大家好,我是白露啊。
最近京东动作开始多了起来。
上一周就有人爆料京东零售开始严查考勤,并且调整了午休以及一系列工作作息相关规则:
- 早上考勤统计:
- 每天早上9点,要求统计上班工位人数。如果班车晚点,需提供证明照。
- 午休时间调整:
- 午休时间从11:30-13:30调整至12:00-13:00,午休期间工区不得熄灯。
- 严禁代打卡:
- 严禁代打卡,现在代打卡一旦被发现,将对涉及人员进行处理。
- 下班时间安排:
- 晚6点下班的员工要领导考虑工作饱和度。
- 工作沟通工具:
- 微信群中非工作的内容全部清空,所有沟通需要通过咚咚进行。
这些措施一出台,着实让不少京东员工感到紧张和困惑。
不过,在降本增效的背景下,员工的工作时长似乎成为了主要的工作饱和度评估指标。
现在严抓考勤的公司不止是京东,这两年很多公司都开始采取类似的措施。
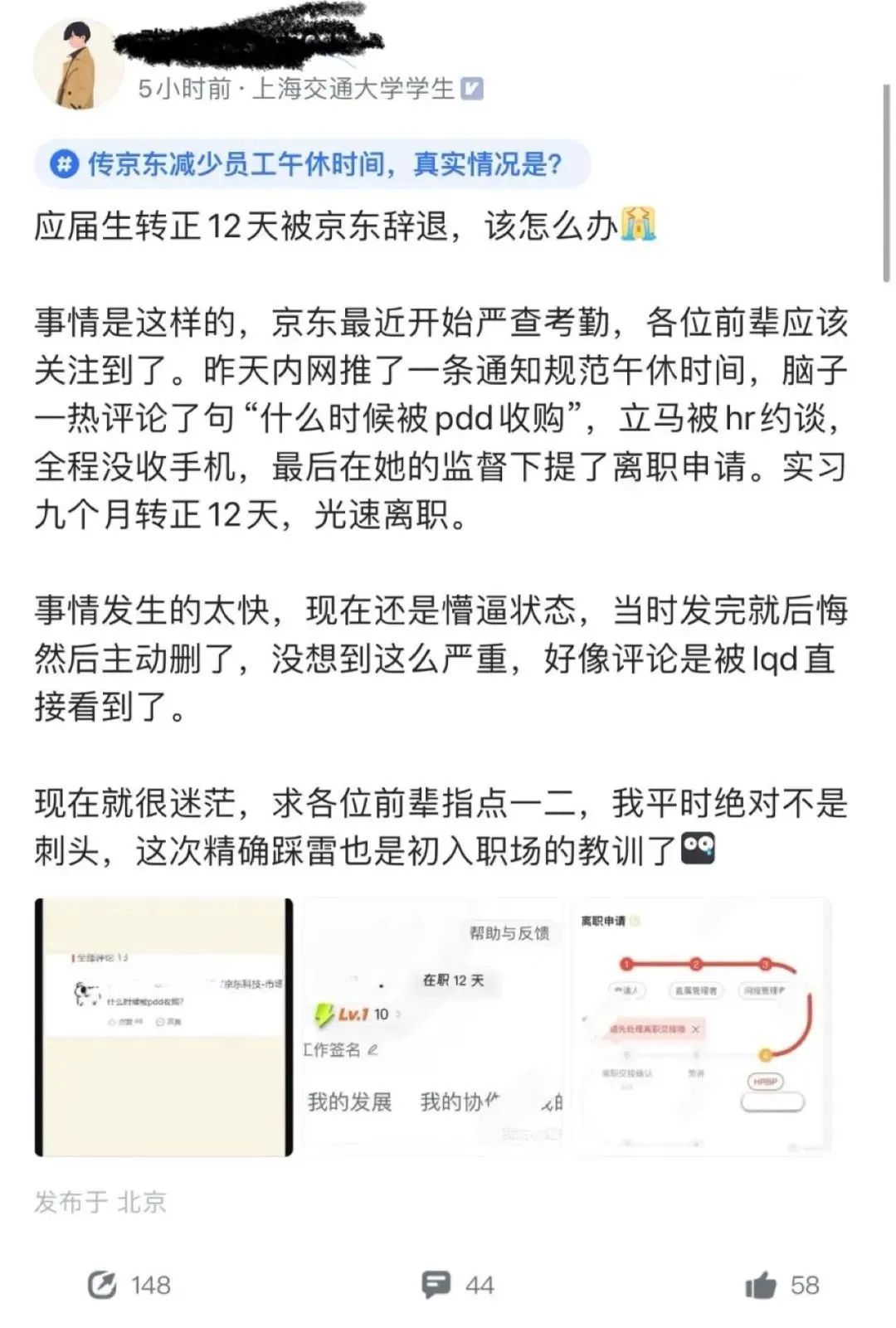
但有意思的是,一个转正12天的应届生,就因为这件事被辞退了。
事情的起因是这样的,这位同学在看到午休时间调整之后,在内网评论了一句:
“什么时候被pdd收购?”
