文章目录
前言
《RSPrompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model》,2024
本篇论文提出了目前SAM存在的一些问题:
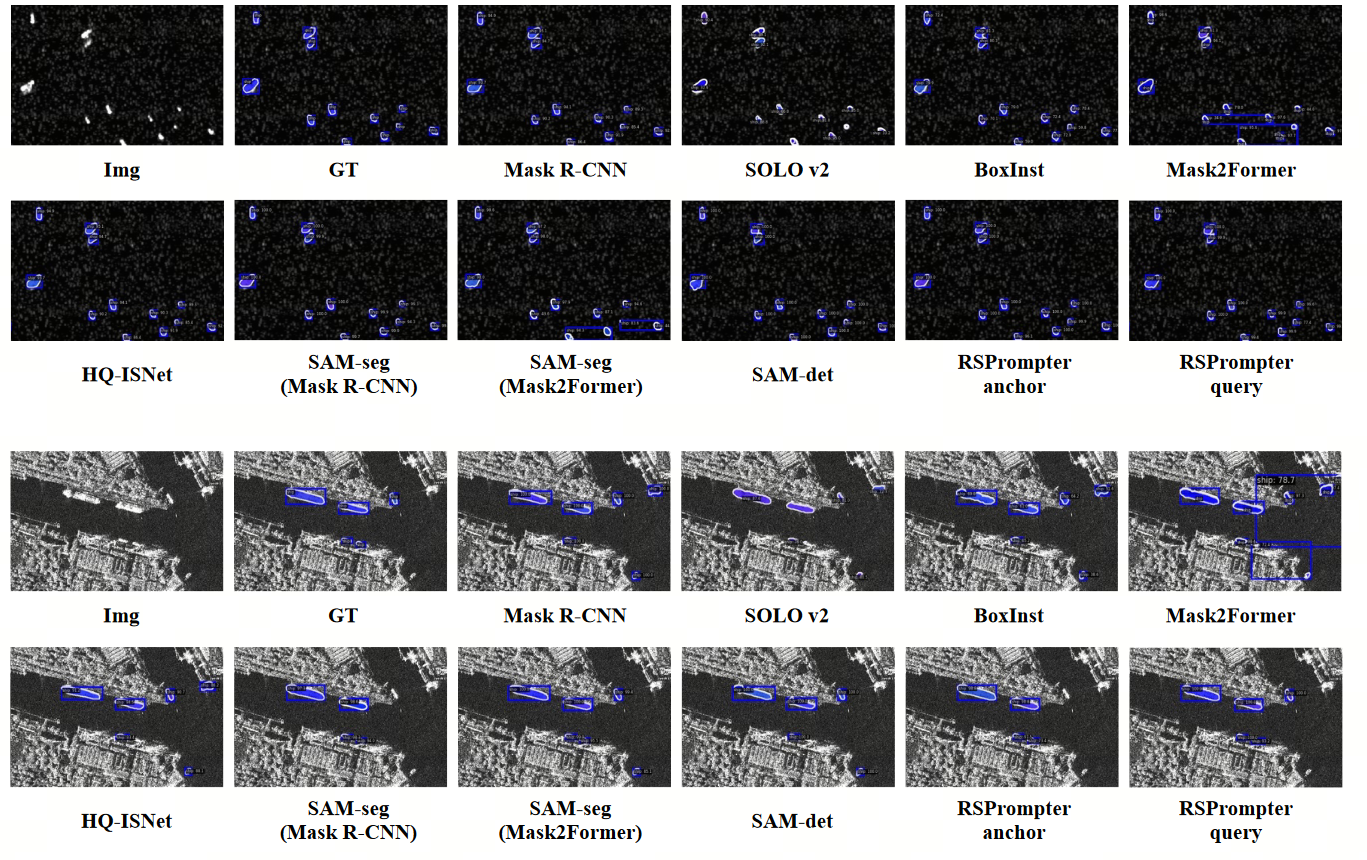
- SAM严重依赖于人工先验(点、框、mask)且分割结果是没有标记类别的,如下图,单点、两点、边框提示的不同分割结果
- SAM在遥感图像分割任务中的性能在很大程度上仍未被探索和证明

1. 自动化提示器
针对问题1,不由得想到:如果能够自动生成多个与类别相关的提示,SAM 的解码器就能够产生带有类别标签的多个实例级掩码。
论文提出训练一个自动化的提示器(RSPrompter),能够处理来自测试集的任何图像,同时对对象进行定位,并推断它们的语义类别和实例掩码。最后通过RSPrompter+SAM,实现分割任务的自动化。
这个过程存在两个主要挑战:(i)类别相关的提示从哪里来?(ii)应选择哪种类型的提示作为掩膜解码器的输入
RSPrompter的结算流程如下:
- 通过冻结权重的SAM image encoder生成多个中间特征图 F i F_i Fi (K×h×w×c)和最终的图像嵌入 F i m g F_{img} Fimg (h×w×c)
- F i F_i Fi通过多尺度特征增强器(结构和原理见1.1)逐步处理获得多尺度特征 F m s F_{ms} Fms
