🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/literature?__c=1000,移动端可微信小程序搜索“历代文学”)总架构师,
15年工作经验,精通Java编程,高并发设计,Springboot和微服务,熟悉Linux,ESXI虚拟化以及云原生Docker和K8s,热衷于探索科技的边界,并将理论知识转化为实际应用。保持对新技术的好奇心,乐于分享所学,希望通过我的实践经历和见解,启发他人的创新思维。在这里,我希望能与志同道合的朋友交流探讨,共同进步,一起在技术的世界里不断学习成长。
技术合作请加本人wx(注明来自csdn):foreast_sea


归并排序:数据排序的高效之道
一、引言
在当今数字化时代,数据处理的规模和复杂性呈指数级增长。无论是处理海量的商业数据、科学研究中的实验数据,还是日常应用程序中的用户信息,排序算法都扮演着至关重要的角色。排序能够将无序的数据转换为有序的序列,从而使得数据的查找、分析和处理变得更加高效和便捷。
归并排序作为一种经典且高效的排序算法,在众多领域都有着广泛的应用。它基于“分治”这一强大的思想策略,通过将大规模的问题逐步分解为更小的子问题,然后分别解决这些子问题,最后将子问题的解合并起来得到原问题的解。这种思想不仅在排序算法中大放异彩,在许多其他复杂的算法设计场景中也被频繁借鉴。
想象一下,在一个大型电商平台的订单处理系统中,每天都有海量的订单数据需要按照订单时间、金额或者客户优先级等进行排序。归并排序能够快速而稳定地对这些数据进行整理,使得商家可以清晰地了解订单的顺序,从而更好地安排发货、库存管理等后续工作。又比如在基因测序领域,大量的基因片段数据需要按照特定的顺序进行排列组合,归并排序可以高效地完成这一任务,为后续的基因分析和疾病研究提供有力支持。
在本文,我们将深入探讨归并排序的原理、详细剖析其代码实现,并全面分析它的时间复杂度、空间复杂度以及其他特性,还会将其与其他常见的排序算法进行对比,从而让您全方位地了解归并排序这一重要的数据处理工具。
二、归并排序的原理
(一)分治思想的核心
归并排序的核心在于“分治”。它将一个未排序的数组不断地分割成更小的子数组,直到每个子数组只包含一个元素。这就像是把一个大任务逐步拆解成一个个极小的、易于处理的子任务。例如,对于一个包含 8 个元素的数组 [5, 3, 8, 2, 9, 1, 7, 4],首先会被分割成两个子数组 [5, 3, 8, 2] 和 [9, 1, 7, 4],然后这两个子数组又会继续被分割,[5, 3, 8, 2] 会变成 [5, 3] 和 [8, 2],[9, 1, 7, 4] 会变成 [9, 1] 和 [7, 4],如此继续,直到每个子数组都只有一个元素,如 [5]、[3]、[8]、[2]、[9]、[1]、[7]、[4]。
(二)合并的巧妙过程
当子数组都分割到最小单位后,就开始了合并的过程。合并是归并排序的关键步骤,它将两个已经排序的子数组合并成一个更大的排序数组。比如有两个已排序的子数组 [2, 5] 和 [3, 8],我们创建一个新的空数组来存储合并后的结果。首先比较两个子数组的第一个元素,即 2 和 3,因为 2 较小,所以将 2 放入新数组,然后 [2, 5] 子数组的指针后移一位。接着比较 5 和 3,3 较小,将 3 放入新数组,[3, 8] 子数组指针后移。再比较 5 和 8,5 较小,放入新数组,此时 [2, 5] 子数组的元素已全部处理完,直接将 [3, 8] 子数组剩余的 8 放入新数组,最终得到合并后的排序数组 [2, 3, 5, 8]。
(三)归并排序算法
归并排序根据 “分而治之” 原则运行:
首先,我们将要排序的元素分为两半。然后,将生成的子数组再次划分 - 直到创建长度为 1 的子数组:
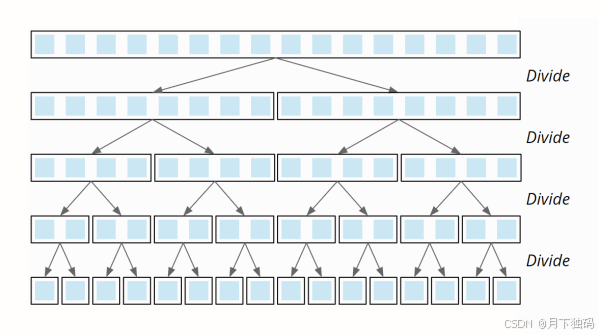
现在,两个子数组已合并,以便从每对子数组创建一个排序数组。在最后一步中,合并原始数组的两半,以便对整个数组进行排序。
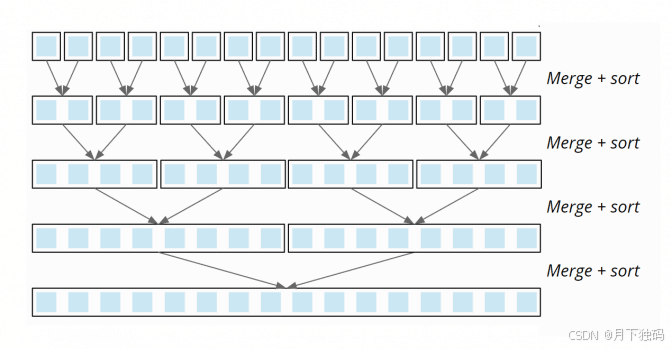
在下面的示例中,您将看到两个子数组如何合并为一个。
合并排序 合并示例
合并本身很简单:对于这两个数组,我们定义一个合并索引,它首先指向相应数组的第一个元素。显示这一点的最简单方法是使用示例(箭头表示合并索引):
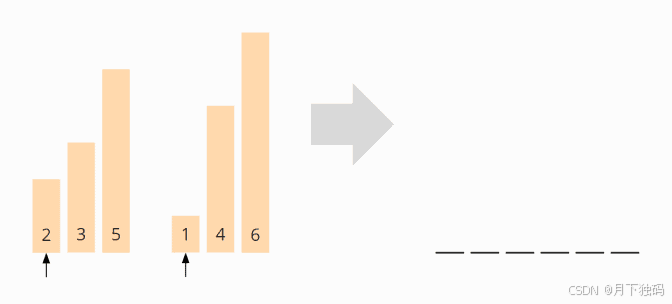
将比较合并指针上的元素。两个中较小的一个(示例中的 1)被附加到一个新数组中,并且指向该元素的指针向右移动了一个字段:
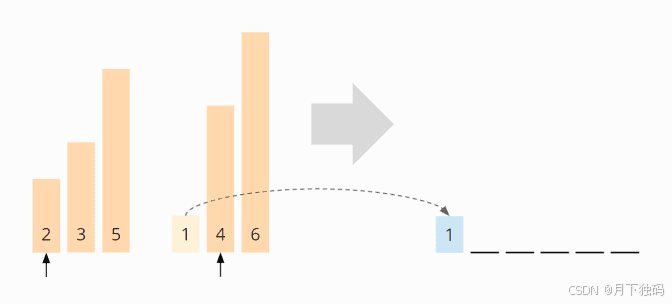
现在,将再次比较指针上方的元素。这次 2 小于 4,因此我们将 2 附加到新数组中:
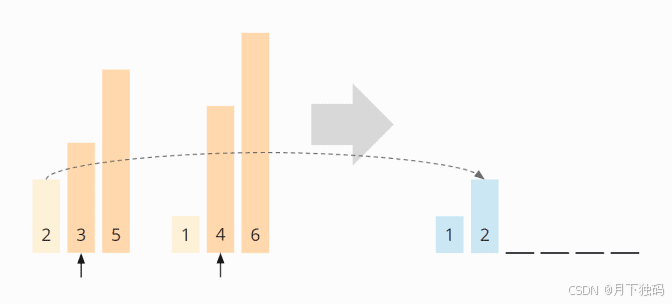
现在指针位于 3 和 4 上。3 更小,并附加到目标数组中:
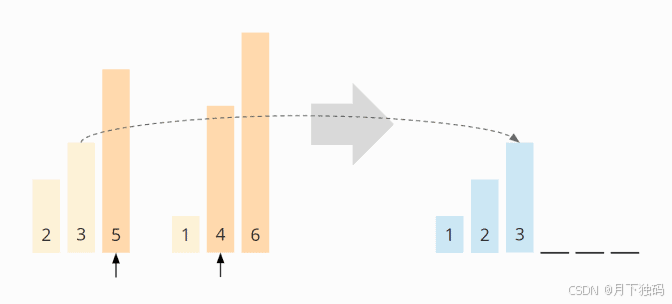
现在 4 是最小的元素:
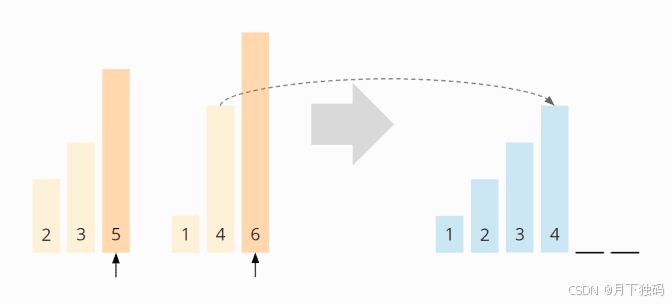
现在是 5:
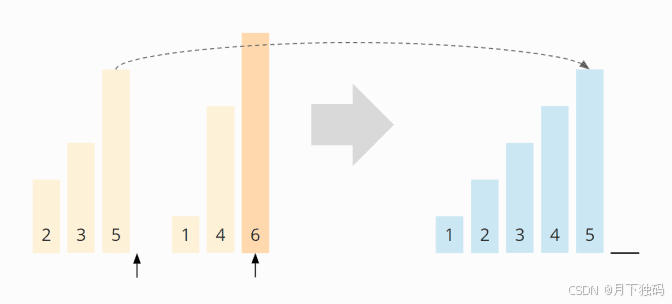
在最后一步中,将 6 附加到新数组中:

两个排序的子数组被合并到排序的最终数组中。
三、归并排序的作用
(一)数据有序化的利器
归并排序的最主要作用就是将无序的数据转换为有序的数据。在很多数据处理场景中,有序的数据能够极大地提高数据查询和处理的效率。例如在数据库查询中,如果数据是按照特定的字段(如主键、索引字段)进行排序的,那么在进行范围查询、等值查询时,数据库引擎可以利用排序的特性快速定位到目标数据,减少查询的时间复杂度。
(二)为其他算法提供基础
归并排序得到的有序数据还可以作为其他更复杂算法的基础。比如在一些搜索算法中,有序的数据可以使用二分搜索等高效的搜索策略。在图像处理领域,对图像像素数据进行排序后,可以更方便地进行图像的边缘检测、特征提取等操作,因为有序的数据结构能够让算法更有规律地处理图像中的信息。
四、归并排序的使用场景
(一)大规模数据处理
在处理大规模数据时,归并排序的优势尤为明显。由于其时间复杂度为 O ( n log n ) O(n\log n) O(nlogn),即使数据量非常庞大,它也能够在相对合理的时间内完成排序任务。例如在大数据分析平台中,需要对海量的用户行为数据、日志数据等进行排序以便进行后续的分析挖掘,归并排序可以有效地处理这些数据,为数据分析提供有序的数据基础。
(二)稳定性要求高的场景
归并排序是一种稳定的排序算法,这意味着在排序过程中,相等元素的相对顺序不会改变。在一些对数据顺序稳定性有严格要求的场景中,归并排序是首选。比如在金融交易系统中,对于同一时间发生的多笔交易,如果按照交易金额进行排序,并且要求相同金额的交易按照交易时间的先后顺序排列,归并排序就能够很好地满足这一需求,确保交易数据的排序既按照金额有序,又不会打乱相同金额交易的时间顺序。
五、归并排序的代码实现
(一)Java 代码示例
以下是归并排序的 Java 代码实现:
public class MergeSort {
// 归并排序的入口方法,接收一个数组作为参数
public static void mergeSort(int[] arr) {
// 调用递归的归并排序方法,传入数组、起始索引 0 和结束索引数组长度 - 1
