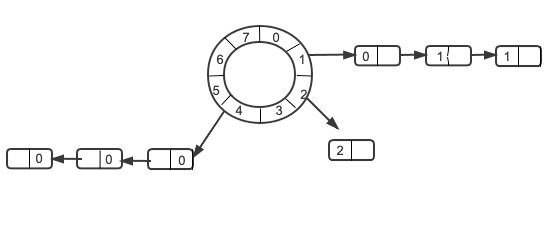
线程池核心线程设置为0时的任务执行流程
线程池的任务执行流程是怎么样的呢?
1、首先会判断当前工作线程数量是否大于核心线程数量(corePoolSize),如果小于核心线程数量,直接创建线程执行任务。如果大于核心线程数量,就将任务放入任务队列中进行缓存。
2、判断任务队列容量是否已满,如果不满,任务放入任务队列。
3、如果任务队列满了,判断当前工作线程数量是否大于最大线程数量(maximumPoolSize),如果小于最大线程数量,创建线程执行任务。
4、当工作线程已经大于最大线程了,此时,任务会触发拒绝策略,默认的拒绝策略是抛出异常。
当工作线程数量为0时,会执行下一步的创建线程执行任务。

100亿订单超时处理的阿里方案
100亿订单的超时处理难题
100亿订单的超时处理,是一个很有技术难度的问题。比如,用户下了一个订单之后,需要在指定时间内(例如30分钟)进行支付,在到期之前可以发送一个消息提醒用户进行支付。下面是一个订单的流程:
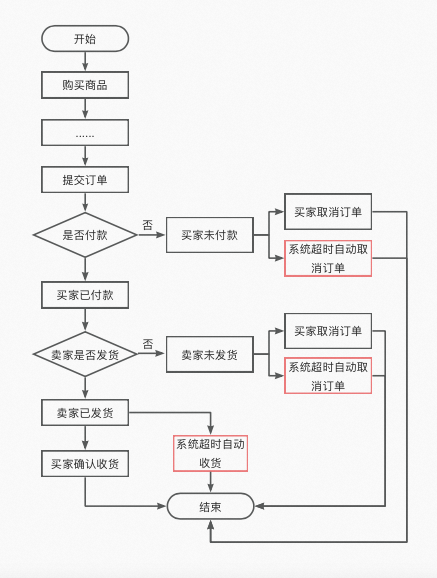
如上图所示,实际的生产场景中,一个订单流程中有许多环节要用到定时处理,比如:
-
买家超时未付款: 超过15分钟没有支付,订单自动取消。
-
商家超时未发货: 商家超过1个月没发货,订单自动取消。
-
买家超时未收货: 商家发货后,买家没有在14天内点击确认收货,则自动收货。
海量任务的定时处理方案
-
基于内存的延迟队列/优先级队列处理
-
基于内存的时间轮调度
-
基于分布式队列延迟消息的定时方案
-
基于分布式K-V组件(如Redis)过期时间的定时方案
一些消息中间件的Broker端内置了延迟消息支持的能力
方案1:基于内存的延时队列
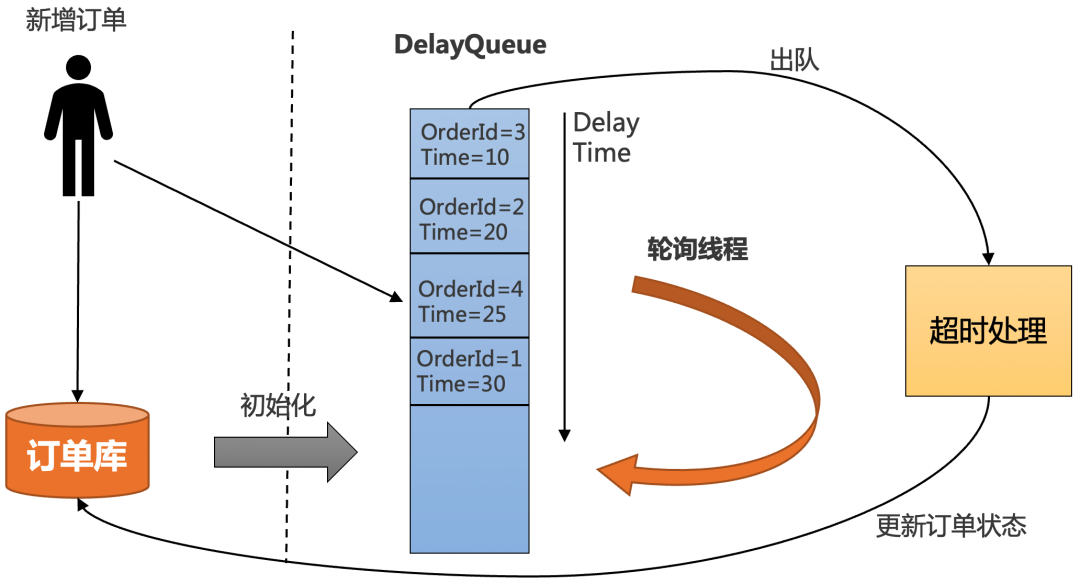
JDK中提供了一种延迟队列数据结构DelayQueue,其本质是封装了PriorityQueue,可以把元素进行排序。Java 的Timer、JUC的延迟调度,最终都是基于 PriorityQueue。基于内存的延时队列进行调度的逻辑,其实比较简单,具体如下:
-
把订单插入DelayQueue中,以超时时间作为排序条件,将订单按照超时时间从小到大排序。
-
起一个线程不停轮询队列的头部,如果订单的超时时间到了,就出队进行超时处理,并更新订单状态到数据库中。
-
为了防止机器重启导致内存中的DelayQueue数据丢失,每次机器启动的时候,需要从数据库中初始化未结束的订单,加入到DelayQueue中。
基于内存的延时队列调度的优点和缺点:
-
优点: 简单,不需要借助其他第三方组件,成本低。
-
缺点:
-
所有超时处理订单都要加入到DelayQueue中,占用内存大。
-
没法做到分布式处理,只能在集群中选一台leader专门处理,效率低。
-
不适合订单量比较大的场景。
-
方案2:RocketMQ的定时消息
RocketMQ支持任意秒级的定时消息,如下图所示
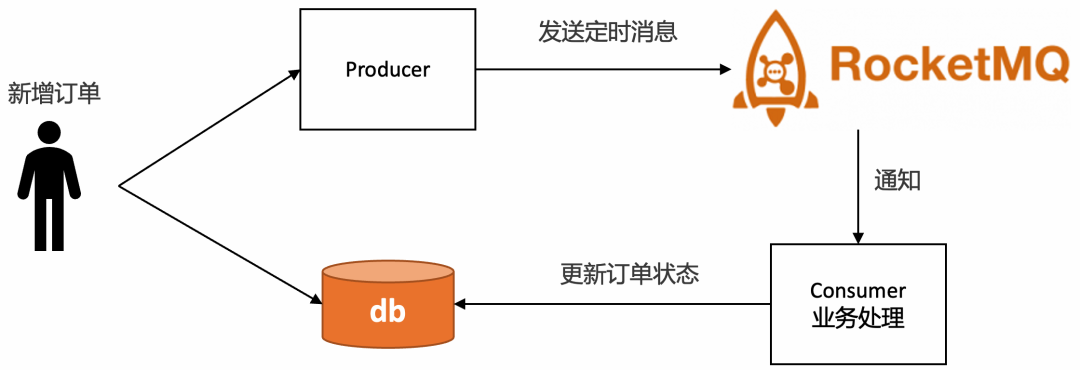
使用门槛低,只需要在发送消息的时候设置延时时间即可,以 java 代码为例:
MessageBuilder messageBuilder = null;
Long deliverTimeStamp = System.currentTimeMillis() + 10L * 60 * 1000; //延迟10分钟
Message message = messageBuilder.setTopic("topic")
//设置消息索引键,可根据关键字精确查找某条消息。
.setKeys("messageKey")
//设置消息Tag,用于消费端根据指定Tag过滤消息。
.setTag("messageTag")
//设置延时时间
.setDeliveryTimestamp(deliverTimeStamp)
//消息体
.setBody("messageBody".getBytes())
.build();
SendReceipt sendReceipt = producer.send(message);
System.out.println(sendReceipt.getMessageId());
RocketMQ的定时消息是如何实现的呢?
