一 论文解读
1.1论文基本信息
《Generative Adversarial Nets》是Ian J.Goodfellow发表在NIPS 2014上的一篇论文,也是GANs的开山之作。NIPS(NeurIPS),全称神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),是一个关于机器学习和计算神经科学的国际会议。该会议固定在每年的12月举行,由NIPS基金会主办。NIPS是机器学习领域的顶级会议。在中国计算机学会的国际学术会议排名中,NIPS为人工智能领域的A类会议。Ian Goodfellow因提出了生成对抗网络(GANs)而闻名,他被誉为“GANs之父”,甚至被推举为人工智能领域的顶级专家。2016年10月24日, 他和谷歌大脑研究员Alexey Kurakin共同参加了Geekpwn2016嘉年华美国硅谷站,分享了人工智能领域关于机器视觉的阿基里斯之踵的议题。
1.2论文摘要翻译
我们提出了一个通过对抗过程估计生成模型的新框架,在新框架中我们同时训练两个模型:一个用来捕获数据分布的生成模型G,和一个用来估计样本来自训练数据而不是G的概率的判别模型D,G的训练过程是最大化D产生错误的概率。这个框架相当于一个极小化极大的双方博弈。在任意函数G 和D 的空间中存在唯一的解,其中G恢复训练数据分布,并且D处处都等于1212。在G和D 由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间不需要任何马尔科夫链或展开的近似推理网络。实验通过对生成的样品进行定性和定量评估来展示这个框架的潜力。
1.3研究背景以及研究问题的提出
深度学习的任务是寻找丰富的层次模型,能够在人工智能领域里用来表达各种数据的概率分布,例如自然图像,包含语音的音频波形和自然语言语料库中的符号等。到目前为止,在深度学习领域,目前为止最成功的的模型之一就是判别式模型,通常它们将高维丰富的感知器输入映射到类标签上。这些显著的成功主要是基于反向传播和丢弃算法来实现的,特别是具有特别良好梯度的分段线性单元。由于在最大似然估计和相关策略中出现的许多难以解决的概率计算的困难,以及很难利用在生成上下文中时使用分段线性单元的好处,深度生成模型的影响很小。这里提出一个新的生成模型估计程序,来分步处理这些难题。
在提到的对抗网络框架中,生成模型对抗着一个对手:一个学习去判别一个样本是来自模型分布还是数据分布的判别模型。生成模型可以被认为是一个伪造团队,试图产生假货并在不被发现的情况下使用它,而判别模型类似于警察,试图检测假币。在这个游戏中的竞争驱使两个团队改进他们的方法,直到真假难分为止。
这个框架可以针对多种模型和优化算法提供特定的训练算法。在这篇文章中,探讨了生成模型通过将随机噪声传输到多层感知机来生成样本的特例,同时判别模型也是通过多层感知机实现的。称这个特例为对抗网络。在这种情况下,可以仅使用非常成熟的反向传播和丢弃算法训练两个模型,生成模型在生成样本时只使用前向传播算法。并且不需要近似推理和马尔可夫链作为前题。
1.4相关背景知识
1.4.1 GAN的思想
GAN有两个重要的角色:一个生成器(Generator),还有一个判别器(Discriminator)。
