Hive数仓总结
大数据产生来源
典型的数据分析系统,要分析的数据种类⽐较丰富,依据来源⼤体可以分为以下⼏部分:
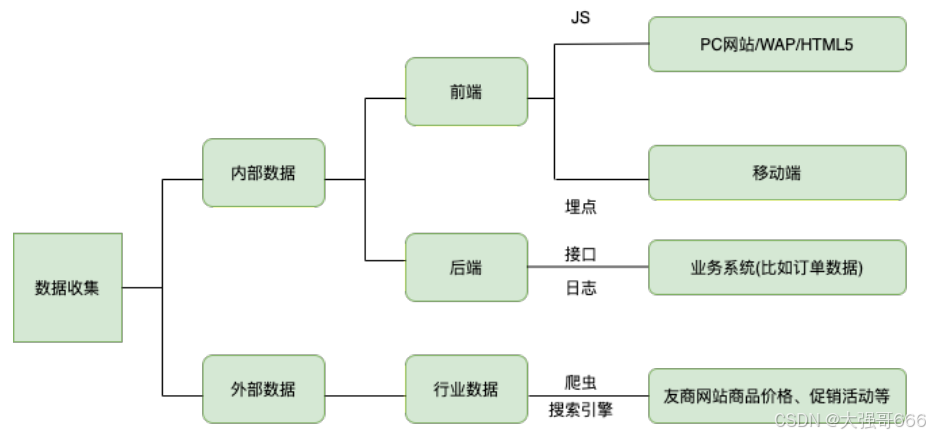
内部数据
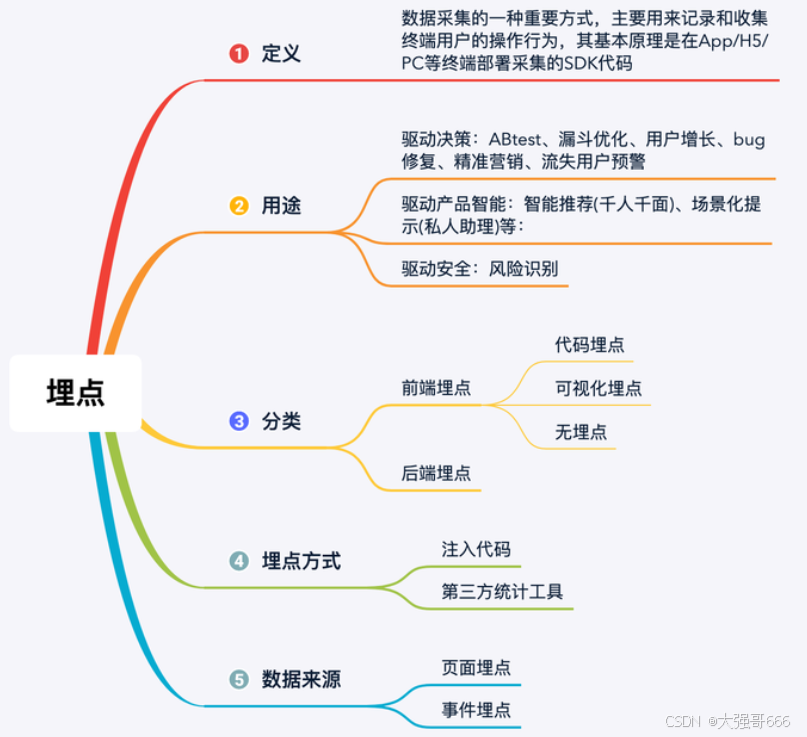
如何进⾏埋点
埋点原理
对基于⽤户⾏为的数据平台来说,发⽣在⽤户界⾯的,能获取⽤户信息的触点就是⽤户数据的直接来源,⽽建⽴这些触点的⽅式就是埋点。当这些触点获取到⽤户⾏为、身份数据后,会通过⽹络传输到服务器端进⾏后续的处理。
埋点分类
埋点从准确性⻆度考虑,分为客户端埋点和服务端埋点。**客户端埋点,即客户操作界⾯中,**在客户产⽣动作时对⽤户⾏为进⾏记录,这些⾏为只会在客户端发⽣,不会传输到服务器端;⽽服务端埋点则通常是在程序和数据库交互的界⾯进⾏埋点,这时的埋点会更准确地记录数据的改变,同时也会减⼩由于⽹络传输等原因⽽带来的不确定性⻛险。如下图所示为不同埋点方式对比:
| 类型 | 代码埋点 | 全埋点 | 可视化埋点 | 服务端埋点 |
|---|---|---|---|---|
| 采集说明 | 嵌入SDK,定义事件并添加事件代码 | 嵌入SDK | 嵌入SDK,可视化圈选定义事件 | 接口调用,数据结构化 |
| 场景 | 认可业务价值为出发点的行为分析 | 无需采集事件,适用于活动页、着陆页、关键页设计体验衡量 | 用户在页面的行为与业信息关联较少。页面数量多且页面元素较少,对行为数据的应用较浅 | 前后端数据整合 |
| 优势 | 按需采集,业务信息更完善,对数据的分析更聚焦 | 简单、快捷,与代码埋点相比工作量更小 | 与代码埋点相比工作量更小 | 更灵活,更准确,数据上传更及时 |
| 劣势 | 与后两种采集方式相比,开发人员工作量更大 | 数据准确性不高,上传数据多,消耗流量大,数据维度单一(仅点击、加载、刷新) | 业务人员工作量较大,改版后需重新定义事件,缺乏基于业务的解读 | 前端交互数据缺失仅服务端数据采集,缺少前端环境数据 |
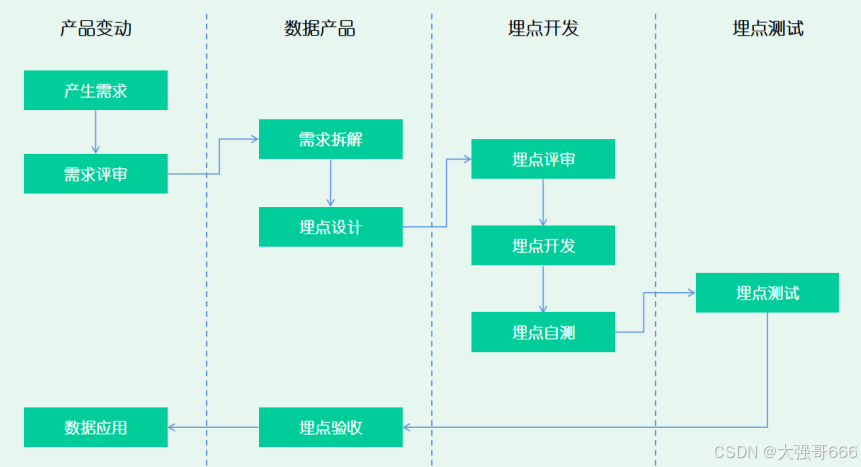
埋点采集⼯作流程
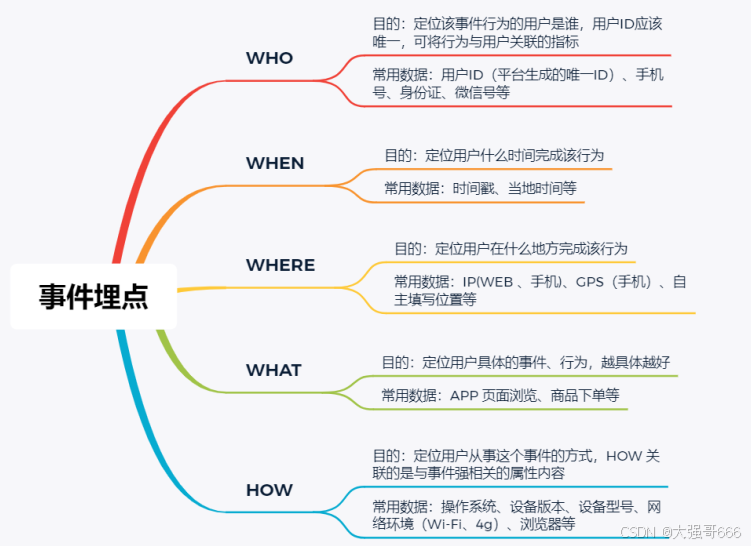
埋点数据采集维度
埋点⽂档必备要素
| 要素 | 备注 |
|---|---|
| 事件名称 | 埋点的事件名称,如优惠券领取/优惠券使用 |
| 事件定义 | 用户点击领取优惠券,则上报该事件 |
| 包含属性 | 用户进行了该行为,上报事件中需要传输哪些内容,如用户ID、时间、应用版本、 网络环境、手机型号、用户IP、内容ID等;如某些属性在所有事件中都需要上传, 则可以整理公共属性进行管理 |
| 属性定义 | 说明属性的定义,如用户地址:可以是用户主动上传的地址,如没有则用用户IP代替 |
| 属性值类型 | 说明传输属性的类型,字符串、数值、bool |
| 开发名称 | 对应的开发变量名,可以由开发进行补充。如userid、contentid |
| 当前状态 | 说明当前该变量的状态。如待开发、开发中、验收中、已上线、已下线 |
| 上线版本 | 说明该内容在哪个版本上进行上线。 |
| 备注 | 备注中可以记录该属性的变动情况和常见值等内容。 |
案例:优惠券营销场景的事件设计
在整个埋点⼯作流程中,埋点设计环节是最关键的⼀环,在这个环节整体可以根据需求梳理和转化的路径,分为业务分解、分析指标、事件设计、属性设计的四个阶段。其中,业务分解和分析指标,是事件设计和属性设计的关键信息输⼊,通过对业务场景和分析需求的梳理,确认埋点的内容和范围, ⽽事件和属性设计,则是将这些业务分析诉求,转换成⾯向幵发的需求语⾔,让开发能看懂需要他在什么场景和规则下采集哪些数据。接下来,我们以优惠券营销场景为案例,讲述该如何进⾏埋点设计。

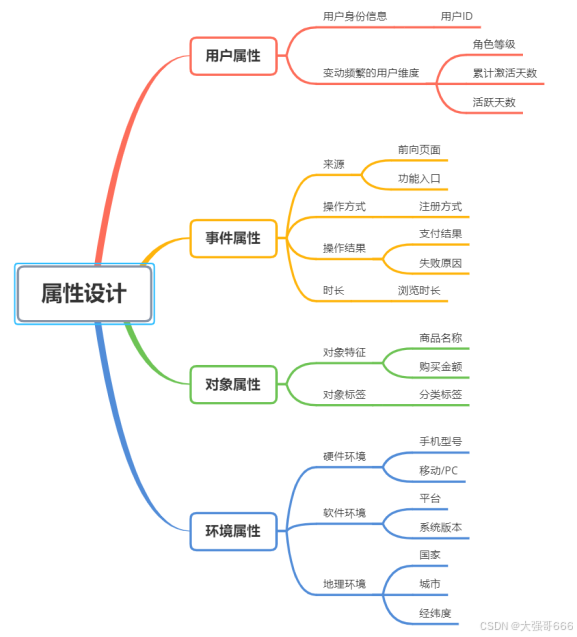
埋点采集中常⻅事件属性的类型举例,主要包含⽤户属性、事件属性、对象属性和环境属性四⼤类。
外部数据
1、竞争对⼿数据——爬取数据(电⼦商务⾏业最初对爬⾍的需求来源于⽐价(⽣意参谋,⽣e经));2、国家统计局数据;3、友商提供的数据。
⼤数据特点(5V特点)
⼤数据特点(5V特点):1、Volume(大):体现在数据的采集,计算,存储量都是非常庞大的;2、Variety:(多):体现在数据种类和来源的多样化。其中的种类有:结构化、半结构化和非结构化数据等,而常见的来源有:网络日志,音频,视频,照片等;3、Value(值):体现在数据价值密度相对较低,如大浪淘金,百炼成钢般才能获取到大量信息中的部分有价值的信息;4、Velocity(快):体现在数据增长速度快,处理速度也快,获取数据的速度也要快;5、Veracity(信):数据的准确性和可信性程度高,即数据的质量高。
海量的数据
1、2021年第一季度抖音日活(DAU)数据:峰值约7亿、平均值超6亿;2、2020年拼多多APP平均月活(MAU)跃用户数达7.199亿;3、2020年爱奇艺月活跃用户超5.6亿;4、2019支付宝的日活突破3亿。
传统数据库的存储量
| 数据库 | 单表建议存储量(条) |
|---|---|
| Access | 小于10W |
| Mysql | 小于500W(数据量多时可以分区处理) |
| Oracle | 小于500W(数据量多时可以分区处理) |
传统数据库面临的挑战
1、无法满足快速增长的海量数据存储需求;2、无法有效处理不同类型的数据(图片,音频,视频等);3、计算和处理能力不足。
Hadoop及Hive环境
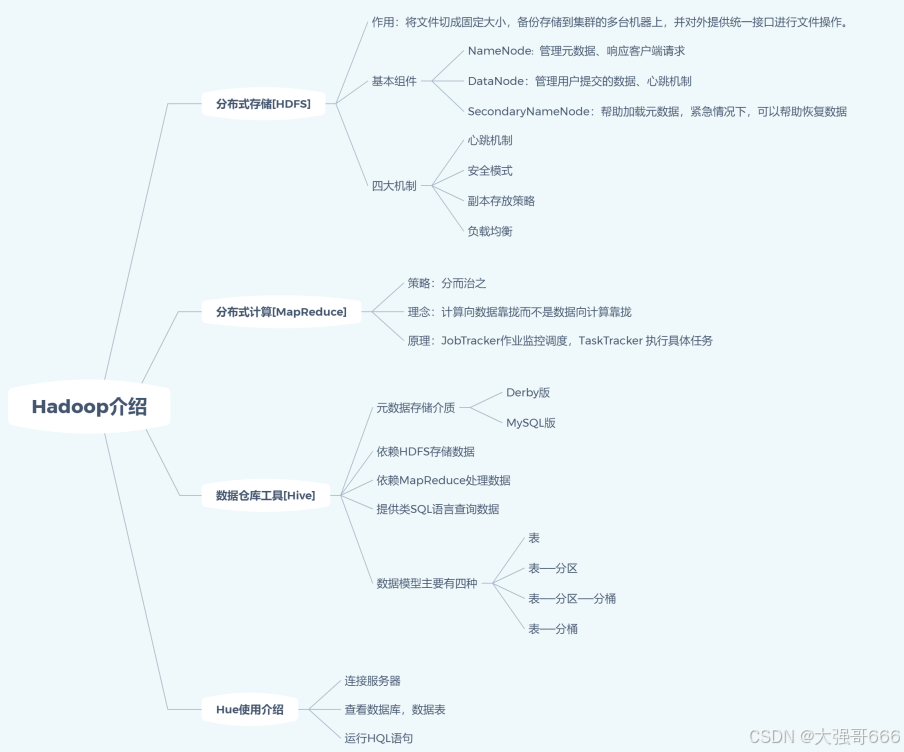
Hadoop简介
Hadoop是什么?简单来说, Hadoop就是解决⼤数据时代下海量数据的存储和分析计算问题。Hadoop不是指具体的⼀个框架或者组件,它是Apache软件基⾦会下⽤Java语⾔开发的⼀个开源分布式计算平台,实现在⼤量计算机组成的集群中对海量数据进⾏分布式计算,适合⼤数据的分布式存储和计算,从⽽有效弥补了传统数据库在海量数据下的不⾜。
Hadoop优点
1、⾼可靠性: Hadoop按位存储和处理数据的能⼒值得⼈们信赖;2、⾼扩展性: Hadoop是在可⽤的计算机集群间分配数据并完成计算任务,这些集群可以⽅便地扩展到数以千计的节点中;3、⾼效性: Hadoop能够在节点之间动态地移动数据,并保持各个节点的动态平衡(保证不会出现其中一个节点在拼命工作,而其他节点没事干的情况),因此处理速度⾮常快;4、⾼容错性: Hadoop能够⾃动保存数据的多个副本(如果一台计算机出的错,不会打扰其他副本的计算机的继续操作),并且能够⾃动将失败的任务重新分配;5、低成本: Hadoop是开源的,项⽬的软件成本因⽽得以⼤⼤降低。
Hadoop生态圈
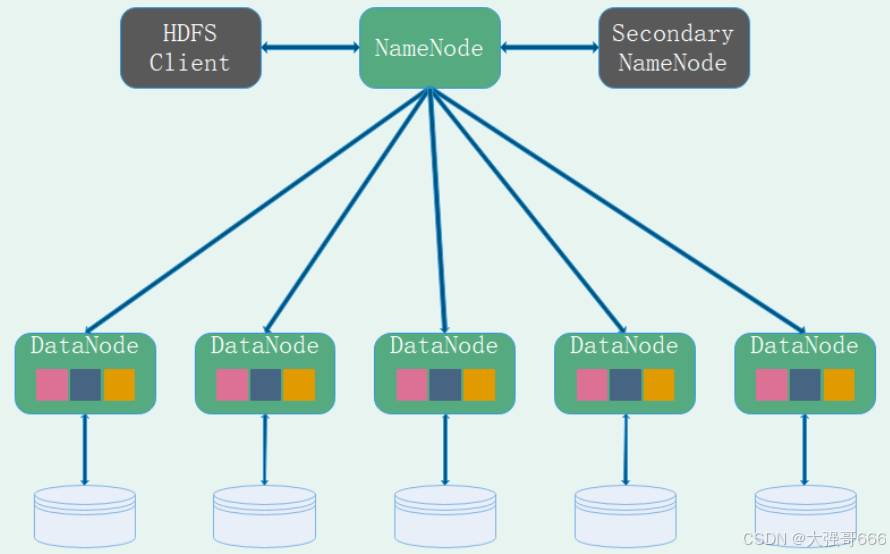
分布式存储文件系统(HDFS)
现在企业环境中, 单机容量无法存储大量数据,需要跨机器[集群]存储,而统一管理分布在集群上的文件系统称之为分布式文件系统。HDFS(Hadoop Distributed Fill System) 是Hadoop项目的子项目,使用多台计算机存储文件,并且提供统一的访问接口(NameNode),像是访问一个普通文件系统一样使用分布式文件系统。
HDFS的工作原理就是:将⽂件切分成固定⼤⼩的数据块block(⽂件严格按照字节来切,所以若是最后切得小⼀点点,也算单独⼀块,hadoop2.x默认的固定⼤⼩是128MB,不同版本的默认值不同,可以通过Client端上传⽂件设置)。比如一个200M,系统就会将其切割成128M和72M两块分别放置在两个不同的节点上,并且对每一块进行备份,默认备份2份,加上自己就有3份,对于不同的副本,存储在不同的节点上,就是因为其分布式存储及多副本备份实现了Hadoop的容错性及工作量的均衡。
HDFS的优点是:1、分布式存储;2、支持分布式和并行计算;3、水平可伸缩性。
HDFS基本组件
1、HDFS Client : 提供命令管理HDFS
2、NameNode:管理整个文件系统的元数据;工作职责:管理元数据、维护目录结构、响应客户端请求。
3、DataNode:复制管理用户的文件数据块;工作职责:管理用户提交的数据与心跳机制块报告。
4、SecondaryNameNode:NameNode的助理,帮助加载元数据,紧急情况下(例如NameNode宕机),可以帮助恢复数据。
HDFS四大机制
1、心跳机制(Master/Slave结构, Master是NameNode, Slave是DataNode):默认DataNode向NameNode发送请求的时间间隔为3s。默认NameNode向DataNode发送请求的时间间隔为5min。NameNoder如果长时间没有接收到DataNode的心跳,也会每隔一段时间(5min)向DataNode发送请求,一共会发两次。
2、安全模式:HDFS集群正常冷启动时,NameNode也会在safemode状态下维持相当长一段时间,等待它自动退出安全模式即可。
3、副本存放策略:将每个文件的数据进行分块存储,每一个数据块有保存有多个副本,这些数据块副本分布在不同的机器节点上。
4、负载均衡:机器容量最高的那个值和最低的那个值差距不能超过10%。
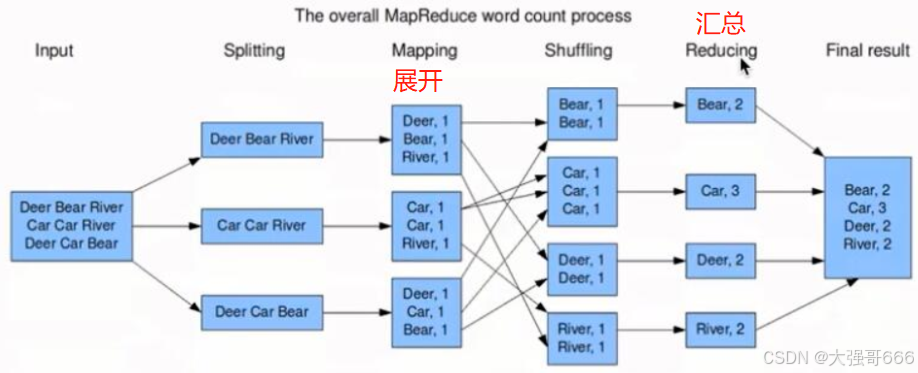
分布式计算(MapReduce)
MapReduce为海量的数据提供了计算。MapReduce从它名字上来看就⼤致可以看出个缘由,两个动词Map和Reduce, “Map(展开) ”就是将⼀个任务分解成为多个任务, “Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。 MapReduce采⽤"分⽽治之"的思想,简单地说, MapReduce就是"任务的分解与结果的汇总"。总之MapReduce 是一种分布式并行编程框架,其中MapReduce的策略是:分而治之;而MapReduce的理念是:计算向数据靠拢而不是数据向计算靠拢。
MapReduce 体系架构(主从(Master/Slave)架构)
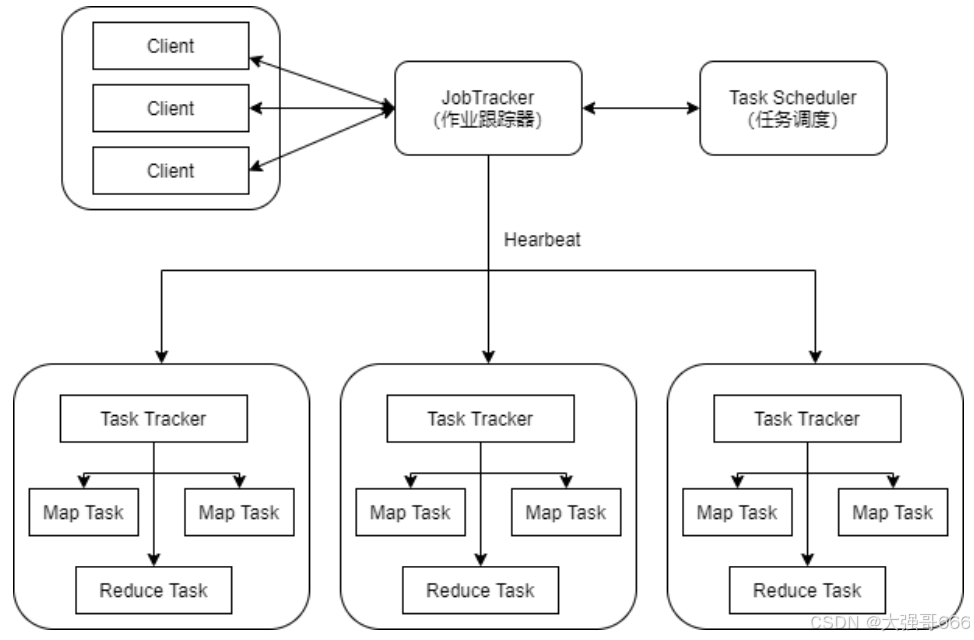
client(客户端):通过Client可以提交用户编写的应用程序,用户通过它将应用程序提交到 JobTracker端,用户也可以通过Client提供的一些接口去查看之前提交作业的运行状态。
JobTracker:资源的监控和作业的调度。监控底层的其他的TaskTracker以及当前运行的Job的健康状况,一旦探测到失败的情况就把这个任务转移到其它节点继续执行跟踪任务执行和资源使用量。
TaskTracker: 执行具体的相关任务一般接受Job Tracker 发送过来的命令(如启动新任务,杀死任务等),把一些自己的资源使用情况,以及任务的运行进度通过心跳的方式也就是heartbest发送给JobTracker。
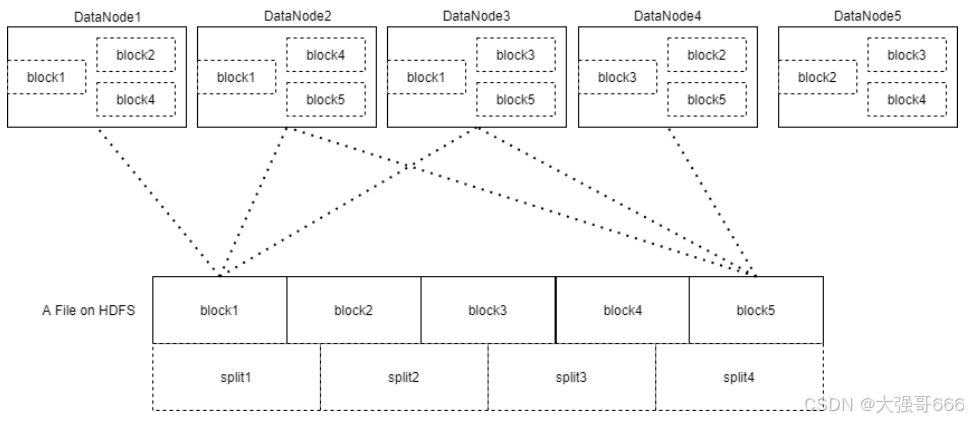
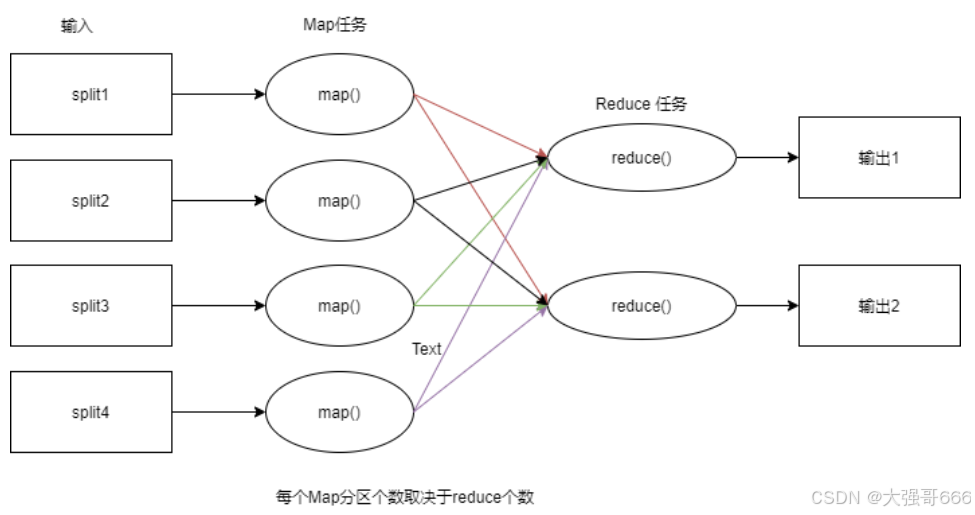
Task: 分为MapTask和Reduce Task两种,均由TaskTracker启动。HDFS以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split。它的划分方法完全由用户自己决定。但需要注意的是,split的多少决定了MapTask的数目,因为每一个split只会交给一个MapTask处理。split与block的关系图如下:
Mapreduce工作流程
数据仓库
数据仓库含义
数据仓库(Data Warehouse),简称DW。数据仓库顾名思义,是⼀个很⼤的数据存储集合,出于企业的分析性报告和决策⽀持⽬的⽽创建,对多样的业务数据进⾏筛选与整合。它为企业提供⼀定的BI(商业智能)能⼒,指导业务流程改进。
数据仓库解决什么问题
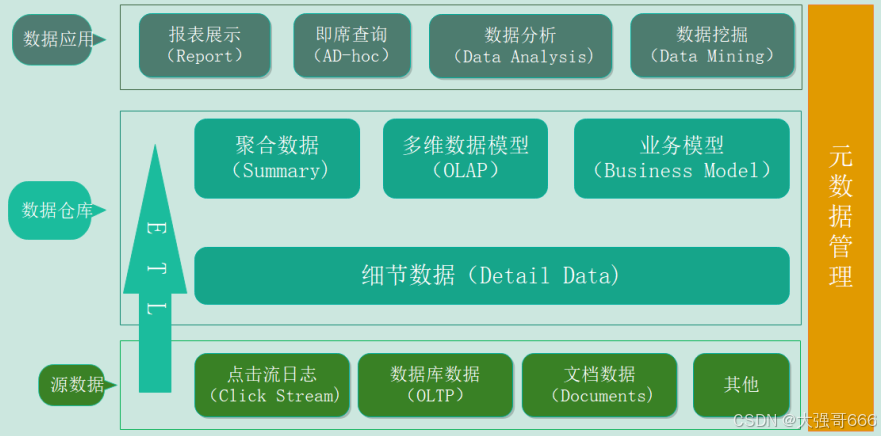
数据仓库从⼤的⽅向来说解决三类问题:存储,快速提取,跨部⻔应⽤。
数据仓库作用
数据仓库的作用:1、历史数据积存及处理能力问题(分布式存储与处理);2、将各种数据源整合到一起统一数据中心,解决数据壁垒(数据仓库的集成性特点)。3、规范表、字段名称,统一字段数据格式,完善注释内容。4、生产适合OLAP(面向分析)的大宽表,方便用户多维度快速分析(仓库的主题性特点)。5、数据质量的保证和指标口径的一致性。
抖音的用户播放记录、拼多多的用户行为日志、爱奇艺的用户行为日志、支付的支付记录,不会发生变更的实时数据以及历史存档数据都可以放入到数仓中。
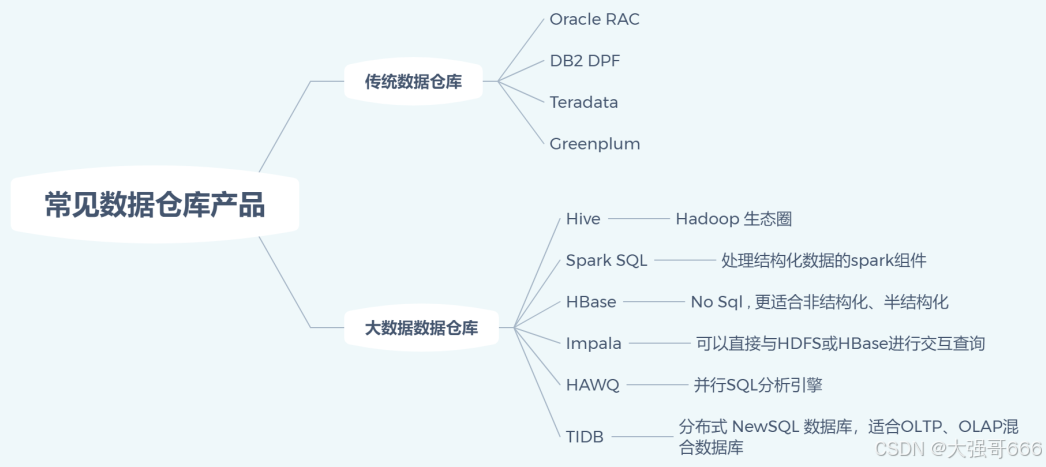
常见的数据仓库产品
数据仓库的主要特征
数据仓库的主要特征是:1、⾯向主题的;2、集成的;3、稳定的(不易丢失的);4、时变的(反映历史变化的)。
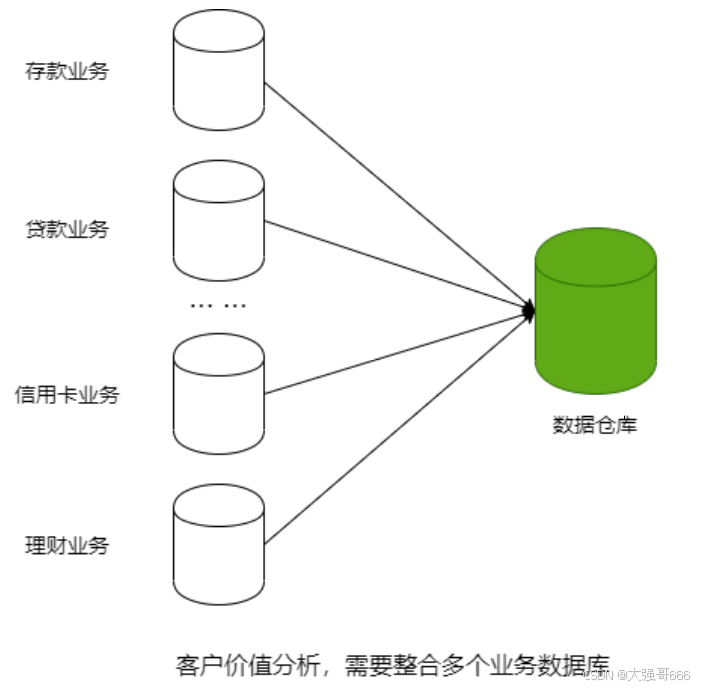
数据仓库与数据库区别
1、数据库与数据仓库的区别实际讲的是OLTP(面向事务)与OLAP(面向分析)的区别:
2、数据仓库的出现,并不是要取代数据库:
| 差异项 | 数据库 | 数据仓库 |
|---|---|---|
| 特征 | 操作处理 | 信息处理 |
| 面向 | 事务 | 分析 |
| 用户 | DBA、开发 | 经理、主管、分析人员 |
| 功能 | 日常操作 | 长期信息需求、决策支持 |
| DB设计 | 基于ER模型,面向应用 | 星形/雪花模型,面向主题 |
| 数据 | 当前的、最新的 | 历史的,跨时间维护 |
| 汇总 | 原始的、高度详细 | 汇总的,统一的 |
| 视图 | 详细、一般关系 | 汇总的,多维的 |
| 工作单元 | 短的、简单事务 | 复杂查询 |
| 访问 | 读/写 | 大多为读 |
| 关注 | 数据进入 | 信息输出 |
| 操作 | 主键索引操作 | 大盘的磁盘扫描 |
| 用户数 | 数百到数亿 | 数百 |
| DB规模 | GB到TB | 大于等于TB |
| 优先 | 高性能,高可用性 | 高灵活性 |
| 度量 | 事务吞吐量 | 查询吞吐量,相应时间 |
数据仓库元数据管理
元数据(MetaData),主要记录数据仓库中模型的定义,各层级间的映射关系、监控数据仓库的数据状态及ETL的任务运⾏状态,⼀般会通过元数据质量库(Metadata Repository)来统⼀地存储和管理元数据,其主要⽬的是使数据仓库的设计、部署、操作和管理能达成协同和⼀致,保证数据质量。
元数据是数据仓库管理系统的重要组成部分,元数据管理是企业级数据仓库中的关键组件,贯穿数据仓库构建的整个过程,直接影响着数据仓库的构建、使⽤和维护。
构建数据仓库的主要步骤之⼀是ETL,这时元数据将要发挥重要的作⽤,它定义了源数据系统到数据仓库的映射、数据转换的规则、数据仓库的逻辑结构、数据更新规则、数据导⼊历史记录以及装载周期等相关内容。数据抽取和转换的专家以及数据仓库管理员正是通过元数据⾼效地构建数据仓库。
⽤户在使⽤数据仓库时,通过元数据访问数据,明确数据项的含义以及定制报表数据仓库的规模及其复杂性离不开正确的元数据管理,包括增加或移除外部数据源,改变数据清洗⽅法,控制出错的查询以及安排备份等。
元数据分为技术元数据和业务元数据:1、技术元数据为开发和管理数据仓库的IT⼈员使⽤, 描述了与数据仓库开发、管理和维护相关的数据,包含数据源信息、数据转换描述、数据仓库模型、数据清洗与更新规则、数据映射和访问权限等;2、业务元数据为管理层和业务分析⼈员服务,从业务⻆度描述数据包括商务术语、数据仓库中有什么数据、数据的位置和数据的可⽤性等。
元数据不仅定义了数据仓库中数据的模式、来源、抽取和转换规则等、⽽且是整个数据仓库系统运⾏的基础,它把数据仓库系统中各个松散的组件联系起来,组成了⼀个有机的整体。
数据治理
数据是企业核⼼资产,数据治理能成就企业(特别是银⾏)的未来。它涉及数据质量、数据管理、数据政策、商业过程管理、⻛险管理等多个领域。
脏数据的种类
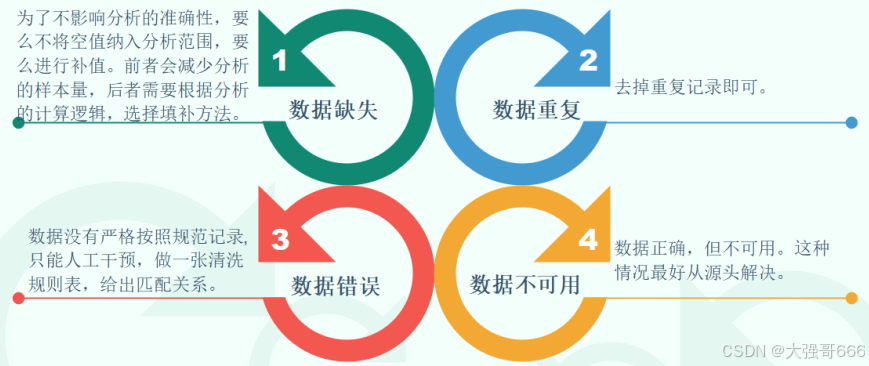
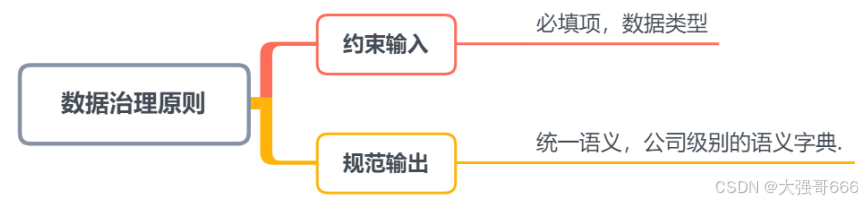
数据治理原则
数据仓库工具(Hive)
Hive是Facebook为了解决海量日志数据的统计分析而开发的基于Hadoop的一个数据仓库工具(后来开源给了Apache软件基金会),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能.HQL。
Hive特点
1、Hive 本身并不支持数据存储和处理,只是一个面向用户的编程接口;2、Hive 依赖分布式文件系统HDFS存储数据;3、Hive 依赖分布式并行计算模型MapReduce 处理数据;4、借鉴SQL语言设计了新的查询语言HQL。
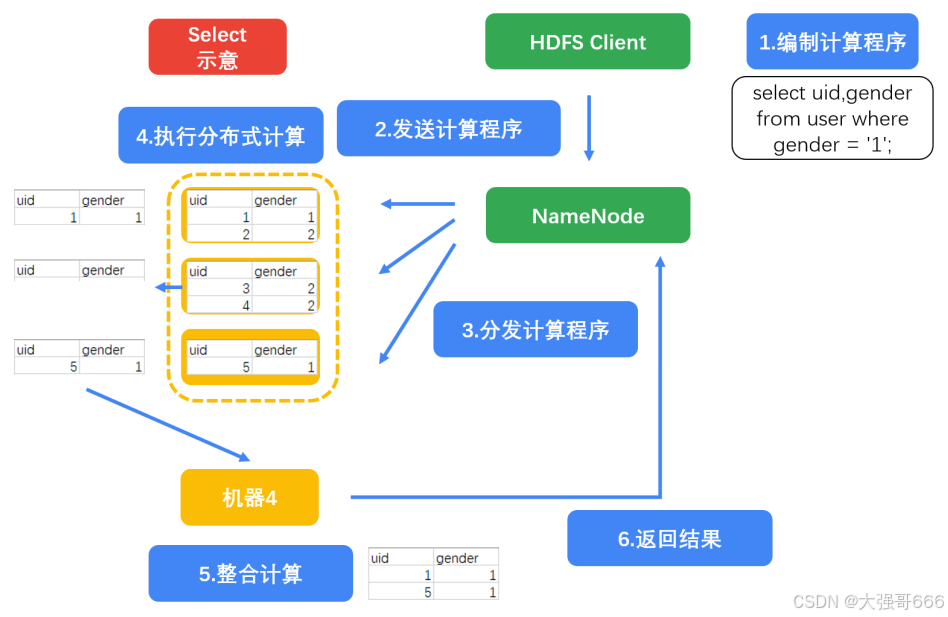
HQL 转换为 MapReduce原理
假如我们有两个表:
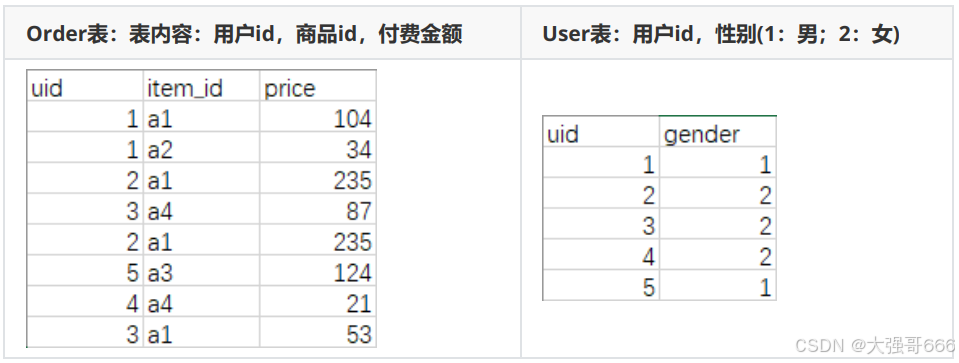
直接抽取
select uid,gender from user;
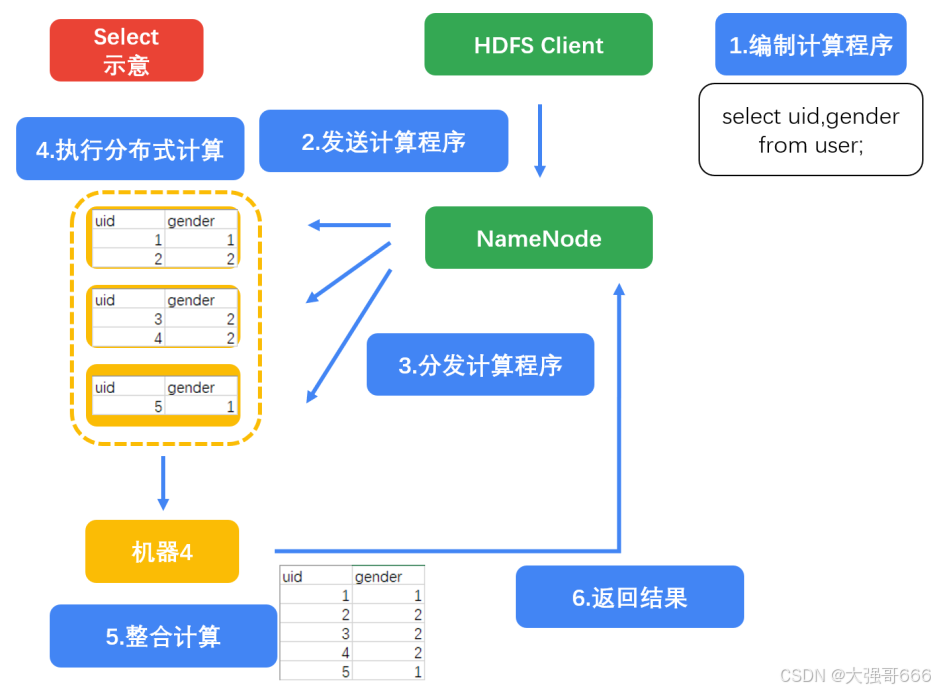
select uid,gender from user where gender = '1';
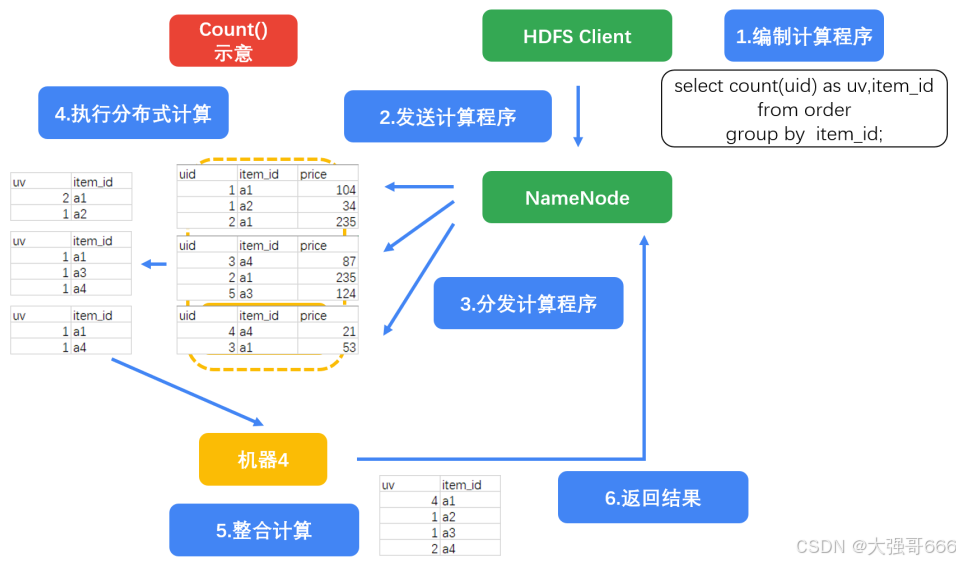
group by
select count(uid) as uv,item_id from order group by item_id;
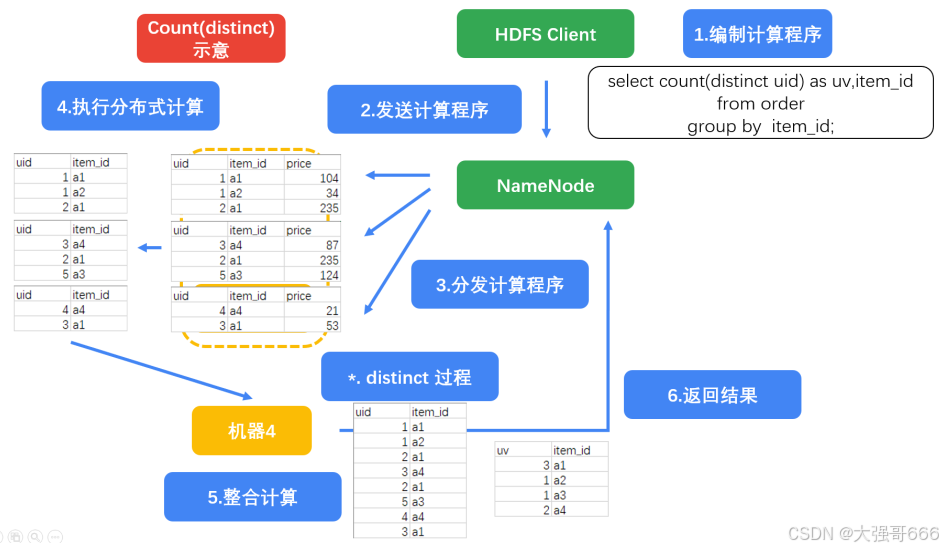
select count(distinct uid) as uv,item_id from order group by item_id;
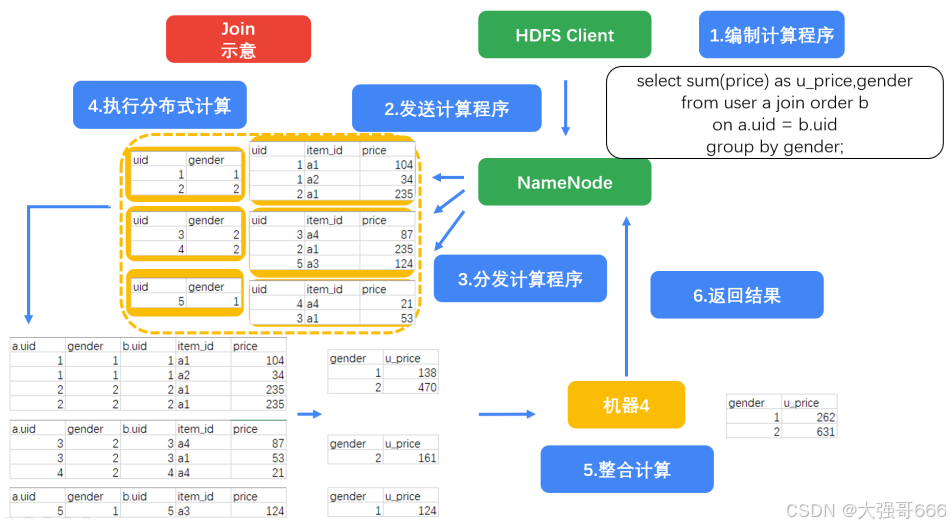
join
join时其中一个优化方案是:左表尽量用小表,他会加载到内存中。
select sum(price) as u_price,genderfrom user a join order b on a.uid = b.uid
group by gender;
数据仓库分层架构
⼤数据系统需要数据模型方式来帮助更好地组织和存储数据,以便在性能、成本、效率和质量之间取得最佳平衡,主流的⽅法是分层架构。其中数据仓库的数据来源于不同的源数据,并提供多样的数据应⽤,数据⾃下层流⼊数据仓库后向上层开放应⽤,⽽数据仓库只是中间集成化数据管理的⼀个平台。
数据分层的好处
数据分层的好处:1、清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解;2、减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算;3、统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径;4、复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题,减少运用层的子查询。
通用的数据分层设计(4层)
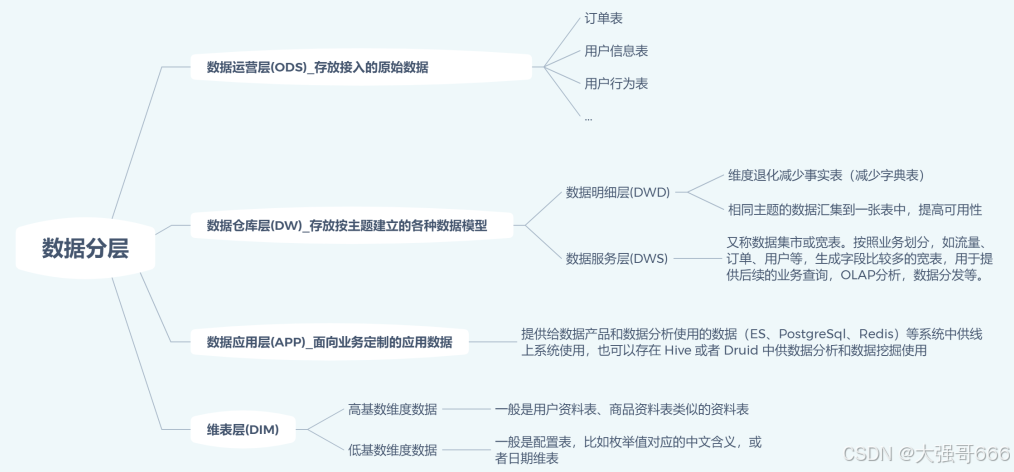
ODS数据运营层(原数据层)
ODS数据运营层:在结构上其与源系统的增量或者全量数据基本保持一致。它相当于一个数据准备区,同时又承担着基础数据的记录以及历史变化。其主要作用是把基础数据(mysql,oracle,sql server中的数据)引入到数据仓库。作用:当发现问题或者要新开一个分析专题事务时,可能需要从原始数据重新搭建一些东西出来。
DW数据仓库层
DW数据仓库层:又细分为DWD(数据明细层)和DWS(数据服务层/汇总数据层)。它的主要作用是完成数据加工与整合、建立一致性的维度、构建可复用的面向分析和统计的明细事实表以及汇总公共粒度的指标。
DWD数据明细层
DWD数据明细层:是为机构所有级别的决策制定过程,提供所有类型数据支持的战略集合,是一个包含所有主题的通用的集合;
主要工作任务:1、数据再次清洗:在ods层基础上,结构和粒度与ods保持一致,对ods层数据进行再次清洗(去空、去脏数据,去超过极限的数据);大数据层面调整压缩算法、存储格式,比如将一些后续不需要使用的如注释字段去除掉。2、进行维度退化(降维):比如说大学这个维度,在mysql中分了大学、学院、专业三个维度,那么将其合并成一个维度! sql语句比较好实现,也就是三张表合并为一张表;或者将一些编码恢复过来,如一些事务表中性别不是写的男女而是用1和2代替,就需要将其编码恢复。3、建模:这个算是这一层最主要的功能了,在这一层的建模中,你必须:① 确定建模方式(雪花模型、星型模型等); ②根据建模的方式抽取维度表和事实表。
DWS数据服务层(汇总数据层)
DWS数据服务层(汇总数据层):以DWD层为基础,进行轻度汇总,一般聚集到以用户当日、设备当日、商家当日、商品当日等等的粒度。在这层通常会有以某一维度为线索,组成跨主题的宽表,比如一个用户的当日签到数、收藏数、评论数、抽奖数、订阅数、浏览商品数、添加购物车数、下单数、支付数等组成的多列表。注意:这一层就可以理解为是一张行为宽表,以时间(每天、每周、每月)统计各种指标;
APP数据应用层(数据集市)
APP数据应用层(数据集市):以某个业务应用为出发点而建设的局部数据表,数据表只关心自己需要的数据,不会全盘考虑企业整体的数据架构和应用。每个应用有自己的数据表,提供给数据产品和数据分析使用的数据(ES\PostgreSql\Redis)等系统中供线上系统使用,也可以存在Hive或Druid中供数据分析和数据挖掘使用。
示例1:电商网站分层
电商网站的数据体系设计。暂且只关注用户访问行为及用户信息,商品信息等部分数据。

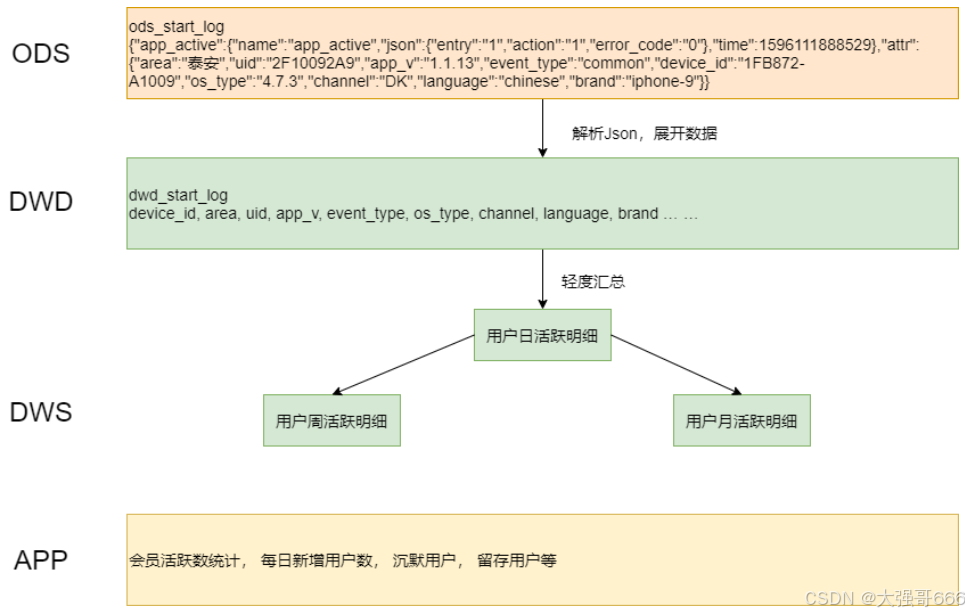
示例2:用户日志分层
用户行为日志代码分层。
Hue 环境
Hue含义
HUE相当于Hive的客户端,类似于navicat是mysql的客户端一样。Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。通过使用Hue,可以在浏览器端的Web控制台上与Hadoop集群进行交互,来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job,执行Hive的HQL语句,浏览HBase数据库等等。
Hue的功能
Hue的功能:1、访问HDFS和文件浏览;2、通过web调试和开发hive以及数据结果展示;3、通过web调试和开发impala交互式SQL Query;4、spark调试和开发;5、Pig开发和调试;6、Hbase数据查询和修改,数据展示;7、Hive的元数据(metastore)查询;8、MapReduce任务进度查看,日志追踪;9、创建和提交MapReduce,Streaming,Java job任务;9、Sqoop2的开发和调试;10、Zookeeper的浏览和编辑;11、数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示。
