第一章:什么是数据库?
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
- 1.数据以表格的形式出现
- 2.每行为各种记录名称
- 3.每列为记录名称所对应的数据域
- 4.许多的行和列组成一张表单
- 5.若干的表单组成database
1.1 RDBMS 术语
在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语:
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
MySQL 为关系型数据库(Relational Database Management System), 这种所谓的"关系型"可以理解为"表格"的概念, 一个关系型数据库由一个或数个表格组成, 如图所示的一个表格:

- 表头(header): 每一列的名称;
- 列(col): 具有相同数据类型的数据的集合;
- 行(row): 每一行用来描述某条记录的具体信息;
- 值(value): 行的具体信息, 每个值必须与该列的数据类型相同;
- 键(key): 键的值在当前列中具有唯一性。
1.2 MySQL数据库
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL 是开源的,目前隶属于 Oracle 旗下产品。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
- MySQL 对 PHP 有很好的支持,PHP 是很适合用于 Web 程序开发。
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。
- MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系统。
1.3 项目准备
高校教务管理系统”是依托Java EE(Struts 2)开发平台与MySQL 数据库相结合设计开发的一款B/S架构的应用于高校教务管理的项目,可以用来提高课程管理、班级开课和学生成绩管理工作效率。通过本系统:管理员可以对学生、班级、课程及教师的基本信息,班级开课和考试成绩进行管理及维护;教师可以查看学生成绩及录入学生成绩;学生可以查看本人成绩。
本章主要介绍“高校教务管理系统”的项目背景、项目目标、需求分析、系统设计。系统环境搭建和系统编码实现及项目发布,将在学习情境七中讲解。通过本章的学习,需要掌握以下内容:
01、项目的需求分析;
02、项目的功能模块设计;
03、项目的流程设计;
04、项目的数据库设计。
1.3.1 需求分析
该网站完成的功能主要由以下三部分组成:
1、管理员可以对学生信息、教师信息、课程信息、班级信息、班级开课及学生成绩进行管理,能够实现这些信息的添加、删除、查询、修改等操作;
2、教师可以查看个人信息、修改登录密码、查看及录入学生成绩;
3、学生可以查看个人信息、修改登录密码及查询课程成绩。
1.3.2 系统分析
下面对“高校教务管理系统”从功能设计、流程设计、数据库设计等方面进行详细分析。
第二章:认识数据库
本章主要介绍数据库技术的发展、数据库系统的组成和功能、数据的体系结构、信息的3种世界、概念模型和E-R图,以及最常用的3种数据模型。通过本章学习,需要掌握下列内容:
- 数据库系统的组成和功能
- 数据库的体系结构
- 数据模型
- 概念模型和E-R图
2.1 数据库技术的发展
2.1.1 数据库处理技术
1.数据
数据是数据库中存储的基本对象,数据的种类很多,比如:文本、图形、图像、音频、视频等。
可以对数据做如下定义:描述十五的符号记录称为数据。
数据和关于数据的解释是不可分开的。数据的解释是指对数据含义的说明,数据的含义称为数据的语义,数据与其语义是不可分的。
2.数据处理
数据处理(Data Process)是指数据进行的收集、分类、组织、编码、存储、加工、计算、检索、维护、传播以及打印;数据处理的目的是从大量的数据中根据数据自身的规律和它们之间固有的联系,通过分析、归纳、推理等科学手段提取出有效的信息资源。
2.1.2 数据库技术的发展阶段
数据库管理技术经历了人工管理、文件系统、数据库系统3个阶段。
1.人工管理阶段
人工管理数据的特点是数据有计算或处理程序自行携带,数据和应用程序一一对应,应用程序依赖于数据的物理组织,数据的独立性差,数据不能被长期保存,数据的冗余度大等问题。
2.文件系统阶段
文件系统把计算机中的数据组织成相互独立的数据文件,可以按照文件的名称对其进行访问,实现对文件中记录的查询、修改、插入和删除,但是,文件系统从整体来看却是无结构的,其数据面向特定的应用程序,所以依然存在数据共享性、独立性差,冗余度大,管理和维护的代价大等缺点。
3.数据库系统阶段
数据库管理系统(DataBase ManagementSystem,DBMS)的特点主要有以下几个方面:
1、数据结构化
2、数据的共享性高。冗余度低,易扩展
3、数据独立性高
包括数据的物理独立性和数据的逻辑独立性。
4、数据由DBMS统一管理和控制
1)、数据库的安全性(Security)保护;
2)、数据的完整性检查(Integrity);
3)、并发(Concurrency)控制;
4)、数据库恢复(Recovery)。
数据库是长期存储在计算机内有组织的大量的共享数据集合,它可以供各种用户共享,具有最小的冗余和较高的数据独立性。
2.1.3 数据库技术新发展
1、分布式数据库
分布式数据库由一组数据组成,这组数据分布在计算机网络的不同计算机上,网络中的每个结点具有独立处理的能力,可移植性局部应用。
2、面向对象数据库
数据库技术与面向对象程序设计方法相结合的产物,以关系数据库和SQL。
(1)、扩充数据类型;
(2)、支持复杂对象;
(3)、支持继承的概念;
(4)、提供通用的规则系统。
3、并行数据库
4、多媒体数据库
5、数据仓库
数据仓库是一个面向主题的、集成的。相对稳定的、反映历史变化的数据集合,用于支持管理决策。
6、数据挖掘
数据挖掘就是从大量数据中提取或挖掘知识。
7、大数据
2.2 数据库系统介绍
2.2.1 数据库系统的组成
数据库系统一般有数据库、数据库管理系统、数据库开发工具、数据应用系统和人员构成。
1、数据库
数据库数据具有永久性、有组织和可共享三个基本特点。
2、数据库管理系统
1)、数据定义功能
2)、数据组织、存储和管理
3)、数据操纵功能
例如:查询、插入、删除、修改
4)、数据库的事务管理和运行管理
以保证数据的安全性、完整性、多用户对数据的并发使用及发生故障后的系统恢复。
5)、数据库的建立和维护功能
数据库初始数据的输入、转换功能。数据库的转储、恢复功能,数据库的重组功能和性能监视、分析功能等。
6)、其他功能
DBMS与网络中与其他软件系统的通信功能;一个DBMS与另一个DBMS或文件系统的数据转换功能;异构数据库之间的互访和互操作功能了。
3、数据库应用系统
4、人员
2.2.2 数据库的体系结构
1、数据库的三级模式结构
通常DBMS将数据库的体系结构分为三级模式,即外模式、模式、内模式。
1)、外模式
外模式对应用户级数据库
2)、模式
模式对应概念级数据库
3)、内模式
内模式对应物理级数据库
2、数据库的两级映像
1)、外模型/模式映像
2)、模式/内模式映像
2.3 数据模型
2.3.1 信息世界
1、现实世界
是人们所能看见的、接触到的世界,是存在于人脑之外的客观世界。
2、概念世界
概念世界就是现实世界在人们头脑中的反映,又称为信息世界。
3、机器世界
机器世界又叫数据世界,就是概念世界中的信息数据化后对应的产物。
2.3.2 概念模型
1、基本概念
1)、实体
实体是客观存在并可以相互区分的事物,从具体的人、物、事件到抽象的状态与概念都可以用实体抽象地表示,实体不仅可指事物本身,也可指事物之间的具体联系。
2)、属性
属性(Atúibute)是实体所具有的某些特性。实体是由属性组成的,通过属性对实体进行描述。
3)、码
一个实体往往有多个属性,这些属性之间是有关系的,它们构成该实体的属性集合。如果其中有一个属性或属性集合能够唯一地标识每一个实体,则称该属性或属性集合为该实体的码(Key),
4)、实体型
具有相同属性的实体必然具有共同的特征和性质,用实体名及其属性名集合来抽象和刻画同类实体称为实体型(Entity Type)。
5)、实体集
同型实体的集合称为实体集(Entityset)。
6)、联系
现实世界中的事物之间是有联系的,即各实体型之间是有联系的。
