省时查报告-专业、及时、全面的行研报告库
省时查方案-专业、及时、全面的营销策划方案库
【免费下载】2024年3月份热门报告合集
2024中国AI Agent行业研究报告(附下载链接)
推荐技术在vivo互联网商业化业务中的实践.pdf
推荐系统基本问题及系统优化路径.pdf
大规模推荐类深度学习系统的设计实践.pdf
荣耀推荐算法架构演进实践.pdf
推荐系统在腾讯游戏中的应用实践.pdf
微信视频号实时推荐技术架构分享
推荐系统的变与不变
本文首先介绍了美团搜索广告的三个阶段:多策略关键词挖掘、分层召回体系、生成式召回;然后重点介绍了生成式关键词召回、多模态生成式向量召回、生成式相关性判断在美团的实践。最后是一些经验分享及总结,希望能对大家有所帮助或启发。
美团搜索广告介绍
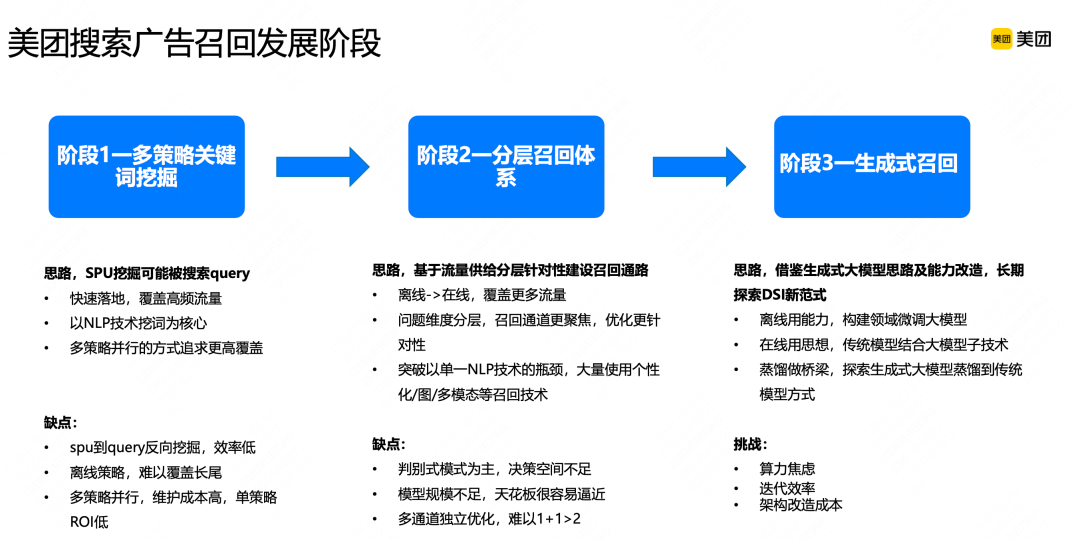
美团搜索广告召回发展阶段
阶段一:多策略关键词挖掘
阶段二:分层召回体系
阶段三:生成式召回
总结
美团搜索广告介绍
从美团流量场景角度来看,美团搜索广告分为两大类,一是列表推荐广告;二是搜索广告。推荐广告以展现商家模式为主,通常叫商家流。搜索广告的展现形式比较丰富,有商家模式,即以商家展现为主,会挂上菜品/商品;还有商品模式,即以商品展现为主,以呈现商品大图、商品标题等核心商品信息为主。
美团搜索广告流量有以下几个典型特点:
搜商品意图占据绝大多数份额,搜索商家只占较小的一部分;因此检索以商品为主,看候选规模的话,美团有百万量级的商家和十亿级别的商品,供给规模较庞大。
从商家特点来看,它有一个和业界传统电商场景不太一致的特点是很多是中小商家/夫妻店,他们的线上运营能力较弱,导致美团商家的内容质量没有其他电商平台好,所以在内容质量处理上,花费了很多时间。
美团的O2O场景特点是LBS属性,供给相对不那么充分,一个蜂窝内的几百个、上千个商家,搜索场景里有相关性约束,供给队列更短,有很多位置受限于供给没有填上。因此,美团搜索广告对召回率的要求更高。
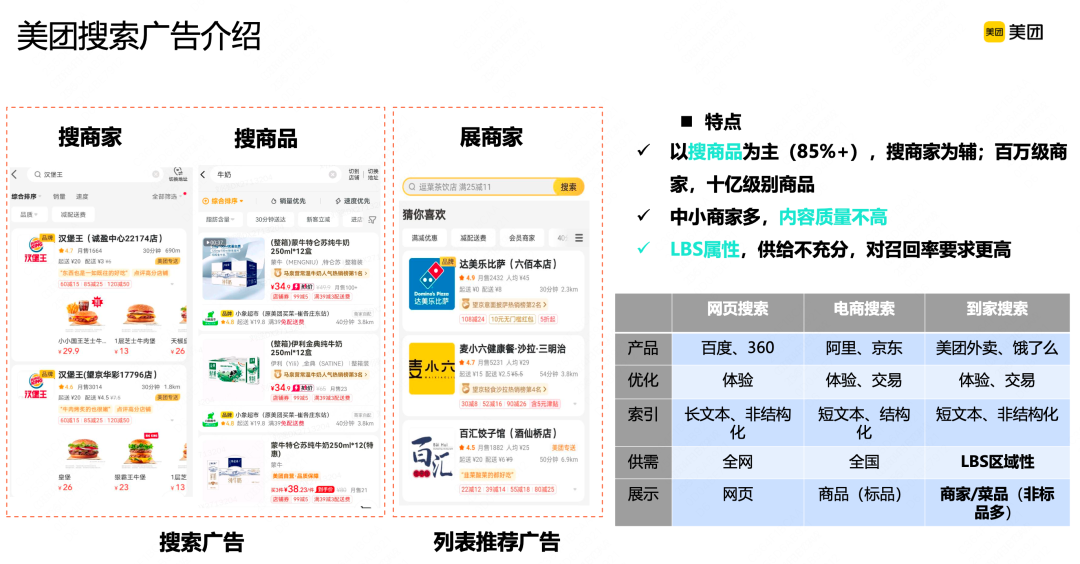
上图展示了美团广告和传统广告之间一些的差异。 下面介绍围绕着召回率提升我们做的一些工作。美团的搜索广告从2019年开始建设,主要经历了三个发展阶段:
第一阶段是美团搜索广告启动阶段,我们叫多策略关键词挖掘阶段。这时的工程基建能力处于起步阶段,也缺乏线上反馈数据,另外考虑落地节奏,希望尽可能快的把整个系统从0到1搭建起来,并希望在数据有限的情况下,快速支持迭代效率。所以这个阶段的召回方式是SPU通过离线方式,挖掘核心关键词,在线与Query精确匹配。
特点:一是只聚焦于通过离线方式覆盖高频流量;二是缺乏线上的行为数据,以NLP的挖词技术为主;三是为了追求更多的覆盖,采用了多策略并行的方式,不断叠加新的召回策略,以达到更高的流量覆盖。
缺点:第一,它不是一个正向匹配过程,而是从商品反向挖掘,所以整体挖掘效率很低,挖出了大量无效关键词,放到线上后,又无法匹配;第二,由于它是一个离线策略,所以只能覆盖一些高频流量,20%-30%的长尾流量无法覆盖;第三个是多策略并行,在后期,新通路会通过不断挤压旧召回通路,最终形成10+的召回通路,这种模式的维护成本较高,而且如果一个算法同学优化一个召回通路,策略面覆盖有限,整体的ROI在后期较低;第四个是缺乏个性化技术。
第二阶段是分层召回体系,它是基于流量和供给特点,按照业务类型,聚焦在几个象限内,每个象限里采用更聚焦的针对性召回策略,进行优化。
特点:第一,在一个业务范畴内,通过把技术做深能够取得业务效果的极大提升;第二是随着基建能力的提升,更多的是把召回由离线切换成在线,以此覆盖更多的流量;第三是在单通路的召回能力上,我们突破了传统单一NLP技术瓶颈,开始大规模使用个性化/图/多模态等新的召回技术。在2022年底,整个分层召回体系取得了不少成效。
缺点:第一是整个召回体系还是以判别式召回模式为主,决策空间不够,倾向于学习历史数据行为,马太效应现象变得越来越严重,而且整个探索空间在这种判别式模型下面,局限性也越来越明显;第二是整个模型规模和容量相对不足,天花板很容易逼近;第三是采用多通道独立优化的方式,每个通道都有自己的样本特征,很难做到通道之间的融合,难以形成1+1>2的效果。
第三个阶段是生成式召回。核心思路是借鉴生成式大模型的思路和能力,改造现有的召回技术体系,长期上来看,我们会探索DSI新召回范式。
大模型在C端流量的落地,会遇到很多算力瓶颈。经过一年的探索,我们形成了大模型落地的方式和原则,分为三类。第一是离线用能力构建领域微调大模型;第二是在线用大模型技术思想,结合传统模型改造现有模型能力;第三是通过蒸馏方式,在线尽可能学习离线大模型能力,通过蒸馏方式把大模型通用知识蒸馏到在线规模相对较小的模型上。
面临的挑战包括三个方面:第一是有算力焦虑;第二是在模型规模变得越来越大的情况下,如何保证模型迭代效率;第三模型的变化不能发挥模型能力本身的优势,我们希望构建以大模型核心能力基础为核心的架构,拿到更好的效果,但改造成本较大。
美团搜索广告召回发展阶段
| 阶段一:多策略关键词挖掘
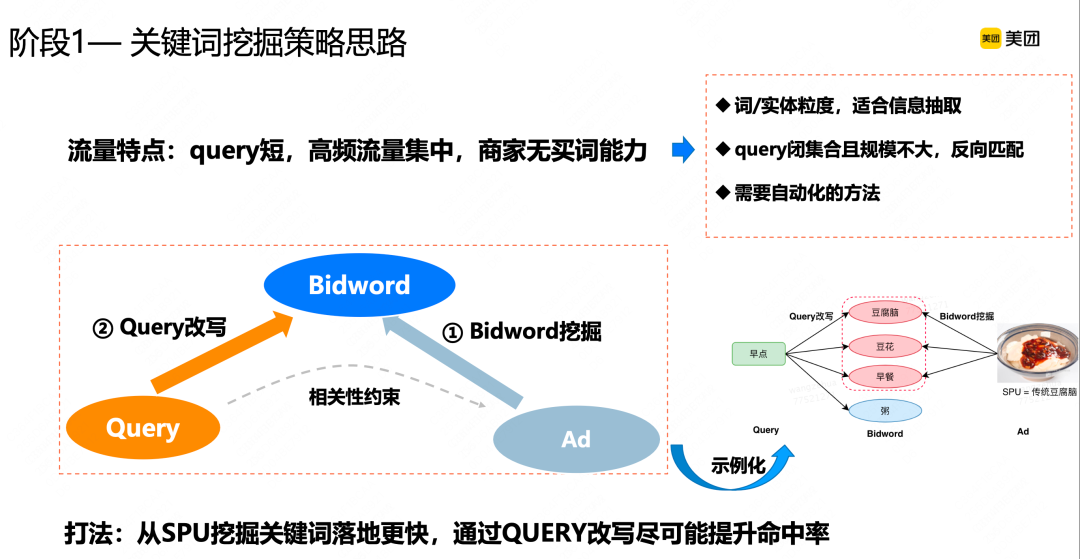
对于多策略关键词挖掘阶段,美团搜索广告的特点一是Query较短,平均长度也就两三个字,因为很多人在美团App搜索比如烧烤、西餐这种很泛但又很短的Query;二是流量分布比较集中,高频、Top几万的Query就占了大约70% ~ 80%的流量,头部效应比较明显;三是区别于业界传统的搜索广告,美团搜索广告商家没有买词能力,通常以整个店铺的投放模式为主。
基于这三个特点,我们设计了关键词挖掘策略思路。一由于Query很短,我们很容易通过信息抽取,把词或实体核心信息抽取出来;二是因为头部效应比较明显,Top2万的Query覆盖了很多流量,采用这种离线方式能快速拿到大部分收益;三是由于商家没有买词能力,如果用Query直接匹配商品,会涉及到传导文本匹配问题,匹配难度会更高,所以我们最后采用模型从商家商品里挖掘核心词,在线做短串匹配的方式。
如左下图所示的召回模式是离线,我们从广告或SPU里通过关键词挖掘的方式挖掘出关键词,在线通过Query改写的方式尽可能提升在线匹配效率。
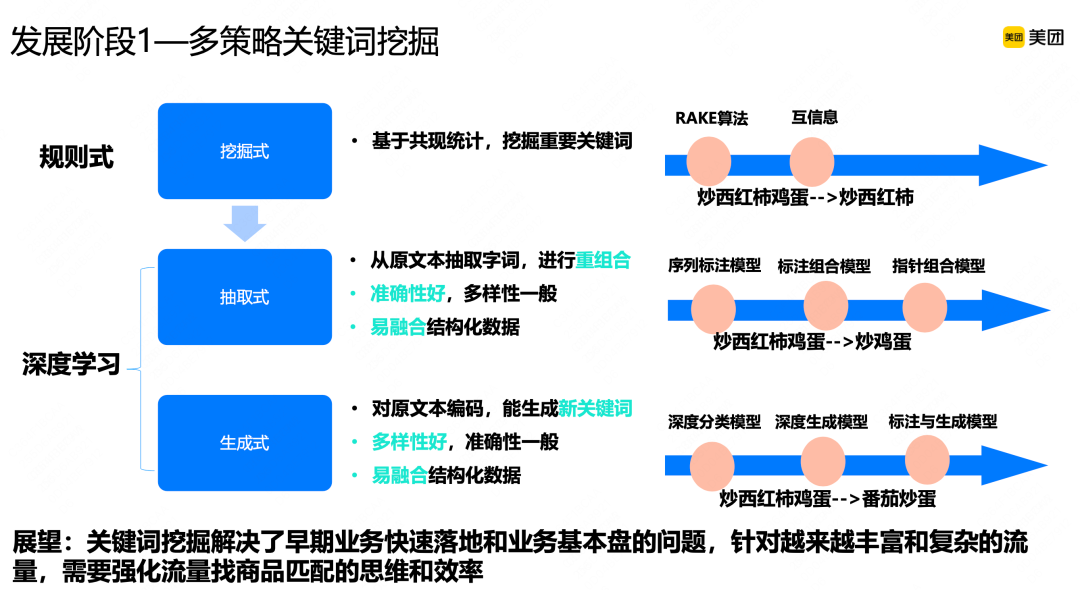
具体来说,我们的关键词挖掘策略经历过三版迭代,按照技术由浅入深的方式做的。
早期第一版创建时,我们更多采用基于规则的挖掘式策略,把流量分成了商家词、商品词和品类词。商品词通过分词和词频贡献的算法,挖掘核心关键词,由于品类字面没有完全匹配的信息,我们通过互信息,构建词之间的权重去挖掘。但问题一是规则能力较弱;第二是只能挖掘出连续的短差,比如“炒西红柿鸡蛋”,它只能挖掘出“炒西红柿”,挖掘不出“炒鸡蛋”。
所以在快速落地了规则式挖掘策略后,我们开始用模型方法自动挖掘关键词。模型通常有两种,抽取式和生成式。
从准确性和数据局限考虑,先采用的是抽取式挖掘方式挖掘关键词,这经过了三个阶段的策略迭代。第一版将规则式升级为了模型挖掘方式,传统上叫序列标注模型,这种模型只能挖掘出连续短串,好处是挖掘效率比基于规则的挖掘模式高,但会导致很多关键词受限于连续短串的方式而挖掘不出来;后面做了两版突破连续短串的挖掘方式,分别是标注组合模型和指针组合模型。标注组合模型能够跨越连续短串挖掘,但它有一个顺序概念在里面;指针组合模型可以在原有短串里随机组合词,突破顺序和连续的局限。但抽取式模型的准确率较高,探索空间不足。
在迭代了三版抽取式策略后,我们将策略重心聚焦在生成式挖掘方向上,希望突破字面极限,探索更大的流量空间,最后做了三个阶段的迭代。第一个阶段是深度分类模型,它能够突破字面限制,Top2万的Query能够覆盖大部分流量,那将SPU商品文本直接分类到这2万个Query标签里,做词和Query间的匹配,但这种多分类模型较难优化,也不能泛化出更多的Query,时效性和更新频率也有限;所以后来我们采用了深度生成模型,实现了相对广阔空间的挖掘,但受限于模型规模和样本丰富度,准确性不太好,所以我们在后面加了标注和生成模型,在具备生成泛化性的同时,尽量控制Query质量,以上所有模型都是传统NLP里的基础模型,我们只是把模型数据、业务特点做了适配。
未来,我们期望在关键词挖掘阶段,较好地解决了早期业务落地和基本盘问题,但是面对美团比较复杂的流量场景,还需要通过新方式强化流量,提高商品匹配效率。
| 阶段二:分层召回体系
2022年,我们开始正式规划第二代召回体系即分层召回体系,核心思路是按照流量和供给特点分类,强意图是直接搜索一个商品;泛意图比如搜索“烧烤”这个品类,泛意图用户虽然表达了需求,但满足需求的候选可以很广,甚至可以替代;供给层面分为有供给、弱供给和没有供给三个象限。我们找到核心象限聚焦优化,最终找到以下四类场景。
第一是强意图有供给,通过关键词就能较好满足,因此在这个象限里,我们更多是在迭代关键词召回技术。一是通过离线统一到生成式的方式。前面介绍离线关键词挖掘策略可能会有十几个通道,不管迭代哪个通道,策略召回的覆盖面都是有限的,而且团队也没那么多人迭代,但这种情况下,我们把整个离线关键词十多路的挖掘策略通过规模较大的生成式模型做了统一,引入了多模态信息,做到了数据更多、模型更多以及召回目标更多的情况,后期只需要通过优化模型能力,就能取得线上全流量覆盖的效果;二是通过离线关键词的方式做到了在线。我们并没有采用业界传统的布尔检索,这种方式有两个局限,一是Query改写以及商品分词基于较浅层的模型,整体效果会受限于模型效果。二是它没有做到检索和最终目标的匹配。在线系数化检索方式类似于双塔向量检索,但每个模型出来不是一个稠密的向量,而是一个几万维稀疏的term粒度,通过端到端的建模方式,把Query和商品映射到一个稀疏的几万维槽位的几个槽位里,离线训练时通过槽位端到端的建模,实现目标检索和目标一致性,在线检索时,基于槽位构建倒排检索,具备一定的可解释性。
第二个是泛意图有供给,体现了用户的个性化偏好,通过迭代向量召回模型覆盖这个场景。向量召回经过了三版迭代。第一版是基于传统语义相关性约束的双塔模型,和业界的做法类似;我们的向量召回目标最终要让建模用户个性化,第二版将用户个性化提上了日程,但如果只把用户个性化特征和传统语义特征融合在一起,黑盒式学习很容易被用户个性化信息带偏,最后我们让用户个性化信息和语义个性化信息分别学习,通过显式叠加的方式做端到端的建模。这种检索方式能够兼顾个性化和语义相关性信息;第三版是基于平台的多样化目标,我们需要对齐后链路的精排目标,在召回阶段考虑整体商业价值。
第三个是泛需求弱供给,比如搜索“汉堡王”,但给TA一个“肯德基”,TA也会下单,通过搜索推荐化的方式覆盖和解决。这个场景比较复杂,从业务来看,它需要做引导和推荐,在结果页里也做偏泛结果的推荐,涉及到搜索前和搜索中,搜索中既有商家也有菜品,既涉及要推荐什么样的菜品,也涉及推荐什么样的商家;另外推荐本身是一个关系建模。我们最后选择基于图模型的迭代,因为图模型首先是一个基于关系的建模,而且图模型具备多场景海量信息的容纳能力,在图建模里,一是构建了异构的多节点百亿规模图,通过图预训练加微调的方式识别多个场景,我们最近也在尝试做图和大模型训练相结合的方式;二是我们把整个图检索搬到在线,因为在搜索场景中,用户需求是即时需求,属性较强,只有把检索搬到在线,通过图在线的实时检索聚合到用户当前最有可能的潜在兴趣情况下,才能实现收益最大化。
第四个是没有供给的场景,通过流量结合供给运营化的方式解决。
阶段2通过划分象限和场景聚焦迭代的方式,拿到了不错的收益,但很快也遇到了瓶颈。

| 阶段三:生成式召回
2023年,我们开始探索新生成式召回方式,核心思路是结合大模型或生成式技术思想,提高召回算法的决策空间,提升模型的匹配能力。经过一段时间迭代,我们抽象出广告子模块结合LLM落地的三类思想及方式,分别是用思想、学能力、用LLM。具体和子模块结合的一些探索如下:
一是离线关键词召回方向。如刚才介绍,我们已经把整个离线关键词召回技术方式统一到了规模不错的生成式模型方式上。大模型出来后,直接用大模型其实还存在着算力及效果的2个挑战。但我们认为大模型的两个核心技术思想:Cot(Chain-of-thought,能使大型语言模型能够更好地理解人类的语言请求)推理和RLHF(Reinforcement Learning from Human Feedback,一种基于人类偏好的强化学习方法)对齐人类反馈思想,对我们现有模型的优化也是有帮助的,因此我们使用大模型的这些技术思想来改造离线生成式召回模型。
二是在向量召回方向。我们已经将向量表征升级为多模态模型,进一步我们思考,LLM语言大模型对于离散Token的信息归纳及表征是有比较大的提升的,但是在稠密表征领域,一个值得借鉴的方法是扩散模型,因为扩散模型也是通过多步去噪的方式来生成目标,通过扩散多步过程,在其中引入多元信息多步融合的思路,提升整个向量召回的向量表征能力。
三是随着我们探索的深入及对应算法能力的提升,我们构建了美团领域广告大模型,尝试直接把大模型用到美团实际场景里做关键词召回,将离线中等规模的生成式模型直接替换成大模型,并探索大模型在线化。
第四个是蒸馏大模型能力,主要在相关性场景落地,目前蒸馏了两块能力,Cot推理能力和模型隐层知识能力蒸馏。
下面我主要介绍下结合LLM的能力,在召回场景下已经全量的一些技术探索。
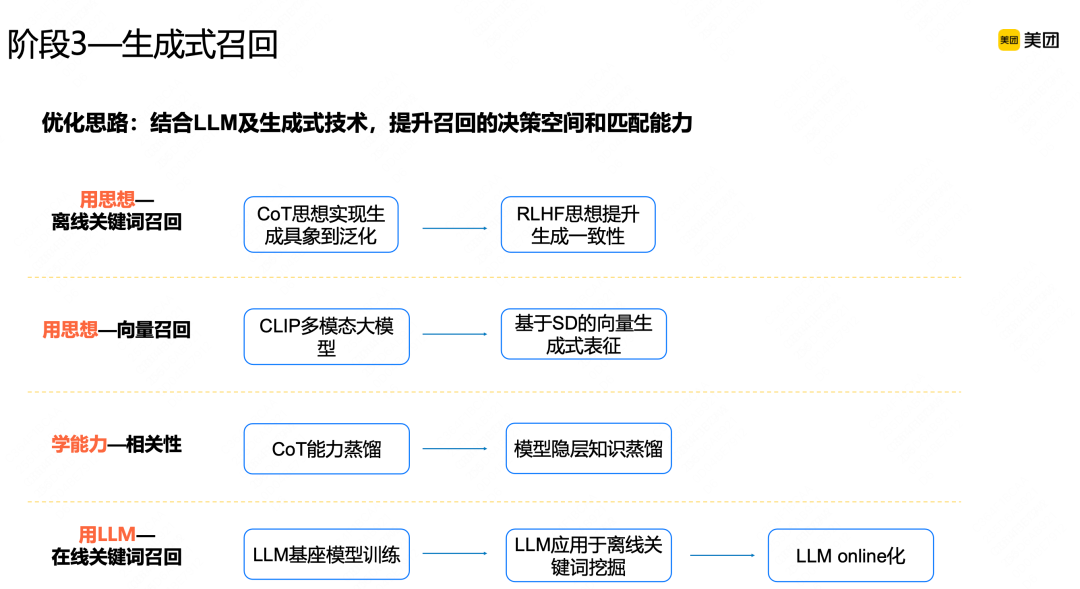
生成式关键词召回
生成式召回主要借鉴大模型思想,我们已经升级为统一的生成式模型,它的工作方式是基于beamsearch的方式,一次生成多个结果,但结果之间是互相看不到的,我们认为这种方式会存在问题,另外,从线上和实际生成结果来看,词之间是有关系的,按照概率方式来看,如果一个关键词能够推理出另一个关键词,大概率前面这个关键词要比下一个关键词的信息含量多,那能否借鉴大模型推理思想,按照序列生成方式逐步推理出多个关键词。
我们通过构建概率贡献图的方式,采样得到关键词之间的导出关系,在一次生成时,直接生成多个关键词,这多个关键词之间有推理关系,比如要给“花仙女鲜花店”商家生成关键词,第一个关键词就是相对具象的“鲜花店”,它的含义和商家的商品描述是确定的,在生成“鲜花店”时,可以推理成“花店”,进一步可能会生成新关键词,通过这种序列推理方式,能够很好地利用关键词之间的关系。
在序列推理生成关键词时,比如生成了5个关键词,有一个关键词不相关,剩下的4个关键词是相关的,那如何通过模型识别出这种不一致现象,能否借助人类反馈方式,实现模型序列好坏端到端的判断。模型生成的关键词序列与人工标注是否一致,通过这种反馈对齐的方式喂给模型,提升整个序列生成结果的一致性。
通过这种方式,召回得到明显提升,而且生成相关性的准确度也得到明显提升。
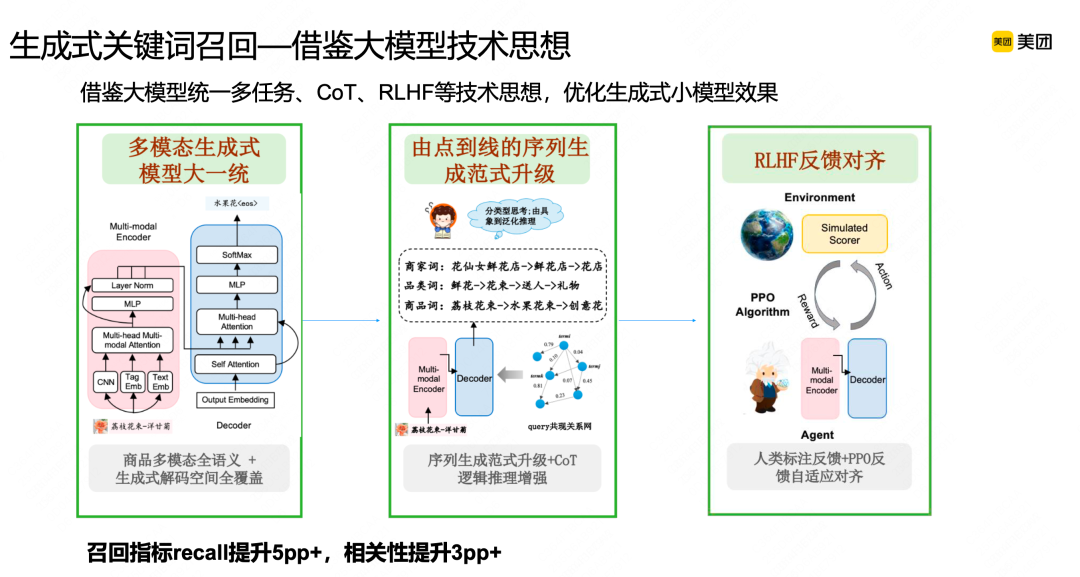
对于离线关键词,前面是中等规模的模型,我们最近把整个离线关键词替换成大模型,之前没有替换是因为开源通用大模型能力在领域场景里,挖掘词的准确性和通用性有限,我们一直在构建美团广告领域的大模型,通过激发大模型知识,生成更全面准确的模型,我们做了3个阶段的优化。
第一是融合领域知识,比如健身和轻食相关,这是领域知识,通过领域全参数训练得到一个基础的广告领域模型。第二是融入场景知识,美团有很多店铺和商品名,比如川菜和眉州东坡在店铺里有很多相关数据。通过这种指令微调的方式学习店铺知识,在实际应用时,再学习偏实际的知识,比如搜索“猪手”时,发现他之前检索过很多“猪肘切片”,通过这种检索方式增强大模型当前推理知识能力。最后通过构建领域大模型和检索增强范式,在一些场景里替换传统大模型,这样,我们发现召回效率明显提升。
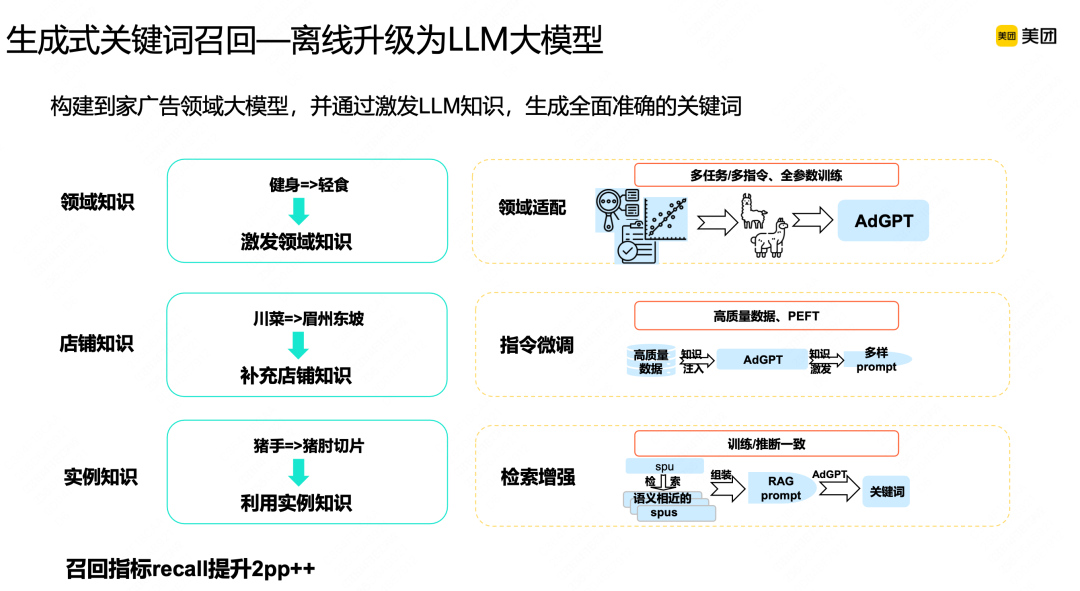
多模态生成式向量召回——结合扩散模型,多阶段生成向量表征
我们改造或优化多模态向量召回,在表征里结合扩散模型做了优化,如下图左边所示,传统的多模态向量召回更多是在item侧表征里,将商品图片和文本模态信息融合在一起,得到一个表征,那能否通过一些方式在Query侧也实现多模态表征。一个用户在美团场景里搜索一个Query时,大概率他的脑海里已经有关于这个Query所对应菜品图片的大致印象。那我们如何通过模型建模的方式还原图片的印象,核心在于还原用户的潜在意识。我们的做法是,一是把Query历史点击的图片信息汇集在一起,表征Query所代表的通用视觉信息;二是将用户历史点击图片代表用户个性化视觉信息,把这两类视觉信息叠加在一起,可以在一定程度上反映用户在当前搜索框架下,想要得到的流量侧多模态信息,最后通过多模态表征匹配技术,整个离线召回效率也有提升。
但这种方式也是基于传统的判别式表征,比如现在大家都在做个性化向量召回,相关性和个性化之间有递进关系,最浅层的需要保证相关性,第二层才需要在相关性里挑选更个性化、更符合用户偏好的候选集,给到下游链路。但传统的判别式方式一般在特征阶段叠加不同特征,通过建模、多目标落实反向迁移方式,不能很好的显式学习到不同目标间的递进关系,但SD生成模型比较适合这种稠密向量生成,通过多步还原过程,本质上也是一个不断推理的生成式过程。
我们希望向量表征具备不同信息的推理能力,SD的多步加噪去噪过程类似于推理过程,可以相结合,在不同步骤中引入不同维度的信息,做到多维信息的显式理解及融合。在正向编码过程中,先将item通过编码器编码成向量后,逐渐加噪还原成白噪声,在反向去噪还原过程中,在噪声里分阶段添加用户Query以及side info信息,通过多步还原的方式,还原出Query所代表的信息。并有两个对比的操作,一是传统的样本Paiwise学习,通过对比学习方式拉近Query与相似Item的表征;二是我们认为相似item有类似的标准过程,通过对比学习拉近相似item之间在扩散中间过程的表征,这是整个建模过程。
在还原阶段,我们会显式还原中间步骤叠加相关性信息、个性化信息,通过对比方式让模型在还原过程中显式相关性和个性化信息,最后在模型结果里能看到,如下图左边是传统的判别式模型里最好的一个Baseline,它能够较好区分Query和正样本信息,但它在个性化样本和相关性样本里基本是混在一起的,通过这种扩散模型方式,相关性样本和个性化样本就有一定程度区分开来的能力。
总结
生成式算法相比判别式,能够有效的拓展整个召回的策略空间,2023年我们基于大模型的技术思想赋能现有的召回模型拿到了一些效果,但远未达到新技术方式的上限。看未来,一方面随着算力的逐渐提升,我们可以探索更大规模的生成式模型直接落地,另一方面可以探索在线的端到端生成式召回,来优化多级漏斗带来的样本偏差和漏斗效率问题。
「 更多干货,更多收获 」

【免费下载】2024年3月份热门报告合集
ChatGPT的发展历程、原理、技术架构及未来方向
2023年AIGC发展趋势报告:人工智能的下一时代
推荐系统在腾讯游戏中的应用实践.pdf
推荐技术在vivo互联网商业化业务中的实践.pdf
2023年,如何科学制定年度规划?
《底层逻辑》高清配图
推荐技术在vivo互联网商业化业务中的实践.pdf
推荐系统基本问题及系统优化路径.pdf
荣耀推荐算法架构演进实践.pdf
大规模推荐类深度学习系统的设计实践.pdf
某视频APP推荐策略详细拆解(万字长文)