Hue界面应用
Hue登录界面
在浏览器中输入相应的网址,然后输入用户名密码进入Hue主界面,点击Editor下的Hive选项,进入Hive操作界面。

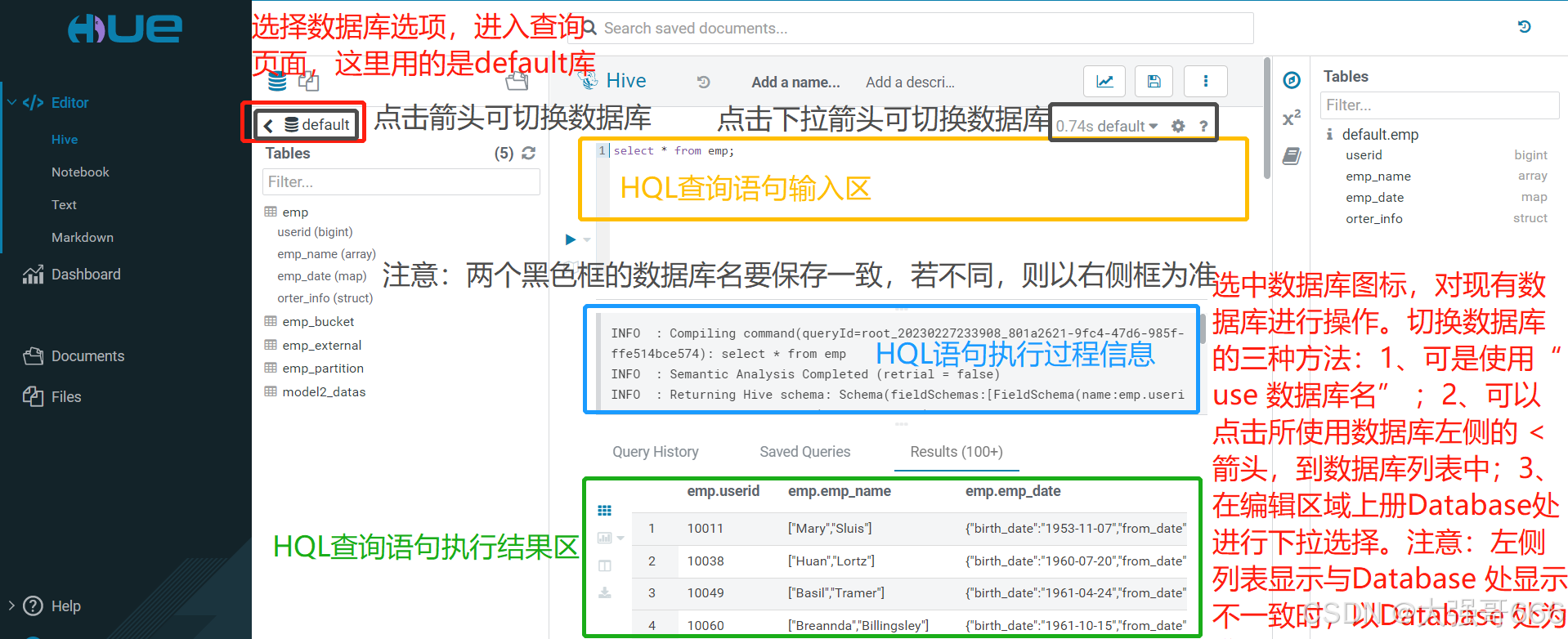
查询与切换数据库
选中“数据库”图标,对现有数据库进行操作。切换数据库的三种方法:1、可是使用“use 数据库名” ;2、可以点击所使用数据库左侧的 < 箭头,到数据库列表中;3、在编辑区域上册Database处进行下拉选择。注意:左侧列表显示与Database 处显示不一致时,以Database 处为准。
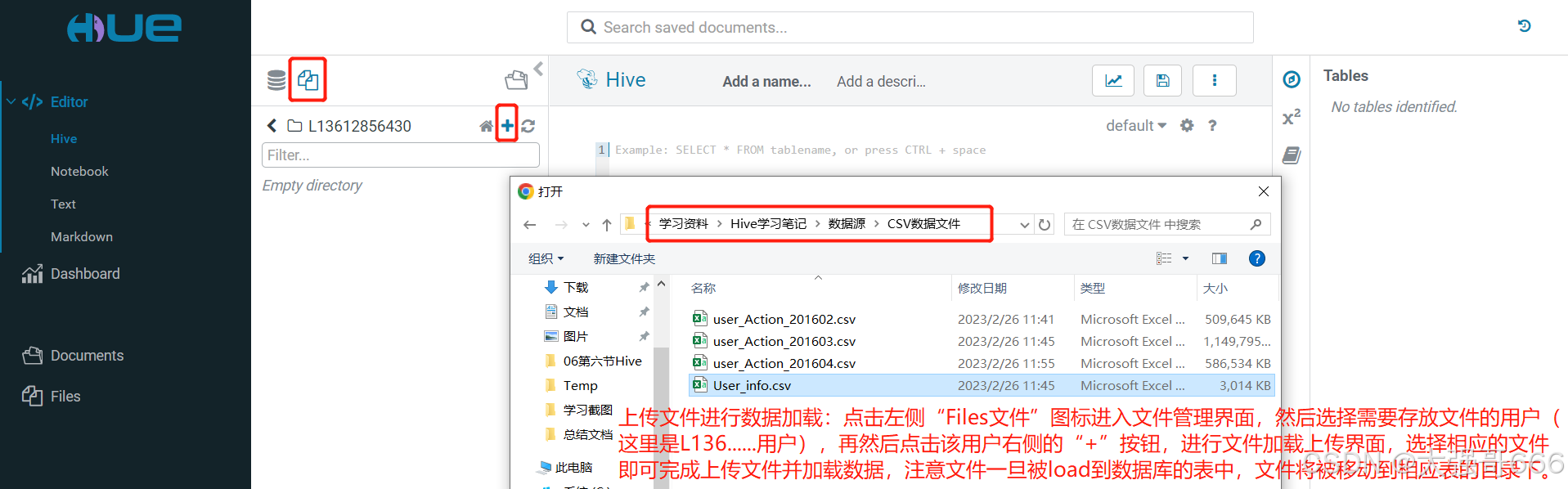
上传文件进行数据加载
上传文件进行数据加载:点击左侧“Files文件”图标进入文件管理界面,然后选择需要存放文件的用户(这里是L136…用户),再然后点击该用户右侧的“+”按钮,进行文件加载上传界面,选择相应的文件即可完成上传文件并加载数据,注意文件一旦被load到数据库的表中,文件将被移动到相应表的目录下。
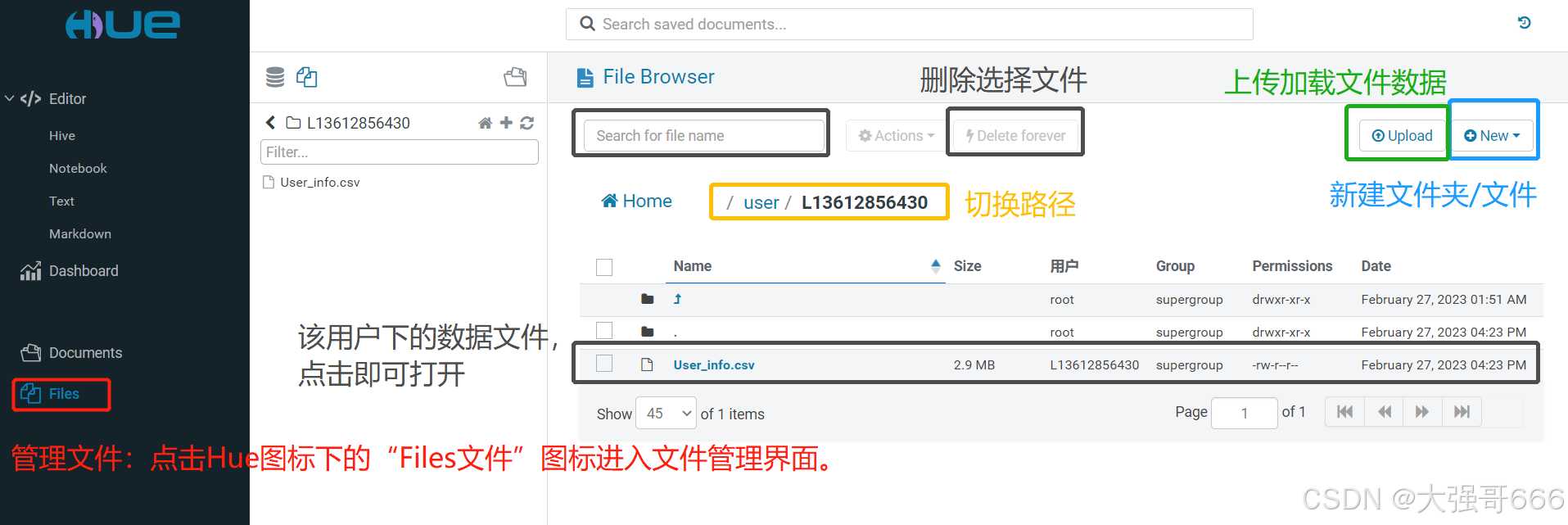
管理文件
管理文件:点击Hue图标下的“Files文件”图标进入文件管理界面。
点击打开的任意文件,可以对当前文件进行编辑或下载。
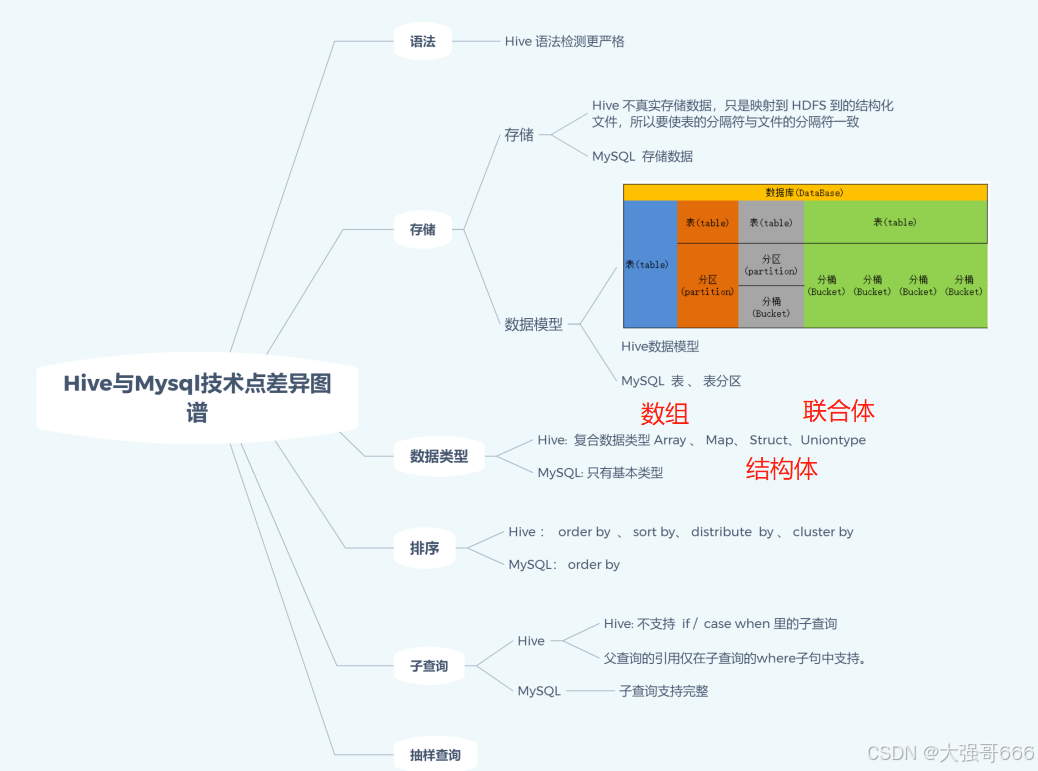
Hive与MySQL技术差异点
数据库数据表定义
Hive 语句注意事项:
Hive 语句注意事项:HQL 语言大小写不敏感,但是内容分大小写(where ,if/ case when后面所添加的条件),HDFS 路径名分大小写;2、HQL 可以写在一行或者多行;3、关键字不能被缩写也不能分行;4、各子句一般要分行写 (美化);5、使用缩进提高语句的可读性;6、-- 为注释符号。
DDL(数据库/表定义)知识图谱

创建及使用该数据库
create database if not exists liu_hive;
use liu_hive;
建表指定数据类型
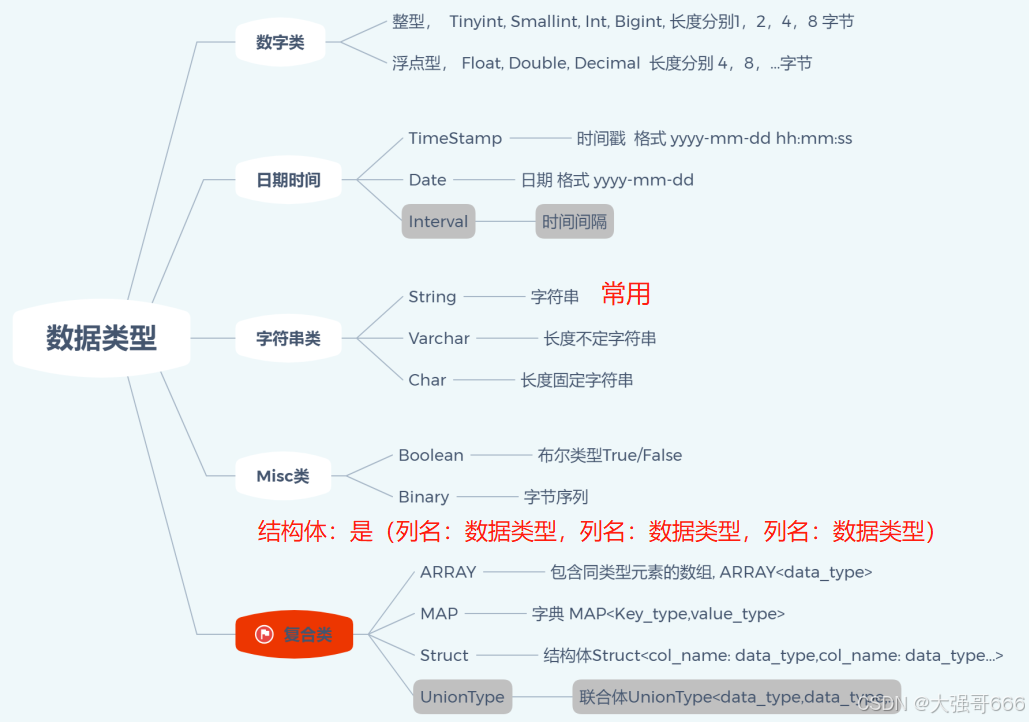
Hive常用的3复合数据类型及访问方式
数组 array : 列名[索引_从0开始]
字典 map : 列名[“key名”]
结构体: 列名.子列名。
数据类型转换
1、如果将浮点型的数据转换成int类型的,内部操作是通过round()或者floor()函数来实现的,而不是通过cast实现!
2、对于BINARY(字节序列)类型的数据,只能将BINARY(字节序列)类型的数据转换成STRING(字符串)类型。如果你确信BINARY(字节序列)类型数据是一个数字类型(a number),这时候你可以利用嵌套的cast操作。
3、对于Date类型的数据,只能在Date、Timestamp以及String之间进行转换。如:cast(列名 as 要转换的类型);convert(数据类型,列名)
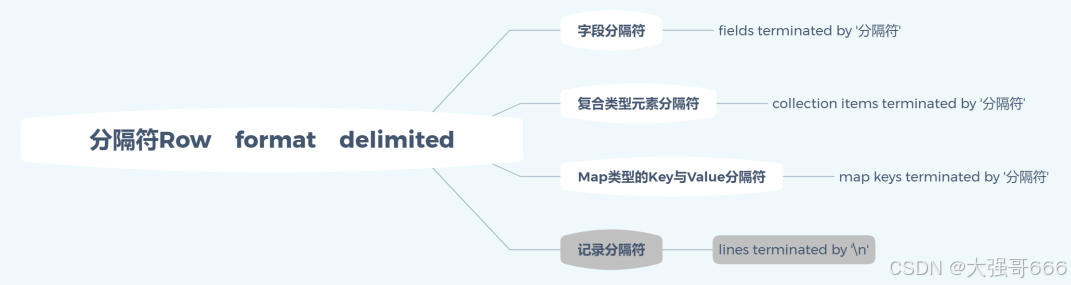
建表指定分隔符
需要指定分隔符的原因:因为Hive是不存储数据的,只是存储表到HDFS文件的映射关系,文件通常是以文本或csv存在的,而文本或csv通常是用空格,逗号,冒号等分隔符进行分开的内容。
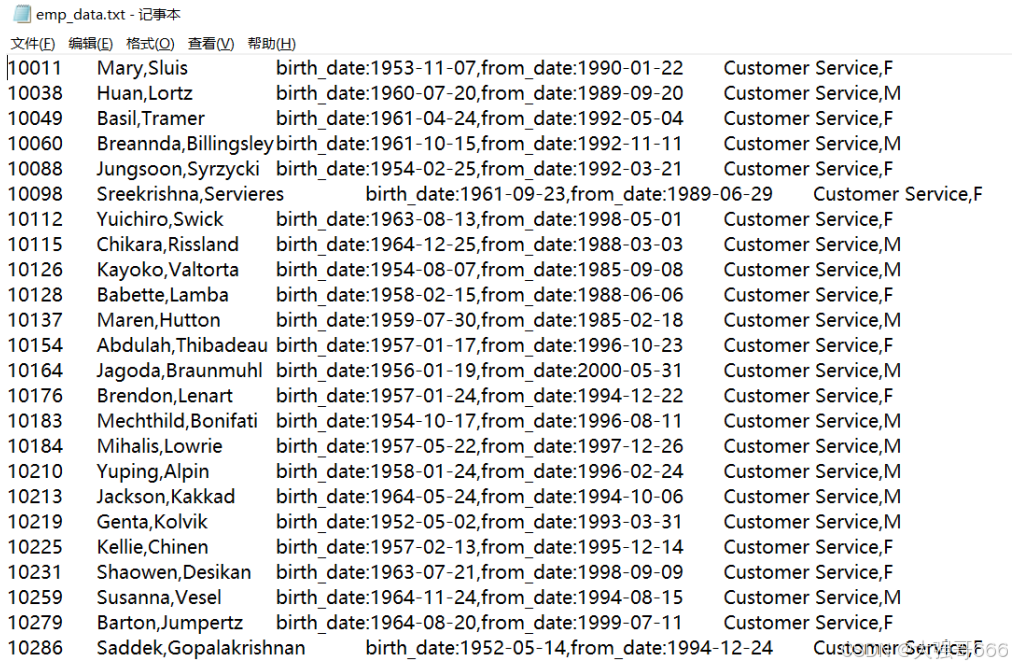
注意:先知道我们的数据,然后创建数据表及数据表里面各字段的数据类型和分隔符。如下面,已知下面的emp_data.txt文件数据情况,需要根据所给出的数据,创建数据表。
创建普通表
创建数据表语句如下:
-- 创建普通表(即没有分区,没有分桶)
CREATE TABLE emp(
userid bigint,
emp_name array<string>,
emp_date map<string,date>,
other_info struct<deptname:string, gender:string>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':';
-- 注意:三类分隔符指令都存在时,顺序不能错
分区表(分区=文件夹)
分区表技术与意义
1、避免hive全表扫描,提升查询效率。比如:where想找北京的,如果没有分区,则会从第一条到最后条找,但是有分区的话,因为每个分区相当于一个文件夹,他就会自动到存北京的文件夹中去寻找,不去其他文件夹中寻找。
2、减少数据冗余进而提高特定(指定分区)查询分析的效率。比如:有个北京分区,那我就不需要在地理字段中定义他是属于北京的哪里,他自动归到北京文件夹中。
3、在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的列值存储在表目录的子目录中,目录名为“分区键=键值”。
4、查询时尽量利用分区字段(相当于HQL优化)。如果不使用分区字段,就会全部扫描。
分区表类型
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。
创建分区表
-- 创建分区表,分区字段不能存在于字段列表中
CREATE TABLE emp_partition(
emp_no bigint,
first_name string,
last_name string,
gender string,
birth_date date,
from_date date)
partitioned by (dept_name string)
-- 创建分区语句,注意上面指定字段中压根没用“dept_name”字段,但用它做分区了,就减少了数据冗余
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
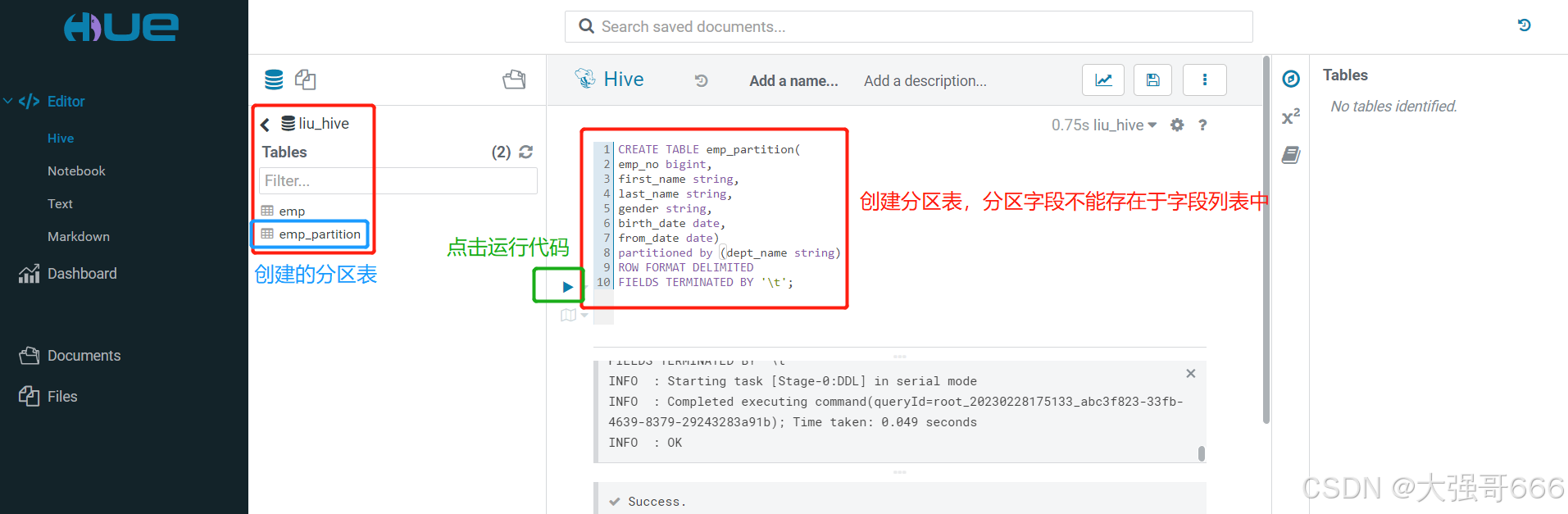
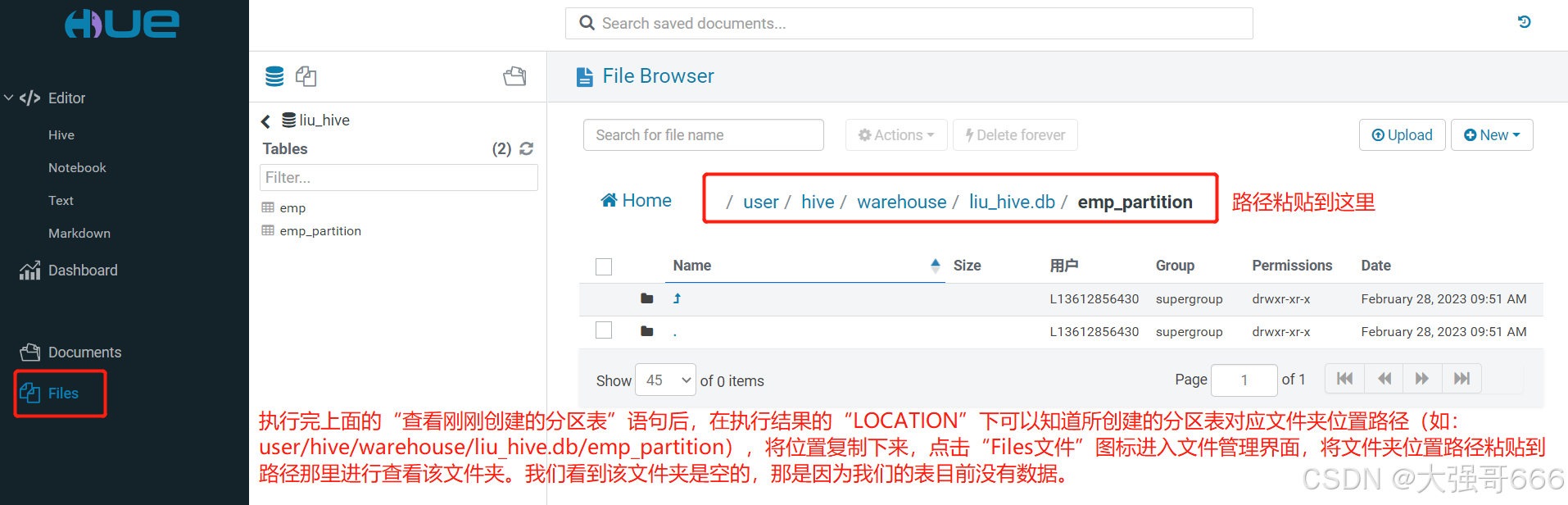
-- 查看刚刚创建的分区表,可以得到所创建的分区表对应文件夹的位置。
show create table emp_partition;
执行完上面的“查看刚刚创建的分区表”语句后,在执行结果的“LOCATION”下可以知道所创建的分区表对应文件夹位置路径(如:user/hive/warehouse/liu_hive.db/emp_partition),将位置复制下来,点击“Files文件”图标进入文件管理界面,将文件夹位置路径粘贴到路径那里进行查看该文件夹。我们看到该文件夹是空的,那是因为我们的表目前没有数据。
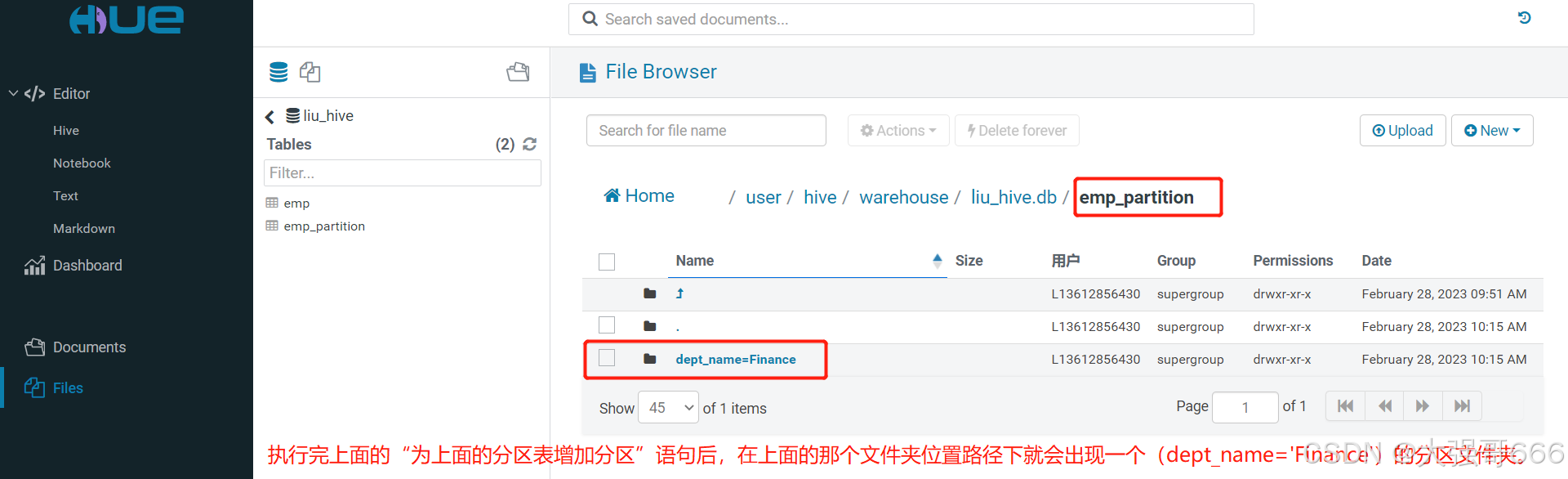
-- 为上面的分区表增加分区,其中Finance是分区字段名:
alter table emp_partition add partition(dept_name='Finance');
执行完上面的“为上面的分区表增加分区”语句后,在上面的那个文件夹位置路径下就会出现一个(dept_name=‘Finance’)的分区文件夹。
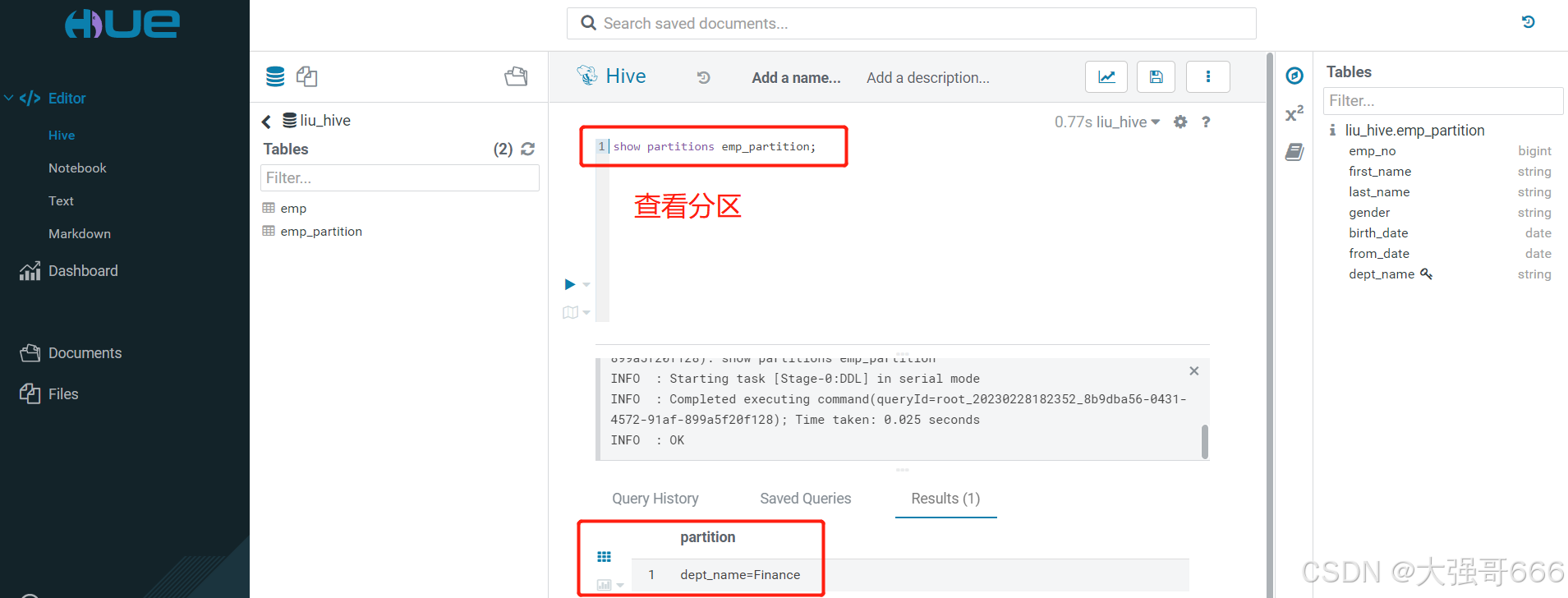
-- 查看分区
show partitions emp_partition;
分桶表(分桶=文件)
背景: 单个分区或者表中数据量越来越大,当分区不能更细粒度划分数据时,采用分桶技术将数据更细力度的划分和管理。
实质: 分桶是对分桶字段做hash 然后存到对应的文件中,逻辑上分桶与否无差异,物理上每个桶为一个文件。
作用:1、提高join 查询效率(表A的每个桶就可以和表B对应的桶直接join,而不用全表join);2、方便抽样
-- 创建分桶表
create table emp_bucket (
emp_no bigint,
first_name string,
last_name string,
gender string,
birth_date date,
from_date date,
dept_name string)
clustered by(gender) into 2 buckets
-- 创建分桶语句,因为性别要么男要么女,所以分成两个桶
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
分区表与分桶表的作用
分区表产生不同的目录: 避免全表扫描。
分桶表产生不同的文件:使 jion 速度更快和桶抽样。
外部表与内部表
外部表与内部表的区别:
| 内部表 | 外部表 | |
|---|---|---|
| 关键字 | 无 | external |
| 位置 | hive\metastore\warehouse | Location 指定 |
| 数据 | Hive自身管理(删除表直接删除元数据、存储数据) | HDFS管理(删除表仅会删除元数据,存储数据 并不会被删除) |
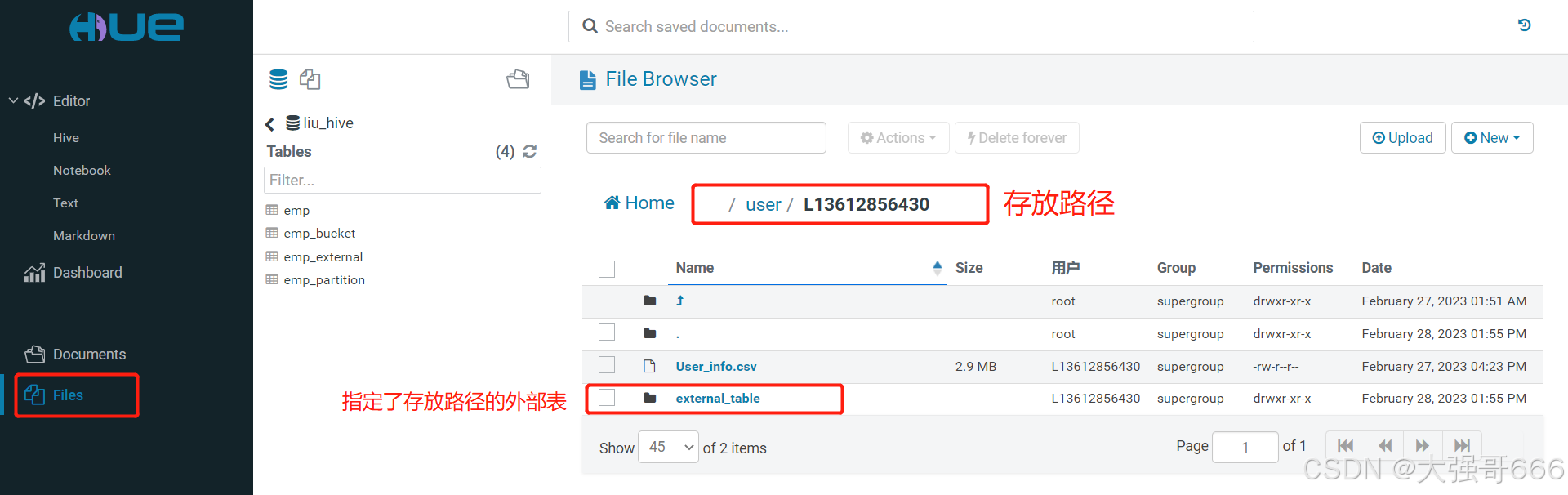
创建外部表,除了这个是外部表,之前创建的数据表都是内部表。
-- 创建外部表,有自动创建文件夹的功能
create external table emp_external(
emp_no bigint,
first_name string,
last_name string,
gender string,
birth_date date,
from_date date,
dept_name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
location '/user/L13612856430/external_table/emp_external';
-- 指定外部表存放的位置
数据导入导出及删除
注意:导入导出的数据表文件都存放在linux下的HDFS下,而并非什么C盘,D盘。另外数据入仓后,最好不要去改表,改字段等。

装载/插入数据
普通表装载/插入数据
普通表:load data【 local 】 inpath ‘数据文件路径’ [overwrite] into table 表名 ;其中local: 指的是放入到Liunx系统上的文件;而overwrite: 关键字表示覆盖原有数据,没有此关键字表示添加数据。
第一步,跟之前的上传文件进行数据加载步骤一样:点击左侧“Files文件”图标进入文件管理界面,然后选择需要存放文件的用户(这里是L136…用户),再然后点击该用户右侧的“+”按钮,进行文件加载上传界面,选择相应的文件即可完成上传文件并加载数据。
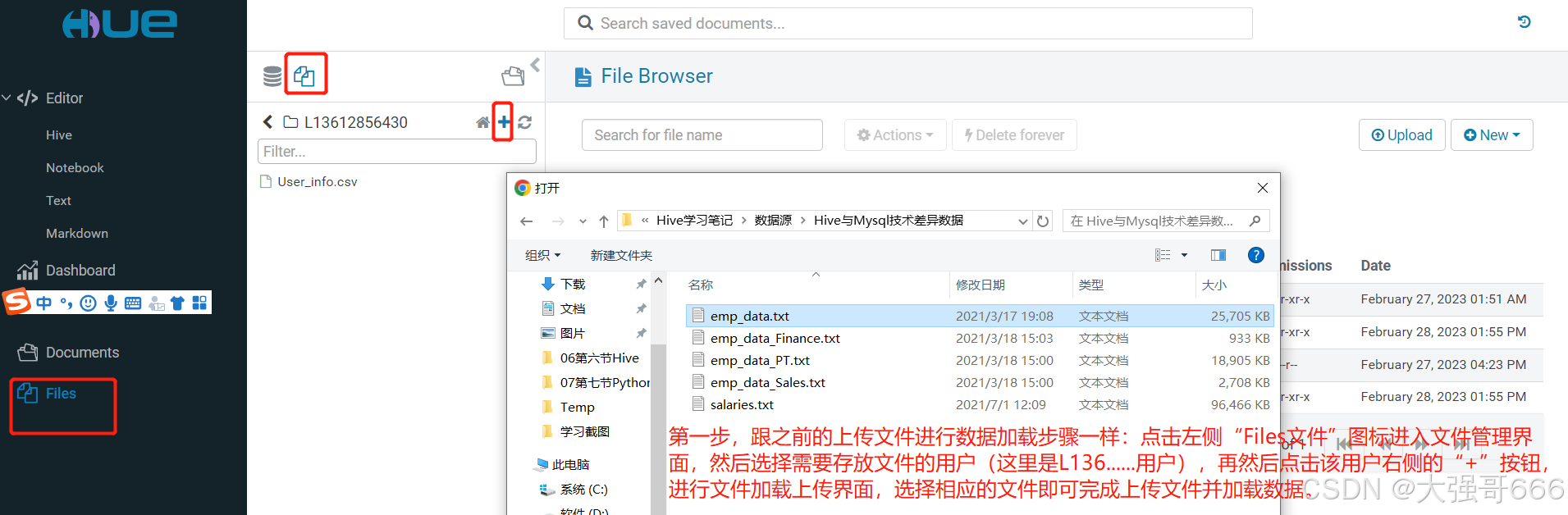
看上传过来的数据,跟之前创建的普通表(emp表)相同。地址路径为:‘/user/L13612856430/emp_data.txt’
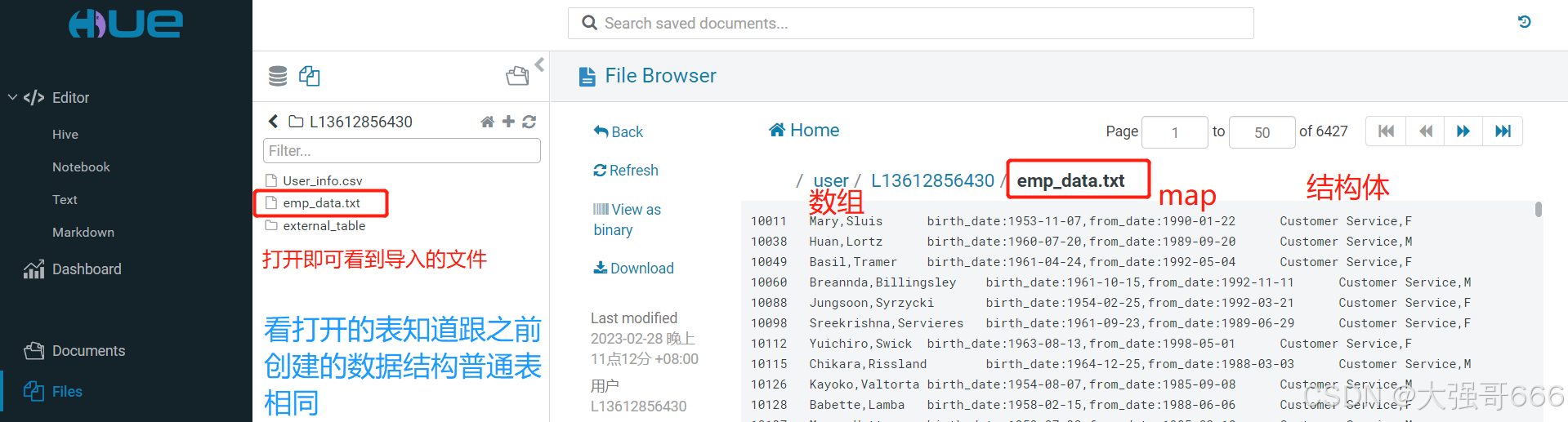
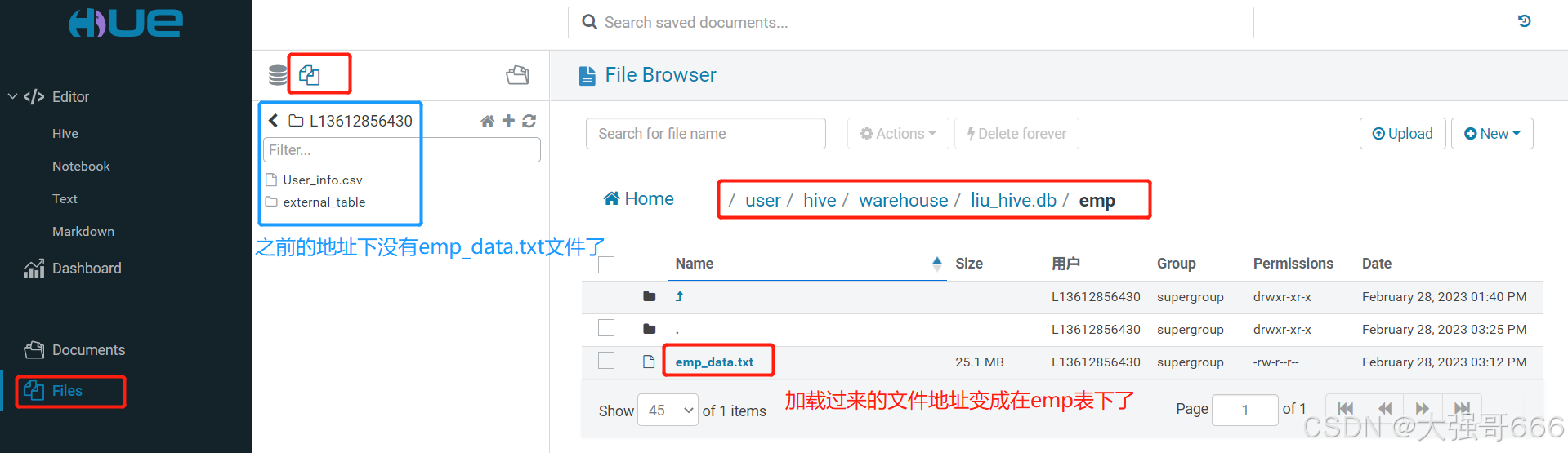
