2.2.3 结果汇总
2.2.4 Cross Validation 的参数
2.2.5 Cross Validation 的流程
2.2.6 示例
2.2.7 总结
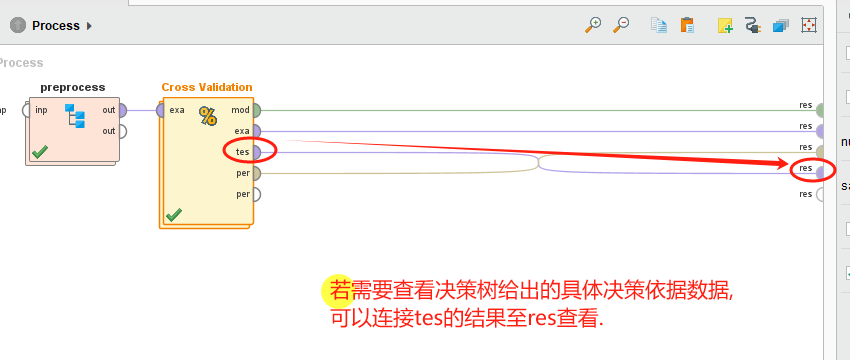
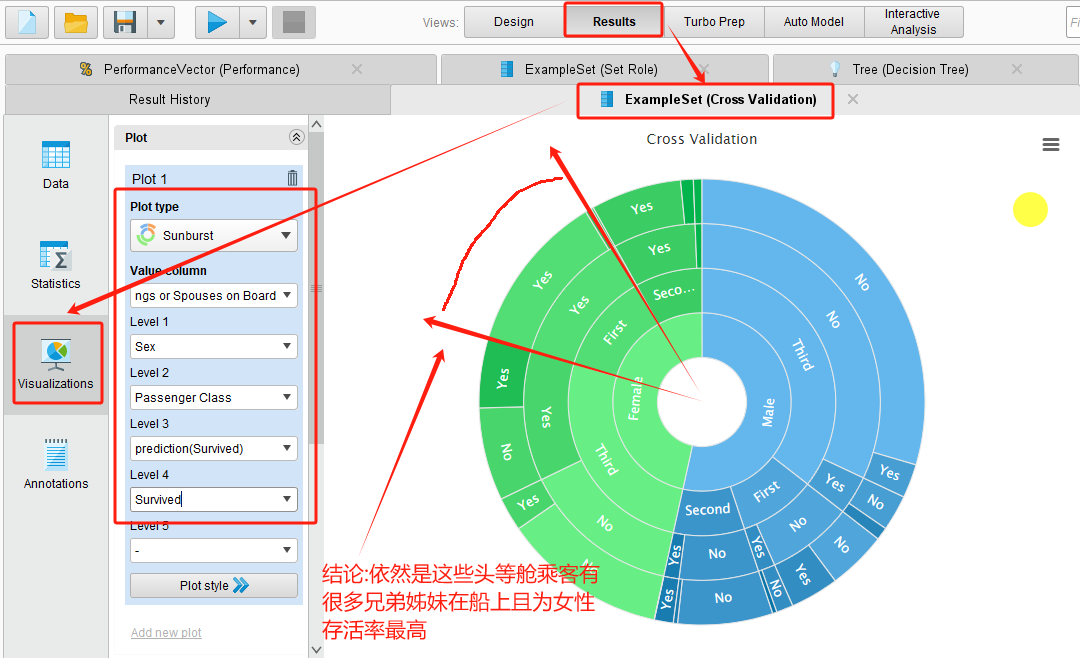
5 决策依据
一、前提
请确保已有第⑥小节中所完成的模型,没有可以点击数据分析系列--⑥RapidMiner构建决策树(泰坦尼克号案例含数据)
链接学习.