mergeSort(arr, 0, arr.length - 1);
}
// 递归的归并排序方法,用于对指定范围内的数组进行排序
private static void mergeSort(int[] arr, int left, int right) {
// 如果左索引小于右索引,说明子数组中至少有两个元素,需要继续分割
if (left < right) {
// 计算中间索引,用于将数组分割成两部分
int mid = (left + right) / 2;
// 对左半部分子数组进行递归排序
mergeSort(arr, left, mid);
// 对右半部分子数组进行递归排序
mergeSort(arr, mid + 1, right);
// 合并两个已排序的子数组
merge(arr, left, mid, right);
}
}
// 合并两个已排序子数组的方法
private static void merge(int[] arr, int left, int mid, int right) {
// 计算左子数组的长度
int leftLen = mid - left + 1;
// 计算右子数组的长度
int rightLen = right - mid;
// 创建临时数组来存储左子数组和右子数组的元素
int[] leftArr = new int[leftLen];
int[] rightArr = new int[rightLen];
// 将原数组中的左子数组元素复制到临时左子数组
for (int i = 0; i < leftLen; i++) {
leftArr[i] = arr[left + i];
}
// 将原数组中的右子数组元素复制到临时右子数组
for (int j = 0; j < rightLen; j++) {
rightArr[j] = arr[mid + 1 + j];
}
// 初始化合并索引,分别指向左子数组和右子数组的起始位置
int leftPos = 0;
int rightPos = 0;
// 初始化合并后的数组索引,指向合并后数组的起始位置
int mergeIndex = left;
// 比较左子数组和右子数组的元素,将较小的元素放入原数组
while (leftPos < leftLen && rightPos < rightLen) {
if (leftArr[leftPos] <= rightArr[rightPos]) {
arr[mergeIndex] = leftArr[leftPos];
leftPos++;
} else {
arr[mergeIndex] = rightArr[rightPos];
rightPos++;
}
mergeIndex++;
}
// 如果左子数组还有剩余元素,将其全部放入原数组
while (leftPos < leftLen) {
arr[mergeIndex] = leftArr[leftPos];
leftPos++;
mergeIndex++;
}
// 如果右子数组还有剩余元素,将其全部放入原数组
while (rightPos < rightLen) {
arr[mergeIndex] = rightArr[rightPos];
rightPos++;
mergeIndex++;
}
}
}
在上述代码中:
mergeSort方法是对外公开的入口方法,它接收一个数组并调用递归的mergeSort方法开始排序过程,传入数组的起始索引 0 和结束索引arr.length - 1。- 递归的