GAN的思想简单来说就是这两个角色之间的博弈:生成器生成图片,并试图尽自己最大的努力去欺骗判别器——这是一张自然的图片,而判别器则是尽可能的去辨别——不,这是一张生成的图片。
我们可能很快会想到Minimax Theorem——最小化最大值原理,事实上这也是为什么我们称之为对抗(Adversarial),这就是两个互相对弈的象棋大师:双方都努力做出最佳的应招,而显然,在双方都做出最佳的选择的情况下,结果就必然是确定的。这保证了我们的训练最终将会收敛,也就是说,最终生成器将会作出最好的采样,得到最为接近真实的图片,而判别器将束手无策。
1.4.2 GAN网络架构
生成对抗网络由两个网络组成:
生成器(Generator)网络
判别器(Discriminator)网络
下面图1是一个基本的GAN网络架构:
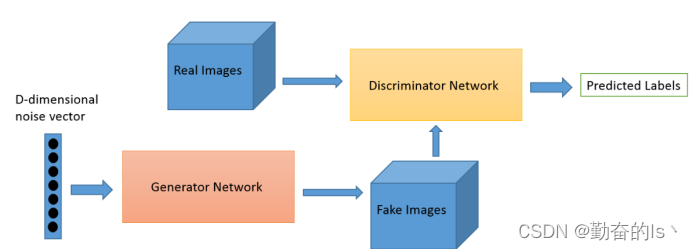
图1
输入D维的噪声向量,通过生成器网络产生假图像,然后输入到判别器中,判别器根据数据集中的真是图像做出判断,给出判断结果,即这是否是一张真实的图片。
1.4.2.1 生成器 Generator
生成器具体是怎样来生成图片的,GAN的生成器的架构是类似下面图2这样,可以看到这实际上可以看成一个反卷积(reverse convolutional neural network)的过程:输入是一个随机的噪声向量,最终通过多层的反卷积生成一张64×64的图片。
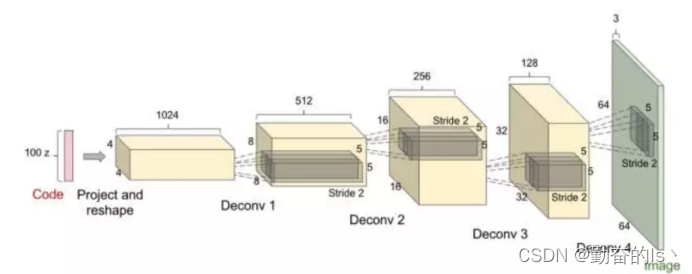
图2
反卷积:相比于卷积的下采样(subsample,将一张图片最终变成一个向量),这是一个上采样的过程(upsample,将一个向量转为图片):首先对图像进行上采样,如下图3,原本的图像是一张 3×3的图像,可以看到上采样之后变成了7×7的图片中蓝色的9个像素点,并且出现了很多空白部分。然后,我们必须对空白部分进行填充,填充就是采用一个反卷积的过程。
下图中深绿色的5×5的部分其实就是我们的反卷积的模板,反卷积不同于卷积的地方就是:我们是用反卷积模板中的每个像素拿来和我们所要进行反卷积的图片进行卷积,也就是说,这是5×5=25个1×1的模板和一张3×3 进行卷积的过程的进行卷积的过程。
从下面的图片可以看到,下面投射出来的阴影部分就是上面5×5绿色模板中的每个像素和3×3蓝色图片卷积的结果:
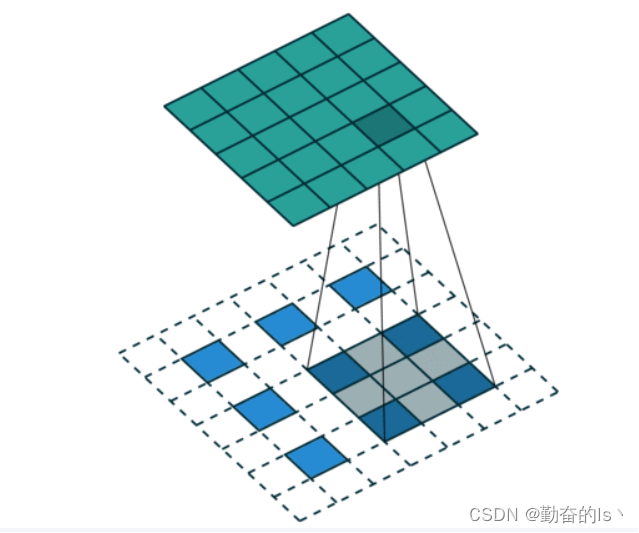
图3
我们也可以发现,之所以采用的是5×5的反卷积模板,是为了能够将一张3×3的图片对7×7的上采样结果进行插值:3+5−1=7
1.4.2.2 判别器 Discriminator
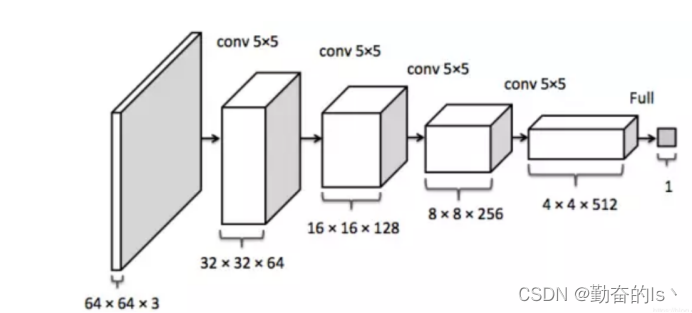
图4这是一个非常接近于CNN(Convolutional Neural Network 卷积神经网络)的过程,前面两维是特征图像的大小,第三维是特征图像的数量(例如,经过第一层的卷积层之后得到了 64张32×32的特征图像)。
这里的判别器架构没有给出池化的过程,但是我们可以看到,在每次卷积之后图像的两个维度都变成了原来的1/2,事实上是经过了一个池化的操作,我们有时也会把卷积和池化合并在一个卷积层的操作当中,而不是单独作为一个池化层。
1.5问题的解决过程分析
