Paper : https://arxiv.org/abs/1912.09629v1
Code : https://tinyurl.com/sbdnet
SBD首先将四边形边框离散为几个关键边缘,其中包含所有可能的水平和垂直位置。为了解码准确的顶点位置,提出了一种简单而有效的匹配程序来重构四边形边界框。
基本思想是利用与标签序列无关的不变表示形式(例如,最小x,最小y,最大x,最大y,平均中心点和对角线的相交点)来反推边界框坐标。为了简化参数化,SBD首先查找所有包含顶点的离散水平和垂直边。 然后学习序列标记匹配类型以找出最佳拟合的四边形。 摆脱了训练目标的模糊性。
贡献
- 第一个根据四边形边界框的顺序解决文本检测歧义的方法,这对于实现良好的检测精度至关重要
- 方法的灵活性使其可以利用几个关键的改进,这些改进对于进一步提高准确性至关重要。 我们的方法在各种场景文本基准(包括ICDAR 2015 和MLT)上均达到了最先进的性能。 此外,我们的方法在最近的 ICDAR2019 Robust Reading Challenge on Reading Chinese Text on Signboard 中赢得了文本检测任务的冠军
- 方法经过有效的改进,也可以推广到航空图像中的船舶检测。 TIoU-Hmean的显着改进进一步证明了我们方法的鲁棒性。
Method
所提出的方法是基于 MaskR-CNN 的。
主要组成:Sequential-free Box Discretization(SBD) + Math-Type Learning(MTL) + Re-scoring and Post Processing(RPP)
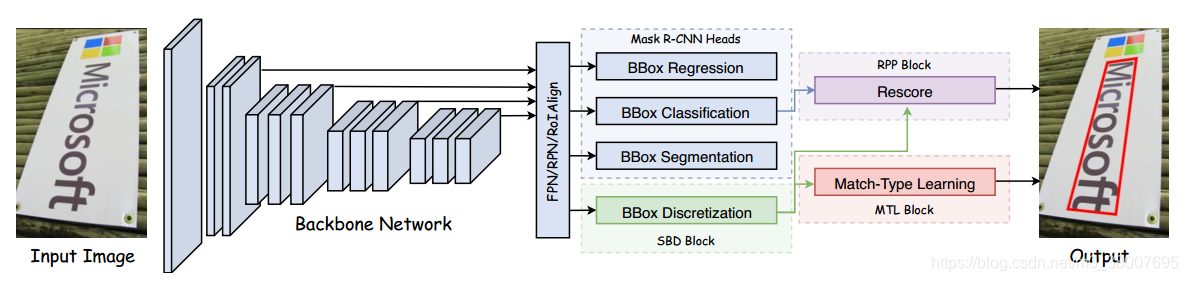
无序列边框离散化 SBD
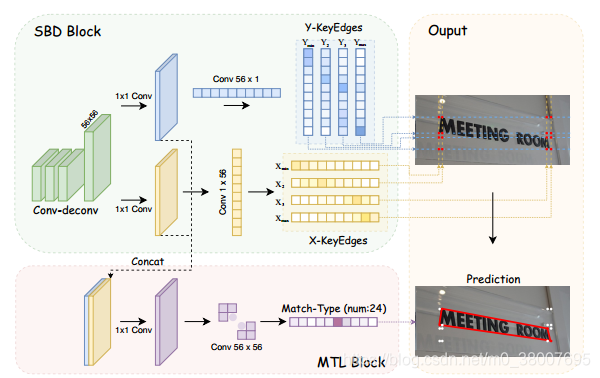
目的:SBD block 将四边形框离散为8个关键边缘(KEs)。这些关键边缘由有序无关点组成,即最小x( x m i n x_{min} xmin)和y( y m i n y_{min} ymin); 第二个最小的x( x 2 x_2 x2)和y( y 2 y_2 y2); 第二大x( x 3 x_3 x3)和y( y 3 y_3 y3); 以及最大x( x m a x x_{max} xmax)和y( y m a x y_{max} ymax)。 使用 x-KEs 和 y-KEs 分别表示 [ x m i n , x 2 , x 3 , x m a x ] [x_{min},x_2,x_3,x_{max}] [xmin,x2,x3,xmax] 和 [ y m i n , y 2 , y 3 , y m a x ] [y_{min},y_2,y_3,y_{max}] [ymin,y2,y3,ymax]
原理: RoIAlign处理的 proposal 被送入SBD块,在该块中,特征图通过一系列卷积层; 然后再对这些特征进行2倍的上采样,并将来自反卷积的输出特征图 F o u t F_{out} Fout 限制为 M × M M×M M×M 大小。然后,使用两个具有4个通道的 1 × M 1×M 1×M 和 M × 1 M×1 M×1 的卷积核来缩小水平和垂直特征分别为 x-KEs 和 y-KEs 。 最后,通过最小化 M M M 方向 SoftMax 输出上的交叉熵损失 L k e L_{ke} Lke 来训练SBD模型,其中,将真实值 KEs 的对应位置对应到每个输出通道。