- 将多尺度特征 F m s F_{ms} Fms输入RSPrompter(结构和原理见1.2)以获得多组提示语( F s p a r s e m ∈ R K p × c , m ∈ { 1 , ⋅ ⋅ ⋅ , N p } F^m_{sparse} ∈ R^{K_p×c}, m ∈ \{1, · · · , Np\} Fsparsem∈RKp×c,m∈{1,⋅⋅⋅,Np})和它们的语义类别( c m ∈ R c , m ∈ { 1 , ⋅ ⋅ ⋅ , N p } c_m ∈ R^c, m ∈ \{1, · · · , Np\} cm∈Rc,m∈{1,⋅⋅⋅,Np}),其中, K p K_p Kp定义了每次掩码生成的提示嵌入次数; N p N_p Np是提示的个数,用来定义输出实例掩码的个数。
需要注意的是, F s p a r s e m F^m_{sparse} Fsparsem只包含前景目标实例提示,其语义类别由 c m c_m cm给出。单个 F s p a r s e m F^m_{sparse} Fsparsem是多个提示的组合,即用多个点嵌入或一个边框表示一个实例掩码。
1.1 多尺度特征增强器
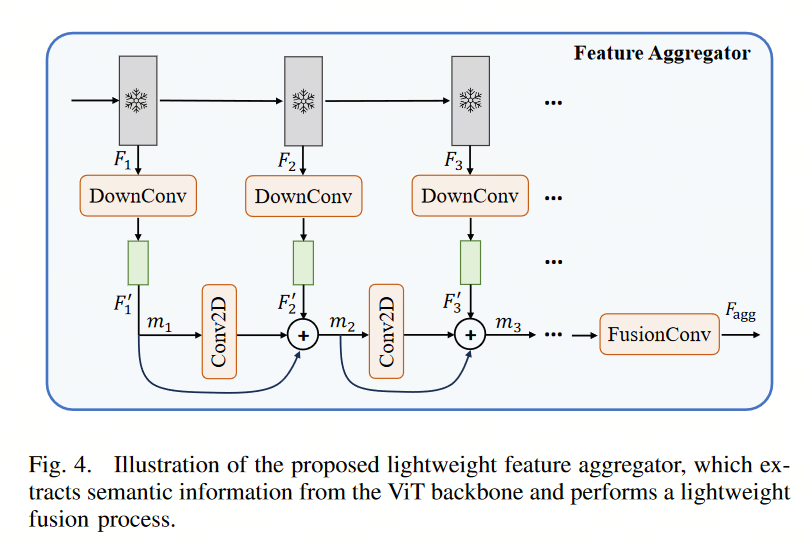
为了在不增加提示器(Prompter)计算复杂度的情况下提取具有语义相关性和判别性的特征,论文提出了一种轻量级的多尺度特征增强器。该增强器包括特征聚合器(Feature Aggregator)和特征分割器(Feature Splitter)。
Feature Aggregator的设计是为了从SMA ViT backbone的众多中间特征层中学习具有代表性的语义特征并进行融合,Feature Splitter被用于从融合后的特征图中生成多尺度金字塔特征图。具体过程如下:
- 对每个中间层特征图下采样(1×1卷积降维+3×3卷积提升空间信息)到同一通道:h×w×c -> h×w×32
