背景:
对一块string对象进行拷贝到char数组的时候发现数据缺失了。
分析:
由于在拷贝的时候使用的是strncpy,而strncpy在复制的时候,在遇到’\0’时,先复制过去,然后的把dest剩下置为了0。所以,一旦源字符串中存在\0则会导致源数据被截断。为此我们可以采用memcpy进行拷贝操作(snprintf 拷贝的时候遇到\0 也会停止)。
各个拷贝函数的比较:
strncpy:
strncpy比strcpy稍微安全点,strncpy顶多拷贝n个字节,所以在dest不够的情况下,不会像strcpy出现拷贝越界。但也只是稍微安全点而已,如果src长度比n大,那么dest就不是以\0结尾的了,需要手动方式自行添加\0 结束符(而用strcpy函数复制时目的串后会自动补0)。所以通常要这么使用:
strncpy(buf, str, n);
if (n > 0)
{
buf[n - 1]= '\0';
}给一串字符设置 \0的方式有两种,分别为string[n]=0或string[n]= \0。因为字符可以当做整型单独赋值,0表示ASCII编号的0;也可以当做字符赋值,字符赋值时特殊字符需用\来转义。字符’0’的ASCII编号为30,而字符’\0’的ASCII编号为0。
char src[] = "abcdefg1234567890";
char dest[5];
int len = 0;
bzero(dest, sizeof(dest));
strncpy(dest, src, sizeof(dest));
// dest[4]=0;//注释与否的差异
std::cout<<dest<<std::endl;注释前后运行结果如下,可知dest[4]=0 将该位置加入了\0结束符。

在高效方面strncpy也做得不好,它的大致实现这样的:
char *strncpy(char *dest, const char *src, size_t n)
{
size_t i;
for (i = 0; i < n && src[i] != '\0'; i++) {
dest[i] = src[i];
}
for ( ; i < n; i++) {
dest[i] = '\0';
}
return dest;
}当src长度比n小时,未使用的字符,它会帮你填充为0,但我们往往会开一个大的Buffer来接收数据,如此必然有大量的多余空间,这样不仅速度慢,而且还会导致实存的消耗上涨。总之,strncpy的即不怎么安全,也不怎么高效。
memcpy:
至于memcpy:void *memcpy(void *dest, const void *src, size_t n);
