折线图的概念及作用:
折线图(Line Chart)是一种常见的图表类型,用于展示数据的变化趋势或时间序列数据。它通过一系列的数据点(通常表示为坐标系中的点)与这些点之间的线段相连,直观地展示变量随着时间或其他因素变化的情况。折线图适用于比较多个数据集的变化趋势,尤其是在时间序列数据分析中,常用于反映数据的连续性和波动。
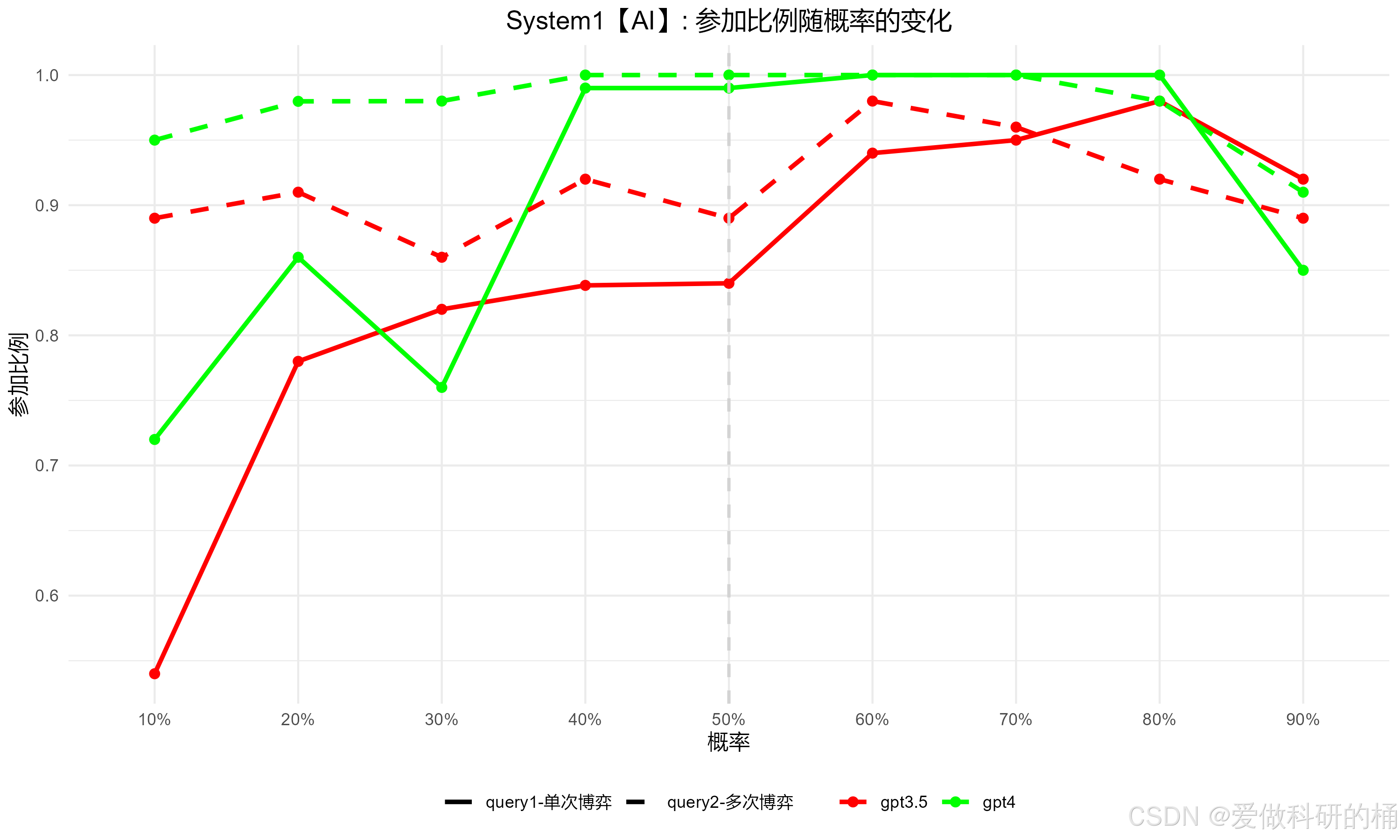
1. 折线图的基本概念
折线图是由坐标系中的一系列数据点和这些点之间的直线段组成。每个数据点的横坐标通常代表某一时间点或顺序,而纵坐标则表示对应的数值(如销量、温度、股票价格等)。通过连接这些点,形成折线图,可以清晰地看到数据的波动趋势和变化规律。
- 横坐标(X轴):通常表示自变量,例如时间、日期、阶段等。它是连续的或离散的。
- 纵坐标(Y轴):表示因变量,即需要观察的数据值。
- 数据点:每一个数据点对应一个横坐标和纵坐标的组合,表示某个时刻或某个条件下的观测值。
- 折线:通过连接数据点,形成的线条展示了数据的变化趋势。
2. 折线图的作用
折线图的作用主要体现在以下几个方面:
a. 展示数据变化的趋势
折线图最常见的用途是展示数据随时间或其他因素变化的趋势。通过观察折线的走势,可以直观地了解数据随时间的波动和变化模式。
- 例如,绘制一年中每个月的气温变化折线图,可以清晰地看出气温的升降趋势,揭示季节性变化。
b. 比较多个数据系列
折线图还可以用来比较多个数据系列的变化趋势。当有多个变量或不同类别的时间序列数据时,可以将它们绘制在同一张图表上,通过不同的颜色、线型或符号区分不同的数据系列。
- 例如,比较不同公司在同一时间段内的股票价格变化,或不同地区的气温变化。
c. 揭示数据的波动性和周期性
折线图不仅能展示数据的趋势,还能揭示数据中的周期性波动(如季节变化)、突发性变化、趋势反转等重要特征。
- 例如,通过绘制股票市场的折线图,可以看到市场的波动性,识别牛市和熊市的周期性变化。
d. 识别异常值或趋势变化点
折线图能够帮助观察数据中的异常值或突变点。例如,突如其来的数据激增或暴跌在折线图中会形成尖锐的波动,容易被观察者识别出来。
- 例如,销售额的急剧下降可能是某个重要事件导致的,需要进一步分析。
3. 折线图的类型
根据数据的特点和需求,折线图可以有不同的变种,常见的有:
a. 基本折线图(Simple Line Chart)
最基本的折线图,展示一个数据系列随时间的变化趋势。
b. 多重折线图(Multiple Line Chart)
适用于比较多个数据系列。每个系列通过不同的颜色或线型区分,以便在同一图表中显示多个变量的变化趋势。
c. 堆叠折线图(Stacked Line Chart)
在多重折线图的基础上,堆叠折线图显示了不同数据系列之间的叠加关系。每个数据系列的值在前一系列之上堆叠起来,适用于表示部分与整体的关系。
- 例如,展示各个产品在某个月的销售额时,可以通过堆叠折线图看到不同产品的销售额与总销售额之间的关系。
d. 平滑折线图(Smooth Line Chart)
在基本折线图的基础上,通过平滑算法(如样条插值等)使得折线不那么尖锐,适用于数据变化较为平稳、且不要求每个数据点之间的波动都十分显著的情况。
代码:
第一部分:加载所需包
library(ggplot2)
library(dplyr)
library(tidyr)
library(gridExtra)
library(openxlsx)
ggplot2:用于数据可视化。dplyr:用于数据操作。tidyr:用于数据整理(例如宽表和长表的转换)。gridExtra:用于排版多个图表。openxlsx:用于读取和写入 Excel 文件。
第二部分:数据加载与清理
mydata <- read.xlsx("gpt.xlsx")
mydata <- subset(mydata, mydata$final != 3)
mydata <- mydata %>%
mutate(
gpt = factor(gpt, levels = c("gpt3.5", "gpt4")),
system = factor(system, levels = c("system2", "system1")),
query = factor(query, levels = c("query1", "query2")),
final_new = factor(final, labels = c("不参加", "参加")),
sort_new = factor(sort, labels = paste0(seq(10, 90, by = 10), "%"))
)
-
数据加载:
read.xlsx("gpt.xlsx"):读取 Excel 文件gpt.xlsx。
-
数据过滤:
subset(mydata, mydata$final != 3):去除final列中值为 3 的数据。