- 通过跳连+add形势逐渐合并各层特征,FusionConv表示最终的融合卷积层,由两个3 × 3卷积层和一个1 × 1卷积层组成,以恢复通道维度,得到最终融合特征图 F a g g F_{agg} Fagg。
- 将 F a g g F_{agg} Fagg输入特征分割器,Feature Splitter使用转置卷积层生成上采样特征,使用最大池化生成下采样特征。通过利用上/下采样层,最终获得了五种不同尺度的特征图: F m s j ∈ R H 2 j + 1 , W 2 j + 1 , c F_{ms}^j ∈ R^{\frac{H}{2^{j+1}},\frac{W}{2^{j+1}},c} Fmsj∈R2j+1H,2j+1W,c,其中 j ∈ { 1 , 2 , 3 , 4 , 5 } j ∈ \{1, 2, 3, 4, 5\} j∈{1,2,3,4,5}。
1.2 RSPrompter
在获取语义特征后,利用提示器为SAM mask decoder生成提示嵌入就变得可行。采用了两种不同结构的提示器:anchor-based和query-based。
Anchor-based Prompter
首先利用基于锚点的区域建议网络( RPN )生成候选目标框。随后通过RoI Pooling从位置编码的特征图中提取每个对象的独特视觉特征表示。
然后利用对象的视觉特征得到3个感知头:语义头(semantic head)、定位头(localization head)和提示头(prompt head)。
- 语义头部的作用是识别特定的物体类别
- 定位头部负责建立生成的提示表示与目标实例掩码之间的匹配准则,即基于定位( Intersection over Union , IoU)的贪婪匹配。