而后立马被hr约谈,当天下午就办理理智手续了。
老实说,白露第一眼看到这个消息的时候有点懵逼。
这都什么年代了,还因言获罪?
但后面也就释然了,毕竟谎言不会伤人,真相才是快刀。
近几年京东一直被pdd压着打,从上至下肯定都憋着一团火。
这位同学心直口快的一句牢骚,正好撞枪口上了。
另外,白露还想说:言多必少,祸从口出。
言论自由,并不代表着你可以说任何事情。而是在该说的地方,说该说的话。
在职场上如此,在生活中亦是如此。
另外,我注意到京东在6.19号就开始了秋招提前批。对互联网大厂感兴趣的同学们可以趁暑假这段时间准备起来了。
今天我们就以《拿下面试官》中收录的京东到家面试题为例,看看京东面试官都喜欢怎么问吧。
京东-到家面试
面试官: 你好,今天我们就一些Java编程相关的问题进行面试。首先,请你说一下hashCode()方法。
求职者: hashCode() 方法是一个 native 方法,用于返回对象的哈希码。public native int hashCode(); 按照约定,相等的对象必须具有相等的哈希码。如果重写了 equals 方法,就应该重写 hashCode 方法。
面试官: 那么,能否介绍一下面向对象编程的三大特性?
求职者: 当然,面向对象编程有三大特性:封装、继承、多态。
- 封装:封装是指将数据(属性)和操作数据的方法(行为)捆绑在一起,形成一个独立的对象(类的实例)。
- 继承:继承允许一个类(子类)继承现有类(父类或者基类)的属性和方法。以提高代码的复用性,建立类之间的层次关系。同时,子类还可以重写或者扩展从父类继承来的属性和方法,从而实现多态。
- 多态:多态允许不同类的对象对同一消息做出响应,但表现出不同的行为。多态是一种能力——同一个行为具有不同的表现形式;换句话说,就是 Java 在运行时能根据对象类型的不同产生不同的结果。
面试官: 那么,接口和抽象类有什么区别呢?
求职者: 一个类只能继承一个抽象类,但一个类可以实现多个接口。我们在新建线程类的时候,一般推荐使用实现 Runnable 接口的方式,这样线程类还可以继承其他类,而不单单是 Thread 类。
- 抽象类符合 is-a 的关系,而接口更像是 has-a 的关系。
- 抽象类更多地是用来为多个相关的类提供一个共同的基础框架,包括状态的初始化,而接口则是定义一套行为标准,让不同的类可以实现同一接口,提供行为的多样化实现。
面试官: 接下来,我们来说说 HashMap。你能解释一下它的结构和扩容机制吗?