(1) 一对一联系(1∶1);
(2) 一对多联系(1:M);
(3) 多对多联系(M:N);
2、实体-联系模型
(1)、用矩形表示实体,在矩形框内写实体名。
(2)、用椭圆形表示实体的属性,并用无向边把实体和属性连接起来。
(3)、用菱形表示实体间的联系,在菱形框内写上联系名,用无向边分别把菱形框与有关实体连接起来,在无向边旁注明联系的类型。如果实体间的联系也有属性,则把属性和菱形框也用无向边连接起来。
2.3.3 常见的3种数据模型
(1)数据结构:数据结构是对计算机的数据组织方式和数据之间的联系进行框架性述的集合,是对数据库静态特征的描述。
(2)数据操作:数据操作是指数据库中的各记录允许执行的操作集合,包括操作方及有关的操作规则等,如插入、删除、修改、检索等操作,是对数据库动态特征的描述,数据模型要定义这些操作的确切含义、操作符号、操作规则以及实现操作的语言等。
(3)数据的完整性约束:数据的约束条件是关于数据状态和状态变化的一组完整性约束规则的集合,以保证数据的正确性、有效性和一致性。
1、层次模型
2、网状模型
3、关系模型
(1)、关系:一个关系就是一张二维表,每个关系都有一个关系名
(2)、元组:二维表的行称为元组,每一行是一个元组,元组对应存储文件中的一个
录。
(3)、属性:二维表中的列称为属性,每一列有一个属性名,属性值是属性的具体值,属性对应存储文件中的一个字段。
(4)、域:域是属性的取值范围。例如,学生信息表中性别的取值范围只能是男或女,即性别的域为(男,女)。
(5)、关系模式:对关系的信息结构及语义限制的描述称为关系模式,用关系名和包含属性名的集合表示。
(6)、关键字或码:在关系的属性中,能够用来唯一标识元组的属性或属性组合称为关键字或码(Key)。
(7)、候选关键字或候选码:如果在一个关系中存在多个属性或属性组合都能用来唯一标识该关系中的元组,这些属性或属性组合都称为该关系的候选关键字或候选码,候选码可以有多个。
(8)、主键或主码:在一个关系的若干候选关键字中,被指定作为关键字的候选关键字称为该关系的主键或主码(Primary Key)。通常,我们习惯选择号码作为一个关系的主码。
(9)、主属性和非主属性;在一个关系中,包含在任何候选关键字中的各个属性都称为主属性,不包含在任一候选关键字中的属性称为非主属性。
(10)、外键或外码:一个关系的某个属性或属性组合不是该关系的主键或主键的一部分,缺失另一个关系的主键,则称这样的属性为该关系的外键或外码(Foreign Key),外码是表语表联系的纽带。
第三章:认识关系数据库
关系数据库系统是支持关系模式的数据库系统,它由关系数据结构、关系操作和关系完整性约束三要素组成。
3.1 关系数据结构
3.1.1 关系的定义和性质
1、域
定义:域是一组具有相同数据类型的值的集合
2、笛卡尔积
笛卡儿积是域上的一种集合运算。
定义:给定一组域D,D2,…,D,允许其中某些域是相同的,D,D,…,D的卡儿积定义为DxD,x…xD。={(d,由,…,d)|d∈D:,i=1,2,…,n}。其中,每一个元(d,凶,…,d,)叫做一个元组,元素中的每一个值d叫做一个分量。
3、关系
定义:D;xD,x…xD,的子集叫做在域 D,D2,…,D上的关系,表示为R(D,D,…D.)。其中,R为关系名,n表示关系的目、度或元。关系是笛卡儿积的有限子集,所以关系也是一张二维表,表的每行对应一个元组,表的每列对应一个域。由于域可以相同,为了加以区分,必须为每列起一个名字,称为属性。
4、关系的性质
关系是一种规范化了的二维表中行的集合。
- 列是同质的,即每一列中的分量是同一类型的数据,来自同一个域。
- 同一关系中的任意两个元组不能完全相同。
- 在同一关系中不同列的数据类型可以相同,但每个列必须赋予不同的属性名。
- 关系中列的顺序可以任意互换,不会改变关系的意义。
- 关系中行的次序和列的次序一样,也可以任意交换。
- 关系中每一个分量都必须是不可分的数据项,属性和元组分量具有原子性。
3.1.2 关系模式和关系数据库
1、关系模式
2、关系数据库
3.2 关系完整性
关系模型中有三类完整性约束;实体完整性(EntityIntegrity)、参照完整性(Referenti
Integriy)和用户定义完整性(User-definedIntegry)。
3.2.1 实体完整性
关系数据库中的每个元组应该是可区分的,是唯一的。
实体完整性规则:若属性(指一个或一组属性)A是基本关系R的主属性,则不能取空值。所谓空值就是“不知道”或“不存在”或“无意义”的值。
实体完整性规则:
(1) 实体完整性规则是针对基本关系而言的。一个基本表通常对应现实世界的一个实体集。
(2) 现实世界中的实体是可区分的,即它们具有某种唯一性标识。
(3) 相应地,关系模型中以主码作为唯一性标识。
(4) 主码中的属性即主属性不能取空值。如果主属性取空值,就说明存在某个不可标识的实体,即存在不可区分的实体,因此这个规则称为实体完整性。
3.2.2 参照完整性
参照完整性规则:若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码K相对应(基本关系R和S也可能是同一个关系),则R中个元组在上的值或者取空值(F的每个属性值均为空值),或者等于S中某个元组的主码值。
3.2.3 用户定义完整性
用户定义的完整性就是针对某一具体关系数据库的约束条件,它反映某一具体应用所涉及的数据必须满足的语义要求。
3.3 关系运算
关系代数是以关系为运算对象的一组高级运算的集合;
关系代数中的运算可以分为两类,一是传统的集合运算,包括并、交、差和广义笛卡儿积;二是专门的关系运算,包括选择、投影、连接和除等。
3.3.1 传统的集合运算
传统的集合运算,包括并、交、差、广义笛卡儿积四种运算。设关系R和关系S具有相同的目(即两个关系都具有n个属性),且相应的属性取自同一个域,四种运算定义如下:
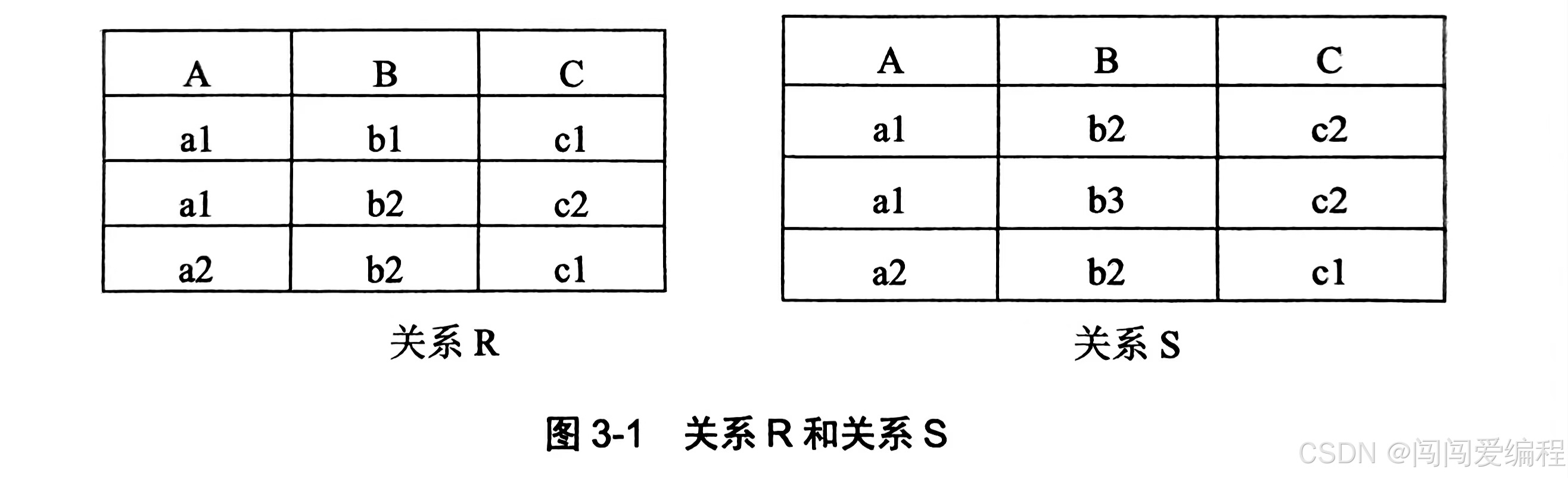
并(Union)
- 定义:设关系 R 和关系 S 具有相同的目 n(即两个关系都有 n 个属性),且相应的属性取自同一个域,则关系 R 与关系 S 的并由属于 R 或属于 S 的元组组成。
交(Intersection)
- 定义:设关系 R 和关系 S 具有相同的目 n,且相应的属性取自同一个域,则关系 R 与关系 S 的交是由既属于 R 又属于 S 的元组组成。
差(Difference)
- 定义:设关系 R 和关系 S 具有相同的目 n,且相应的属性取自同一个域,则关系 R 与关系 S 的差是由属于 R 但不属于 S 的元组组成。
广义笛卡尔积(Extended Cartesian Product)
- 定义:设关系 R 为 m 目关系,有个元组,关系 S 为 n 目关系,有q个元组,则关系 R 和关系 S 的广义笛卡尔积是一个(m+n)目关系,元组个数是p * q个。
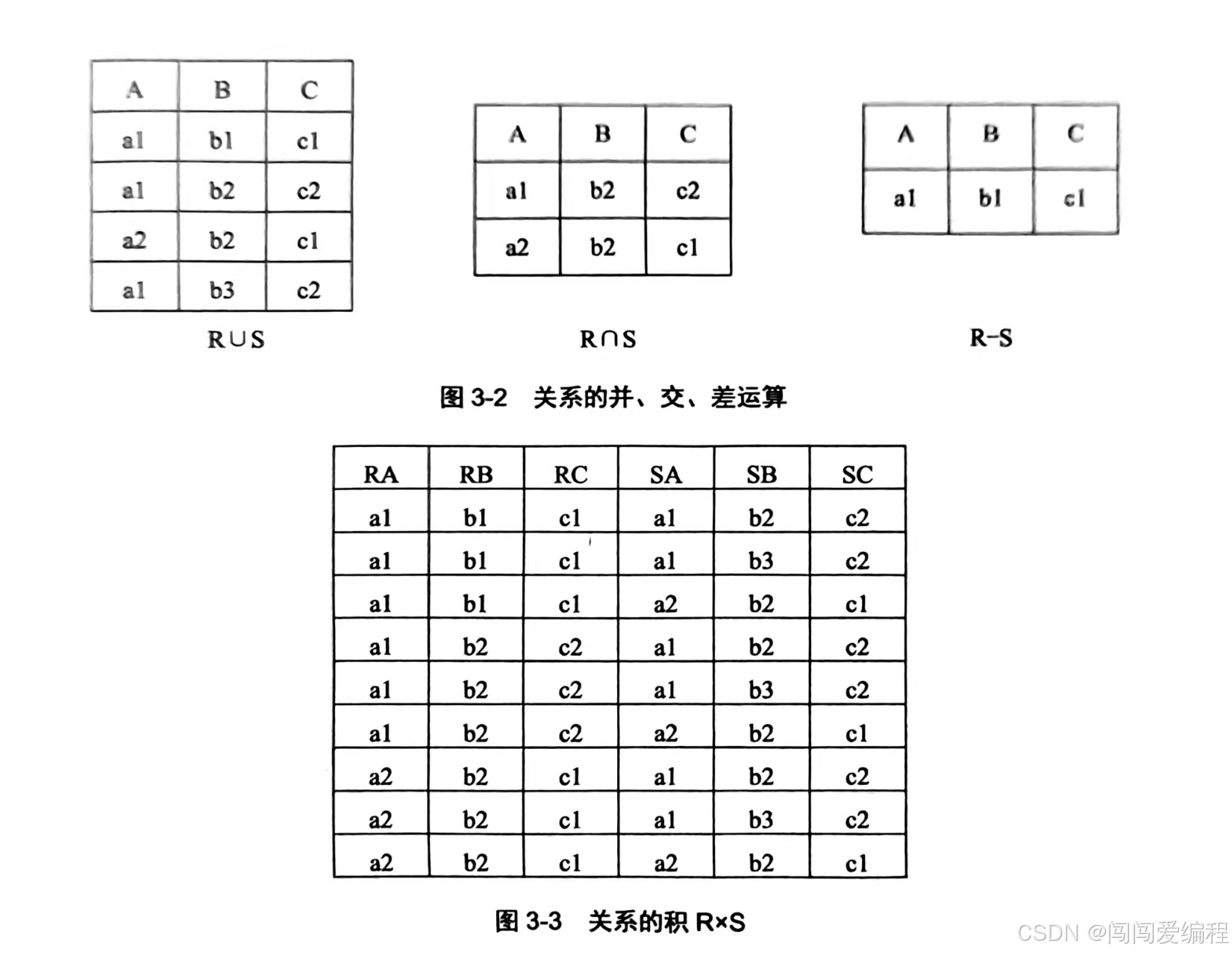
3.3.2 专门的关系运算
专门的关系运算包括选择、投影、连接、除等。
1、选择
选择(Selection)运算是指在关系R中选择满足给定条件的诸元组。
选择时在一个关系中将满足条件的元组找出来,即水平方向筛选。
2、投影运算
投影是在一个关系中去掉不需要的属性,保留需要的属性,即垂直方向筛选。
3、连接
1)、连接运算的含义
是指从两个关系的笛卡儿积中选取满足某个规定条件的全体元祖。
2)、常见的两种连接运算
(1)、等值连接
条件是类似于"B列=D列"的"某列=某列"的条件,就是等值连接;
(2)、自然连接
自然连接是不提出明确的连接条件,但"暗含"着一个条件,就是"列名相同的值也相同"。在自然连接的结果表中,往往还要合并相同列名的列。当对关系R和S进行自然连接时,要求R和S含有一个或者多个共有的属性。
4、专门的关系运算操作实例

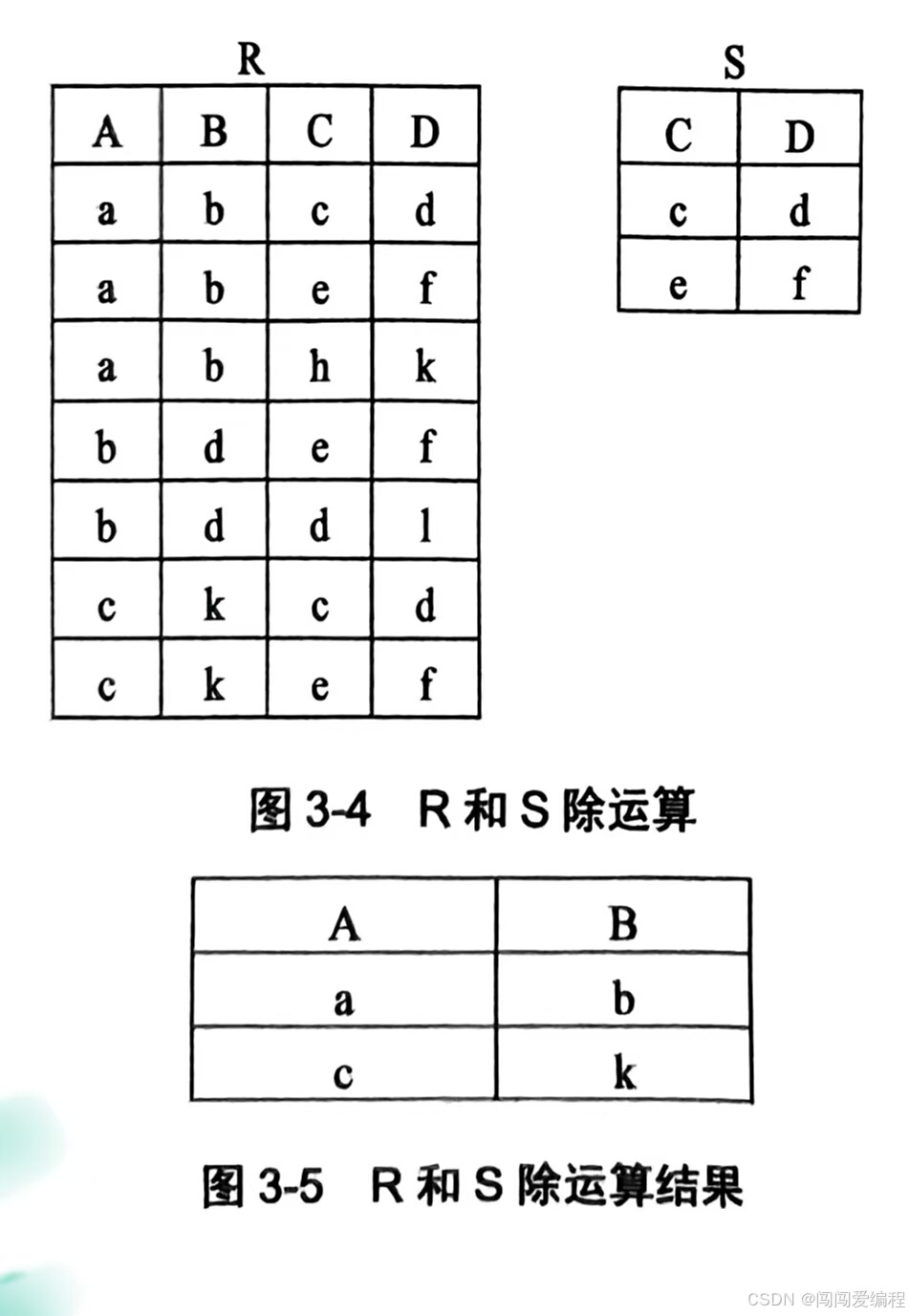
5、除运算
(1)、如果把笛卡尔积看作乘法运算,则除法是笛卡尔积的逆运算;
(2)、设有关系R和关系S,除运算需满足S的属性集是R属性集的真子集;
(3)、R÷S的结果是R属性减去S属性的结果。
3.4 关系规范化
3.4.1 关系规范化的过程
一个低一级范式的关系模式,通过模式分解可以转换为若干个高一级范式的关系模式的集合,这个过程称为规范化。
1、第一范式
设R是一个关系模式。如果R的每个属性的值域都是不可分的简单数据项的集合,则称这个关系模式属于第一范式,记为R∈1NF。