第二步:在Hue的代码书写区书写下面的第一行代码并运行该代码。注意:执行完下面的加载语句后,“emp_data.txt”就不在原来的“/user/L13612856430”路径下了,而是存放在普通表(emp表)所在路径下了,跟上面的“创建分区表”章节中查看表的地址路径相同,执行下面第三行代码,就知道其路径了,将路径复制下来,然后点击“Files文件”图标进入文件管理界面,将文件夹位置路径粘贴到路径那里进行查看到“emp_data.txt”文件了。
-- 执行下面代码加载数据到普通表(emp表)中
load data inpath '/user/L13612856430/emp_data.txt' overwrite into table emp;
-- 执行下面代码看是否加载成功
select count(*) from emp;
-- 执行下面代码查看普通表(emp表)所在地址,从而知道“emp_data.txt”文件地址
show create table emp;
分区表装载/插入数据
分区表:load data【local】inpath ‘数据文件路径’ [overwrite] into table 表名 partition (分区字段=值);
任务一:向已存在的分区的分区表中加载数据(创建分区表中已经创建了该分区(即dept_name='Finance’分区))
第一步与之前普通表相同,先完成“上传文件进行数据加载”,略。看上传过来的数据,跟之前创建的分区表(emp_partition表)相同。地址路径为:‘/user/L13612856430/emp_data_Finance.txt’
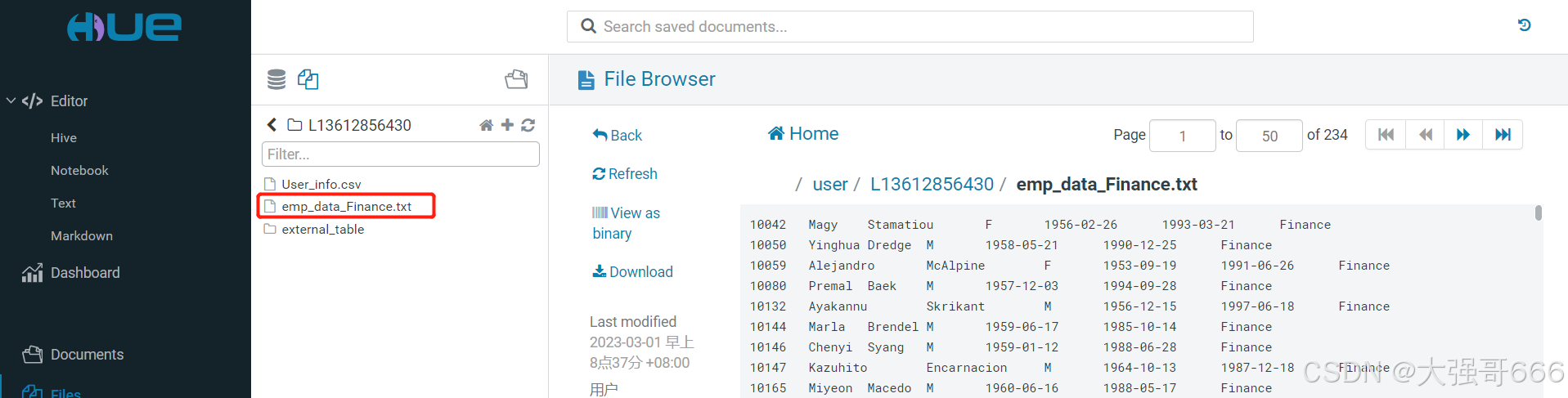
第二步:在Hue的代码书写区书写下面的第一行代码并运行该代码。其余同之前的普通表,略。
-- 执行下面代码加载数据到分区表(emp_partition表)中
load data inpath '/user/L13612856430/emp_data_Finance.txt' into table emp_partition
partition(dept_name='Finance');
-- 执行下面代码是否加载成功
select count(*) from emp_partition;
-- 执行下面代码查看分区表(emp_partition表)所在地址,从而知道“emp_data_Finance.txt”文件地址
show create table emp_partition;
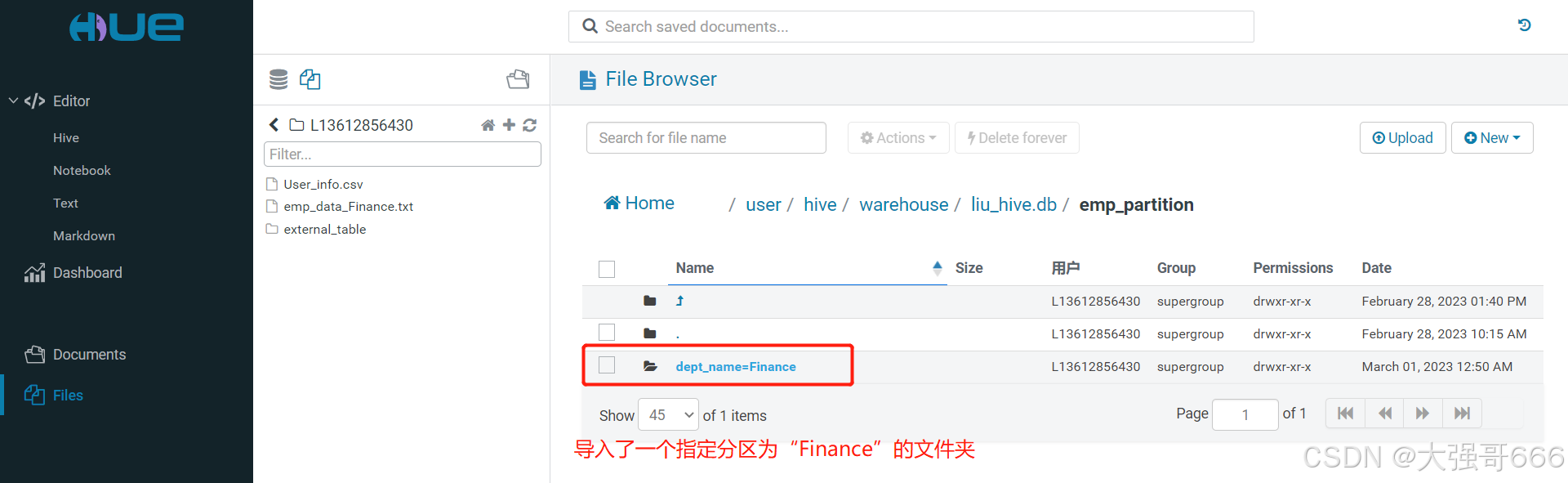
任务二:添加数据时自动创建某个分区(因为创建分区表章节没有创建“sales销售分区”)
第一步和第二步与上面的任务一相同,略,运行下面代码即可。
-- 执行下面代码加载数据到分区表(emp_partition表)中
load data inpath '/user/L13612856430/emp_data_Sales.txt' into table emp_partition
partition(dept_name='Sales');
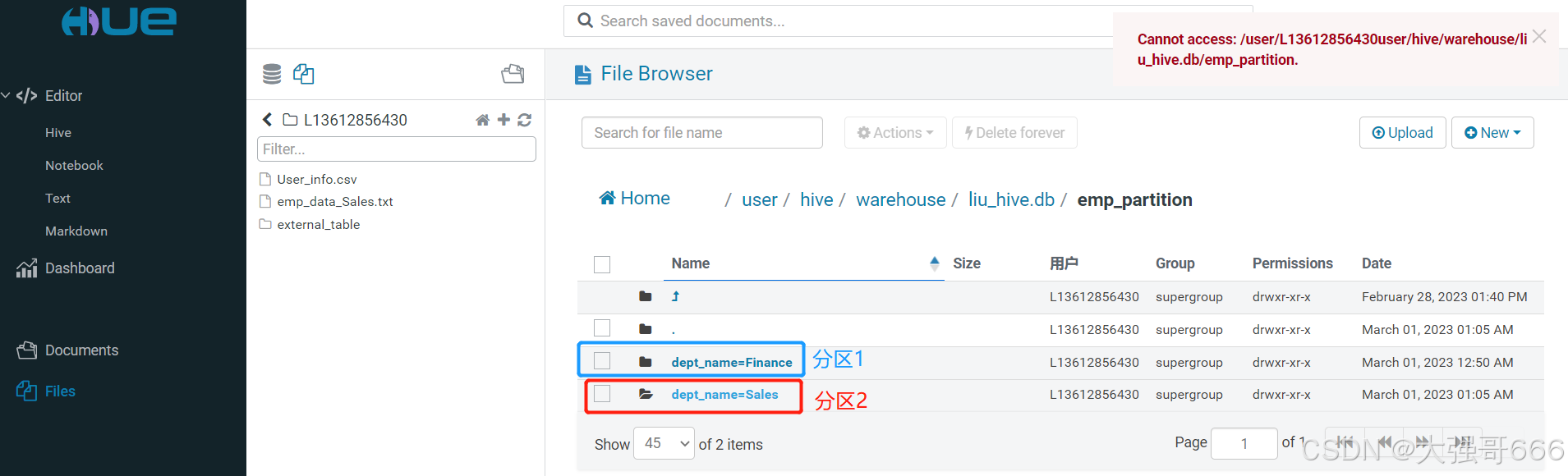
任务三:根据数据自动创建多个分区
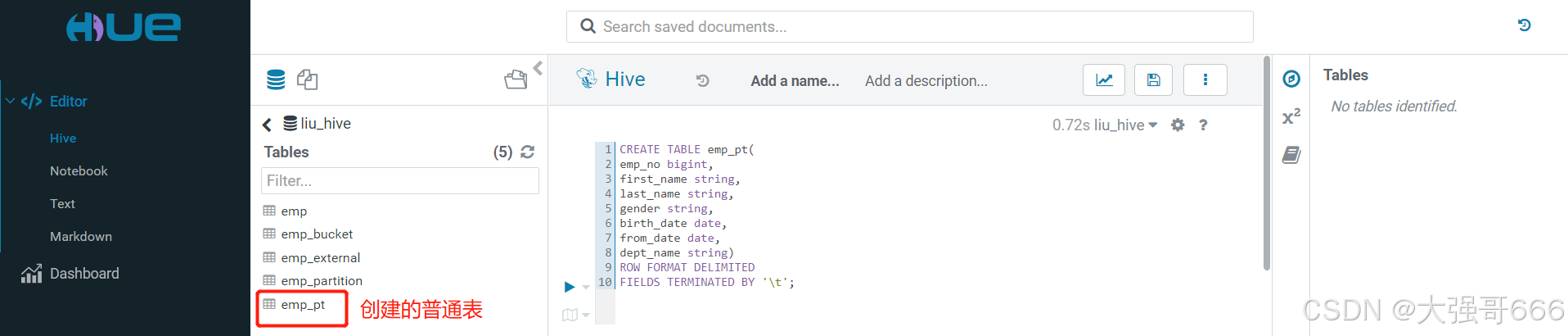
1、创建一个普通表
CREATE TABLE emp_pt(
emp_no bigint,
first_name string,
last_name string,
gender string,
birth_date date,
from_date date,
dept_name string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
2、向普通表里加载全部数据(分步骤同上面的普通表装载/插入数据章节)
load data inpath '/user/L13612856430/emp_data_PT.txt' into table emp_pt;
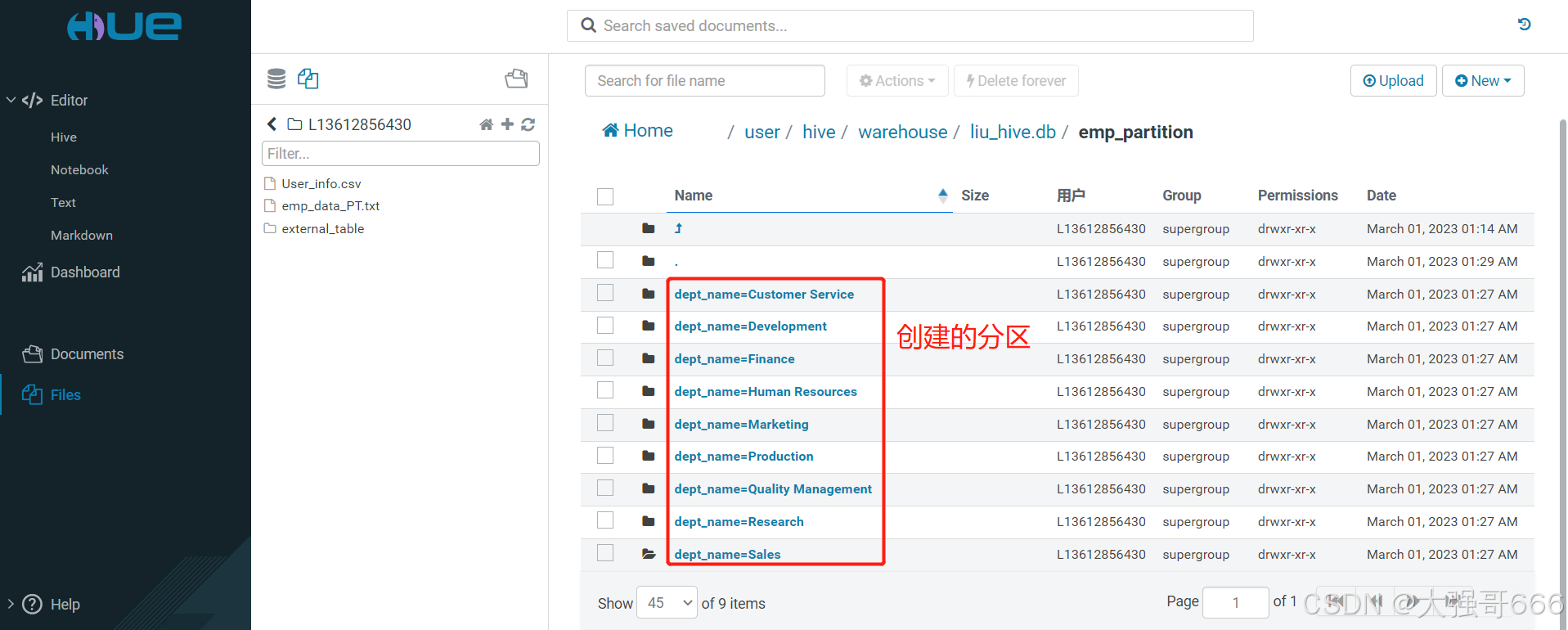
3、把普通表的数据插入到分区表中
--开启动态分区开关
set hive.exec.dynamic.partition.mode=nonstrict;
--通过insert 语句自动分区
insert overwrite table emp_partition partition(dept_name)
select * from emp_pt;
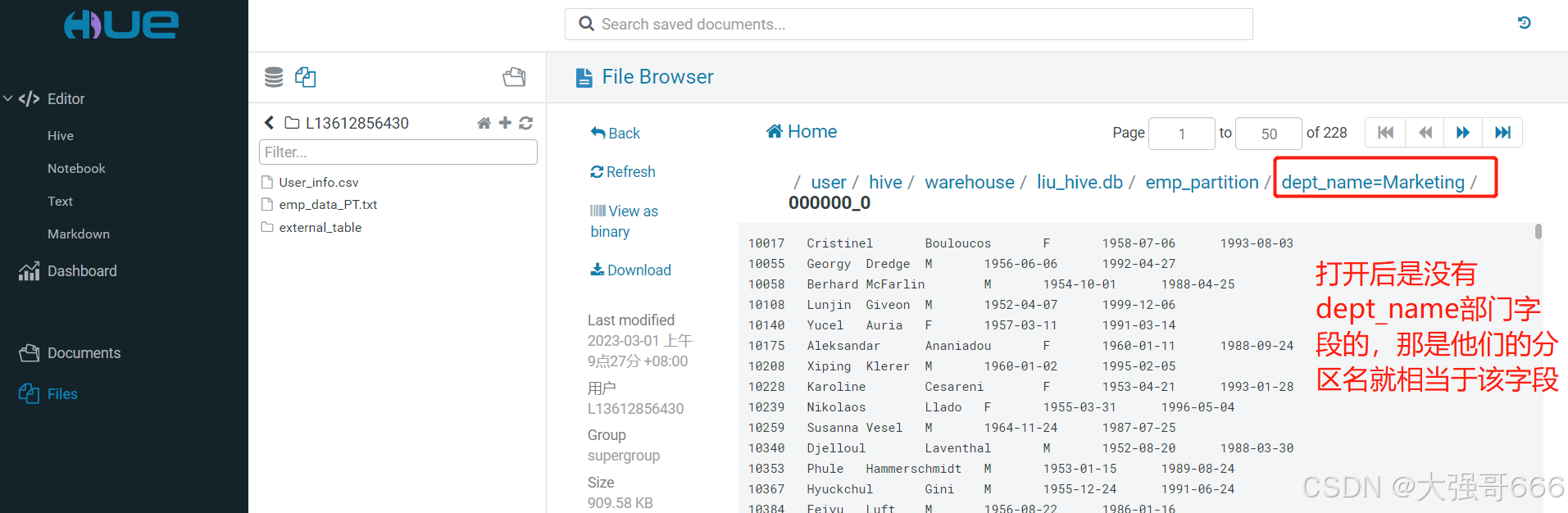
分桶表装载/插入数据与普通表一致
其余步骤与之前的普通表装载/插入数据章节相同,略。依次执行下面的代码即可。
-- 开启分桶功能
set hive.enforce.bucketing=true
-- 忽略掉安全检查
set hive.strict.checks.bucketing=false;
-- 执行下面代码加载数据到分桶表(emp_bucket表)中
load data inpath '/user/L13612856430/emp_data_Sales.txt' into table emp_bucket;
根据之前的性别来进行分桶,分成了两个文件,一个文件只含男性,另一个只含女性。注意:hue不支持像分桶表中Load data 数据。
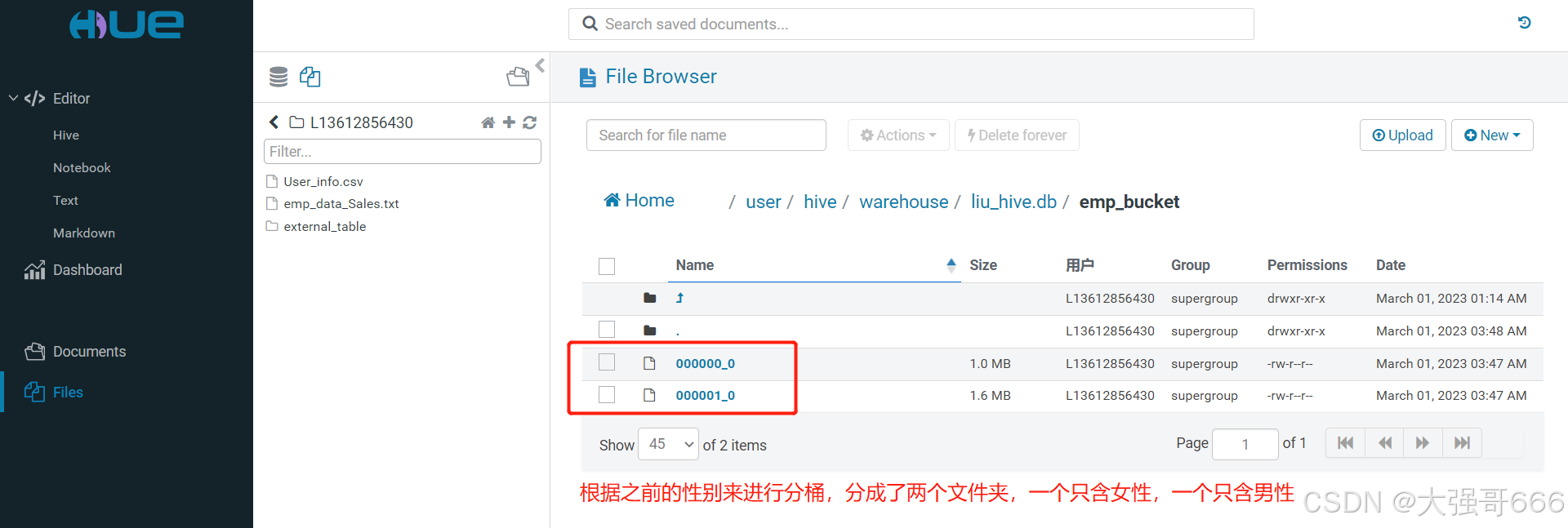
导出数据
INSERT OVERWRITE DIRECTORY ‘文件夹路径’ ROW FORMAT DELIMITED FIELDS TERMINATED by ‘字段分隔符’ 查询语句;
注意: OVERWRITE 把指定的文件夹重写了 (一定要小心覆盖掉有用的文件);默认分隔符是用语句指定的,和本身建表语句指定的没有关系;有新建文件夹功能;导出的文件都为000000_0命名。
任务:将普通表导出到HDFS中。执行下面的程序就可以在“/user/L13612856430”下新建一个“out_data”文件夹,该文件夹下有个以“000000_0”命名的新文件就是导出的文件,勾选该文件前面,在顶部“Actions”按钮下拉框下就可以进行“重命名/复制/下载”等操作。
INSERT OVERWRITE DIRECTORY '/user/L13612856430/out_data'
ROW FORMAT DELIMITED FIELDS TERMINATED by '\t'
select * from emp_pt;
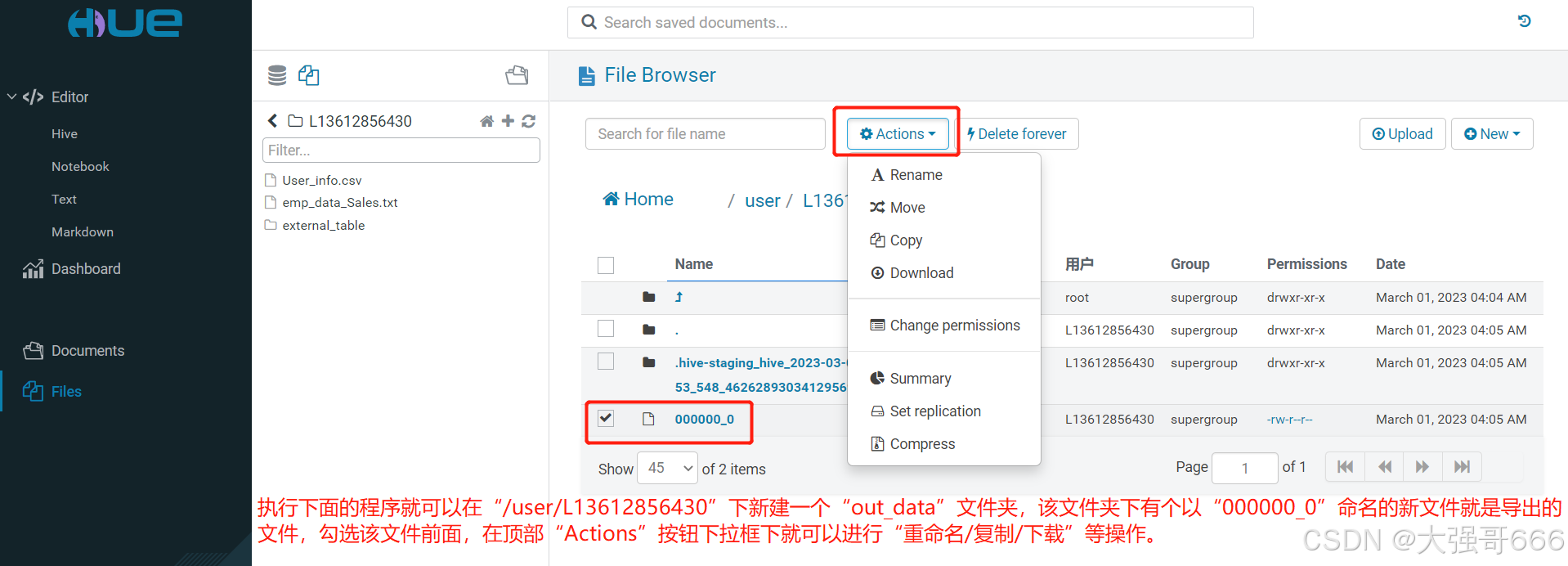
删除数据
删除所有数据
使用truncate仅可删除内部表数据,不可删除表结构,truncate table 表名
--删除内部数据
truncate table emp_pt;
使用shell命令删除外部表数据(hdfs dfs -rm -r 外部表路径)
-- 删除外部表数据
hdfs dfs -rm -r /user/admin/external_table/emp_external/*
-- 文件列表内直接删除
删除表部分数据
有partition(分区)表
1、删除指定分区 : alter table table_name drop partition(partiton_name=‘value’))
--删除指定分区
alter table emp_partition drop partition(dept_name = 'Sales');
2、删除partition内的部分信息(INSERT OVERWRITE TABLE)
INSERT OVERWRITE TABLE emp_partition partition(dept_name='Finance')
SELECT * FROM emp_partition
WHERE dept_name='Finance' and gender = "F";
重新把对应的partition信息写一遍,通过WHERE 来限定需要留下的信息,没有留下的信息就被删除了。
无partiton(分区)表
INSERT OVERWRITE TABLE 表名 SELECT * FROM 表名 WHERE 条件;
Insert overwrite table emp_pt select * from emp_pt where gender = "F";
DQL数据库(select)查询语句
内置运算符
关系运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| 普通运算 | 所有基本类型 | A = B、A != B、A < B、A <= B、A > B、A >= B |
| A [NOT] BETWEEN B AND C | 基本数据类型 | 如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且 小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可 达到相反的效果 |
| A IS [NOT] NULL | 所有类型 | 如果A等于NULL,则返回TRUE,反之返回FALSE, NOT 正好相反 |
| A IN(数值 1, 数值2) | 所有类型 | 如果A存在指定的数据中,则返回TRUE,反之返回FALSE |
| A [NOT] LIKE B | 字符串 | 如果A与B匹配的话,则返回TRUE;反之返回FALSE。%代表任意多个字 符,_代表一个字符 |
| A RLIKE B | 字符串 | 如果A或B为NULL;如果A任何子字符串匹配Java正则表达式B;否则 FALSE |
| A REGEXP B | 字符串 | 等同于RLIKE |
算术运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| 四则运算 | 所有数字类型 | A + B、A - B、A * B 、A / B |
| A%B | 所有数字类型 | A除以B所产生的余数 |
逻辑运算符
| 运算符 | 操作 | 描述 |
|---|---|---|
| A AND B 、A && B | boolean | 如果A和B都是TRUE时为TRUE,否则FALSE |
| A OR B、 A||B | boolean | 如果A或B或两者都是TRUE时为TRUE,否则FALSE |
| NOT A、 !A | boolean | 如果A是FALSE时为TRUE,否则FALSE |
复合运算符(hive有,mysql没有)
| 运算符 | 操作 | 描述 |
|---|---|---|
| A[n] | A是一个数组,n是一个int | 它返回数组A的第n个元素,第一个元素的索 引0 |
| M[key] | M 是一个 Map<K, V> 并 key 的类型 为K | 它返回对应于映射中关键字的值 |
| S.x | S 是一个结构 | 它返回S的s字段 |
内置函数
数学函数
| 返回类型 | 语法 | 描述 |
|---|---|---|
| BIGINT或DOUBLE | round(double a) round(double a, int d) | 返回double类型的整数值部分(遵循四舍五入)返回指定精度d的double类型 |
| BIGINT | floor(double a) ceil(double a) | 返回等于或者小于该double变量的最大的整数,返回等于或者大于该double变量的最小的整数 |
| DOUBLE | rand()或rand(int seed) | 返回一个0到1范围内的随机数。如果指定种子seed,则会等到一个稳定的随机数序列 |