二、模型评估
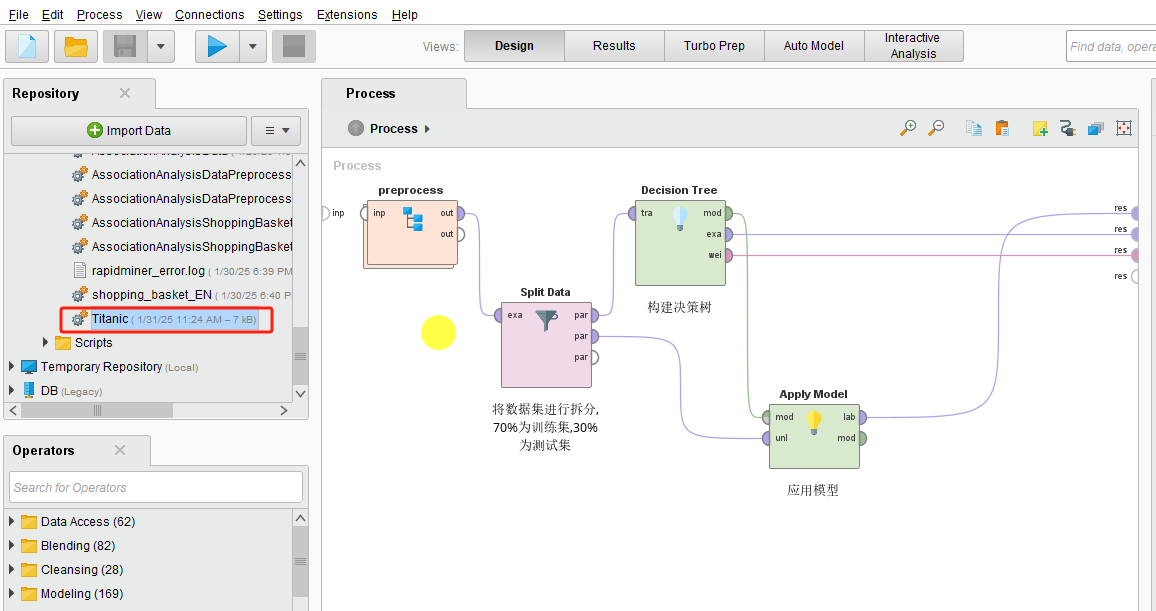
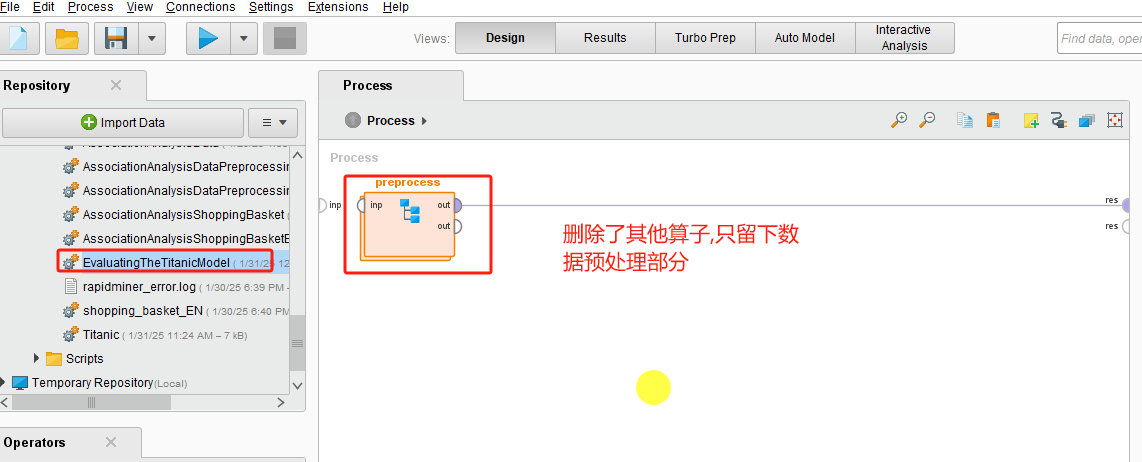
1.改造⑥
⑥小节完成后的模型如下,复制粘贴保存为EvaluatingTheTitanicModel.
