前言
理解高速缓存对 C 程序性能的影响,通过两部分实验达成:编写高速缓存模拟器;优化矩阵转置函数以减少高速缓存未命中次数。Part A一开始根本不知道要做什么,慢慢看官方文档,以及一些博客,和B站视频,终于知道是干嘛的了,看完别人的解题方法后,就能自己写出来了。按照我给出的一些链接,完全能搞懂Cache Simulator。Part B给大家推荐了两篇文章。
参考资料:
Lab下载链接,CacheLab官方文档,CacheLab官方课件(强烈推荐阅读),大佬笔记
Part A: Writing a Cache Simulator
下面这些描述是我用豆包对官方PDF生成的总结
- 输入输出:接受 Valgrind 内存跟踪文件作为输入,模拟高速缓存的命中 / 未命中行为,输出命中、未命中和驱逐(替换)的总数。
- 参考模拟器:提供
csim - ref作为参考模拟器,使用 LRU(最近最少使用)替换策略,命令行参数为Usage:./csim - ref [-hv] - s <s> - E <E> - b <b> - t <tracefile>,其中-h为帮助标志,-v为详细输出标志,-s指定组索引位数,-E指定每行关联度,-b指定块大小位数,-t指定 Valgrind 跟踪文件路径。 - 编程规则:编译无警告;为任意 S、E、b 值正确工作,需用
malloc分配存储空间;忽略指令缓存访问(以 “I” 开头的行);在main函数结束时调用printSummary函数输出结果;假设内存访问已正确对齐,忽略 Valgrind 跟踪文件中的请求大小。 - 提示:先在小跟踪文件(如