也可以说,如果关系模式R的每一个属性都是不可分解的,则R为第一范式。INF是规范化最低的范式。在任何一个数据库系统中,关系至少应该是第一范式。
2、第二范式
如果关系模式R届于第一范式,且它的每个非主属性都完全函数依赖手码(候选码)称R为满足第二范式的关系模式,记为R∈2NF。
包含在任何候选码中的各个属性称为主属性,不包含在任选码的属性称为非主属性。在规范化时,我们采用的是每个关系的最小函数依赖集。
(1) 关系RE1NF且其主码只有一个属性,则关系R一定属于第二范式。
(2) 主码是属性组合的关系,可能不属于第二范式。
3、第三范式
如果关系模式R属于第二范式,且没有一个非主属性传递函数依赖于码,则称R为满足第三范式的关系模式,记为R∈3NF。
4、BC范式
5、关系规范化
第四章:数据库设计
- 数据库设计的步骤;
- 需求分析的方法;
- 概念结构设计的方法;
- 逻辑结构设计的方法;
- 物理结构设计的内容和方法;
- 数据库的实施和维护。
4.1 数据库设计概述
4.1.3 数据库设计的基本步骤
1、需求分析阶段
2、概念结构设计阶段
3、逻辑结构设计阶段
4、物理结构设计阶段
5、数据库实施阶段
6、数据库运行和维护阶段
4.2 需求分析
4.3 概念结构设计
4.4 逻辑结构设计
4.5 物理结构设计
4.5.1 确定数据库的物理结构
确定数据的存储结构、设计数据的存取路径、确定数据的存放位置和确定系统配置。
1、确定数据的存储结构
存取时间、存储空间利用率和维护代价三个方面的因素。
2、设计数据的存取路径
索引方法(目前主要是B+树索引方法)、聚簇(CLUSTER)和 HASH(哈希)方法。
1)、 索引方法
在关系数据库中,选择存取路径主要是指确定如何建立索引。
2)、聚簇方法
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚簇码)上具有相值的元组集中存放在连续的物理块上称为聚簇。
3)、HASH方法
(1)该关系的属性主要出现在等值连接条件中或相等比较选择条件中。
(2)该关系的大小可预知且关系的大小不变,或该关系的大小动态改变但所选用的DBMS 提供了动态 HASH存取方法。
3、确定数据的存放位置
易变部分与稳定部分分磁盘存放把经常存取部分和存取频率较低部分分磁盘存放,以及把数据表和索引分磁盘存放、把数据和日志分磁盘存放等。
4、确定系统配置
4.5.2 评价物理结构
时间效率、空间效率、维护代价和各种用户要求进行权衡。
4.6 数据库的实施、运行与维护
1、如模式和子模式中加入感数据库安全性、完整性的描述;
2、完成应用程序和加载程序的设计;
3、数据库系统的试运,并在试运行中对系统进行评价;
4、如果评价结果不能满足用户要求,还需要对数据库进行修正设计。
4.6.1 数据库的实施
计算机上建立起实际的数据库结构并装入数据、进行试运行和评价的过程叫数据库的实施或实现。
1.建立实际的数据库结构
定义语言(DDL)编写描述逻辑设计和物理设计结果的程序(一般称为数据库脚本程序),经计算机编译处理和执行后就生成了实际的数据库结构。
2.数据的加载
数据库应用程序的设计应该与数据库设计同时进行。通常,应用程序的设计应该包括数据库加载程序的设计。
3.数据库的试运行和评价
在加载了部分必需的数据和应用程序之后,就可以开始对数据库系统进行联合调度了称为数据库的试运行。一般将数据库的试运行和评价结合起来,目的如下:
(1) 测试应用程序的功能。
(2) 测试数据库的运行效率是否达到设计目标,是否为用户所容忍。
测试的目的是众现问题,而不是为了说明能实现哪些功能,所以在测试中一定要有非设计人员参与。
4.6.2 数据库的运行与维护
4.7 数据库设计实例
1、需求分析
与用户协商,了解用户的需求,了解需要哪些数据和操作,确定系统中应包含的书籍员工、部门和出版社实体。
2、概念结构设计
根据需求分析,可以得到图书借阅系统的E-R图。
3、逻辑结构设计
根据E-R图,结合表的转换原则。
4、物理结构设计
根据查询需求设计每个关系的索引文件。
第五章:MySQl数据库
- 了解数据库及其对象;
- 熟练掌握创建/删除、备份/恢复数据库的方法。
6.1 MySQl数据库管理
6.1.1 创建数据库
MySQL中创建数据库的基本SQL语法格式如下:
create database <数据库名>;创建数据库的基本语法:
CREATE DATABASE [IF NOT EXISTS] database_name
[CHARACTER SET charset_name]
[COLLATE collation_name];6.1.2 查看数据库
使用MySQl命令“show databases”,即可查看当前Mysq服务实例上所有的数据库:
show databases;6.1.3 显示数据库结构
使用MySQl命令“show create database database_name”,即可查看名为database_name的数据库。
show create database database_name;6.1.4 选择当前操作的数据库
在MySQl命令提示符窗口中,使用use命令即可指定当前操作的数据库,其命令格式如下:
use database_name;6.1.5 删除数据库
使用SQL语句drop database 即可删除名为database_name的数据库,其命令格式如下:
DROP DATABASE database_name; -- 直接删除数据库,不检查是否存在
或
DROP DATABASE [IF EXISTS] database_name;解析:
IF EXISTS是一个可选的子句,表示如果数据库存在才执行删除操作,避免因为数据库不存在而引发错误。database_name是你要删除的数据库的名称。
6.2 MySQl数据库的备份和恢复
6.2.1 导出或导入表数据
用户可以使用select into ... outfile语句将表数据导入到一个文本文件中,并用load data...infile语句恢复数据。但是这种方式只能导出或导入数据的内容,不包括表的结构。如果标的结构文件损坏,则必须先恢复原来表的结构。
1、导出表数据
SELECT *INTO UTFIE文件名1
[FIELDS
[TERMINATED BY 'string']
[[OPTIONALLY]ENCOSED BY 'char']
[ESCAPED BY 'char']]
[LINES TERMINATED BY 'string']
|DOMPFILE '文件名2'使用OUTFILE时,可以加入两个自选的子句,它们的作用是决定数据行在文件中存放格式。(1)FIELDS子句:至少需要下列三个指令中的一个。
- TERMINATEDBY:指定字段值之间的符号,例如,“TERMINATEDBY”指定了逗号作为两个字段值之间的标志。
- ENCLOSEDBY:指定包裹文件中字符值的符号,例如,“ENCLOSEDBY'示文件中的字符值放在双引号之间,若加上关键字OPTIONALLY则表示所有的值都放在引号之间。
- ESCAPEDBY:指定转义字符,例如,“ESCAPEDBY'*”将“*”指定为转义字取代“\”,如空格将表示为“*”
(2)LINES子句:使用TERMINATEDBY指定一行结束的标志,如“LINESERMINATED BY"?”表示一行以“?”作为结束标志。
2、导入表数据
LOAD DATALOWRIORITYICONCURRENT][LOCAL]INFIE件名.txt
[REPLACE | IGNORE]
INTO TABLE 表名
[FIELDS
[TERMINATED BY 'string']
[!OPTIONALLY] ENCLOSED BY 'char']]
[ESCAPED BY 'char']
[LINES
[STARTINT BY 'string']
[TERMINATED BY 'string']]
[IGNORE number LINES]
[(列名或用户变量,…)]
[SET 列名-表达式,]- LOW_PRIORITYICONCURRENT:若指定LOWPRIORITY,则延迟语句的执指定CONCURRENT,则当LOADDATA执行的时候,其他线程也可以同时使用该数据。
- LOCAL:文件会被客户端读取,并被发送到服务器。
- 文件名.txt:该文件中保存了待存入数据库的数据行,它由SELECTINTO…OUTE命令导出产生。载入文件时可以指定文件的绝对路径,若不指定路径,则服务器在数据默认目录中读取。
