SAX事件驱动方式解析Excel文件
最近在做项目功能时,发现传统
Apache POI提供的API去解析大量数据Excel文件时,很容易抛出内存溢出的异常,导致Excel数据很难读到内存上去。因此在网上找了很多资料,最后找到了SAX事件驱动方式解析Excel文件,完美解决了大数据量读取问题,在这里简单做下整理分享给大家!
1、两种解析方式
Apache POI读取Excel文件有两种模式,分别是用户模式和SAX事件驱动模式。两种方式并没有好坏之分只是适合的应用场景不同。
1、用户模式:提供了丰富的API接口,例如Workbook、Sheet、Row、Cell可以很容易的解析Excel,也是实际开发中使用比较多的一种方式。
Workbook wb = new XSSFWorkbook(inputStream); // 解析 .xlsx
Workbook wb = new HSSFWorkbook(inputStream); // 解析 .xls
Sheet sheet = wb.getSheetAt(index); // 获取sheet
Row row = sheet.getRow(index); // 获取行
Cell cell = row.getCell(index); // 获取单元格
但是这种模式会把文件上所有内容都加载到内存中,对内存消耗很大!当遇到很大的 sheet 时(比如十几万条),很容易抛出 OOM 等异常,导致文件解析失败。分批或逐行处理虽然也可以解决,但是有一定的局限性,不好灵活处理数据。
2、SAX事件驱动模式:SAX全称Simple API for XML,既是一种接口,也是一种软件包。它是一种XML解析的替代方法。将Excel转为xml然后使用SAXParser解析器解析xml文件得到Excel数据(SAX不同于DOM解析,它逐行扫描文档,一边扫描一边解析。由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中,这对于大型文档的解析是个巨大优势),可以有效解决内存溢出,适合大文件处理,这也是POI官方推荐解决内存溢出的方式!
坐标依赖获取地址
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.2</version>
</dependency>
2、快速入门SAX事件驱动解析方式
为了操作数据更快、消耗内存更小、更方便提取单元格数据,我们最终选择把Excel数据以行列坐标(key)-值(value) 的形式保存到一个LinkedHashMap中。
首先要新建一个类SheetHandler继承DefaultHandler,这个类可放在工具类包路径上,这个类需要重写startElement()、endElement()、characters()方法,把数据封装到LinkedHashMap中也是在这几个方法中实现!如:
SheetHandler.java
/**
* @description: 重写startElement() endElement() characters() 用于把Excel数据封装到 LinkedHashMap<String, String> 中
* @date: 2021/12/16 15:10
*/
public class SheetHandler extends DefaultHandler {
private SharedStringsTable sst;
private String lastContents;
private boolean nextIsString;
private String cellPosition;
private LinkedHashMap<String, String> rowContents = new LinkedHashMap<String, String>();
public LinkedHashMap<String, String> getRowContents() {
return rowContents;
}
public void setRowContents(LinkedHashMap<String, String> rowContents) {
this.rowContents = rowContents;
}
public SheetHandler(SharedStringsTable sst) {
this.sst = sst;
}
public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException {
if (name.equals("c")) {
cellPosition = attributes.getValue("r");
String cellType = attributes.getValue("t");
if (cellType != null && cellType.equals("s")) {
nextIsString = true;
} else {
nextIsString = false;
}
}
// 清楚缓存内容
lastContents = "";
}
public void endElement(String uri, String localName, String name)
throws SAXException {
if (nextIsString) {
int idx = Integer.parseInt(lastContents);
lastContents = new XSSFRichTextString(sst.getEntryAt(idx)).toString();
nextIsString = false;
}
if (name.equals("v")) {
// 数据读取结束后,将单元格坐标,内容存入map中
if (!(cellPosition.length() == 2) || (cellPosition.length() == 2 && !"1".equals(cellPosition.substring(1)))) { //不保存第一行数据
rowContents.put(cellPosition, lastContents);
}
}
}
public void characters(char[] ch, int start, int length) throws SAXException {
lastContents += new String(ch, start, length);
}
}
在main方法中编写测试代码,测试Excel数据读取,可以自行准备个Excel文件,体验下SAX事件驱动解析方式。
/**
* @description:
* @author: laizhenghua
* @date: 2022/5/17 20:03
*/
public class SAXTest {
public static void main(String[] args) throws IOException {
String filePath = "C:\\Users\\laizhenghua\\Desktop\\test.xlsx";
InputStream sheet = null;
OPCPackage pkg = null;
SheetHandler sheetHandler = null;
try {
pkg = OPCPackage.open(filePath); // 可以指定一个文件路径/File类/输入流等
XSSFReader reader = new XSSFReader(pkg);
SharedStringsTable table = reader.getSharedStringsTable(); // 共享字符串表
sheetHandler = new SheetHandler(table);
XMLReader parser = XMLReaderFactory.createXMLReader("com.sun.org.apache.xerces.internal.parsers.SAXParser");
parser.setContentHandler(sheetHandler);
sheet = reader.getSheet("rId1"); // rId1是sheet1 rId2是sheet2 以此类推
InputSource sheetSource = new InputSource(sheet);
parser.parse(sheetSource); // 解析excel的每条记录 在这个过程中startElement() characters() endElement() 这三个函数会依次执行
LinkedHashMap<String, String> rowContents = sheetHandler.getRowContents();
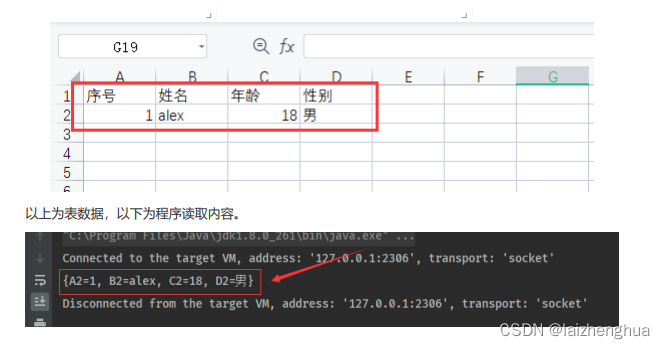
System.out.println(rowContents);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sheet != null) {
sheet.close();
}
if (pkg != null) {
pkg.close();
}
}
}
}
执行结果如下
3、工具类封装