traces/dave.trace)上调试。参考模拟器的-v选项可显示详细的命中、未命中和驱逐信息,建议在csim.c中实现此功能辅助调试。推荐使用getopt函数解析命令行参数,需包含<getopt.h>、<stdlib.h>、<unistd.h>头文件。数据加载(L)或存储(S)操作最多导致一次缓存未命中,数据修改(M)操作视为一次加载和一次存储,可能产生两次命中、一次未命中加一次命中或一次未命中加一次命中加一次驱逐。
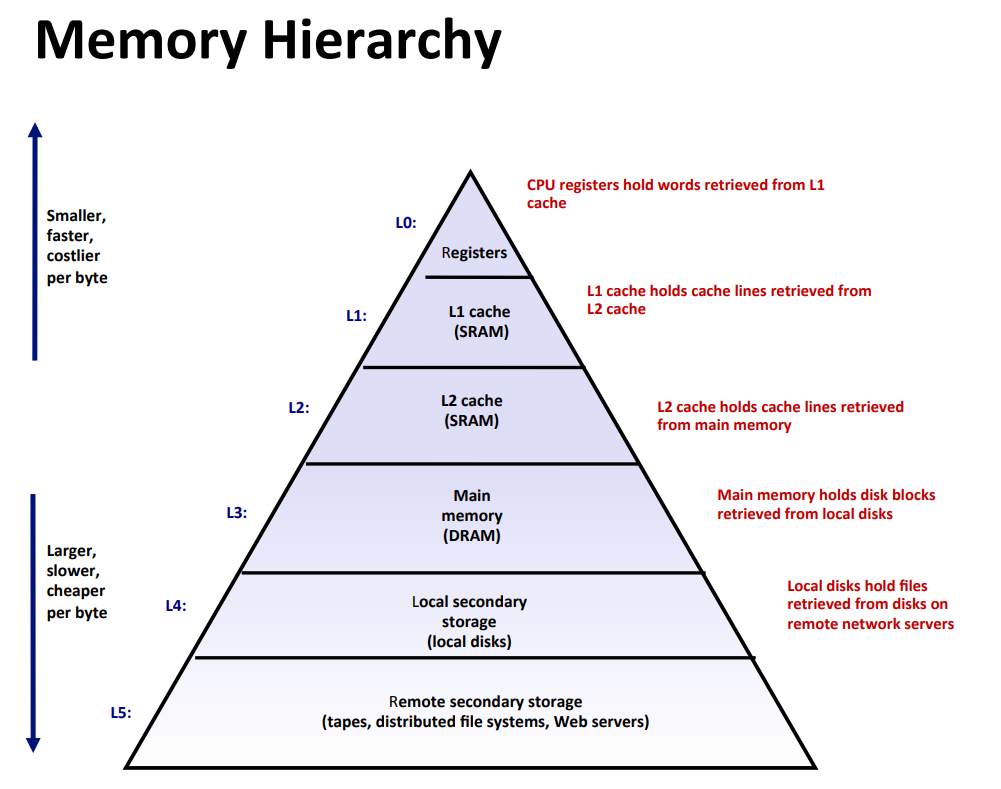
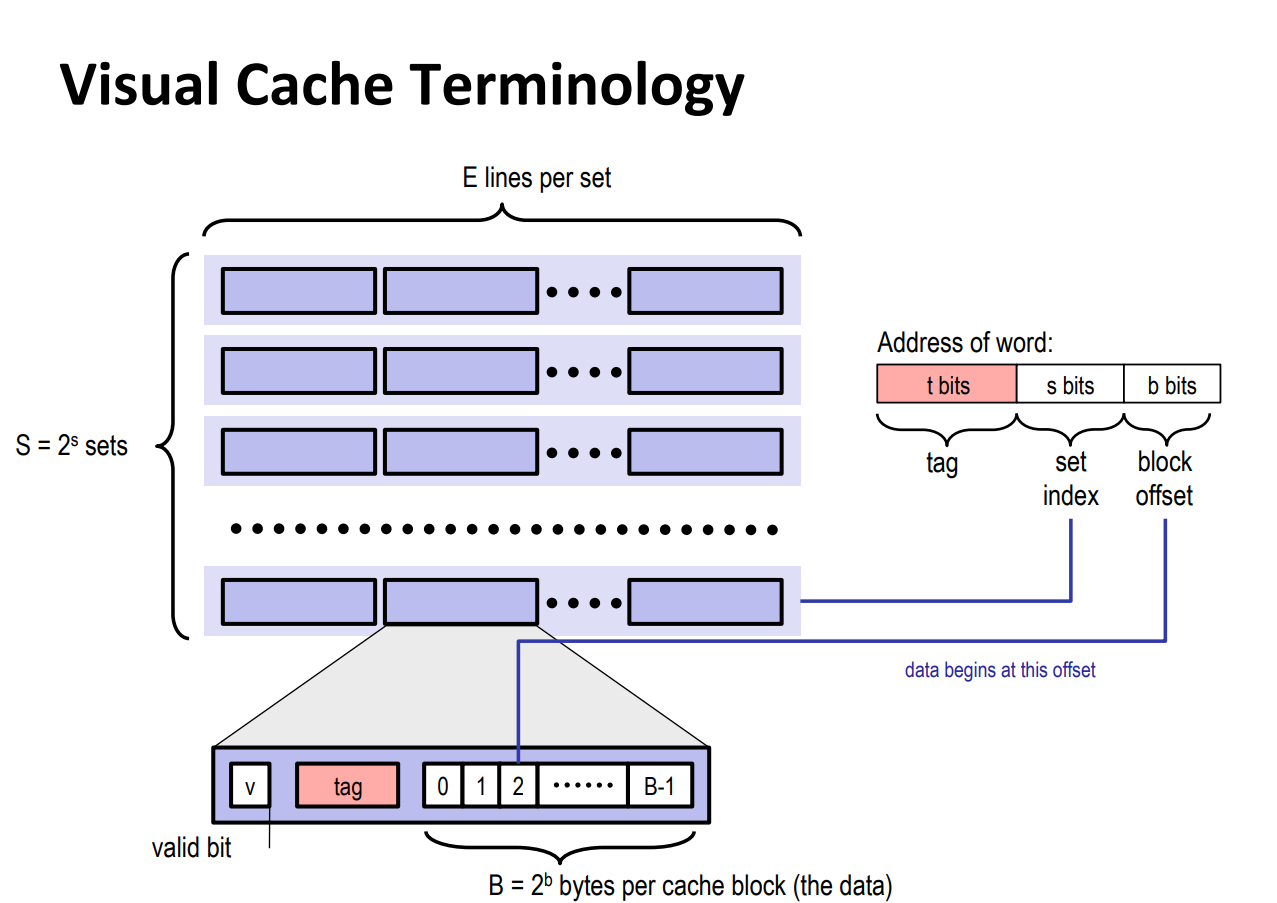
下面是高速缓存(S, E, B, m)的通用组织。高速缓存是一个高速缓存的数组。每个组包含一个或多个行,每个行包含一个有效位,一些标记位,以及一个数据块。高速缓存的结构将m个地址位划分成了t个标记位,s个索引位和b个块偏移位。详见CSAPP6.4。强烈推荐B站视频,看完之后就知道这个实验要做什么了,理解计算机Cache(一):从块到缓存结构,以及逐步推出映射策略和理解计算机Cache(二):缓存与内存的交互。
下面是看完别人的解法后,又自己写的代码
#include "cachelab.h"
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <getopt.h>
typedef struct cache_line
{
int valid_bit; // 有效位
unsigned tag; // 标记位
int stamp; // 时间戳用于LRU
}cache_line;
// S(2^s)块大小, s组索引.