-
数据清理:
- 使用
mutate对数据进行格式化处理:- 将
gpt、system和query列转为因子变量,设定排序规则。 - 对
final和sort列创建新的因子变量,并赋予更易读的标签。
- 将
- 使用
第三部分:分组并汇总数据
result_wide <- mydata %>%
group_by(gpt, system, query, final_new) %>%
summarise(Frequency = n(), .groups = 'drop') %>%
pivot_wider(names_from = final_new, values_from = Frequency, values_fill = list(Frequency = 0)) %>%
mutate(Proportion = 参加 / (不参加 + 参加))
-
分组与汇总:
group_by(gpt, system, query, final_new):按gpt、system、query和final_new进行分组。summarise(Frequency = n(), .groups = 'drop'):计算每组的频数,生成Frequency列。
-
宽表转换:
pivot_wider(names_from = final_new, values_from = Frequency, values_fill = list(Frequency = 0)):- 将
final_new的值("不参加" 和 "参加")作为新列,值来源于Frequency。 - 未匹配的单元格填充为
0。
- 将
-
计算比例:
mutate(Proportion = 参加 / (不参加 + 参加)):计算 "参加" 在总频数中的比例,结果存储在Proportion列中。
第四部分:绘制折线图
plota <- ggplot(result_wide, aes(x = system, y = Proportion,
color = gpt, linetype = query,
group = interaction(gpt, query))) +
geom_line(linewidth = 1.1) +
geom_point(size = 2) +
labs(title = "比对折线图", x = "system", y = "参加比例") +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5),
legend.title = element_blank(),
legend.position = "bottom"
) +
scale_color_manual(values = c("gpt3.5" = "red", "gpt4" = "green")) +
scale_linetype_manual(
values = c("query1" = "solid", "query2" = "dashed", "query4" = "dotted"),
labels = c("query1" = "query1-单次博弈", "query2" = "query2-多次博弈", "query4" = "query4-聚合结果的多次博弈")
) +
scale_x_discrete(labels = c("system1" = "system1【AI】", "system2" = "system2【Human】"))
核心部分解释:
-
ggplot初始化:aes(x = system, y = Proportion, color = gpt, linetype = query, group = interaction(gpt, query)):- x:
system作为 x 轴变量。 - y:
Proportion作为 y 轴变量(参加比例)。 - color:
gpt区分颜色。 - linetype:
query区分线型(例如虚线、实线等)。 - group:按照
gpt和query的组合分组,确保线条连续。
- x:
-
绘制折线和点:
geom_line(linewidth = 1.1):绘制折线,设置线宽为 1.1。geom_point(size = 2):在线上叠加点,设置点大小为 2。
-
添加标题和标签:
labs(title = "比对折线图", x = "system", y = "参加比例"):设置图表标题和轴标签。
-
主题样式:
theme_minimal():应用简约主题。theme(...):plot.title = element_text(hjust = 0.5):标题居中。legend.title = element_blank():去除图例标题。legend.position = "bottom":将图例放在底部。
-
自定义颜色和线型:
scale_color_manual(...):指定颜色:"gpt3.5"为红色,"gpt4"为绿色。
scale_linetype_manual(...):values:指定线型(实线、虚线、点线)。labels:为每种query提供易读的标签描述。
-
自定义 x 轴标签:
scale_x_discrete(labels = c("system1" = "system1【AI】", "system2" = "system2【Human】")):- 将
system1和system2的标签分别替换为system1【AI】和system2【Human】。
- 将
第五部分:保存图表
ggsave("plota.png", plota, width = 8, height = 6, bg = "white")
- 将绘制的图形
plota保存为 PNG 文件:- 文件名为
plota.png。 - 宽度和高度分别为 8 英寸和 6 英寸。
- 背景色为白色。
- 文件名为
总结:
# ------- 加载所需包 -------
library(ggplot2)
library(dplyr)
library(tidyr)
library(gridExtra)
library(openxlsx)
# ------- 加载并清理数据 -------
mydata <- read.xlsx("gpt.xlsx")
mydata <- subset(mydata, mydata$final != 3)
mydata <- mydata %>%
mutate(
gpt = factor(gpt, levels = c("gpt3.5", "gpt4")),
system = factor(system, levels = c("system2", "system1")),
query = factor(query, levels = c("query1", "query2")),
final_new = factor(final, labels = c("不参加", "参加")),
sort_new = factor(sort, labels = paste0(seq(10, 90, by = 10), "%"))
)
# ------- 分组并汇总数据 -------
result_wide <- mydata %>%
group_by(gpt, system, query, final_new) %>%
summarise(Frequency = n(), .groups = 'drop') %>%
pivot_wider(names_from = final_new, values_from = Frequency, values_fill = list(Frequency = 0)) %>%
mutate(Proportion = 参加 / (不参加 + 参加))
# 打印汇总数据
print(result_wide)
# ------- 绘制折线图 -------
plota <- ggplot(result_wide, aes(x = system, y = Proportion,
color = gpt, linetype = query,
group = interaction(gpt, query))) +
geom_line(linewidth = 1.1) +
geom_point(size = 2) +
labs(title = "比对折线图", x = "system", y = "参加比例") +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5),
legend.title = element_blank(),
legend.position = "bottom"
) +
scale_color_manual(values = c("gpt3.5" = "red", "gpt4" = "green")) +
scale_linetype_manual(
values = c("query1" = "solid", "query2" = "dashed", "query4" = "dotted"),
labels = c("query1" = "query1-单次博弈", "query2" = "query2-多次博弈", "query4" = "query4-聚合结果的多次博弈")
) +
scale_x_discrete(labels = c("system1" = "system1【AI】", "system2" = "system2【Human】"))
# 显示图表
print(plota)
# ------- 保存图表 -------
ggsave("plota.png", plota, width = 8, height = 6, bg = "white")