求职者: 在 JDK 8 中,HashMap 的结构是 数组+链表+红黑树。它的核心是一个动态数组(Node[] table),用于存储键值对。这个数组的每个元素称为一个“桶”(Bucket),每个桶的索引是通过对键的哈希值进行哈希函数处理得到的。
当多个键经哈希处理后得到相同的索引时,会发生哈希冲突。HashMap 通过链表来解决哈希冲突——即将具有相同索引的键值对通过链表连接起来。不过,链表过长时,查询效率会比较低,于是当链表的长度超过 8 时(且数组的长度大于 64),链表就会转换为红黑树。红黑树的查询效率是 O(log n),比链表的 O(n) 要快。数组的查询效率是 O(1)。
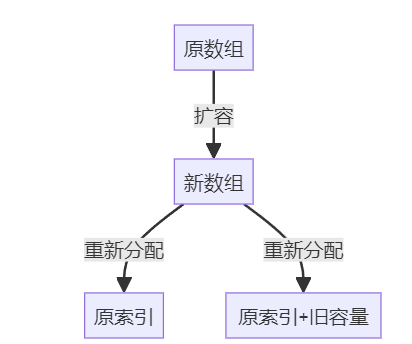
扩容机制:
当 HashMap 的容量达到一定阈值时(一般是数组容量的 0.75 倍),它会创建一个新的数组,其容量是原数组容量的两倍。然后将键值对重新分配到新数组中。一部分索引不变,另一部分索引为“原索引+旧容量”。
面试官: 很好。那你能详细说说 JVM 内存区域吗?
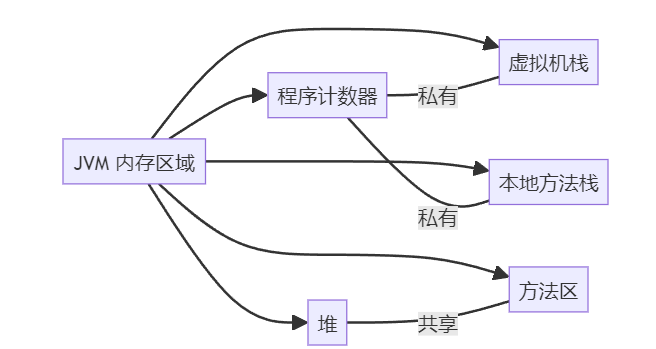
求职者: JVM 的内存区域有时叫 JVM 的内存结构,有时也叫 JVM 运行时数据区,按照 Java 的虚拟机规范,可以细分为 程序计数器、虚拟机栈、本地方法栈、堆、方法区等。
其中,方法区和堆是线程共享的,虚拟机栈、本地方法栈和程序计数器是线程私有的。
面试官: 说得不错。那对象从新生代转移到老年代的条件是什么?
求职者: 对象通常会先在年轻代中分配,然后随着时间的推移和垃圾收集的处理,某些对象会进入到老年代中。
- 长期存活的对象将进入老年代:对象在年轻代中存活足够长的时间(即经过足够多的垃圾回收周期)后,会晋升到老年代。每次 GC 未被回收的对象,其年龄会增加。当对象的年龄超过一个特定阈值(默认通常是 15),它就会被移动到老年代。这个年龄阈值可以通过 JVM 参数
-XX:MaxTenuringThreshold来设置。 - 大对象直接进入老年代:为了避免在年轻代中频繁复制大对象,JVM 提供了一种策略,允许大对象直接在老年代中分配。这些是所谓的“大对象”,其大小超过了预设的阈值(由 JVM 参数
-XX:PretenureSizeThreshold控制)。 - 动态对象年龄判定:除了固定的年龄阈值,还会根据各个年龄段对象的存活大小和总空间等因素动态调整对象的晋升策略。
面试官: 那么,如何判断一个对象是否可以回收?
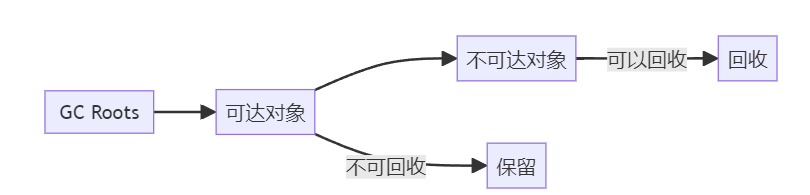
求职者: 判断一个对象是否存活,也就等同于判断一个对象是否可以被回收。通常有两种方式:引用计数算法和可达性分析算法。
- 引用计数法:每个对象有一个引用计数器,记录引用它的次数。当计数器为零时,对象可以被回收。但无法解决循环引用问题。
- 可达性分析算法:通过一组名为“GC Roots”的根对象,进行递归扫描。那些无法从根对象到达的对象是不可达的,可以被回收;反之,是可达的,不会被回收。这也是 Java 垃圾回收器(如 G1、CMS 等)使用的主要算法。
面试官: 接下来我们来聊聊 Spring。什么是 Spring 循环依赖,Spring 是如何解决的?