| DOUBLE | pow(double a, double p)、sqrt(double a) | 返回a的p次幂、返回a的平方根 |
| DOUBLE或INT | abs(double a)或abs(int a) | 返回数值a的绝对值 |
日期函数
| 返回类型 | 语法 | 描述 |
|---|---|---|
| STRING | from_unixtime(bigint unixtime[, string format]) | 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数) 到当前时区的时间格式 |
| BIGINT | unix_timestamp() unix_timestamp(string date) unix_timestamp(string date, string pattern) | 获得当前时区的UNIX时间戳 转换格式为"yyyy-MM-dd HH:mm:ss"的日期到UNIX时间戳。如果转化失败,则返回0转换pattern格式的日期到UNIX时间戳。 如果转化失败,则返回0 |
| STRING或 Int | to_date(string timestamp) year(string date) month (string date) day (string date) hour (string date)minute (string date) second (string date) weekofyear (string date) | 返回日期时间字段中的日期部分、年 、 月、 天、时、 分 、秒 |
| INT | datediff(string enddate, string startdate) | 返回结束日期减去开始日期的天数 日期 有格式要求 yyyy-mm-dd hh:MM:ss 或 yyyy-mm-dd |
| STRING | date_add(string startdate, int days)、 add_months(string startdate, int months) date_sub (string startdate, int days) | 返回开始日期startdate增加days天后的 日期 返回开始日期startdate增加months 月后的日期 返回开始日期startdate减少 days天后的日期 |
条件判断函数
| 返回类型 | 语法 | 描述 |
|---|---|---|
| T | if(boolean testCondition, valueTrue, valueFalseOrNull) | 当条件testCondition为TRUE时,返回 valueTrue;否则返回valueFalseOrNull |
| T | CASE a WHEN b THEN c [WHEN d THEN e] [ELSE f] END | 如果a等于b,那么返回c;如果a等于d,那么返 回e;否则返回f |
| T | CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | 如果a为TRUE,则返回b;如果c为TRUE,则返回 d;否则返回e |
字符串函数
| 返回类型 | 语法 | 描述 |
|---|---|---|
| INT | length(string A) | 返回字符串A的长度 |
| STRING | reverse(string A) | 返回字符串A的反转结果 |
| STRING | concat(string A, string B…) | 返回输入字符串连接后的结果,支持任 意个输入字符串 |
| STRING | concat_ws(string SEP, string A, string B…) | 返回输入字符串连接后的结果,SEP表示 各个字符串间的分隔符 |
| STRING | substr(string A, int start),substring(string A, int start) substr(string A, int start, int len),substring(string A, int start, int len) | 返回字符串A从start位置到结尾的字符串 返回字符串A从start位置开始,长度为 len的字符串 |
| STRING | upper(string A) ucase(string A) | 返回字符串A的大写格式 |
| STRING | lower(string A) lcase(string A) | 返回字符串A的小写格式 |
| STRING | trim(string A) ltrim(string A) rtrim(string A) | 去除字符串两边的空格 除字符串左边的 空格 去除字符串右边的空格 |
| STRING | regexp_replace(string A, string B, string C) | 将字符串A中的符合java正则表达式B的 部分替换为C |
| STRING | regexp_extract(string subject, string pattern, int index) | 将字符串subject按照pattern正则表达式 的规则拆分,返回index指定的字符 |
| STRING | parse_url(string urlString, string partToExtract [, string keyToExtract]) | 返回URL中指定的部分。partToExtract 的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO |
| STRING | get_json_object(string json_string, string path) | 解析json的字符串json_string,返回path 指定的内容。如果输入的json字符串无 效,那么返回NULL |
| STRING | space(int n) | 返回长度为n的空格字符串 |
| STRING | repeat(string str, int n) | 返回重复n次后的str字符串 |
| STRING | lpad(string str, int len, string pad) rpad(string str, int len, string pad) | 将str进行用pad进行左补足到len位 将 str进行用pad进行右补足到len位 |
| ARRAY | split(string str, string pat) | 按照pat字符串分割str,会返回分割后的 字符串数组 |
| INT | find_in_set(string str, string strList) 如:find_in_set(‘ab’,‘aa,ab,ac’) | 返回str在strlist第一次出现的位置, strlist是用逗号分割的字符串。如果没有 找该str字符,则返回0 |
| INT | instr(string str, string substr) instr(“abcde”,“ab”) | 返回substr在str中第一次出现的位置, 未出现则返回0(如果参数为NULL则返 回NULL;位置从1开始) |
统计函数
| 返回类型 | 语法 | 描述 |
|---|---|---|
| INT | count(*), count(expr), count(DISTINCT expr[, expr_.]) | count(*)统计检索出的行的个数,包括NULL值的行; count(expr)返回指定字段的非空值的个数;count(DISTINCT expr[, expr_.])返回指定字段的不同的非空值的个数 |
| DOUBLE | sum(col), sum(DISTINCT col) | sum(col)统计结果集中col的相加的结果;sum(DISTINCT col)统计结果中col不同值相加的结果 |
| DOUBLE | avg(col), avg(DISTINCT col) | avg(col)统计结果集中col的平均值;avg(DISTINCT col)统计 结果中col不同值相加的平均值 |
| DOUBLE | min(col) max(col) | 统计结果集中col字段的最小值 统计结果集中col字段的最大 值 |
| DOUBLE | var_pop(col) var_samp (col) | 统计结果集中col非空集合的总体方差 统计结果集中col非空 集合的样本变量 |
| DOUBLE | stddev_pop(col) stddev_samp (col) | 统计结果集中col非空集合的总体标准差 统计结果集中col非 空集合的样本标准差 |
| DOUBLE | percentile(BIGINT col, p) | 求准确的第p个百分位数,p必须介于0和1之间,但是col字段 目前只支持整数,不支持浮点数类型 |
| ARRAY | percentile(BIGINT col, array(p1 [, p2]…)) | 功能和上述类似,之后后面可以输入多个百分位数,返回类 型也为array,其中为对应的百分位数 |
复合类型构建访问函数
| 返回类型 | 语法 | 描述 |
|---|---|---|
| MAP | map (key1, value1, key2, value2, …) | 根据输入的key和value对构建map类型 |
| STRUCT | struct(val1, val2, val3, …) | 根据输入的参数构建结构体struct类型 |
| ARRAY | array(val1, val2, …) | 根据输入的参数构建数组array类型 |
| … | A[n] | 返回数组A中的第n个变量值。数组的起始下标为0。 |
| … | M[key] | 返回map类型M中,key值为指定值的value值 |
| … | S.x | 返回结构体S中的x字段 |
| INT | size(Map<K.V>) size(Array) | 返回map类型的长度 返回array类型的长度 |
| … | explode(map | array) | 列变行(炸列函数) |
| ARRAY | collect_set ( col) | 对col行变列并 去重 |
| ARRAY | collect_list ( col) | 对col行变列并不去重 |
| ARRAY | map_keys(map) | 取map类型的所有Key |
| ARRAY | map_values(map) | 取map类型的所有value |
| T | array_contains(array,obj) | 判断指定的obj 是否村在数组中 |
Select 语句结构
注意:如果下列语句的子指令都存在,则HQL语句书写顺序绝对不能变。
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]][ORDER BY
col_list]
[LIMIT number];
HQL语句与Mysql语句执行顺序对比
查看HQL语句执行顺序(explain语句),相对于mysql语句的执行顺序,HQL将select提前了,因为在MapReduce(分布式计算)中系统将group by分组语句和聚合函数放在了Reduce中进行执行。注意:Group by 后 select 只能有 group by 的字段和聚合函数。