RocketMQ 定时消息的推送,主要分为 : 延迟消息、定时消息。
-
在 RocketMQ 4.x 版本,使用延迟消息来实现消息的多个级别延迟消息—粗粒度延迟。
-
在 RocketMQ 5.x 版本,使用定时消息来实现消息的更精准定时消息—细粒度延迟。
RocketMQ 4.x 版本只支持延迟消息,有一些局限性。而 RocketMQ 5.x 版本引入了定时消息,弥补了 延迟消息的不足。
RocketMQ 4.x 粗粒度 延迟消息
RocketMQ 的 延迟消息是指 Producer 发送消息后,Consumer 不会立即消费,而是需要等待固定的时间才能消费。在一些场景下, 延迟消息是很有用的,比如电商场景下关闭 30 分钟内未支付的订单。使用 延迟消息非常简单,只需要给消息的 delayTimeLevel 属性赋值就可以。
发送 分级定时消息,参考下面代码:
Message message = new Message("TestTopic", ("Hello scheduled message " + i).getBytes());
//第 3 个级别,10s
message.setDelayTimeLevel(3);
producer.send(message);延迟消息有 18 个级别,如下:
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
实现原理
延迟消息的实现原理如下图:
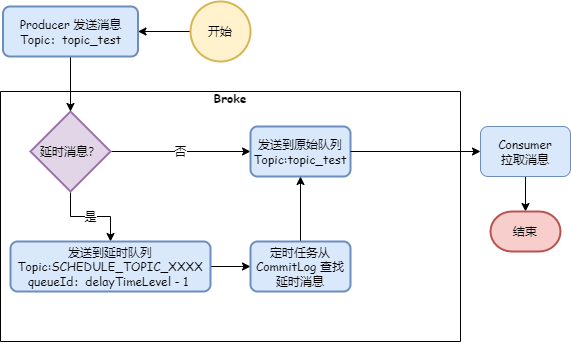
Producer 把消息发送到 Broker 后,Broker 判断是否 延迟消息,如果是,首先会把消息投递到延时队列(Topic = SCHEDULE_TOPIC_XXXX,queueId = delayTimeLevel - 1)。
另外,由于18 个级别的延迟,所以定时任务线程池会有 18 个线程来对延时队列进行调度,每个线程调度一个延时级别,调度任务把 延迟消息再投递到原始队列,这样 Consumer 就可以拉取到了到期的消息。
RocketMQ 4.x 粗粒度 延迟消息存在不足
RocketMQ 4.x 延迟消息存在着一些不足:
1、延时级别只有 18 个,粒度很粗,并不能满足所有场景;
"1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
2、可以通过修改 messageDelayLevel 配置来自定义延时级别,虽然可以修改,但是不灵活
比如一个在大规模的平台上,延时级别成百上千,而且随时可能增加新的延时时间;
3.延时时间不准确,后台的定时线程可能会因为处理消息量大导致延时误差大。
RocketMQ 5.x 细粒度定时消息
为了弥补 延迟消息的不足,RocketMQ 5.0 引入了细粒度定时消息。
经典的时间轮算法如下:
时间轮类似map,key 为时间的刻度,value为此刻度所对应的任务列表。
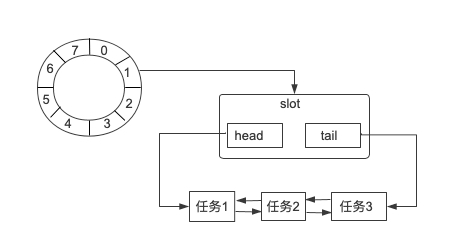
一般来说,可以理解为一种环形结构,像钟表一样被分为多个 slot 槽位。每个 slot 代表一个时间段,每个 slot 中可以存放多个任务,使用的是链表结构保存该时间段到期的所有任务。时间轮通过一个时针随着时间一个个 slot 转动,并执行 slot 中的所有到期任务。
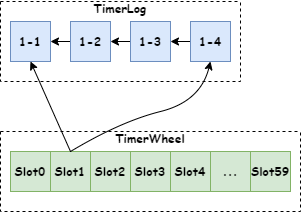
从内部结构来看,是一个Bucket 数组,每个 Bucket 表示时间轮中一个 slot。从 Bucket 的结构定义可以看出,Bucket 内部是一个双向链表结构,双向链表的每个节点持有一个 task 对象,task 代表一个定时任务。每个 Bucket 都包含双向链表 head 和 tail 两个 task 节点,这样就可以实现不同方向进行链表遍历。
时间轮的算法、以及时间轮的演进,非常重要
RocketMQ 5.X的时间轮
RocketMQ 定时消息引入了秒级的时间轮算法。注意,是秒级时间轮。从源码来看,RocketMQ 定义了一个 7 天的以秒为单位的时间轮。
注意:时间刻度为1s,没有再细,比如 10ms、100ms之类的 。作为参考下面提供一个一分钟的,以1s为刻度的时间轮,如下图:
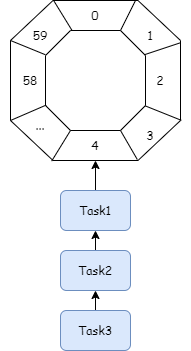
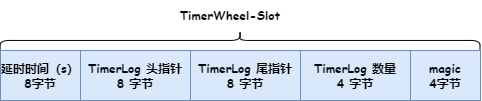
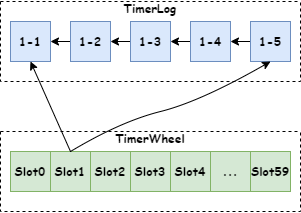
图中是一个 60s 的时间轮,每一个槽位是一个链表,链表里边的节点,通过TimerLog节点结构来记录不同时刻的消息。所以,RocketMQ 使用 TimerWheel 来描述时间轮,TimerWheel 中每一个时间节点是一个 Slot,Slot 保存了这个延时时间的 TimerLog 信息的链表。
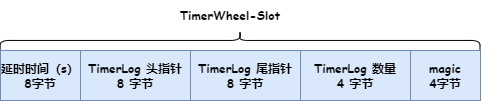
Slot 数据结构如下图:
参考下面代码:
//类 TimerWheel
public void putSlot(long timeMs, long firstPos, long lastPos, int num, int magic) {
localBuffer.get().position(getSlotIndex(timeMs) * Slot.SIZE);
localBuffer.get().putLong(timeMs / precisionMs);
localBuffer.get().putLong(firstPos);
localBuffer.get().putLong(lastPos);
localBuffer.get().putInt(num);
localBuffer.get().putInt(magic);
}
绑定时间轮
时间通过TimerWheel来描述时间轮不同的时刻,并且,对于所处于同一个刻度的的消息,组成一个槽位的链表,每一个定时消息,有一个TimerLog 描述定时相关的信息。TimerLog 有一个核心字段prevPos,同一个时间轮槽位里边的TimerLog ,会通过prevPos串联成一个链表。首先看一下 TimerLog 保存的数据结构,如下图:

参考下面代码:
//TimerMessageStore类
ByteBuffer tmpBuffer = timerLogBuffer;
tmpBuffer.clear();
tmpBuffer.putInt(TimerLog.UNIT_SIZE); //size
tmpBuffer.putLong(slot.lastPos); //prev pos
tmpBuffer.putInt(magic); //magic
tmpBuffer.putLong(tmpWriteTimeMs); //currWriteTime
tmpBuffer.putInt((int) (delayedTime - tmpWriteTimeMs)); //delayTime
tmpBuffer.putLong(offsetPy); //offset
tmpBuffer.putInt(sizePy); //size
tmpBuffer.putInt(hashTopicForMetrics(realTopic)); //hashcode of real topic
tmpBuffer.putLong(0); //reserved value, just set to 0 now
long ret = timerLog.append(tmpBuffer.array(), 0, TimerLog.UNIT_SIZE);
if (-1 != ret) {
// If it's a delete message, then slot's total num -1
// TODO: check if the delete msg is in the same slot with "the msg to be deleted".