求职者: Spring 循环依赖指的是 A 依赖 B,B 依赖 A,或者 C 依赖 C 的情况。循环依赖只发生在 Singleton 作用域的 Bean 之间,如果是 Prototype 作用域的 Bean,Spring 会直接抛出异常。
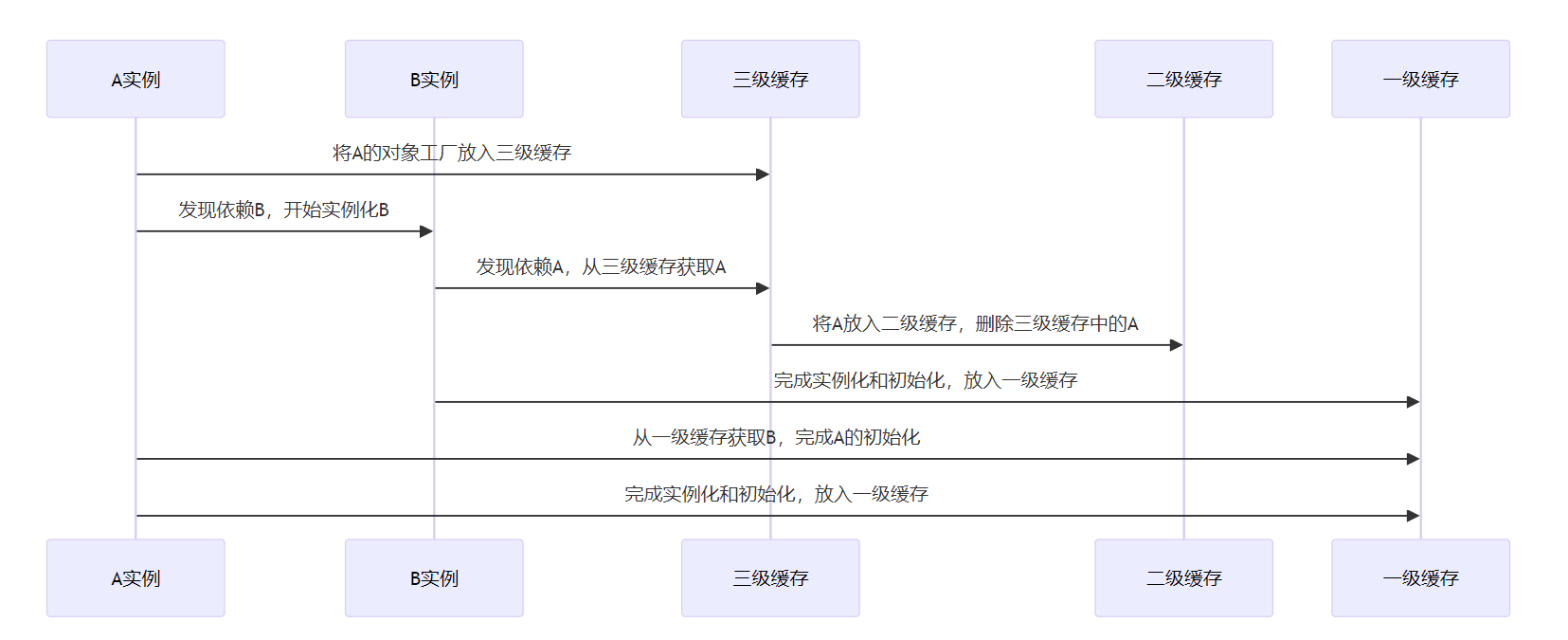
Spring 通过**三级缓存(Three-Level Cache)**机制来解决循环依赖。
- 一级缓存:用于存放完全初始化好的单例 Bean。
- 二级缓存:用于存放正在创建但未完全初始化的 Bean 实例。
- 三级缓存:用于存放 Bean 工厂对象,用于提前暴露 Bean。
三级缓存解决循环依赖的过程:
- 创建 A 实例,实例化的时候把 A 的对象工厂放入三级缓存,表示 A 开始实例化。
- A 注入属性时,发现依赖 B,此时 B 还没有被创建出来,所以去实例化 B。
- B 注入属性时发现依赖 A,它就从缓存里找 A 对象。依次从一级到三级缓存查询 A。发现可以从三级缓存中通过对象工厂拿到 A,虽然 A 不太完善,但是存在,就把 A 放入二级缓存,同时删除三级缓存中的 A。
- B 完成实例化和初始化,把 B 放入一级缓存。
- A 继续属性赋值,顺利从一级缓存拿到实例化且初始化完成的 B 对象,A 对象创建也完成,删除二级缓存中的 A,同时把 A 放入一级缓存。
- 最后,一级缓存中保存着实例化、初始化都完成的 A、B 对象。
面试官: 那么,聚簇索引和非聚簇索引有什么区别?B+树的叶子节点有什么特点?
