今天我要给大家分享的是如何爬取豆瓣上深圳近期即将上映的电影影讯,并分别用普通的单线程、多线程和协程来爬取,从而对比单线程、多线程和协程在网络爬虫中的性能。
具体要爬的网址是:https://movie.douban.com/cinema/later/shenzhen/
除了要爬入口页以外还需爬取每个电影的详情页,具体要爬取的结构信息如下:
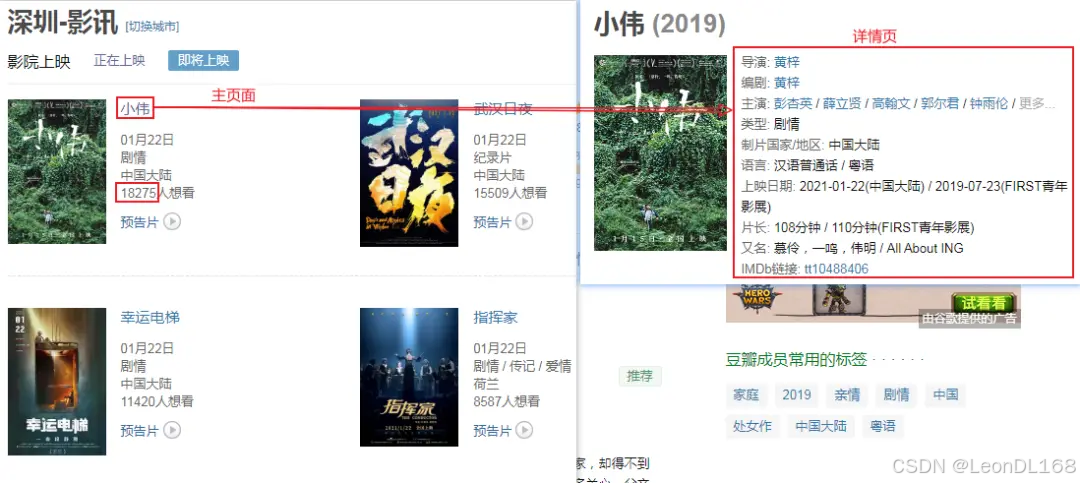
爬取测试
下面我演示使用xpath解析数据。
入口页数据读取:
import requests
from lxml import etree
import pandas as pd
import re
main_url = "https://movie.douban.com/cinema/later/shenzhen/"
headers = {
"Accept-Encoding": "Gzip",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
r = requests