当模型是多层感知器时,对抗模型框架是最直接应用的。为了学习生成器关于数据x上的分布pg, 我们定义输入噪声的先验变量pz(z),然后使用G(z;θg)来代表数据空间的映射。这里G是一个由含有参数θg的多层感知机表示的可微函数。我们再定义了一个多层感知机D(x;θd)用来输出一个单独的标量。D(x)代表x来自于真实数据分布而不是pg的概率,我们训练D来最大化分配正确标签给不管是来自于训练样例还是G生成的样例的概率。我们同时训练G来最小化log(1−D(G(z)))。换句话说,D和G的训练是关于值函数V(G,D)的极小化极大的二人博弈问题。
GminDmaxV(D,G)=Ex∼Pdata(x)[logD(x)]+Ez∼Pz(z)[log(1−D(z))] (1)
对抗网络的理论分析,基本上表明基于训练准则可以恢复数据生成分布,因为G和D被给予足够的容量,即在非参数极限。如图5展示了该方法的一个非正式却更加直观的解释。实际上,我们必须使用迭代数值方法来实现这个过程。在训练的内部循环中优化D到完成的计算是禁止的,并且有限的数据集将导致过拟合。相反,我们在优化D的k个步骤和优化G的一个步骤之间交替。只要G变化足够慢,可以保证D保持在其最佳解附近。该过程如算法1所示。
实际上,方程1可能无法为G提供足够的梯度来学习。训练初期,当G的生成效果很差时,D会以高置信度来拒绝生成样本,因为它们与训练数据明显不同。因此,log(1−D(G(z)))饱和。因此我们选择最大化logD(G(z))而不是最小化log(1−D(G(z)))来训练G,该目标函数使G和D的动力学稳定点相同,并且在训练初期,该目标函数可以提供更强大的梯度。
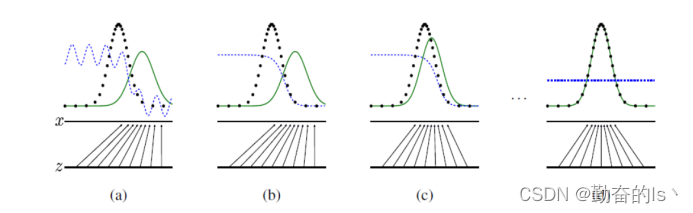
图5
图5:训练对抗神经网络时,同时更新判别分布(D,蓝色虚线)使D能区分数据生成分布px(黑色虚线)中的样本和生成分布pg (G,绿色实线) 中的样本。下面的水平线为均匀采样z的区域,上面的水平线为x的部分区域。朝上的箭头显示映射x=G(z)如何将非均匀分布pg作用在转换后的样本上。G在pg高密度区域收缩,且在pg地的低密度区域扩散。
(a)考虑一个接近收敛的对抗的模型对:pg与pdata相似,且D是个部分准确的分类器。
(b)在算法的内循环中,训练D来判断数据中的样本,收敛到
D∗(x)=pdata(x)/(pdata(x)+pg(x)) 。
(c)在G的一次更新后,D的梯度引导G(z) 流向更可能分类为数据的区域。
(d)训练若干步后,如果G和D有足够的容量,他们将会接近某个点,由于pg=pdata 两者都无法提高性能。判别器将不能区别出训练数据分布和生成数据分布,即D(x)=1/2。
算法1.生成对抗网络的minibatch随机梯度下降训练。判别器的训练步数,是一个超参数。在我们的实验中使用,使消耗最小。

1.6实验结果分析
本次实验用了大多数示例使用手写数字的MNIST数据集。该数据集包含60,000个用于训练的示例和10,000个用于测试的示例。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28x28像素),其值为0到1。为简单起见,每个图像都被平展并转换为784(28 * 28)个特征的一维numpy数组。