timerWheel.putSlot(delayedTime, slot.firstPos == -1 ? ret : slot.firstPos, ret,
isDelete ? slot.num - 1 : slot.num + 1, slot.magic);
}
时间轮上的时间指针
时间轮上,会有一个指向当前时间的指针定时地移动到下一个时间(秒级)。TimerWheel中的每一格代表着一个时刻,同时会有一个firstPos指向槽位链的首条TimerLog记录的地址,一个lastPos指向这个槽位链最后一条TimerLog的记录的地址。
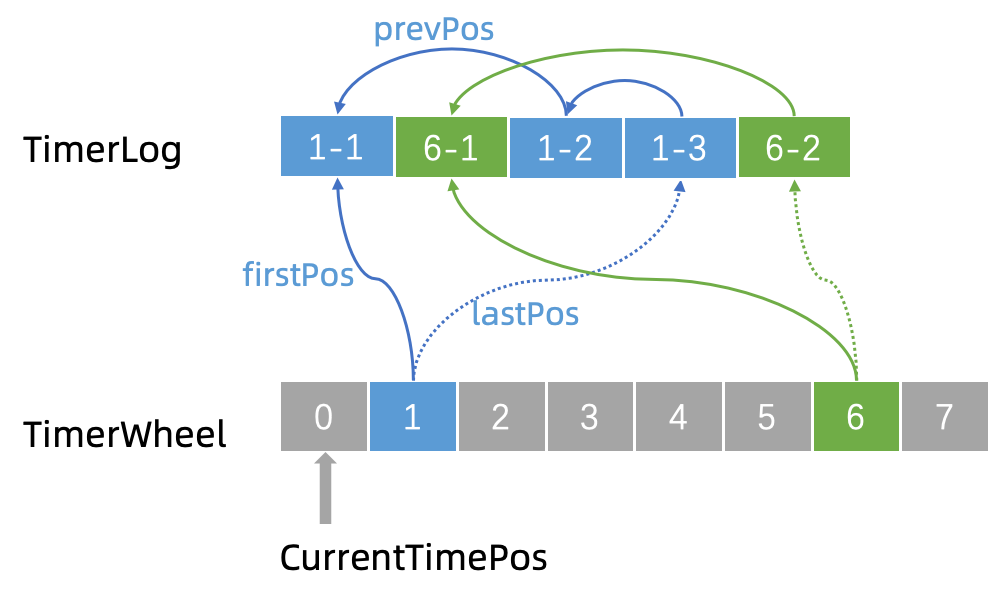
当需要新增一条记录的时候,例如现在我们要新增一个 “1-4”。那么就将新记录的 prevPos 指向当前的 lastPos,即 “1-3”,然后修改 lastPos 指向 “1-4”。这样就将同一个刻度上面的 TimerLog 记录全都串起来了。
精准定时消息发送方式
使用 RocketMQ 定时消息时,客户端定义精准定时消息的示例代码如下:
//定义消息投递时间
// deliveryTime = 未来的一个时间戳
org.apache.rocketmq.common.message.Message messageExt = this.sendMessageActivity.buildMessage(null,
Lists.newArrayList(
Message.newBuilder()
.setTopic(Resource.newBuilder()
.setName(TOPIC)
.build())
.setSystemProperties(SystemProperties.newBuilder()
.setMessageId(msgId)
.setQueueId(0)
.setMessageType(MessageType.DELAY)
.setDeliveryTimestamp(Timestamps.fromMillis(deliveryTime))
.setBornTimestamp(Timestamps.fromMillis(System.currentTimeMillis()))
.setBornHost(StringUtils.defaultString(RemotingUtil.getLocalAddress(), "127.0.0.1:1234"))
.build())
.setBody(ByteString.copyFromUtf8("123"))
.build()
),
Resource.newBuilder().setName(TOPIC).build()).get(0);
源码分析:消息投递原理
客户端SDK代码中,Producer 创建消息时给消息传了一个系统属性 deliveryTimestamp,这个属性指定了消息投递的时间,并且封装到消息的 TIMER_DELIVER_MS 属性,代码如下:
protected void fillDelayMessageProperty(apache.rocketmq.v2.Message message, org.apache.rocketmq.common.message.Message messageWithHeader) {
if (message.getSystemProperties().hasDeliveryTimestamp()) {
Timestamp deliveryTimestamp = message.getSystemProperties().getDeliveryTimestamp();
//delayTime 这个延时时间默认不能超过 1 天,可以配置
long deliveryTimestampMs = Timestamps.toMillis(deliveryTimestamp);
validateDelayTime(deliveryTimestampMs);
//...
String timestampString = String.valueOf(deliveryTimestampMs);
//MessageConst.PROPERTY_TIMER_DELIVER_MS="TIMER_DELIVER_MS"
MessageAccessor.putProperty(messageWithHeader, MessageConst.PROPERTY_TIMER_DELIVER_MS, timestampString);
}
}
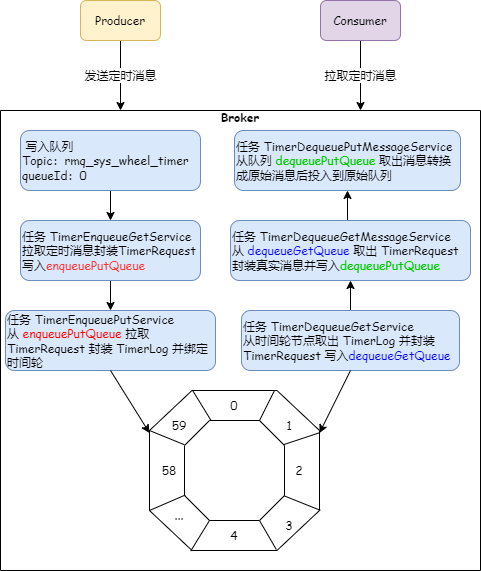
服务端代码中,Broker 收到这个消息后,判断到 TIMER_DELIVER_MS 这个属性是否有值,如果有,就会把这个消息投递到 Topic 是 rmq_sys_wheel_timer 的队列中,这个只有一个分区,queueId 是 0,作为中转的队列
中转的时候,同时会保存原始消息的 Topic、queueId、投递时间(TIMER_OUT_MS)。
TimerMessageStore 中有个定时任务 TimerEnqueueGetService 会从 rmq_sys_wheel_timer 这个 Topic 中读取消息,然后封装 TimerRequest 请求并放到内存队列 enqueuePutQueue。一个异步任务TimerEnqueuePutService 从上面的 enqueuePutQueue 取出 TimerRequest 然后封装成 TimerLog,然后绑定到时间轮。
TimerLog 是怎么和时间轮关联起来的呢?
RocketMQ 使用 TimerWheel 来描述时间轮,从源码上看,RocketMQ 定义了一个 7 天的以秒为单位的时间轮。TimerWheel 中每一个时间节点是一个 Slot,Slot 保存了这个延时时间的 TimerLog 信息。
数据结构如下图:
参考下面代码:
//类 TimerWheel
public void putSlot(long timeMs, long firstPos, long lastPos, int num, int magic) {
localBuffer.get().position(getSlotIndex(timeMs) * Slot.SIZE);
localBuffer.get().putLong(timeMs / precisionMs);
localBuffer.get().putLong(firstPos);
localBuffer.get().putLong(lastPos);
localBuffer.get().putInt(num);
localBuffer.get().putInt(magic);
}
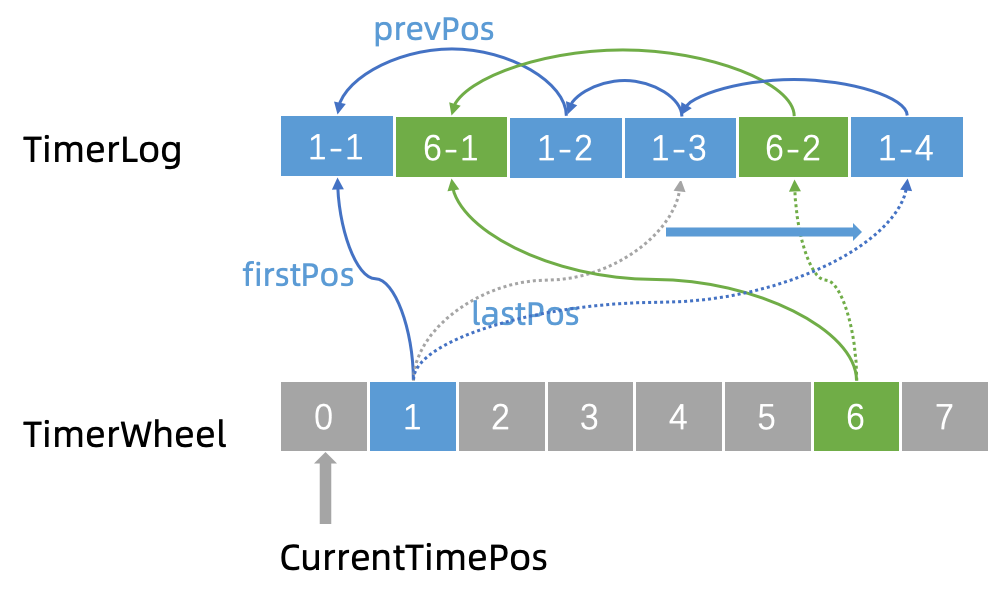
通过TimerWheel的 putSlot方法,TimerLog 跟 时间轮就绑定起来了,见下图:
如果时间轮的一个时间节点(Slot)上有一条新的消息到来,那只要新建一个 TimerLog,然后把它的指针指向该时间节点的最后一个 TimerLog,然后把 Slot 的 lastPos 属性指向新建的这个 TimerLog,如下图:
时间轮中的 定时消息异步处理总流程
定时消息进入到时间轮了。随着时间刻度的步进,上面的消息,怎么转移到原始的topic的分区?