mergeSort方法首先检查子数组是否至少有两个元素,如果是,则计算中间索引mid,将数组分割成左右两部分,然后分别对左右子数组进行递归排序,最后调用merge方法合并两个已排序的子数组。 merge方法首先创建两个临时数组来存储左右子数组的元素,然后通过循环比较两个临时数组中的元素,将较小的元素放入原数组中对应的位置,当其中一个临时数组的元素全部处理完后,将另一个临时数组剩余的元素全部放入原数组。
(二)Python 代码示例
def merge_sort(arr):
# 如果数组长度大于 1,则进行排序
if len(arr) > 1:
# 计算中间索引
mid = len(arr) // 2
# 分割左子数组
left_half = arr[:mid]
# 分割右子数组
right_half = arr[mid:]
# 递归地对左子数组进行归并排序
merge_sort(left_half)
# 递归地对右子数组进行归并排序
merge_sort(right_half)
# 初始化索引,分别用于左子数组、右子数组和合并后的数组
i = j = k = 0
# 比较左子数组和右子数组的元素,将较小的元素放入原数组
while i < len(left_half) and j < len(right_half):
if left_half[i] <= right_half[j]:
arr[k] = left_half[i]
i += 1
else:
arr[k] = right_half[j]
j += 1
k += 1
# 如果左子数组还有剩余元素,将其全部放入原数组
while i < len(left_half):
arr[k] = left_half[i]
i += 1
k += 1
# 如果右子数组还有剩余元素,将其全部放入原数组
while j < len(right_half):
arr[k] = right_half[j]
j += 1
k += 1
# 测试归并排序
arr = [5, 3, 8, 2, 9, 1, 7, 4]
merge_sort(arr)
print(arr)
在 Python 代码中:
- 首先判断数组长度是否大于 1,如果是则计算中间索引
mid,将数组分割成左右两半。 - 然后分别递归地对左右子数组进行归并排序。
- 接着通过循环比较左右子数组的元素,将较小的元素放入原数组
arr中,使用三个索引i、j、k分别跟踪左子数组、右子数组和合并后数组的位置。 - 最后处理左右子数组剩余元素的情况,将它们依次放入原数组。
六、归并排序的时间复杂度分析
(一)分割过程的时间消耗
在归并排序中,分割过程是不断地将数组一分为二。对于一个包含 n n n 个元素的数组,每次分割都将问题规模减半。设分割的次数为 k k k,则有 n = 2 k n = 2^k n=2k,通过对数运算可得 k = log 2 n k=\log_2 n k=log2n。每次分割的操作时间复杂度相对较低,可以看作是常数时间,所以分割过程总的时间复杂度为 O ( log n ) O(\log n) O(logn)。
(二)合并过程的时间消耗
合并过程是将两个已排序的子数组合并成一个更大的排序数组。在合并时,对于长度为 n n n 的数组,需要遍历每个元素一次,所以合并过程的时间复杂度为 O ( n ) O(n) O(n)。
(三)总体时间复杂度
由于归并排序的分割过程时间复杂度为 O ( log n ) O(\log n) O(logn),合并过程时间复杂度为 O ( n ) O(n) O(n),并且在每一层的分割后都需要进行合并操作,所以总的时间复杂度为 O ( n log n ) O(n\log n) O(nlogn)。这意味着无论输入数组是有序、逆序还是随机排列,归并排序的时间复杂度都保持在 O ( n log n ) O(n\log n) O(nlogn) 这一相对高效的水平。
七、归并排序的空间复杂度分析
