mmpose一般使用如同coco数据json文件格式读取数据与标注,但是当我们用labelme去标注自己的训练集时,只能获取每张图片的标注json文件。接下来,我们简单介绍coco的关键点json文件,并教大家如何获得自己训练集的json文件。
一、COCO中目标关键点的标注格式
打开person_keypoints_val2017.json文件,会出现info,licenses,images,annotations,categories几个分支,其中info,licenses与标注无关,无需关注。

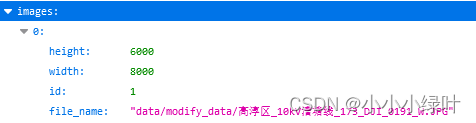
1.images:
images记录了一些关键信息,如图像的文件名、宽、高,图像ID等信息。因为一张图片会存在多个目标需要检测关键点,因此图像ID会与annotation中的目标对应。
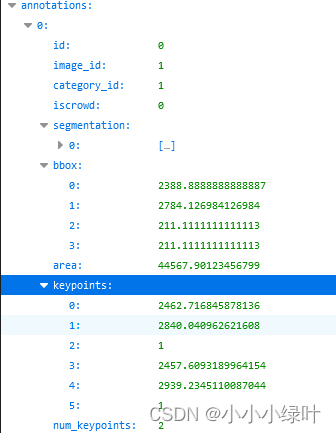
2.annotations
annotations包含了目标检测中annotation所有字段,另外额外增加了2个字段。
新增的keypoints是一个长度为 3 ∗ k的数组,其中 k 表示关键点的个数。每一个 keypoint 是一个长度为3的数组,第一和第二个元素分别是 x 和 y 坐标值,第三个元素是个标志位 v ,v 为 0 时表示这个关键点没有标注(这种情况下 x = y = v = 0), v 为 1 时表示这个关键点标注了但是不可见(被遮挡了), v 为 2 时表示这个关键点标注了同时也可见。
id表示该目标的索引,image_id与images相对应,bbox表示目标框左上角位置与宽高。num_keypoints表示这个目标上被标注的关键点的数量,比较小的目标上可能就无法标注关键点。
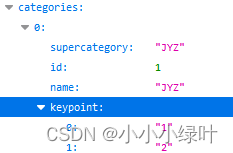
3.categories
对于每一个category结构体,相比目标检测中的中的category新增了2个额外的字段, keypoints 是一个长度为k的数组,包含了每个关键点的类别;skeleton 定义了各个关键点之间的连接性,可以不用注明,mmpose中coco.py可以添加skeleton信息。
二、如何构建自己的json
直接上代码吧,其实没啥难理解的,就是解析每张图的json信息,并把这些信息汇总构建一个新的json文件。
import os
import sys
import glob
import json
import shutil
import argparse
import numpy as np
import PIL.Image
import os.path as osp
from tqdm import tqdm
import cv2
from sklearn.model_selection import train_test_split
class Labelme2coco_keypoints():
def __init__(self, args):
"""
Lableme 关键点数据集转 COCO 数据集的构造函数:
Args
args:命令行输入的参数
- class_name 根类名字
"""
self.classname_to_id = {args.class_name: 1}
self.images = []
self.annotations = []
self.categories = []
self.ann_id = 0
self.img_id = 0
def save_coco_json(self, instance, save_path):
json.dump(instance, open(save_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=1)
def read_jsonfile(self, path):
with open(path, "r", encoding='utf-8') as f:
return json.load(f)
def _get_box(self, points):
min_x = min_y = np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
return [min_x, min_y, max_x - min_x, max_y - min_y]
def _get_keypoints(self, points, keypoints, num_keypoints):
"""
解析 labelme 的原始数据, 生成 coco 标注的 关键点对象
例如:
"keypoints": [
67.06149888292556, # x 的值
122.5043507571318, # y 的值
1, # 相当于 Z 值,如果是2D关键点 0:不可见 1:表示可见。
82.42582269256718,
109.95672933232304,
1,
...,
],
"""
if points[0] == 0 and points[1] == 0:
visable = 0
else:
visable = 1
num_keypoints += 1
keypoints.extend([points[0], points[1], visable])
return keypoints, num_keypoints
def _image(self, obj, path):
"""
解析 labelme 的 obj 对象,生成 coco 的 image 对象
生成包括:id,file_name,height,width 4个属性
示例:
{
"file_name": "training/rgb/00031426.jpg",
"height": 224,
"width": 224,
"id": 31426
}
"""
image = {}
# img_x = utils.img_b64_to_arr(obj['imageData']) # 获得原始 labelme 标签的 imageData 属性,并通过 labelme 的工具方法转成 array
img_path = path
if os.path.exists(img_path.replace('.json','.jpg')):
img_path = img_path.replace('.json','.jpg')
img_x = cv2.imread(img_path)
elif os.path.exists(img_path.replace('.json','.JPG')):
img_path = img_path.replace('.json','.JPG')
img_x = cv2.imread(img_path)
else:
img_path = img_path.replace('.json','.png')
img_x = cv2.imread(img_path)
image['height'], image['width'] = img_x.shape[:-1] # 获得图片的宽高
