一、STM32怎么选型
什么是 STM32
STM32,从字面上来理解,ST是意法半导体,M是Microelectronics的缩写,32表示32位,合起来理解,STM32就是指ST公司开发的32位微控制器。在如今的32位控制器当中,STM32可以说是最璀璨的新星,它受宠若娇,大受工程师和市场的青睐,无芯能出其右。
STM32属于一个微控制器,自带了各种常用通信接口,比如USART、I2C、SPI等,可接非常多的传感器,可以控制很多的设备。现实生活中,我们接触到的很多电器产品都有STM32的身影,比如智能手环,微型四轴飞行器,平衡车、移动POST机,智能电饭锅,3D打印机等等。
现在无人机非常火热,高端的无人机用STM32做不来,但是小型的四轴飞行器用STM32还是绰绰有余的。
STM32 分类
STM32有很多系列,可以满足市场的各种需求,从内核上分有Cortex-M0、M3、M4和M7这几种,每个内核又大概分为主流、高性能和低功耗。具体如下表所示。
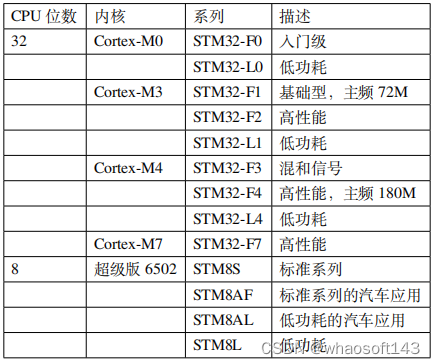
单纯从学习的角度出发,可以选择F1和F4,F1代表了基础型,基于Cortex-M3内核,主频为72MHZ,F4代表了高性能,基于Cortex-M4内核,主频180M。之于F1,F4(429系列以上)除了内核不同和主频的提升外,升级的明显特色就是带了LCD控制器和摄像头接口,支持SDRAM,这个区别在项目选型上会被优先考虑。但是从大学教学和用户初学来说,还是首选F1系列,目前在市场上资料最多,产品占有量最多的就是F1系列的STM32。
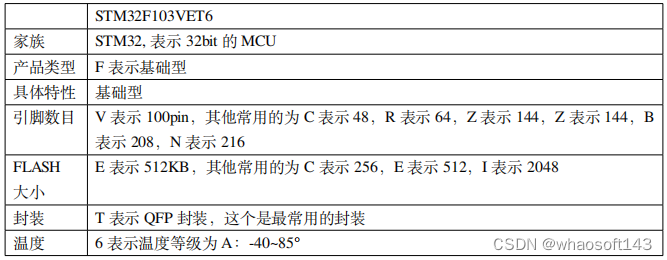
更详细的命名方法说明,见下图。
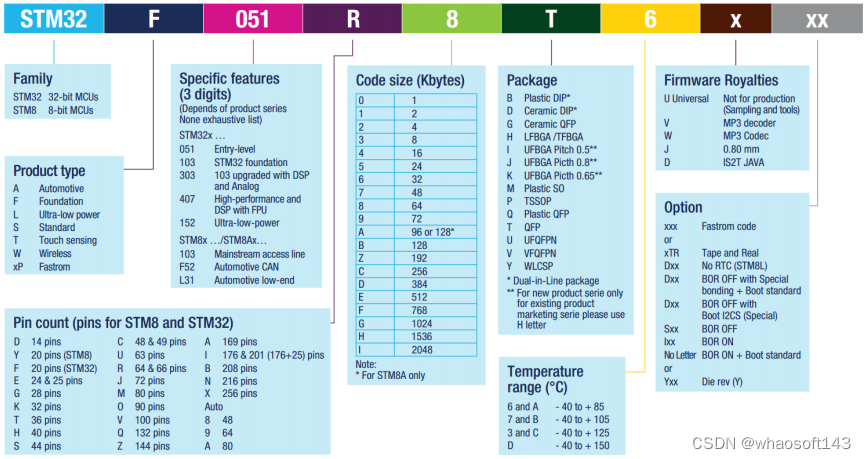
选择合适的 MCU
了解了STM32的分类和命名方法之后,就可以根据项目的具体需求先大概选择哪类内核的MCU,普通应用,不需要接大屏幕的一般选择Cortex-M3内核的F1系列,如果要追求高性能,需要大量的数据运算,且需要外接RGB大屏幕的则选择Cortex-M4内核的F429系列。明确了大方向之后,接下来就是细分选型,先确定引脚,引脚多的功能就多,价格也贵,具体得根据实际项目中需要使用到什么功能,够用就好。确定好了引脚数目之后再选择FLASH大小,相同引脚数的MCU会有不同的FLASH大小可供选择,这个也是根据实际需要选择,程序大的就选择大点的FLASH,要是产品一量产,这些省下来的都是钱啊。有些月出货量以KK(百万数量级)为单位的产品,不仅是MCU,连电阻电容能少用就少用,更甚者连PCB的过孔的多少都有讲究。项目中的元器件的选型有很多学问。
二、C语言内存泄漏问题及其检视方法
本文通过介绍内存泄漏问题原理及检视方法,希望后续能够从编码检视环节就杜绝此类问题发生。
预防内存泄漏问题有多种方法,如加强代码检视、工具检测和内存测试等,本文聚集于开发人员能力提升方面。
内存泄漏问题原理
1 堆内存在C代码中的存储方式
内存泄漏问题只有在使用堆内存的时候才会出现,栈内存不存在内存泄漏问题,因为栈内存会自动分配和释放。C语言代码中堆内存的申请函数是malloc,常见的内存申请代码如下:

由于malloc函数返回的实际上是一个内存地址,所以保存堆内存的变量一定是一个指针(除非代码编写极其不规范)。再重复一遍,保存堆内存的变量一定是一个指针,这对本文主旨的理解很重要。当然,这个指针可以是单指针,也可以是多重指针。
malloc函数有很多变种或封装,如g_malloc、g_malloc0、VOS_Malloc等,这些函数最终都会调用malloc函数。
2 堆内存的获取方法
看到本小节标题,可能有些同学有疑惑,上一小节中的malloc函数,不就是堆内存的获取方法吗?的确是,通过malloc函数申请是最直接的获取方法,如果只知道这种堆内存获取方法,就容易掉到坑里了。
一般的来讲,堆内存有如下两种获取方法:
「方法一:将函数返回值直接赋给指针,一般表现形式如下:」
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_0">char *local_pointer_xx = NULL;
local_pointer_xx = (char*)function_xx(para_xx, …);</code>- 1.