- 表名:该表在数据库中必须存在,表结构必须与导入文件的数据行一致。
- REPLACEIIGNORE:如果指定了REPLACE,则当文件中出现与原有行相同的唯-键字值时,输入行会替换原有行,如果指定了IGNORE,则把与原有行有相同的唯一关字值的输入行跳过。
- FIELDS子句:和SELECTINTO…OUTFILE语句类似。用于判断字段之间和数据行间的符号。
- LINES 子句:TERMINATEDBY指定一行结束的标志。
- STARTINTBY指定一个前导入数据行时,忽略行中的该前缀和前缀之前的内容。如果某行不包括该前缀,则整个被跳过。
- IGNOREnumber LINES:这个选项可以用于忽略文件的前几行。行数由number指定列名或用户变量:如果需要载入一个表的部分列或文件中字段值的顺序与表中列的顺序不同,就必须指定一个列清单。
- SET子句:可以在导入数据时修改表中列的值。
第六章:MySQl数据库表操作
在数据库中,表是存储数据的容器,是最重要的数据对象。一个完整的表包括表结构和表数据(也叫记录)两部分内容。通过学习本章,需要掌握以下内容:
- 创建数据库表的方法
- 维护数据库表的方法
- 对表数据进行操作的方法
6.1 MySQL数据类型
MySQL提供的数据类型包括:数值类型、字符串类型、日期类型、二进制类型和复合类型。
6.1.1 数值类型
MySQL 支持支持五种整数类型:tinyint、smallint、mediumint、int和bigint,如下表所示这些整数类型的取值范围依次递增,如果只希望表示0和正整数可以使用无符号关键字“unsigned”对整数类型进行修饰;
MySQL支持两种小数类型:精确小数类型decimal和浮点类型,其中浮点类型分为float单精度浮点数和double双精度浮点数,Decimal(length,precision)用于表示精度确定(小数点后数字位数确定)的小数类型,其中length用来决定概述的最大位数,precision用来设置精度(小数点后数字的位数),无符号关键字unsiged也可用于修饰小数。

6.1.2 字符串类型
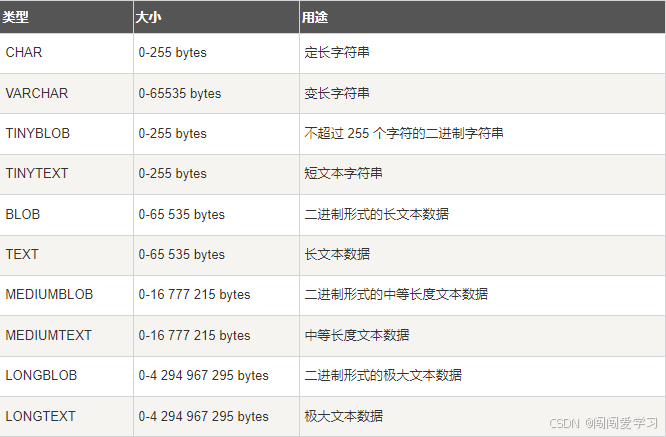
MySQL主要支持六种字符串类型:char、varchar、tinytext、text、mediumtext、longtext。
char(n)为定长字符串类型,表示占用了n个字符(注意不是字节)的存储空间,n的最大值为255,;
varchar(n)为变长字符串类型,这就意味着此类字符串占用的存储空间就是字符自身占用的存储空间,与n无关,这与char(n)不同。
除了varchar(n)以外,tunytext、text、mediumtext和longtext等数据类型也都是变长字符串类型。
6.1.3 日期类型
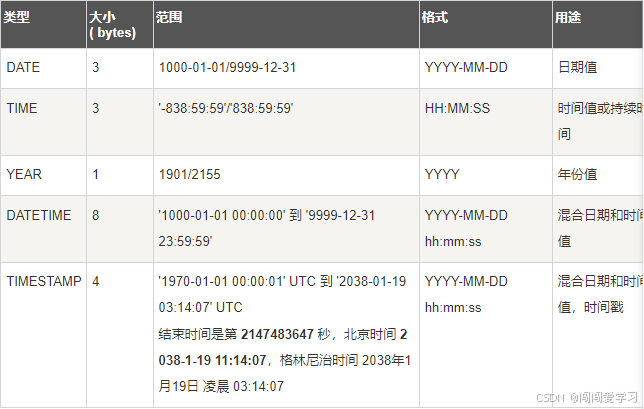
MySQL主要支持5种日期类型:date、time、year、datetime和timestamp。其中,dat表示日期,默认格式为'YYYY-MM-DD':time表示时间,默认格式为HH:ii:ss':year表示份:datetime与timestamp是日期和时间的混合类型,默认格式为'YYYY-MM-DD HH:ii:ss'。
datetime与timestamp都是日期和时间的混合类型,它们之间的区别如下。
- 表示的取值范围不同,datetime的取值范围远远大于timestamp的取值范围
- 将NUL插入timestamp字段后,该字段的值实际上是MySQL服务器当前的日期和时间。
- 对于同一个 timestamp类型的日期或时间,不同的时区显示结果不同。使用 MySQL命令“show variables like 'ime zone,;”可以查看当前 MySQL服务实例的时区。
- 当对包含timestamp数据的记录进行修改时,imestamp数据将自动更新为MySQI服务器当前的日期和时间
6.1.4 二进制类型
MYSQL主要支持7种二进制类型:binary、varbinary、bit、tinyblob、blob、mediumblob 和longblob。二进制类型的字段主要用于存储由'0'和’1'组成的字符串。从某种意所示义上讲,二进制类型的数据是一种特殊格式的字符串。二进制类型与字符串类型的区别在于,字符串类型的数据以字符为单位进行存储,因此存在多种字符集、多种字符序;除了bit 数据类型以位为单位进行存储外,其他二进制类型的数据都以字节为单位进行存储,仅存在二进制字符集 binary。
6.1.5 复合类型
MYSOL支持两种复合数据类型:enum枚举类型和set集合类型。
enum 类型的字段只允许从一个集合中取得某一个值,类似于单选按钮的功能。例如,一个人的性别从集合“男”女"中取值,且只能取其中一个值。
se t类型的字段允许从一个集合中取得多个值,类似于复选框的功能。例如,一个人的兴趣爱好可以从集合{听音乐,看电影,购物,旅游,游泳,游戏”中取值,自可以取多个值。
一个enum类型的数据最多可以包含65535个元素,一个set类型的数据最多可以包含64个元素。
6.1.6 如何选择合适的数据类型
(1)在符合应用要求(取值范围、精度)的前提下,尽量使用“短”数据类型。“短”数据类型的数据在外存(如硬盘)、内存和缓存中需要更少的存储空间,查询连接的效率更高,计算速度更快。
(2)数据类型越简单越好。
(3)尽量采用精确小数类型(如_decimal),而不采用浮点数类型。
(4)在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储日期和时间。
(5)尽量避免NULL字段,建议将字段指定为notnu!l约束。
6.2 MySQL表操作
6.2.1 创建表
1、创建全新表
创建 MySQL 数据表需要以下信息:
- 表名
- 表字段名
- 定义每个表字段的数据类型
以下为创建 MySQL 数据表的 SQL 通用语法:
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
);参数说明:
table_name是你要创建的表的名称。column1,column2, ... 是表中的列名。datatype是每个列的数据类型。
【例6.2.1】在jwgl数据库中创建学生表student:
use jwgl;
create table student(
stu_id char(10) primary key,
stu_username char(10) not null,
stu_sex enum('男','女') not null,
stu_birthdate date not null);例题解析:
stu_id: 用户 id,整数类型,自增长,作为主键。stu_username: 用户名,变长字符串,不允许为空。stu_name: 用户性别,枚举类型,不允许为空。stu_birthdate: 用户的生日,日期类型。
2、复制已有表
以下为复制 MySQL 数据表的 SQL 通用语法:
CREATE TABLE new_name LIKE person;
CREATE TABLE copy_name AS (select * from person);其中LIKE关键字的表明应该是已经存在的表,AS 后为可以复制的表内容。
3、查看表和表结构
表创建完成后,可以使用show tables命令查看数据库中有哪些表,还可以使用describe命令显示表的结构。
以下为查看数据表的 SQL 通用语法:
USE jwgl;
SHOW TABLES;
DESCRIBE student;6.2.2 修改表
1、修改表结构
ALTER TABLE用于更改表的结构,可以增加或删除列一创建或取消索引、更教原看列的数据类型、重新命名列或表,还可以更改表的批注和表的类型。
以下为修改表结构的 SQL 通用语法:
ALTER TABLE 表名
ADD列定义[FIRSTIAFTER 列名]
|IMODIEY 列定义
|IALTER 列名 {SET DEFAULT值|IDROP DEFULTI}
|CHANGE 列名 原列名
|DROP 列名
|RENAME[TO] 新表名ADD 子句:向表中增加新列。通过“FIRSTIAFTER列名”指定增加列的位置,加在最后一列。
在person表中增加一列sex:
use temptest;
ALTER TABLE person ADD sex char(l)null;MODIFY子句:修改指定列的数据类型。