由于 rocketmq 的源码是超高性能的,所以,这里有N个队列做缓冲,有N个任务。这里用到 5 个定时任务和 3个队列来实现。定时消息的处理流程如下图:
时间轮转动
转动时间轮时,TimerDequeueGetService 这个定时任务从当前时间节点(Slot)对应的 TimerLog 中取出数据,封装成 TimerRequest 放入 dequeueGetQueue 队列。
CommitLog 中读取消息
定时任务 TimerDequeueGetMessageService 从队列 dequeueGetQueue 中拉取 TimerRequest 请求,然后根据 TimerRequest 中的参数去 CommitLog(MessageExt)中查找消息,查出后把消息封装到 TimerRequest 中,然后把 TimerRequest 写入 dequeuePutQueue 这个队列。
写入原队列
定时任务 TimerDequeuePutMessageService 从 dequeuePutQueue 队列中获取消息,把消息转换成原始消息,投入到原始队列中,这样消费者就可以拉取到了。
RocketMQ的定时消息的优点和不足
要注意的地方
对于定时时间的定义,客户端、Broker 和时间轮的默认最大延时时间定义是不同的,使用的时候需要注意。
RocketMQ的定时消息优点
-
精度高,支持任意时刻。
-
使用门槛低,和使用普通消息一样。
RocketMQ的定时消息缺点
-
时长的使用限制: 定时和延时消息的msg.setStartDeliverTime参数可设置40天内的任何时刻(单位毫秒),超过40天消息发送将失败。
设置定时和延时消息的投递时间后,从中转队列调度到了原始的消息队列之后,依然受3天的消息保存时长限制。例如,设置定时消息5天后才能被消费,如果第5天后一直没被消费,那么这条消息将在第8天被删除。
-
海量 消息场景,存储成本高: 在海量订单场景中,如果每个订单需要新增一个定时消息,且不会马上消费,额外给MQ带来很大的存储成本。
-
同一个时刻大量消息会导致消息延迟: 定时消息的实现逻辑需要先经过定时存储等待触发,定时时间到达后才会被投递给消费者。
因此,如果将大量定时消息的定时时间设置为同一时刻,则到达该时刻后会有大量消息同时需要被处理,会造成系统压力过大,导致消息分发延迟,影响定时精度。
方案3:Redis的过期监听
和RocketMQ定时消息一样,Redis支持过期监听,也能达到的能力。
通过Redis中key的过期事件,作为延迟消息
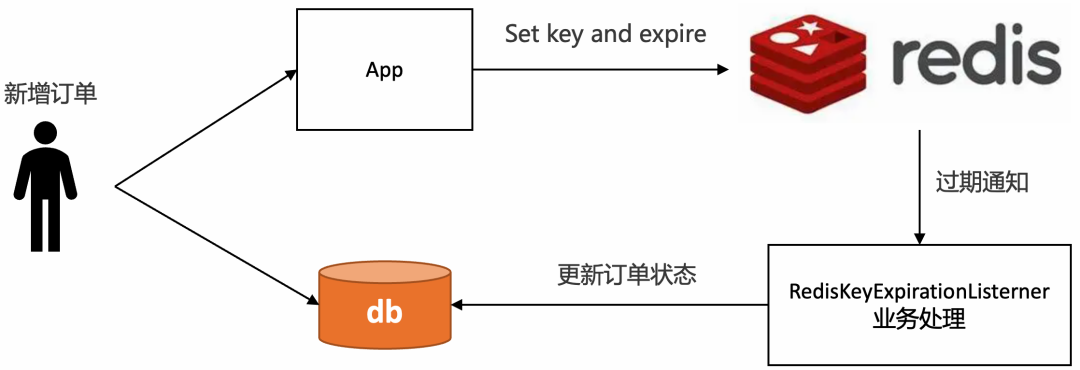
可以通过Redis中key的过期事件,作为延迟消息。使用Redis进行订单超时处理的流程图如下
具体步骤如下:
-
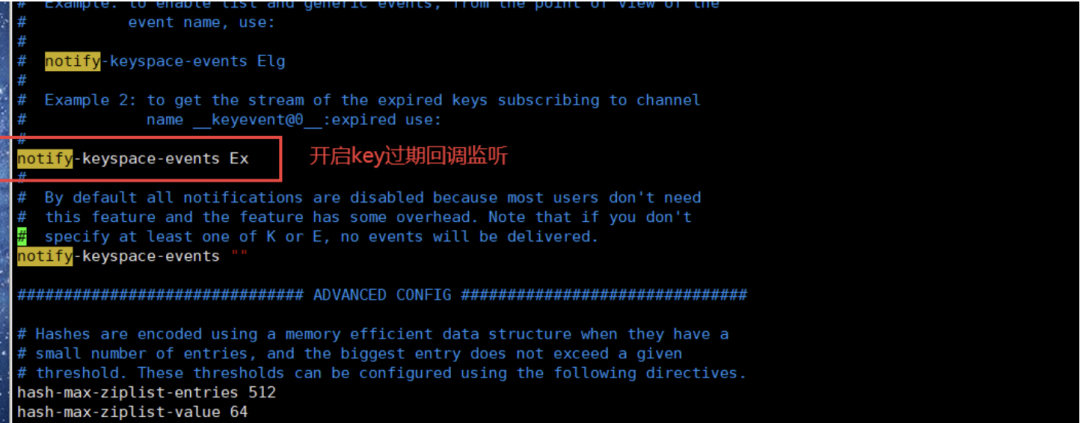
在服务器中 修改redis配置文件, 开启"notify-keyspace-events Ex"
原来notify-keyspace-events 属性是" " 空的,我们只需要填上“Ex”就行了
-
监听key的过期回调
创建一个Redis监控类,用于监控过期的key,该类需继承KeyExpirationEventMessageListener
public class KeyExpiredListener extends KeyExpirationEventMessageListener {
public KeyExpiredListener(RedisMessageListenerContainer listenerContainer) {
super(listenerContainer);
}
@Override
public void onMessage(Message message, byte[] pattern) {
String keyExpira = message.toString();
System.out.println("监听到key:" + expiredKey + "已过期");
}
}
-
创建Redis配置类 , 装配这个 监听器
@Configuration
public class RedisConfiguration {
@Autowired
private RedisConnectionFactory redisConnectionFactory;
@Bean
public RedisMessageListenerContainer redisMessageListenerContainer() {
RedisMessageListenerContainer redisMessageListenerContainer = new RedisMessageListenerContainer();
redisMessageListenerContainer.setConnectionFactory(redisConnectionFactory);
return redisMessageListenerContainer;
}
@Bean
public KeyExpiredListener keyExpiredListener() {
return new KeyExpiredListener(this.redisMessageListenerContainer());
}
}
Redis过期时间作为延迟消息的原理
每当一个key设置了过期时间,Redis就会把该key带上过期时间,在redisDb中通过expires字段维护:
typedef struct redisDb {
dict *dict; /* 维护所有key-value键值对 */
dict *expires; /* 过期字典,维护设置失效时间的键 */
....
