目录
一、Flink简介
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink 提供了数据分发以及并行化计算的能力,并且可以部署在各种集群环境中,如Hadoop YARN、Kubernetes或独立集群。
2.1 Flink 架构
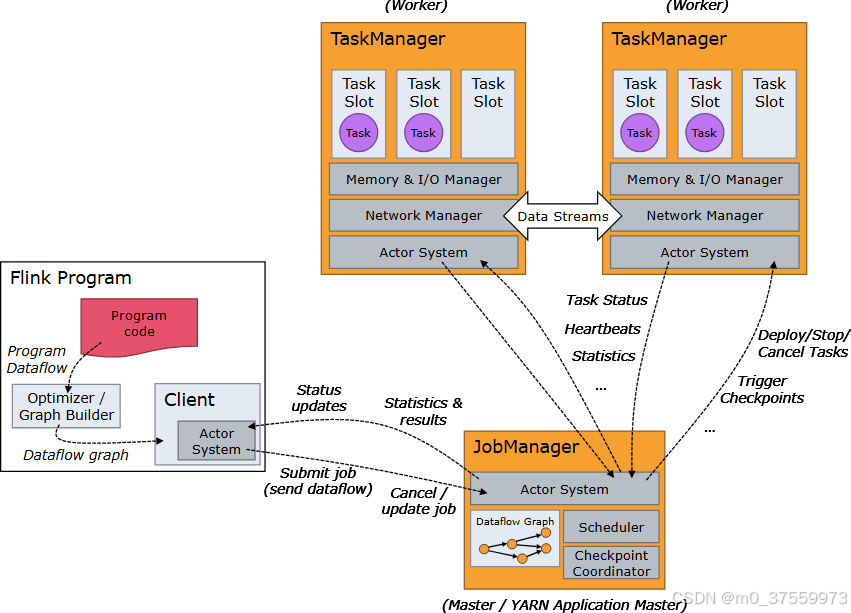
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。
JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。这个进程由三个不同的组件组成:
- ResourceManager:负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位(请参考TaskManagers)。Flink 为不同的环境和资源提供者(例如 YARN、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
- Dispatcher:提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster:负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby。
TaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流。
必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。一个 task slot 中可以执行多个算子。
2.2 Flink 应用程序 运行模式
当Flink应用程序编写好后,可以通过会话模式、单作业模式和应用模式等三种方式运行:
- 会话模式(Session Mode)
会话模式需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
- 单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,可以为每个提交的作业启动一个集群,作业完成后,集群就会关闭,释放资源,这就是所谓的单作业(Per-Job)模式。单作业模式运行稳定,是实际应用的首选模式。
需要注意的是,Flink本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如YARN、Kubernetes(K8s)。
- 应用模式(Application Mode)
会话模式和单作业模式应用代码都是在客户端上执行,然后由客户端提交给JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到JobManger上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个JobManager只为执行这一个应用而存在,执行结束之后JobManager也就关闭了,这就是所谓的应用模式。
应用程序各种运行模式,需要的Flink集群不一样,本地集群和Standalone集群适合会话模式;YARN模式适合单作业模式和应用模式;K8S模式不熟悉,暂时不介绍。
| 应用程序运行模式 | 会话模式 (Session Mode) | 单作业模式 (Per-Job Mode) | 应用模式 (Application Mode) | |
| 集群部署模式 | ||||
| 本地模式 | √ | × | √ | |
| Standalone模式 | √ | × | √ | |
| YARN模式 | √ | √ | √ | |
| K8S模式 | ||||
二、Flink 集群 部署
2.1 本地集群模式
2.1.1 安装JDK
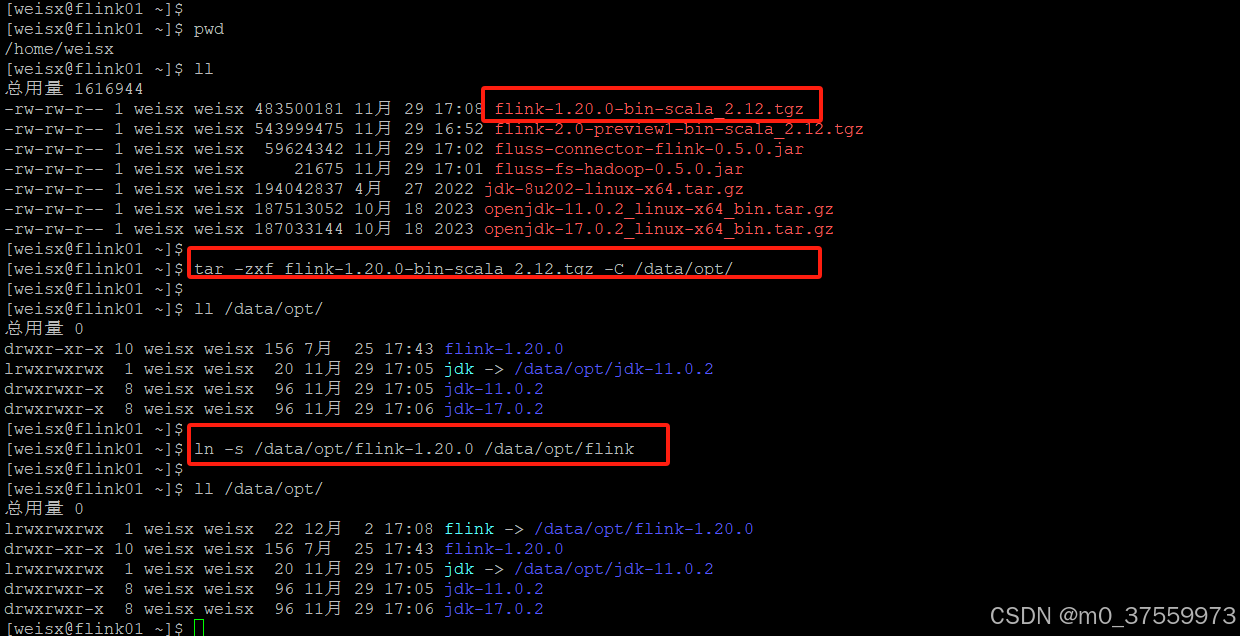
2.1.2 下载、解压 Flink
2.1.3 启动集群
$ ./bin/start-cluster.sh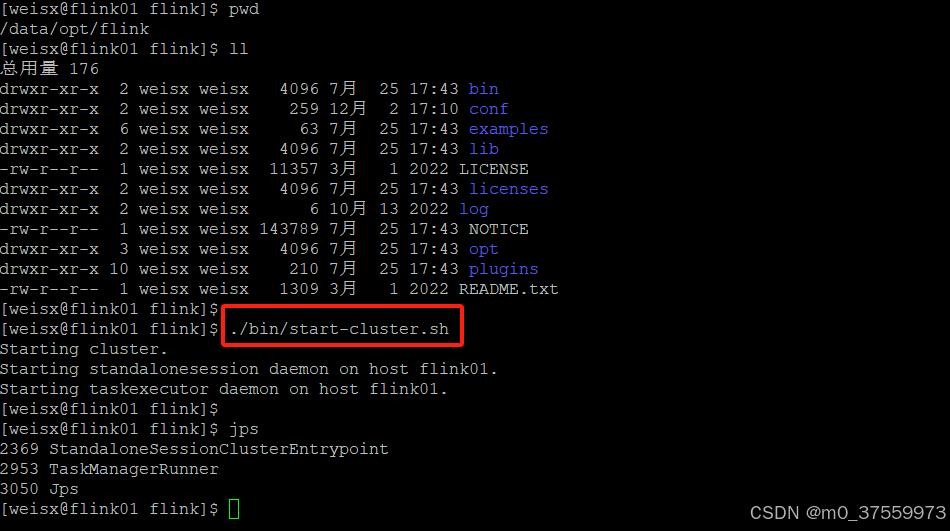
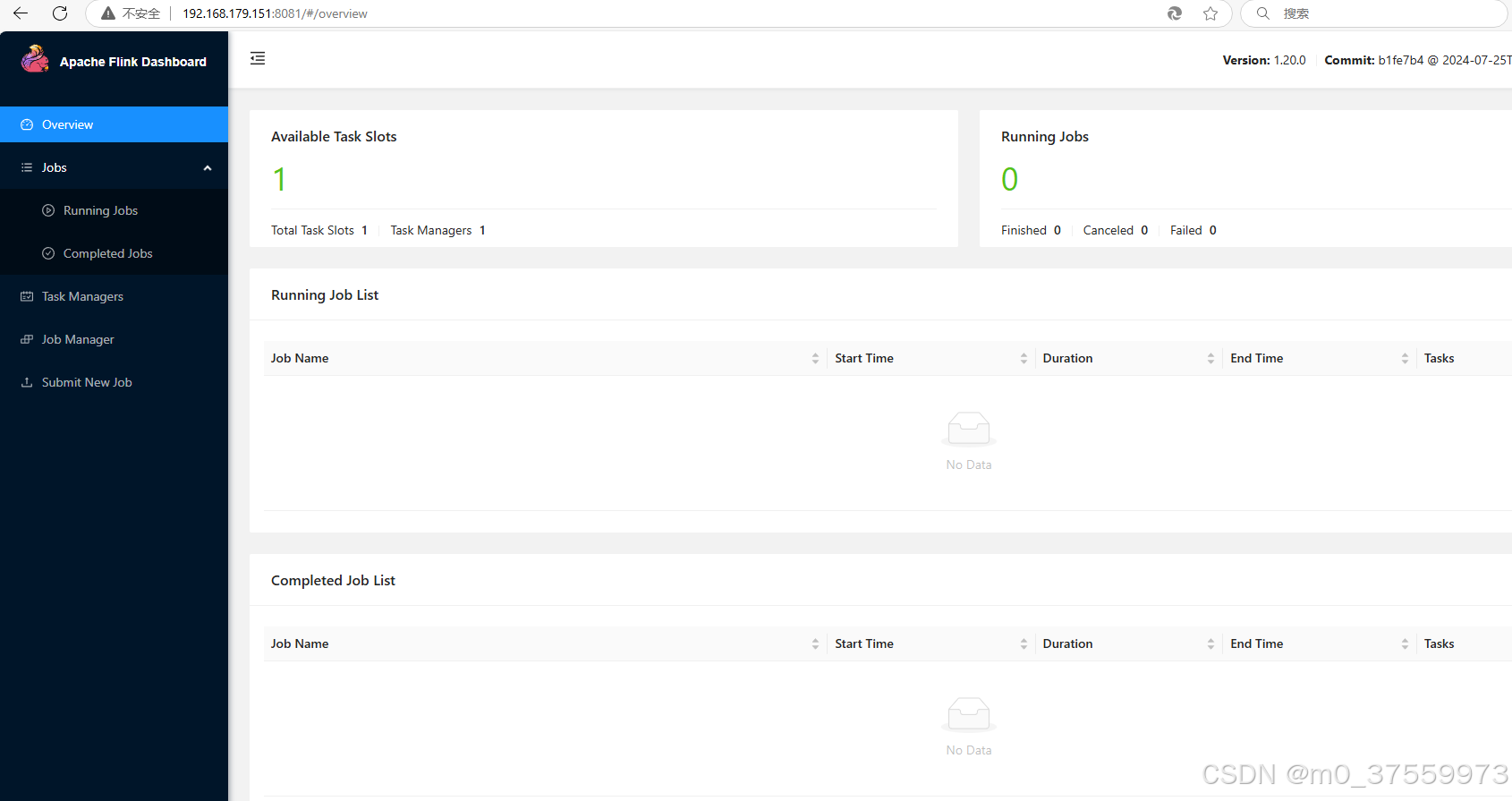
2.1.4 停止集群
$ ./bin/stop-cluster.sh2.2 Standalone 模式
2.2.0 集群规划
| flink01 192.168.179.151 | flink02 192.168.179.152 | flink01 192.168.179.153 |
| JobManager | ||
| TaskManager | TaskManager | TaskManager |
2.2.1 安装JDK
在所有部署Flink的服务器上安装jkd,要求jdk17+,jdk具体安装可参考搭建环境02:安装前准备(配置CentOS7) 中的安装jdk部分。
2.2.2 设置免密登录
在所有部署Flink的服务器上设置免密登录,具体操作可参考搭建环境02:安装前准备(配置CentOS7) 中的设置免密登录部分。
2.2.3 修改配置文件
- config.yaml 文件
vi conf/config.yaml
jobmanager:
bind-host: 0.0.0.0
rpc:
address: 192.168.179.151 #修改成本节点IPtaskmanager:
bind-host: 0.0.0.0
host: 192.168.179.151 #修改成本节点IPrest:
address: 192.168.179.151 #修改成本节点IP
bind-address: 0.0.0.0
port: 8081
- masters文件
vi conf/masters
192.168.179.151:8081
- workers文件
vi conf/workers
192.168.179.151
192.168.179.152
192.168.179.153
2.2.4 启动集群
$ ./bin/start-cluster.sh
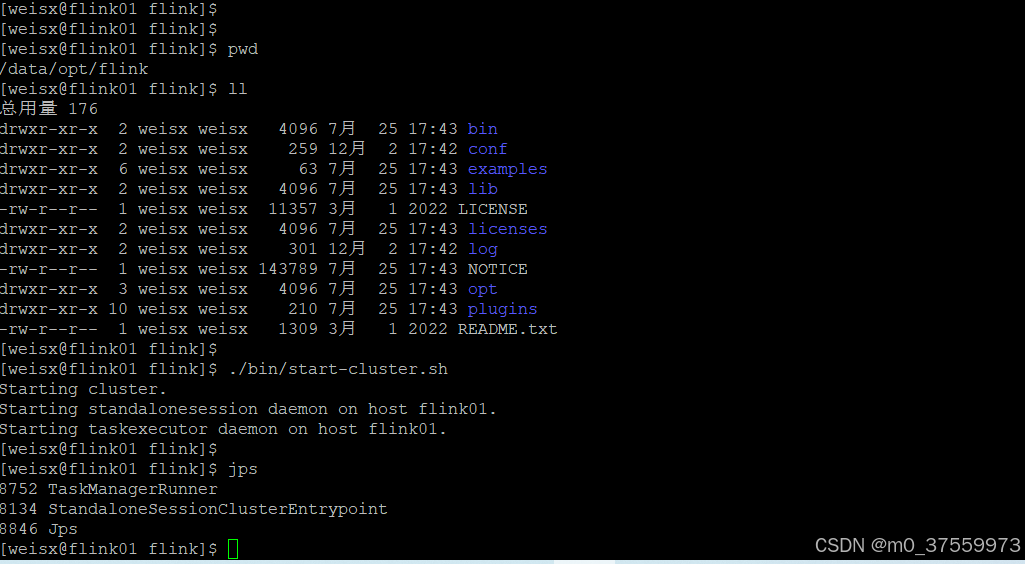
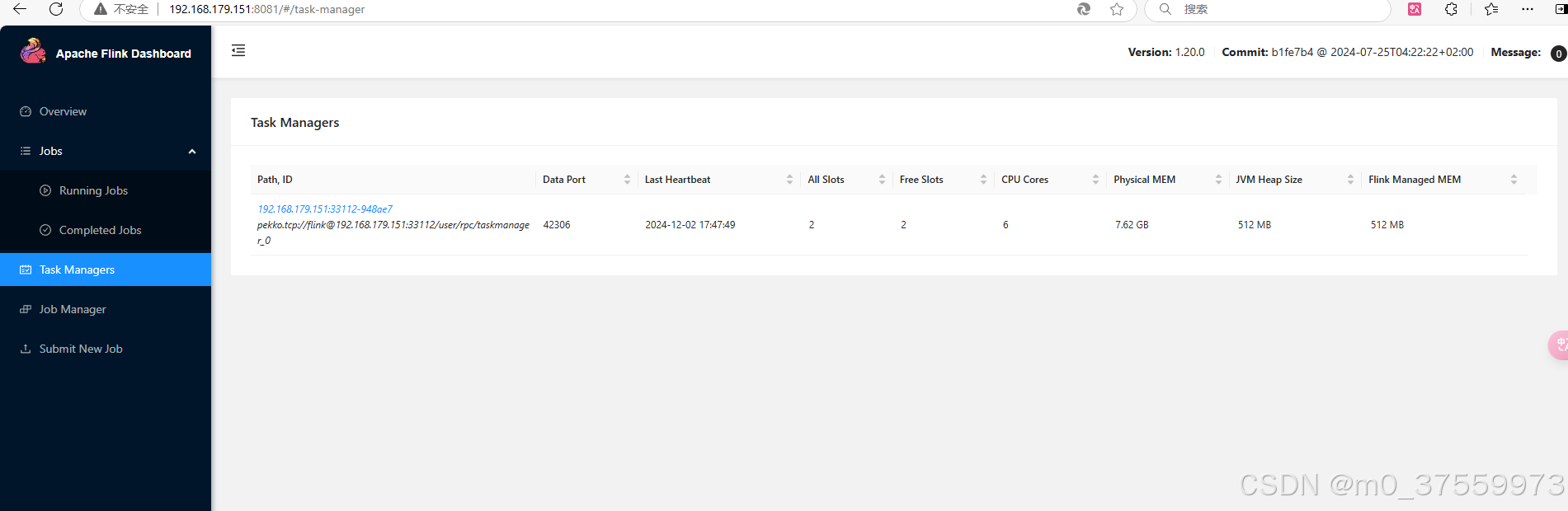
2.2.5 关闭集群
./bin/stop-cluster.sh
2.2.6 Standalone 高可用服务
具体可参考官方文档。
2.3 YARN 模式
比较复杂,另开一篇专门介绍。
2.4 K8S 模式
不熟悉,暂时不做介绍。
三、Flink 应用 开发
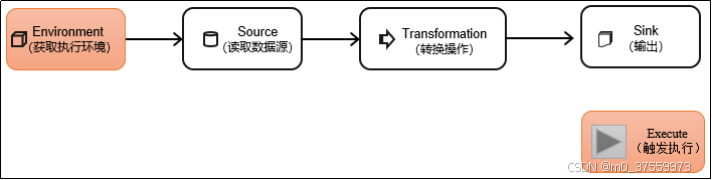
Flink 程序看起来像一个转换 DataStream 的常规程序。每个程序由相同的基本部分组成:
- 获取一个执行环境(execution environment);
- 加载/创建初始数据;
- 指定数据相关的转换;
- 指定计算结果的存储位置;
- 触发程序执行。
3.1 编写Flink 应用程序
3.1.1 maven引入jar
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.20.0</version>
</dependency>
3.1.2 编写代码
package com.yichenkeji.demo.flink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo {
public static void main(String[] args) throws Exception {
//1.获取一个执行环境(execution environment)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.加载/创建初始数据
DataStreamSource<Integer> source = env.fromCollection(Arrays.asList(1,2,3,4,5,6,7,8,9,10));
//3.指定数据相关的转换:乘以2
SingleOutputStreamOperator<Integer> map = source.map(x -> x * 2);
//4.指定计算结果的存储位置:直接输出到控制台
map.print();
//5.触发执行
env.execute();
}
}
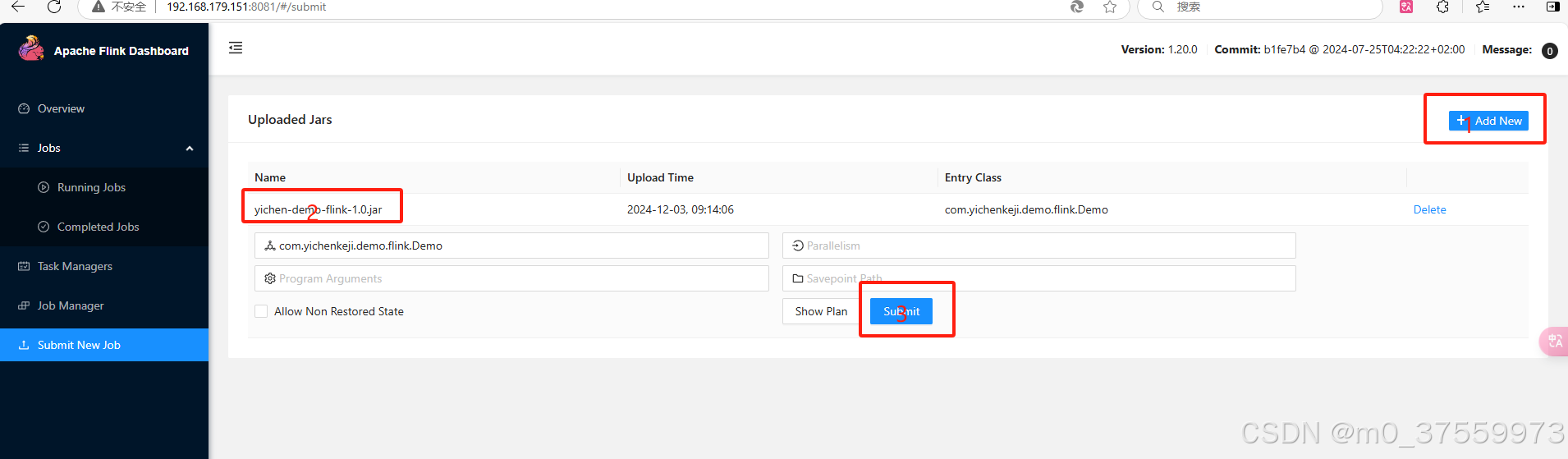
3.1.3 打包程序
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yichenkeji.demo.flink</groupId>
<artifactId>yichen-demo-flink</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.20.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- Replace this with the main class of your job -->
<mainClass>com.yichenkeji.demo.flink.Demo</mainClass>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>3.2 运行 Flink 应用程序
3.2.1 命令行运行
]$ ./bin/flink run /data/flink/demo/yichen-demo-flink-1.0.jar