动态量化和静态量化
量化
神经网络中的计算通常以浮点数计算(Float32)进行,模型量化是指以较低的精度损失将这些浮点数计算近似为更低比特的计算,如Float16、Int8等。从而降低模型存储大小、降低显存占用、提升推理性能。在不同的需求下,选择不同的量化方案。
量化方案
- 线性量化与非线性量化
- 根据量化数据表示的原始数据范围是否均匀,可以将量化分为线性量化和非线性量化
- 对称量化与非对称量化
- 根据浮点值的零点是否映射到量化值的零点,可以将量化分为对称量化和非对称量化
- 量化粒度
- 量化粒度指选取多少个待量化参数共享一个量化系数,量化参数(缩放因子s,零点z)会有一个的共享范围,通常来说粒度越大,精度损失越大。根据量化粒度可以将量化分为逐层量化和逐通道量化,甚至是更细的范围 per-tensor/per-layer、per-channel/per-axis、per-col/per-row、per-embeding/per-token、per-block/group
- 精度选择
- 根据网络中量化位宽的不同,可以将量化分为统一精度量化和混合精度量化
- 量化方式
- 量化方式可以分为两大类,训练后量化和量化感知训练
- 量化感知训练(Quantization Aware Training),量化感知训练:在模型中添加伪量化节点模拟量化,重新训练模型(finetune),流程相对复杂
- 训练后量化(Post Training Quantization),根据是否量化激活又分为:
- Dynamic Quantization:仅量化权重,激活在推理时量化,无需校准数据
- Static Quantization:权重和激活都量化,需要校准数据
- 量化方式可以分为两大类,训练后量化和量化感知训练
动态量化和静态量化
由于训练后量化,相对简单高效,只需要已训练好的模型 + 少量校准数据,无需重新训练模型,所以使用较为广泛,其根据是否量化激活又分为动态量化和静态量化,下面将详细介绍两种方法的区别。
模型的量化对象
- 模型的量化对象主要分权重和激活两类
- 权重:训练完后固定,数值范围(range)与输入无关,可离线完成量化,通常相对容易量化
- 激活:激活输出随输入变化而变化,需要统计数据动态范围,通常更难量化
动态量化(PTQ dynamic)
动态量化由于仅量化权重,也称为权重量化(weight-only quantization),其激活在推理时进行量化,适用于 LSTM、MLP、Transformer 等模型,而静态量化则适用于 CNN, 参考 Quantize ONNX Models
In general, it is recommended to use dynamic quantization for RNNs and transformer-based models, and static quantization for CNN models.
上图是 PTQ dynamic 模型量化前后的结构对比示意,即只有 weight 被提前量化成 INT8,在推理阶段首先将量化的权重反量化为浮点形式,推理过程仍然为浮点计算,无法加速推理过程,如下图所示
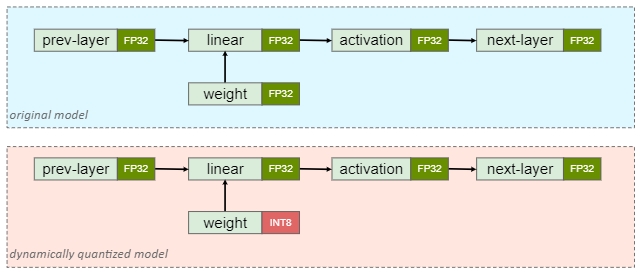
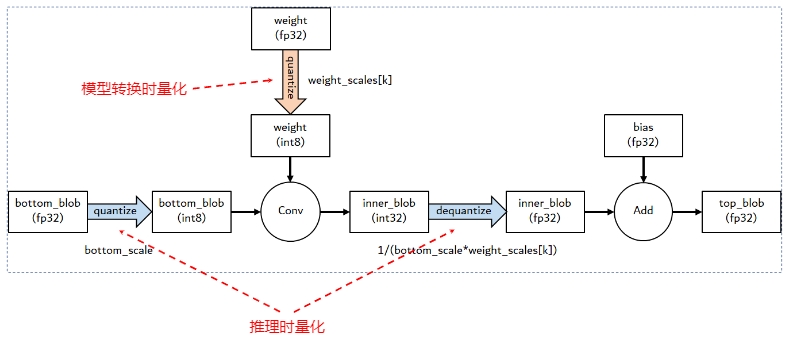
静态量化(PTQ static)
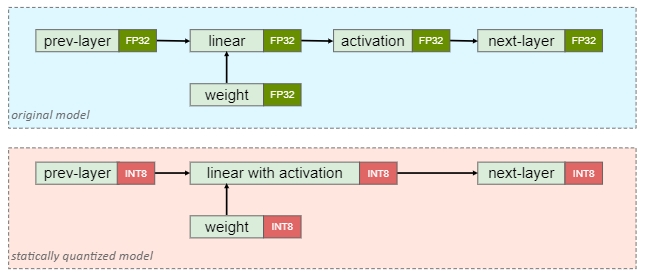
静态量化则是权重和激活都提前量化,也称为全量化,不仅可以压缩模型大小,减少推理过程的内存占用,而且因为激活值和权重都为整型数据,因此可以使用高效的整型运算单元加速推理过程,为了量化激活,需要使用具有代表性的数据进行推理,然后统计各个激活的数据范围,这个步骤也称为“校准”(Calibration)
代码实现
动态量化
在 python 中 onnx 格式的动态量化转换十分简单,无需数据校准,直接调用转换即可
import onnx
from onnxruntime.quantization import quantize_dynamic, QuantType
# float32 onnx 格式的模型
model_path = './wenet.onnx'
model = onnx.load(model_path)
# 量化后的 int8 onnx 格式的模型
quantized_model_path = './wenet_dynamic_int8.onnx'
quantize_dynamic(