} redisDb;
这个结构,通过一个 过期字典dict来维护。过期字典dict 本质上是一个链表,每个节点的数据结构结构如下:
-
key是一个指针,指向某个键对象。
-
value是一个long long类型的整数,保存了key的过期时间。
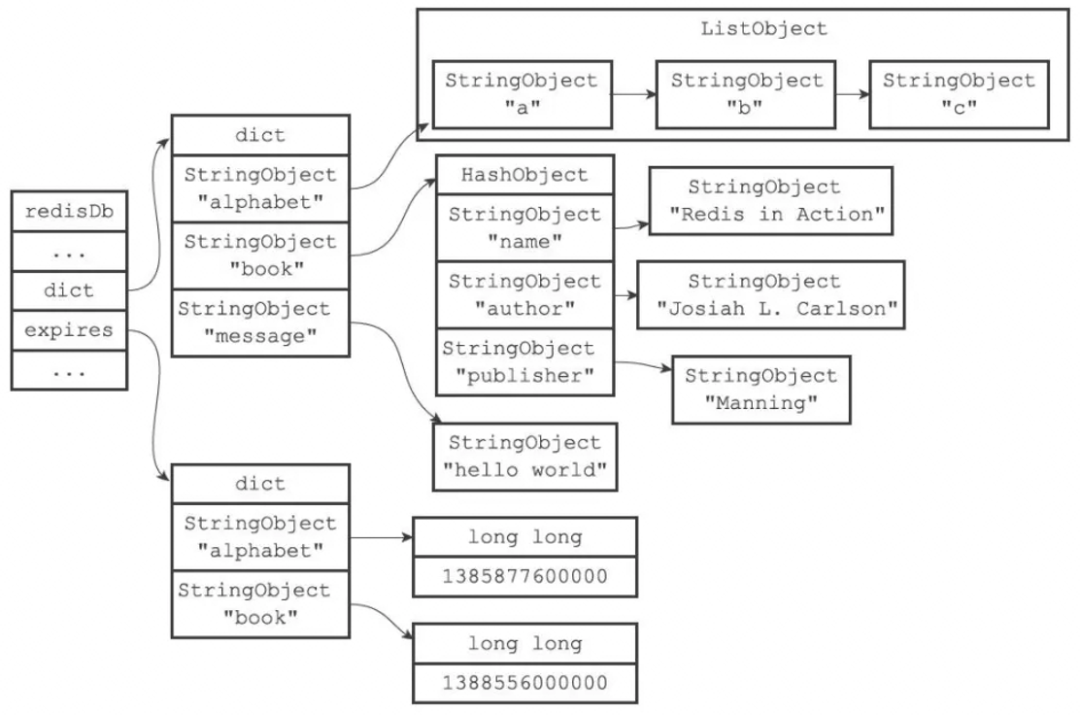
为了提升性能,Redis主要使用了定期删除和惰性删除策略来进行过期key的删除
-
定期删除:每隔一段时间(默认100ms)就随机抽取一些设置了过期时间的key,检查其是否过期,如果有过期就删除。之所以这么做,是为了通过限制删除操作的执行时长和频率来减少对cpu的影响。不然每隔100ms就要遍历所有设置过期时间的key,会导致cpu负载太大。
-
惰性删除:不主动删除过期的key,每次从数据库访问key时,都检测key是否过期,如果过期则删除该key。惰性删除有一个问题,如果这个key已经过期了,但是一直没有被访问,就会一直保存在数据库中。
从以上可以知道,Redis过期删除是不精准的,在订单超时处理的场景下,订单的数据如果没有去访问,那么惰性删除基本上也用不到,所以,无法保证key在过期的时候可以立即删除,更不能保证能立即通知。
如果订单量比较大,那么延迟几分钟也是有可能的。总而言之,Redis过期通知也是不可靠的,Redis在过期通知的时候,如果应用正好重启了,那么就有可能通知事件就丢了,会导致订单一直无法关闭,有稳定性问题。
方案4:超大规模分布式定时批处理 架构
海量订单过期的 分布式定时批处理解决方案,分为两步:
step1:通过分布式定时不停轮询数据库的订单,将已经超时的订单捞出来
step2:分而治之,分发给不同的机器分布式处理
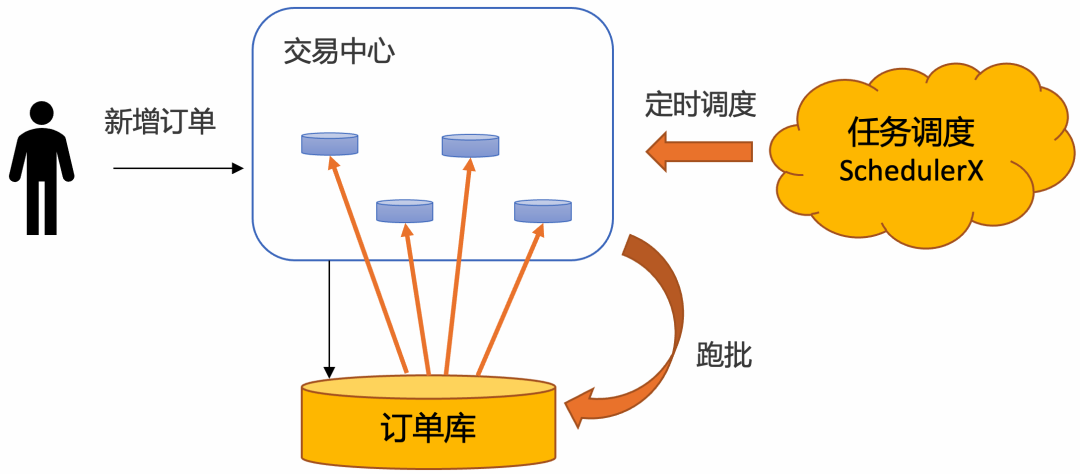
在阿里内部,几乎所有的业务都使用超大规模分布式定时批处理 架构,大致的架构图如下:
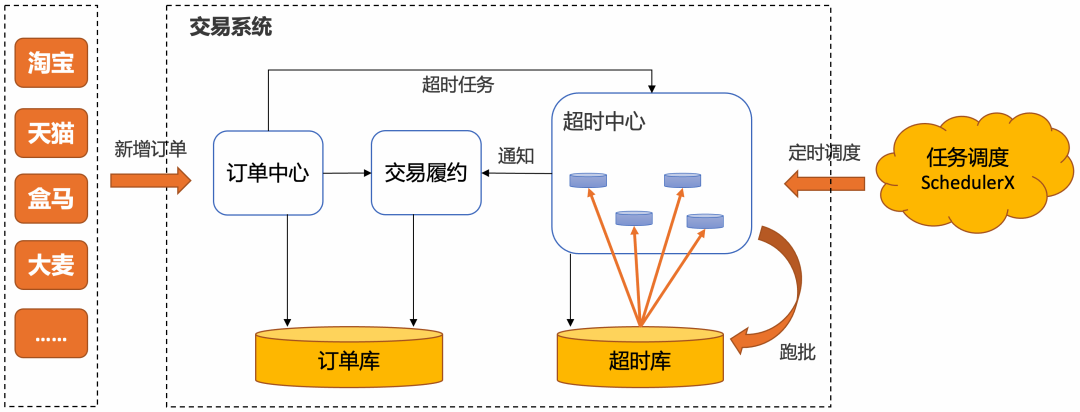
超大规模分布式定时批处理 宏观架构
如何让超时调度中心不同的节点协同工作,拉取不同的数据?宏观的架构如下:
调度中心:海量任务调度执行系统
通常的解决方案如
-
自研分布式调度系统,基于DB的分布式调度系统、基于zookeeper 的分布式调度系统
-
开源的分布式调度系统 如 xxl-job
-
阿里巴巴分布式任务调度系统SchedulerX,不但兼容主流开源任务调度系统,也兼容Spring @Scheduled注解
优先推荐,是使用最新版本的、基于时间轮的xxl-job,或者基于xxl-job做定制开发。xxl-job基于 时间轮完成调度。
在100亿级海量订单超时处理场景中,虽然海量订单,但是对于调度系统来说,不是海量的。因为为了给DB降低压力,订单是批量处理的,不可能一个订单一个延迟任务,而是一大批订单一个延迟任务。所以,任务的数量级,成数量级的下降。所以00亿级海量订单超时处理场景的压力不在调度,而在于数据库。
问题的关键是如何进行数据分片。
海量数据分片模型
首先来看 DB数据的数据是如何分片的。 DB数据分片模型的架构,本身场景复杂:
-
分库分表场景
-
一张大表场景
-
海量数据存储组件 hbase、hdfs 等等
海量数据分片模型 要解决问题:
-
首先是复杂的分片模型的问题
-
其次就是数据批处理的过程中,如何减少数据传输,提升性能的问题。
第一个问题:复杂的分片模型的问题。分片模型与数据库的存储方案的选型,和分库分表的设计有关。
轻量级MapReduce模型
第2个问题:如何减少数据传输。
注意,如果数据源在mysql这样的结构化db,修改订单的状态,是可以直接通过结构化sql,进行批量更新的。这个一条sql搞定,是非常简单的。但是,既然是海量数据,就不一定在结构化DB,而是在异构的DB(NOSQL)中。
异构DB(NOSQL)就没有办法通过结构化sql,进行批量更新了。很多的NOSQL DB的记录修改,是需要两步:
-
step1:把数据读取出来,
-
step2:改完之后,再写入。
所以,如果订单的数据源,不一定是DB,而且在异构的DB(NOSQL)中, 那么久存在大量的数据传输的问题。
100亿级订单规模,基本上会涉及到异构DB,所以阿里的订单状态修改,要求既能兼容 结构化DB,又能兼容异构 DB, 那么就存在大量的数据传输问题。
为了减少数据传输,提升批处理性能的问题。阿里技术团队,使用了轻量级MapReduce模型。
重量级MapReduce模型
首先看看,什么是MapReduce模型。
传统的基于hadoop的文件批处理,数据在hdfs文件系统中,读取到内存之后,再把结果写入到hdfs,这种基于文件的批处理模式,存在大量的数据传输、磁盘IO,性能太低太低,根本不在目前的这个场景考虑之内。
基于内存的批量数据处理,比如spark中的离线批量处理,采用的内存处理方式,和基于文件的批量处理相比,速度有了质的飞越。
在spark基于内存的批处理流程中(这里简称为基于内存的MR),首先把数据加载到内存, 进行map转换、reduce 规约(或者聚合)之后,再把结果通过网络传输到下一个环节。这里,存在着大家的数据传输。
所以,不论是内存的批处理、还是基于文件批处理,都需要大量的传输数据,大量的数据传输,意味着性能太低, 不适用 海量订单批处理场景。
轻量级MapReduce模型
阿里自研了轻量级MapReduce模型,可以简称为本地批处理。所以轻量级MapReduce模型,就是减少数据传输,在原来的数据库里边进行数据的计算(比如通过SQL语句),不需要把数据加载到内存进行计算。
轻量级MapReduce模型在执行的过程中,计算节点主要管理的是 转换、规约 的分片规则、执行状态和结果,对这些任务中的业务数据,计算节点不去读取计算的目标数据,减少了海量业务数据的反复读取、写入。
转换阶段:
轻量级MapReduce模型,通过实现map函数,通过代码自行构造分片,调度系统将分片平均分给超时中心的不同节点分布式执行。
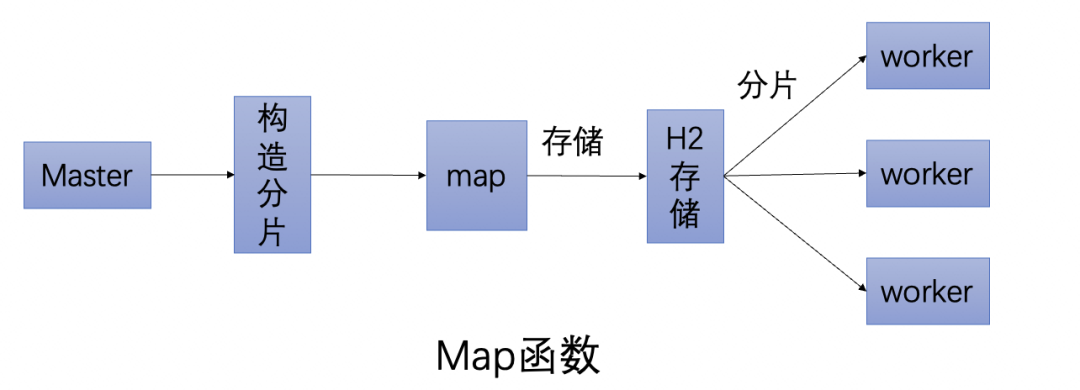
注意,在MR集群中,分片由Master主节点完成,保存在内存数据库H2中。工作节点的调度,也是Master完成。
规约阶段
通过实现reduce函数,可以做聚合,可以判断这次跑批有哪些分片跑失败了,从而通知下游处理。
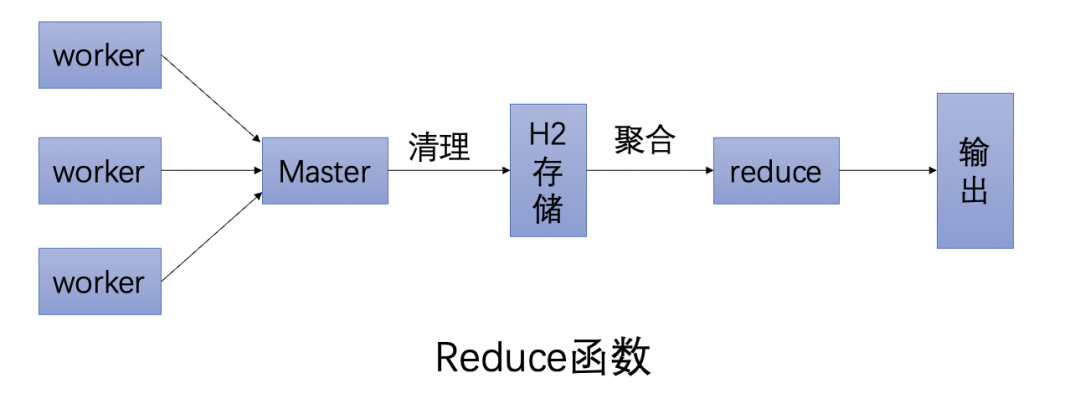
注意,在MR集群中,work的分片任务执行结果汇报到Master,这些结果保存在内存数据库H2中,由Master完成规约(或聚合)。有了这个自研了轻量级MapReduce模型,阿里的超时调度中心可以针对任意异构数据源,简单几行代码就可以实现海量数据秒级别跑批。
定时任务分布式批处理的方案的优势:
使用定时任务分布式批处理的方案具有如下优势:
-
稳定性强:
基于通知的方案(比如MQ和Redis),比较担心在各种极端情况下导致通知的事件丢了。使用定时任务跑批,只需要保证业务幂等即可,如果这个批次有些订单没有捞出来,或者处理订单的时候应用重启了,下一个批次还是可以捞出来处理,稳定性非常高。
-
效率高:
基于MQ的方案,需要一个订单一个定时消息,consumer处理定时消息的时候也需要一个订单一个订单更新,对数据库tps很高。
使用定时任务跑批方案,一次捞出一批订单,处理完了,可以批量更新订单状态,减少数据库的tps。在海量订单处理场景下,批量处理效率最高。
-
可运维:
基于数据库存储,可以很方便的对订单进行修改、暂停、取消等操作,所见即所得。如果业务跑失败了,还可以直接通过sql修改数据库来进行批量运维。
-
成本低:
相对于其他解决方案要借助第三方存储组件,复用数据库的成本大大降低。
定时任务分布式批处理的方案的缺点:
但是使用定时任务有个天然的缺点:没法做到精度很高。
定时任务的延迟时间,由定时任务的调度周期决定。如果把频率设置很小,就会导致数据库的qps比较高,容易造成数据库压力过大,从而影响线上的正常业务。