通过以上方法,我们已经可以把数据读到内存里,要对数据进行计算还是保存到数据库,其实已经很简单了~
为了代码方便复用与定制化,把解析Excel数据代码封装成一个工具类ExcelUtil.java ,相当于要想在项目使用这种方式读取Excel数据,就要引入这两个封装好的工具类。
SheetHandler.java
ExcelUtil.java
/**
* 数据量比较大(8万条以上)的excel文件解析,将excel文件解析为 行列坐标-值的形式存入map中,此方式速度快,内存耗损小 但只能读取excel文件
* 提供处理单个sheet方法 processOneSheet(String filename) 以及处理多个sheet方法 processAllSheets(String filename)
* 只需传入文件路径+文件名即可 调用处理方法结束后,只需接收ExcelUtil.getRowContents()返回值即可获得解析后的数据
*/
public class ExcelUtil {
private static LinkedHashMap<String, String> rowContents = new LinkedHashMap<String, String>();
private static SheetHandler sheetHandler;
public LinkedHashMap<String, String> getRowContents() {
return rowContents;
}
public static void setRowContents(LinkedHashMap<String, String> rc) {
rowContents = rc;
}
public SheetHandler getSheetHandler() {
return sheetHandler;
}
public static void setSheetHandler(SheetHandler sh) {
sheetHandler = sh;
}
public static List<LinkedHashMap<String, String>> processSheetByRId(InputStream in, Integer count) throws Exception {
OPCPackage pkg = null;
InputStream sheet = null;
List<LinkedHashMap<String, String>> results = new ArrayList<LinkedHashMap<String, String>>();
try {
pkg = OPCPackage.open(in);
XSSFReader r = new XSSFReader(pkg);
SharedStringsTable sst = r.getSharedStringsTable();
for (int i = 0; i < count; i++) {
sheet = r.getSheet("rId" + (i + 1));
InputSource sheetSource = new InputSource(sheet);
XMLReader parser = fetchSheetParser(sst);
parser.parse(sheetSource);
results.add(sheetHandler.getRowContents());
}
return results;
} catch (Exception e) {
e.printStackTrace();
throw e;
} finally {
if (pkg != null) {
pkg.close();
}
if (sheet != null) {
sheet.close();
}
}
}
// 处理一个sheet
public static void processOneSheet(String filename) throws Exception {
InputStream sheet2 = null;
OPCPackage pkg = null;
try {
pkg = OPCPackage.open(filename);
XSSFReader r = new XSSFReader(pkg);
SharedStringsTable sst = r.getSharedStringsTable();
XMLReader parser = fetchSheetParser(sst);
sheet2 = r.getSheet("rId1");
InputSource sheetSource = new InputSource(sheet2);
parser.parse(sheetSource);
setRowContents(sheetHandler.getRowContents());
} catch (Exception e) {
e.printStackTrace();
throw e;
} finally {
if (pkg != null) {
pkg.close();
}
if (sheet2 != null) {
sheet2.close();
}
}
}
// 处理多个sheet
public static void processAllSheets(String filename) throws Exception {
OPCPackage pkg = null;
InputStream sheet = null;
try {
pkg = OPCPackage.open(filename);
XSSFReader r = new XSSFReader(pkg);
SharedStringsTable sst = r.getSharedStringsTable();
XMLReader parser = fetchSheetParser(sst);
Iterator<InputStream> sheets = r.getSheetsData();
while (sheets.hasNext()) {
System.out.println("Processing new sheet:\n");
sheet = sheets.next();
InputSource sheetSource = new InputSource(sheet);
parser.parse(sheetSource);
}
} catch (Exception e) {
e.printStackTrace();
throw e;
} finally {
if (pkg != null) {
pkg.close();
}
if (sheet != null) {
sheet.close();
}
}
}
public static XMLReader fetchSheetParser(SharedStringsTable sst) throws SAXException {
XMLReader parser = XMLReaderFactory.createXMLReader("com.sun.org.apache.xerces.internal.parsers.SAXParser");
setSheetHandler(new SheetHandler(sst));
ContentHandler handler = (ContentHandler) sheetHandler;
parser.setContentHandler(handler);
return parser;
}
/**
* See org.xml.sax.helpers.DefaultHandler
*/
// 测试
public void test() throws Exception {
Long time = System.currentTimeMillis();
ExcelUtil example = new ExcelUtil();
example.processOneSheet("C:/Users/Desktop/2018041310024112.xlsx");
Long endtime = System.currentTimeMillis();
LinkedHashMap<String, String> map = example.getRowContents();
Iterator<Entry<String, String>> it = map.entrySet().iterator();
int count = 0;
String prePos = "";
while (it.hasNext()) {
Map.Entry<String, String> entry = (Map.Entry<String, String>) it.next();
String pos = entry.getKey();
if (!pos.substring(1).equals(prePos)) {
prePos = pos.substring(1);
count++;
}
System.out.println(pos + ";" + entry.getValue());
}
System.out.println("解析数据" + count + "条;耗时" + (endtime - time) / 1000 + "秒");
}
}