2.Cross Validation算子说明
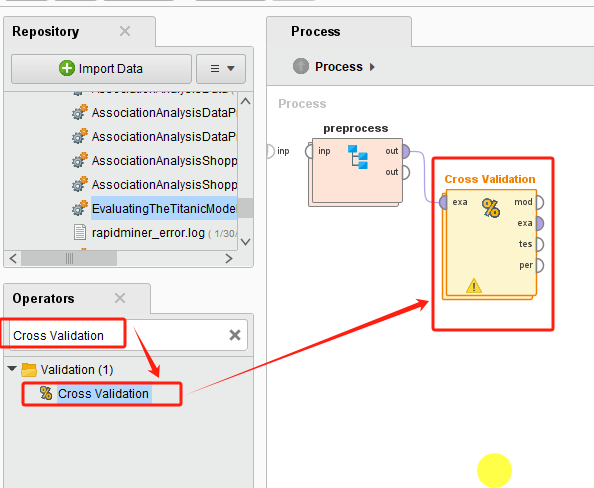
在RapidMiner中,Cross Validation又称为交叉验证,用于评估模型的性能和泛化能力。它是一种统计方法,通过将数据集分成多个子集来训练和测试模型,从而减少过拟合和评估偏差。
2.1Cross Validation 的作用
2.1.1 模型评估
- 交叉验证通过多次训练和测试模型,提供更可靠的性能评估(如准确率、精确率、召回率等)。
- 与简单的训练-测试分割相比,交叉验证能更全面地反映模型的表现。
2.1.2 减少过拟合