# self.img_id = int(os.path.basename(path).split(".json")[0])
self.img_id = self.img_id + 1
image['id'] = self.img_id
# image['file_name'] = os.path.basename(path).replace(".json", ".jpg")
image['file_name'] = img_path
return image
def _annotation(self, bboxes_list, keypoints_list, json_path):
"""
生成coco标注
Args:
bboxes_list: 矩形标注框
keypoints_list: 关键点
json_path:json文件路径
"""
if len(keypoints_list) != args.join_num * len(bboxes_list):
print('you loss {} keypoint(s) with file {}'.format(args.join_num * len(bboxes_list) - len(keypoints_list), json_path))
print('Please check !!!')
sys.exit()
i = 0
for object in bboxes_list:
annotation = {}
keypoints = []
num_keypoints = 0
label = object['label']
bbox = object['points']
annotation['id'] = self.ann_id
annotation['image_id'] = self.img_id
annotation['category_id'] = int(self.classname_to_id[label])
annotation['iscrowd'] = 0
# annotation['area'] = 1.0
annotation['segmentation'] = [np.asarray(bbox).flatten().tolist()]
annotation['bbox'] = self._get_box(bbox)
annotation['area'] = annotation['bbox'][2] * annotation['bbox'][3]
for keypoint in keypoints_list[i * args.join_num: (i + 1) * args.join_num]:
point = keypoint['points']
if not ((min(bbox[0][0], bbox[1][0]) <= point[0][0] <= max(bbox[0][0], bbox[1][0])) and\
(min(bbox[0][1], bbox[1][1]) <= point[0][1] <= max(bbox[0][1], bbox[1][1]))):
# raise Exception('point out of bbox')
print(bbox)
print(point)
annotation['keypoints'], num_keypoints = self._get_keypoints(point[0], keypoints, num_keypoints)
annotation['num_keypoints'] = num_keypoints
i += 1
self.ann_id += 1
self.annotations.append(annotation)
def _init_categories(self):
"""
初始化 COCO 的 标注类别
例如:
"categories": [
{
"supercategory": "hand",
"id": 1,
"name": "hand",
"keypoints": [
"wrist",
"thumb1",
"thumb2",
...,
],
"skeleton": [
]
}
]
"""
for name, id in self.classname_to_id.items():
category = {}
category['supercategory'] = name
category['id'] = id
category['name'] = name
category['keypoint'] = [ '1', '2']
# category['keypoint'] = [str(i + 1) for i in range(args.join_num)]
self.categories.append(category)
def to_coco(self, json_path_list):
"""
Labelme 原始标签转换成 coco 数据集格式,生成的包括标签和图像
Args:
json_path_list:原始数据集的目录
"""
self._init_categories()
for json_path in tqdm(json_path_list):
print(json_path)
obj = self.read_jsonfile(json_path) # 解析一个标注文件
self.images.append(self._image(obj, json_path)) # 解析图片
shapes = obj['shapes'] # 读取 labelme shape 标注
bboxes_list, keypoints_list = [], []
for shape in shapes:
if shape['shape_type'] == 'rectangle': # bboxs
bboxes_list.append(shape) # keypoints
elif shape['shape_type'] == 'point':
keypoints_list.append(shape)
self._annotation(bboxes_list, keypoints_list, json_path)
keypoints = {}
keypoints['info'] = {'description': 'Lableme Dataset', 'version': 1.0, 'year': 2021}
keypoints['license'] = ['BUAA']
keypoints['images'] = self.images
keypoints['annotations'] = self.annotations
keypoints['categories'] = self.categories
return keypoints
def init_dir(base_path):
"""
初始化COCO数据集的文件夹结构;
coco - annotations #标注文件路径