由于RoI的限制,SBD不能直接学习 x-KEs 和 y-KEs。 原始的 Mask R-CNN 框架仅学习预测 RoI 区域内的目标对象,并且不能恢复 RoI 之外的对象部分丢失的像素。因此,为解决此问题,在训练时将 x-KEs 和 y-KEs 编码为 “half lines” 形式,x-KEs
x
i
∈
[
x
m
i
n
,
x
2
,
x
3
,
x
m
a
x
]
x^i \in [x_{min},x_2,x_3,x_{max}]
xi∈[xmin,x2,x3,xmax],y-KEs
y
i
∈
[
y
m
i
n
,
y
2
,
y
3
,
y
m
a
x
]
y^i \in [y_{min},y_2,y_3,y_{max}]
yi∈[ymin,y2,y3,ymax]。
x
h
a
l
f
i
=
x
i
+
x
m
e
a
n
2
y
h
a
l
f
i
=
y
i
+
y
m
e
a
n
2
x_{half}^i = \frac{x^i + x_{mean}}{2} \\ y_{half}^i = \frac{y^i + y_{mean}}{2}
xhalfi=2xi+xmeanyhalfi=2yi+ymean
其中,
x
m
e
a
n
,
y
m
e
a
n
x_{mean}, y_{mean}
xmean,ymean 分别表示 x 轴和 y 轴的 gt 边界框的平均中心点的值。通过采用这样的训练策略,所提出的SBD块可以打破RoI的限制,即在大多数情况下,即使文本实例的边界位于RoIs之外,由于
x
h
a
l
f
x_{half}
xhalf和
y
h
a
l
f
y_{half}
yhalf 落入RoIs区域,文本实例的完整也可以得到保证。
与Mask R-CNN类似,检测器是在多任务方式下进行训练的。所以损失函数由四部分下组成:
L
=
L
c
l
s
+
L
b
o
x
+
L
m
a
s
k
+
L
k
e
L = L_{cls} + L_{box} + L_{mask} + L_{ke}
L=Lcls+Lbox+Lmask+Lke
L
c
l
s
,
L
b
o
x
,
L
m
a
s
k
L_{cls}, L_{box}, L_{mask}
Lcls,Lbox,Lmask 与 Mask RNN一样,
L
k
e
L_{ke}
Lke 表示学习 关键边缘预测 任务的交叉熵损失。
匹配类型学习(MTL)
SBD只是学习了预测 8 条线的数值,但是忽视了怎么在 x-KEs 和 y-KEs 之间进行连接。所以提出了 MTL 从关键边重构四边形边界框。
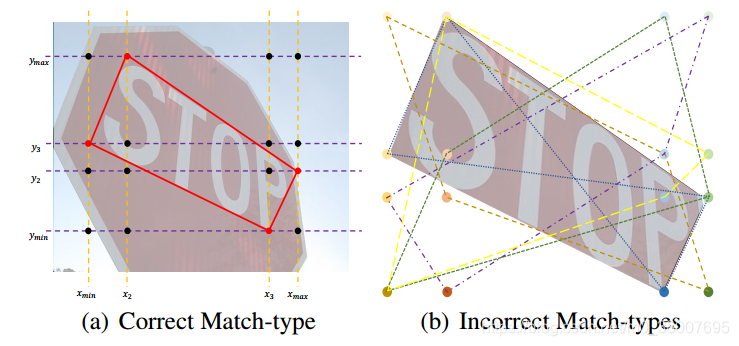
目的: SBD输出得到 4 个 x-KEs 和 4 个 y-KEs,每个 x-KEs 应该匹配一个 y-KEs 构成一个角点,然后得到四个角点就是最终的边界框的顶点的预测。 构成的不同的角点会有不同的结果,总共有 A 4 4 = 24 A_4^4 = 24 A44=24 种可能。例如在下图中预测的匹配类型应该是 [ ( x m i n , y 3 ) , ( x 2 , y m a x ) , ( x m a x , y 2 ) , ( x 3 , y m i n ) ] [(x_{min}, y_3), (x_2, y_{max}), (x_{max}, y_2), (x_3, y_{min})] [(xmin,y3),(x2,ymax),(xmax,y2),(x3,ymin)] ,这就应该是最终的预测。
