前言
2017横空出世的Transformer可谓是惊艳了所有人,再到2018年谷歌推出的BERT更是将其威力发挥到了极致,在NLP的11项下游任务中夺得SOTA结果,轰动了整个NLP领域。当然BERT取得的出色成绩并不是一蹴而就的,而是ELMO和GPT等预训练的集大成者。但正是因为Transformer的出现开启了大规模预训练时代,为研究者指引了新的方向。相信NLP的学习者多多少少都看过不少关于Transformer的文章,其中大多千篇一律,且鲜有代码辅助讲解。所有我决定对Transformer的模型原理和代码进行通俗讲解,让读者清楚模型内部到底发生什么。
给读者的一些建议
- 希望你对Transformer的模型有过一定的学习,可先阅读这篇博客:https://blog.csdn.net/longxinchen_ml/article/details/86533005
这篇对模型原理讲解的很清楚,在对模型有一定的理解后看代码会更容易。 - “Attention is all you need” 论文原文在此,请自行阅读
https://arxiv.org/pdf/1706.03762.pdf - 代码参考
The Annotated Transformer
对于代码我进行了调整,可以让读者更容易理解模型,所以读者自上而下阅读即可 - 该项目包含transformer的代码是实现和一个运行案例,代码移步本人的代码仓,代码一键运行,开箱即食,觉得对你有帮助的话给个star吧~
github代码
Transformer模型
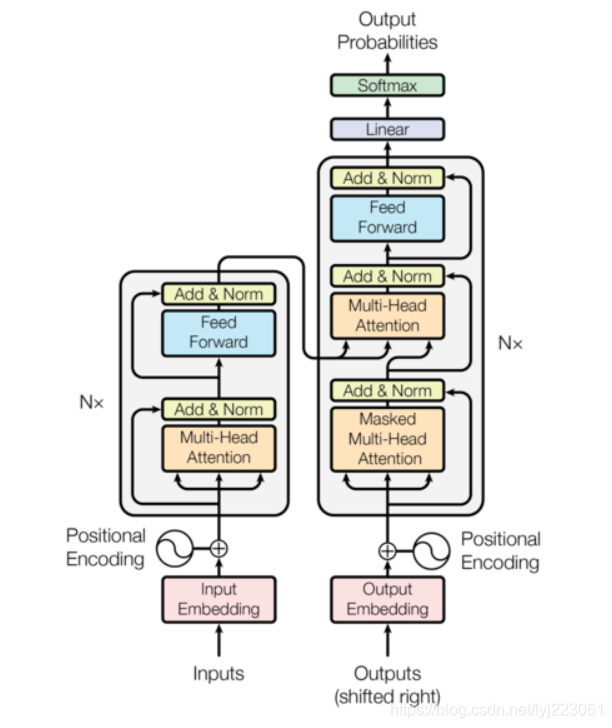
用最通俗简单的话来解释一下模型,先从宏观讲看一下模型包含哪些组件吧。
首先记得,inputs从输入到最终输出的维度始终保持在[batch_size, max_len, d_model], d_model就是模型所谓的hidden_size,代码部分会提到。
模型的左边encoder,右边decoder。inputs在经过embedding+positional embedding之后embedding成encoder真正的输入。在经过了Nx=6,也就是6层encoderlayer之后得到encoder的输出memory,用于decoder输入的一部分。同样的,decoder的输入在经过embedding+positional embedding之后开始输入到decoder中,经过6层decoderlayer后输出,最终经过一个linear和softmax层得到最终的output。
下图所示仅为单层encoderlayer和decoderlayer的结构。其中encoder由6层(论文中使用了6层)encoderlayer组成,decoder也由6层decoderlayer组成。
encoderlayer中包含两个重要的部分:self-attention,feed_forward。其中会有一些小trick,在每经过self-attention和feed_forward后都会经过一个LayerNorm,并且由残差结构相连。
decoderlayer基本和encoderlayer类似,不同的是decoderlayer里的attention不太一样,第一个是self-attention,第二个soft-attention。并且decoder中有sequence mask机制来避免decoder解码时看到未来信息。另外,encoder输出会当作memory分别传入decoderlayer的第二层中。
代码
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy, time
from torch.autograd import Variabs
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model) # [batch, max_Len, embed_dim]
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0., max_len).unsqueeze(1) # [50000, 1] -> [[0.], [1.], [2.],....[4999]]
div_term = torch.exp(torch.arange(0., d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
class Generator(nn.Module):
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1) # [batch, max_len, vocab]
def clones(module, N):
# copy.deepcopy硬拷贝函数
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
# features=layer.size=512
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True) # [batch, max_len, 1]
std = x.std(-1, keepdim=True) # [batch, max_len, 1]
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
# sublayer是layer的一个子结构
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
#Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N)
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2) # 将残差结构复制两份
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # 第一层:self_attn
return self.sublayer[1](x, self.feed_forward) # 第二层:feed_forward
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask): # x: decoder在embed和position_embed后的输入
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
# memory就是encoder输出
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
# self-attetion q=k=v,输入是decoder的embedding,decoder的第一层
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# soft-attention q!=k=v x是deocder的embedding,m是encoder的输出,decoder的第二层
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward) # decoder的第三层过一个feed_forward
# 为了避免decoder看到未来信息,影响解码,制作一个下三角矩阵
def subsequent_mask(size):