- 2.
该类涉及到内存申请的函数,返回值一般都指针类型,例如:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_1">GSList* g_slist_append (GSList *list, gpointer data)</code>- 1.
「方法二:将指针地址作为函数返回参数,通过返回参数保存堆内存地址,一般表现形式如下:」
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_2">int ret;
char *local_pointer_xx = NULL; /**转换后的字符串**/
ret = (char*)function_xx(..., &local_pointer_xx, ...);</code>- 1.
- 2.
- 3.
该类涉及到内存申请的函数,一般都有一个入参是双重指针,例如:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_3">__STDIO_INLINE _IO_ssize_t
getline (char **__lineptr, size_t *__n, FILE *__stream)</code>- 1.
- 2.
前面说通过malloc申请内存,就属于方法一的一个具体表现形式。其实这两类方法的本质是一样的,都是函数内部间接申请了内存,只是传递内存的方法不一样,方法一通过返回值传递内存指针,方法二通过参数传递内存指针。
3 内存泄漏三要素
最常见的内存泄漏问题,包含以下三个要素:
**要素一:**函数内有局部指针变量定义;
**要素二:**对该局部指针有通过上一小节中“两种堆内存获取方法”之一获取内存;
**要素三:**在函数返回前(含正常分支和异常分支)未释放该内存,也未保存到其它全局变量或返回给上一级函数。
4 内存释放误区
稍微使用过C语言编写代码的人,都应该知道堆内存申请之后是需要释放的。但为何还这么容易出现内存泄漏问题呢?一方面,是开发人员经验不足、意识不到位或一时疏忽导致;另一方面,是内存释放误区导致。很多开发人员,认为要释放的内存应该局限于以下两种:
1)直接使用内存申请函数申请出来的内存,如malloc、g_malloc等;
2)该开发人员熟悉的接口中,存在内存申请的情况,如iBMC的兄弟,都应该知道调用如下接口需要释放list指向的内存:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_4">dfl_get_object_list(const char* class_name, GSList **list)</code>- 1.
按照以上思维编写代码,一旦遇到不熟悉的接口中需要释放内存的问题,就完全没有释放内存的意识,内存泄漏问题就自然产生了。
内存泄漏问题检视方法
检视内存泄漏问题,关键还是要养成良好的编码检视习惯。与内存泄漏三要素对应,需
要做到如下三点:
(1)在函数中看到有局部指针,就要警惕内存泄漏问题,养成进一步排查的习惯
(2)分析对局部指针的赋值操作,是否属于前面所说的“两种堆内存获取方法”之一,如果是,就要分析函数返回的指针到底指向啥?是全局数据、静态数据还是堆内存?对于不熟悉的接口,要找到对应的接口文档或源代码分析;又或者看看代码中其它地方对该接口的引用,是否进行了内存释放;
(3)如果确认对局部指针存在内存申请操作,就需要分析该内存的去向,是会被保存在全局变量吗?又或者会被作为函数返回值吗?如果都不是,就需要排查函数所有有”return“的地方,保证内存被正确释放。
三、.h文件与.c文件
.h文件与.c文件的关系
参考高手的程序时,发现别人写的严格的程序都带有一个“KEY.H”,里面定义了.C文件里用到的自己写的函数,如Keyhit()、Keyscan()等。.H文件就是头文件,估计就是Head的意思吧,这是规范程序结构化设计的需要,既可以实现大型程序的模块化,又可以实现根各模块的连接调试。
.H文件介绍:
在单片机嵌入式C程序设计中,项目一般按功能模块化进行结构化设计。将一个项目划分为多个功能,每个功能的相关程序放在一个C程序文档中,称之为一个模块,对应的文件名即为模块名。一个模块通常由两个文档组成,一个为头文件*.h,对模块中的数据结构和函数原型进行描述;另一个则为C文件*.c ,对数据实例或对象定义,以及函数算法具体实现。
.H文件的作用
作为项目设计,除了对项目总体功能进行详细描述外,就是对每个模块进行详细定义,也就是给出所有模块的头文件。通常H头文件要定义模块中各函数的功能,以及输入和输出参数的要求。模块的具体实现,由项目组成根据H文件进行设计、编程、调试完成。为了保密和安全,模块实现后以可连接文件OBJ、或库文件LIB的方式提供给项目其他成员使用。由于不用提供源程序文档,一方面可以公开发行,保证开发人员的所有权;另一方面可以防止别人有意或无意修改产生非一致性,造成版本混乱。所以H头文件是项目的详细设计和团队工作划分的依据,也是对模块进行测试的功能说明。要引用模块内的数据或算法,只要用包含include指定模块H头文件即可。
.H文件的基本组成
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_5">/*如下为键盘驱动的头文档*/
#ifndef _KEY_H_ //防重复引用,如果没有定义过_KEY_H_,则编译下句
#define _KEY_H_ //此符号唯一, 表示只要引用过一次,即#i nclude,则定义符号_KEY_H_
/
char keyhit( void ); //击键否
unsigned char Keyscan( void ); //取键值
/
#endif</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
尽量使用宏定义#define
开始看别人的程序时,发现程序开头,在文件包含后面有很多#define语句,当时就想,搞这么多标示符替换来替换去的,麻不麻烦啊,完全没有理解这种写法的好处。原来,用一个标示符表示常数,有利于以后的修改和维护,修改时只要在程序开头改一下,程序中所有用到的地方就全部修改,节省时间。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_6">#define KEYNUM 65//按键数量,用于Keycode[KEYNUM]
#define LINENUM 8//键盘行数
#define ROWNUM 8//键盘列数</code>- 1.
