字典生效了:
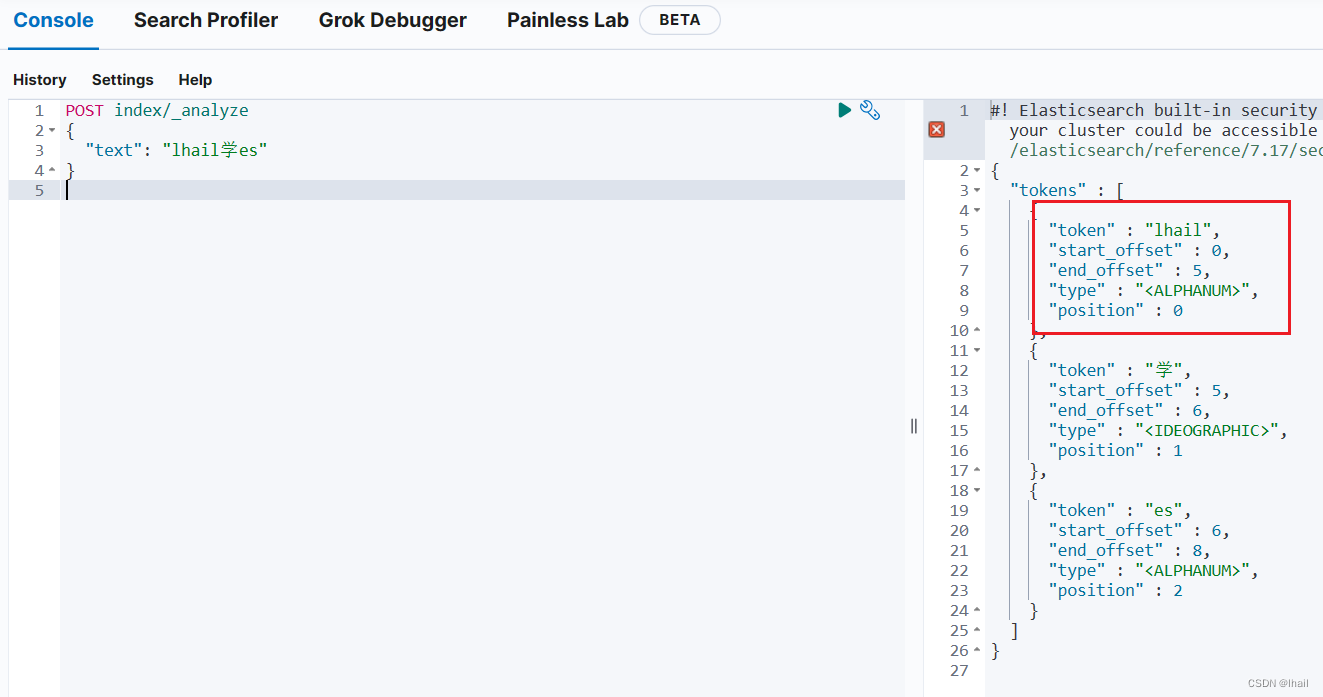
热更新 ik 分词
目前该插件支持热更新 IK 分词,通过上文在 IK 配置文件中提到的如下配置
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">location</entry>
其中location是指一个 url,比如http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
1、该 http 请求需要返回两个头部(header),一个是Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
2、该 http 请求返回的内容格式是一行一个分词,换行符用\n即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在 nginx 或其他简易 http server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。
Go集成ES
下载 es 组件
go get github.com/olivere/elastic/v7
Go操作es
package es
import (
"errors"
"github.com/olivere/elastic/v7"
"log"
"os"
"time"
)
type EsService struct{}
// CreateClient 创建一个客户端
func (es *EsService) CreateClient() (client *elastic.Client, err error) {
// 1.创建客户端
client, err = elastic.NewClient(
elastic.SetURL("http://127.0.0.1:9200"),
elastic.SetGzip(true),
elastic.SetHealthcheck(true),
elastic.SetHealthcheckTimeout(10*time.Second),
elastic.SetErrorLog(log.New(os.Stderr, "ELASTIC", log.LstdFlags)), // 设置日志输出的名字
elastic.SetInfoLog(log.New(os.Stdout, "", log.LstdFlags)), // 输出日志级别
)
if err != nil {
err = errors.New("连接es失败")
}
return
}
package main
import (
"fmt"
"go-elasticsearch/es"
)
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("连接成功: ", client)
}
}
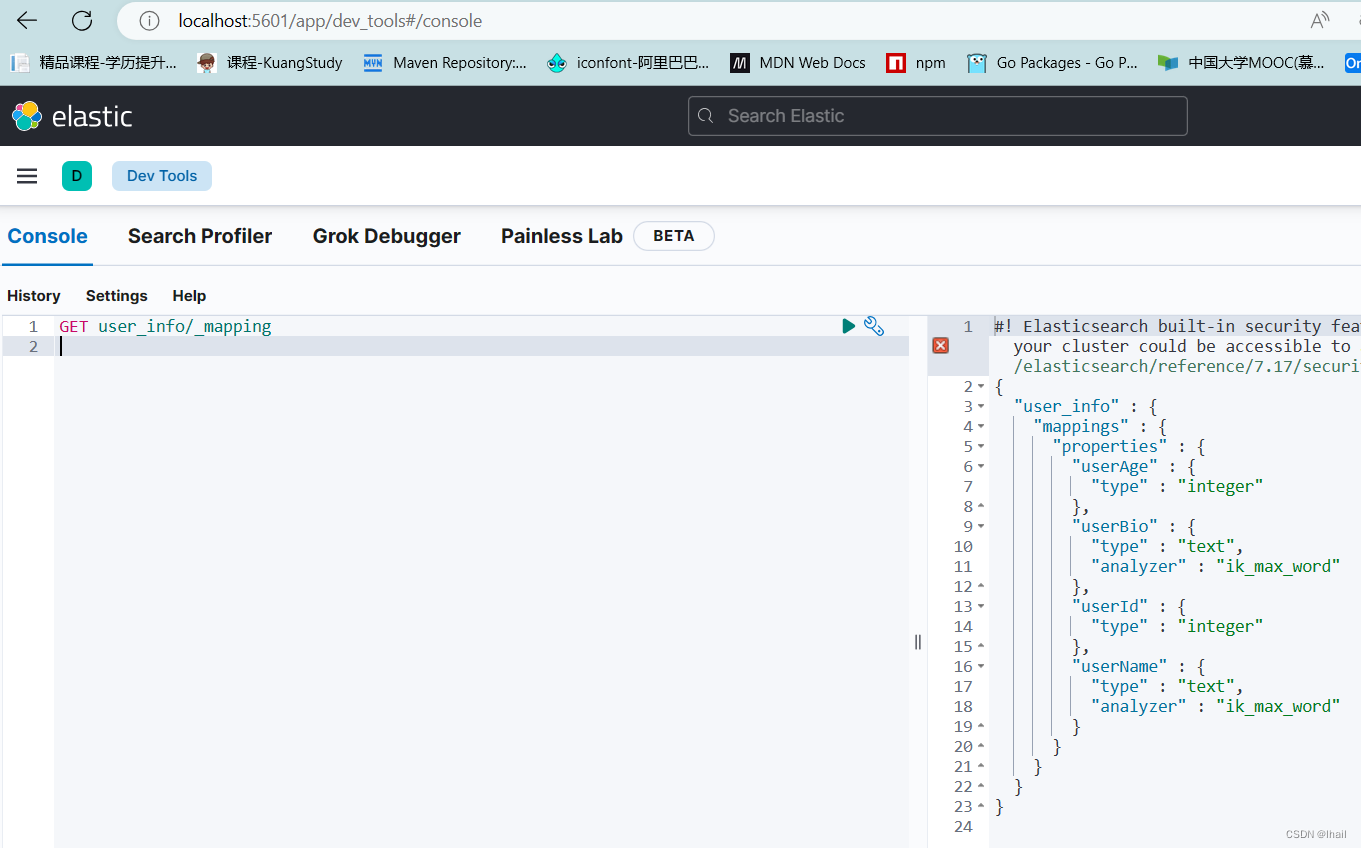
创建索引映射Mapping
package es
