背景
最近DeepSeek火到没边了,自己也想尝试下用人工智能写代码事什么感觉,正好看到IT之家的以下两篇新闻,顺便免体验一把
- 国家超算互联网平台宣布免费开放 3 个月 DeepSeek API 接口
- 国家超算互联网平台宣布上线 DeepSeek-R1-Distill-Qwen-7B / 14B API 接口服务,免费提供 100 万 Tokens
Java开发中使用开发工具Idea,下面介绍下Idea集成DeepSeek的步骤
环境
操作系统:win11企业版
Idea版本:2024.3.1.1(Build #IU-243.22562.218, built on December 18, 2024)
DeepSeek:DeepSeek-R1-Distill-Qwen-32B
步骤
一、申请并生成DeepSeek的token
想要白嫖token,推荐硅基流动注册,(国家超算平台三天两头出问题)如下链接是硅基流动注册方案:
硅基流动:邀请注册即送2000万Tokens,畅享DeepSeek R1 671B满血版
也可以通过国家超算平台获取,目前都是免费的
1、登录国家超算平台,没有账号需要先注册

2、在超算互联网的应用商城首页中搜索“DeepSeek-R1”,点击“DeepSeek-R1 接口服务轻松使用 DeepSeek”商品,购买完成后,点击“去使用”。

3、一定找“接口服务”的去购买,我买的是这一款,现阶段基本都是免费的,根据需求选购即可
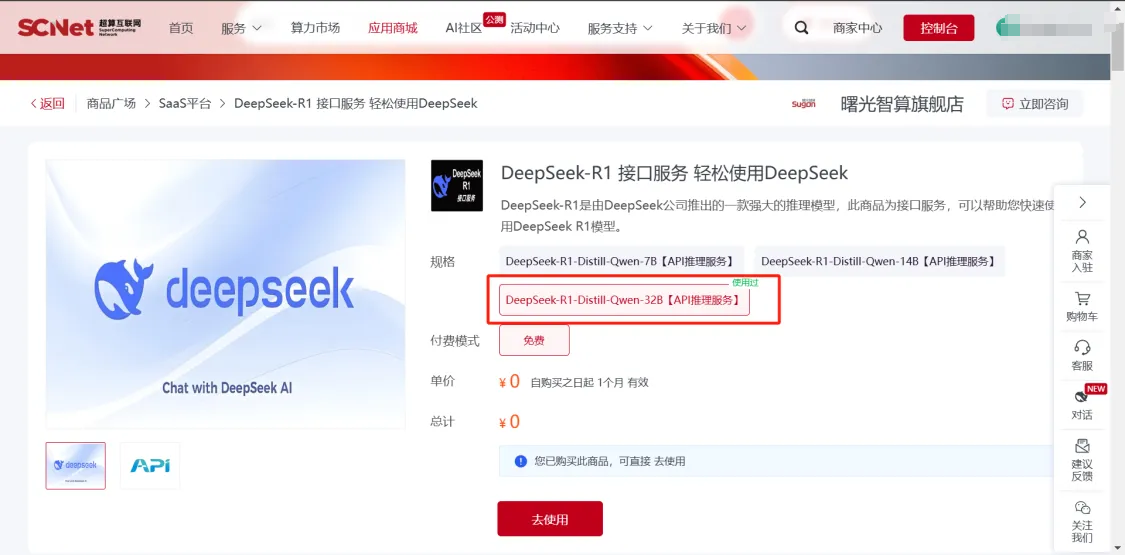
4、订单页面点击去使用
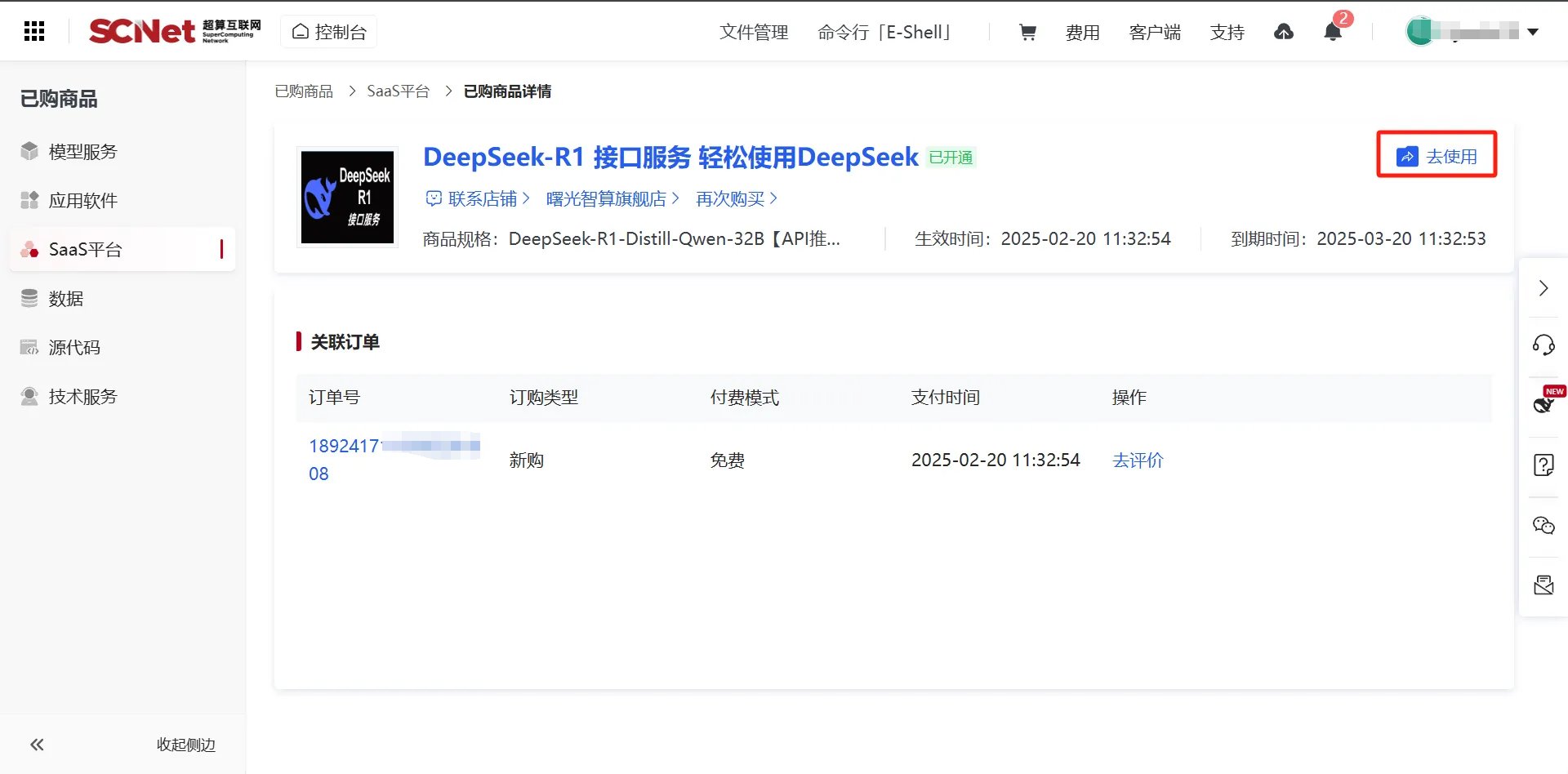
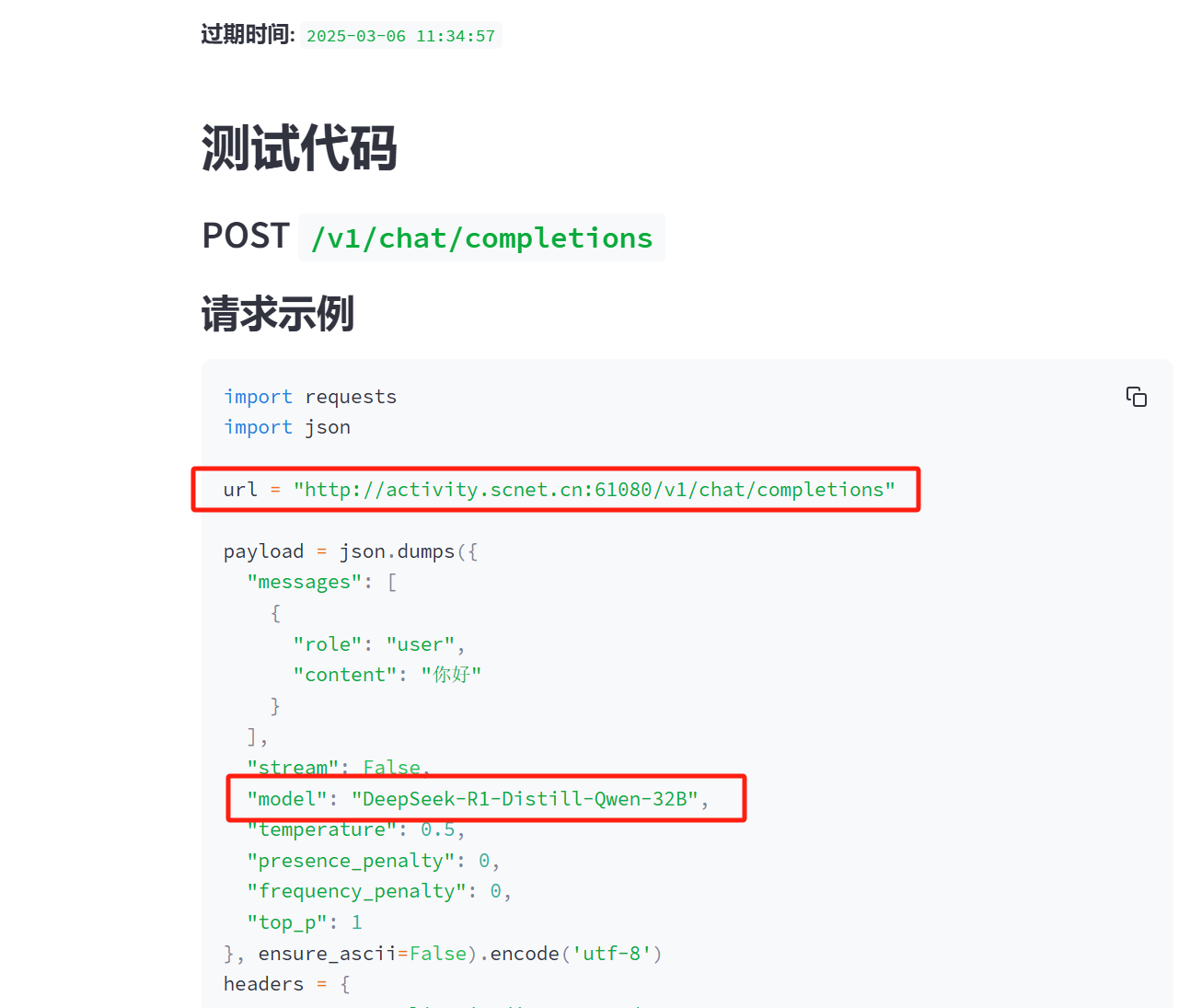