本次实验在一定范围的数据集内训练对抗网络,生成器网络使用整流器线性激活函数和sigmoid激活函数的混合,而辨别器网络使用maxout激活函数。Dropout应用于训练辨别器网络中。通过将高斯帕尔森窗口应用于G产生的样本中,并且在这个分布下报告对数似然函数,来评估pg之下的测试数据集的可能性。
这个新的框架有缺点也有优点,涉及到先前的模型框架。缺点主要是没有pg(x) 的显性表示,并且在训练过程中,D必须是与G同步的(特别的,如果没有更新D,G不应训练过多,为了避免“the Helvetica scenario”情况,G折叠了太多z的值到同一个x的值,以至于模型没有足够的多样性),尽管Boltzmann机器的负链必须保持学习步数之间的约定。优点就是马尔科夫链不再需要,只是用后向传播来获取梯度,在学习期间不再需要推理,并且更多样性的函数可以成为模型的一部分。上面提到的优点主要是计算方面的,对抗网络不仅从生成器网络中,利用数据例子直接更新,获得了很多统计上的优点,也从辨别器中获得了梯度。这意味着输入的成分不会直接复制到生产器的参数中。对抗网络的另一个优点是,即使是退化分布,他们表现地也非常敏捷,尽管基于马尔科夫链的方法要求,对于链,分布必须是有些模糊的,以至于有能力混合模型。
二 程序解读
2.1工程文件结构图及部分代码说明
2.1.1工程文件
第一个gan.py文件夹用来存放GAN的代码,运行代码后,会在同一个目录下自动生成gandata文件夹,该文件夹里用来存放数据集,接下来会用到这个数据集。还会在同一个目录下生成一个img文件夹,用来存在实验结果。
2.1.2部分核心代码

数据集的下载
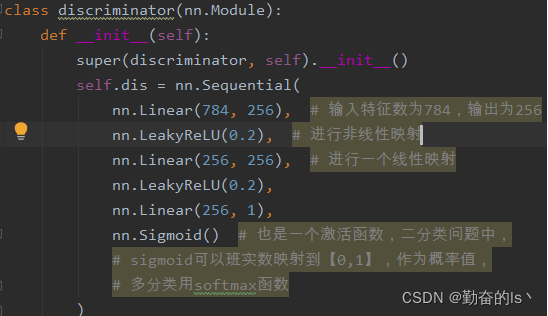
定义判别器
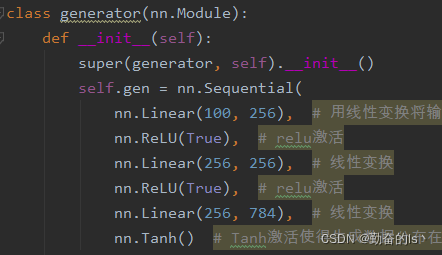
定义生成器
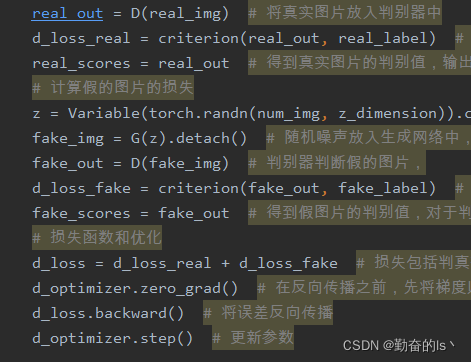
训练判别器
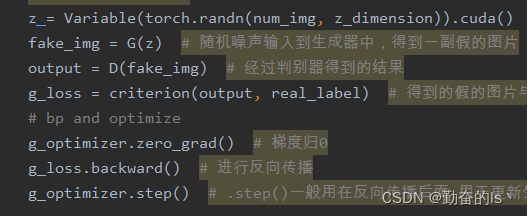
训练生成器
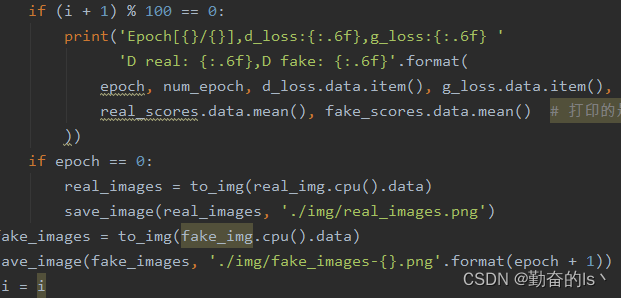
打印中间损失
2.2程序运行所依赖的环境
系统:Win10操作系统
本文主要使用python实现的,所以需要安装python,我安装的是python3.7。需要安装torch库,版本为1.4.0;torchvision库的版本为0.5.0;还有一些基础库。需要安装与torch配套的cuda,我安装的是9.2版本。
2.3程序运行及结果展示
打印的图片,如图所示


中间损失值

2.4修改参数及结果分析
将优化函数的学习率由0.0003改为0.0005,生成的图片和中间损失值如下图所示。



通过真实的图片和生成器产生图片对判别器进行训练,判别器会逐渐明白,一张真实的图片应该具备什么样的特点(比如,一只猫应该有尾巴,甚至是某个特定品种的猫具有什么样的特点)
判别器可以对生成器产生的图片做出反馈,告诉生成器怎么样才能做的更好,他们并不是一味的对抗,而是在对抗之后(一次迭代),双方选手进行赛后复盘,最终得出应该怎样才能做的更好,然后开始下一场比赛。通过这样的共同训练,可以保证某一方不会过于强大,双方同时进步。改变了学习率后,判别器和生成器有了新的对抗,所以就会生成这种新的图片。