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
# subsequent_mask(5)
# tensor([[[ True, False, False, False, False],
# [ True, True, False, False, False],
# [ True, True, True, False, False],
# [ True, True, True, True, False],
# [ True, True, True, True, True]]])
# scaled dot-product attention
# Attention(Q, K, V) = softmax(Q*K.T/sqrt(d_k)) * V
def attention(Q, K, V, mask=None, dropout=None):
# Query=Key=Value: [batch_size, 8, max_len, 64]
d_k = Q.size(-1)
# Q * K.T = [batch_size, 8, max_len, 64] * [batch_size, 8, 64, max_len]
# scores: [batch_size, 8, max_len, max_len]
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
#padding mask
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9) # 极小值填充
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, V), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4) # WQ=WK=WV=W0:[512, 512]
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None): # q, k, v就是传进的x
# q=k=v: [batch_size, max_len, d_model]
if mask is not None:
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 第一步:将q,k,v分别与Wq,Wk,Wv矩阵相乘, Wq=Wk=Wv: [512,512]
# 第二步:将获得的Q、K、V进行维度切分, [batch_size,max_length,8,64]
# 第三部:交换纬度, [batch_size,8,max_length,64]
Q, K, V = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# q*wq, k*wk, v*wv, self.linears调用了3层
# 得到Q, K, V之后开始做scaled dot-product attention
# Query=Key=Value: [batch_size, 8, max_len, 64]
# x: 输出, self.attn: 计算得到的attention
x, self.attn = attention(Q, K, V, mask=mask, dropout=self.dropout)
# 纬度交换还原: [batch_size, max_length, 512]
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
# 与W0大矩阵相乘: [batch_size, max_len, 512]
return self.linears[-1](x) # 调用第四层linear
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
# [512, 2048]
self.w_1 = nn.Linear(d_model, d_ff)
# [2048, 512]
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(Transformer, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
# src=tgt:[batch_size, max_length]
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
# Mask机制
# Transformer 模型里面涉及两种mask,padding mask 和 sequence mask。
# padding mask 在所有的 scaled dot-product attention 里面都需要用到,
# 而 sequence mask 只有在 decoder 的 self-attention 里面用到。
#
# Padding Mask
# 因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。
# 具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。
# 因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
# 具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
# 而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
#
# Sequence mask
# 文章前面也提到,sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,
# 在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。
# 因此我们需要想一个办法,把 t 之后的信息给隐藏起来。 那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。
# 把这个矩阵作用在每一个序列上,就可以达到我们的目的。
#
# 对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和
# sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
# 其他情况,attn_mask 一律等于 padding mask。
### 解码过程
# Decoder的最后一个部分是过一个linear layer将decoder的输出扩展到与vocabulary size一样的维度上。
# 经过softmax 后,选择概率最高的一个word作为预测结果。在做预测时,步骤如下:
# (1)给 decoder 输入 encoder 对整个句子 embedding 的结果 和一个特殊的开始符号 。
# decoder 将产生预测,在我们的例子中应该是 ”I”。
# (2)给 decoder 输入 encoder 的 embedding 结果和 “I”,在这一步 decoder预测 “am”。
# (3)给 decoder 输入 encoder 的 embedding 结果和 “I am”,在这一步 decoder预测 “a”。
# (4)给 decoder 输入 encoder 的 embedding 结果和 “I am a”,在这一步 decoder预测 “student”。
# (5)给 decoder 输入 encoder 的 embedding 结果和 “I am a student”, decoder应该输出 ”。”
# (6)然后 decoder 生成了 ,翻译完成。
def make_model(src_vocab, tgt_vocab, N=6,