- 通过多次使用不同的训练和测试子集,交叉验证可以检测模型是否过拟合训练数据。
2.1.3 数据利用
- 交叉验证充分利用所有数据,既用于训练也用于测试,适合数据量较少的情况。
2.2 Cross Validation 的工作原理
2.2.1 数据分割
- 将数据集分成 \( k \) 个大小相似的子集(称为“折”或“folds”)。
- 例如,\( k=10 \) 表示 10 折交叉验证。
2.2.2 迭代训练与测试
- 每次迭代中,选择一个子集作为测试集,其余 \( k-1 \) 个子集作为训练集。
- 训练模型并在测试集上评估性能。
2.2.3 结果汇总
- 所有迭代完成后,计算性能指标的平均值,作为模型的最终评估结果。
2.2.4 Cross Validation 的参数
在 RapidMiner 中,Cross Validation 算子有以下关键参数:
2.2.4.1 Number of folds(折数)
- 决定将数据集分成多少个子集。常见值为 5 或 10。
2.2.4.2 Sampling type(采样类型)
- 决定如何分割数据,例如分层采样(Stratified Sampling)可以保持类别分布。
2.2.4.3 Use local random seed(使用本地随机种子)
- 控制数据分割的随机性,确保结果可重复。
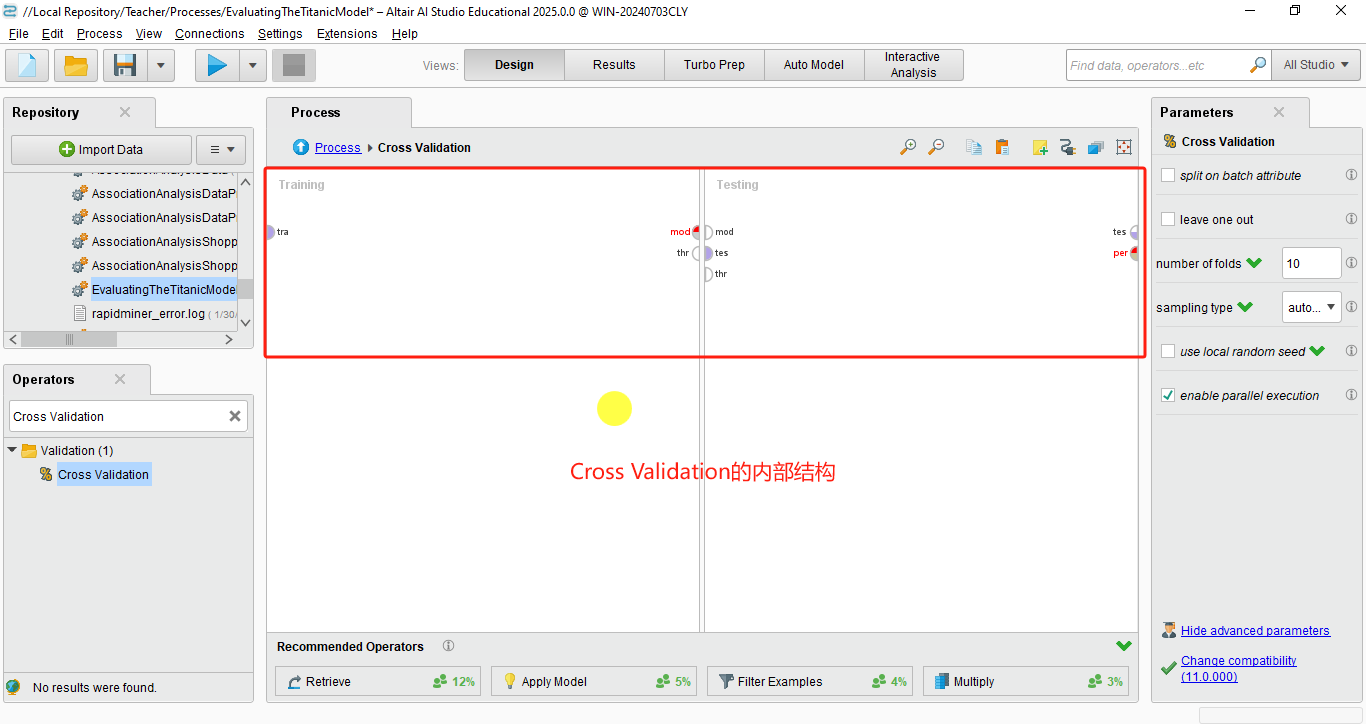