(一)临时数组的空间需求
在归并排序的合并过程中,需要创建临时数组来存储左右子数组的元素。在最坏的情况下,当对一个包含 n n n 个元素的数组进行排序时,临时数组的大小可能达到 n n n 个元素的规模。例如,在最后一次合并时,左右子数组的长度之和可能接近 n n n。
(二)总体空间复杂度
因此,归并排序的空间复杂度为 O ( n ) O(n) O(n),这是因为在排序过程中需要额外的空间来存储临时数组中的元素。与一些原地排序算法(如冒泡排序、插入排序在某些优化情况下)相比,归并排序需要更多的额外空间,但它换来的是更高效的时间复杂度。
八、归并排序的其他特性
(一)稳定性
归并排序是一种稳定的排序算法。在合并过程中,当左右子数组的元素相等时,先将左子数组的元素放入合并后的数组。这就保证了相等元素在排序前后的相对顺序不会改变。例如,对于数组 [(3, 'a'), (3, 'b'), (5, 'c')],按照元素的第一个值进行排序时,归并排序会确保 (3, 'a') 在 (3, 'b') 之前,即使它们的第一个值相等。
(二)并行性
归并排序具有一定的并行性潜力。由于其分治的特性,可以将不同的子数组分割任务分配给不同的处理器核心或者线程来并行处理。例如,在对一个非常大的数组进行排序时,可以将数组分割成多个子数组,然后让多个线程同时对这些子数组进行归并排序,最后再将各个线程排序好的子数组合并起来。不过,在实际实现并行归并排序时,需要考虑线程同步、负载均衡等问题,以确保并行计算的效率。
九、归并排序与其他排序算法的对比
(一)与冒泡排序对比
冒泡排序是一种简单的比较排序算法,它的时间复杂度在最坏情况下为 O ( n 2 ) O(n^2) O(n2),平均情况下也为 O ( n 2 ) O(n^2) O(n2)。而归并排序的时间复杂度为 O ( n log n ) O(n\log n) O(nlogn),在大规模数据排序时,归并排序的效率远远高于冒泡排序。例如,当对 10000 个元素进行排序时,冒泡排序可能需要进行大量的元素比较和交换操作,时间消耗巨大,而归并排序则能够在相对较短的时间内完成排序任务。
(二)与插入排序对比
插入排序在最好情况下(数组已经部分有序)时间复杂度为 O ( n ) O(n) O(n),但在最坏和平均情况下时间复杂度为 O ( n 2 ) O(n^2) O(n2)。归并排序在任何情况下都保持 O ( n log n ) O(n\log n) O(nlogn) 的时间复杂度。而且插入排序是一种原地排序算法,空间复杂度为 O ( 1 ) O(1) O(1),而归并排序空间复杂度为 O ( n ) O(n) O(n)。在数据量较小且数组可能已经部分有序的情况下,插入排序可能表现较好,但对于大规模数据,归并排序更具优势。
(三)与快速排序对比
快速排序在平均情况下时间复杂度为 O ( n log n ) O(n\log n) O(nlogn),并且它是一种原地排序算法,空间复杂度在平均情况下为 O ( log n ) O(\log n) O(logn)。然而,快速排序在最坏情况下时间复杂度会退化为 O ( n 2 ) O(n^2) O(n2),例如当数组已经有序或者逆序时。而归并排序始终保持 O ( n log n ) O(n\log n) O(nlogn) 的时间复杂度,并且是稳定的。在数据随机分布且对稳定性要求不高的情况下,快速排序可能因为其原地特性和较好的平均性能而更常用,但在稳定性要求高或者数据可能出现最坏情况的场景下,归并排序则是更好的选择。
十、总结
归并排序作为一种经典的排序算法,以其高效的时间复杂度 O ( n log n ) O(n\log n) O(nlogn)、稳定的排序特性以及分治的巧妙思想,在数据处理领域占据着重要的地位。