要把一个列的数据类型修改为enum:
ALTER TABLE person MoDIFY sexenum('男,女')not null;ALTER 子句:修改表中指定列的默认值,或者删除列的默认值。
CHANGE 子句:修改列的名称。
DROP 子句:删除列或约束。
在jwgl数据库的student表中增加emai 列,并将stu pwd 列删除:
use jwgl;
ALTEK TABlE student
ADD email varchar(20)null
DROP stu_pwd;2、更改表名
除了上面的ALTERTABLE命令,还可以直接用RENAMETABLE语句来更改表的称。命令格式如下:
RENAME TAELE 原表名 TO 新表名;6.2.3 删除表
需要删除一个表时可以使用DROP TABLE语句,其语法格式如下:
DROP TABLE [IF EXISTS] 表名...; -- [IF EXISTS] 会检查是否存在,如果存在则删除参数说明:
table_name是要删除的表的名称。IF EXISTS是一个可选的子句,表示如果表存在才执行删除操作,避免因为表不存在而引发错误。
删除表copy_person:
DROP TABLE IF EXISTS copy_person;6.3 MySQL表记录操作
6.3.1 插入记录
MySQL 表中使用 INSERT INTO 语句来插入数据。
1、插入新记录
以下为向MySQL数据表插入数据通用的 INSERT INTO SQL语法:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
参数说明:
table_name是你要插入数据的表的名称。column1,column2,column3, ... 是表中的列名。value1,value2,value3, ... 是要插入的具体数值。
如果数据是字符型,必须使用单引号 ' 或者双引号 ",如: 'value1', "value1"。
use jwgl;
insert into student
values('18010101','秦始皇','男','259',null,null,null,null,null);2、从已有表中插入新记录
使用INSERTINTO…SELECT…语句可以快速地从一个或多个已有的表记录问表入多个行,其语法格式如下:
INSERT[INTO)表名[(列名,.)]
SELECT 语句;3、插入图片
MySQL还支持插入图片,图片一般要以路径的形式来存储,即可以采用插入图片的存储路径的方式来操作。当然也可以直接插入图片,只要用LOADFE函数即可。
向 student表中插入一行数据,除包含非空列外还包含 stu picture 列。
INSERT INTO student(stu no,stu name,stu sex,stu birth,stu picture)
VALUES('1801010102',张吉哲',男’,'2000-12-05','D:\IMAGE\02.jpg');6.3.2 修改记录
1、替换旧记录
REPLACE语句可以再插入数据之前将于新纪录冲突的旧记录删除,从而使新记录能够替换旧记录,正常插入。REPLACE语的格式与ISERT相同,其语法格式如下。
REPLACE INTO)表名
((列名,…)] VALUES({exPrIDEFAULT}...)
|SET 列名-{exprIDEFAULT},…REPLACE INTO student(stu no,stu name,stu sex,stu birth)
VALUES('1801010102',王胜男',女',1999-11-08');2、修改单个表
修改单个表的语法格式如下:
UPDATE 表名
SET列名1=expr1[列名2=expr2,..]
[WHERE 条件]若语句中不设定WHERE子句,则更新所有行。列名1、列名2...为要修改的列,列值为expr,expr可以是常量、变量、列名或表达式。可以同时修改所在数据行的多个列值,中间用逗号分隔。
WHERE子句:指定的修改记录条件。如果省略则修改表中的所有行。
修改jwgl数据库中student表中的秦建兴同学的数据,将备注修改为“辅修金融学专业”:
UPDATE student
SEt stu_remark='辅修金融学专业'
WHERE stu_name='秦建兴';3、修改多个表
UPDATE 表名,表名...
SET 列名1=expr1[列名2=expr2,...]
[WHERE 条件]修改jwgl数据库中的 student表和 xs表,将秦建兴同学的出生日期 stu_binh修改为“1999年5月15日”:
UPDATE student,xs
SET student.stu birth='1999-5-15',xs.stu birth='1999-5-15
WHERE student.stuno=xs.stuno AND xs.stu name='秦建兴';6.3.3 删除记录
DELETE语句或TRUNCUTETABLE语句可以用来删除表中的一行或多行记录。
1、删除单个表的行
使用DELETE语句可以删除数据表中的一行或多行记录。
其基本语法格式如下:
DELETE FROM table_name
WHERE condition;
参数说明:
table_name是你要删除数据的表的名称。WHERE condition是一个可选的子句,用于指定删除的行。如果省略WHERE子句,将删除表中的所有行。
2.使用 TRUNCATE TABLE 清空数据表
清除表中所有记录也可以使用TRUNCATETABLE语句。
其语法格式如下:
TRUNCATE TABLE 表名;第七章:MYSQL索引与完整性约束
7.1 MySQL索引
7.1.1 MySQL索引概述
MySQL 索引是一种数据结构,用于加快数据库查询的速度和性能。
MySQL 索引的建立对于 MySQL 的高效运行是很重要的,索引可以大大提高 MySQL 的检索速度。
索引分单列索引和组合索引:
- 单列索引,即一个索引只包含单个列,一个表可以有多个单列索引。
- 组合索引,即一个索引包含多个列。
合适的索引具有以下功能:
(1)、加快数据查询;
(2)、加快表的连接;
(3)、索引能提高WHEKE语句的数据提取速度,也能提高更新和删除数据记录的速度;
(4)、确保数据的唯一性。
7.1.2 创建索引的原则
(1)、PRIMARYKEY约束所定义的作为主键的字段,主键可以快速定位到相应的记录
(2)、应用UNIQUE约束的字段,唯一键可以加快定位到相应的记录,还能保证键的唯一性。
(3)、FOREIGNKEY约束所定义的作为外键的字段,因为外键通常用来做连接,在外键上建索引可以加快表间的连接。
(4)、在经常被用来搜索数据记录的字段上建立索引,键值就会排列有序,查找时就会加快查询速度。
(5)对经常用来作为排序基准的字段建立索引。
7.1.3 索引的分类
索引是根据表中的一列或若干列按照一定顺序建立的列值与记录行之间的对应关系表。在列上创建索引之后,查找数据时可以直接根据该列上的索引找到对应行的位置,从而快速地找到数据。
索引类型分成以下几种。
1)普通索引
普通索引(INDEX)是最基本的索引类型,它没有唯一性之类的限制。创建普通索引的关
键字是 INDEX。
2)唯一性索引
唯一性索引和前面的普通索引基本相同,但有一个区别,索引列的所有值只能出现-次,即必须是唯一的。
3)主键
主键(PRIMARYKEY)是一种唯一性索引。主键一般在创建表的时候指定,也可以通过修改表的方式加入主键。但是每个表只能有一个主键。
4)全文索引(FULLTEXT)
MySQL支持全文检索和全文索引。全文索引只能在VARCHAR或TEXT类型的列上创建。
7.2 MySQL索引操作
1、CREATE INDEX 语句创建
CREATEINDEX语句可以在一个已有表上创建索引,一个表可以创建多个案引,其法格式如下:
CREATE [UNIOUE|FULLTEXTISPATIA]
INDEX索可名[素引类型] ON 表名(索引列名)
[索引选项]...其中索引列名的形式:列名[(长度)][ASCIDESC]。
UNIQUE表示创建的是唯一性索引;FULLTEXT表示创建全文索引;SPATIAL表示建空间索引,可以用来索引几何数据类型的列。
索引名、案引在一个表中名称必须是唯一的。
索引类型:BTREE和HASH。BTREE为采用二叉树方式,HASH为采用哈希方式.