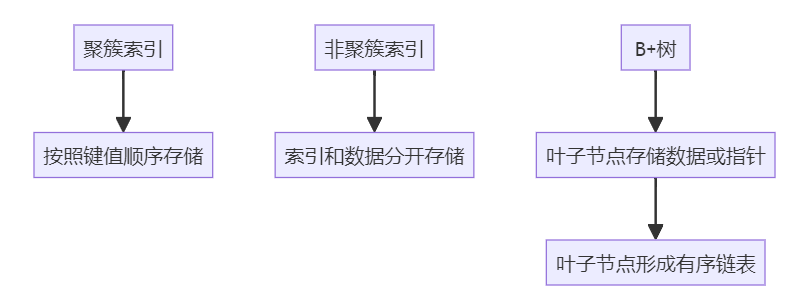
求职者: 在 MySQL 的 InnoDB 存储引擎中,主键就是聚簇索引。聚簇索引不是一种新的索引,而是一种数据存储方式。
- 聚簇索引:表中的行是按照键值(索引)的顺序存储的。这意味着表中的实际数据行和键值之间存在物理排序的关系。因此,每个表只能有一个聚簇索引。
- 非聚簇索引:索引和数据是分开存储的,索引中的键值指向数据的实际存储位置。因此,非聚簇索引也被称为二级索引或辅助索引。表可以有多个非聚簇索引。
B+树的所有值(数据记录或指向数据记录的指针)都存在于叶子节点,并且叶子节点之间通过指针连接,形成一个有序链表。
面试官: 你能解释一下 MySQL 中有哪些锁吗?
求职者: 按照锁粒度划分,MySQL 的锁有:
- 表锁:开销小,加锁快;锁定力度大,发生锁冲突概率高,并发度最低;不会出现死锁。
- 行锁:开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率低,并发度高。
- 页锁:开销和加锁速度介于表锁和行锁之间;会出现死锁;锁定粒度介于表锁和行锁之间,并发度一般。
面试官: MySQL 的事务隔离级别有哪些?默认的是哪一种?如何避免幻读?
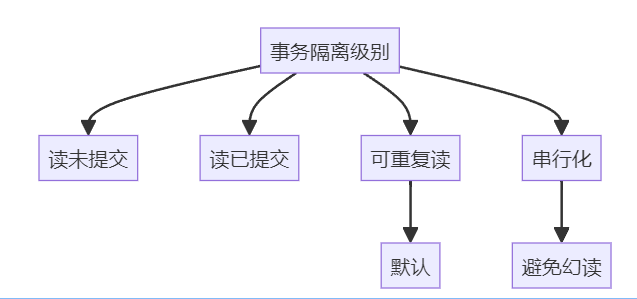
求职者: MySQL 支持四种事务隔离级别:
- 读未提交(Read Uncommitted):允许读取未提交的数据,可能会导致脏读。
- 读已提交(Read Committed):只允许读取已提交的数据,避免脏读,但可能会出现不可重复读。
- 可重复读(Repeatable Read):在同一事务内多次读取相同数据时,结果是一样的,避免不可重复读,但可能会出现幻读。这是 MySQL 的默认隔离级别。
- 串行化(Serializable):最高的隔离级别,完全隔离事务,避免幻读,但性能开销最大。
避免幻读可以通过设置隔离级别为串行化,但代价是降低并发性能。
面试官: 你能解释一下 MySQL 的三大日志吗?