2.2.5 Cross Validation 的流程
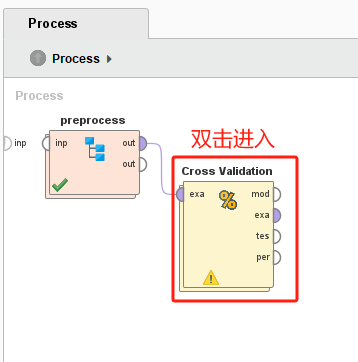
在 RapidMiner 中,Cross Validation 算子的典型流程如下:
1. 将数据集连接到 Cross Validation 算子的输入端口。
2. 在 Cross Validation 算子内部:
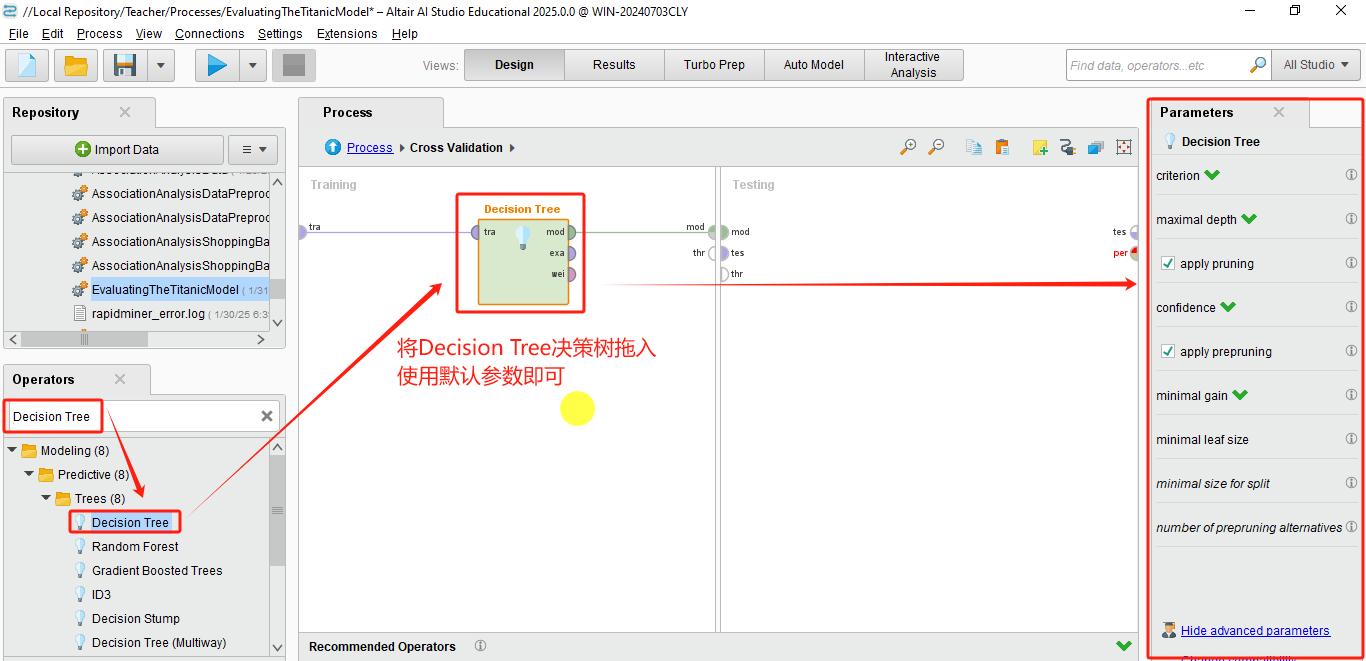
- 将模型(如决策树、逻辑回归等)放入 Training 子流程。
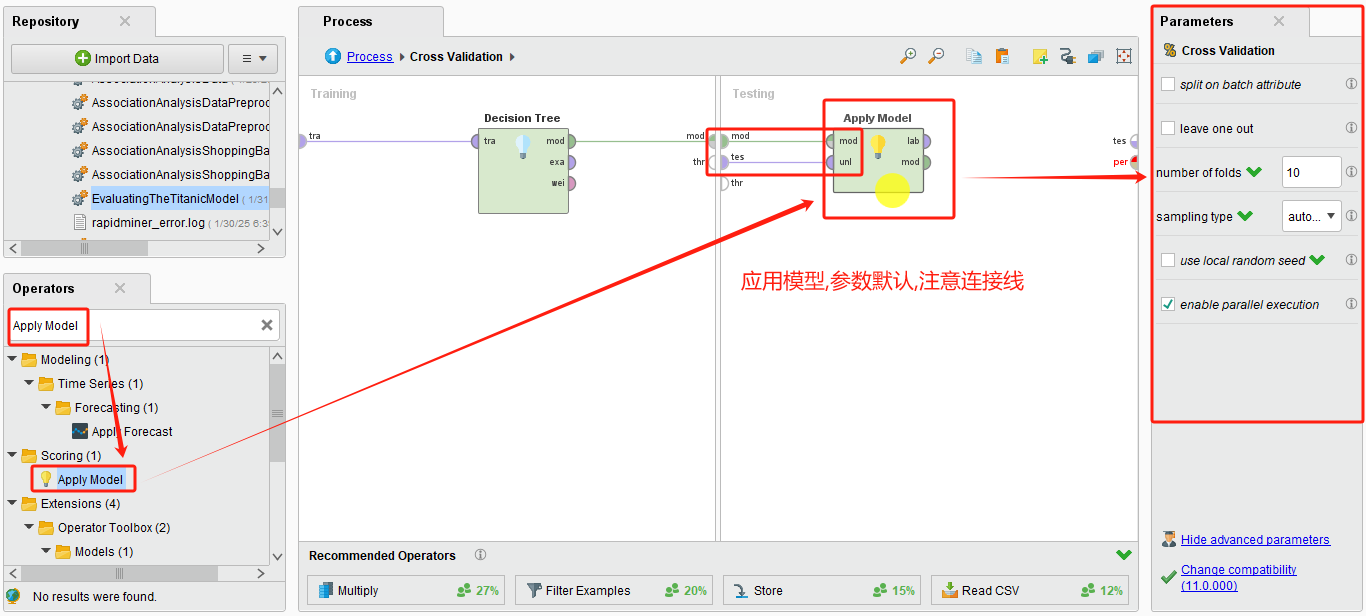