索引列名:创建索引的列名后的长度表示索引中关键字的长度。这可使索引文件的太大藏小,从而节省磁盘空间。另外,还可以规定索引按升序(ASC)或降序(DESC)排列,默认
为 ASC.
如果一个索引包含多个列,中间用逗号隔开,但它们属于同一个表,这样的索引叫做
复台索引。
但是,CREATE INDEX语句并不能创建主键。
根据sudent表的学号列上的前6个字符建立一个升序索引xhindex。在Scon表上建立一个学号和课程号的复合索引xhkh。
USE jwgl;
CREATE INDEX xh_index ON student(stu_no(5) ASC);
CREATE INDEX xs_kh ON score(stu_no,course_no);使用“SHOWINDEXFROM 表名”命令查看表的索引情况。
2、在建立表时创建索引
CREATE TABLE [IF NOT EXISTS]表名
({ [列定义],…[|索引定义]
PRIMARY KEY( 列名,...));3、ALTER TABLE 语句创建索引
用户使用ALTERTABLE语句修改表,其中也包括向表中添加索引,其语法格式如下:
ALTER TABLE表名
...
|ADD PRIMARY KEY(列名) /*主键*/
|ADD INDEX|KEY索引名][索引类型](索引列名,…) /*普通索引*/
|ADD UNIQUE[索引名](索引列名,.) /*唯一性索引*/
|ADD FOREIGN KEY【索引名](索引列名,…)【参照性定义] /*外键*/
4、删除索引
当一个索引不再需要时,可以用DROPINDEX语句或ALTERTABLE语句删除。
1)使用 DROP INDEX 删除
DROP INDEX 索引名 ON 表名2)使用 ALTER TABLE 删除
ALTER TABLE 表名
DROP PRIMARY KEY
|DROP 索引名
|DROP FOREIGN KEY 外键标识7.3 MySQL数据完整性约束
7.3.1 主键约束
主键就是表中的一列或多个列的组合,其值能唯一地标识表中的每一行,是实体完
性的其体实现。
(1)通过定义PRIMARYKEY约束来创建主键,而且PRIMARYKEY约束中的列不
取空值;
(2)当为表定义PRIMARYKEY约束时,MySQL为主键列创建唯一性索引,实现数
的唯一性;
(3)在查询中使用主键时,该索引可用来对数据进行快速访问;
(4)如果PRIMARYKEY约是由多列组合定义的,则某一列的值可以重复,但PRIMARYKEY约束定义中所有列的组合值必须唯一;
可以用两种方式定义主键,作为列或表的完整性约束。
(1)作为列的完整性约束时,只需在列定义的时候加上关键字PRIMARY KEY。
(2)作为表的完整性约束时,需要在语句最后加上一条PRIMARYKEY(列名..)子句。
创建course表,将course_no 定义为主键:
create table courses
(course_no char(6) primary key,
course_name varchar(16) not null);7.3.2 代替键约束
替代键约束像主键一样,是表的一列或多列,它们的值在任何时候都是唯一的。替代键是没有被选作主键的候选键。定义替代键的关键字是UNIQUE。
创建表stul,并将表中的姓名stu_name 定义为替代键。
Create table stu1
(Stu_no char(10)primary key,
Stu_name char(10)not null UNIQUE,
Stu_sexenum('男','女')not null,
Stu_birth date not null);在MySQL中,替代键和主键的区别主要有以下几点:
(1)一个数据表只能有一个主键。但是一个表可以有若干个 UNIQUE 键,并且它们甚至可以重合。例如,在C1和C2列上定义了一个替代键,同时又在C2和C3列上定义了另一个替代键。
(2)主键字段的值不允许为 NULL,而 UNIQUE 字段的值可以取 NULL,但是必须使用 NULL 或 NOT NULL声明。
(3)一般创建PRIMARYKEY约束时,系统会自动产生PRIMARYKEY索引。创建UNIQUE 约束时,系统自动产生UNIQUE索引。
7.3.3 参照完整性约束
创建表时定义参期完幕性的语法格式如下:
CREATE TABLE [IF NOT EXISTS] 表名
( [列定义),...|[索引定义]
PRIMARY KEY (列名,));
|FOREIGN KEY [索引名](索引列名)【参照性定义]
REFERENCES 表名((索引列名)
[ON DELETE {RESTRICT|CASCADE |SET NULL|NO ACTION}]
[ON UPDATE {RESTRICT|CASCADE |SET NULL|NO ACTION}]
FOREIGNKEY:称为外键,被定义为表的完整性约束。
REFERENCES:称为参照性,定义中包含外键所参照的表和列。这里的表叫被参照而外键表叫参照表。其中,列名是外键可以引用一个或多个列,外键中的所有列值在引用的列中必须全部存在。外键可以只引用主键或替代键。
ON DELETEION UPDATE:可以为每个外键定义参照动作。
参照动作包括两部分:
在第一部分中,指定这个参照动作应用哪一条语句,这里有两条相关语句,即DELET和UPDATE语。在第二部分中,指定采用哪个动作,可能采取的动作是RESTRICT、CASCADE、SET NULL、NO ACTION 和 SET DEFAULT。
下面说明这些不同动作的含义。
(1)RESTRICT;当要删除或更新父表中被参照列上的在外键中出现的值时,拒绝对父表的删除或更新操作。
(2)CASCADE:当从父表删除或更新行时自动删除或更新子表中匹配的行。(3)SETNULL:当从父表删除或更新行时,设置子表中与之对应的外键列为NULL,如果外键列没有指定NOTNULL限定词,这就是合法的。
(4)NOACTION:意味着不采取任何动作,就是如果有一个相关的外键值在被参考的表里,删除或更新父表中主键值的企图不被允许,与RESTRICT相同。
(5)SETDEFAULT:作用和SETNULL一样,只不过是指定子表中的外键列为默认值
如果没有指定动作,两个参照动作就会默认使用RESTRICT。
7.3.4 命名完整性约束
CONSTRADNT关键字用来指定完整性约束的名字,其语法格式如下:
CONSTRAINT [完整性约束名]7.3.5 删除约束
使用ALTERTABLE语句,完整性约束可以单独被删除而不必删除表。
删除xs2表的主键约束:
ALTER TABLE xs2 DROP PRIMARY KEY;第八章:MySQL查询与视图
8.1 数据查询
MySQL 数据库使用 SELECT 语句来查询数据。
以下为在 MySQL 数据库中查询数据通用的 SELECT 语法:
SELECT column1, column2, ...