memcpy不安全,它只是做简单的拷贝而已,不过它很高效,如果你能保证不会越界的话,就使用memcpy吧。其实memcpy的实现就是一个一个赋值,strcpy也是一个一个赋值,不过,memcpy做了点优化,64位机器下,它会64位64位地拷贝,即8个字节8个字节地拷贝,对于除8的余数,再做单独处理,而strcpy是一个字节一个字节地拷贝,所以当有大量字符串需要拷贝时,理论上memcpy会比strcpy快8倍。
snprintf:
int snprintf(char *str, size_t size, const char *format, cahr *source_str)
通过snprintf(dst_str, dst_size, “%s”, source_str); 可以将source_str拷贝到dst_str。snprintf的特点是安全,不管怎么着,它都能保证结果串str以\0结尾,哪怕dst_size不够大,它都能做好截断,同时在末尾添加上\0。
char src[] = "abcdefg1234567890";
char dest[5];
int len = 0;
bzero(dest, sizeof(dest));
snprintf(dest, sizeof(dest), "%s", src);
std::cout<<dest<<std::endl;运行结果是:
abcd因为末尾的数据被自动用\0 来作为结束符。
在性能方面,当source_str远长于dst_size时,该函数却很低效的,其他情况下该函数即安全又高效。
当source_str远长于dst_size时,该函数低效,是因为该函数的返回值为source_str的长度(不包括\0),那么它就必须将source_str全部过一遍,哪怕并不拷贝到dst_str中去。
注意,当source_str长度比dst_size小时,它不会把末尾的多余字符置零,所以它是很高效的,不会多做无用功。
测试对比:
test_memcpy.cpp:
#include <string.h>
int main(){
char src[] = "abcdefg1234567890";
char dest[2048];
int len = 0;
for(int i = 0; i < 20000000; ++i){
memset(dest, 0, sizeof(dest));
len = strlen(src);
len = sizeof(dest) - 1 > len? len: sizeof(dest) -1;
memcpy(dest, src, len);
dest[len] = '\0';
}
return 0;
} test_strncpy.cpp:
#include <string.h>
int main() {