5、可以看到API接口信息,这个秘钥和请求示例后面要用到

二、安装 Python 环境(可以先跳过,我win11没装也照样能用)
DeepSeek 助手依赖 Python 环境来运行,需要提前在操作系统中安装 Python 3.7 及以上版本。安装完成后,务必将 Python 添加到系统环境变量中。这一步至关重要,它能确保系统在后续调用 Python 时能够准确找到其路径,避免因环境配置问题导致的集成失败。
Macbook:GithubCommitSpace Aion$ python --version
Python 3.12.8Macbook:GithubCommitSpace Aion$三、Idea上安装插件
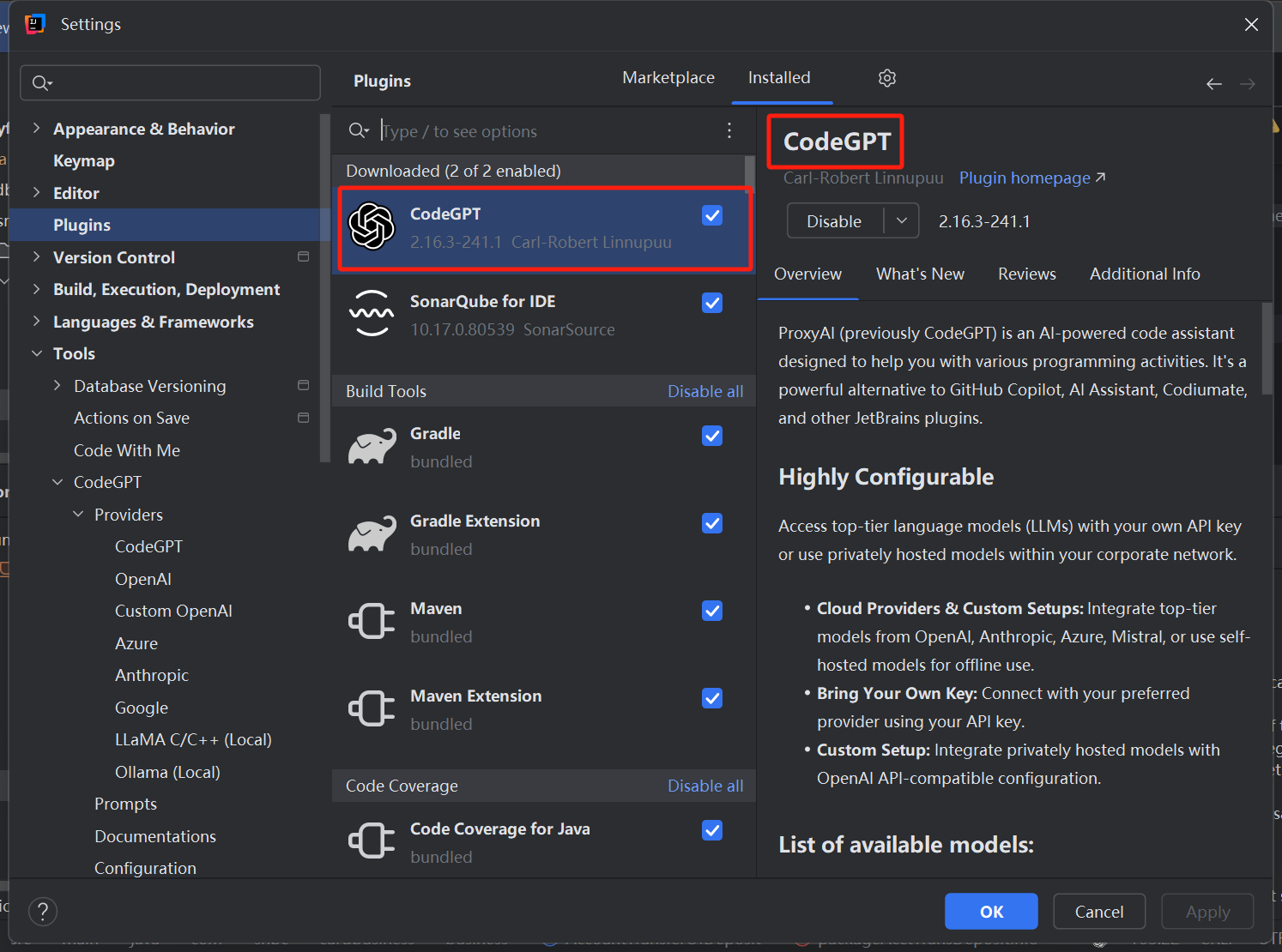
1、安装插件CodeGPT,新版叫ProxyAI,是一个东西