- train #训练数据集
- val #验证数据集
Args:
base_path:数据集放置的根路径
"""
if not os.path.exists(os.path.join(base_path, "coco", "annotations")):
os.makedirs(os.path.join(base_path, "coco", "annotations"))
if not os.path.exists(os.path.join(base_path, "coco", "train")):
os.makedirs(os.path.join(base_path, "coco", "train"))
if not os.path.exists(os.path.join(base_path, "coco", "val")):
os.makedirs(os.path.join(base_path, "coco", "val"))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--class_name", "--n", help="class name", type=str, required=True)
parser.add_argument("--input", "--i", help="json file path (labelme)", type=str, required=True)
parser.add_argument("--output", "--o", help="output file path (coco format)", type=str, required=True)
parser.add_argument("--join_num", "--j", help="number of join", type=int, required=True)
parser.add_argument("--ratio", "--r", help="train and test split ratio", type=float, default=0.12)
args = parser.parse_args()
labelme_path = args.input
saved_coco_path = args.output
init_dir(saved_coco_path) # 初始化COCO数据集的文件夹结构
json_list_path = glob.glob(labelme_path + "/*.json")
train_path, val_path = train_test_split(json_list_path, test_size=args.ratio)
print('{} for training'.format(len(train_path)),
'\n{} for testing'.format(len(val_path)))
print('Start transform please wait ...')
l2c_train = Labelme2coco_keypoints(args) # 构造数据集生成类
# 生成训练集
train_keypoints = l2c_train.to_coco(train_path)
l2c_train.save_coco_json(train_keypoints, os.path.join(saved_coco_path, "coco", "annotations", "keypoints_train.json"))
# 生成验证集
l2c_val = Labelme2coco_keypoints(args)
val_instance = l2c_val.to_coco(val_path)
l2c_val.save_coco_json(val_instance, os.path.join(saved_coco_path, "coco", "annotations", "keypoints_val.json"))
# 拷贝 labelme 的原始图片到训练集和验证集里面
for file in train_path:
shutil.copy(file.replace("json", "bmp"), os.path.join(saved_coco_path, "coco", "train"))
for file in val_path:
shutil.copy(file.replace("json", "bmp"), os.path.join(saved_coco_path, "coco", "val"))
这里还想提供一些标注的经验给大家。为了保证关键点标注的精度,建议大家先画框,然后把框扣成小图,在小图上标关键点,最后,再把小图的json合并。这样可以大大增加效率并减少误标。合并的程序也给你们
import os
import sys
import glob
import json
import shutil
import argparse
import numpy as np
import PIL.Image
import os.path as osp
from tqdm import tqdm
import json
from base64 import b64encode
from json import dumps
import shutil
def read_jsonfile(path):
with open(path, "r", encoding='utf-8') as f:
return json.load(f)
if __name__ == '__main__':
json_match_dict = {}
src_json_file = '/home/xxx/mmpose-master/data/images/'
for root, dir_list, file_list in os.walk(src_json_file):
for index, file_fn in enumerate(file_list):
if file_fn.endswith('json'):
json_match_dict[file_fn] = []
cut_json_file = '/home/xxx/mmpose-master/data/cut_img/'
for root, dir_list, file_list in os.walk(cut_json_file):
for index, file_fn in enumerate(file_list):
if file_fn.endswith('json'):
if file_fn.split('_JYZ')[0] + '.json' in json_match_dict:
json_match_dict[file_fn.split('_JYZ')[0] + '.json'].append(file_fn)
for src_json_path, cut_json_path in json_match_dict.items():