import (
"context"
"errors"
)
const IndexName = "user_info"
// mapping其实就是一种描述索引库字段类型的一种形式
// es 存储的数据的形态都是json。包括mapping字段描述也是json方式
// "analyzer":"ik_max_word" 如果这样写,es必须安装ik分词器,否则会报。此含义是未来如果搜索数据索引化的时候,它会把你的标题进行分词和你的文档进行关联
var mapping = `
{
"mappings":{
"properties":{
"userId":{
"type":"integer"
},
"userName":{
"type":"text",
"analyzer":"ik_max_word"
},
"userAge":{
"type":"integer"
},
"userBio":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
`
// CreateIndex 创建索引库
func (es *EsService) CreateIndex() (bool, error) {
// 创建client
client, _ := es.CreateClient()
// 创建一个上下文
ctx := context.Background()
exists, err := client.IndexExists(IndexName).Do(ctx)
if err != nil {
return false, err
}
if !exists {
do, err := client.CreateIndex(IndexName).Body(mapping).Do(ctx)
if err != nil {
return false, err
}
return do.Acknowledged, nil
}
return false, errors.New("索引库已存在")
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println(err)
} else {
fmt.Println("连接成功: ", client)
}
index, _ := service.CreateIndex()
fmt.Println("===>", index)
}
创建文档
package es
import (
"context"
"fmt"
)
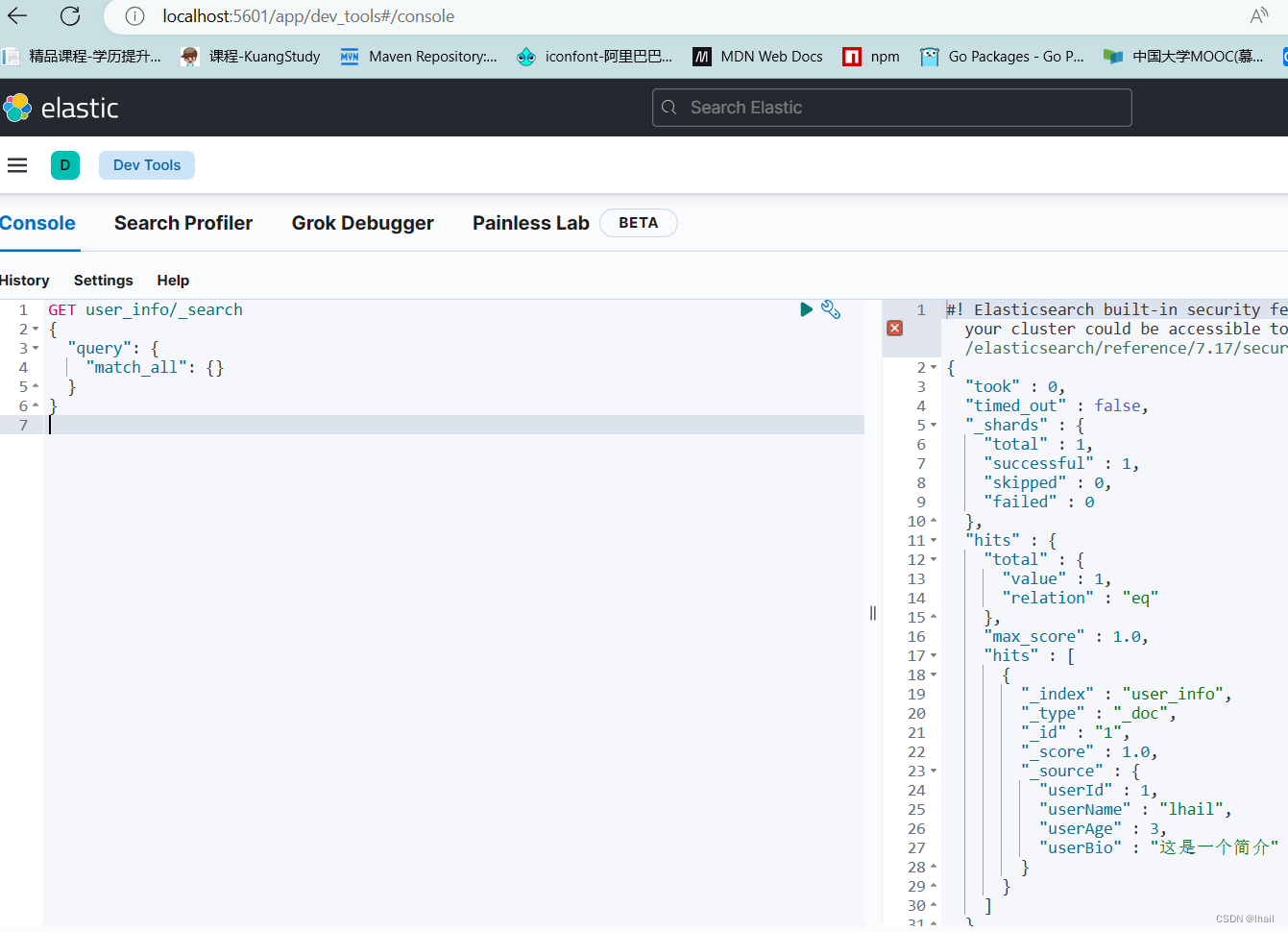
func (es *EsService) Save() (bool, error) {
// 创建一个对象信息
user := User{
UserId: 1,
UserName: "lhail",
UserAge: 3,
UserBio: "这是一个简介",
}
// 创建Client
client, _ := es.CreateClient()
// 创建一个上下文对象
ctx := context.Background()