解决方案就是DB解耦:
阿里内部,一般需要解耦单独超时库,单独做订单的超时调度,不会和业务库在在一起操作。同时也有独立的超时中心,完成 数据的分片,以及跑批任务的调度。
订单任务调度场景的选型
(1)超时精度比较高、超时任务不会有峰值压力的场景
如果对于超时精度比较高,不会有峰值压力的场景,推荐使用RocketMQ的定时消息解决方案。
(2)超时精度比较低、超时任务不会有峰值压力的场景(100亿级订单)
在电商业务下,许多订单超时场景都在24小时以上,对于超时精度没有那么敏感,并且有海量订单需要批处理,推荐使用基于定时任务的跑批解决方案。
阿里的100亿级订单超时处理选型,选择的是后面的方案。
参考链接:
[1]https://developer.aliyun.com/article/994932
[2]https://redis.io/docs/manual/keyspace-notifications/
[3]https://www.aliyun.com/aliware/schedulerx
[4]https://developer.aliyun.com/article/706820
[5]https://blog.csdn.net/zjj2006/article/details/127825955
4次迭代,让HttpClient提速100倍
在生产项目中,经常需要通过Client组件(HttpClient/OkHttp/JDK Connection)调用第三方接口。
在一个高并发的中台生产项目中。有一个比较特殊的请求,一次请求,包含 10个 Web 外部服务调用,每个服务调用的预定时间200ms。
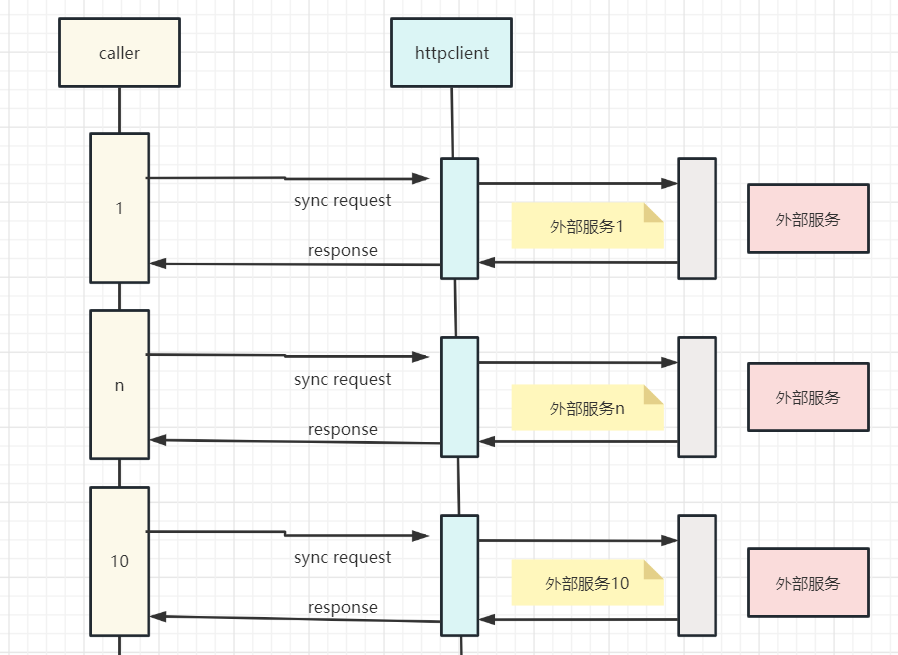
为了并行,使用了一个很大的线程池,最大100个线程。注意,这里100个线程已经很多了,因为其他的环节也需要很多线程,所以不能太多。
第1次迭代:使用 CompletableFuture 完成并发
最早的代码,是通过向线程池中提交任务的方式完成的,从代码的优雅程度上来说,比使用CompletableFuture 的方式,差得太远。所以,第1轮迭代,是通过CompletableFuture进行代码的优化。这个环节,对性能没有本质的提升,但是CompletableFuture 这种 函数式编程的风格,为后面的迭代打下来一些技术基础。
使用CompletableFuture 并发10个远程api 接口,有两个方法
-
方法1:CompletableFuture 和 CountDownLatch
-
方法2:CompletableFuture.allOf 算子
在代码实现的时候,使用了结合使用CompletableFuture 和 CountDownLatch 进行并发回调

为了大家能体验效果,给大家提供了一段原始代码的参考程序,具体如下:
package com.crazymaker.springcloud;
import com.crazymaker.springcloud.common.util.ThreadUtil;
import org.junit.Test;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
public class CoCurrentDemo {
/**
* 使用CompletableFuture 和 CountDownLatch 进行并发回调
*/
@Test
public void testMutiCallBack() {
CountDownLatch countDownLatch = new CountDownLatch(10);
//批量异步
ExecutorService executor = ThreadUtil.getIoIntenseTargetThreadPool();
long start = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
CompletableFuture<Long> future = CompletableFuture.supplyAsync(() -> {
long tid = ThreadUtil.getCurThreadId();
try {
doRpc(tid); //异步执行 远程调用
} catch (InterruptedException e) {
e.printStackTrace();
}
return tid;
}, executor);
future.thenAccept((tid) -> {
System.out.println("线程" + tid + "结束了");
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
//输出统计结果
float time = System.currentTimeMillis() - start;
System.out.println("所有任务已经执行完毕");
System.out.println("运行的时长为(ms):" + time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void doRpc(long tid) throws InterruptedException {
System.out.println("线程" + tid + "开始了,模拟一下远程调用");
Thread.sleep(200);
}
}
第2次迭代:响应式 Flux 流进行异步回调改造
执行一次WEB调用操作所需的实际工作非常少。实际的工作就2点:
-
生成并触发一个请求
-
等一段时间,收到一个响应。
而且,其中有一个节非常低性能,这个环节是:在请求和响应之间,线程根本没有做任何工作,而且在等待,等待200ms。线程资源是宝贵的。咱们一个java应用不能开始太多的线程,一般最多就400个左右。如果开启太多,很多的cpu资源就用去做线程上下文切换了。
如何要让这些线程不等待,去干别的工作,该当如何?这是使用异步框架。使用异步框架发出 Web 请求的核心优势之一,在请求进行中时您不会占用任何线程。第2次迭代:响应式 Flux 流进行异步回调改造。

使用异步框架的核心逻辑,如下所以:
Flux.range(0,100)
.subscribeOn(Schedulers.boundedElastic())
.flatMap(i -> webClientCallApi(i))
.subscribe(...) //定义结果
响应式的本质,是回调。其原理,请参考:京东一面:20种异步,你知道几种?含协程
在响应式框架中,我们的线程不用再死耗了,底层的逻辑是:把异步任务加入响应式组件的内部的队列之后,就去干起别的事情了,不需要去死死等200ms。
我们进行了第2次迭代:响应式Flux流进行异步回调改造。为了大家能体验效果,给大家提供了一段原始代码的参考程序,具体如下:
private Flux<Integer> doRpcFlux(int key) {
return Flux.create(sink -> {
log.info("模拟远程调用,参数为:" + key);
ThreadUtil.sleepMilliSeconds(100);
sink.next(key);
sink.complete();
});
}
@Test
public void mergeTest5() throws InterruptedException {
long startTime = LocalTiker.SINGLETON.now();
Iterable<Integer> targetKeys = Arrays.asList( 101, 102, 103, 104, 105);
Flux.fromIterable(targetKeys)
.publishOn(Schedulers.fromExecutorService(