print(src_json_path)
print(cut_json_path)
if not cut_json_path or os.path.exists(os.path.join(src_json_file, src_json_path).replace('images','modify_data')):
continue
bboxes_list, keypoints_list = [], []
src_obj = read_jsonfile(os.path.join(src_json_file, src_json_path)) # 解析一个标注文件
for i in range(len(cut_json_path)):
cut_obj = read_jsonfile(os.path.join(cut_json_file, cut_json_path[i]))
cut_shapes = cut_obj['shapes']
for cut_shape in cut_shapes:
if cut_shape['shape_type'] == 'point':
keypoints_list.append(cut_shape)
shapes = src_obj['shapes'] # 读取 labelme shape 标注
for shape in shapes:
if shape['shape_type'] == 'rectangle': # bboxs
bboxes_list.append(shape) # keypoints
json_dict = {
"version": "4.5.7",
"flags": {},
"shapes": [],
"imageHeight": src_obj['imageHeight'],
"imageWidth": src_obj['imageWidth']
}
for rect_ind in range(len(bboxes_list)):
bbox_dict = bboxes_list[rect_ind]
bbox_label = bbox_dict['label']
if bbox_label != 'JYZ':
bbox_label = 'JYZ'
bbox_points = bbox_dict['points']
bbox_group_id = bbox_dict['group_id']
bbox_shape_type = bbox_dict['shape_type']
json_dict['shapes'].append({
"label": bbox_label,
"points": bbox_points,
"group_id": bbox_group_id,
"shape_type": bbox_shape_type,
"flags": {}
})
for point_ind in range(0, len(keypoints_list), 2):
p2b_ind = point_ind // 2
p2bbox_dict = bboxes_list[p2b_ind]
rect_cord = p2bbox_dict['points']
x_left, y_left = min(rect_cord[0][0], rect_cord[1][0]), min(rect_cord[0][1], rect_cord[1][1])
keypoint1_dict = keypoints_list[point_ind]
keypoint1_label = keypoint1_dict['label']
keypoint1_group_id = keypoint1_dict['group_id']
keypoint1 = keypoint1_dict['points'][0]
json_dict['shapes'].append({
"label": keypoint1_label,
"points": [
[
keypoint1[0] + x_left,
keypoint1[1] + y_left
]
],
"group_id": keypoint1_group_id,
"shape_type": "point",
"flags": {}
})
keypoint2_dict = keypoints_list[point_ind + 1]
keypoint2_label = keypoint2_dict['label']
keypoint2_group_id = keypoint2_dict['group_id']
keypoint2 = keypoint2_dict['points'][0]
json_dict['shapes'].append({
"label": keypoint2_label,
"points": [
[
keypoint2[0] + x_left,
keypoint2[1] + y_left
]
],
"group_id": keypoint2_group_id,
"shape_type": "point",
"flags": {}
})
img_path = os.path.join(src_json_file, src_json_path)
if os.path.exists(img_path.replace('.json','.jpg')):
img_path = img_path.replace('.json','.jpg')
elif os.path.exists(img_path.replace('.json','.JPG')):
img_path = img_path.replace('.json','.JPG')
else:
img_path = img_path.replace('.json','.png')
with open(img_path, 'rb') as jpg_file:
byte_content = jpg_file.read()
# 把原始字节码编码成base64字节码
base64_bytes = b64encode(byte_content)
# 把base64字节码解码成utf-8格式的字符串
base64_string = base64_bytes.decode('utf-8')
# 用字典的形式保存数据
json_dict["imageData"] = base64_string
json_dict["imagePath"] = img_path
shutil.copy(img_path, img_path.replace('images', 'modify_data'))
with open(os.path.join('/home/xxx/mmpose-master/data/modify_data/', src_json_path), "w", encoding='utf-8') as f:
# json.dump(dict_var, f) # 写为一行
json.dump(json_dict, f,indent=2,sort_keys=False, ensure_ascii=False) # 写为多行