put, err := client.Index().
Index(IndexName). // 设置索引名称
Id("1"). // 设置文档ID
BodyJson(user). // 指定前面声明的对象信息
Do(ctx) // 执行请求,需要传入一个上下文对象
if err != nil {
panic(err)
}
fmt.Printf("文档Id %s, 索引名 %s\n", put.Id, put.Index)
return true, nil
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
index, _ := service.CreateIndex()
fmt.Println("index==>", index)
save, _ := service.Save()
fmt.Println("save==>", save)
}
更新文档
- 根据ID更新文档
package es
import (
"context"
"fmt"
)
func (es *EsService) UpdateById(id string, age int) (bool, error) {
// 创建Client
client, _ := es.CreateClient()
// 创建一个上下文对象
ctx := context.Background()
put, err := client.Update().
Index(IndexName).
Id(id).
Doc(map[string]interface{}{"userAge": age}).Do(ctx)
if err != nil {
panic(err)
}
fmt.Printf("文档Id %s, 索引名 %s\n", put.Id, put.Index)
return true, nil
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 创建索引库
index, _ := service.CreateIndex()
fmt.Println("index==>", index)
// 给索引库添加文档数据
//save, _ := service.Save()
//fmt.Println("save==>", save)
// 根据Id更新索引库文档数据
updateById, _ := service.UpdateById("1", 2)
fmt.Println("updateById==>", updateById)
}

- 根据查询条件更新文档
// UpdateQuery 根据查询条件更新文档
func (es *EsService) UpdateQuery(uid int, age int) (bool, error) {
// 创建Client
client, _ := es.CreateClient()
// 创建一个上下文对象
ctx := context.Background()
do, err := client.UpdateByQuery(IndexName).