char src[] = "abcdefg1234567890";
char dest[2048];
int len = 0;
for(int i = 0; i < 20000000; ++i) {
memset(dest, 0, sizeof(dest));
strncpy(dest, src, sizeof(dest));
}
return 0;
} test_snprintf.cpp:
#include <stdio.h>
#include <string.h>
int main() {
char src[] = "abcdefg1234567890";
char dest[2048];
int len = 0;
for(int i = 0; i < 20000000; ++i) {
memset(dest, 0, sizeof(dest));
snprintf(dest, sizeof(dest), "%s", src);
}
return 0;
} 运行结果如下图所示:
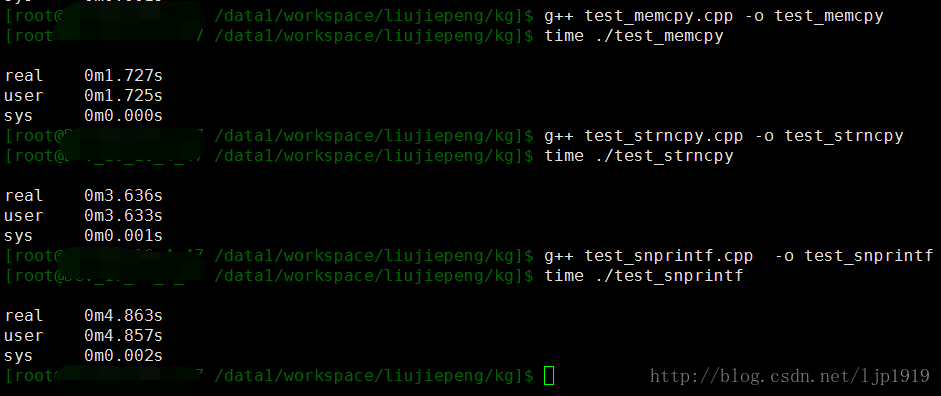
从中可以看出,memcpy的速度是最快的,差不多是strncpy的2倍多,是snprintf的3倍。
采用O3优化情况下不同函数消耗时间对比如下图:
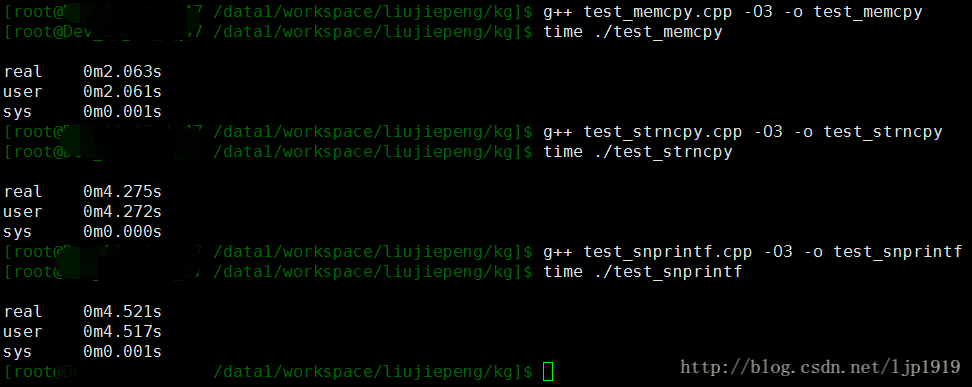
发现memcpy和strncpy的性能反而变差,只有snprintf性能提升了。这点需要再次探索。
将上述三个文件中的memset()改为用bzero()来实现数组的清零操作。结果如下:
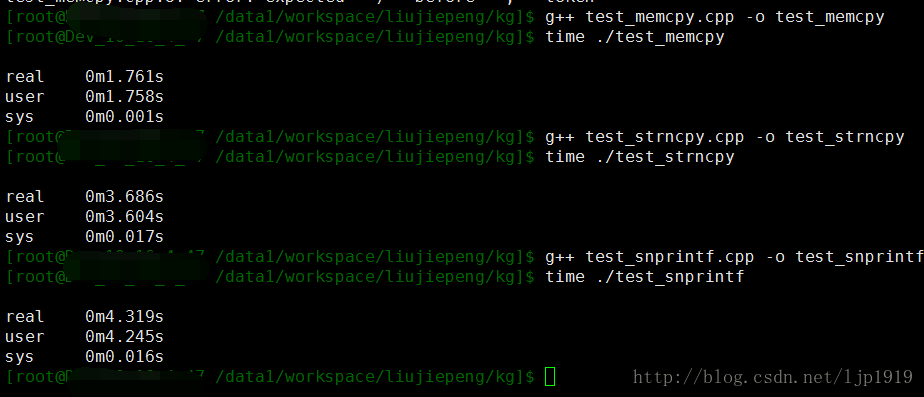
发现对于memcpy和strncpy来说,并没有明显的变化,只是对snprintf的性能似乎是有所优化。但是随着循环次数的加大,我们是可以看出两者之间的性能差距的。
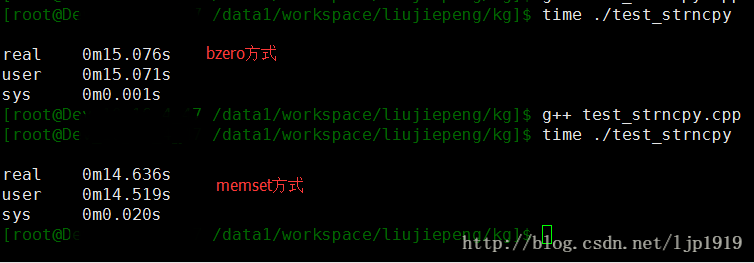
对于memcpy和strncpy来进行进一步的测试发现:memset 的性能优于bzero
strncpy的memset()和bzero()对比:
对应大数组来说,memset 的性能优于bzero
char src[] = "abcdefg1234567890";
char dest[2048];
int len = 0;
for(int i = 0; i < 80000000; ++i) {
// bzero(dest, sizeof(dest));
memset(dest, 0, sizeof(dest));
strncpy(dest, src, sizeof(dest));
} 同样对于小数组,也是如此:
char src[] = "abcdefg1234567890";
char dest[20];//小数组
int len = 0;
for(int i = 0; i < 1000000000; ++i) {
// bzero(dest, sizeof(dest));
memset(dest, 0, sizeof(dest));
strncpy(dest, src, sizeof(dest));
} 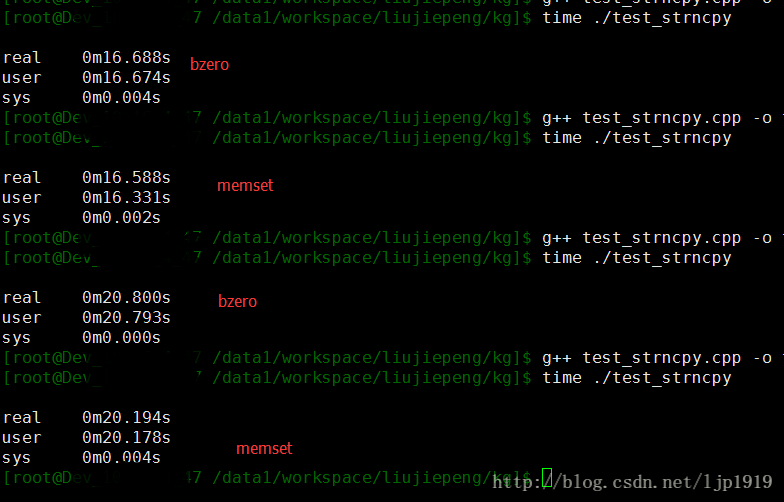
只是随着循环次数的增加,两者的差距在扩大,上图上面第一组数据,bzero和memset的差距是0.1s,而第二组数据中两者的差距变为0.7s。
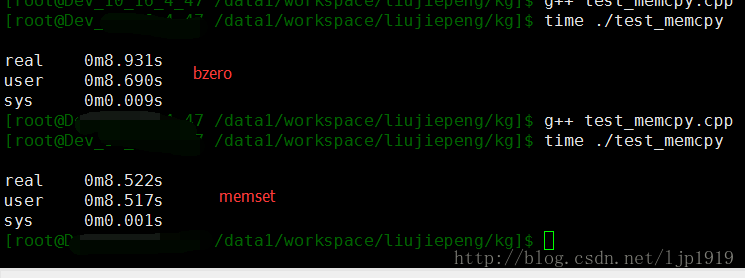
memset:
char src[] = "abcdefg1234567890";
char dest[2048];
int len = 0;
for(int i = 0; i < 100000000; ++i){
// bzero(dest, sizeof(dest));
memset(dest, 0, sizeof(dest));
len = strlen(src);
len = sizeof(dest) - 1 > len? len: sizeof(dest) -1;
memcpy(dest, src, len);
dest[len] = '\0';
} 
对于snprintf:
bzero方案运行两次,memset的编译结果也运行两次,结果分别如下,可以看出,memset性能确实由于bzero的。
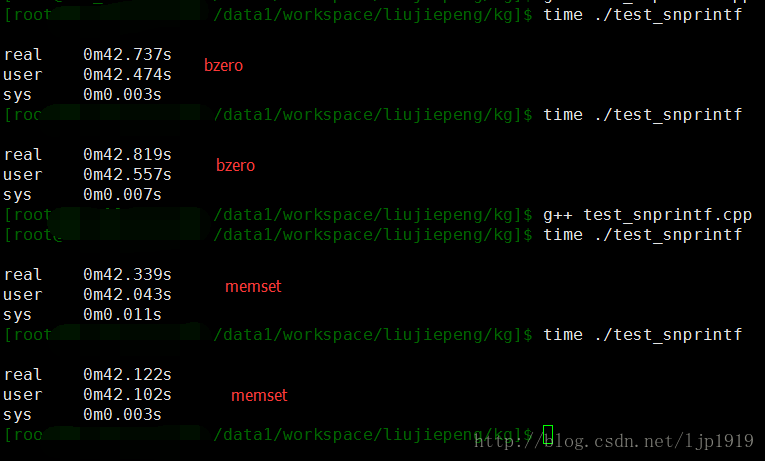
对于大数组和小数组,都是memset的性能更加优越。
综上结果,可以得出memset在置0的时候性能由于bzero。
备注:g++ test_snprintf.cpp -o test_snprintf 编译的时候并没有采用另外参数进行优化。
编译器对比和标准的选择:
同一段代码,选用不同的编译器编译后,执行效率如何呢??
采用memcpy来进行测试:
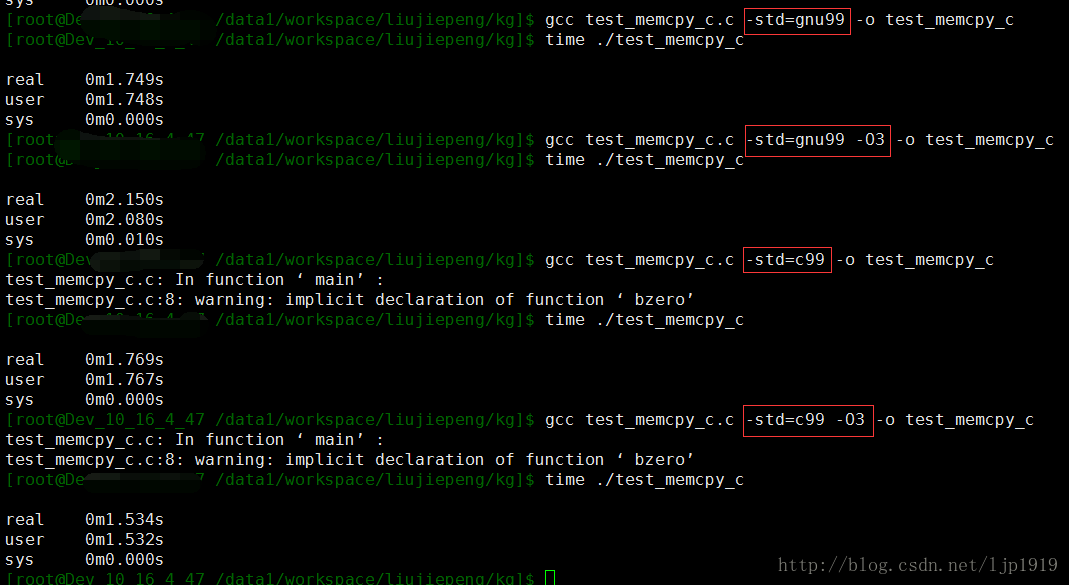
从上述结果可以看出,c99这个标准对于参数-O3才会有显著的性能提升。而对于gnu99(gnu99 , 对应 C99 的 GNU 扩展)这个标准,-O3 并不会明显提升,反而是降低了其性能。-O3该选项除了执行-O2所有的优化选项之外,一般都是采取很多向量化算法,提高代码的并行执行程度,利用现代CPU中的流水线,Cache等。所以这里是存有疑惑的?
从标准的选择来对比,能够看出c99的编译结果的执行效率要高于gnu99。