from -->where --> select --> group by -->聚合函数--> having --> order by -->limit
MySQL 语句执行顺序:
from-->where --> group by -->聚合函数--> having--> select --> order by -->limit
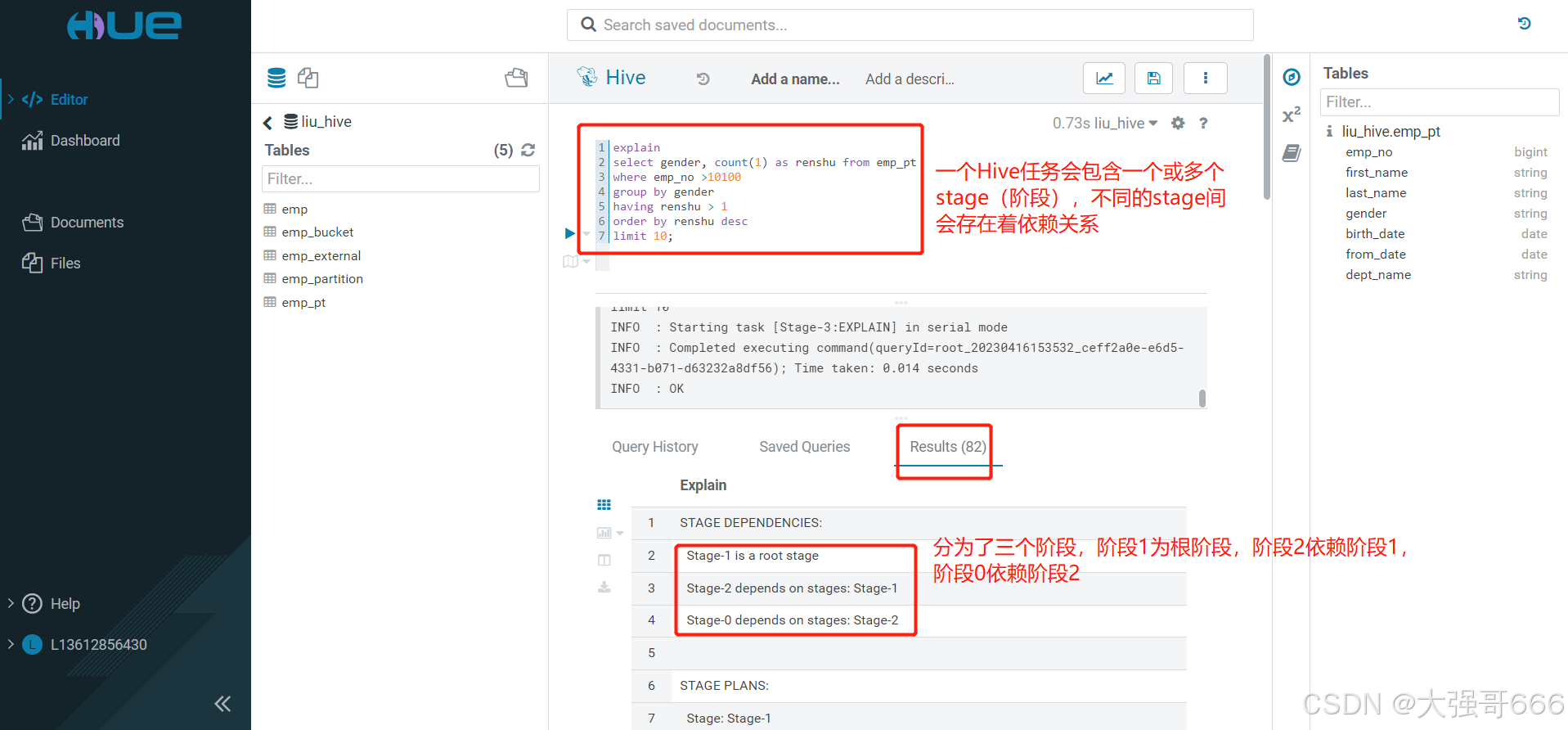
一个Hive任务会包含一个或多个stage(阶段),不同的stage间会存在着依赖关系
explain
select gender, count(1) as renshu from emp_pt
where emp_no >10100
group by gender
having renshu > 1
order by renshu desc
limit 10;
复合类型的数据查询
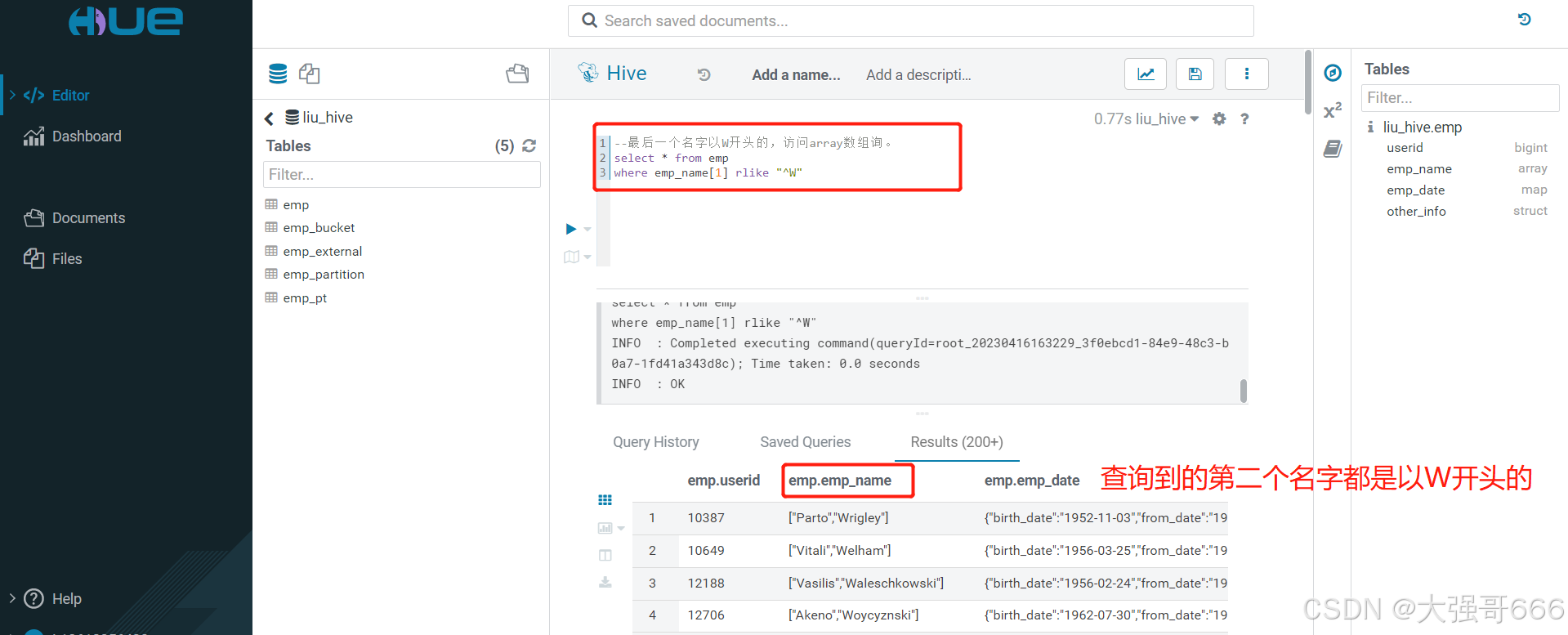
数组(array) 引用方式:列名[元素索引_以0开始]
--最后一个名字以W开头的,访问array数组,like类似mysql模糊查询,但是rlike却是正则匹配查询。
--下面两个HQL语句效果相同。
select * from emp
where emp_name[1] rlike "^W";
select * from emp
where emp_name[1] like "W%";
map(字典)引用方式为:列名[“Key”]
--出生日期是在5几年 访问Map字典,to_date是转换为日期时间类型
select * from emp
where emp_date["birth_date"] between to_date("1950-1-1")
and to_date("1959-12-31")
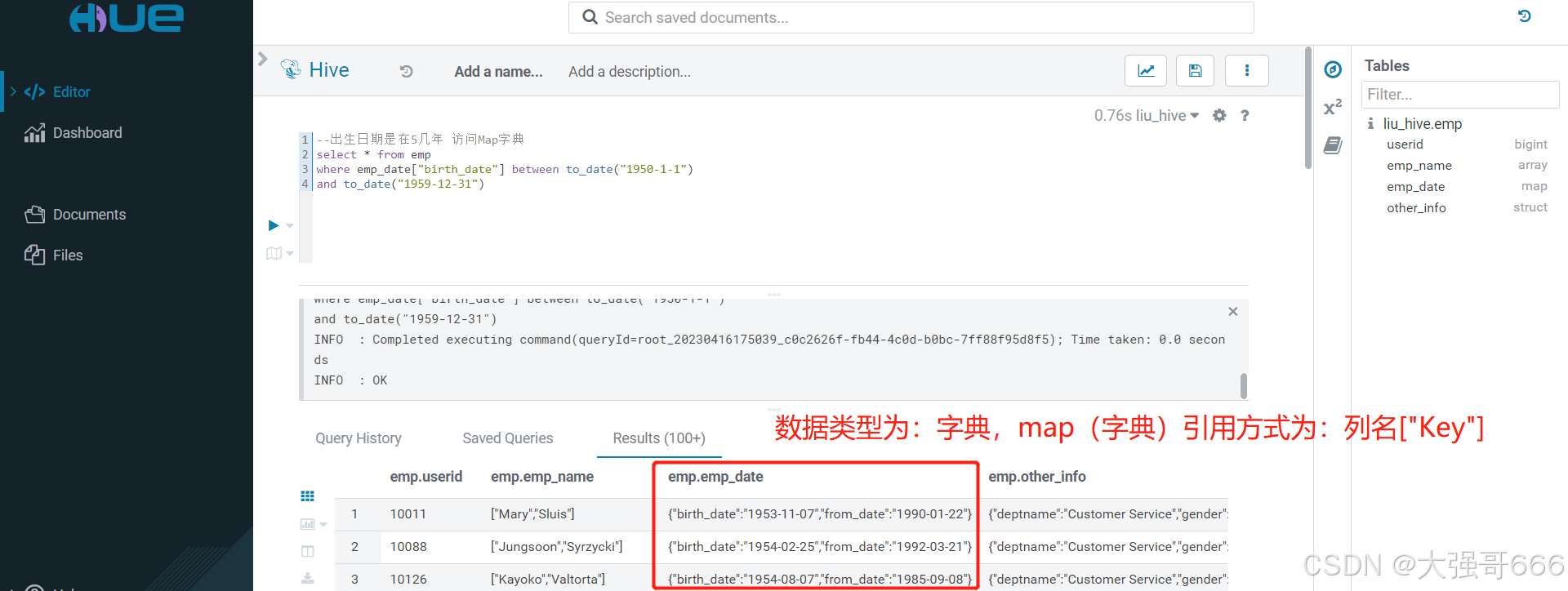
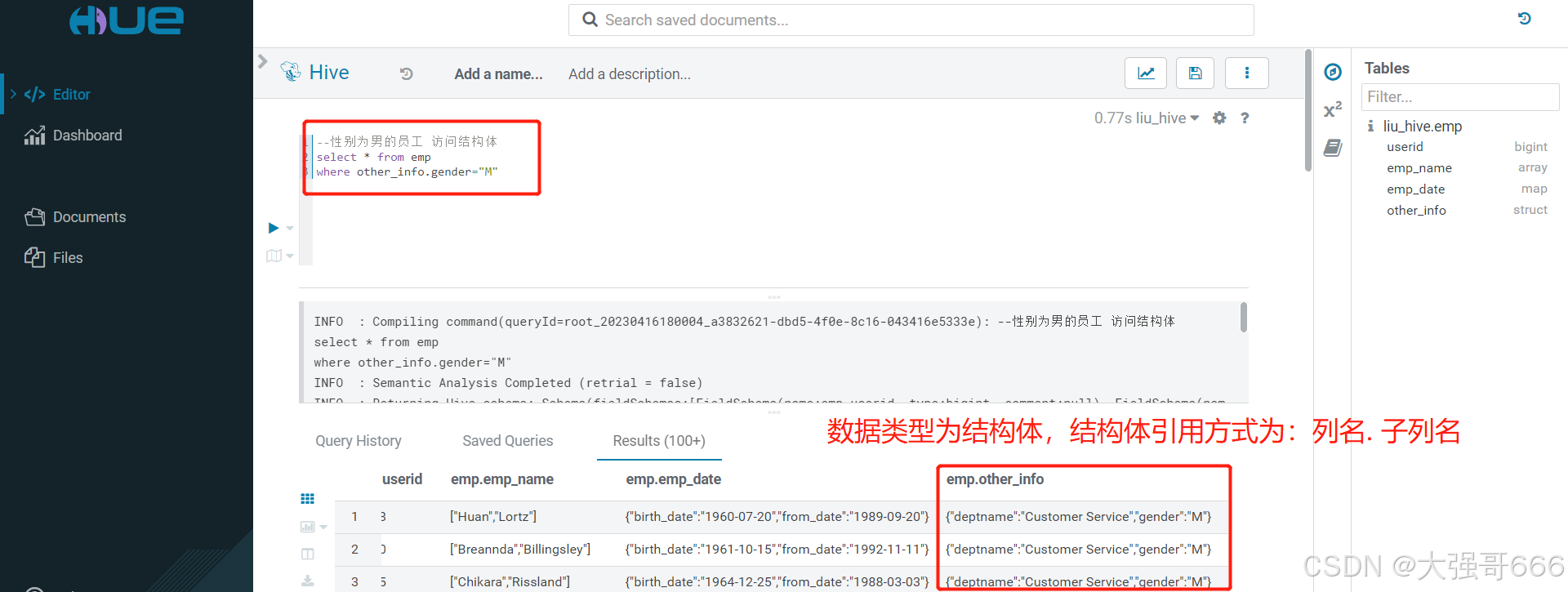
结构体引用方式为:列名. 子列名
--性别为男的员工 访问结构体
select * from emp
where other_info.gender="M"
正则匹配查询与rlike一起使用
与之前的python正则表达式匹配方式是一模一样的。
| 字符 | 说明 |
|---|---|
| \ | 将下一个字符标记为特殊字符,文本,反向引用或八进制转义符。例如"n"匹配字符"n"。但"\n"匹配换行符。 |
| ^ | 匹配输入字符串开始的位置。如果设置了RegExp对象的Multiline属性,^还会与"\n"或"\r"之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了RegExp对象的Multiline属性,$还会与"\n"或"\r"之后的位置匹配。 |
| * | 零次或多次匹配前面的字符或子表达式。例如:zo*匹配"z"和"zoo"。其功能等效于{0,}。 |
| + | 一次或多次匹配前面的字符或子表达式。例如:"zo+"与"zo"和"zoo"匹配,但是与"z"不匹配。+等效于{1,}。 |
| ? | 零次或一次匹配前面的字符或子表达式。例如:"do(es)?“匹配"do"或"does"中的"do”。?等效于{0,1}。 |
| {n} | n是非负整数。正好匹配n次。例如:"o{2}"与"Bob"中的"o"不匹配,但是与"food"中的两个"o"匹配。 |
| {n,} | n是非负整数。至少匹配n次。例如:"o{2,}"与"Bob"中的"o"不匹配,但是与"foooooood"中的所有"o"匹配。"o{1,}“等效于"o+”。"o{0,}“等效于"o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。匹配至少n次,至多m次。例如:"o{1,3}"匹配"foooood"中的头三个o。"o{0,1}“等效于"o?”。注意:不能将空格插入逗号和数字之间。 |
| ? | 当此字符紧随任何其他限定符(、+、?、{n}、{n,}、{n,m})之后时,匹配模式是”非贪婪匹配“。”非贪婪匹配“模式匹配搜索到的,尽可能短的字符串,而默认的”贪婪匹配“模式匹配搜手到的尽可能长的字符串。例如:在字符串"oooooo"中,"o+?“只匹配单个"o”,而"o+“匹配所有的"o”。 |
| . | 匹配除了"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式 |
| \d | 匹配数字字符。等效于[0-9] |
| \D | 匹配非数字字符 |
| \s | 匹配任意空白字符,包括空格、制表符、换页符等 |
| \S | 匹配任何非空白字符 |
| \w | 匹配任何字类字符,包括下划线。与"[A-Za-z0-9]"等效。 |
| \W | 匹配任何非单词字符 |
排序
hive的排序语句中普通表,分区表,分桶表是无差异的,用法一致。注意:在系统中我们将reduce设置为-1时,则表示reduce个数不受限制,可以是1个也可以是任意多个。
| order by | sort by | distribute by | cluster by | |
|---|---|---|---|---|
| 作用 | 与mysql相同,会对输入做全局排序 | sort by是单独在各自的reduce中(相当于各分区)进行排序 | 控制map中的输出在reduce中是如何进行划分的 | 相当于distribute by和sort by合用,前提是distribute by和sort by后面的字段是一样的 |
| 缺点 | 只有一个Reduce,即一个输出,一个文件含义,当输入规模较大时,消耗较长的计算时间 | 不能保证全局有序 | 只是分,没有排序,需要与sort by合用才能排序 | 只能做升序 |
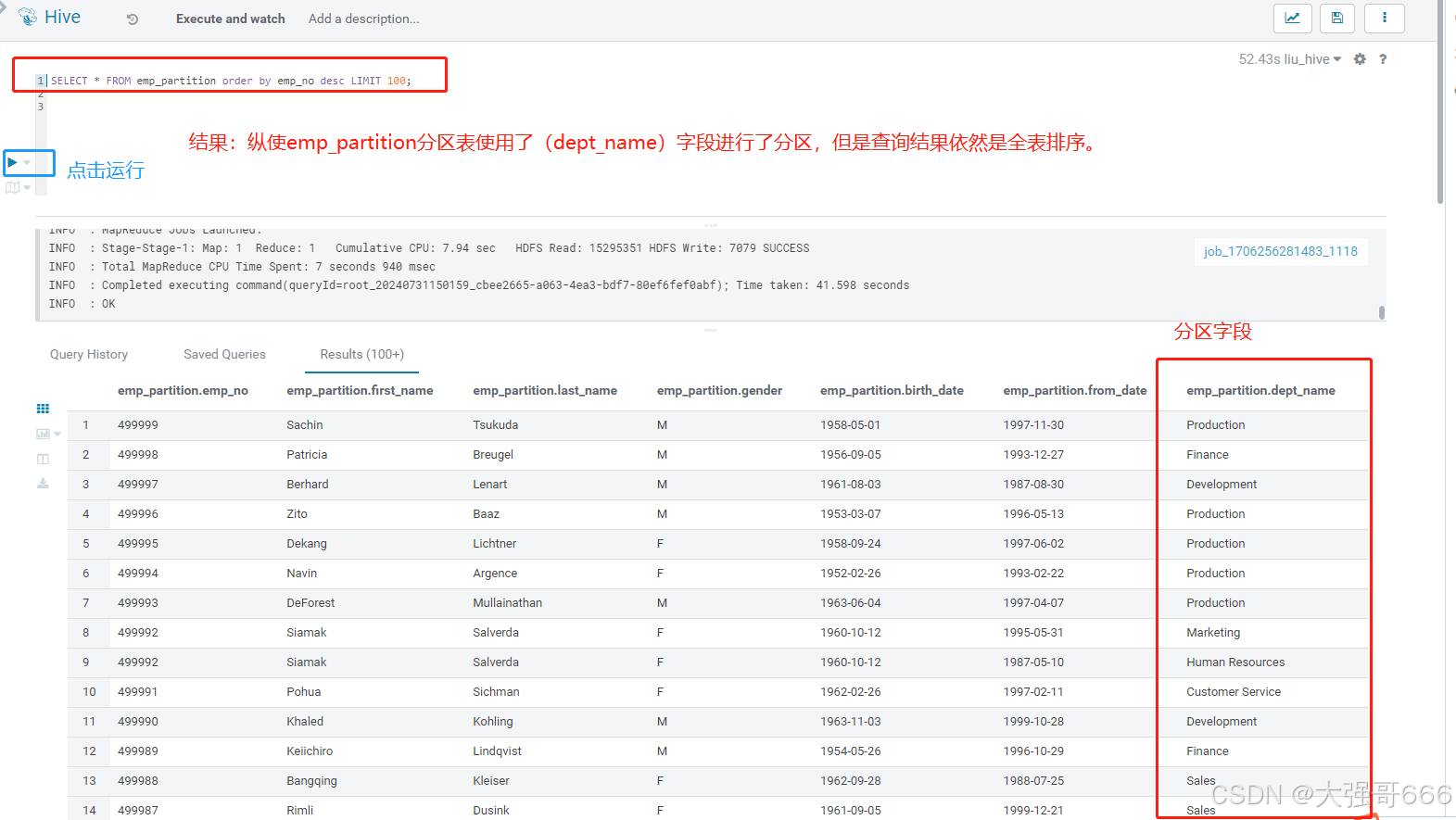
order by(全局排序asc,desc)
SELECT * FROM emp_partition order by emp_no desc LIMIT 100;
结果:纵使emp_partition分区表使用了(dept_name)字段进行了分区,但是查询结果依然是全表排序。
sort by(reduce内排序)
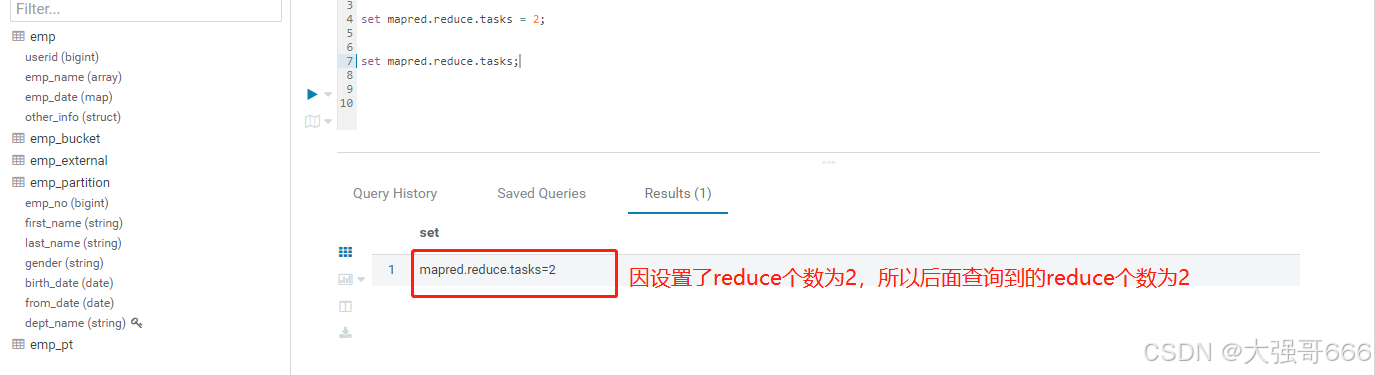
注意:在系统中我们将reduce设置为-1时,则表示reduce个数不受限制,可以是1个也可以是任意多个。
set mapred.reduce.tasks;
-- 查询reduce个数,默认为:-1;
set mapred.reduce.tasks = 2;
-- 更改reduce个数,将其个数设置为:2;
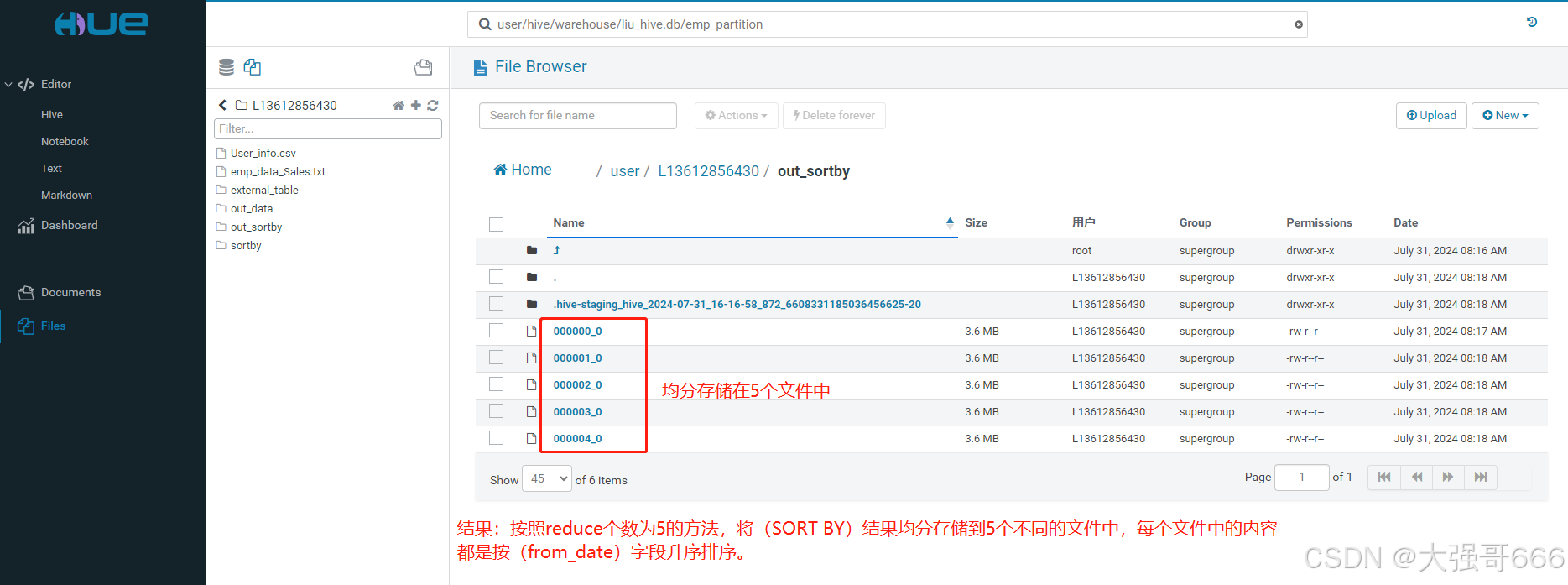
set mapred.reduce.tasks = 5;
-- 更改reduce个数,将其个数设置为:5;
INSERT OVERWRITE DIRECTORY '/user/L13612856430/out_sortby'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
SELECT * FROM emp_partition SORT BY from_date ASC;
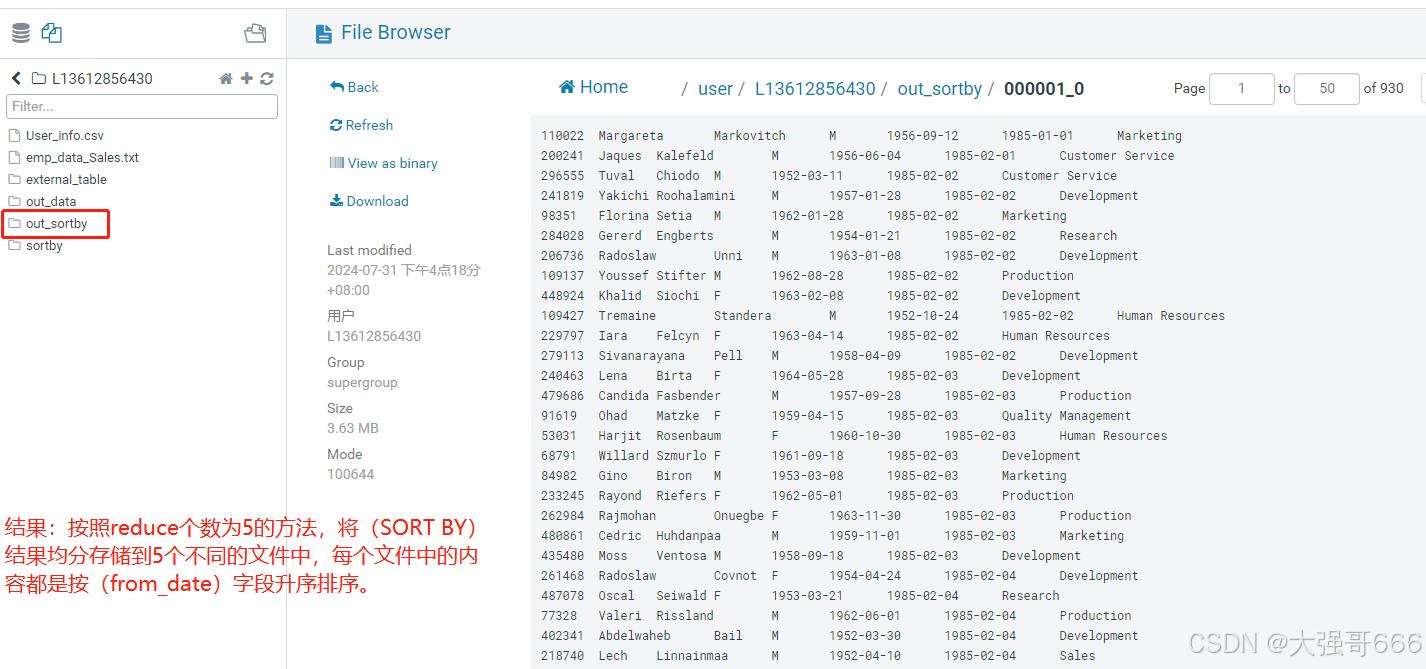
结果:按照reduce个数为5的方法,将(SORT BY)结果均分存储到5个不同的文件中,每个文件中的内容都是按(from_date)字段升序排序。
distribute by(分区排序)
Distribute 类似MapReduce中的partition 进行分区,结合sort by 使用(要放到sort by 的前面)
INSERT OVERWRITE DIRECTORY '/user/L13612856430/out_distributeby'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
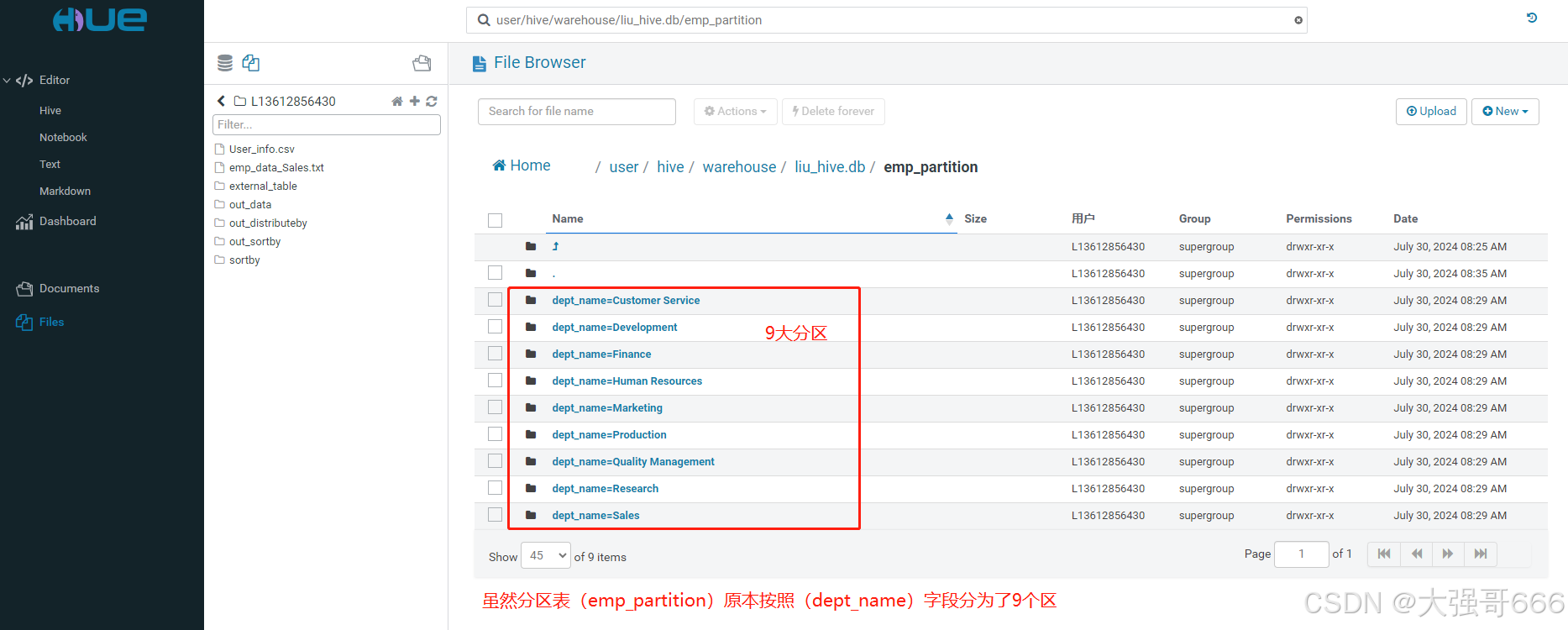
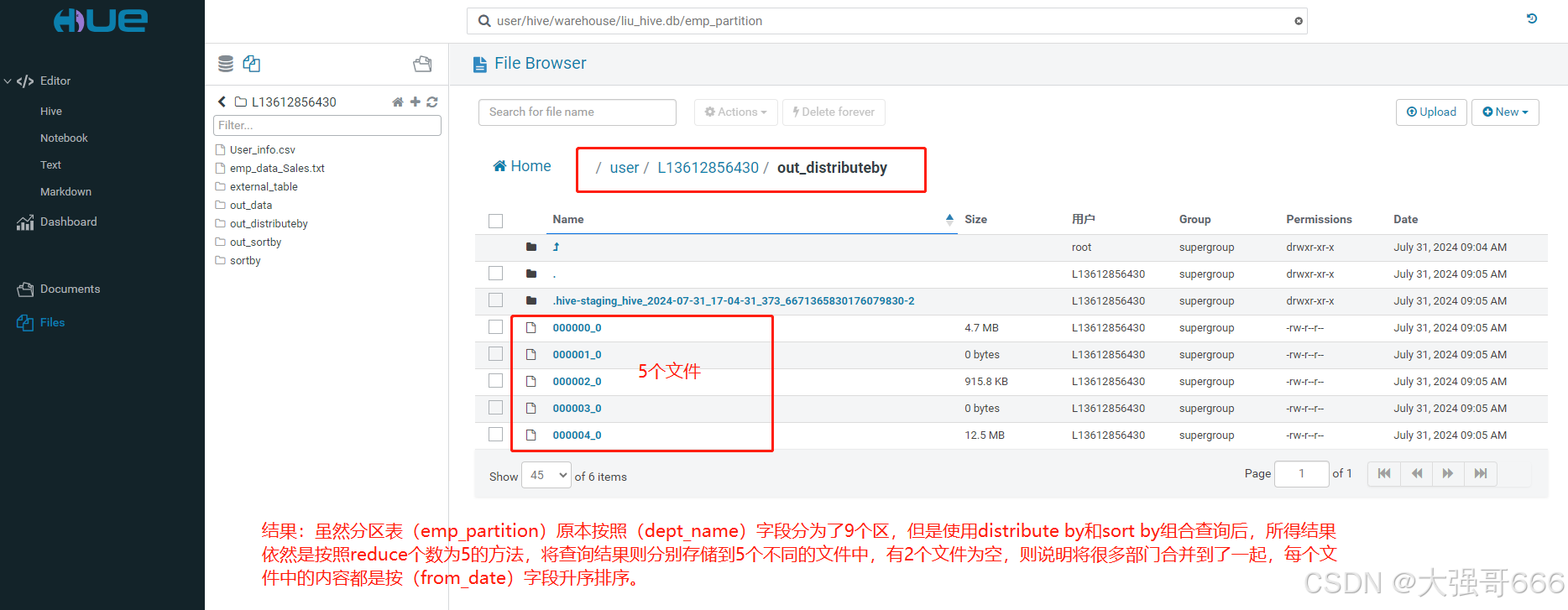
SELECT * FROM emp_partition DISTRIBUTE BY dept_name SORT BY from_date ASC;
结果:虽然分区表(emp_partition)原本按照(dept_name)字段分为了9个区,但是使用distribute by和sort by组合查询后,所得结果依然是按照reduce个数为5的方法,将查询结果则分别存储到5个不同的文件中,有2个文件为空,则说明将很多部门合并到了一起,每个文件中的内容都是按(from_date)字段升序排序。
cluster by(相当于distribute by和sort by合用)
当 distribute by 和 sorts by 字段相同时 ,可以使用,除具有distribute by 的功能,还有 sort by的功能, 但只能升序 。
INSERT OVERWRITE DIRECTORY '/user/L13612856430/out_clusterby'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
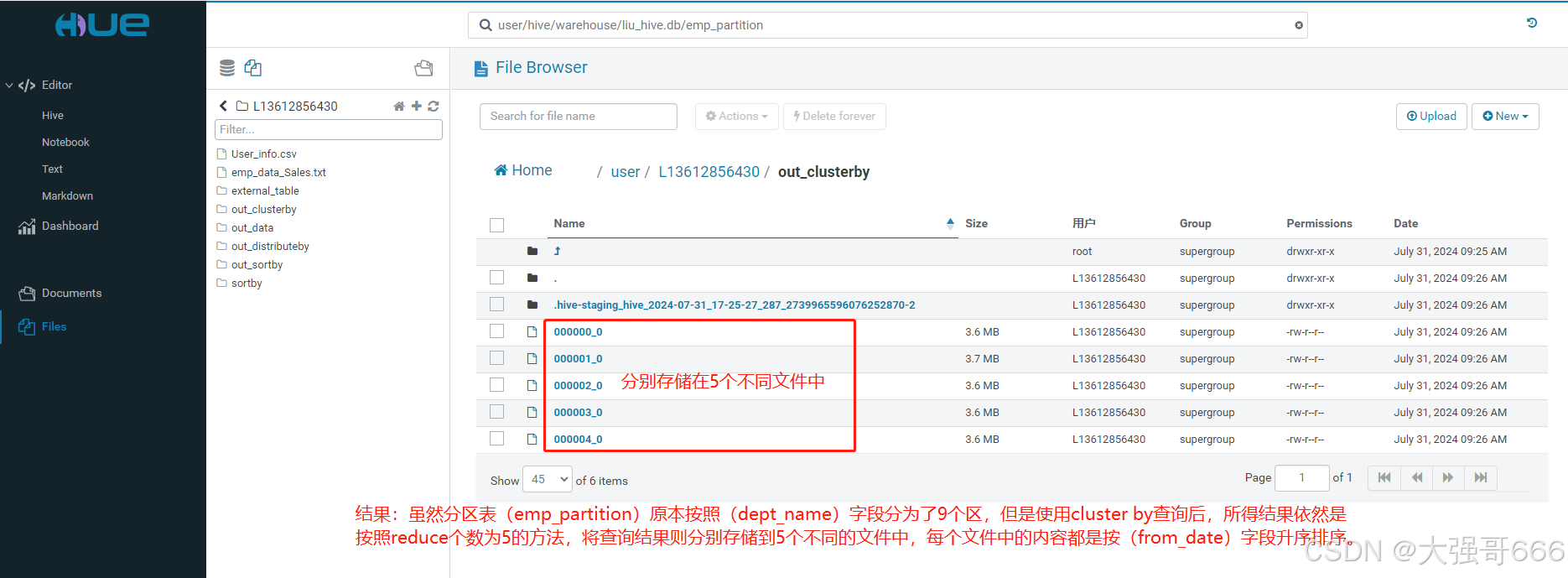
SELECT * FROM emp_partition cluster by from_date;
结果:虽然分区表(emp_partition)原本按照(dept_name)字段分为了9个区,但是使用cluster by查询后,所得结果依然是按照reduce个数为5的方法,将查询结果则分别存储到5个不同的文件中,每个文件中的内容都是按(from_date)字段升序排序。
表关联
Hive中Join的限制
只支持等值连接
Hive支持类似 mysql 的大部分Join 操作,但是注意只支持等值(如userid = userid)连接,并不支持不等值(如出生日期 > 某个日期)连接。原因是Hive语句最终是要转换为MapReduce 程序来执行的,但是 MapReduce程序很难实现这种不等判断的连接方式。
连接谓词中不支持or
连接谓词中不支持or :即on 后面的表达式不支持 or。
Full join
Full Join(对比mysql多出的一项功能)会将连接的两个表(左右表)中的记录都保留下来。
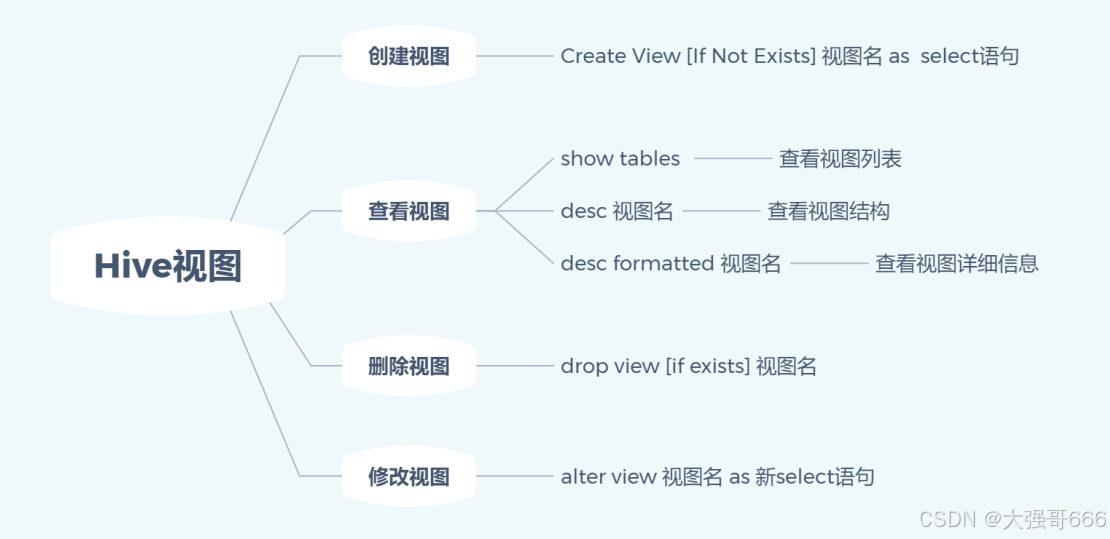
Hive视图(总体等同于mysql视图)
视图是一个虚表,一个逻辑概念,可以跨越多张表。表是物理概念,数据放在表中,视图是虚表,操作视图和操作表是一样的,所谓虚,是指视图下不存数据。
视图是建立在已有表的基础上,视图赖以建立的这些表称为基表。
视图也可以建立再已有的视图上。
视图可以简化复杂的查询(相当于将子查询变成视图,简化SQL)。
注意事项
视图是只读的,不能用作 LOAD / INSERT / ALTER 的目标;
在创建视图时候视图就已经固定,对基表的增加列操作将不会反映在视图,删除视图引用的列,视图会失效;