Query(elastic.NewTermQuery("userId", uid)).
Script(elastic.NewScript("ctx._source['userAge'] = " + strconv.Itoa(age))).
ProceedOnVersionConflict().Do(ctx)
if err != nil {
panic(err)
}
fmt.Printf("文档一共更新了 %d\n", do.Total)
return true, nil
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 创建索引库
//index, _ := service.CreateIndex()
//fmt.Println("index==>", index)
// 根据查询条件更新文档
updateQuery, _ := service.UpdateQuery(1, 6)
fmt.Println(updateQuery)
}
删除文档
- 根据ID删除文档
func (es *EsService) DeleteById(id string) (bool, error) {
// 创建Client
client, _ := es.CreateClient()
// 创建一个上下文对象
ctx := context.Background()
put, err := client.Delete().
Index(IndexName).
Id(id).
Do(ctx)
if err != nil {
panic(err)
}
fmt.Printf("文档Id %s, 索引名 %s\n", put.Id, put.Index)
return true, nil
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 根据Id删除文档
id, _ := service.DeleteById("1")
fmt.Println(id)
}
- 根据查询条件删除文档
func (es *EsService) DeleteQuery(uid int) (bool, error) {
// 创建Client
client, _ := es.CreateClient()
// 创建一个上下文对象
ctx := context.Background()
do, err := client.DeleteByQuery(IndexName).
Query(elastic.NewTermQuery("userId", uid)).
Do(ctx)
if err != nil {
panic(err)
}
fmt.Printf("文档一共删除了 %d\n", do.Total)
return true, nil
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 根据查询条件删除文档
deleteQuery, _ := service.DeleteQuery(1)
fmt.Println(deleteQuery)
}
查询文档
- 根据ID查询文档
func (es *EsService) Get(docId string) (user User) {
client, _ := es.CreateClient()
// 执行es请求需要提供一个上下文对象
ctx := context.Background()
// 根据ID查询文档
getResult, err := client.Get().
Index(IndexName).
Id(docId).
Do(ctx)
if err != nil {
panic(err)
}
if getResult.Found {
fmt.Printf("文档id=%s 版本号=%d 索引名=%s\n", getResult.Id, getResult.Version, getResult.Index)
}
// 提取文档内容,原始类型是json数据
data, _ := getResult.Source.MarshalJSON()
// 将json转为struct结果
json.Unmarshal(data, &user)
// 返回结果
return
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 根据文档Id查询文档
user := service.Get("1")
fmt.Println(user)
}
高级查询
精确匹配单个字段
func (es *EsService) SearchByTerm(uid string) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
result, err := client.Search(IndexName).
Query(elastic.NewTermQuery("userId", uid)).
Sort("userAge", false). // 设置排序字段 false表示升序
From(0). // 设置分页参数 - 起始偏移量,从第0行记录开始
Size(10). // 设置分页参数 - 每页大小
Pretty(true). // 查询结果返回可读性较好的JSON格式
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 根据词搜索文档
users := service.SearchByTerm("1")
fmt.Println(users)
}
通过terms实现SQL的in查询
func (es *EsService) SearchIn(uids ...interface{}) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
result, err := client.Search(IndexName).
Query(elastic.NewTermsQuery("userId", uids...)).
Sort("userAge", true). // 排序 第二个字段若为false表示逆序
From(0).
Size(10).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// terms实现SQL的in查询
users := service.SearchIn("1", "2", "3", "4")
fmt.Println(users)
}
匹配单个字段
func (es *EsService) SearchOne(name string) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
result, err := client.Search(IndexName).
Query(elastic.NewMatchQuery("userName", name)).
Sort("userAge", true). // 排序 第二个字段若为false表示逆序
From(0).
Size(10).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 匹配单个字段
users := service.SearchOne("lhail")
fmt.Println(users)
}
范围查询
func (es *EsService) SearchRangeQuery(start, end int) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
// Gte Lte: userAge >= start and userAge <= end
// Gt Lt: userAge > start and userAge < end
result, err := client.Search(IndexName).
Query(elastic.NewRangeQuery("userAge").Gte(start).Lte(end)).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 范围查询
users := service.SearchRangeQuery(2, 6)
fmt.Println(users)
}
根据语义查询
func (es *EsService) SearchByMatch(str string) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
result, err := client.Search(IndexName).