d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = Transformer(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn),
c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# 参数初始化
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
###################运行一个简单实例#########################
class Batch:
def __init__(self, src, trg=None, pad=0):
# src=tgt: [batch_size, max_len] = [30, 10]
self.src = src
# padding_mask
self.src_mask = (src != pad).unsqueeze(-2) # [batch, 1, max_len]
if trg is not None:
## decoder是用encoder和t-1时刻取预测t时刻
self.trg = trg[:, :-1] # 去掉每行的最后一个词,表明t-1时刻
self.trg_y = trg[:, 1:] # 去掉每行第一个词, 表明t时刻
self.trg_mask = self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum() # 不为pad的都计算为单词,统计数量
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2) # [batch, 1, max_len]
# 将padding_mask和sequence_mask进行结合得到decoder的mask矩阵
tgt_mask = tgt_mask & Variable(subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask
def run_epoch(data_iter, model, loss_compute):
"Standard Training and Logging Function"
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_iter):
# batch.tgt: t-1时刻
# batch.tgt_y: t时刻
# out: transformer输出的预测
out = model.forward(batch.src, batch.trg, batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed = time.time() - start
print("Epoch Step: %d Loss: %f Tokens per Sec: %f" % (i, loss / batch.ntokens, tokens / elapsed))
start = time.time()
tokens = 0
return total_loss / total_tokens
global max_src_in_batch, max_tgt_in_batch
def batch_size_fn(new, count, sofar):
"Keep augmenting batch and calculate total number of tokens + padding."
global max_src_in_batch, max_tgt_in_batch
if count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max(max_src_in_batch, len(new.src))
max_tgt_in_batch = max(max_tgt_in_batch, len(new.trg) + 2)
src_elements = count * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max(src_elements, tgt_elements)
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step is None:
step = self._step
return self.factor * (self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
# 正则化
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(reduction='sum')
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
#x====>[batch_size*max_length-1,vocab_size]
#target====>[batch_size*max_length-1]
assert x.size(1) == self.size
true_dist = x.data.clone()
#fill_就是填充
true_dist.fill_(self.smoothing / (self.size - 2))
#scatter_修改元素
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))
# (vocab, 30, 20)
# batch: 每次送入的句子数, nbathces: 输入几次
def data_gen(V, batch, nbatches):
"Generate random data for a src-tgt copy task."
for i in range(nbatches):
# [30, 10]
data = torch.from_numpy(np.random.randint(1, V, size=(batch, 10)).astype(np.int64))
data[:, 0] = 1 # [batch, max_len] = [30, 10], 且句首都是1
src = Variable(data, requires_grad=False)
tgt = Variable(data, requires_grad=False)
yield Batch(src, tgt, 0)
# Compute loss
class SimpleLossCompute:
"A simple loss compute and train function."