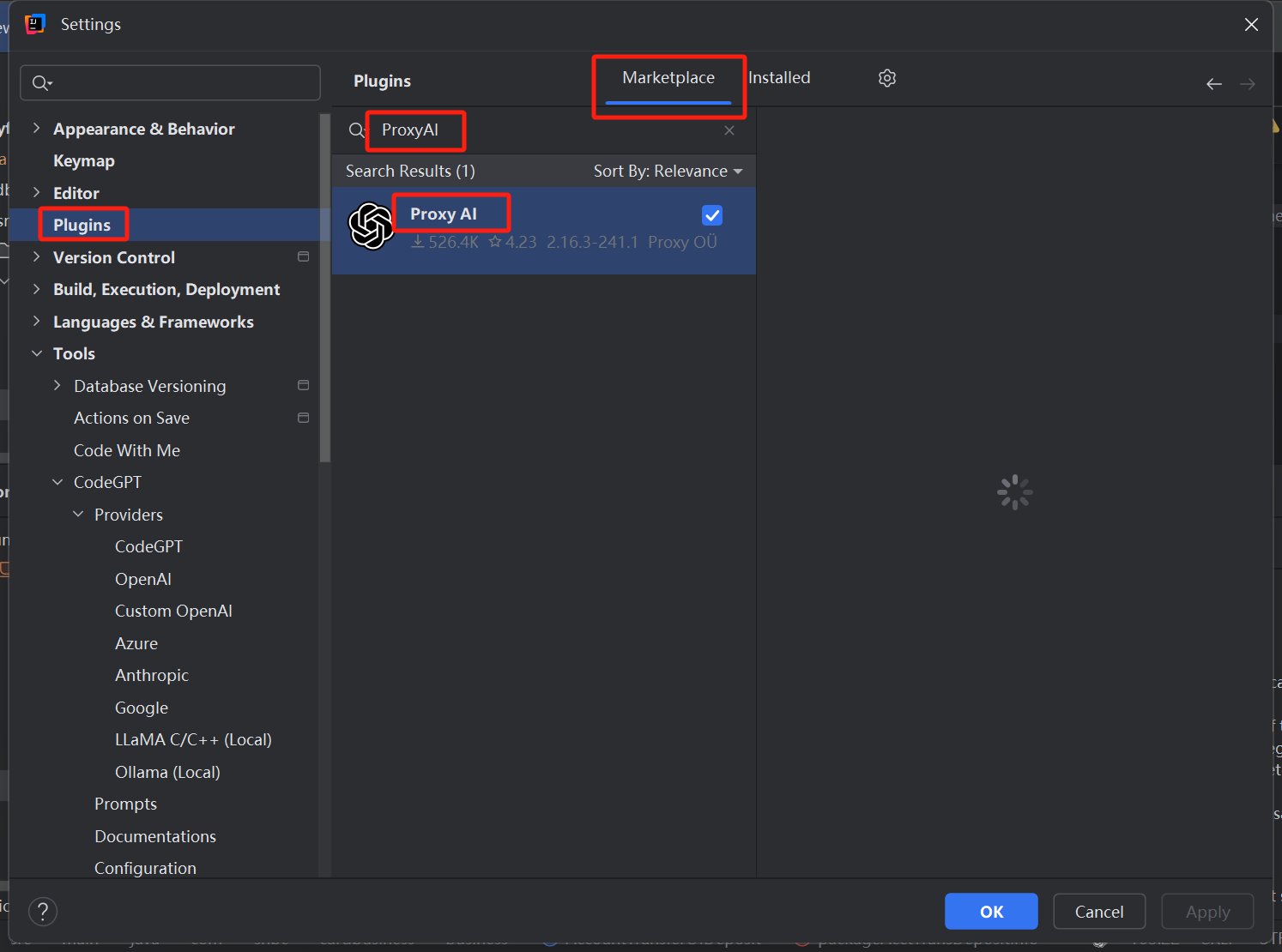
2、安装完还是变成了CodeGPT
四、IDEA中集成DeepSeek
1、重复上述的设置操作,在IDEA中找到已经安装的插件 CodeGpt 工具的设置,然后依次找到 Custom OpenAI 的设置。这里有三部分需要配置,第一个是选择模版,输入API KEY;第二个是配置聊天模型;第三个是配置推理模型。
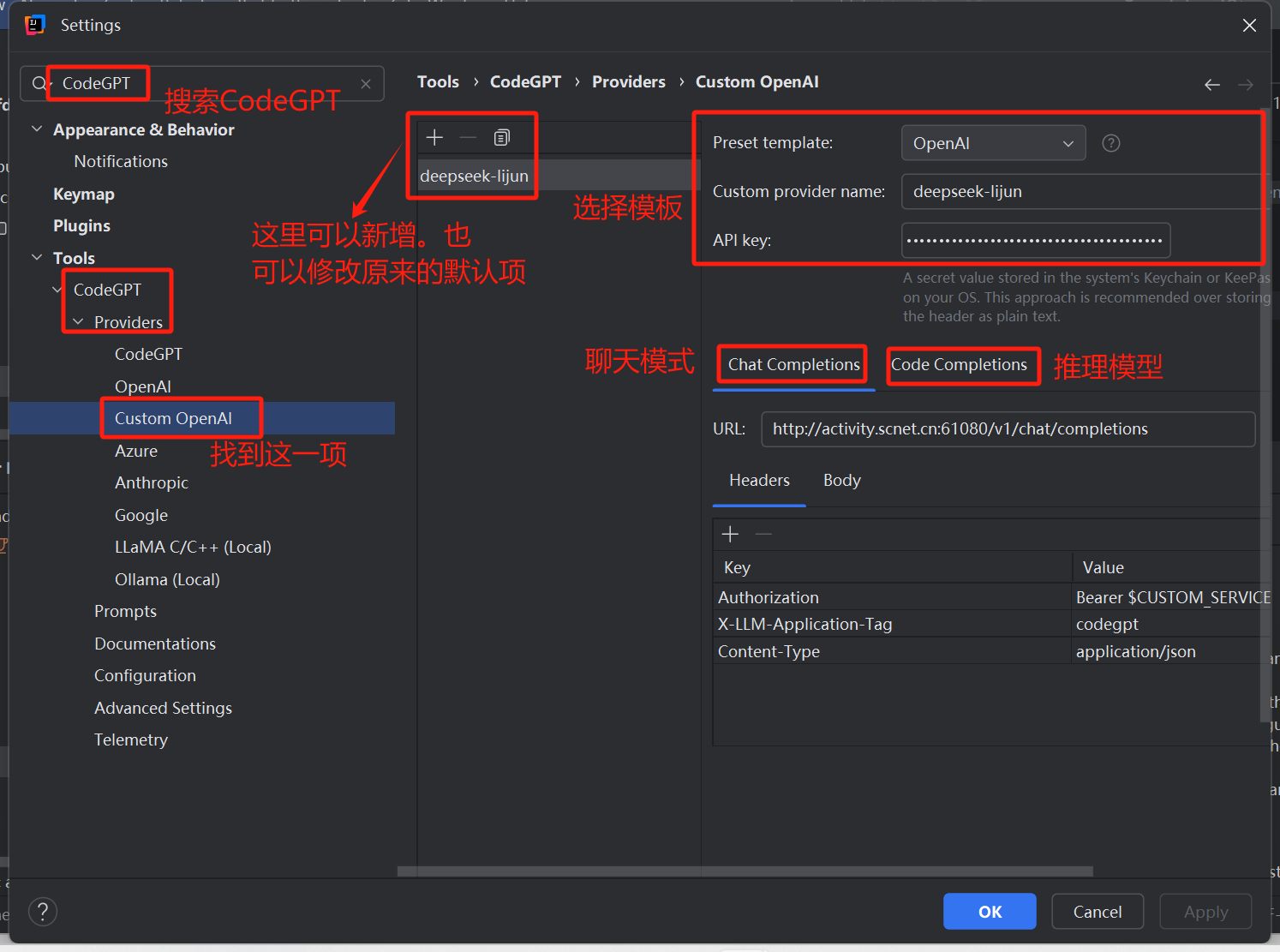
2、配置自己的DeepSeek
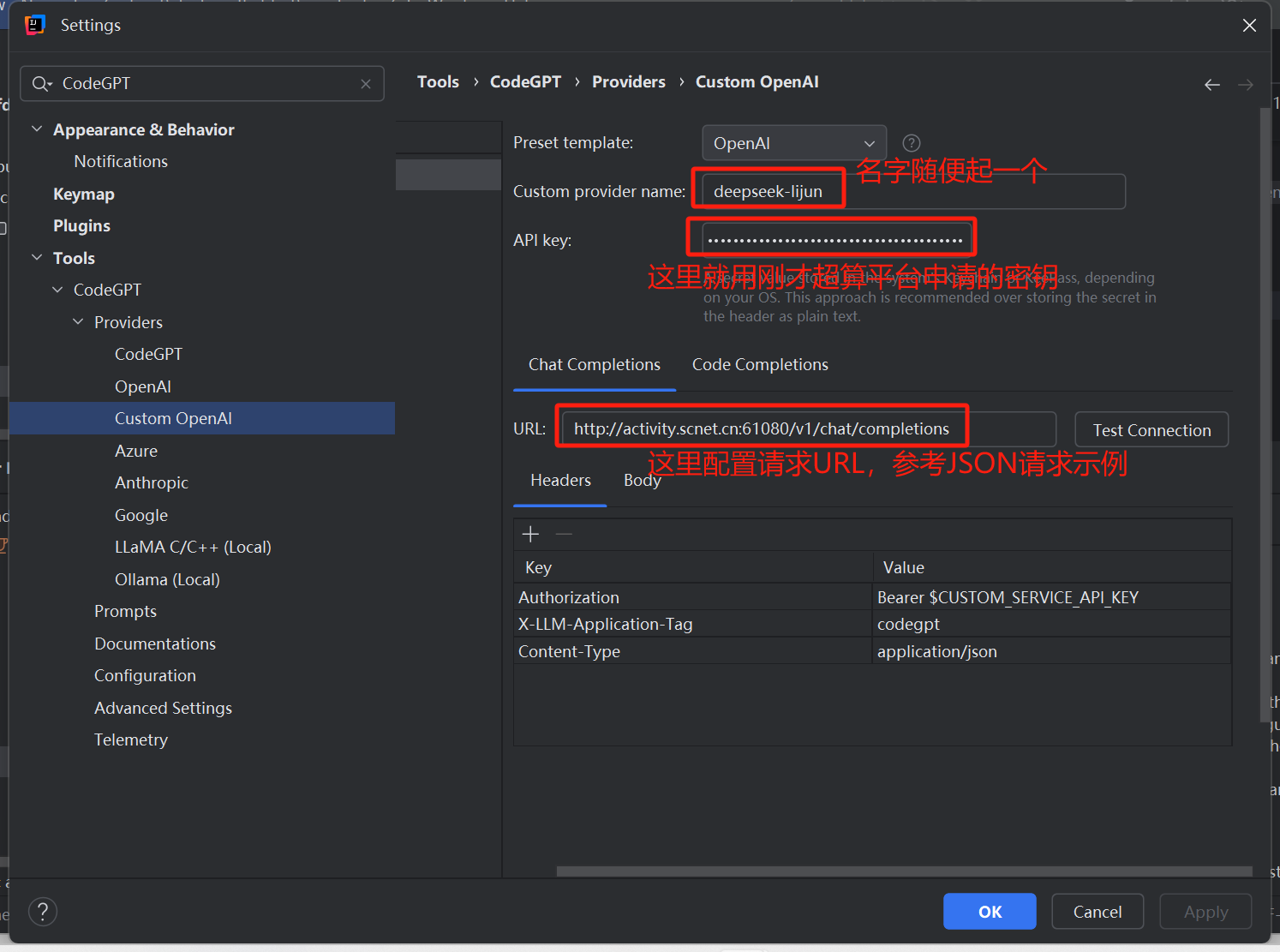
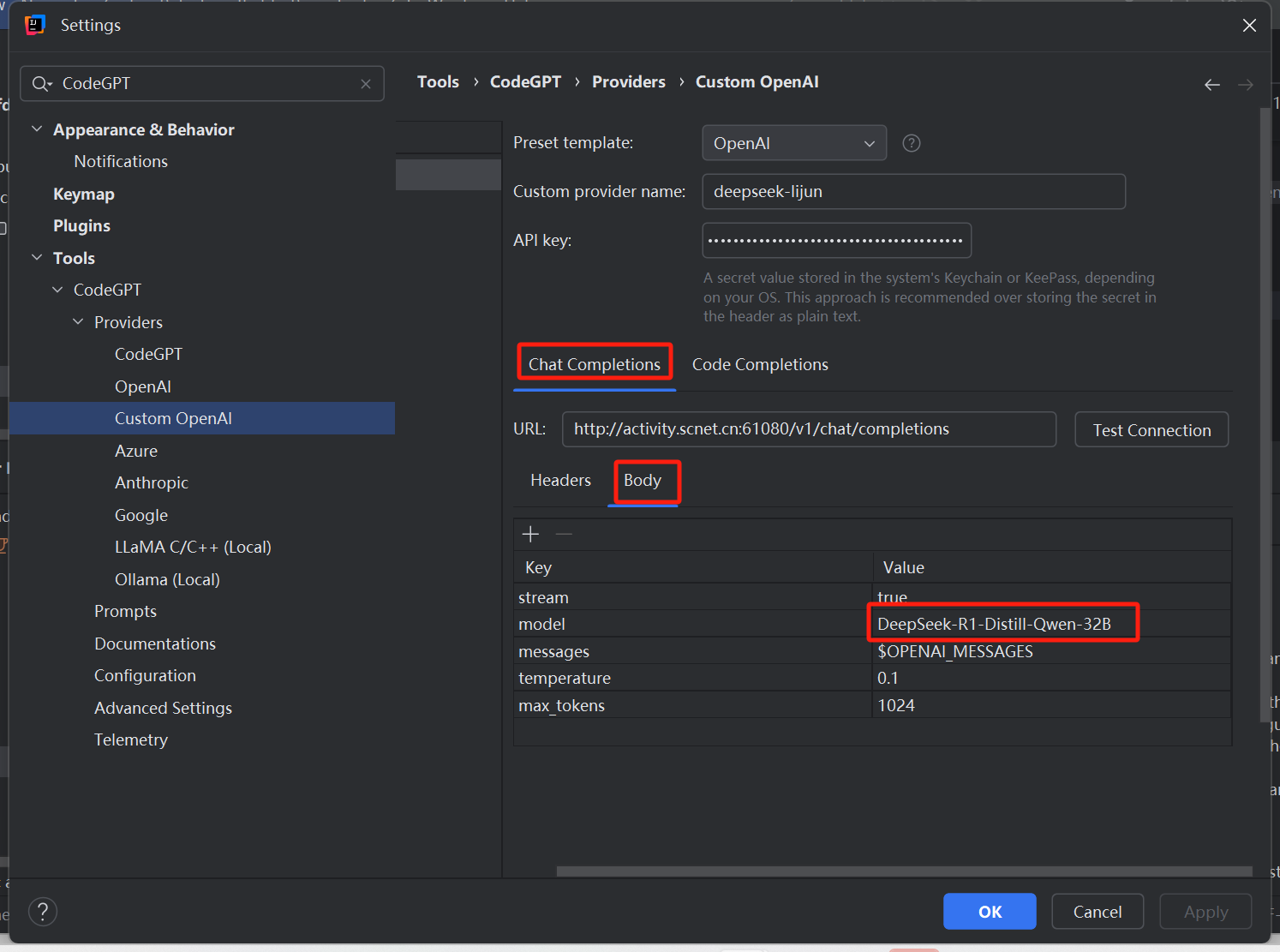
3、参考上面超算平台的请求示例,按照下图配置请求URL和请求体的model
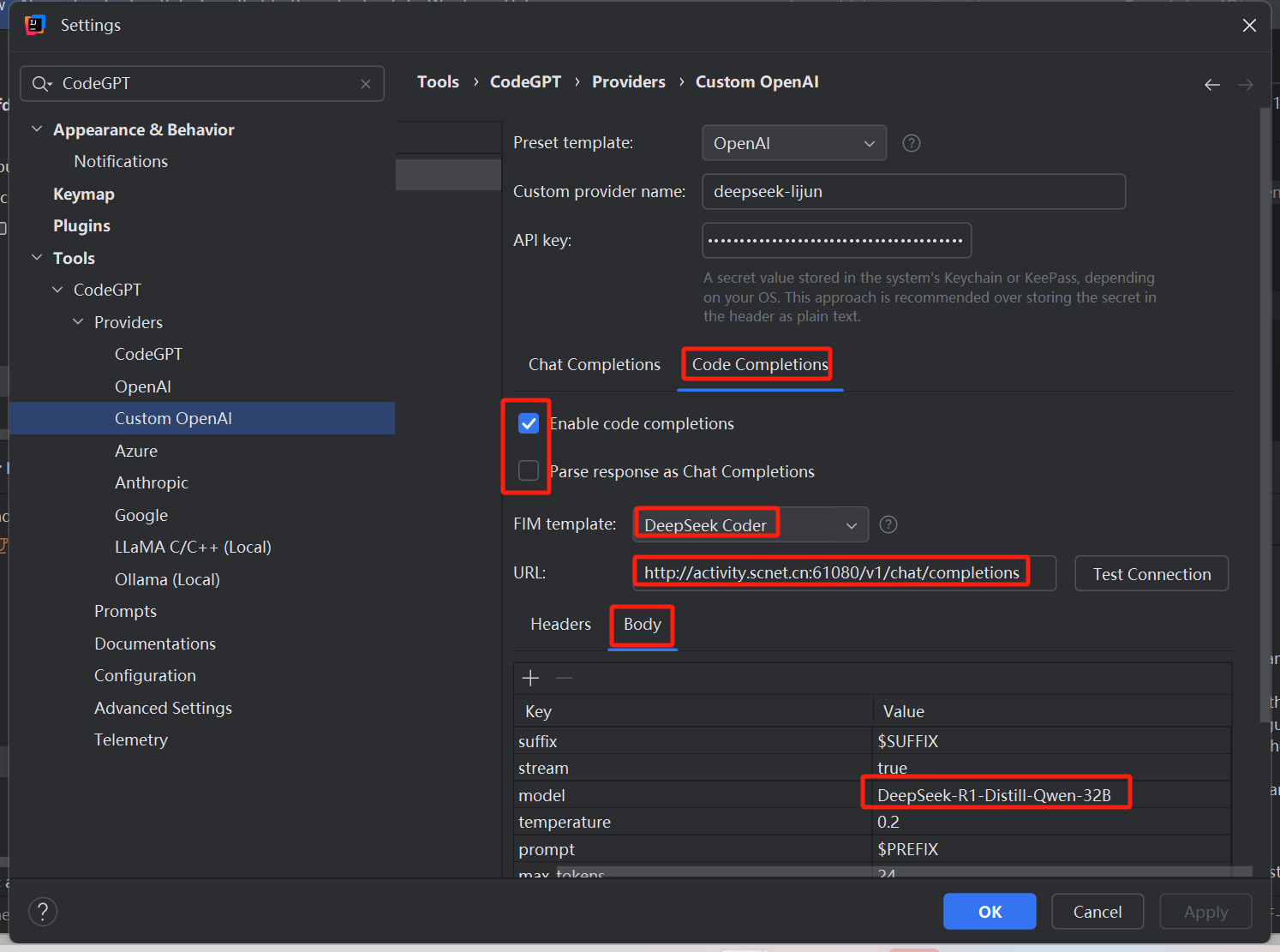