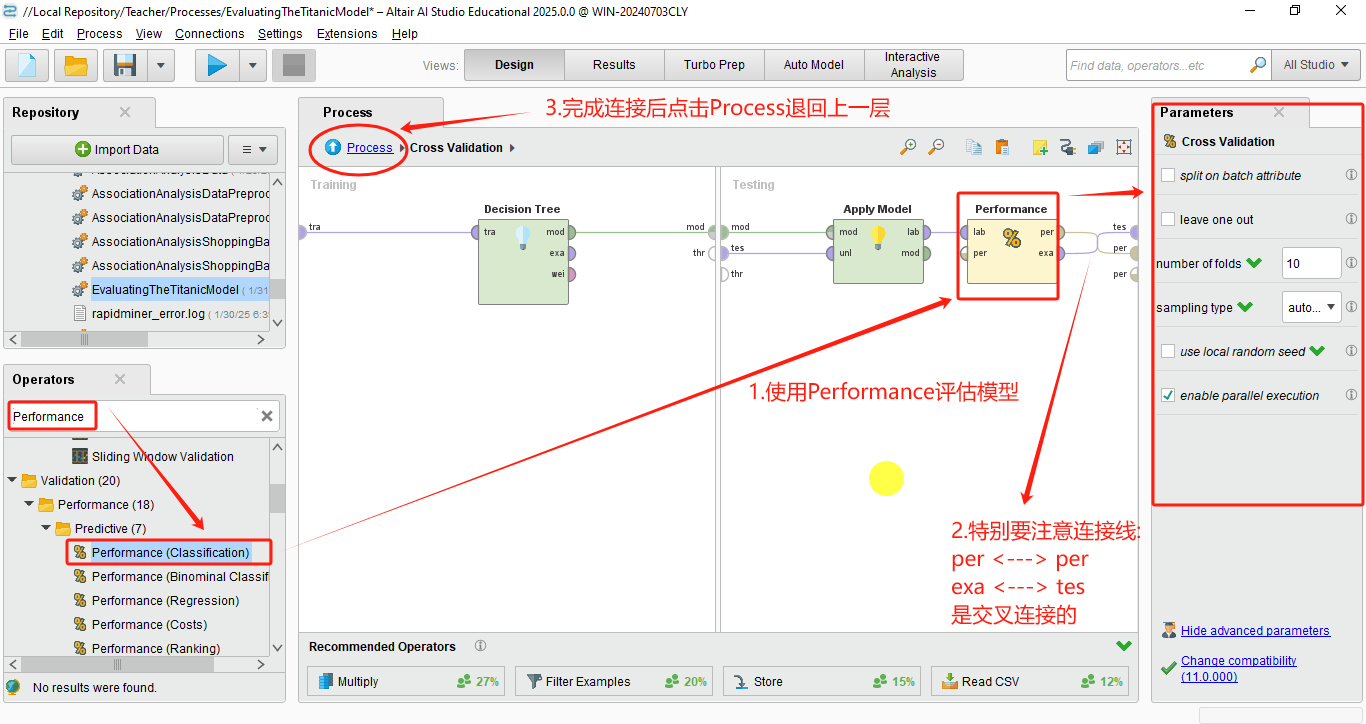
- 将性能评估算子(如 Performance)放入 Testing 子流程。
3. 运行流程后,Cross Validation 会输出模型的平均性能指标。
2.2.6 示例
假设使用 5 折交叉验证评估决策树模型:
1. 数据集被分成 5 个子集。
2. 进行 5 次迭代:
- 每次使用 4 个子集训练模型,1 个子集测试模型。
3. 最终输出 5 次测试的平均准确率、F1 分数等。
2.2.7 总结
Cross Validation 算子的主要作用是:
- 提供更可靠的模型性能评估。
- 减少过拟合风险。
