目录
一. 知识图谱的介绍
详情请参考 知乎专栏
1. 知识库与三元组
“奥巴马出生在火奴鲁鲁。”, “姚明是中国人。”,“谢霆锋的爸爸是谢贤。”
这些就是一条条知识,而把大量的知识汇聚起来就成为了知识库。我们可以在wiki百科,百度百科等百科全书查阅到大量的知识。然而,这些百科全书的知识组建形式是非结构化的自然语言,这样的组织方式很适合人们阅读但并不适合计算机去处理。为了方便计算机的处理和理解,我们需要更加形式化、简洁化的方式去表示知识,那就是三元组(triple)。
“奥巴马出生在火奴鲁鲁。” 可以用三元组表示为 (BarackObama, PlaceOfBirth, Honolulu)。
这里我们可以简单的把三元组理解为 (实体entity,实体关系relation,实体entity),进一步的,如果我们把实体看作是结点,把实体关系(包括属性,类别等等)看作是一条边,那么包含了大量三元组的知识库就成为了一个庞大的知识图。
Extracted KBs 知识库涉及到的两大关键技术是
- 实体链指(Entity linking) ,即将文档中的实体名字链接到知识库中特定的实体上。它主要涉及自然语言处理领域的两个经典问题实体识别 (Entity Recognition) 与实体消歧 (Entity Disambiguation),简单地来说,就是要从文档中识别出人名、地名、机构名、电影等命名实体。并且,在不同环境下同一实体名称可能存在歧义,如苹果,我们需要根据上下文环境进行消歧。
- 关系抽取 (Relation extraction),即将文档中的实体关系抽取出来,主要涉及到的技术有词性标注 (Part-of-Speech tagging, POS),语法分析,依存关系树 (dependency tree) 以及构建SVM、最大熵模型等分类器进行关系分类等。
2. 知识库问答
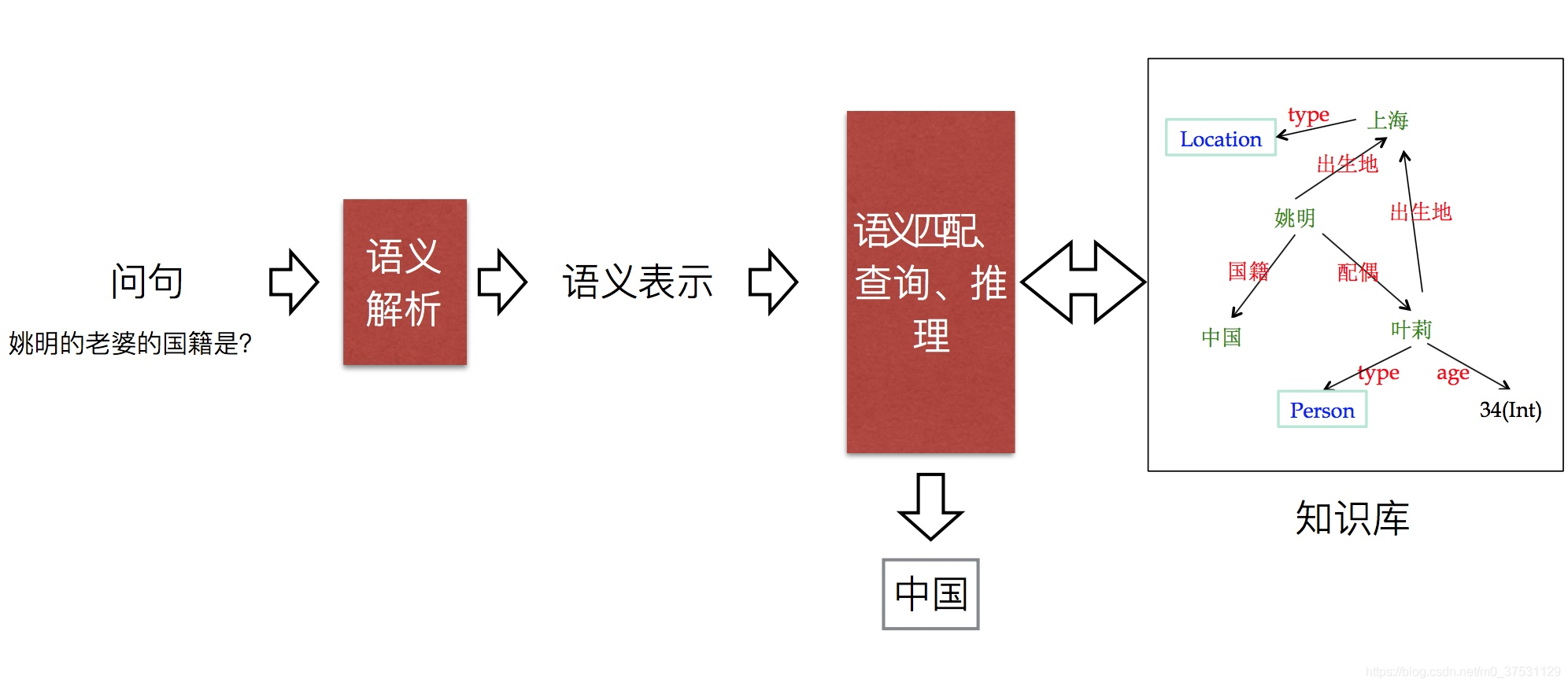
知识库问答(knowledge base question answering,KB-QA)即给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案.
与对话系统、对话机器人的交互式对话不同,KB-QA具有以下特点:
- 答案:回答的答案是知识库中的实体或实体关系,或者no-answer(即该问题在KB中找不到答案),当然这里答案不一定唯一,比如 中国的城市有哪些 。而对话系统则回复的是自然语言句子,有时甚至需要考虑上下文语境。
- 评价标准:回召率 (Recall),精确率 (Precision) ,F1-Score。而对话系统的评价标准以人工评价为主,以及BLEU和Perplexity。
当我们在百度询问 2016年奥斯卡最佳男主角 时,百度会根据知识库进行查询和推理,返回答案,这其实就是KB-QA的一个应用。
3. 知识库问答的主流方法
关于KB-QA的方法,传统的主流方法可以分为三类:
- 语义解析(Semantic Parsing):该方法是一种偏linguistic的方法,主体思想是将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句(类似lambda-Caculus)在知识库中进行查询,从而得出答案。下图红色部分即逻辑形式,绿色部分where was Obama born 为自然语言问题,蓝色部分为语义解析进行的相关操作,而形成的语义解析树的根节点则是最终的语义解析结果,可以通过查询语句直接在知识库中查询最终答案。
- 信息抽取(Information Extraction):该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。信息抽取的代表论文Yao X, Van Durme B. Information Extraction over Structured Data: Question Answering with Freebase[C]//ACL (1). 2014: 956-966.
- 向量建模(Vector Modeling): 该方法思想和信息抽取的思想比较接近,根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高,如下图所示。模型训练完成后则可根据候选答案的向量表达和问题表达的得分进行筛选,得出最终答案。
4. 基于深度学习的KQ问答
随着深度学习(Deep Learning)在⾃然语⾔处理领域的⻜速发展,从15年开始,开始涌现出⼀系列基 于深度学习的KB-QA⽂章,通过深度学习对传统的⽅法进⾏提升,取得了较好的效果。
使⽤卷积神经⽹络对向量建模⽅法进⾏提升,使⽤卷积神经⽹络对语义解析⽅法进⾏提升,使⽤⻓短时记忆⽹络(LSTM),卷积神经⽹络共同进⾏实体关系分类,使⽤记忆⽹络(Memory Networks),注意⼒机制(Attention Mechanism)进⾏KB-QA。
直到2018年底,BERT对NLP的巨⼤突破,使得⽤BERT进⾏KB-QA也取得了较好的效果。本项⽬基于BERT模型实现。
二. 本项目介绍
本项目的主要目标是,构建一个知识库问答系统,从用户所提出的问题,对知识库进行检索,返回一个确定的答案,如果没有答案的 返回 无答案。
1. 项目数据集
NLPCC全称⾃然语⾔处理与中⽂计算会议(The Conference on Natural Language Processing and Chinese Computing),它是由中国计算机学会(CCF)主办的 CCF 中⽂信息技术专业委员会年度学术会议,专注于⾃然语⾔处理及中⽂计算领域的学术和应⽤创新。
本项目的数据集采用的是NLPCC2017的Task5:Open Domain Question Answering;其包含 14,609 个问答对的训练集和包含 9870 个问答对的测试集。并提供一个知识库,包含 6,502,738 个实体、 587,875 个属性以及 43,063,796 个三元组。
NLPCC2017_task5
数据集格式如下:
2. 处理数据集
请参考文件 preProcessData/createTrainingData.py
里面包含2 步, 1) 构建命名实体识别数据集, 2) 构建相似度训练数据集
2.1 构造命名实体识别数据集
构造命名实体识别NER数据集, 需要根据三元组-Enitity反向标注问题,给Question 打标签, 这里只需要识别实体,使用[’“O”, “B-LOC”, “I-LOC”]来做标记,其中O 表示其他非实体,B-LOC 实体开始,I-LOC 实体 非首字母。
生成结果放到 NERData 文件夹下面, 点开 train.txt 可以看到NERdata 结构如下:

2.2 构造知识库数据集
构造知识库,主要提取原始数据集中的 作为知识库,传进database 里面,用于当检索。
2.3 构建属性相似的数据
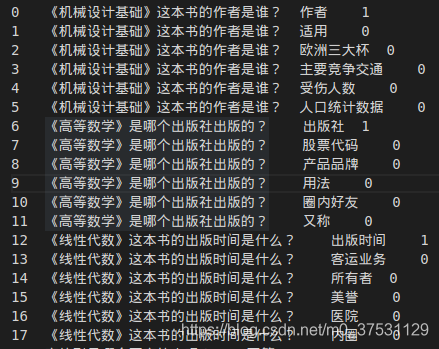
构造正负样本,用于问题和属性相似度的训练。当用户输入问题时,第一个通过命名实体识别提取出实体, 进行数据库查询,有可能得到多条信息,因为一个实体会对应很多属性。 此时通过问题和属性相似度训练模型进行属性选择,选择一个与用户输入问题 最相近的属性,将答案返回。
构造的数据集如下: 一个正样本,五个负样本。
其中问题和属性 作为 seq1 和 seq2 输入BertForSequenceClassification 进行训练。
4. 构建数据库数据
Ubuntu mysql 安装 请参考 链接: Ubuntu mysql 安装
使用请参考 Ubuntu mysql使用方法
python 操作mysqlubuntu python mysql
5. 模型构建
5.1 BertCRF
本项目用的是 hunggingface的Transformers版本的BERT .
思路:
- BertModel得到output 即最后一层的hidden_state(shape: batch_size, seq_len, hidden_size)
- 通过线性变换,将hidden_state 由 hidden_size 转成 num_labels, 此处num_labels = 3 即命名实体识别的3种类型[‘O’, ‘B-LOC’. ‘I-LOC’]. 此时输出shape (batch_size, seq_len, num_label), 我们将这里的输出作为CRF的输入.
- 将上一步的输出,作为CRF的输入.
transformers 自带的BertForTokenClassification 正好满足第一步和第二步的需求. 因为这里我们只需要获取输出的hidden,不需要计算损失,所以BERT的输入中不需要输入target label, 当没有label输入时, BertForTokenClassification的输出 第一项就是我们想要的结果 emission(batch_size, seq_len, num_labels=3). 请见代码:
emissions = self.bertModel(input_ids = input_ids,attention_mask = attention_mask, token_type_ids=token_type_ids)[0]
5.2 BertForSequenceClassification
该模型是用来从问题中提取属性的。
当一个问题来的时候,我们第一步通过命名实体识别提取实体名,第二步要确认问题的属性。关于属性的确认就是通过分类模型来得到。
该模式输入是序列如下:[CLS] 问题 [SEP] 属性[SEP].
数据集就是上面构造的similarity 数据集,每一个正样本,对应有五个负样本。
通过二分类模型,进行 ‘问题’ 和 ‘属性’ 的相似度训练。
这里采用的是transformers 自带的BertForSequenceClassification. 这是一个在BERT基础上 添加一个序列分类 用于微调的模型。 大题步骤: 1. BertModel得到output 即最后一层的hidden_state(shape: batch_size, seq_len, hidden_size),取最后一层hidden_state的第一个token用于分类(batch_size, hidden_size) 2. 通过线性变换,将分类token 由 hidden_size 转成 num_labels, 此处num_labels = 2 即正负样本(0,1),与真实label计算交叉熵损失。
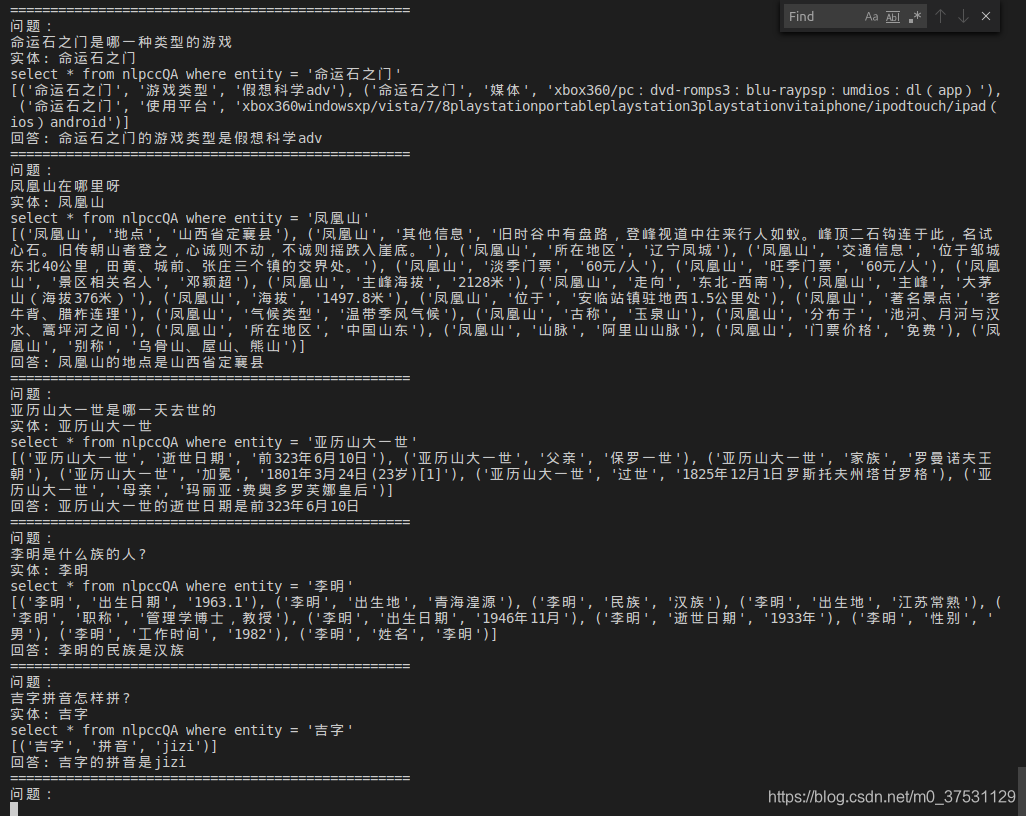
6. 模型运行效果
参考:
基于知识图谱的问答系统入门—NLPCC2016KBQA数据集
知乎专栏
问答QA(二)基于BERT的知识库问答实战
基于BERT模型的知识库问答(KBQA)系统