- 提示头为SAM mask decoder生成必要的提示嵌入。
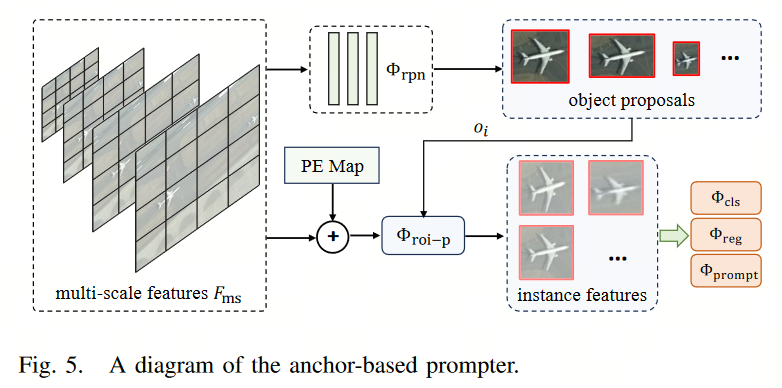
ps:PE 是positional encoding
简单来说,该提示器本质上就是一个简单的目标检测网络。其主要框架和Faster RCNN基本一致。其损失函数如下:
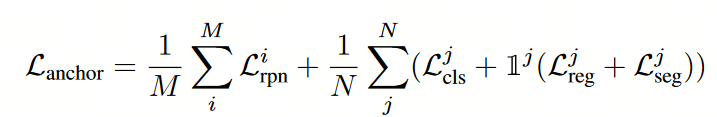
包含:
- 候选区生成网络损失 L r p n L_{rpn} Lrpn
- 分类损失 L c l s L_{cls} Lcls:交叉熵(CE)
- 回归损失 L r e g L_{reg} Lreg:SmoothL1 loss for 偏移量
- 分割损失 L s e g L_{seg} Lseg:表示SAM decoder 掩码与真实实例掩码之间的二进制CE损失,其中框的IoU决定了有监督的匹配准则。
Query-based Prompter
Anchor-based的方法较为复杂,需要使用框信息进行掩码匹配和监督训练。
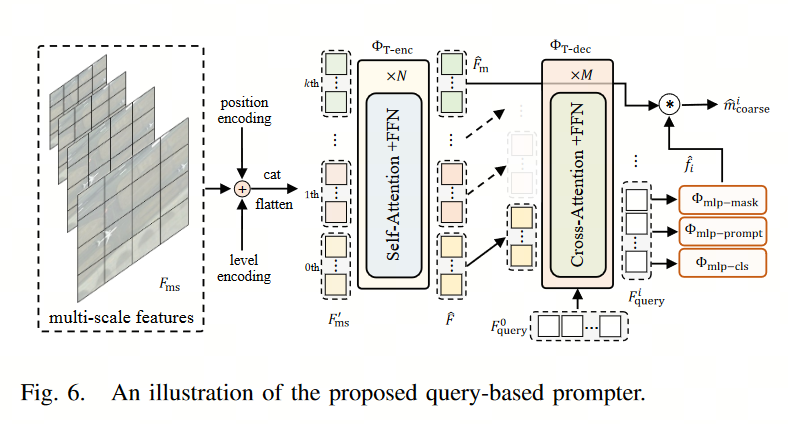
因此提出了以最优传输为基础的query-based提示器。如下图所示:
- 编码器用于提取高层次聚集的语义特征,建模各尺度特征图间的关系,输出建模后的多尺度特征图 F ^ i \hat F_i F^i,其中 F ^ m \hat F_m F^m是尺寸最大的特征图(原图四分之一大小)
- 解码器通过交叉注意力交互将预设的可学习查询token转换为SAM和相应语义类别的提示嵌入