Query(elastic.NewMatchQuery("userBio", str)).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 语义查询
users := service.SearchByMatch("我需要找个人简介")
fmt.Println(users)
}
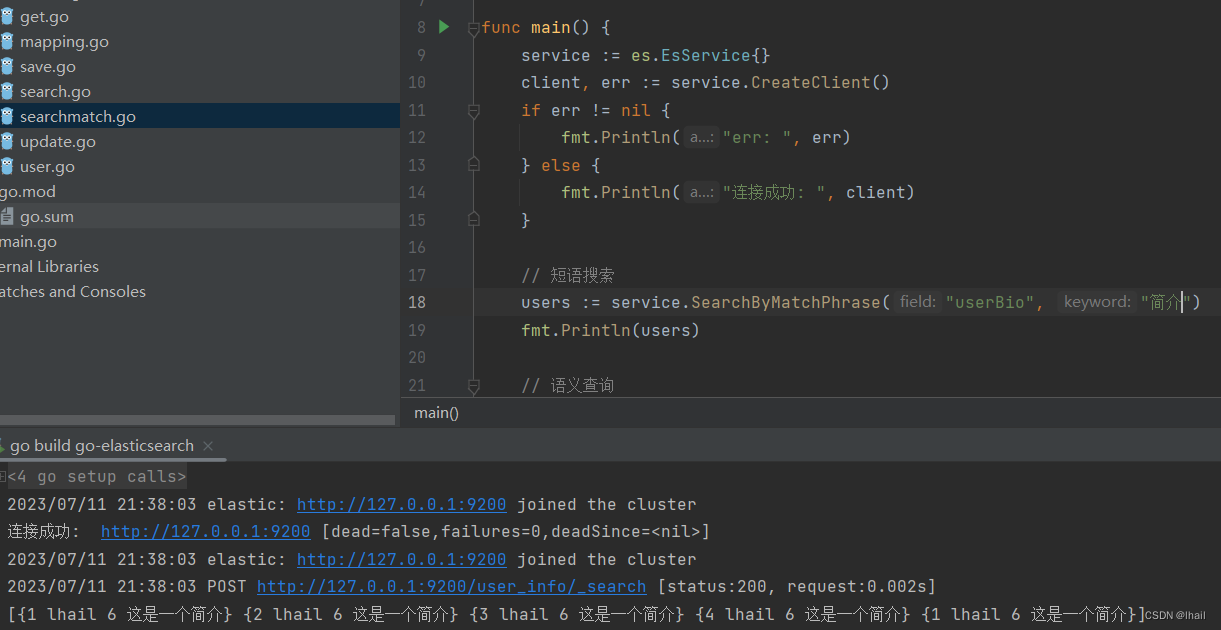
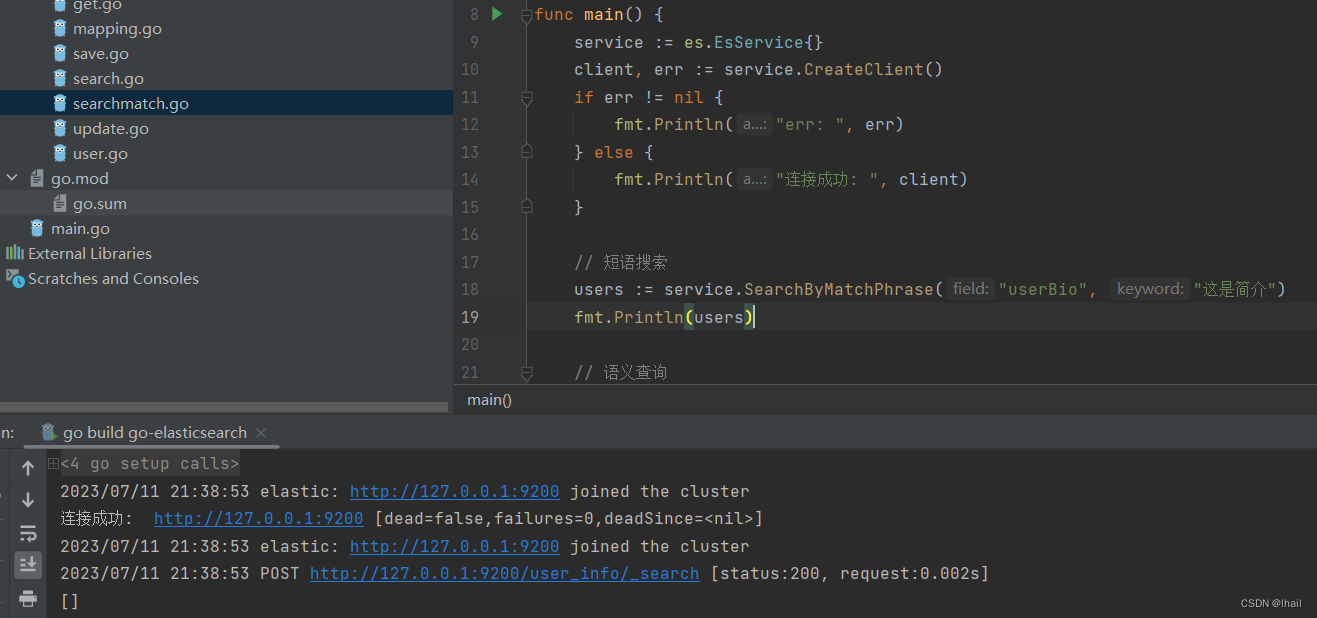
根据短语搜索
func (es *EsService) SearchByMatchPhrase(field, keyword string) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
result, err := client.Search(IndexName).
Query(elastic.NewMatchPhraseQuery(field, keyword)).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 短语搜索
users := service.SearchByMatchPhrase("userBio", "这是简介")
fmt.Println(users)
}
前缀搜索
func (es *EsService) SearchByPrefixQuery(field, keyword string) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
result, err := client.Search(IndexName).