// E缓存块(2^b)行数, b块偏移.
int S, s, B, b, E;
// 命中,未命中,替换
int hit, miss, eviction;
char *filepath;
cache_line **cache;
void init()
{
// malloc cache[S][E]
cache = (cache_line**)malloc(sizeof(cache_line*) * S);
for (int i = 0; i < S; i++)
cache[i] = (cache_line*)malloc(sizeof(cache_line) * E);
for (int i = 0; i < S; i++)
{
for (int j = 0; j < E; j++)
{
cache[i][j].valid_bit = 0;
cache[i][j].tag = cache[i][j].stamp = -1;
}
}
}
void destroy()
{
for (int i = 0; i < S; i++)
free(cache[i]);
free(cache);
}
void update(unsigned addr)
{
int s_addr = (addr >> b) & ((-1U) >> (32 - s));
int t_addr = (addr >> (s + b));
// 缓存命中
for (int i = 0; i < E; i++)
{
if (cache[s_addr][i].tag == t_addr)
{
cache[s_addr][i].stamp = 0;
hit++;
return;
}
}
// 缓存未命中,还有空块
for (int i = 0; i < E; i++)
{
if (cache[s_addr][i].valid_bit == 0)
{
miss++;
cache[s_addr][i].valid_bit = 1;
cache[s_addr][i].tag = t_addr;
cache[s_addr][i].stamp = 0;
return;
}
}
// 没有空组,产生替换
miss++;
eviction++;
int max_stamp = 0, max_i = 0;
for (int i = 0; i < E; i++)
{
if (cache[s_addr][i].stamp > max_stamp)
{
max_stamp = cache[s_addr][i].stamp;
max_i = i;
}
}
cache[s_addr][max_i].tag = t_addr;
cache[s_addr][max_i].stamp = 0;
return;
}
void time()
{
for (int i = 0; i < S; i++)
{
for (int j = 0; j < E; j++)
{
if (cache[i][j].valid_bit == 1) // 被使用了
cache[i][j].stamp++;
}
}
}
int main(int argc, char* argv[])
{
int opt;
while (-1 != (opt = getopt(argc, argv, "s:E:b:t:")))
{
switch (opt)
{
case 's':
s = atoi(optarg); // optarg是getopt函数设置的指向当前选项参数的指针
S = 1 << s;
break;
case 'E':
E = atoi(optarg);
break;
case 'b':
b = atoi(optarg);
B = 1 << b;
break;
case 't':
filepath = optarg;
break;
}
}
init();
FILE* pf = fopen(filepath, "r");
if (pf == NULL)
{
printf("fopen fail\n");
exit(-1);
}
char op;
unsigned addr;
int size;
while (fscanf(pf, "%c %x,%d", &op, &addr, &size) > 0)
{
switch (op)
{
case 'L':
update(addr);
break;
case 'M': // 执行两次
update(addr);
case 'S':
update(addr);
break;
}
time();
}
destroy();
fclose(pf);
printSummary(hit, miss, eviction);
return 0;
}
Part B: Optimizing Matrix Transpose
- 函数功能:在
trans.c中编写transpose_submit函数,计算矩阵的转置并存储结果,尽量减少高速缓存未命中次数。 - 编程规则:编译无警告;每个转置函数最多定义 12 个
int类型的局部变量,不能使用long类型变量或位技巧规避此规则;函数不能使用递归;使用辅助函数时,辅助函数和顶级转置函数在栈上的局部变量总数不能超过 12 个;不能修改数组 A,可随意处理数组 B;不能定义数组或使用malloc。 - 提示:转置函数在直接映射缓存上评估,冲突未命中是潜在问题,需考虑代码中尤其是对角线上的冲突未命中,设计降低冲突未命中的访问模式。分块是减少缓存未命中的有用技术,可参考利用分块提高时间局部性PDF 获取更多信息。测试程序
test - trans会保存函数的跟踪文件(如trace.f0等),可通过参考模拟器的-v选项运行跟踪文件辅助调试。
给大家推荐两个写的好的文章,我做不出来…