FROM table_name
[WHERE condition]
[ORDER BY column_name [ASC | DESC]]
[LIMIT number];
参数说明:
column1,column2, ... 是你想要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。WHERE condition是一个可选的子句,用于指定过滤条件,只返回符合条件的行。ORDER BY column_name [ASC | DESC]是一个可选的子句,用于指定结果集的排序顺序,默认是升序(ASC)。LIMIT number是一个可选的子句,用于限制返回的行数。
MySQL SELECT 语句简单的应用实例:
-- 选择所有列的所有行
SELECT * FROM users;
-- 选择特定列的所有行
SELECT username, email FROM users;
-- 添加 WHERE 子句,选择满足条件的行
SELECT * FROM users WHERE is_active = TRUE;
-- 添加 ORDER BY 子句,按照某列的升序排序
SELECT * FROM users ORDER BY birthdate;
-- 添加 ORDER BY 子句,按照某列的降序排序
SELECT * FROM users ORDER BY birthdate DESC;
-- 添加 LIMIT 子句,限制返回的行数
SELECT * FROM users LIMIT 10;SELECT 语句可以是灵活的,我们可以根据实际需求组合和使用这些子句,比如同时使用 WHERE 和 ORDER BY 子句,或者使用 LIMIT 控制返回的行数。
在 WHERE 子句中,你可以使用各种条件运算符(如 =, <, >, <=, >=, !=),逻辑运算符(如 AND, OR, NOT),以及通配符(如 %)等。
8.1.1 选择输出列
1、查询表中若干列
在数据库jwgl的学生表student 中查询学生的学号及姓名:
usE jwgl;
SELECT stu no,stu name
FROM student;2、查询表中全部列
在数据库jwgl中,查询课程表course中的所有信息:
USE jwgl;
SELECT *
FROM course;3、设置字段别名
SQL语言提供了在SELECT语句中操作别名的方法。用户可以根据实际需要对查询数据的列标题进行修改,或者为没有标题的列加上临时标题。其语法格式为:
查询jwgl数据库的课程表course,列出表中的所有记录,设置字段名称依次为课程编号、课程名称、课程学分及开课时间:
use jwgl;
SELECT course_no As 课程编号,course_name AS 课程名称,course_credit AS 课程学分,course_term AS 开课时间
FROM course;4、查询经过计算的值
SELECT 子句中的<字段名列表>不仅可以是表中的属性列,也可以是表达式,包括等符串常量、函数等。其语法格式为:
计算字段名=表达式5、返回全部记录
不使用LIMIT 子句,则表示返回全部记录。
在数据库jwgl中,查询学生表student中所有学生的班级代码:
USE jwgl;
SELECT class_no
FROM student;6、过滤重复记录
需在SELECT子句中用过滤重复记录(DISTINCT)命令指定在结果集中只能显示唯一行。
在数据库jwg!中,查询“学信息”表中的学生所在班级有哪些(重复班级只显示一次):
USE jwgL;
SELECT DISTINCT class_no
FROM student;8.1.2 数据来源:FROM 子句
SELECT语句中的FROM子句用于指明数据的来源。
在MySOL中连接查询类型分为内连接、外连接和白连接,连接查询就是关系运算的连接运算。
1、内连接
内连接(Inner Join)也称自然连接,它是组合两个表的常用方法。内连接根据每个表共有列的值匹配两个表中的行。
内连接有以下两种语法格式:
SELECT 列名列表 FROM 表名1,表名2 [INNER] JOIN 表名2 0N 表名1.列名=表名2.列名
或
SELECT 列名列表 FROM 表名1,表名2 WHERE 表名1.列名<比较运算符>表名2.列名内连接分为等值和不等值连接。等值连接;在连接条件中使用等于(()运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。梁菱佰建投,在连接条件中使用等于以外的其他比较运算符比较被连接列的列(些运算符包括>、>=、<、<=、!>、!<、<≥。
2、外连接
与内连接不同,参与外连接的表有主次之分。以主表中的每一行数据去匹配从表中的数据列,符合连接条件的数据将直接返回到结果集中,对那些不符合连接条件的列,将被填上NULL值后再返回到结果集中。
外连接分为左外连接,右外连接和全外连接。
主表在连接符的左边,从左侧引用左表的所有行后向外连接。
左外连接的语法格式如下:
SELECT 列名列表 FROM 表名1 AS A LEFT [OUTER] JOIN 表名2 AS B ON A,列名=B,列名右外连接的结果表中包括右表所有的行和左表中满足连接条件的行。
SELECT 列名列表
FROM 表名1 AS A RIGHT [OUTER] JOIN 表名2 AS B ON A.列名=B.列名3、自然连接
如果在一个连接查询中,涉及的两个表是同一个表,这种查询称为自连接查询接是一种特殊的内连接,它是指相互连接的表在物理上为同一张表,但可以在迎辑费来表。
在数据库jwgl的学生表sudemt 中查询和“朱凡”在同一个班的所有男生信息:
UsE jwgl;
SELECT B.*
FROM student A,student B
WHERE A.stu name='朱凡'AND B.class_no=A.class no AND B.stu_sex='男’B.stu name<>'朱凡';8.1.3 查询条件:WHERE 子句
我们知道从 MySQL 表中使用 SELECT 语句来读取数据。
如需有条件地从表中选取数据,可将 WHERE 子句添加到 SELECT 语句中。
WHERE 子句用于在 MySQL 中过滤查询结果,只返回满足特定条件的行。
以下是 SQL SELECT 语句使用 WHERE 子句从数据表中读取数据的通用语法:
SELECT column1, column2, ...
FROM table_name
WHERE condition;
参数说明:
column1,column2, ... 是你要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。WHERE condition是用于指定过滤条件的子句。
更多说明:
- 查询语句中你可以使用一个或者多个表,表之间使用逗号, 分割,并使用WHERE语句来设定查询条件。
- 你可以在 WHERE 子句中指定任何条件。
- 你可以使用 AND 或者 OR 指定一个或多个条件。
- WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
- WHERE 子句类似于程序语言中的 if 条件,根据 MySQL 表中的字段值来读取指定的数据
1、比较表达式作为查询条件
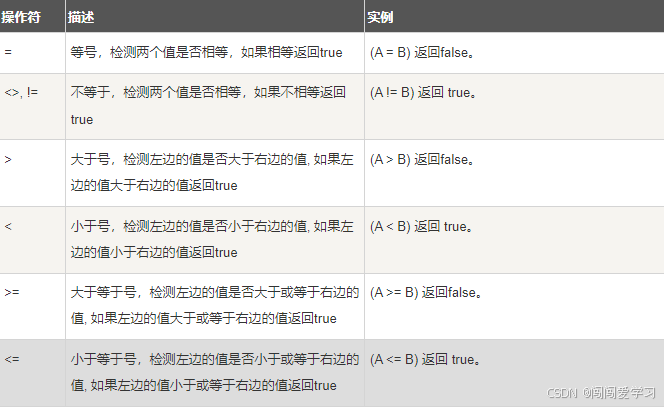
比较表达式是逻辑表达式的一种,使用比较表达式作为查询条件的一般表达形式是:
委达式1 比较运算符 表达式2其中,表达式为常量、变量和列表达式的任意有效组合。比较运算符包括-(等于)、<(小王)、(大于)、◎(不等于)、!>(不大于)、!<(不小于)、>-(大于或等于)、<-(小于或等于)、=(不等于)。
查询年龄在 20岁以下的学生。
UsE jwgl;
SELECT stu_name,stu_sex, YEAR(now())-Year
(stu_birth) as age
FROM student
WHERE
(YEAR(now())-Year(stu_birth))<20;2、逻辑表达式作为查询条件
使用逻辑表达式作为查询条件的一般表达形式如下:
表达式1 AND|OR 表达式2,或NOT 表达式查询年龄为20岁的女生信息:
use jwgl;
SELECT stu_name,stu_sex, YEAR(now())-Year(stu_birth) as age
FROM student
WHERE(YEAR(now())-Year(stu_birth))<20 AND stu_sex ='女';3、(NOT)BETWEEM...AND...关键字
其语法格式如下:
表达式 [NOT] BETWEEN 表达式1 AND 表达式2查询年龄在19~20岁之间的女学生的姓名和年龄:
USE jwgl;
SElECT stu_name,stu_sex, YEAR(now ())-Year
(stu_birth) as age
FROM student
WHERE YEAR(now())-Year(stu_birth) BETWEEN 19 AND 20 AND stu_sex='女';4、IN关键字
同BETWEEN关键字一样,I的引入也是为了更方便地限制检索数据的范围,,灵活修用I关键字,可以用简洁的语句实现结构复杂的查询。语法格式如下:
表达式(NOT) IN (表达式1,表达式2...)如果表达式的值是调词IN后面括号中列出的表达式1,表达式2,……,表达式n中的一个值,则条件为真。
查询选修了010001和020001两门课程的学生的学号:
USE jwgl;
SELECT DISTINCT stu_no
FROM score
WHERE course no IN('010001','020001');5、LIKE关键字
在实际的应用中,用户不会总是能够给出精确的查询条件。因此,经常需要根据一些并不确切的线索来搜索信息,这就是所谓的模糊查询。MySQL提供了LIKE子句来进行模糊查询。
语法格式:
表达式 [NOT] LIKE <匹配串>LIKE子句的含义是查找指定的属性列值与“匹配串”相匹配的元组。“匹配串”可以是一个完整的字符串,也可以含有通配符。MySQL提供了以下4种通配符供用户灵活实现复杂的查询条件。
%(百分号):表示0~n个任意字符。
_下画线):表示单个任意字符。
[](封闭方括号):表示方括号里列出的任意一个字符。
[^]:任意一个没有在方括号里列出的字符。
需要注意的是,以上所有通配符都只有在LIKE子句中才有意义,否则通配符会被当作普通字符处理。
查询“王”姓学生的学号及姓名:
USE Mg);
SELECT stu_no,stu_name
FROM student
WHERE stu_name LIKE %';6、涉及空值的查询
对于空值(NULL)要用IS进行连接,不能用“=”代替。
查询选修了课程却没有成绩的学生的学号:
use jwgl;
GO
SELECT *
FROM score
WHERE score IS NULL;8.1.4 分组:GROUP BY 子句
1、集合函数
汇总查询是把存储在数据库中的数据作为一个整体,对查询结果得到的数据集合进行汇总或求平均值等各种运算。MySQL提供了一系列统计函数,用于实现汇总查询。

查询学生总人数:
USE jwgl;
SELECT COUNT(*) as 学生总人数
FROM student;如果指定 DISTINCT 短语,则表示在计算时要取消指定列中的重复值。如果不指定 DISTINCT 短语或指定 ALL 短语(ALL为缺省值),则表示不取消重复值。
2、GROUP BY 子句
前面进行的统计都是针对整个查询结果集的,通常也会要求按照一定的条件对数据行分组统计,如对每科考试成绩统计其平均分等。GROUPBY子就能够实现这种统计它按照指定的列,对查询结果进行分组统计,该子句写在WHERE子句的后面。
注意:SELECT子句中的选择列表中出现的列,或者包含在集合函数中,或者包含在GROUPBY子句中,否则,MySQL将返回错误信息。其语法格式如下:
GROUP BY column name
[HAVING search_condition]在数据库jwgl的学生表 student中按班级统计出男生和女生的平均年龄及人数:
use jwgl;
SELECT class_no,stu_sex,
AVG(YEAR(now())-Year(stu_birth)) As 平均年龄
COUNT(*) AS 人数
FROM student
GROUP BY class_no,stu_sex;8.1.5 分组条件:HAVING 子句
HAVING 子饲用于输出满足一定条件的分组,是对GROUPBY生成的组进行筛选。即当完成数据结果的查询和统计后,可以使用HAVING关键字对查询和统计的结果进行进一步的筛选。
在数据库jw中,查询成绩表scoe 中平均成绩大于或等于80分的学生的学号、平均分:
USE jwgl;
SELECT stu_no AS 学号,AVG(score )AS 平均成绩
FROM score
GROUP BY stu_no
HAVING AVG(score) >= 80;注意:WHERE 子句是对表中的记录进行筛选,而HAVING 子句是对组内的记录进行筛选,在 HAVING 子句中可以使用集合函数,并且其统计运算的集合是组内的所有列值,而WHERE子句中不能使用集合函数。
8.1.6 排序:ORDER BY 子句
我们知道从 MySQL 表中使用 SELECT 语句来读取数据。
如果我们需要对读取的数据进行排序,我们就可以使用 MySQL 的 ORDER BY 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。
MySQL ORDER BY(排序) 语句可以按照一个或多个列的值进行升序(ASC)或降序(DESC)排序。
以下是 SELECT 语句使用 ORDER BY 子句将查询数据排序后再返回数据:
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...;
参数说明:
column1,column2, ... 是你要选择的列的名称,如果使用*表示选择所有列。table_name是你要从中查询数据的表的名称。ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...是用于指定排序顺序的子句。ASC表示升序(默认),DESC表示降序。
更多说明:
- 你可以使用任何字段来作为排序的条件,从而返回排序后的查询结果。
- 你可以设定多个字段来排序。
- 你可以使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。
- 你可以添加 WHERE...LIKE 子句来设置条件。
8.1.7 行数限制:LIMIT 子句
使用SELECT语句时,经常需要返回前几条或者中间某几条记录,可以使用谓词关键字LIMIT 实现。其语法格式如下:
SELECT 字段名列表
FROM 表名/视图名
LIMIT [start,]length;注意:LHMHT接受一个或两个整数参数。stant 表示从第几行记录开始检索,lengt表示检索多少行记录。表中第一行记录的 start 值为 0(不是1)。
在数据库jwgl中,查询学生表student中前10条记录的学号、姓名、性别生日和籍贯。在数据库jwgl中,查询学生表student中前10条记录的学号、姓名、性别生日和籍贯:
USE jwgl;
SELECT stu_no,stu_name,stu_sex,stu_birth,stu_source
FROM student
LIMIT 10;8.1.8 联合查询:UNION 语句
MySQL UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合,并去除重复的行。
UNION 操作符必须由两个或多个 SELECT 语句组成,每个 SELECT 语句的列数和对应位置的数据类型必须相同。
MySQL UNION 操作符语法格式:
SELECT column1, column2, ...