- 充分利用数据,特别适合小数据集。
它是模型开发和评估中不可或缺的工具,帮助确保模型在实际应用中的稳定性和泛化能力。
3 实践
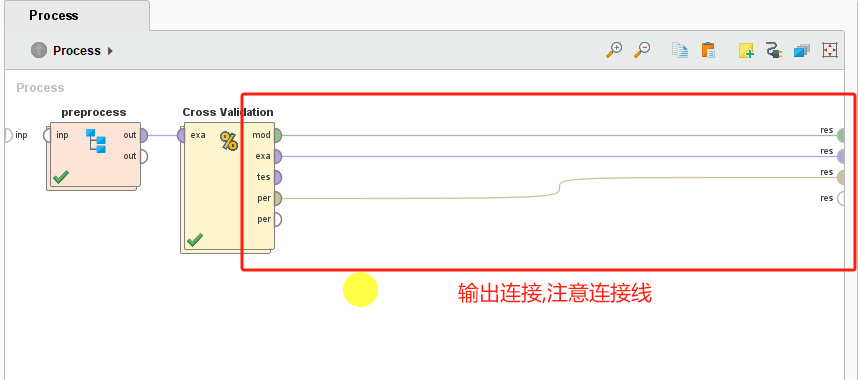
4 结果说明
这是一个混淆矩阵,根据混淆矩阵可知如下结果:
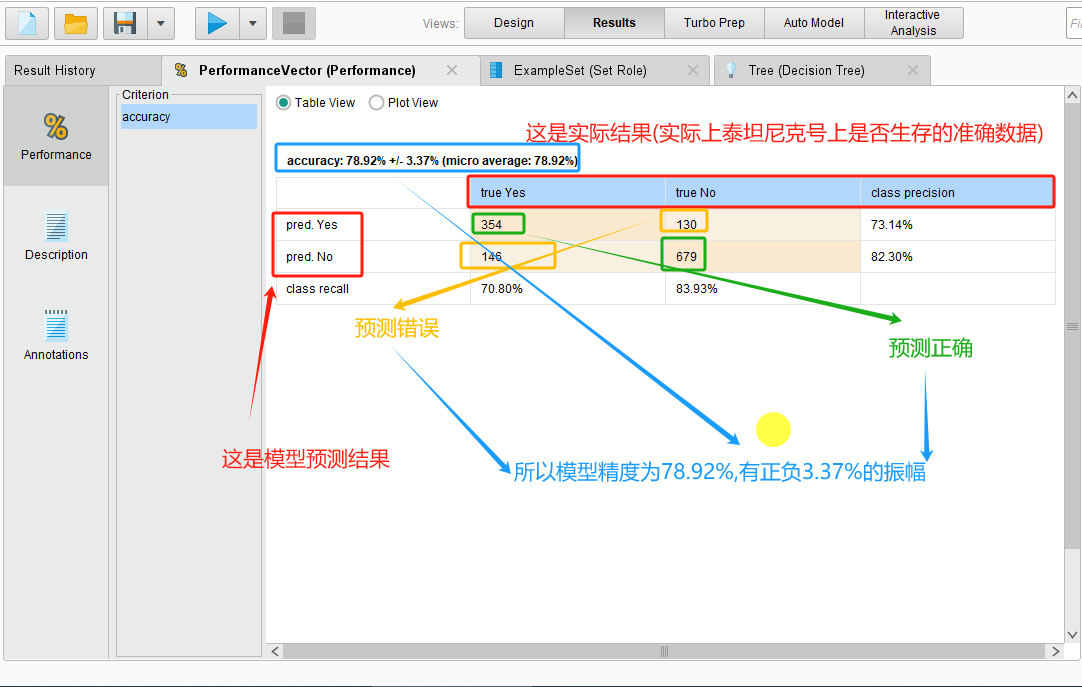
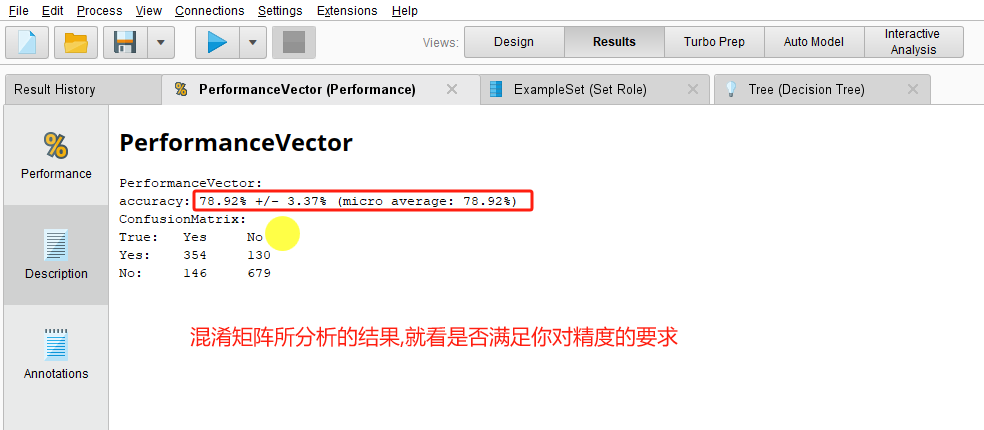
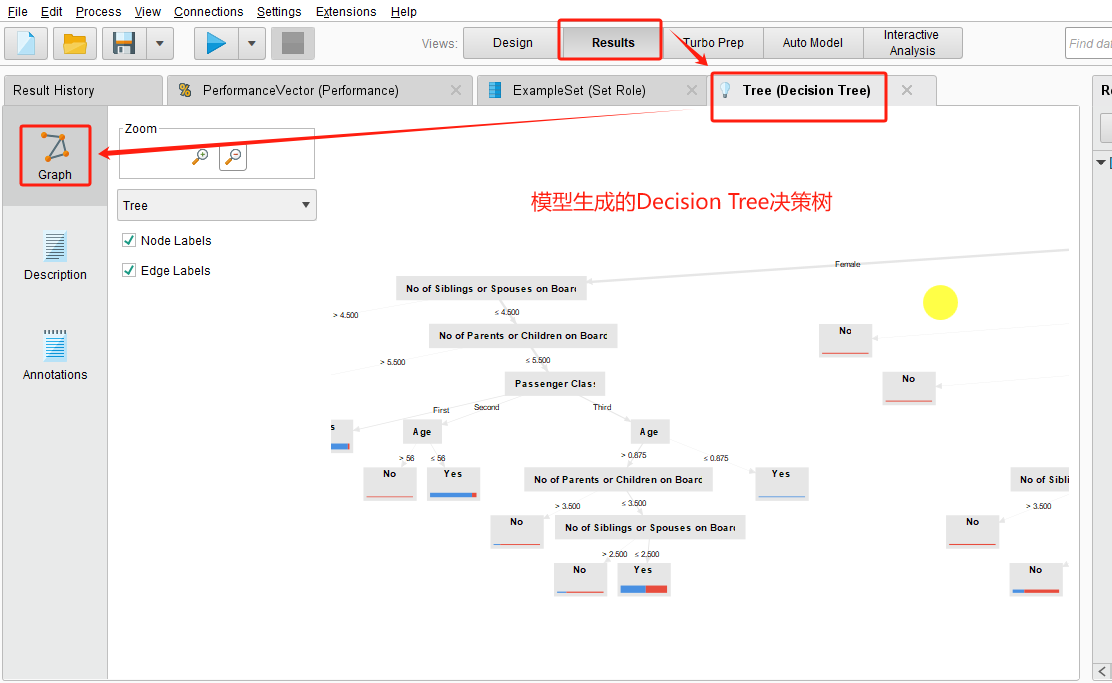
5 决策依据

Ending, congratulations, you're done.