数据预处理是将 原始数据 转化成能够用于建模的一致数据的过程,它是分析流程中非常关键的一个环节!!!!
首先,载入需要的R包
caret :提供机器学习模型及拟合效果的系统交互界面
e1071:各类计量经济和机器学习的延伸,我们使用其中的naiveBayes函数进行朴素贝叶斯判别
gridExtra:绘图辅助功能,将不同图形组合在一起成为图表
lattice:建立在核心绘图能力上的格子框架图形
imputeMissings:填补缺失值
RANN:应用K-邻近算法
corrplot:相关矩阵的高级可视化
nnet:拟合单个潜层级的神经网络模型
car:回归模型解释和可视化工具
gpairs:广义散点图
reshape2:灵活重构和整合数据,主要有两个函数melt()和dcast()
psych:心理计量学方法和抽样调查分析,尤其是因子分析和项目反映模型plyr:可以将数据分割成更小的数据,然后对分割后的数据进行一些操作,最后把操作的结果汇总
tidyr:清理糅合数据的包,主要函数是spread()和gather()
> library(caret)
> library(e1071)
> library(gridExtra)
> library(lattice)
> library(imputeMissings)
> library(RANN)
> library(corrplot)
> library(nnet)
> library(car)
> library(gpairs)
> library(reshape2)
> library(psych)
> library(plyr)
> library(tidyr)数据清理
检查数据
1.有哪些变量
2.变量怎样分布
3.是不是存在错误的观测
以下是读取服装消费者数据
> sim.dat=read.csv("https://raw.githubusercontent.com/happyrabbit/DataScientistR/master/Data/SegData.csv")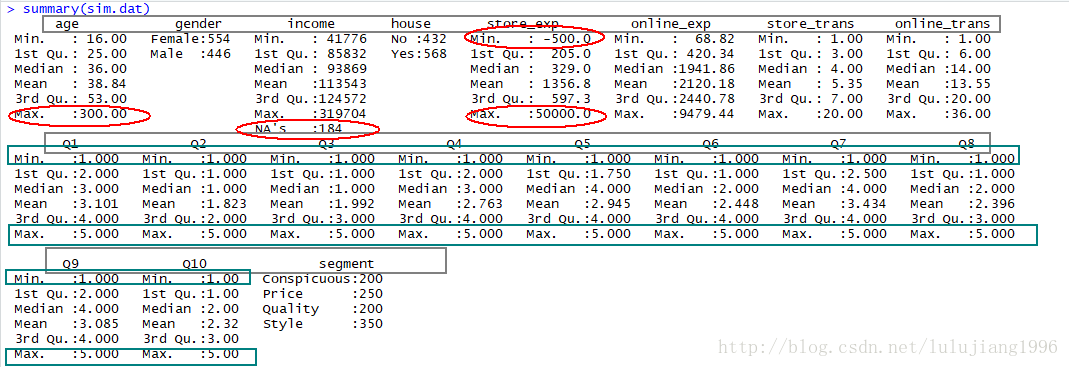
由上图,灰色框勾选的即为所有的变量。Q1…Q10貌似合理,min为1,max为5,gender,house,online_exp,store_trans,online_trans,segment看上去也合理。
而其他(红色区域勾选部分)存在异常,其中age和store_exp中存在离群值,income中存在缺失值。
异常值初步处理:
1.将这些值设置成缺失状态
> sim.dat$age[which(sim.dat$age>100)]=NA
> sim.dat$store_exp[which(sim.dat$store_exp<0)]=NA
> summary(subset(sim.dat,select=c("age","income")))
age income
Min. :16.00 Min. : 41776
1st Qu.:25.00 1st Qu.: 85832
Median :36.00 Median : 93869
Mean :38.58 Mean :113543
3rd Qu.:53.00 3rd Qu.:124572
Max. :69.00 Max. :319704
NA's :1 NA's :184
> 2.缺失值填补
-(1)中位数或众数填补
即用含有缺失值变量中的中位数或众数填补缺失值
#impute()为imputeMissings包中的函数
> demo_imp=impute(sim.dat,method="median/mode")
> summary(demo_imp[,1:5])
age gender income house store_exp
Min. :16.00 Female:554 Min. : 41776 No :432 Min. : 155.8
1st Qu.:25.00 Male :446 1st Qu.: 87896 Yes:568 1st Qu.: 205.1
Median :36.00 Median : 93869 Median : 329.8
Mean :38.58 Mean :109923 Mean : 1357.7
3rd Qu.:53.00 3rd Qu.:119456 3rd Qu.: 597.3
Max. :69.00<