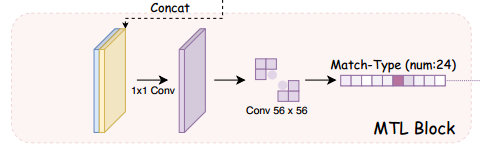
原理: 将SBD的两个生成 x-KEs 和 y-KEs 的特征图拼接在一起,通过 1x1 的卷积层后进行分类,24类分类任务。该方法中 MTL 头是通过最小化交叉熵损失来训练的。
重新评分和后处理(RPP)
检测器有时可以为错误正样本输出高置信度分数,为了抑制不合理的错误正样本,提出了 RPP。
在RPP中,首先基于8个KEs计算SBD得分
S
S
B
D
S_{SBD}
SSBD:
S
S
B
D
=
1
K
∑
k
=
1
K
max
v
k
f
(
v
k
)
S_{SBD} = \frac{1}{K} \sum_{k=1}^K \max_{v^k} f(v^k)
SSBD=K1k=1∑Kvkmaxf(vk)
其中
K
=
8
K = 8
K=8 是 KEs 的数量。尽管在大多数情况下,
S
S
B
D
S_{SBD}
SSBD 的分布显示出一个单峰模式,但峰值仍显着低于1。因此,我们对每个关键边缘分数的4个相邻分数求和,以使其接近峰值,以避免置信度过低 。 假设
v
k
v_k
vk 是第
k
k
k 个关键边的输出得分矢量,则函数
f
(
v
k
)
f(v^k)
f(vk) 定义为峰值
v
i
v_i
vi 及其邻居的和:
v
k
=
[
v
1
,
v
2
,
…
,
v
i
−
2
,
v
i
−
1
,
v
i
,
v
i
+
1
,
v
i
+
2
⏟
f
(
v
k
)
=
∑
p
=
m
a
x
(
i
−
2
,
1
)
P
=
m
i
n
(
n
,
n
+
2
)
(
v
p
)
,
…
,
v
n
]
v^k = [v_1, v_2, \dots, \underbrace{v_{i-2}, v_{i-1}, v_i, v_{i+1}, v_{i+2}}_{f(v^k) = \sum_{p=max(i-2,1)}^{P=min(n,n+2)}(v_p)}, \dots,v_n]
vk=[v1,v2,…,f(vk)=∑p=max(i−2,1)P=min(n,n+2)(vp)
vi−2,vi−1,vi,vi+1,vi+2,…,vn]
应当注意,如果峰值位于向量的头部或尾部,则相邻值的数量将小于4,因此在这种情况下,仅存在的邻居会被计数。 最后,可以通过以下方法获得精确的置信度:
s
c
o
r
e
(
R
)
=
(
2
−
γ
)
S
b
o
x
+
γ
S
S
B
D
2
score(\mathfrak{R}) = \frac{(2-\gamma)S_{box} + \gamma S_{SBD}}{2}
score(R)=2(2−γ)Sbox+γSSBD
其中
0
≤
γ
≤
2
0 \leq \gamma \leq 2
0≤γ≤2 。
S
b
o
x
S_{box}
Sbox 是bbox的原始 Softmax置信度。通过将
S
S
B
D
S_{SBD}
SSBD 计入最终分数,它可以根据 8 个KEs的得分进行调整。
总结
SBD通过将点式预测分解为无序的关键边,解决了标签不一致的问题;使用 MLT 解码准确的顶点位置。
与一些基于分割的方法利用分割掩模直接重构边界框相比,MTL块可以学习几何约束,避免分割输出不准确造成的误报,这也减少了对分割任务的严重依赖性。
由于本文方法使用的四条横线和四条竖线的四个交点获得最终的边界框的顶点,所以只能检测旋转矩形,不能检测多边形以及任意形状的文本。