- 2.
- 3.
注意的地方:
- 宏名一般用大写
- 宏定义不是C语句,结尾不加分号
不要乱定义变量类型
以前写程序,当需要一个新的变量时,不管函数内还是函数外的,直接在程序开头定义,虽然不是原则上的错误,但是很不可取的作法。下面说一下,C语言中变量类型的有关概念。从变量的作用范围来分,分为局部变量和全局变量:
- 全局变量:是在函数外定义的变量,全局变量在程序全部执行过程中都占用资源,全局变量过多使程序的通用性变差,因为全局变量是模块间耦合的原因之一。
- 局部变量:在函数内部定义的变量,只在函数内部有效。
从变量的变量值存在的时间分为两种:
- 静态存储变量:程序运行期间分配固定的存储空间。
- 动态存储变量:程序运行期间根据需要动态地分配存储空间。
具体又包括四种存储方式:
- auto
- static
- register
- extern
不加说明默认为auto型,即动态存储,如果不赋初值,将是一个不确定的值。而将局部变量定义为static型的话,则它的值在函数内是不变的,且初值默认为0。编译时分配为静态存储区,可以被本文件中的各个函数引用。如果是多个文件的话,如果在一个文件中引用另外文件中的变量,在此文件中要用extern说明。不过如果一个全局变量定义为static的话,就只能在此一个文件中使用。register定义寄存器变量,请求编译器将这个变量保存在CPU的寄存器中,从而加快程序的运行。
特殊关键字const volatile的使用
const
const用于声明一个只读的变量。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_7">const unsigned char a=1;//定义a=1,编译器不允许修改a的值</code>- 1.
作用:保护不希望被修改的参数。
volatile
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。精确地说就是,优化器在用到这个变量时必须每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_8">static int i=0;
int main(void)
{
...
while (1)
{
if (i)
dosomething();
}
}
/* Interrupt service routine. */
void ISR_2(void)
{
i=1;
}</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
程序的本意是希望ISR_2中断产生时,在main当中调用dosomething函数,但是,由于编译器判断在main函数里面没有修改过i,因此可能只执行一次对从i到某寄存器的读操作,然后每次if判断都只使用这个寄存器里面的“i副本”,导致dosomething永远也不会被调用。如果将将变量加上volatile修饰,则编译器保证对此变量的读写操作都不会被优化(肯定执行)。
一般说来,volatile用在如下的几个地方:
- 中断服务程序中修改的供其它程序检测的变量需要加volatile;
- 多任务环境下各任务间共享的标志应该加volatile;
- 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义。
四、嵌入式C语言知识点
C语言中的关键字
C语言中的关键字按照功能分为:
- 数据类型(常用char, short, int, long, unsigned, float, double)
- 运算和表达式( =, +, -, *, while, do-while, if, goto, switch-case)
- 数据存储(auto, static, extern,const, register,volatile,restricted),
- 结构(struct, enum, union,typedef),
- 位操作和逻辑运算(<<, >>, &, |, ~,^, &&),
- 预处理(#define, #include, #error,#if...#elif...#else...#endif等),
- 平台扩展关键字(__asm, __inline,__syscall)
这些关键字共同构成了嵌入式平台的C语言语法。嵌入式的应用从逻辑上可以抽象为三个部分:
- 数据的输入,如传感器,信号,接口输入
- 数据的处理,如协议的解码和封包,AD采样值的转换等
- 数据的输出,如GUI的显示,输出的引脚状态,DA的输出控制电压,PWM波的占空比等
对于数据的管理就贯穿着整个嵌入式应用的开发,它包含数据类型,存储空间管理,位和逻辑操作,以及数据结构,C语言从语法上支撑上述功能的实现,并提供相应的优化机制,以应对嵌入式下更受限的资源环境。
数据类型
C语言支持常用的字符型,整型,浮点型变量,有些编译器如keil还扩展支持bit(位)和sfr(寄存器)等数据类型来满足特殊的地址操作。C语言只规定了每种基本数据类型的最小取值范围,因此在不同芯片平台上相同类型可能占用不同长度的存储空间,这就需要在代码实现时考虑后续移植的兼容性,而C语言提供的typedef就是用于处理这种情况的关键字,在大部分支持跨平台的软件项目中被采用,典型的如下:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_9">typedef unsigned char uint8_t;
typedef unsigned short uint16_t;
typedef unsigned int uint32_t;
......
typedef signed int int32_t;</code>- 1.