- 可学习的查询token: F q u e r y i ∈ R N p × c F^i_{query} ∈ R^{N_p×c} Fqueryi∈RNp×c,其中 N p N_p Np为提示个数,即实例数量
- 可学习的查询token和多尺度特征图进行交叉注意力计算再经过三个head后得到:
- 输出类别: c ^ i ∈ R N p × c \hat c_i ∈ R^{N_p×c} c^i∈RNp×c
- 输出掩膜滤波器: f ^ i ∈ R N p × c \hat f_i ∈ R^{N_p×c} f^i∈RNp×c
- 输出提示嵌入 c ^ i ∈ R N p × K p × c \hat c_i ∈ R^{N_p×K_p×c} c^i∈RNp×Kp×c,其中 K p K_p Kp用于定义每个提示的嵌入次数,即表示一个实例目标所需的提示数量。
- 第i级粗分割掩膜( m ^ c o a r s e i \hat m_{coarse}^i m^coarsei)由 F ^ m \hat F_m F^m通过 f ^ i \hat f_i f^i线性加权得到
- 然后将 m ^ c o a r s e i \hat m_{coarse}^i m^coarsei经过SAM promopt encoder编码后得到稠密提示编码 F d e n s e i F^i_{dense} Fdensei
- 通过计算 e i + s i n ( e i ) e_i + sin(e_i) ei+sin(ei)后得到稀疏提示编码 F s p a r s e i F^i_{sparse} Fsparsei
整体方程可以沿着层级i循环计算,以获得多语义结果。为了进行推理,只考虑最后一层,通过数学运算得到二值掩码的边框。