ThreadUtil.getMixedTargetThreadPool()))
.flatMap(key -> doRpcFlux(key))
.doOnError(ReactorPrallelDemo::doOnError)
.doOnComplete(ReactorPrallelDemo::doOnComplete)
.doFinally(signalType -> log.info("并发执行的时间: " + LocalTiker.SINGLETON.gapFrom(startTime)))
.subscribe(responseData -> log.info(responseData.toString()), e -> log.info("error:" + e.getMessage()));
Thread.sleep(200000);
}
第3次迭代:响应式 parallel Flux 流进行并行异步回调改造
改造之后,虽然线程资源得到了有效的利用。但是由于前期对flux流的机制,不是太清楚。实际上的情况是,性能反而下降了。实际上,flux的内部机制:flux流里边的任务,默认是串行执行的。所以上面的代码,实际上是让10次调用 串行执行。初心是并行,实际上适得其反,变成了串行,性能反而大大下降。
怎么回到并行呢?需要使用 Flux parallel流。下面是一段 使用paralle Flux 的demo:
Flux.range(0,100)
.parallel()
.runOn(Schedulers.boundedElastic())
.flatMap(i -> webClientCallApi(i))
.sequential().collecttoList();我们进行了第3次迭代:响应式 parallel Flux 流进行并行异步回调改造。

为了大家能体验效果,给大家提供了一段原始代码的参考程序,具体如下:
@Test
public void mergeTest6() throws InterruptedException {
long startTime = LocalTiker.SINGLETON.now();
Iterable<Integer> targetKeys = Arrays.asList(100, 101, 102, 103, 104, 105, 106, 107);
Flux.fromIterable(targetKeys)
.parallel()
.runOn(Schedulers.fromExecutorService(ThreadUtil.getMixedTargetThreadPool()))
.flatMap(key -> doRpcFlux(key))
.sequential()
.doOnError(ReactorPrallelDemo::doOnError)
.doOnComplete(ReactorPrallelDemo::doOnComplete)
.doFinally(signalType -> log.info("并发执行的时间: " + LocalTiker.SINGLETON.gapFrom(startTime)))
.subscribe(i -> log.info("->" + i));
Thread.sleep(200000);
}
private static void doOnComplete() {
log.info("并发远程调用异常完成");
}运行的结果如下:
12:31:34.138 [Biz-1-cpu-2] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - this taskB start
12:31:34.138 [Biz-1-cpu-1] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - this taskA start
12:31:34.227 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
12:31:34.296 [Biz-2-mixed-18] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:101
12:31:34.296 [Biz-2-mixed-22] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:105
12:31:34.296 [Biz-2-mixed-23] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:106
12:31:34.296 [Biz-2-mixed-24] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:107
12:31:34.296 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:103
12:31:34.296 [Biz-2-mixed-21] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:104
12:31:34.296 [Biz-2-mixed-17] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:100
12:31:34.296 [Biz-2-mixed-19] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:102
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->103
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->100
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->101
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->102
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->104
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->105
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->106
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->107
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发远程调用异常完成
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的时间: 105
响应式Flux parallel流进行并行异步回调改造,实现了两个效果:
-
并行
-
没有线程阻塞等待(异步回调)
还有点问题没有解决,就是底层组件是httpclient,没有使用异步非阻塞的netty组件。虽然底层IO组件还是存在线程阻塞,只是这个下一次迭代再说。至少从业务维度,第三次迭代之后,没有线程阻塞等待。
接下来,说说parallel Flux并行 流的使用场景和基础原理。
parallel Flux 流的使用场景
Flux 本质上是将通量元素划分为单独的轨道,元素之间是串行。Flux parallel 模式,就是将通量元素划分为并行的轨道,才是真正并行的。Flux parallel 并行流,在生产场景,经常用到。
假设我上游有一个元素,下游需要根据这个元素有多个Task处理,但是需要等多个Task处理完成后才能返回,如果我不用ConnectFlux的话 ,还有什么其他方法解决吗?
类似于 Mono.just(1).map(a-> { executeTaskA(a); executeTaskB(a); }).subscribe();
我这个executeTaskA 和 executeTaskB 是并行操作的,不存在依赖关系
以上这样的生产问题,都可以使用并行流。
parallel Flux 的底层原理
1. parallel Flux 分配上游元素过程
parallel操作符执行过后,会生成一个新的flux 即parallelFlux。parallelFlux能够接受多个订阅者,他会从原始flux中请求perfetch个元素,将上游传递push过来的元素依次按顺序分配给子订阅者。
parallelFlux分配上游元素过程是:依次分配给下游每个订阅者,当某个子订阅者请求数已经满足时,将跳过此订阅者继续向下一个子订阅者分配。
他有两个参数 parallelism 和 prefetch:
-
parallelism 第一个参数表示划分子流的数量,默认等于cpu核心数
-
prefetch 表示向原始流预取的数量。
parallel本质上是包装每个子订阅者,将接受到的数据存入子订阅者的queue中,然后使用线程池处理queue内的数据。
2. parallel 操作符后接 map/flapMap 操作符
map/flapMap操作符会将真实订阅者生成代理,他将上游onNext的值使用map / flapMap操作符进行转换。在parallelFlux场景下,它会将每个子订阅者包装起来进行转换。
3. parallel 后面可以接 sequential 操作符
sequential 可以将parallelFlux转成普通flux,他的原理是创建parallel需要的子订阅者,使用子订阅者订阅parallelFlux,然后将数据依次从每个子订阅者中获取到数据,向下游发送。
在sequential操作执行时,数据可能来自多个线程,这里采用的是哪个线程先到则负责将其他子订阅者队列中的值向下发,没获取到锁的线程存入队列直接退出。
sequential允许传递参数,表示每个子订阅者身上能存储的元素最大数。
4.parallel 后接 runOn 操作符
parallel本质上是包装每个子订阅者,将接受到的数据存入子订阅者的queue中,然后使用线程池处理queue内的数据。runOn处理的逻辑也是和上面sequential类似,使用AtomicInteger限制每个子订阅者同时只会有一个线程在执行,如果当前已经存在一个线程在执行,后来的数据存入queue后会直接退出。
它还可以传递第二个参数表示每个子订阅者预取的数量,这里为什么要预取呢?
是因为如果下游订阅者请求了非常大的数量,而runOn将任务分配到线程池中本身是非堵塞的,也就是任务全部堆积在线程池中,可能导致内存溢出。所以使用预取参数分批次满足下游的请求数量。
第4次迭代:响应式 WebClient 组件去掉底层的io线程阻塞
虽然httpclient也支持高性能的 nio 模式,但是 httpclient 线程模型是阻塞的,httpclient没有和Netty这样的reactor反应器线程模型。httpclient底层的io线程是阻塞式的,具体如下图:
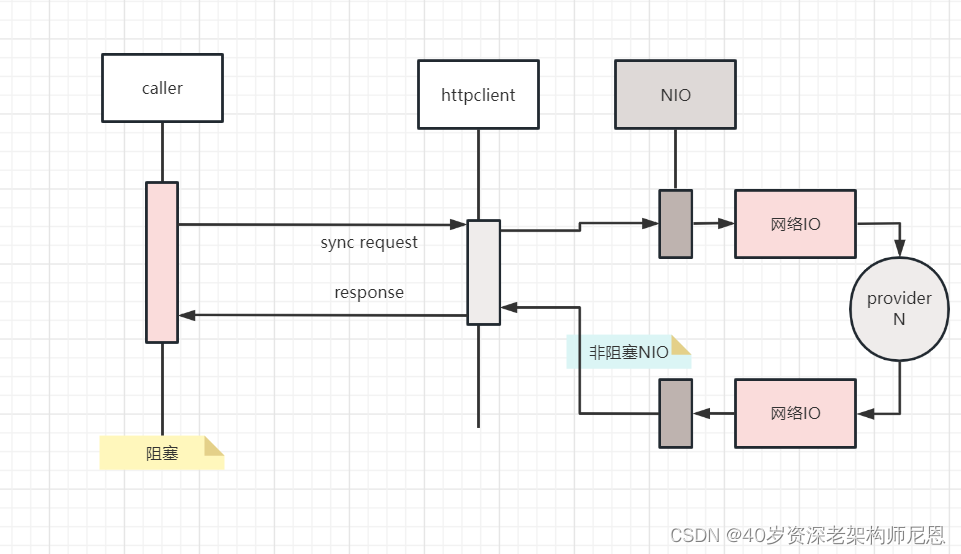
Netty这样的reactor反应器线程模型,底层的io线程是非阻塞式的
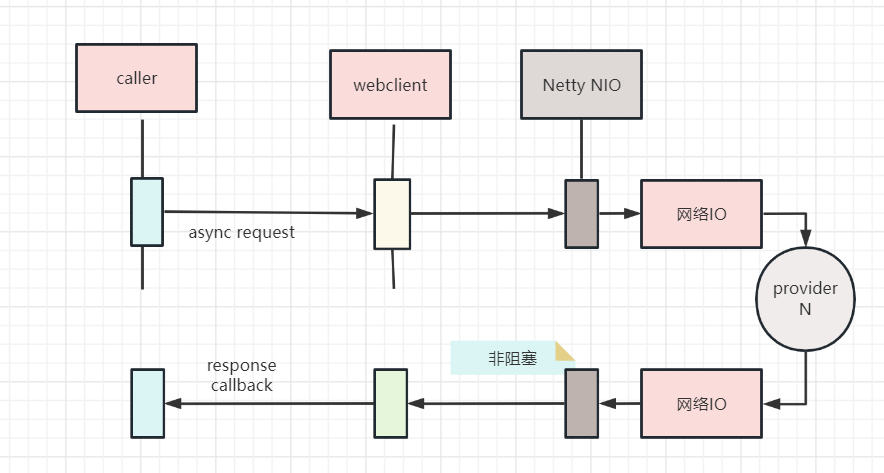
所以,要彻底提升性能,底层需要非阻塞。如果底层的io传输,也需要使用反应器线程,怎么办? 3个措施:
-
那么要么使用netty
-
要么使用基于netty的http组件
-
或者基于netty自己进行封组
这里,使用了响应式的http组件,WebClient组件。使用 WebClient 进行了第四次迭代。

为了大家能体验效果,给大家提供了一段原始代码的参考程序,具体如下:
@Test
public void mergeTest7() throws InterruptedException {
long startTime = LocalTiker.SINGLETON.now();
Iterable<Integer> targetKeys = Arrays.asList( 101, 102, 103, 104, 105);
Flux.fromIterable(targetKeys)
.parallel()
.runOn(Schedulers.fromExecutorService(ThreadUtil.getMixedTargetThreadPool()))
.flatMap(key -> doRpcUseWebClient(key))
.sequential()
.doOnError(ReactorPrallelDemo::doOnError)
.doOnComplete(ReactorPrallelDemo::doOnComplete)
.doFinally(signalType -> log.info("并发执行的时间: " + LocalTiker.SINGLETON.gapFrom(startTime)))
.subscribe(responseData -> log.info(responseData.toString()), e -> log.info("error:" + e.getMessage()));
Thread.sleep(200000);
}
private Flux<RestOut<JSONObject>> doRpcUseWebClient(int key) {
//响应式客户端
WebClient client = null;
WebClient.RequestBodySpec request = null;
//方式一:极简创建
//方式二:使用builder创建
client = WebClient.builder()
.baseUrl("")
.defaultHeader(HttpHeaders.CONTENT_TYPE, "application/json")
.defaultHeader(HttpHeaders.USER_AGENT, "Spring 5 WebClient")
.build();
String restUrl = "http://crazy.api/demo/hello/v1?key=" + key;
/**
* 是通过 WebClient 组件构建请求
*/
request = client
// 请求方法
.method(HttpMethod.GET)
// 请求url 和 参数
// .uri(restUrl, params)
.uri(restUrl)
// 媒体的类型
.accept(MediaType.APPLICATION_JSON);
WebClient.ResponseSpec retrieve = request.retrieve();
// 处理异常 请求发出去之后判断一下返回码
retrieve.onStatus(status -> status.value() == 404,
response -> Mono.just(new RuntimeException("Not Found")));
ParameterizedTypeReference<RestOut<JSONObject>> parameterizedTypeReference =
new ParameterizedTypeReference<RestOut<JSONObject>>() {
};
// 返回流
Mono<RestOut<JSONObject>> resp = retrieve.bodyToMono(parameterizedTypeReference);
return Flux.from(resp);
}