Query(elastic.NewPrefixQuery(field, keyword)).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
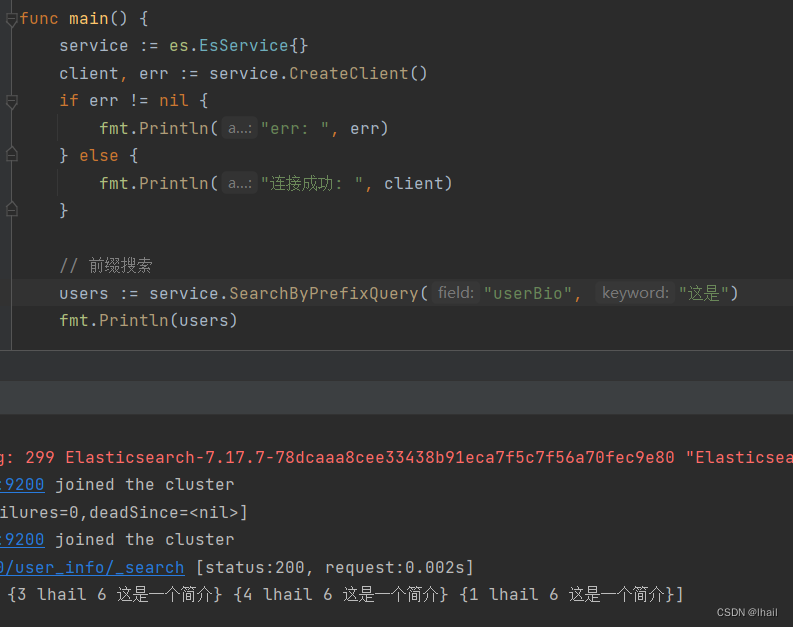
模糊查询(通配符)
- 查询包含通配符表达式字段的文档(等价于 MySQL 的 like 查询)
- 通配符 * :匹配任何字符序列(包括空字符)
- 占位符 ? :匹配任何单个字符
func (es *EsService) SearchByWildcardQuery(field, keyword string) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
result, err := client.Search(IndexName).
Query(elastic.NewWildcardQuery(field, keyword)).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 模糊查询
users1 := service.SearchByWildcardQuery("userName", "l?ail")
users2 := service.SearchByWildcardQuery("userName", "lh*")
fmt.Println(users1)
fmt.Println(users2)
}
模糊查询(fuzzy)
fuzzy这是一种拼写错误时模糊搜索技术。如:输入 “lahil” 此时也须匹配到 “lhail”
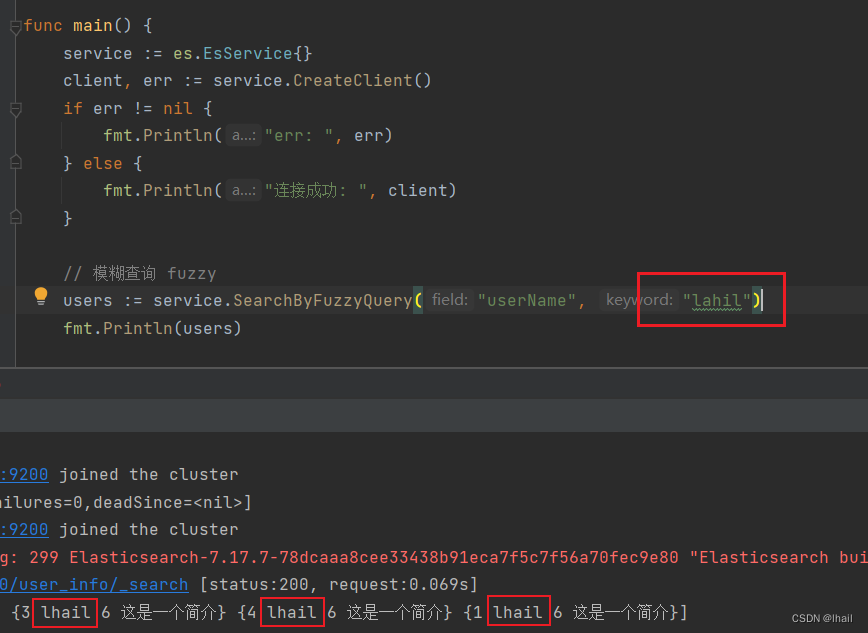
func (es *EsService) SearchByFuzzyQuery(field, keyword string) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
result, err := client.Search(IndexName).
Query(elastic.NewFuzzyQuery(field, keyword)).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
多字段搜索
func (es *EsService) SearchByMultiMatchQuery(keyword string, fields ...string) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
result, err := client.Search(IndexName).
Query(elastic.NewMultiMatchQuery(keyword, fields...)).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
func main() {
service := es.EsService{}
client, err := service.CreateClient()
if err != nil {
fmt.Println("err: ", err)
} else {
fmt.Println("连接成功: ", client)
}
// 多字段搜索
users := service.SearchByMultiMatchQuery("gin go", "userName", "userBio")
fmt.Println(users)
}

bool组合查询
bool组合查询,类似SQL语句的 and 和 or 将查询条件组合起来
- must 条件
- 类似SQL的 and,代表必须匹配的条件
- must_not 条件
- 与 must 作用相反,用法相似
- should 条件
- 类似SQL的 or,只需匹配其中一个条件即可
func (es *EsService) SearchByBoolQuery() (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
idTermQuery := elastic.NewTermQuery("userId", 1)
ageTermQuery := elastic.NewTermQuery("userAge", 6)
bioMatchQuery := elastic.NewMatchQuery("userBio", "go")
boolQuery := elastic.NewBoolQuery().Must(idTermQuery, ageTermQuery).Should(bioMatchQuery)
result, err := client.Search(IndexName).