在基于查询的提示器的训练过程中,主要进行了两个步骤:( i ) N p N_p Np预测掩码与K个真实实例掩码(一般来说, N p > K Np > K Np>K)的匹配;( ii )利用匹配的标签进行监督训练的后续实现。
1. 在执行最优运输匹配时,建立如下的匹配成本,该成本同时包含了预测的类别和掩码:
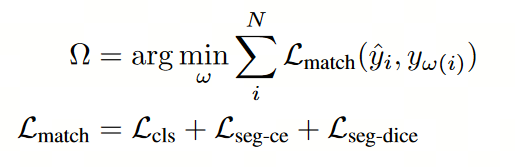
ω 表示分配关系。使用匈牙利算法来确定 N p N_p Np个预测和K个目标之间的最优分配。匹配代价考虑了预测和真实标注之间的相似性。具体来说,它包括类分类匹配代价( L c l s L_{cls} Lcls )、掩码交叉熵代价( L s e g − c e L_{seg-ce} Lseg−ce )和掩码dice代价( L s e g − d i c e L_{seg-dice} Lseg−dice是一种相似性度量损失,和iou loss类似)。
2. 匹配后即可计算最终loss,由分类交叉熵损失和mask二元交叉熵损失构成:
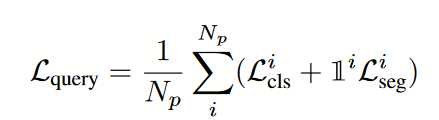
2. SAM的扩展
针对上述问题2:除了提出的RSPrompter,还引入了另外三种基于SAM的实例分割方法进行对比分析,以探索SAM性能改进方向。其中,前两种方法为论文提出,具有简单实现的SAM - det已经在社区内引起了相当大的关注和应用。
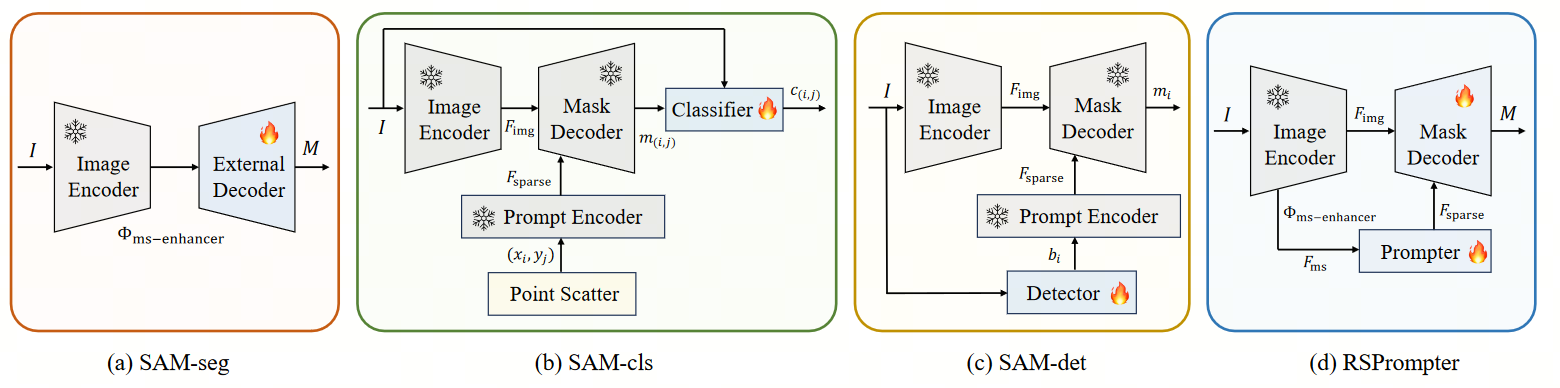