model_input=model_path,
model_output=quantized_model_path,
weight_type=QuantType.QUInt8
)
print(f"动态量化后的模型已保存到 {quantized_model_path}")
静态量化
在 python 中 onnx 格式的静态量化转换需求提供质量较高的校准数据,用于量化激活,数据格式和训练时相同即可
import os
import numpy as np
import torch
from onnxruntime.quantization import quantize_static, CalibrationDataReader, QuantFormat, QuantType
class MyCalibrationDataReader(CalibrationDataReader):
def __init__(self):
self.data_len = 10000
self.data_list = self.load_data()
self.data_index = 0
def load_data(self):
train_data = []
## 加载所需的数据
...
return train_data
def get_next(self):
if self.data_index >= len(self.data_list):
return None
inputs = {
'a': self.data_list[self.data_index]['audio'],
'b': self.data_list[self.data_index]['face']
}
self.data_index += 1
print(self.data_index)
return inputs
def quantize_model(input_model_path, output_model_path):
# 创建一个校准数据集
calibration_data_reader = MyCalibrationDataReader()
# Perform static quantization
quantize_static(
model_input=input_model_path,
model_output=output_model_path,
calibration_data_reader=calibration_data_reader,
quant_format=QuantFormat.QDQ,
activation_type=QuantType.QInt8,
weight_type=QuantType.QInt8
)
if __name__ == "__main__":
## float32 onnx 格式的模型
input_model_path = './wenet.onnx'
# 量化后的 int8 onnx 格式的模型
output_model_path = './wenet_static_int8.onnx'
quantize_model(input_model_path, output_model_path)
print("动态量化后的模型已保存到", output_model_path)
推理速度
按照上述模型量化手段,分别在两个模型上对推理速度做比较
模型1:
模型主要以 Transformer 堆叠为主,测试结果符合预期,动态量化推理速度并未提升,反而可能会因为 int8 -> float32 而拖慢了运行速度
# float32 模型运行100次的平均速度
Average run time over 100 iterations: 630.59 ms
# int8 动态量化模型运行100次的平均速度
Average run time over 50 iterations: 878.31 ms
模型2:
模型主要以 CNN 堆叠为主,结果和理论有出入,动态量化的推理速度和静态量化基本相同,但大幅度优于未量化的模型
# float32 模型运行100次的平均速度
Average run time over 100 iterations: 59.11
# int8 动态量化模型运行100次的平均速度
Average run time over 50 iterations: 37.03 ms
# int8 静态量化模型运行100次的平均速度
Average run time over 50 iterations: 38.64 ms