Query(boolQuery).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
// 通过Each方法,将es结果的json结构转换成struct对象
for _, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
users = append(users, t)
}
}
}
return
}
搜索词条高亮处理
func (es *EsService) SearchByMatchHigh(keyword string, fields ...string) (users []User) {
client, _ := es.CreateClient()
ctx := context.Background()
hl := elastic.NewHighlight()
var fieldArr []*elastic.HighlighterField
for _, k := range fields {
fieldArr = append(fieldArr, elastic.NewHighlighterField(k))
}
hl = hl.Fields(fieldArr...)
hl = hl.PreTags("<em>").PostTags("</em>")
matchQuery := elastic.NewMultiMatchQuery(keyword, fields...)
result, err := client.Search(IndexName).
Query(matchQuery).
Highlight(hl).
Do(ctx)
if err != nil {
panic(err)
}
if result.TotalHits() > 0 {
// 查询结果不为空,遍历结果
var u User
hits := result.Hits.Hits
// 通过Each方法,将es结果的json结构转换成struct对象
for index, item := range result.Each(reflect.TypeOf(u)) {
// 转换成User对象
if t, ok := item.(User); ok {
hlUserNameArr := hits[index].Highlight["userName"]
hlUserBioArr := hits[index].Highlight["userBio"]
// 如果命中到高亮的内容就直接使用高亮内容,否则使用原来内容
if len(hlUserNameArr) > 0 {
t.UserName = hlUserNameArr[0]
}
if len(hlUserBioArr) > 0 {
t.UserBio = hlUserBioArr[0]
}
users = append(users, t)
}
}
}
return
}
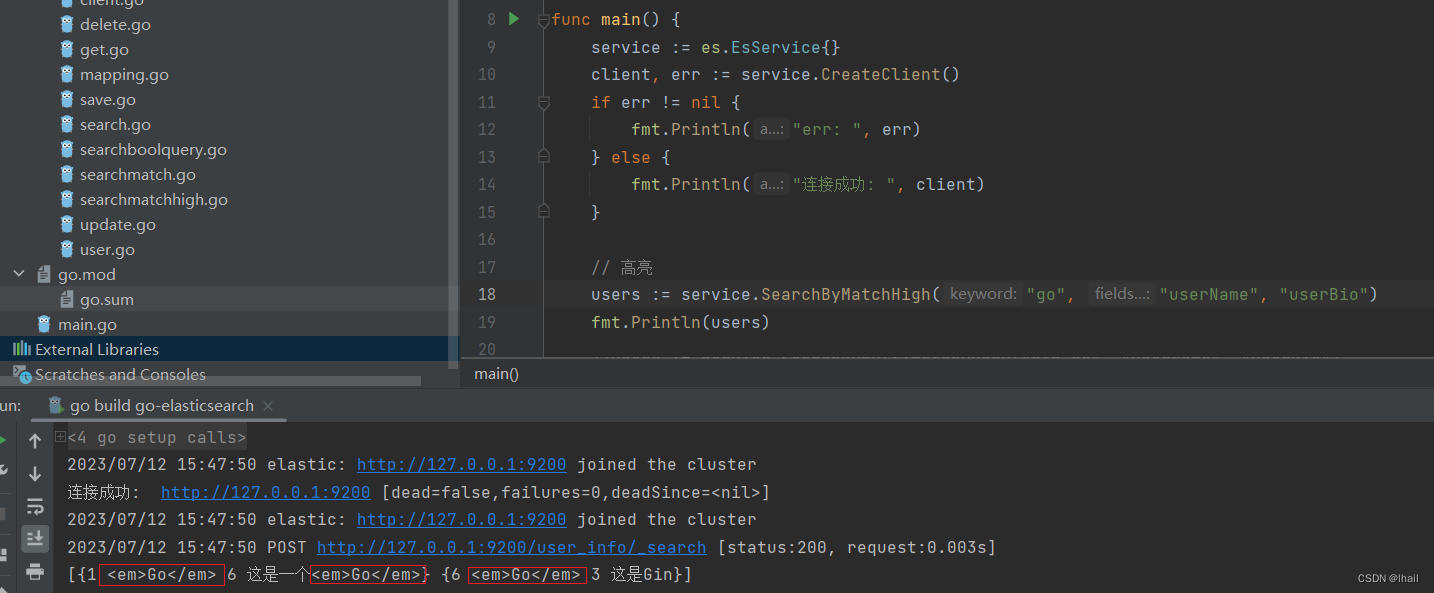
集群配置
此处以windows为例,Linux方法类似
集群包的准备
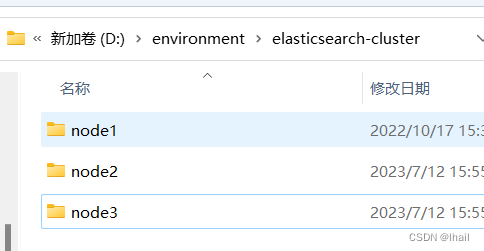
- 新建一个
elasticsearch-cluster文件夹 - 将
elasticsearch-7.17.7-windows-x86_64.zip文件解压三份,分别命名:- node1
- node2
- node3
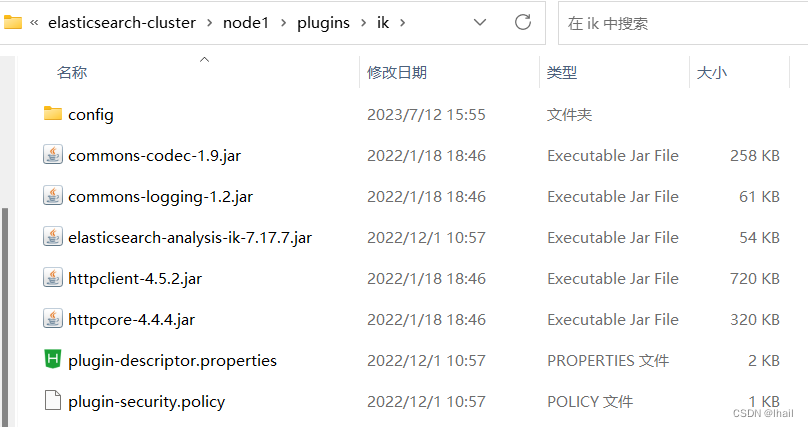
- 后面需要用到
ik分词器所以根据前面ES集成整合IK分词器将IK分词器插件分别安装到上述3个解压文件对应的目录中,如下所示:
启动第一个节点
对node1的config目录下的elasticsearch.yml进行修改
# 集群名称,节点间须保持一致
cluster.name: my-elasticsearch
# 当前节点名称 是否能成为master
node.name: node-2001
node.master: true
node.data: true
network.host: 127.0.0.1
http.port: 2001
# TCP通信端口
transport.tcp.port: 9301
# 跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
- 完成上述配置后,即可启动第一个节点
从启动日志中,可以看到集群名称
- 使用 get 请求,可以查看集群状态
http://localhost:2001/_cluster/health
响应结果如下

{
"cluster_name":"my-elasticsearch",