- (a)SAM-seg:冻结SAM Image Encoder,使用多尺度增强器获取多尺度特征,然后输入到其他网络的实例分割头,即Mask RCNN或Mask2Former的mask decoder。
- (b)SAM-cls:在图像上均匀分布点,并将每个点作为实例的提示输入,将提示输入到SAM以获得图像中所有潜在的实例目标。在获得所有实例的掩码后,再使用分类器为每个掩码分配标签。
- (c)SAM-det:首先,训练一个目标检测器,以精确定位图像中的期望目标。随后,将检测到的边界框作为提示输入到SAM中。
- (d)SAM-RSPromopt:和SAM-det的理念是比较相似的,区别在于直接生成提示嵌入,而非提示本身。
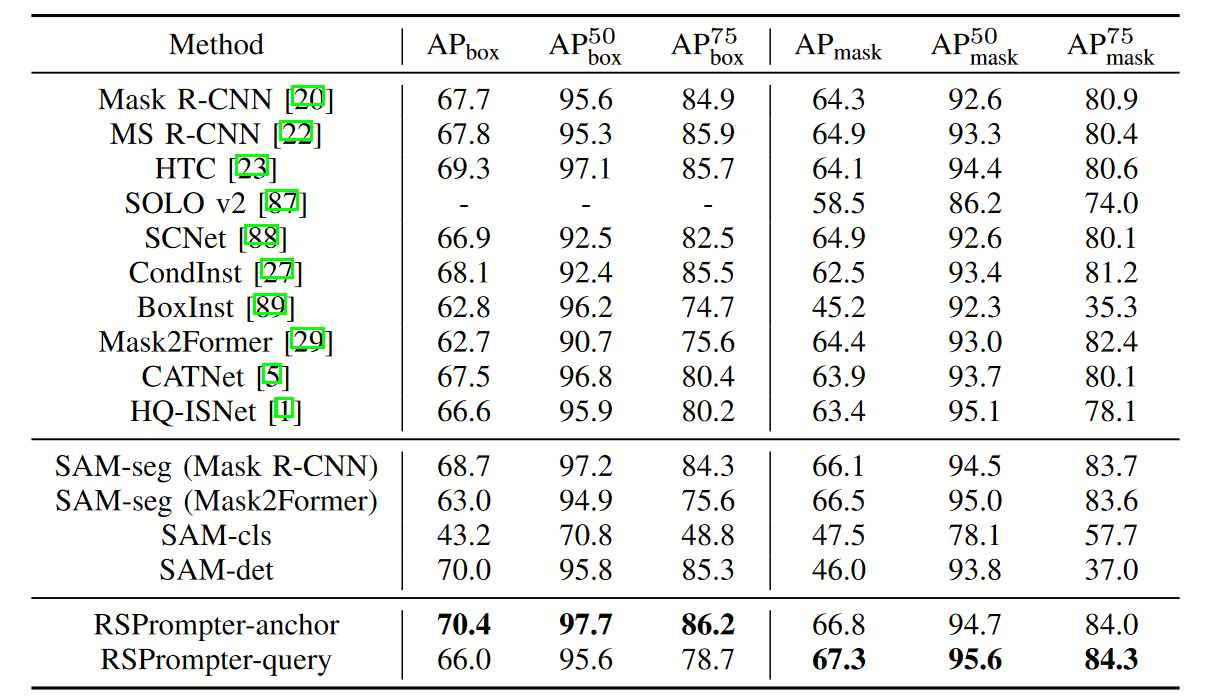
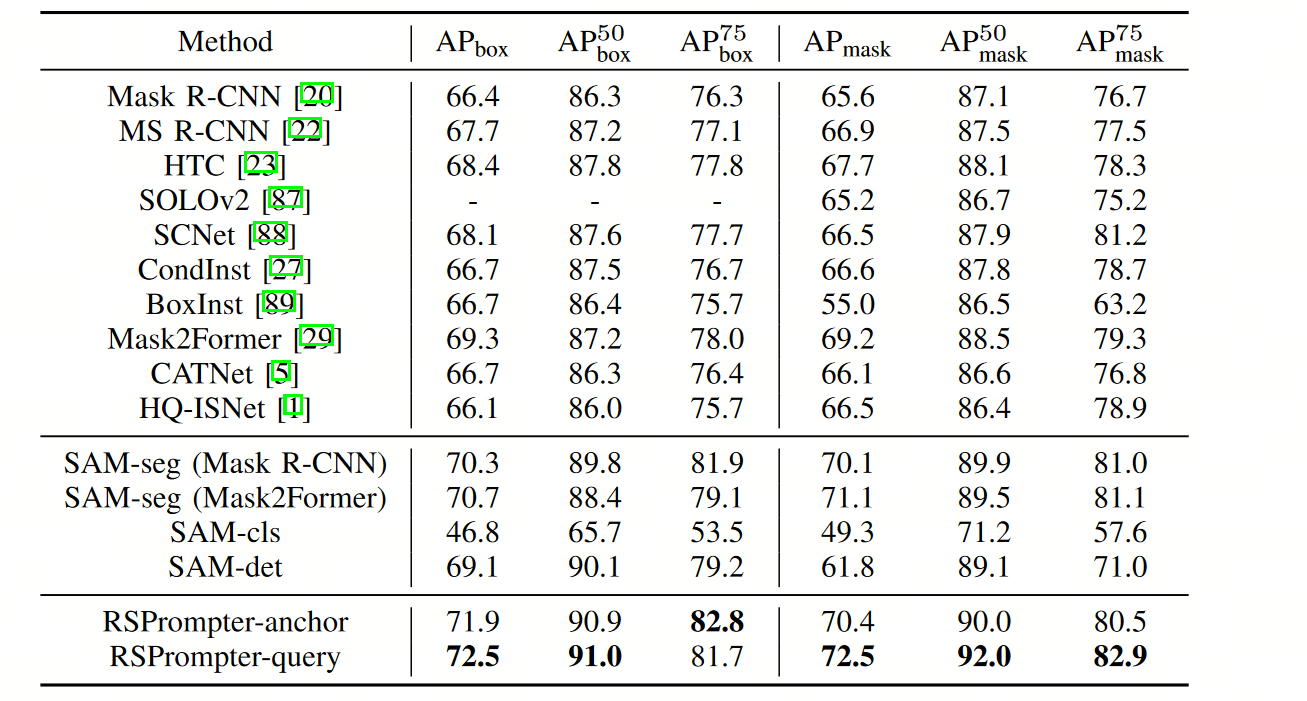
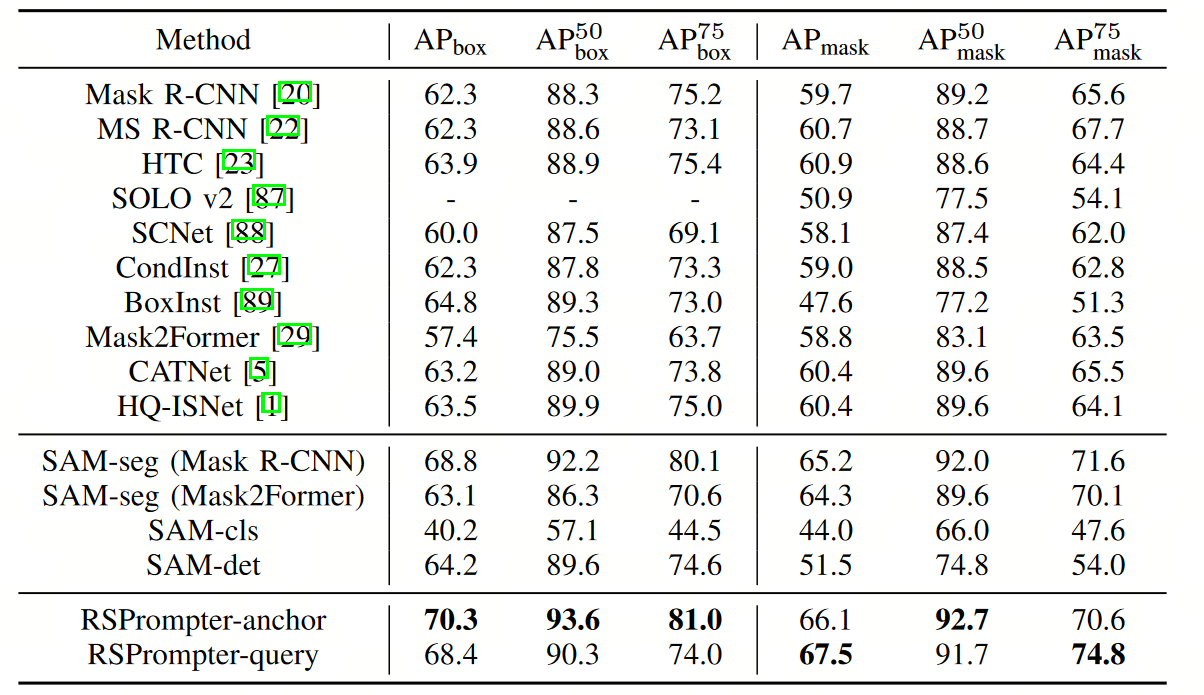
3. 结果
在本文中使用了三个公共的遥感实例分割数据集:
- WHU建筑提取数据集中的航空图像子集
- NWPU VHR-10数据集(包含10个类比的遥感图像目标检测数据集)
- SSDD数据集(SAR图像舰船检测数据集)
WHU数据集是单类建筑物目标提取分割,NWPU VHR-10是多类目标检测分割,SSDD是SAR船只目标检测分割。使用 mAP 进行模型性能评价。

![![[Pasted image 20240406180018.png]]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2RpcmVjdC9hODAyYjA5M2RkODk0NWNkYjc0YmRjY2RjMzBjMzZlNC5wbmc%3D)