删除基表并不会删除视图,视图失效,需要手动删除视图;
视图可能包含 ORDER BY 和 LIMIT 子句。如果引用视图的查询语句也包含这类子句,其执行优先级低于视图对应子句。
创建视图时,如果未提供列名,则将从 SELECT 语句中自动派生列名(如 SELECT 语句中包含其他表达式,例如 x + y,则列名称将以C0,C1 等形式生成)。
子查询(含其限制)
hive 3.1 支持select,from,where 子句中的子查询,但是也有限制。限制一:select 子查询的限制,例如:不支持 if / case when 里的子查询。限制二:where 子查询的限制,例如:IN/NOT IN 子查询只能选择一列(本质上,mysql也有本条限制)。限制三:where 子查询的限制:对父查询的引用仅在子查询的WHERE子句中进行引用。限制四:集合中如果含null数据,不可使用not in,但是可以使用in。
开窗函数
Group by 与普通聚合函数(sum/count/AVG等)结合使用每组只有一条记录,而开窗函数则可以为窗口中的每行都返回一个值。普通聚合函数聚合的行集是组,开窗函数聚合的行集是窗口。
语法
分析函数(如:sum(), max(), row_number()...) + 窗口子句(over函数)
over函数(指定分析函数工作的数据窗口大小)
over([partition by [column_n] order by [column_m]])
--注意:over函数里面必须含有排序函数。
over() 内部参数:
1. PARTITION BY col_name
2. ORDER BY col_name asc|desc
3. ROWS between 窗口子句 and 窗口子句
窗口子句
| 窗口子句 | 备注 |
|---|---|
| PRECEDING | 往前 n preceding 从当前行向前n行 |
| FOLLOWING | 往后 n following 从当前行向后n行 |
| CURRENT ROW | 当前行 |
| UNBOUNDED | 起点 |
| UNBOUNDED PRECEDING | 表示该窗口最前面的行(起点) |
| UNBOUNDED FOLLOWING | 表示该窗口最后面的行(终点) |
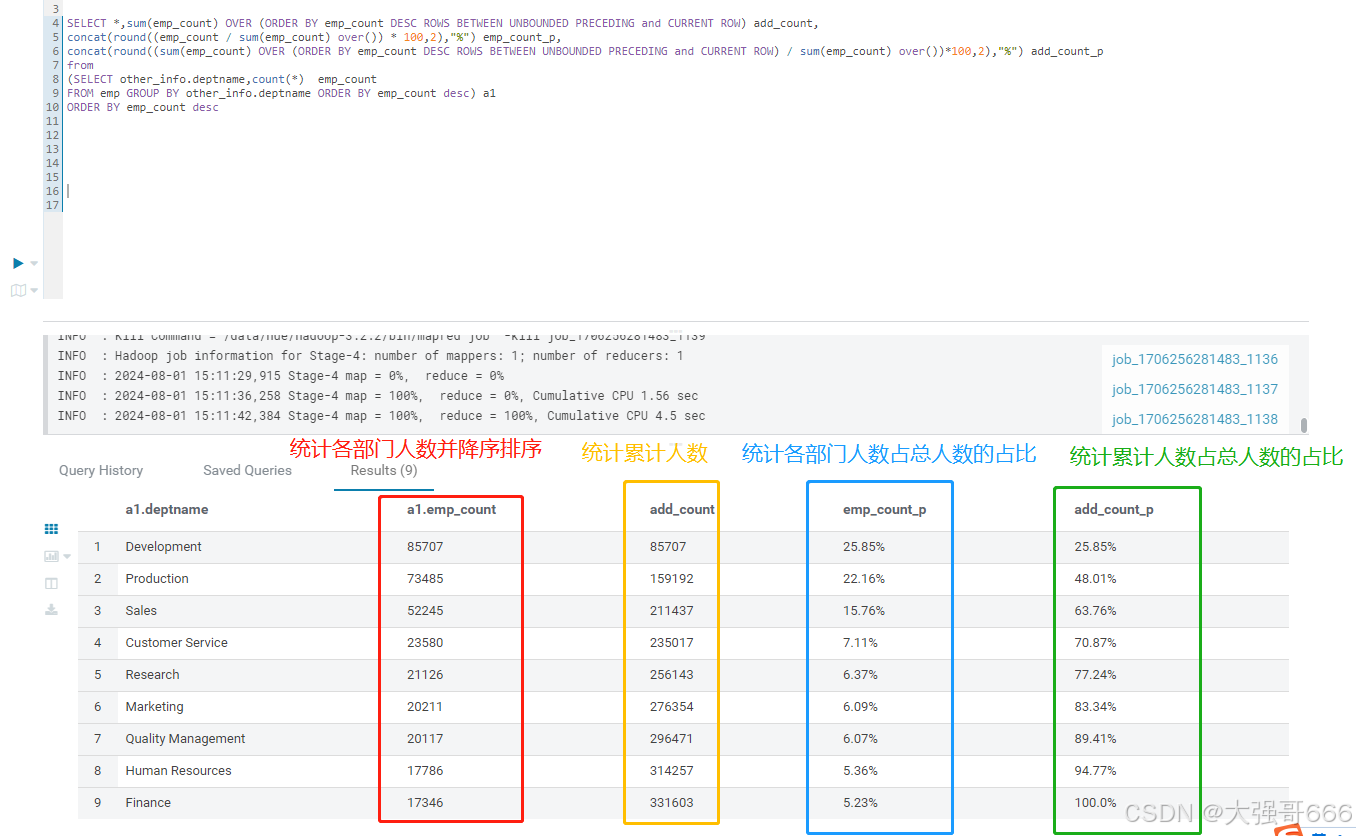
--需要:部门人数从多到少排序,计算累计人数及累计占比
SELECT *,sum(emp_count) OVER (ORDER BY emp_count DESC ROWS BETWEEN UNBOUNDED PRECEDING and CURRENT ROW) add_count,
--统计累计人数
concat(round((emp_count / sum(emp_count) over()) * 100,2),"%") emp_count_p,
--统计各部门人数占总人数的占比
concat(round((sum(emp_count) OVER (ORDER BY emp_count DESC ROWS BETWEEN UNBOUNDED PRECEDING and CURRENT ROW) / sum(emp_count) over())*100,2),"%") add_count_p
--统计累计人数占总人数的占比
from
(SELECT other_info.deptname,count(*) emp_count
FROM emp GROUP BY other_info.deptname ORDER BY emp_count desc) a1
--统计各部门人数并降序排序
ORDER BY emp_count desc;
偏移函数
| 偏移函数 | 备注 |
|---|---|
| LEAD(col,n,DEFAULT) | 用于统计窗口内往下第n行值,从当前行下移几行的值 |
| LAG(col,n,DEFAULT) | 用于统计窗口内往上第n行值,从当前行上移几行的值 |
| first_value(col, DEFAULT) | 取分组内排序后,截止到当前行,第一个值 |
| last_value(col, DEFAULT) | 取分组内排序后,截止到当前行,最后一个值 |
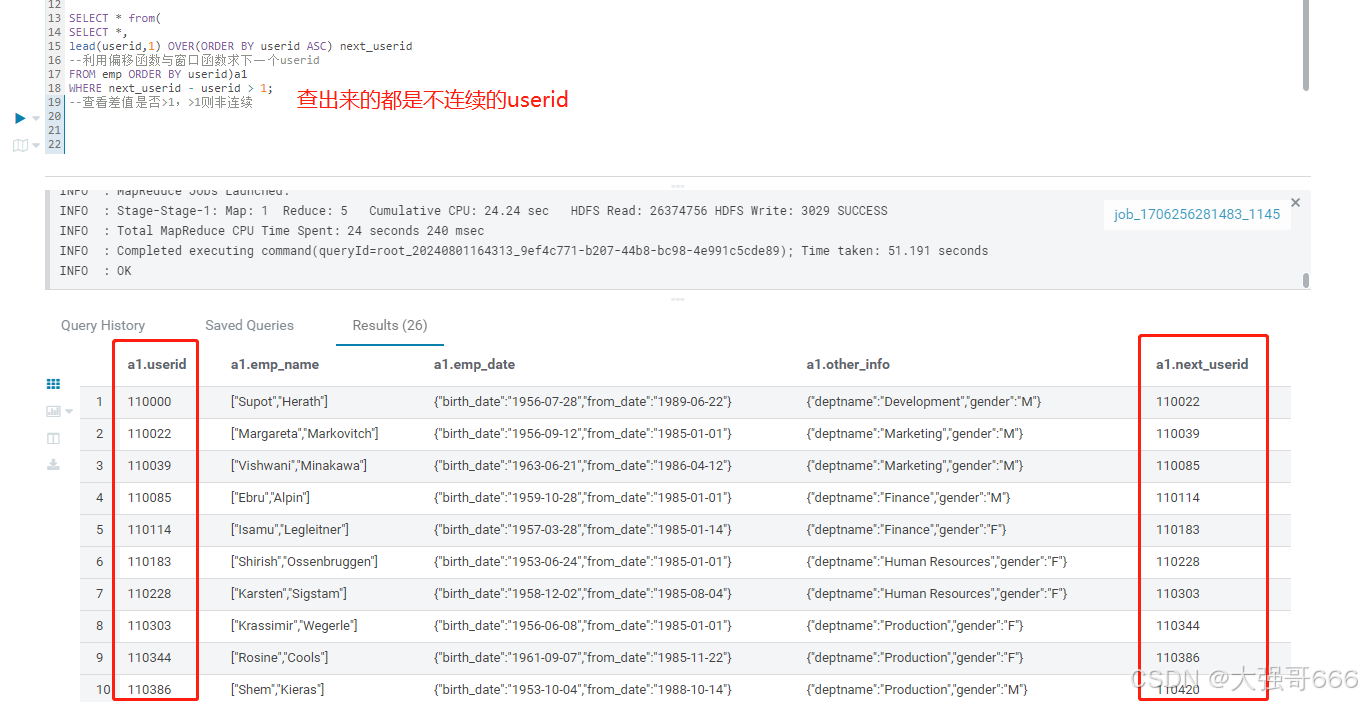
--需求:检验emp表的 userid 是否为连续的 (userid 排序后,差值都为1就表示连续)
SELECT * from(
SELECT *,
lead(userid,1) OVER(ORDER BY userid ASC) next_userid
--利用偏移函数与窗口函数求下一个userid
FROM emp ORDER BY userid)a1
WHERE next_userid - userid > 1;
--查看差值是否>1,>1则非连续
统计函数
| 统计函数 | 备注 |
|---|---|
| COUNT(col) | 统计各分组内个数 |
| SUM(col) | 统计各分组内合计 |
| MIN(col) | 统计各分组内最小值 |
| MAX(col) | 统计各分组内最大值 |
| AVG(col) | 统计各分组内平均值 |
排序函数
| 排序函数 | 备注 |
|---|---|
| ROW_NUMBER() | 从1开始,按照顺序,生成分组内记录的序列 |
| RANK() | 生成数据项在分组中的排名,排名相等会在名次中留下空位 1 2 2 4 |
| DENSE_RANK() | 生成数据项在分组中的排名,排名相等在名次中不会留下空位。1223 |
| NTILE(n) | 用于将分组数据按照顺序切分成n片,返回当前切片值, 等频切片 |
创建普通薪资数据表语句如下:
-- 创建普通表(即没有分区,没有分桶)
CREATE TABLE salaries(
userid bigint,
salary FLOAT,
from_date date,
end_date date)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
向普通薪资表插入数据
-- 执行下面代码加载数据到普通表(salaries表)中
load data inpath '/user/L13612856430/salaries.txt' overwrite into table salaries;
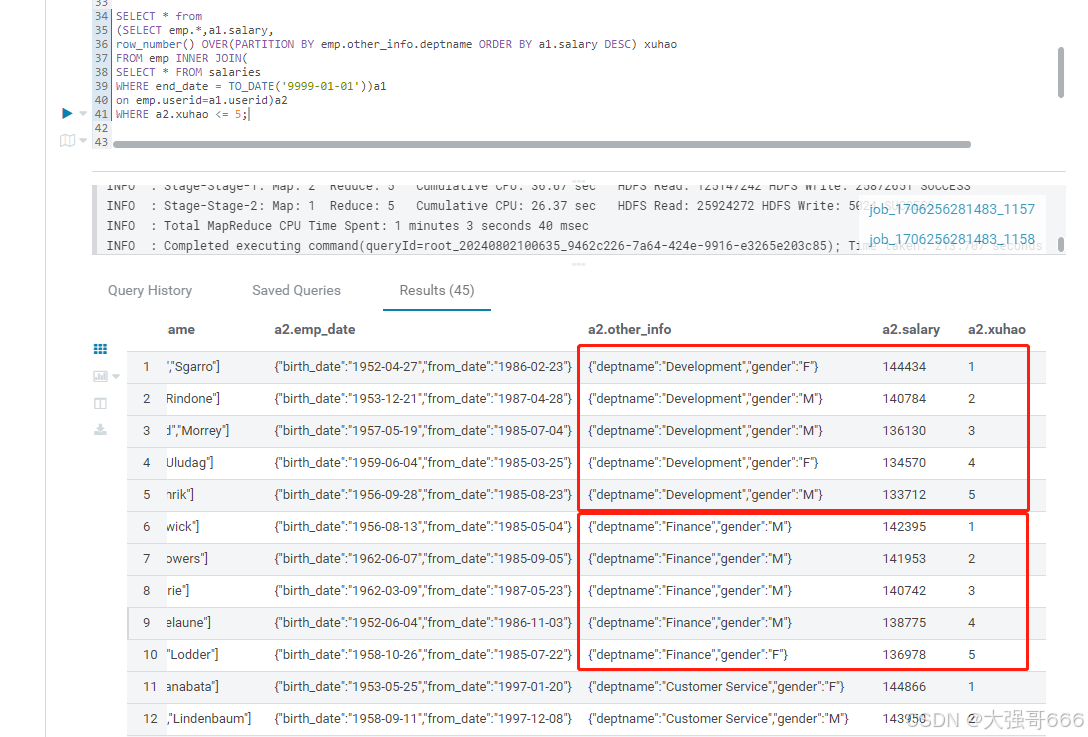
查找每个部门工资最高的前5人
--查找每个部门工资最高的前5人,涉及员工表和薪酬表两个表
--如果有相同的怎么办
--只要5人:方法一:ROW_NUMBER()。方法二:RANK()【前提条件:别是第5名重复:如果是第5名重复的话如:1 2 2 4 5 5 5,则取出了7个人】
--名次为前5的:DENSE_RANK()
SELECT * from
(SELECT emp.*,a1.salary,
row_number() OVER(PARTITION BY emp.other_info.deptname ORDER BY a1.salary DESC) xuhao
--进行排序
FROM emp INNER JOIN(
SELECT * FROM salaries
WHERE end_date = TO_DATE('9999-01-01'))a1
on emp.userid=a1.userid)a2
WHERE a2.xuhao <= 5;
抽样查询
抽样查询:一般算法工程师经常使用,而数据分析师不使用,因为数据分析基本都是全量查询分析。
在大规模数据量的数据分析及建模任务中,往往针对全量数据进行挖掘分析时会十分耗时和占用集群资源,因此一般情况下只需要抽取一小部分数据进行分析及建模操作。
随机抽样(rand()函数)
使用rand()函数与distribute by ,order by ,sort by 合用进行随机抽样,limit关键字限制抽样返回的数据。每次运行下面的代码,都是随机抽取到不同的10个数据的,每次抽取到的数据也全部都是不一样的。
select * from emp order by rand() limit 10;
--distribute和sort关键字可以保证数据在map和reduce阶段是随机分布的
select * from emp distribute by rand() sort by rand() limit 10;
数据块抽样(tablesample()函数)
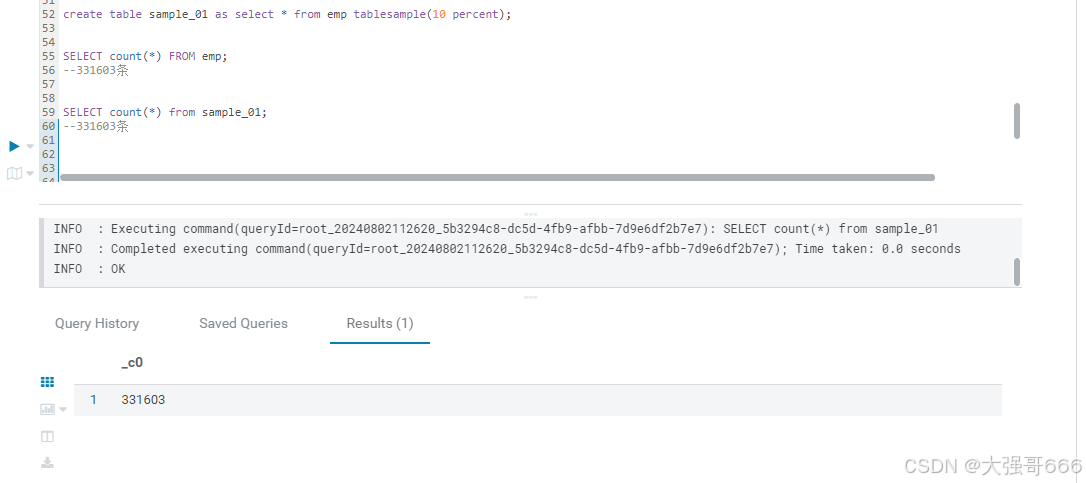
tablesample(n percent) 根据hive表数据的大小(不是行数,而是数据大小)按比例抽取数据,并保存到新的hive表中。
由于在HDFS块层级进行抽样,所以抽样粒度为块的大小,例如如果块大小为128MB,即使输入的n%仅为50MB,也会得到128MB的数据。
--select语句不能带where条件且不支持子查询
create table sample_new as select * from emp tablesample(10 percent) --10%的数据
如果希望在每次抽取相同的数据,可以设置下面的参数:
set hive.sample.seednumber=<INTEGER>;
--列如:set hive.sample.seednumber=10,因为上面就是抽取10%的数据。
tablesample(nM) 指定抽样数据的大小,单位为M
与PERCENT抽样具有一样的限制,因为该语法仅将百分比改为了具体值,但没有改变基于块抽样这一前提条件。
create table sample_02 as select * from emp tablesample(2M);
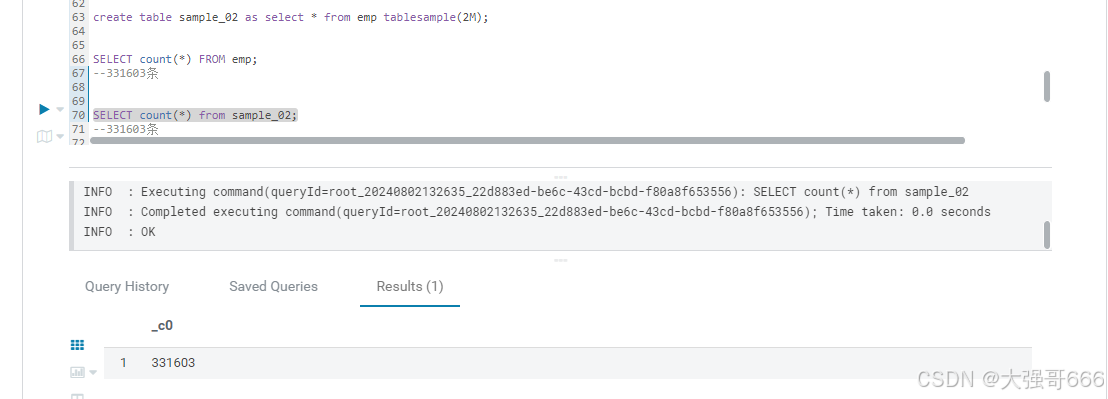
tablesample(n rows) 指定抽样数据的行数,其中n代表每个map任务均取n行数据。
SELECT * FROM emp TABLESAMPLE(10 ROWS);
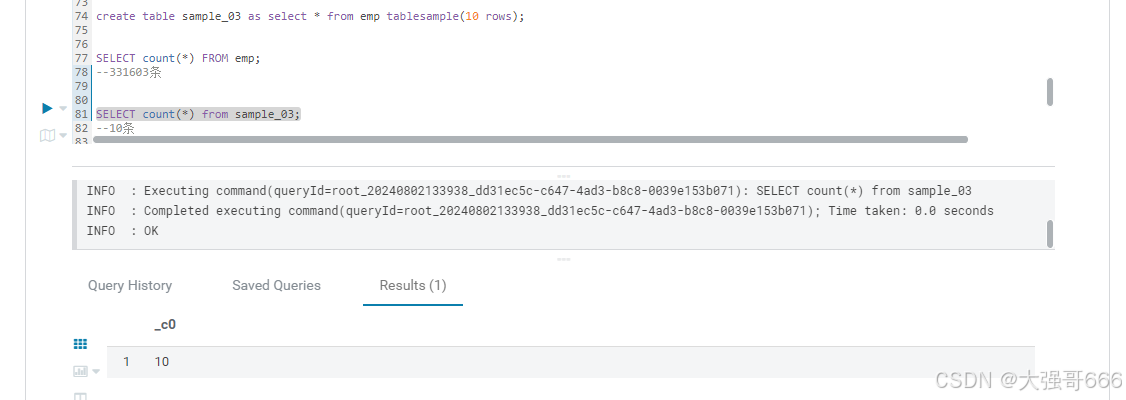
分桶抽样
hive中分桶其实就是根据某一个字段Hash取模,放入指定数据的桶中。
语法:TABLESAMPLE(BUCKET x OUT OF y) y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
未分桶的表
--将表随机分成10组,抽取其中的第一个桶的数据
select * from emp tablesample(bucket 1 out of 10 on rand())
已分桶的表
-- 对第一个桶抽样一半
CREATE TABLE sample_bucket_01 as SELECT * FROM emp_bucket TABLESAMPLE(BUCKET 2 OUT OF 4);
-- 总桶数/4 = 0.5 从第一个桶开始取,取0.5个桶的数据
-- emp_bucket_id 有6个分桶
select * from emp_bucket_id tablesample(bucket 1 out of 3 )
-- 从第一个桶开始取,取2个桶的数据,第二个桶是 1+3
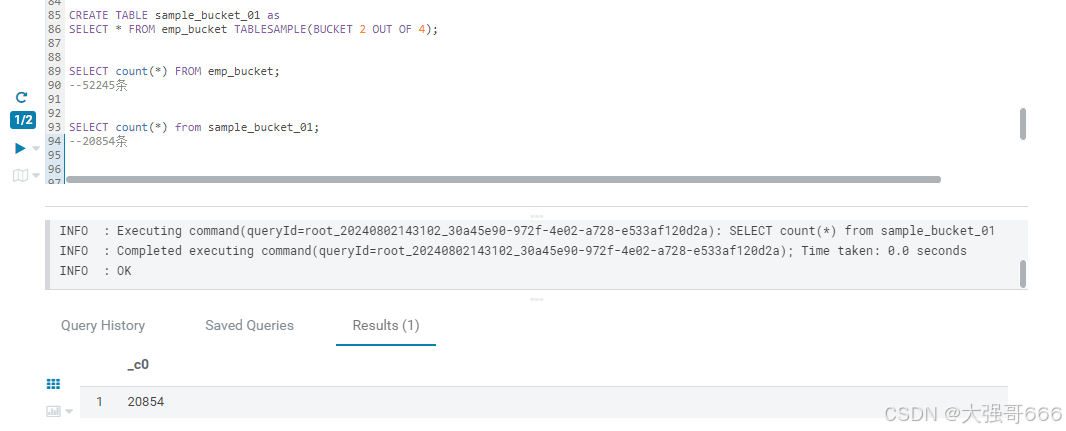
explode 炸裂函数和 lateral 虚拟表