- 2.
- 3.
- 4.
- 5.
既然不同平台的基本数据宽度不同,那么如何确定当前平台的基础数据类型如int的宽度,这就需要C语言提供的接口sizeof,实现如下。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_10">printf("int size:%d, short size:%d, char size:%d\n", sizeof(int), sizeof(char), sizeof(short));</code>- 1.
这里还有重要的知识点,就是指针的宽度,如:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_11">char *p;
printf("point p size:%d\n", sizeof(p));</code>- 1.
- 2.
其实这就和芯片的可寻址宽度有关,如32位MCU的宽度就是4,64位MCU的宽度就是8,在有些时候这也是查看MCU位宽比较简单的方式。
内存管理和存储架构
C语言允许程序变量在定义时就确定内存地址,通过作用域,以及关键字extern,static,实现了精细的处理机制,按照在硬件的区域不同,内存分配有三种方式(节选自C++高质量编程):
- 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static 变量。
- 在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中 ,效率很高,但是分配的内存容量有限。
- 从堆上分配,亦称动态内存分配。程序在运行的时候用 malloc 或 new 申请任意多少的内存,程序员自己负责在何时用 free 或 delete 释放内存。动态内存的生存期由程序员决定,使用非常灵活,但同时遇到问题也最多。
这里先看个简单的C语言实例。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_12">//main.c#include <stdio.h>#include <stdlib.h>
static int st_val; //静态全局变量 -- 静态存储区
int ex_val; //全局变量 -- 静态存储区int main(void)
{
int a = 0; //局部变量 -- 栈上申请
int *ptr = NULL; //指针变量
static int local_st_val = 0; //静态变量
local_st_val += 1;
a = local_st_val;
ptr = (int *)malloc(sizeof(int)); //从堆上申请空间
if(ptr != NULL)
{
printf("*p value:%d", *ptr);
free(ptr);
ptr = NULL;
//free后需要将ptr置空,否则会导致后续ptr的校验失效,出现野指针
}
}</code>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
C语言的作用域不仅描述了标识符的可访问的区域,其实也规定了变量的存储区域,在文件作用域的变量st_val和ex_val被分配到静态存储区,其中static关键字主要限定变量能否被其它文件访问,而代码块作用域中的变量a, ptr和local_st_val则要根据类型的不同,分配到不同的区域,其中a是局部变量,被分配到栈中,ptr作为指针,由malloc分配空间,因此定义在堆中,而local_st_val则被关键字限定,表示分配到静态存储区,这里就涉及到重要知识点,static在文件作用域和代码块作用域的意义是不同的:在文件作用域用于限定函数和变量的外部链接性(能否被其它文件访问), 在代码块作用域则用于将变量分配到静态存储区。
对于C语言,如果理解上述知识对于内存管理基本就足够,但对于嵌入式C来说,定义一个变量,它不一定在内存(SRAM)中,也有可能在FLASH空间,或直接由寄存器存储(register定义变量或者高优化等级下的部分局部变量),如定义为const的全局变量定义在FLASH中,定义为register的局部变量会被优化到直接放在通用寄存器中,在优化运行速度,或者存储受限时,理解这部分知识对于代码的维护就很有意义。此外,嵌入式C语言的编译器中会扩展内存管理机制,如支持分散加载机制和__attribute__((section("用户定义区域"))),允许指定变量存储在特殊的区域如(SDRAM, SQI FLASH), 这强化了对内存的管理,以适应复杂的应用环境场景和需求。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_13">LD_ROM 0x00800000 0x10000 { ;load region size_region
EX_ROM 0x00800000 0x10000 { ;load address = execution address
*.o (RESET, +First)
*(InRoot$$Sections)
.ANY (+RO)
}
EX_RAM 0x20000000 0xC000 { ;rw Data
.ANY (+RW +ZI)
}
EX_RAM1 0x2000C000 0x2000 {
.ANY(MySection)
}
EX_RAM2 0x40000000 0x20000{
.ANY(Sdram)
}
}
int a[10] __attribute__((section("Mysection")));
int b[100] __attribute__((section("Sdram")));</code>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
采用这种方式,我们就可以将变量指定到需要的区域,这在某些情况下是必须的,如做GUI或者网页时因为要存储大量图片和文档,内部FLASH空间可能不足,这时就可以将变量声明到外部区域,另外内存中某些部分的数据比较重要,为了避免被其它内容覆盖,可能需要单独划分SRAM区域,避免被误修改导致致命性的错误,这些经验在实际的产品开发中是常用且重要,不过因为篇幅原因,这里只简略的提供例子,如果工作中遇到这种需求,建议详细去了解下。
至于堆的使用,对于嵌入式Linux来说,使用起来和标准C语言一致,注意malloc后的检查,释放后记得置空,避免"野指针“,不过对于资源受限的单片机来说,使用malloc的场景一般较少,如果需要频繁申请内存块的场景,都会构建基于静态存储区和内存块分割的一套内存管理机制,一方面效率会更高(用固定大小的块提前分割,在使用时直接查找编号处理),另一方面对于内存块的使用可控,可以有效避免内存碎片的问题,常见的如RTOS和网络LWIP都是采用这种机制,我个人习惯也采用这种方式,所以关于堆的细节不在描述,如果希望了解,可以参考<C Primer Plus>中关于存储相关的说明。