"status":"green",
"timed_out":false,
"number_of_nodes":1,
"number_of_data_nodes":1,
"active_primary_shards":3,
"active_shards":3,
"relocating_shards":0,
"initializing_shards":0,
"unassigned_shards":0,
"delayed_unassigned_shards":0,
"number_of_pending_tasks":0,
"number_of_in_flight_fetch":0,
"task_max_waiting_in_queue_millis":0,
"active_shards_percent_as_number":100.0
}
启动第二个节点
对node2的config目录下的elasticsearch.yml进行修改
增加了主节点的配置信息
并且修改对应端口,集群名称保持不变
# 集群名称,节点间须保持一致
cluster.name: my-elasticsearch
# 当前节点名称 是否能成为master
node.name: node-2002
node.master: true
node.data: true
network.host: 127.0.0.1
http.port: 2002
# TCP通信端口
transport.tcp.port: 9302
# 主节点的信息
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# 跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
- 启动第二个节点
- 使用 get 请求,可以查看集群状态
http://localhost:2001/_cluster/health
响应结果如下

启动第三个节点
对node3的config目录下的elasticsearch.yml进行修改
在discovery.seed_hosts中,修改为可以查找 9301 和 9302 即可以去查找 node1 node2 两个节点信息
# 集群名称,节点间须保持一致
cluster.name: my-elasticsearch
# 当前节点名称 是否能成为master
node.name: node-2003
node.master: true
node.data: true
network.host: 127.0.0.1
http.port: 2003
# TCP通信端口
transport.tcp.port: 9303
# 主节点的信息
discovery.seed_hosts: ["localhost:9301","localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# 跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
- 启动第三个节点
- 使用 get 请求,可以查看集群状态
http://localhost:2001/_cluster/health
响应结果如下,可以看到节点数为3了
注意每个节点都要安装:ik的插件,否则会造成失败

golang elasticsearch连接配置
// CreateClient 创建一个客户端
func (es *EsService) CreateClient() (client *elastic.Client, err error) {
// 1.创建客户端
client, err = elastic.NewClient(
// 单机
//elastic.SetURL("http://127.0.0.1:9200"),
// 集群 多个服务地址用逗号分隔
elastic.SetURL("http://127.0.0.1:2001", "http://127.0.0.1:2002", "http://127.0.0.1:2003"),
elastic.SetGzip(true),
elastic.SetHealthcheck(true),
elastic.SetHealthcheckTimeout(10*time.Second),
elastic.SetErrorLog(log.New(os.Stderr, "ELASTIC", log.LstdFlags)), // 设置日志输出的名字
elastic.SetInfoLog(log.New(os.Stdout, "", log.LstdFlags)), // 输出日志级别
)
if err != nil {
err = errors.New("连接es失败")
}
return
}