注意:explode 炸裂函数通常和 lateral 虚拟表一起使用,而单独使用explode 炸裂函数意义不大,而 lateral 虚拟表更是无法单独使用。
explode列变行
explode 对复合类型数据列变行(类似于excel的行列装置)
SELECT * FROM emp LIMIT 100;
-- 查看emp数据内容,看各字段的结构
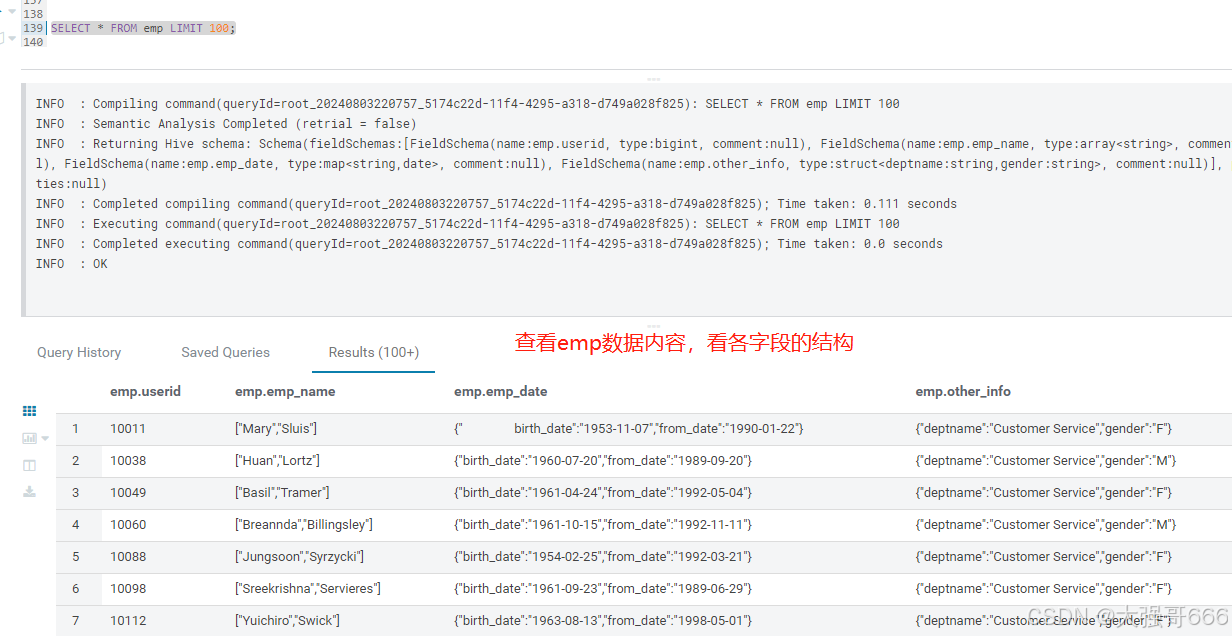
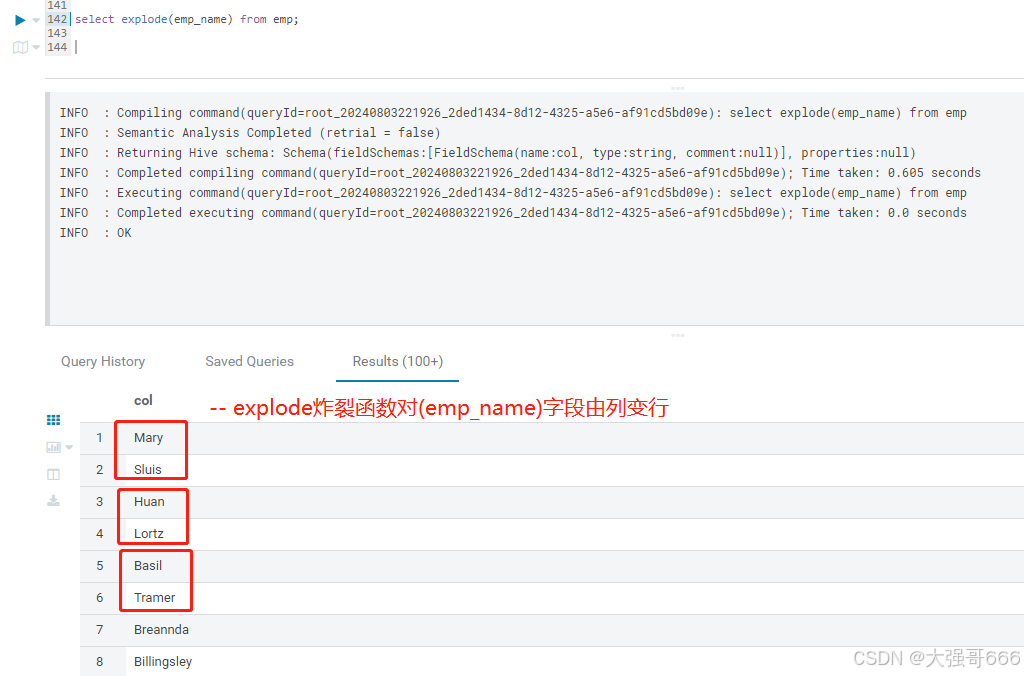
select explode(emp_name) from emp;
-- explode炸裂函数对(emp_name)数组字段由列变行
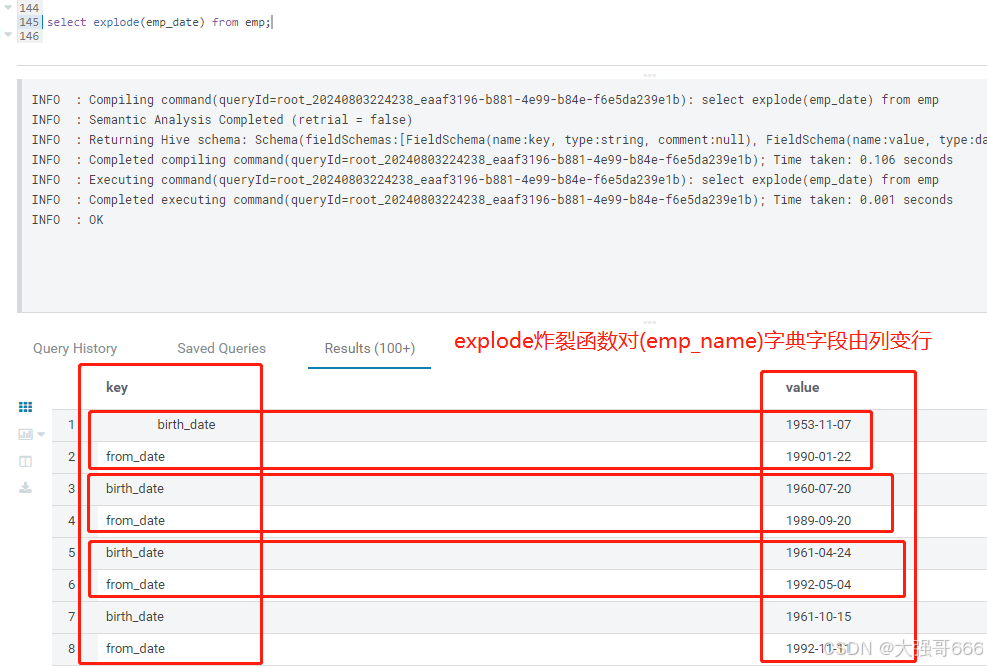
select explode(emp_date) from emp;
-- explode炸裂函数对(emp_date)字典字段由列变行
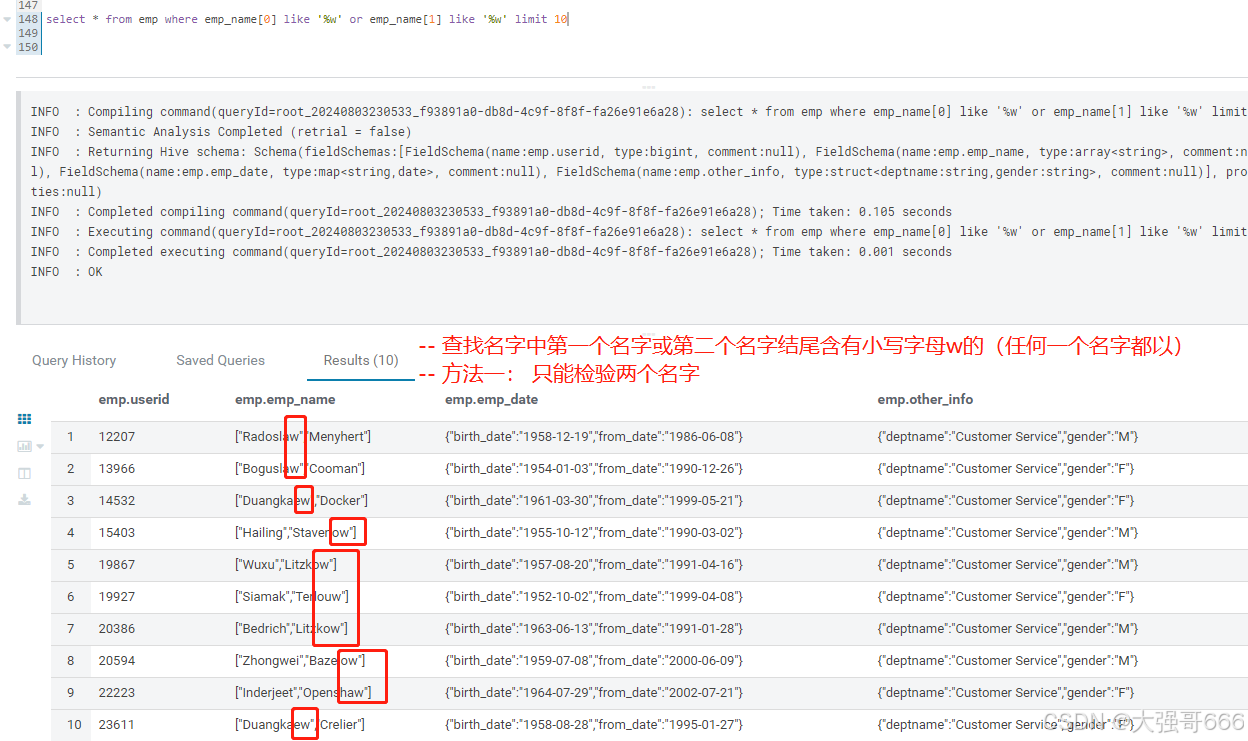
-- 查找名字中第一个名字或第二个名字结尾含有小写字母w的(任何一个名字都可以)
-- 方法一: 只能检验两个名字
select * from emp where emp_name[0] like '%w' or emp_name[1] like '%w' limit 10
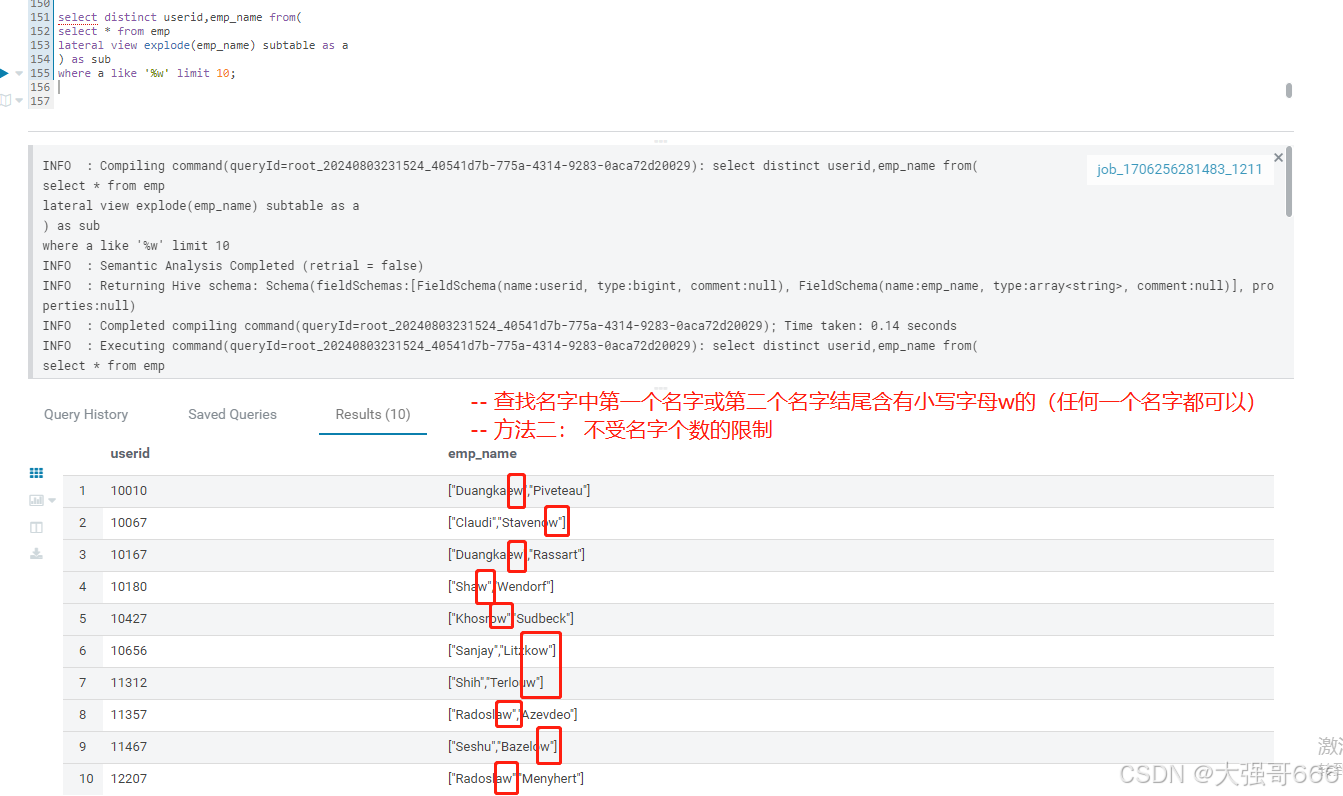
-- 查找名字中第一个名字或第二个名字结尾含有小写字母w的(任何一个名字都可以)
-- 方法二: 不受名字个数的限制
select distinct userid,emp_name from(
select * from emp
lateral view explode(emp_name) subtable as a
) as sub
where a like '%w' limit 10;
lateral 实现与其他列一同显示
lateral 虚拟表的语法:lateral view explode(要炸裂的字段) 虚拟表名字 as 炸裂开的字段的名字。
注意:结构体里面的元素个数是固定的(定义表时指定好了),所以它不需要要炸裂函数,把每个元素作为普通列使用即可。
select * from emp
lateral view explode(emp_name) nameTable as namefeild limit 10;
-- explode炸裂函数对(emp_name)数组字段由列变行并结合lateral 虚拟表使用
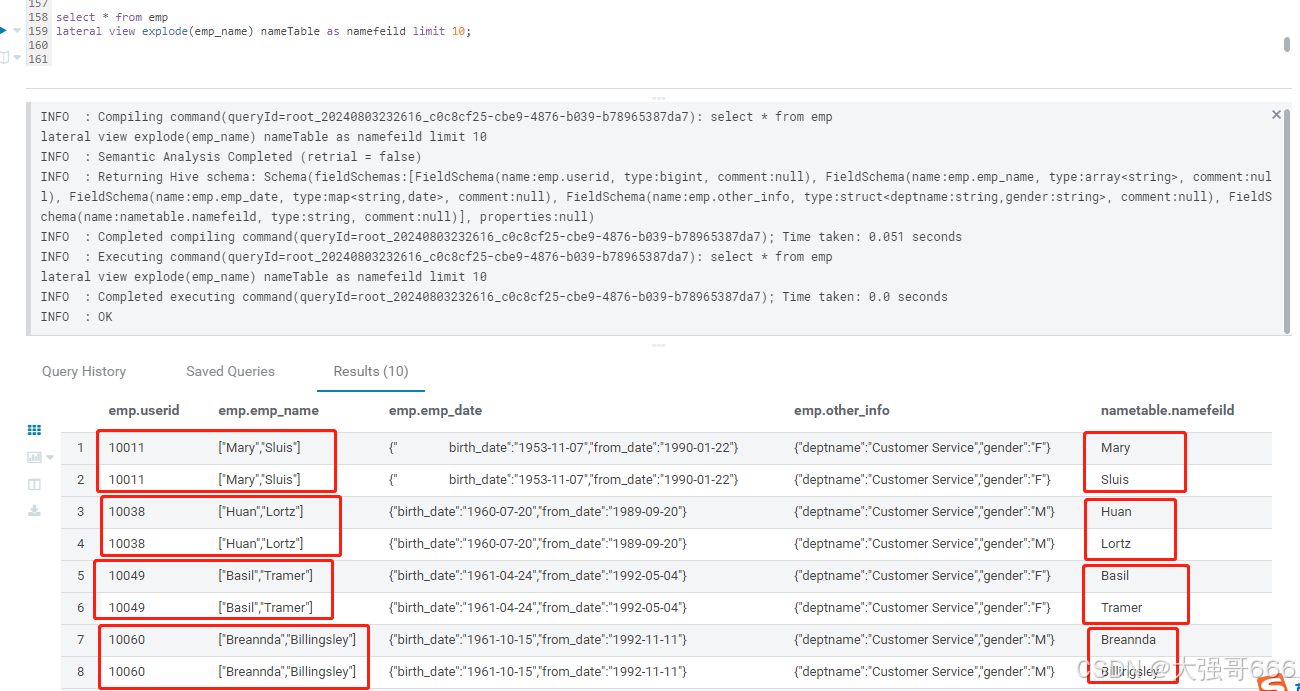
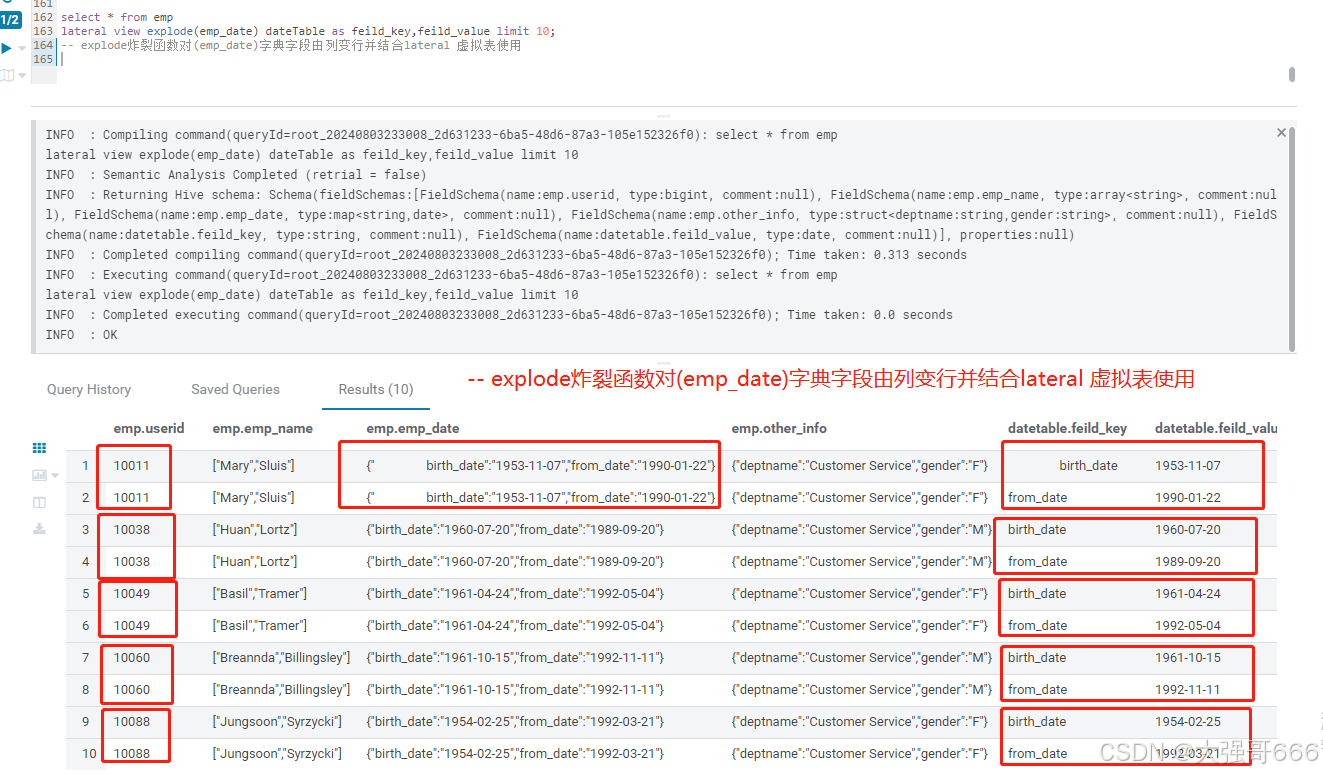
select * from emp
lateral view explode(emp_date) dateTable as feild_key,feild_value limit 10;
-- explode炸裂函数对(emp_date)字典字段由列变行并结合lateral 虚拟表使用
Hive调优(HQL语句调优)
Hive调优本质上是分两个方面进行调优,一个是HQL语句调优,另一个是环境调优(如:创建分区表,创建分桶表,数仓分层等,如上面章节)。
除去多余操作
获取每个员工最高的薪水记录
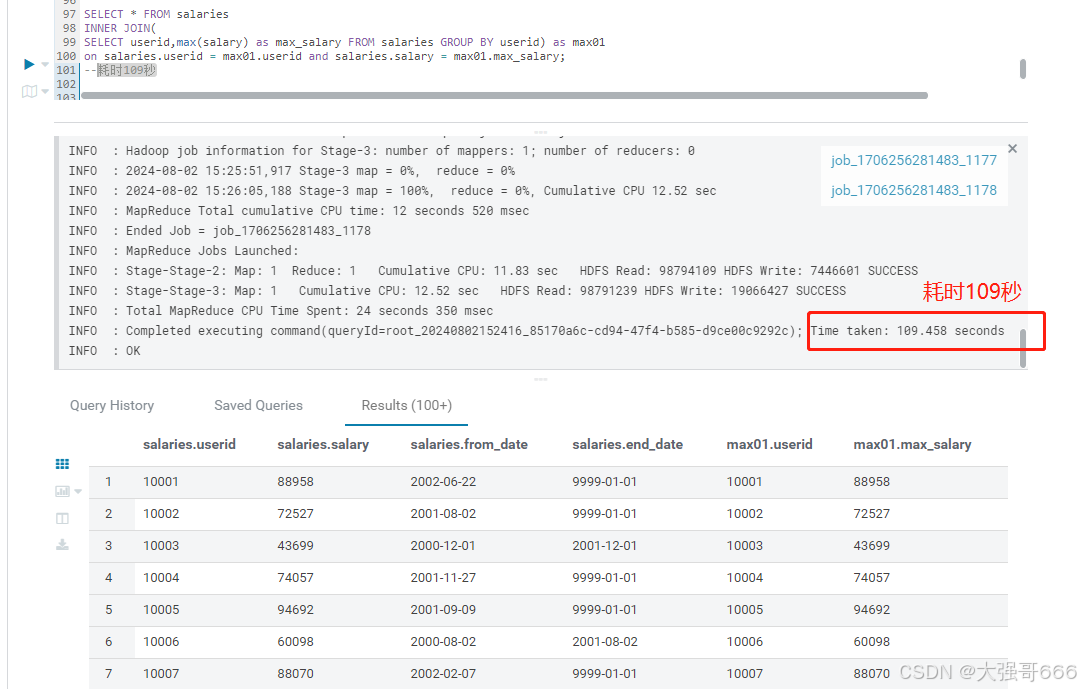
-- 方法一
SELECT * FROM salaries
INNER JOIN(
SELECT userid,max(salary) as max_salary FROM salaries GROUP BY userid) as max01
on salaries.userid = max01.userid and salaries.salary = max01.max_salary;
-- 耗时109秒
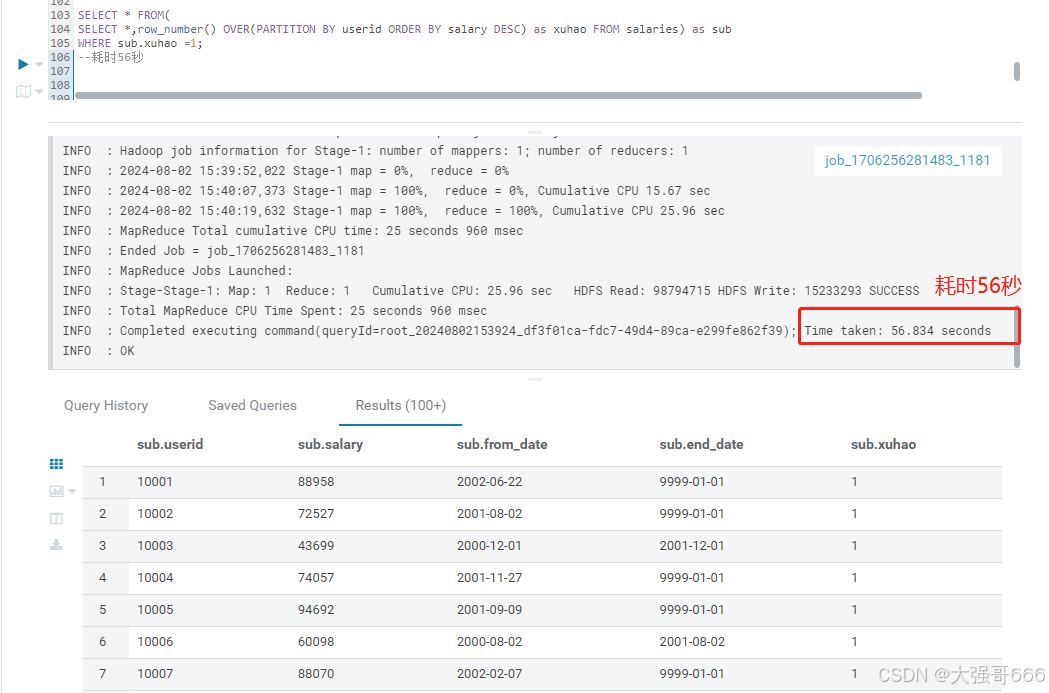
-- 方法二 (减少了Join 操作,系性能提升)
SELECT * FROM(
SELECT *,row_number() OVER(PARTITION BY userid ORDER BY salary DESC) as xuhao FROM salaries) as sub
WHERE sub.xuhao =1;
-- 耗时56秒
Distinct聚合优化(增加reduce个数)
-- 方法一(只有一个reduce处理全量数据,并发度不够,存在单点瓶颈)
SELECT COUNT( DISTINCT userid ) FROM emp ;
-- 方法二(reduce就会有多个,如果数据量大的话,性能提升很多;但是如果数量小的话,反而会降低性能)
SELECT COUNT(userid ) FROM (select distinct userid from emp) as sub;
-- 方法三(reduce就会有多个,性能提升很多)
select count(*) from (SELECT userid FROM emp group by userid ) as sub
使用with as 代替子查询
with sub as
(SELECT userid FROM emp group by userid)
select count(*) from sub;
聚合技巧——利⽤窗⼝函数grouping sets、cube
-- 性别分布
select other_info.gender,count(*) as emp_count from emp
group by other_info.gender;
-- 部门分布
select other_info.deptname,count(*) as emp_count from emp
group by other_info.deptname;
-- 年龄分布
select year(emp_date["birt_date"]),count(*) emp_count from emp
group by year(emp_date["birt_date"]);
-- 缺点:要分别写三次SQL,需要执⾏三次,重复⼯作,且费时
-- 优化方法(聚合结果均在同⼀列,分类字段⽤不同列来进⾏区分)
select other_info.gender,other_info.deptname,
year(emp_date["birth_date"]),count(*) as emp_count
from emp
group by other_info.gender,other_info.deptname,year(emp_date["birth_date"])
grouping sets(other_info.gender,other_info.deptname,year(emp_date["birth_date"]));
-- 效果:一行代码统计出了上面:性别分布,部门分布,年龄分布,三种分布方式各自的人数
-- 思考(如果想统计性别分布情况 + 各性别下的年龄分布情况)
select other_info.gender,other_info.deptname,
year(emp_date["birth_date"]),count(*) as emp_count
from emp
group by other_info.gender,other_info.deptname,year(emp_date["birth_date"])
grouping sets(other_info.gender,other_info.deptname,year(emp_date["birth_date"]),(year(emp_date["birth_date"]),other_info.gender));
cube:根据group by 维度的所有组合进⾏聚合
-- 性别、部门、年龄的各种组合的⽤户分布
select other_info.gender ,other_info.deptname ,year(emp_date["birt_date"])
,count(*) as emp_count
from emp
group by other_info.gender ,other_info.deptname ,year(emp_date["birt_date"])
grouping sets(other_info.gender ,other_info.deptname
,year(emp_date["birt_date"]),
(other_info.gender ,other_info.deptname),
(other_info.deptname ,year(emp_date["birt_date"]))
(other_info.gender,year(emp_date["birt_date"]))
);
-- 优化写法
select other_info.gender ,other_info.deptname ,year(emp_date["birt_date"])
,count(*) as emp_count
from emp
group by other_info.gender ,other_info.deptname ,year(emp_date["birt_date"])
with cube
Join连接优化
⼩表在前,⼤表在后
Hive假定查询中最后的⼀个表是大表,它会将其它表缓存起来,然后扫描最后那个表。
使⽤相同的连接键
当对3个或者更多个表进⾏join连接时,如果每个on⼦句都使⽤相同的连接键的话,那么只会产⽣⼀个 MapReduce job。
尽早的过滤数据
减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使⽤到的字段。逻辑过于复杂时,引⼊中间表。
解决数据倾斜
数据倾斜的表现
任务进度⻓时间维持在99%(或100%),查看任务监控⻚⾯,发现只有少量(1个或⼏个)reduce⼦任务未完成。因为其处理的数据量和其他reduce差异过⼤。例如:某个文件有129M时,采用默认的128M分块,系统会将文件分成2块,一块128M,一块1M,分别存放在2个不同机器上,当对该文件进行处理时,因为数据量不同,其中1M的那块很快就处理完毕了,但是128M的还没有处理完,所有1M的那块需要等待128M的那块。
数据倾斜的原因与解决办法
1.空值产⽣的数据倾斜
解决:如果两个表连接时,使⽤的连接条件有很多空值,建议在连接条件中增加过滤。
select * from emp_partition
inner join salaries
on
salaries.emp_no is not null and
emp_partition.emp_no is not null and
emp_partition.emp_no = salaries.emp_no
2.⼤⼩表连接(其中⼀张表很⼤,另⼀张表⾮常⼩)
解决:将⼩表放到内存⾥,在map端做Join
select * from emp_partition
-- emp_partition小表,注意:小表放到左侧
inner join salaries
on
salaries.emp_no is not null and
emp_partition.emp_no is not null and
emp_partition.emp_no = salaries.emp_no
3.两个表连接条件的字段数据类型不⼀致
解决:将连接条件的字段数据类型转换成⼀致的