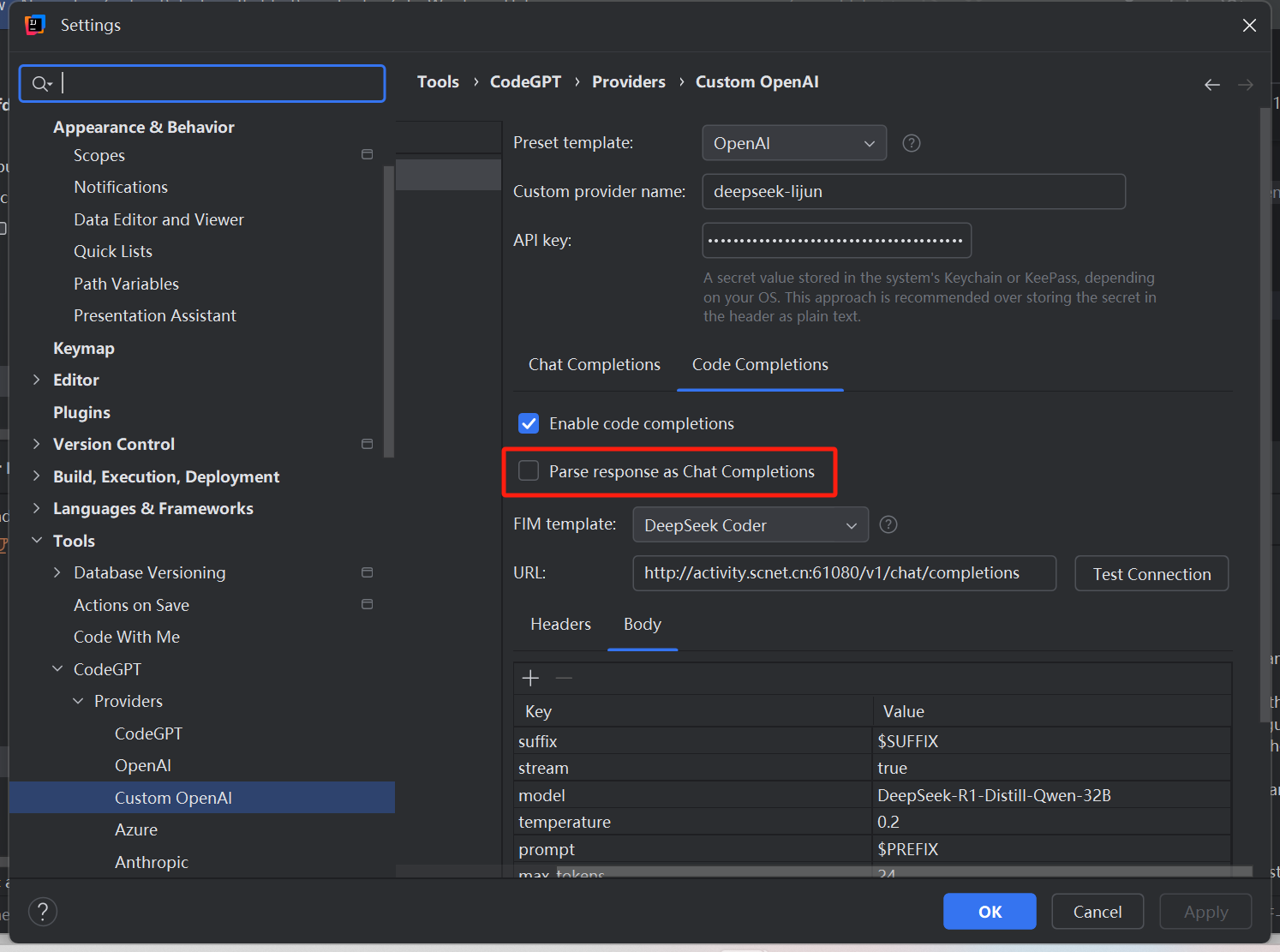
4、配置完成后点击Apply保存后即可使用,只不过下面这个选项配置存在争议,有人说选中,有人说不要选中,反正我选中不能正常运行,根据实际情况调整吧
“Parse response as Chat Completions”翻译为“将响应解析为聊天完成”
5、回到Idea项目上,右侧出现CodeGPT小图标,点击即可打开聊天界面,选择自己配置的DeepSeek即可开始使用
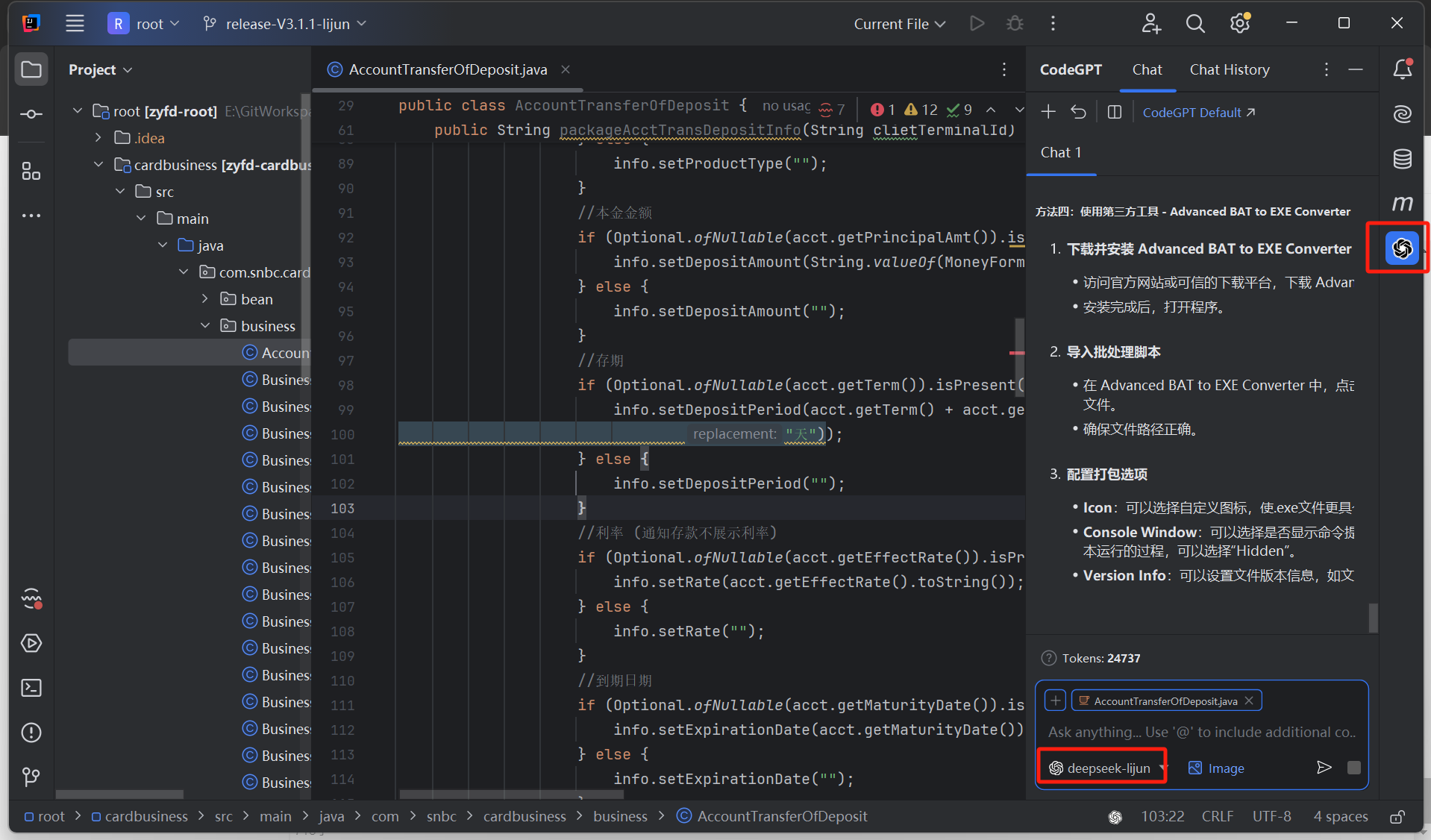
6、用起来还不错,tokens可以看到目前api接口的使用情况,也可以登录超算平台查看

五、插件模型请求参数解释
下面对一些模型参数做解释,可自行调节(我是除了改model其余全部保持默认)

使用硅基流动的DeepSeek API时,关注到接口文档有如下参数:
messages、stream、max_tokens、stop、temperature、top_p、top_k、n、response_format
DeepSeek对于参数详解与插件场景推荐
询问DeepSeek,“解释DeepSeek api的如下参数,当作为Idea开发工具的插件使用时,请推荐配置?”
以下是DeepSeek针对 DeepSeek API 核心参数的解释和 IntelliJ IDEA 插件场景的推荐配置方案:
| 参数 | 类型 | 作用 | IDEA 插件推荐配置 |
|
| Array | 对话上下文(多轮对话历史) | 保留最近3-5轮对话:<br> |
|
| Boolean | 是否启用流式传输(实时逐字返回) | 必须开启 ( )<br>实现代码补全/回答的实时显示,避免用户长时间等待 |
|
| Integer | 生成内容的最大 token 数(1 token≈1.5个汉字) |
<br>代码场景需完整输出,但避免过长响应阻塞 IDE(建议结合 参数控制) |
|
| Array | 停止生成的条件(遇到特定字符/字符串时终止) |
<br>在代码块结束符或语法终止符处停止,确保生成结构完整性 |
|
| Float | 生成随机性(0-2)<br>值越大结果越多样但可能偏离预期 | 代码场景: <br>平衡准确性与创造性<br>(文档问答可提升至 ) |
|
| Float | 核采样阈值(0-1)<br>控制候选 token 的筛选范围 |
<br>过滤低概率 token,保持代码合理性同时避免过于保守 |
|
| Integer | 候选 token 数量限制<br>(仅从概率最高的k个token中选择) |
<br>适用于需要较强创造性的场景(如代码生成) |
|
| Integer | 生成多个独立结果 | 保持 <br>IDE 插件通常只需单结果,多结果会占用屏幕空间且增加计算开销 |
|
| Object | 响应格式控制(如强制 JSON 格式) |
<br>或保持默认(DeepSeek 若支持代码块标记可优先使用) |
DeepSeek对于关键场景优化建议
- 代码补全
- 降低
temperature(0.3-0.5) - 缩短
max_tokens(300-500) - 设置
stop: ["\n"](补全单行代码)
- 代码重构建议
- 提升
temperature(0.6-0.8) - 增加
max_tokens(800-1200) - 设置
stop: ["\n```"](确保完整代码块)
- 文档问答
- 使用更高
temperature(0.7-1.0) - 关闭
stop或设置自然终止符(如["\n\n"])
参考资料: