😊😊😊欢迎来到本博客😊😊😊
本次博客内容将继续讲解关于OpenCV的相关知识
🎉作者简介:⭐️⭐️⭐️目前计算机研究生在读。主要研究方向是人工智能和群智能算法方向。目前熟悉深度学习(keras、pytorch、yolo系列),python网页爬虫、机器学习、计算机视觉(OpenCV)、群智能算法。然后正在学习深度学习的相关内容。以后可能会涉及到网络安全相关领域,毕竟这是每一个学习计算机的梦想嘛!
📝目前更新:🌟🌟🌟目前已经更新了关于网络爬虫的相关知识、机器学习的相关知识、目前正在更新计算机视觉-OpenCV的相关内容。
💛💛💛本文摘要💛💛💛
本文我们将继续讲解计算机视觉项目-目标实时追踪的相关操作。

🌟项目前言
目标追踪技术对于民生、社会的发展以及国家军事能力的壮大都具有重要的意义。它不仅仅可以应用到体育赛事当中目标的捕捉,还可以应用到交通上,比如实时监测车辆是否超速等!对于国家的军事也具有一定的意义,比如说导弹识别目标等方向。所以说实时目标追踪技术对于整个社会来说都是非常重要的!目前被应用的比较多的,而且效果较好的是YOLO系列,目前已经更新到了YOLO7。原作者更新到了YOLO3之后就不再更新YOLO这个系列了,因为被一些不法人员应用到了军事上,给民众要造成了一定的伤害!但是依旧没有阻挡住YOLO的发展。但是我们提出来的这个是基于计算机视觉的,那么为什么有了YOLO这么好的东西我们还要基于计算机视觉来做呢?因为YOLO训练的模型占用的内存一般不小,这就会影响了一些东西的使用,比如说摄像头!就没有办法有这么大的内存来存储,所以还需要一些不需要那么大内存的东西来去实时跟踪目标!

🌟项目详解
首先我们来根据代码来讲解一下如何追踪实时物体!
首先我们导入库和配置参数,对于参数的配置。我们需要在参数框架上输入--video videos/nascar.mp4 --tracker kcf。表示的意思就是我们导入的视频是nascar.mp4,然后用kcf这个框架来干活。
import argparse
import time
import cv2
import numpy as np
# 配置参数
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--video", type=str,
help="path to input video file")
ap.add_argument("-t", "--tracker", type=str, default="kcf",
help="OpenCV object tracker type")
args = vars(ap.parse_args())
然后我们写一些OpenCV已经有的算法。
OPENCV_OBJECT_TRACKERS = {
"csrt": cv2.legacy.TrackerCSRT_create,
"kcf": cv2.legacy.TrackerKCF_create,
"boosting": cv2.legacy.TrackerBoosting_create,
"mil": cv2.legacy.TrackerMIL_create,
"tld": cv2.legacy.TrackerTLD_create,
"medianflow": cv2.legacy.TrackerMedianFlow_create,
"mosse": cv2.legacy.TrackerMOSSE_create
}
这里注意一定要按照这个来写。其他的由于版本问题,可能会有问题。对于新老版本是不一样的。
然后我们建立多个追踪器。并且开始读入视频数据。这里的trackers就是我们需要建立的多目标追踪器。
trackers = cv2.legacy.MultiTracker_create()
vs = cv2.VideoCapture(args["video"])
这里我们取出来视频中的每一帧,然后视频结束了就直接结束。对于每一帧我们都要做一个操作就是同比例处理图像。
while True:
# 取当前帧
frame = vs.read()
# (true, data)
frame = frame[1]
if frame is None:
break
# resize每一帧
(h, w) = frame.shape[:2]
width=600
r = width / float(w)
dim = (width, int(h * r))
frame = cv2.resize(frame, dim, interpolation=cv2.INTER_AREA)
对于追踪结果来说,我们需要每一帧每一帧的进行更新框框。因为物体在运动,所以我们也要更新框框。
(success, boxes) = trackers.update(frame)
for box in boxes:
(x, y, w, h) = [int(v) for v in box]
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
对于每一个框框我们在更新的时候我们都要绘制出来!
cv2.imshow("Frame", frame)
key = cv2.waitKey(100) & 0xFF
然后将框框展示出来。cv2.waitKey(100)这个部分100可以改成其他的这里可以调节视频的快慢。
if key == ord("s"):
# 选择一个区域,按s
box = cv2.selectROI("Frame", frame, fromCenter=False,
showCrosshair=True)
如果我们按下S键,然后我们就可以手动的框出来ROI区域了。

tracker = OPENCV_OBJECT_TRACKERS[args["tracker"]]()#创建一个追踪器 添加追踪器
trackers.add(tracker, frame, box)
这里创建出来追踪器,然后添加上。
elif key == 27:
break
vs.release()
cv2.destroyAllWindows()
最后退出。
可以手动的任意追踪目标!!!完美!!!
追踪效果总体来说还是不错的!

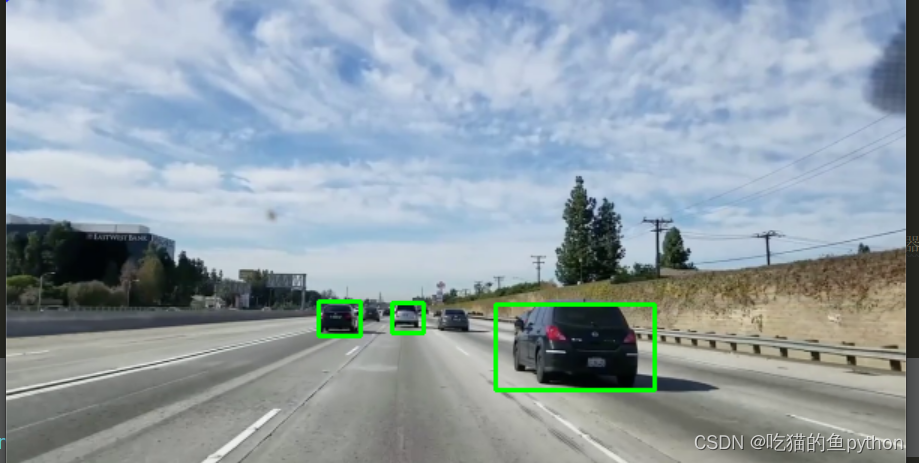

🌟项目深究
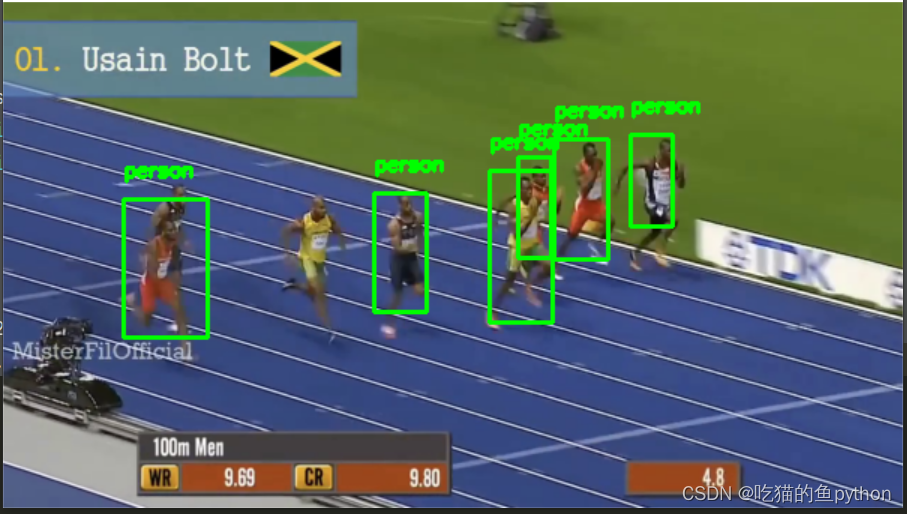
然后又继续做了一个多目标自动识别目标追踪。这里我们以运动员短跑为案例继续来讲解。
这里面我们导入库和第三方参数。
from utils import FPS
import numpy as np
import argparse
import dlib
import cv2
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-v", "--video", required=True,
help="path to input video file")
ap.add_argument("-o", "--output", type=str,
help="path to optional output video file")
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
其中参数导入的话是这样:
--prototxt mobilenet_ssd/MobileNetSSD_deploy.prototxt --model mobilenet_ssd/MobileNetSSD_deploy.caffemodel --video race.mp4
--model mobilenet_ssd/MobileNetSSD_deploy.caffemodel
--video race.mp4
把这段代码直接复制粘贴到参数配置当中就好。
然后我们建立一些分类标签,看看计算机到时候框出来的很多很多框框都属于什么东西,然后我们进行过滤操作。
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
读取网络模型。
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
其中cv2.dnn.readNetFromCaffe(prototxt, model) 用于进行SSD网络的caffe框架的加载
参数说明:prototxt表示caffe网络的结构文本,model表示已经训练好的参数结果把视频读入进来。
print("[INFO] starting video stream...")
vs = cv2.VideoCapture(args["video"])
writer = None
trackers = []
labels = []
fps = FPS().start()
这里我们设置两个列表,等会来添加追踪器和标签信息。并且计算一下视频的fps数值。fps也就是一秒钟计算机可以处理多少帧图像。
while True:
# 读取一帧
(grabbed, frame) = vs.read()
# 是否是最后了
if frame is None:
break
# 预处理操作
(h, w) = frame.shape[:2]
width=600
r = width / float(w)
dim = (width, int(h * r))
frame = cv2.resize(frame, dim, interpolation=cv2.INTER_AREA)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
在这里面和上面一样同样也要同比例放大或者缩小每一帧图像。然后有一个重要操作,就是一定要将BGR图像通道改成RGB通道顺序。
if args["output"] is not None and writer is None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
这里是保存数据,如果output这个文件夹是空的并且writer也是空的,那么我们将实时视频保存下来。这个就涉及到了视频保存的代码,有需要的可以自行提取。
if len(trackers) == 0:
# 获取blob数据
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 0.007843, (w, h), 127.5)
cv2.dnn.blobFromImage主要是对图像进行一个预处理,其中0.007843表示各通道数值的缩放比例。127.5表示各个通道减去的均值。
net.setInput(blob)
detections = net.forward()
这里面把预处理的图像输入到了模型的输入当中,然后进行了一次前向传播。这里面我们就得到了很多的检测框框了。
for i in np.arange(0, detections.shape[2]):
# 能检测到多个结果,只保留概率高的
confidence = detections[0, 0, i, 2]
# 过滤
if confidence > args["confidence"]:
# extract the index of the class label from the
# detections list
idx = int(detections[0, 0, i, 1])
label = CLASSES[idx]
# 只保留人的
if CLASSES[idx] != "person":
continue
这里面在前向传播当中,我们得到一些概率值较大的,这里怎么定义较大呢,用args["confidence"]这个数值来定义,如果大于我们设定的概率数值,我们就把他的索引拿出来,然后取出来对应的标签,如果不是人的话我们就过滤除去,最后留下这一帧图像当中所有检测到的人。
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
这里面就是我们要得到这个框框,然后拿到这个框框的左上角和右下角坐标。
t = dlib.correlation_tracker()
rect = dlib.rectangle(int(startX), int(startY), int(endX), int(endY))
t.start_track(rgb, rect)
然后我们创建一个追踪器,然后得到检测到的框框,然后开始追踪,追踪的时候按照rgb,并且在第一帧图像的时候开始追踪。
labels.append(label)
trackers.append(t)
然后添加人的标签,并且添加多个追踪器,因为不仅仅一个目标。
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 255, 0), 2)
cv2.putText(frame, label, (startX, startY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
然后我们把框画出来,并且把标签贴上去。都是人的标签。
else:
for (t, l) in zip(trackers, labels):
t.update(rgb)#更新追踪器
pos = t.get_position()#获得位置
# 得到位置
startX = int(pos.left())
startY = int(pos.top())
endX = int(pos.right())
endY = int(pos.bottom())
如果检测到框框了,那么就我们遍历一下追踪器和标签,然后更新追踪器,并且获得追踪器的位置。并且得到位置。
if writer is not None:
writer.write(frame)
# 显示
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# 退出
if key == 27:
break
# 计算FPS
fps.update()
fps.stop()
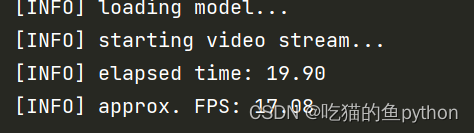
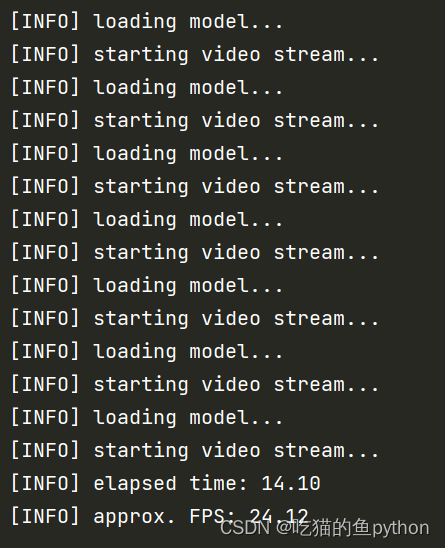
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
if writer is not None:
writer.release()
cv2.destroyAllWindows()
vs.release()
后面这些就是一些退出的一些简单的操作了。
FPS就是表示一秒钟可以处理17帧图片。运行时间是大概有20秒。然后我们想法就是继续进行一下改进,让处理的快一些。那么我们想到的就是使用多线程进行操作。多线程是指从软件或者硬件上实现多个线程并发执行的技术。
然后我们使用多线程进行改进程序:这里主函数就是要加上多线程。

if __name__ == '__main__':
while True:
(grabbed, frame) = vs.read()
if frame is None:
break
(h, w) = frame.shape[:2]
width=600
r = width / float(w)
dim = (width, int(h * r))
frame = cv2.resize(frame, dim, interpolation=cv2.INTER_AREA)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)#深度学习必要要处理的部分
if args["output"] is not None and writer is None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(args["output"], fourcc, 30,
(frame.shape[1], frame.shape[0]), True)
#首先检测位置
if len(inputQueues) == 0:
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, 0.007843, (w, h), 127.5)#图像的预处理操作 详情看笔记
net.setInput(blob)
detections = net.forward()#输出追踪 因为是多个 所以我们下方要进行过滤
for i in np.arange(0, detections.shape[2]): #检测了多少个模型
confidence = detections[0, 0, i, 2]#置信度 这里我们可以理解为每一个模型对应CLASS的概率 然后选出来一个最高的
if confidence > args["confidence"]:
idx = int(detections[0, 0, i, 1])#表示CLASS的类别序号
label = CLASSES[idx]#选出来
if CLASSES[idx] != "person":#过滤掉除了人以外所有的追踪目标
continue
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])#这里标记处框架 这里表示按照长宽背书来定义
(startX, startY, endX, endY) = box.astype("int")
bb = (startX, startY, endX, endY)
# 创建输入q和输出q
iq = multiprocessing.Queue()#定义多进程
oq = multiprocessing.Queue()
inputQueues.append(iq)
outputQueues.append(oq)
# 多核
p = multiprocessing.Process(#八所有追踪器放进进程当中,本电脑为8核 12核会更快
target=start_tracker,
args=(bb, label, rgb, iq, oq))
p.daemon = True
p.start()
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 255, 0), 2)
cv2.putText(frame, label, (startX, startY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
else:
# 多个追踪器处理的都是相同输入
for iq in inputQueues:
iq.put(rgb)
for oq in outputQueues:
# 得到更新结果
(label, (startX, startY, endX, endY)) = oq.get()
# 绘图
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 255, 0), 2)
cv2.putText(frame, label, (startX, startY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
if writer is not None:
writer.write(frame)
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
if key == 27:
break
fps.update()
fps.stop()
print("[INFO] elapsed time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
if writer is not None:
writer.release()
cv2.destroyAllWindows()
vs.release()
这里就是5个线程一起跑。一秒钟可以处理24帧图像,运行时间14秒。大大的改进整体的进程。

🔎支持:🎁🎁🎁如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!