指针和数组
数组和指针往往是引起程序bug的主要原因,如数组越界,指针越界,非法地址访问,非对齐访问,这些问题背后往往都有指针和数组的影子,因此理解和掌握指针和数组,是成为合格C语言开发者的必经之路。
数组是由相同类型元素构成,当它被声明时,编译器就根据内部元素的特性在内存中分配一段空间,另外C语言也提供多维数组,以应对特殊场景的需求,而指针则是提供使用地址的符号方法,只有指向具体的地址才有意义,C语言的指针具有最大的灵活性,在被访问前,可以指向任何地址,这大大方便了对硬件的操作,但同时也对开发者有了更高的要求。参考如下代码。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_14">int main(void)
{
char cval[] = "hello";
int i;
int ival[] = {1, 2, 3, 4};
int arr_val[][2] = {<!-- -->{1, 2}, {3, 4}};
const char *pconst = "hello";
char *p;
int *pi;
int *pa;
int **par;
p = cval;
p++; //addr增加1
pi = ival;
pi+=1; //addr增加4
pa = arr_val[0];
pa+=1; //addr增加4
par = arr_val;
par++; //addr增加8
for(i=0; i<sizeof(cval); i++)
{
printf("%d ", cval[i]);
}
printf("\n");
printf("pconst:%s\n", pconst);
printf("addr:%d, %d\n", cval, p);
printf("addr:%d, %d\n", icval, pi);
printf("addr:%d, %d\n", arr_val, pa);
printf("addr:%d, %d\n", arr_val, par);
}
/* PC端64位系统下运行结果
0x68 0x65 0x6c 0x6c 0x6f 0x0
pconst:hello
addr:6421994, 6421995
addr:6421968, 6421972
addr:6421936, 6421940
addr:6421936, 6421944 */</code>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
对于数组来说,一般从0开始获取值,以length-1作为结束,通过[0, length)半开半闭区间访问,这一般不会出问题,但是某些时候,我们需要倒着读取数组时,有可能错误的将length作为起始点,从而导致访问越界,另外在操作数组时,有时为了节省空间,将访问的下标变量i定义为unsigned char类型,而C语言中unsigned char类型的范围是0~255,如果数组较大,会导致数组超过时无法截止,从而陷入死循环,这种在最初代码构建时很容易避免,但后期如果更改需求,在加大数组后,在使用数组的其它地方都会有隐患,需要特别注意。
由于,指针占有的空间与芯片的寻址宽度有关,32位平台为4字节,64位为8字节,而指针的加减运算中的长度又与它的类型相关,如char类型为1,int类型为4,如果你仔细观察上面的代码就会发现par的值增加了8,这是因为指向指针的指针,对应的变量是指针,也就是长度就是指针类型的长度,在64位平台下为8,如果在32位平台则为4,这些知识理解起来并不困难,但是这些特性在工程运用中稍有不慎,就会埋下不易察觉的问题。另外指针还支持强制转换,这在某些情况下相当有用,参考如下代码:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_15">#include <stdio.h>
typedef struct
{
int b;
int a;
}STRUCT_VAL;
static __align(4) char arr[8] = {0x12, 0x23, 0x34, 0x45, 0x56, 0x12, 0x24, 0x53};
int main(void)
{
STRUCT_VAL *pval;
int *ptr;
pval = (STRUCT_VAL *)arr;
ptr = (int *)&arr[4];
printf("val:%d, %d", pval->a, pval->b);
printf("val:%d,", *ptr);
}
//0x45342312 0x53241256
//0x53241256</code>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
基于指针的强制转换,在协议解析,数据存储管理中高效快捷的解决了数据解析的问题,但是在处理过程中涉及的数据对齐,大小端,是常见且十分易错的问题,如上面arr字符数组,通过__align(4)强制定义为4字节对齐是必要的,这里可以保证后续转换成int指针访问时,不会触发非对齐访问异常,如果没有强制定义,char默认是1字节对齐的,当然这并不就是一定触发异常(由整个内存的布局决定arr的地址,也与实际使用的空间是否支持非对齐访问有关,如部分SDRAM使用非对齐访问时,会触发异常), 这就导致可能增减其它变量,就可能触发这种异常,而出异常的地方往往和添加的变量毫无关系,而且代码在某些平台运行正常,切换平台后触发异常,这种隐蔽的现象是嵌入式中很难查找解决的问题。另外,C语言指针还有特殊的用法就是通过强制转换给特定的物理地址访问,通过函数指针实现回调,如下:
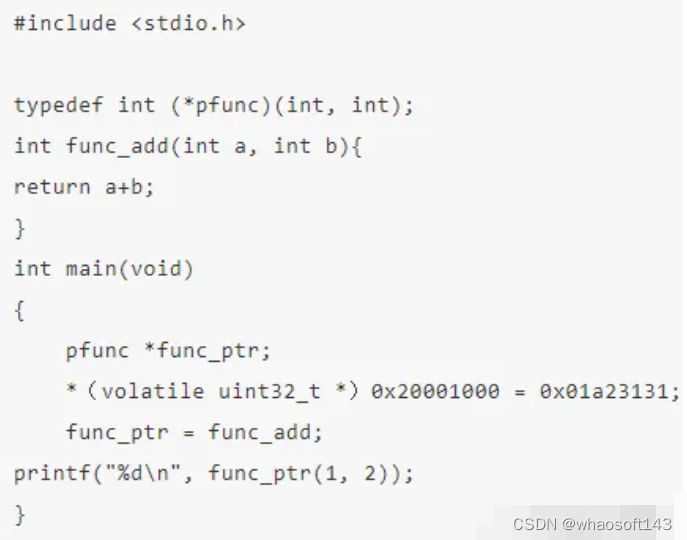
这里说明下,volatile易变的,可变的,一般用于以下几种状况:
- 并行设备的硬件寄存器,如:状态寄存器)
- 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
- 多线程应用中被几个任务共享的变量
volatile可以解决用户模式和异常中断访问同一个变量时,出现的不同步问题,另外在访问硬件地址时,volatile也阻止对地址访问的优化,从而确保访问的实际的地址,精通volatile的运用,在嵌入式底层中十分重要,也是嵌入式C从业者的基本要求之一。函数指针在一般嵌入式软件的开发中并不常见,但对许多重要的实现如异步回调,驱动模块,使用函数指针就可以利用简单的方式实现很多应用,当然我这里只能说是抛砖引玉,许多细节知识是值得详细去了解掌握的。
结构类型和对齐
C语言提供自定义数据类型来描述一类具有相同特征点的事务,主要支持的有结构体,枚举和联合体。其中枚举通过别名限制数据的访问,可以让数据更直观,易读,实现如下:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_16">typedef enum {spring=1, summer, autumn, winter }season;
season s1 = summer;</code>- 1.
- 2.
联合体的是能在同一个存储空间里存储不同类型数据的数据类型,对于联合体的占用空间,则是以其中占用空间最大的变量为准,如下:

联合体的用途主要通过共享内存地址的方式,实现对数据内部段的访问,这在解析某些变量时,提供了更为简便的方式,此外测试芯片的大小端模式也是联合体的常见应用,当然利用指针强制转换,也能实现该目的,实现如下:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_17">int data = 0x12345678;
short *pdata = (short *)&data;
if(*pdata = 0x5678)
printf("%s\n", "小端模式");
else
printf("%s\n", "大端模式");</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
可以看出使用联合体在某些情况下可以避免对指针的滥用。结构体则是将具有共通特征的变量组成的集合,比起C++的类来说,它没有安全访问的限制,不支持直接内部带函数,但通过自定义数据类型,函数指针,仍然能够实现很多类似于类的操作,对于大部分嵌入式项目来说,结构化处理数据对于优化整体架构以及后期维护大有便利。
C语言的结构体支持指针和变量的方式访问,通过转换可以解析任意内存的数据,如我们之前提到的通过指针强制转换解析协议。另外通过将数据和函数指针打包,在通过指针传递,是实现驱动层实接口切换的重要基础,有着重要的实践意义,另外基于位域,联合体,结构体,可以实现另一种位操作,这对于封装底层硬件寄存器具有重要意义。通过联合体和位域操作,可以实现对数据内bit的访问,这在寄存器以及内存受限的平台,提供了简便且直观的处理方式,另外对于结构体的另一个重要知识点就是对齐了,通过对齐访问,可以大幅度提高运行效率,但是因为对齐引入的存储长度问题,也是容易出错的问题,对于对齐的理解,可以分类为如下说明。
- 基础数据类型:以默认的的长度对齐,如char以1字节对齐,short以2字节对齐等
- 数组 :按照基本数据类型对齐,第一个对齐了后面的自然也就对齐了。
- 联合体 :按其包含的长度最大的数据类型对齐。
- 结构体:结构体中每个数据类型都要对齐,结构体本身以内部最大数据类型长度对齐
其中union联合体的大小与内部最大的变量int一致,为4字节,根据读取的值,就知道实际内存布局和填充的位置是一致,事实上学会通过填充来理解C语言的对齐机制,是有效且快捷的方式。
预处理机制
C语言提供了丰富的预处理机制,方便了跨平台的代码的实现,此外C语言通过宏机制实现的数据和代码块替换,字符串格式化,代码段切换,对于工程应用具有重要意义,下面按照功能需求,描述在C语言运用中的常用预处理机制。
#include 包含文件命令,在C语言中,它执行的效果是将包含文件中的所有内容插入到当前位置,这不只包含头文件,一些参数文件,配置文件,也可以使用该文件插入到当前代码的指定位置。其中<>和""分别表示从标准库路径还是用户自定义路径开始检索。
#define宏定义,常见的用法包含定义常量或者代码段别名,当然某些情况下配合##格式化字符串,可以实现接口的统一化处理,实例如下:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_18">#define MAX_SIZE 10
#define MODULE_ON 1
#define ERROR_LOOP() do{\
printf("error loop\n");\
}while(0);
#define global(val) g_##val
int global(v) = 10;
int global(add)(int a, int b)
{
return a+b;
}</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
#if..#elif...#else...#endif, #ifdef..#endif, #ifndef...#endif条件选择判断,条件选择主要用于切换代码块,这种综合性项目和跨平台项目中为了满足多种情况下的需求往往会被使用。
#undef 取消定义的参数,避免重定义问题。
#error,#warning用于用户自定义的告警信息,配合#if,#ifdef使用,可以限制错误的预定义配置。
#pragma 带参数的预定义处理,常见的#pragma pack(1), 不过使用后会导致后续的整个文件都以设置的字节对齐,配合push和pop可以解决这种问题,代码如下:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_19">#pragma pack(push)
#pragma pack(1)
struct TestA
{
char i;
int b;
}A;
#pragma pack(pop); //注意要调用pop,否则会导致后续文件都以pack定义值对齐,执行不符合预期
//等同于
struct _TestB{
char i;
int b;
}__attribute__((packed))A;</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
总结
嵌入式C语言在处理硬件物理地址、位操作、内存访问方面都给予开发者了充分的自由。通过数组,指针以及强制转换的技巧,可以有效减少数据处理中的复制过程,这对于底层是必要的,也方便了整个架构的开发。对于任何嵌入式C语言开发的从业者,清晰的掌握这些基础的知识是必要的。
五、嵌入式C语言知识点2
1 位操作
位操作与位带操作并不相同,位操作就是对一个变量的每一位做运算,而逻辑位操作是对这个变量整体进行运算。
下面是六种常用的操作运算符:
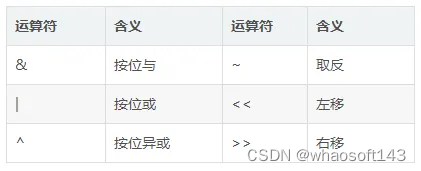
按位取反
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_20">void test01()
{
int num = 7;
printf("~num = %d\n", ~num);//-8
// 0111 按位取反 1000 机器中存放的都是补码
//补码转换原码需要分有符号数和无符号数两种
}</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
按位与
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_21">void test02()
{
int num = 128;
//换算为八位,1换算就是00000001, 这样只要所给数字的二进制最后一位是1.那么就是奇数,否则就是偶数
if ( (num & 1) == 0)
{
printf("num为偶数\n");
}
else
{
printf("num为奇数\n");
}
}</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
按位异或
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_22">void test03()
{
//按位异或的意思是,两个数字相同为0,不同为1。我们可以利用按位异或实现两个数的交换
num01 = 1; // 0001
num02 = 4; // 0100
printf("num01 ^ num02 = %d", num01 ^ num02); // 5 两个二进制按位异或之后是: 0101
printf("交换前\n");
printf("num01 = %d\n", num1);
printf("num02 = %d\n", num2);
num01 = num01 ^ num02;
num02 = num01 ^ num02;
num01 = num01 ^ num02;
//不用临时数字实现两个变量交换
printf("交换后\n");
printf("num01 = %d\n", num1);
printf("num02 = %d\n", num2);
}</code>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
按位或
计算方法:
参加运算的两个数,换算为二进制(0、1)后,进行与运算。只有当 相应位上全部为1时取1, 存在0时为0。
printf是格式化输出函数,它可以直接打印十进制,八进制,十六进制,输出控制符分别为%d, %o, %x, 但是它不存在二进制,如果输出二进制,可以手写,但是也可以调用stdlib.h里面的itoa函数,他不是标准库里面的函数,但是大多数编译器里面都有这个函数。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_23">#include <stdio.h>
#include <stdlib.h>
int main()
{
test04();
}
int test04()
{
int a = 6; //二进制0110
int b = 3; //二进制0011
int c = a | b; //a、b按位或,结果8,二进制111,赋值给c
char s[10];
itoa(c, s, 2);
printf("二进制 --> %s\n", s);//输出:二进制 -->111
}</code>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
左移运算符
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_24">void test05()
{
int num = 6;
printf("%d\n", num << 3);//左移三位,就是0000
}</code>- 1.
- 2.
- 3.
- 4.
- 5.
右移运算符
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_25">void test06()
{
int num = 6; //0110
printf("%d\n", num >> 1); //右移一位,就是0011,输出3
}</code>- 1.
- 2.
- 3.
- 4.
- 5.
上面是用普通c代码举得栗子,下面我们看一下STM32中操作通常用的代码:
(1)比如我要改变 GPIOA-> BSRRL 的状态,可以先对寄存器的值进行& 清零操作
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_26">GPIOA-> BSRRL &= 0xFF0F; //将第4位到第7位清零(注意编号是从0开始的)</code>- 1.
然后再与需要设置的值进行|或运算:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_27">GPIOA-> BSRRL |= 0x0040; //将第4位到第7位设置为我们需要的数字</code>- 1.
(2)通过位移操作提高代码的可读性:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_28">GPIOx->ODR = (((uint32_t)0x01) << pinpos);</code>- 1.
上面这行代码的意思就是,先将"0x01"这个八位十六进制转换为三十二位二进制,然后左移"pinpos"位,这个"pinpos"就是一个变量,其值就是要移动的位数。也就是将ODR寄存器的第pinpos位设置为1。
(3)取反操作使用:
SR寄存器的每一位代表一个状态,如果某个时刻我们想设置一个位的值为0,与此同时,其它位置都为1,简单的作法是直接给寄存器设置一个值:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_29">TIMx->SR=0xFFF7;</code>- 1.
这样的作法设置第 3 位为 0,但是这样的作法可读性较差。看看库函数代码中怎样使用的:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_30">TIMx->SR = (uint16_t)~TIM_FLAG;</code>- 1.
而 TIM_FLAG 是通过宏定义定义的值:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_31">#define TIM_FLAG_Update ((uint16_t)0x0001)
#define TIM_FLAG_CC1 ((uint16_t)0x0002)</code>- 1.
- 2.
2 define宏定义
define 是 C 语言中的预处理命令,它用于宏定义,可以提高源代码的可读性,为编程提供 方便。
常见的格式:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_32">#define 标识符 字符串</code>- 1.
标识符意思是所定义的宏名,字符串可以是常数、表达式或者格式串等,例如:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_33">#define PLL_Q 7 //注意,这个定义语句的最后不需要加分号</code>- 1.
3 ifdef条件编译
在程序开发的过程中,经常会用到这种条件编译:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_34">#ifdef PLL_Q
程序段1
#else
程序段2
#endif</code>- 1.
- 2.
- 3.
- 4.
- 5.
上面这段代码作用就是当这个标识符已经被定义过,那么就进行程序程序段1,如果没有则进行程序段2。当然,和我们设计普通的c代码是一样的,"#else"也可以没有,就是上面的代码减去"#else"和程序段2。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_35">#ifndef PLL_Q //意思就是如果没有定义这个标识符</code>- 1.
4 extern变量申明
C 语言中 extern 可以置于变量或者函数前,以表示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义(一个变量只能定义一次,而extern可以申明很多次)使用例子如下:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_36">extern u16 USART_RX_STA;</code>- 1.
上面例子意思就是申明 “USART_RX_STA” 这个变量在其他文件中已经定义了,"u16"的意思是16位的。
5 结构体
定义一个结构体的一般形式为:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_37">struct 结构名
{
成员列表
};</code>- 1.
- 2.
- 3.
- 4.
成员列表由若干个成员组成,每个成员都是该结构体的一个组成部分。对每个成员也必须作类型说明,其形式:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_38">类型说明符 成员名;//比如:int num;</code>- 1.
结合上面的说明,我们可以构建一个简单的结构体例子:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_39">struct sutdent
{
int num;
char name[20]; //20个字节长的字符
char sex;
int age;
float score;
char addr[30]; //30个字节长的字符
}</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
而如果我们想定义结构体变量,那么我们在定义这个结构体的时候直接定义,或者定义完结构体再另外定义结构体变量,比如:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_40">struct sutdent
{
int num;
char name[20]; //20个字节长的字符
char sex;
int age;
float score;
char addr[30]; //30个字节长的字符
}student01,student02; //变量名表列(如果由结构体变量名,那么我们可以不写结构体名称)</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
有时候我们可能需要用到结构体的嵌套,比如:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_41">struct date
{
int year, month,day;
};
struct sutdent
{
int num;
char name[20]; //20个字节长的字符
char sex;
struct date birthday; //这里就用到了结构体的嵌套
int age;
float score;
char addr[30]; //30个字节长的字符
}student01,student02; //变量名表列(如果由结构体变量名,那么我们可以不写结构体名称)</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
如果需要引用结构体里面的成员内容,可以使用下面的方式:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_42">student01.name = 小李;
// 结构体变量名.成员名(注意这里用的是点),这里是对这个成员的赋值</code>- 1.
- 2.
结构指针变量说明的一般形式为:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_43">struct 结构名 *结构指针变量名</code>- 1.
假如说我们想定义一个指向结构体"student"的指针变量pstu,那么我们可以使用如下代码:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_44">struct student *pstu;</code>- 1.
如果我们要给一个结构体指针变量赋初值,那么我们可以使用如下的方式:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_45">struct student
{
char name[66];
int num;
char sex;
}stu;
pstu = &stu;</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
注意上边的赋值方式,我们如果要进行赋值,那必须使用结构体变量,而不能使用结构体名,像下边这样就是错误的。
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_46">struct student
{
char name[66];
int num;
char sex;
}stu;
pstu = &student;</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
这是因为结构名和结构体变量是两个不同的概念,结构名只能表示一个结构形式,编译系统并不会给它分配内存空间(就是说不会给它分配地址),而结构体变量作为一个变量,编译系统会给它分配一个内存空间来存储。
访问结构体成员的一般形式:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_47">(*pstu).name; //(1)(*结构指针变量).成员名;
pstu->name; //(2)结构指针变量->成员名</code>- 1.
- 2.
结构体的知识就简单说上边这些。
6 typedef类型别名
typedef用来为现有类型创建一个新的名字,或者称为类型别名,用来简化变量的定义(上边extern变量申明的例子中,"u16"就是对"uint16_t"类型名称的简化)。typedef在MDK中用得最多的就是定义结构体的类型别名和枚举类型。
我们定义一个结构体GPIO:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_48">struct _GPIO
{
_IO uint32_t MODER;
_IO uint32_tOTYPER;
...
};</code>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
定义这样一个结构体以后,如果我们想定义一个结构体变量比如"GPIOA",那么我们需要使用这样的代码:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_49">struct _GPIO GPIOA;</code>- 1.
虽然也可以达到我们的目的,但是这样会比较麻烦,而且在MDK中会有很多地方用到,所以,我们可以使用"typedef"为其定义一个别名,这样直接通过这个别名就可以定义结构体变量,来达到我们的目的:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_50">typedef struct
{
_IO uint32_t MODER;
_IO uint32_t OTYPER;
}GPIO_typedef;</code>- 1.
- 2.
- 3.
- 4.
- 5.
这样定义完成之后,如果我们需要定义结构体变量,那么我们只需要这样:
登录后复制
<code class="language-plain has-numbering hljs" id="code_id_51">GPIO_typedef _GPIOA,_GPIOB;</code>