求职者: MySQL 的三大日志包括:
- 二进制日志(Binary Log):记录所有修改数据库状态的 SQL 语句以及每个语句的执行时间,如 INSERT、UPDATE、DELETE 等,但不包括 SELECT 和 SHOW 这类的操作。
- 重做日志(Redo Log):记录对 InnoDB 表的每个写操作,不是 SQL 级别的,而是物理级别的,主要用于崩溃恢复。
- 回滚日志(Undo Log):记录数据被修改前的值,用于事务的回滚。
面试官: 你了解 Redis 的基本数据类型吗?
求职者: Redis 有五种基本数据类型:
- string(字符串)
- hash(哈希)
- list(列表)
- set(集合)
- sorted set(有序集合,也叫 zset)
面试官: 能否简要描述一下 Spring Boot 的启动流程和加载机制?
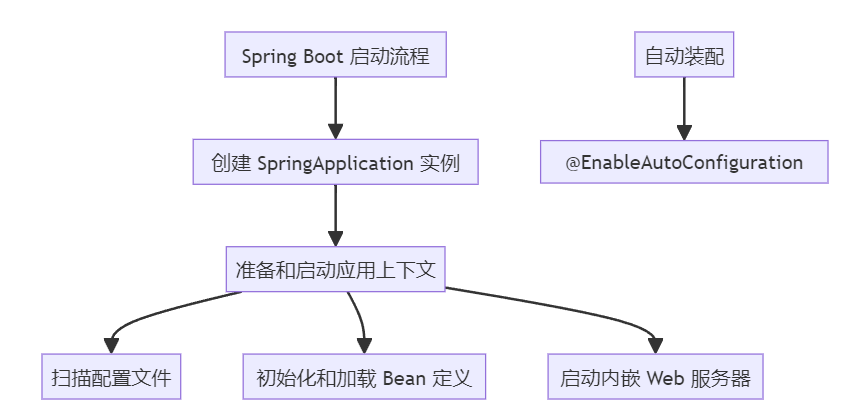
求职者: Spring Boot 应用通常有一个带有 main 方法的主类,这个类上标注了 @SpringBootApplication 注解,它是整个应用启动的入口。这个注解组合了 @SpringBootConfiguration、@EnableAutoConfiguration 和 @ComponentScan,这些注解共同支持配置和类路径扫描。
当执行 main 方法时,首先创建一个 SpringApplication 的实例。这个实例负责管理 Spring 应用的启动和初始化。
SpringApplication.run() 方法负责准备和启动 Spring 应用上下文(ApplicationContext)环境,包括:
- 扫描配置文件,添加依赖项。
- 初始化和加载 Bean 定义。
- 启动内嵌的 Web 服务器。
在 Spring 中,自动装配是指容器利用反射技术,根据 Bean 的类型、名称等自动注入所需的依赖。在 Spring Boot 中,开启自动装配的注解是 @EnableAutoConfiguration。
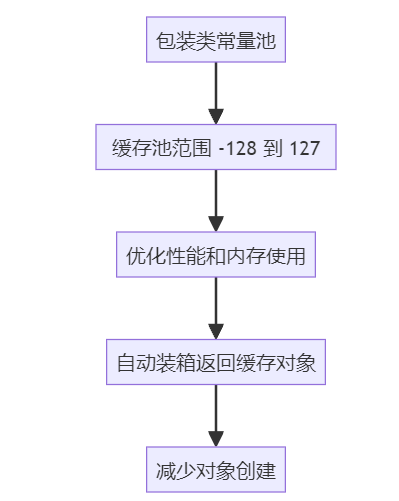
面试官: 最后一个问题,能简要说明一下包装类常量池的作用吗?
求职者: 包装类常量池主要用于优化性能和内存使用。例如,Integer 类有一个缓存池,默认范围是 -128 到 127。当我们使用自动装箱来创建这个范围内的 Integer 对象时,Java 会直接从缓存中返回一个已存在的对象,而不是每次都创建一个新的对象。这意味着,对于这个值范围内的所有 Integer 对象,它们实际上是引用相同的对象实例。
面试官: 很好,今天就到这吧。
参考原文:https://offernow.cn
AI学习助手:https://aistar.cool