def __init__(self, generator, criterion, opt=None):
self.generator = generator
self.criterion = criterion # LabelSmoothing
self.opt = opt
def __call__(self, x, y, norm):
# x对应于out,也就是预测的时刻[batch_size, max_length-1, vocab_size]
# y对应于tgt_y,也就是t时刻 [batch_size, max_length-1]
x = self.generator(x)
#x.contiguous().view(-1, x.size(-1)) ====>[batch_size*max_length-1,vocab_size]
#y.contiguous().view(-1)=========>[batch_size*max_length-1]
loss = self.criterion(x.contiguous().view(-1, x.size(-1)),
y.contiguous().view(-1)) / norm
loss.backward()
if self.opt is not None:
self.opt.step()
self.opt.optimizer.zero_grad()
return loss.data.item() * norm
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 400,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
for epoch in range(10):
model.train()
run_epoch(data_gen(V, 30, 20), model,
SimpleLossCompute(model.generator, criterion, model_opt))
model.eval()
print(run_epoch(data_gen(V, 30, 5), model,
SimpleLossCompute(model.generator, criterion, None)))
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
#ys是decode的时候起始标志
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
print(ys)
for i in range(max_len-1):
out = model.decode(memory, src_mask, Variable(ys),
Variable(subsequent_mask(ys.size(1)).type_as(src.data)))
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word= next_word.data[0]
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
print("ys:"+str(ys))
return ys
model.eval()
src = Variable(torch.LongTensor([[1,2,3,4,5,6,7,8,9,10]]) )
src_mask = Variable(torch.ones(1, 1, 10) )
# print("ys:"+str(ys))
print(greedy_decode(model, src, src_mask, max_len=10, start_symbol=1))
# Epoch Step: 1 Loss: 2.861889 Tokens per Sec: 2006.179199
# Epoch Step: 1 Loss: 1.861335 Tokens per Sec: 2674.957764
# tensor(1.8702)
# Epoch Step: 1 Loss: 1.890580 Tokens per Sec: 1682.654907
# Epoch Step: 1 Loss: 1.658329 Tokens per Sec: 2745.026611
# tensor(1.6821)
# Epoch Step: 1 Loss: 1.817523 Tokens per Sec: 2004.011841
# Epoch Step: 1 Loss: 1.385571 Tokens per Sec: 2860.951904
# tensor(1.4452)
# Epoch Step: 1 Loss: 1.632956 Tokens per Sec: 2000.890625
# Epoch Step: 1 Loss: 1.330772 Tokens per Sec: 2858.529297
# tensor(1.3518)
# Epoch Step: 1 Loss: 1.446098 Tokens per Sec: 2019.426514
# Epoch Step: 1 Loss: 1.404362 Tokens per Sec: 2889.774170
# tensor(1.3607)
# Epoch Step: 1 Loss: 1.222221 Tokens per Sec: 1977.914917
# Epoch Step: 1 Loss: 0.675666 Tokens per Sec: 2861.769043
# tensor(0.6727)
# Epoch Step: 1 Loss: 0.878156 Tokens per Sec: 2021.668823
# Epoch Step: 1 Loss: 0.342367 Tokens per Sec: 2861.562988
# tensor(0.3776)
# Epoch Step: 1 Loss: 0.591462 Tokens per Sec: 1879.208984
# Epoch Step: 1 Loss: 0.284362 Tokens per Sec: 2949.965088
# tensor(0.2932)
# Epoch Step: 1 Loss: 0.648037 Tokens per Sec: 1994.176758
# Epoch Step: 1 Loss: 0.300891 Tokens per Sec: 2786.810059
# tensor(0.3205)
# Epoch Step: 1 Loss: 0.723345 Tokens per Sec: 1838.991577
# Epoch Step: 1 Loss: 0.239575 Tokens per Sec: 2813.084717
# tensor(0.2302)
# tensor([[1]])
# ys:tensor([[1, 2]])
# ys:tensor([[1, 2, 3]])
# ys:tensor([[1, 2, 3, 5]])
# ys:tensor([[1, 2, 3, 5, 4]])
# ys:tensor([[1, 2, 3, 5, 4, 6]])
# ys:tensor([[1, 2, 3, 5, 4, 6, 7]])
# ys:tensor([[1, 2, 3, 5, 4, 6, 7, 8]])
# ys:tensor([[1, 2, 3, 5, 4, 6, 7, 8, 9]])
# ys:tensor([[ 1, 2, 3, 5, 4, 6, 7, 8, 9, 10]])
# tensor([[ 1, 2, 3, 5, 4, 6, 7, 8, 9, 10]])