FROM table1
WHERE condition1
UNION
SELECT column1, column2, ...
FROM table2
WHERE condition2
[ORDER BY column1, column2, ...];
参数说明:
column1,column2, ... 是你要选择的列的名称,如果使用*表示选择所有列。table1,table2, ... 是你要从中查询数据的表的名称。condition1,condition2, ... 是每个SELECT语句的过滤条件,是可选的。ORDER BY子句是一个可选的子句,用于指定合并后的结果集的排序顺序。
基本的 UNION 操作:
SELECT city FROM customers
UNION
SELECT city FROM suppliers
ORDER BY city;以上 SQL 语句将选择客户表和供应商表中所有城市的唯一值,并按城市名称升序排序。
8.2 MySQL视图
视图是数据库的重要组成部分,在大部分的事务和分析型数据库中,都有较多的应用。MYSQL为视图提供了多种重要的扩展特性。视图作为一种基本的数据库对象,是查询一个表或多个表的方法。通过将预先定义好的查询作为一个视图对象存储在数据库中,就可以像使用表一样在查询语句中使用视图。
8.2.1 视图的概念
使用视图将会带来许多好外,它可以帮助用户建立更加安全的数据库,管操作的数据,简化查询过程,使用视图的优点主要表现在以下几个方面。
(1)简化操作。
(2)数据定制与保密。
(3)保证数据的逻辑独立性。
8.2.2 创建视图
用户必须拥有数据库所有者授予的创建视图的权限才可以创建视图。同时须对定义视图时所引用的表有适当的权限。
视图的命名必须遵循标识符规则,对每一个用户都是唯一的。视图名称不视图的用户的其他任何一个表的名称相同。
创建视图的基本语法格式如下:
CREATE [OR REPLACE ][ALGORITHM={UNDEFINED|MERGE|TEMPTABLE}
view 视图名[(column_list)]
AS
Select——statement
[WITH[CASCADED|LOCAL]CHECK OPTION] 语法中的各参数说明如下:
(1)CREATE表示创建新的视图:REPLACE表示替换已经创建的视图。
(2)ALGORITHM表示视图选择的算法。ALGORITHM的取值有3个,分别是UNDEFINEDIMERGEITEMPTABLE。UNDEFINED表示MySQL将自动选择算法;MERGE表示将使用的视图语甸与视图定义合并起来,使得视图定义的某一部分取代语句对应的部分;TENEPTABLE表示将视图的结果存入临时表,然后用临时表来执行。
(3)column_list 是用于指定视图中的字段名称。
(4)Select_statement是用于创建视图的 SELECT 语句
(5)WITH[CASCADEDILOCAL]CHECK OPTION 表示视图在更新时保证在视图的权限范围之内。CASCADED与LOCAL为可选参数,CASCADED为认值,表示更新图时要满足所有相关视图(级联视图)和表的条件;LOCAL表示更新视图时满足该视图定义的条件即可。
创建视图时应该注意以下情况。
(1)只能在当前数据库中创建视图,在视图中最多只能引用1024个列,视图中记录的数目由其基表中的记录数决定。
(2)如果视图引用的基表或者视图被删除,则该视图不能再被使用,直到创建新的基表或者视图。
(3)如果视图中的某一列与函数、数学表达式、常量或者来自多个表的列名相同,则必须为列定义名称。
(4)视图的名称必须遵循标识符规则,且对每个用户必须是唯一的。此外,该名称不
得与该用户拥有的任何表的名称相同。
在jwgl数据库中由学生表student、课程表course、成绩表 score 三个表创建视图“学生成绩视图”stu_cour_score,包含的列有学号、姓名、性别、课程号、课程名称和成绩。代码如下:
USE jwgl;
CREATE VIEW stu_cour_score
AS
SELECT student.stu_no AS 学号,stu_names AS 姓名,stu_sexs AS 性别
course.course_no AS 课程号,course_name AS 课程名称,score AS 成绩
FROM score INNER JOIN course N score.course no =course.course no
INNER JOIN student ON score.stu_no =student.stu_no;8.2.3 查看视图
查看视图是查看数据库中已存在的视图定义。查看视图必须要有SHOW VIEW权限,MySQL数据库下的user 表中保存着这个信息。查看视图的方法包括:DESCRIBE、SHOWTABLESTATUS和 SHOWCREATEVIEW。
1、使用 DESCRIBE 语句查看视图
用DESCRIBE查看视图的具体语法如下:
DESCRIBE 视图名;通过 DESCRIBE语句查看视图 VTEST的定义,代码如下:
use jwgl;
DESCRIBE VTEST;2、使用 SHOW TABLE STATUS 语句查看视图
查看视图的信息可以使用SHOWTABLESTATUS语句,具体语法如下:
SHOW TABLE STATUS LIKE '视图名';通过 SHOW TABLE STATUS语句查看视图VWTEST 的定义,代码如下:
USE jwgl;
SHOW TABLE STATUS LIKE 'VWTEST';
8.2.4 更新视图
更新视图是指通过视图来更新、插入、删除基本表中的数据。因为视图是一个甗其中没有数据,当通过视图更新数据时其实是在更新基本表中的数据。如果对视图据进行增加或者删除操作,实际上就是在对其基本表中的数据进行增加或者删除操作面分别使用UPDATE、INSERT、DELETE语句更新视图。
1、使用 UPDATE 语句更新视图
在MySQL中,可以使用UPDATE语句对视图中原有的数据进行更新。
更新视图VWTEST中学生“耿明”的性别为“女”,代码如下
USE jwgl;
UPDATE VWTEST SET 性别='女' WHERE 姓名 = '耿明';2、使用INSERT 语句更新视图
在MySQL中,可以使用 INSERT 语句向视图中的插入一条记录。
向视图 VTEST 中插入一条记录,代码如下:
USE jwgl;
INSERT INTO VTEST VALUES('1902030103','010004’,93);3、使用 DELETE 语句更新视图
在MySQL中,可以使用DELETE语句删除视图中的部分记录。
删除视图 VTEST中课程号为100101的记录,代码如下:
USE jwgl;
DELETE FROM VTEST WHERE 课程号='100101';8.2.5 修改视图
修改视图是指修改数据库中存在的视图,当基本表中的某些字段发生变化的时候,可以通过修改视图来保持与基本表的一致性。MySQL中通过ALTER VIEW 语句来修改物其语法格式如下:
ALTER [ALGORITHM={ UNDEFINED | MERGE | TEMPTABLE }]
view视图名[(column list)]
AS
Select statement
[WITH [ CASCADED I LOCAL ]CHECK OPTION] 可以看到,修改视图的语句结构与CREATEVIEW语句相同,其中各选项的含义也
CREATE VIEW 语句相同。
修改学生成绩视图stu_cour_score,使其显示成绩在80分以上的学生的
绩信息。代码如下:
USE jwgl;
ALTER VIEW stu_cour_score
AS
SELECT student.stu_no AS 学号,stu_names姓名,stu_sex AS 性别
course.course_no AS 课程号,course_name AS 课程名称,score AS 成绩
FROM score INNER J0IN course ON score.course no =course.course no
INNER JOIN student ON score.stu_no = student.stu_no
WHERE score>80;8.2.6 删除视图
在不需要某个视图的时候或想清除某个视图的定义及与之相关联的权限时,可以删除该视图。视图的删除不会影响所依赖的基表的数据。删除一个或多个视图可以使用DROPVIEW语句,语法如下:
DROP VIEW [IF EXISTS]
view name [,view name]...
[RESTRICT | CASCADE];其中,view_name是要删除的视图名称,可以添加多个需要删除的视图名称,各个名称之间用逗号分隔开。删除视图必须拥有DROP权限。
删除stu_cour_score 视图:
DROP VIEW stucour score;