索引介绍
索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。
索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
索引底层数据结构存在很多种类型,常见的索引结构有: B 树, B+树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyIsam,都使用了 B+树作为索引结构。
索引的优缺点
优点:
- 使用索引可以大大加快数据的检索速度(大大减少检索的数据量), 减少 IO 次数,这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
缺点:
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
但是,使用索引一定能提高查询性能吗?
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
索引底层数据结构选型
Hash 表
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
为何能够通过 key 快速取出 value 呢? 原因在于 哈希算法(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
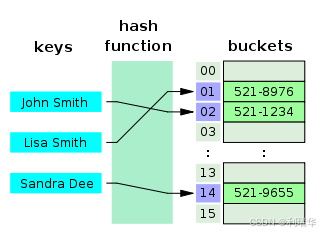
但是!哈希算法有个 Hash 冲突 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 链地址法。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 HashMap 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后HashMap为了减少链表过长的时候搜索时间过长引入了红黑树。
为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
MySQL 的 InnoDB 存储引擎不直接支持常规的哈希索引,但是,InnoDB 存储引擎中存在一种特殊的“自适应哈希索引”(Adaptive Hash Index),自适应哈希索引并不是传统意义上的纯哈希索引,而是结合了 B+Tree 和哈希索引的特点,以便更好地适应实际应用中的数据访问模式和性能需求。自适应哈希索引的每个哈希桶实际上是一个小型的 B+Tree 结构。这个 B+Tree 结构可以存储多个键值对,而不仅仅是一个键。这有助于减少哈希冲突链的长度,提高了索引的效率。关于 Adaptive Hash Index 的详细介绍
既然哈希表这么快,为什么 MySQL 没有使用其作为索引的数据结构呢? 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
试想一种情况:
SELECT * FROM tb1 WHERE id < 500;在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
二叉查找树(BST)
二叉查找树(Binary Search Tree)是一种基于二叉树的数据结构,它具有以下特点:
- 左子树所有节点的值均小于根节点的值。
- 右子树所有节点的值均大于根节点的值。
- 左右子树也分别为二叉查找树。
当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)。
.
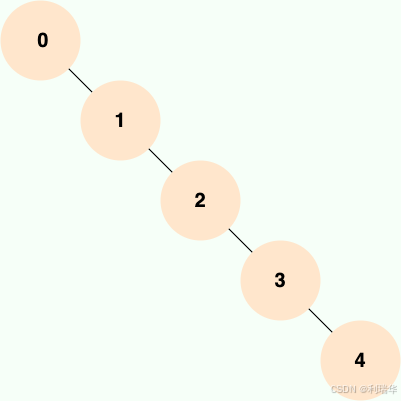
也就是说,二叉查找树的性能非常依赖于它的平衡程度,这就导致其不适合作为 MySQL 底层索引的数据结构。
为了解决这个问题,并提高查询效率,人们发明了多种在二叉查找树基础上的改进型数据结构,如平衡二叉树、B-Tree、B+Tree 等。
AVL 树
AVL 树是计算机科学中最早被发明的自平衡二叉查找树,它的名称来自于发明者 G.M. Adelson-Velsky 和 E.M. Landis 的名字缩写。AVL 树的特点是保证任何节点的左右子树高度之差不超过 1,因此也被称为高度平衡二叉树,它的查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。
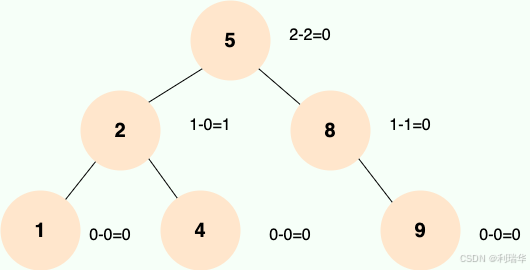
AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
由于 AVL 树需要频繁地进行旋转操作来保持平衡,因此会有较大的计算开销进而降低了数据库写操作的性能。并且, 在使用 AVL 树时,每个树节点仅存储一个数据,而每次进行磁盘 IO 时只能读取一个节点的数据,如果需要查询的数据分布在多个节点上,那么就需要进行多次磁盘 IO。 磁盘 IO 是一项耗时的操作,在设计数据库索引时,我们需要优先考虑如何最大限度地减少磁盘 IO 操作的次数。
实际应用中,AVL 树使用的并不多。