论文笔记-NeruIPS2024-LLM-ESR: Large Language Models Enhancement for Long-tailed Sequential Recommendation
LLM-ESR:用于长尾序列推荐的大模型增强
论文下载: LLM-ESR: Large Language Models Enhancement for Long-tailed Sequential Recommendation
代码: LLM-ESR
摘要
大多数用户只与少量项目交互,而大多数项目则很少被消费,这两个问题被称为长尾用户挑战和长尾项目挑战。虽然已有工作旨在解决这两个挑战,但是由于交互的稀缺性仍存在摇摆或者噪音问题。
本文提出大模型增强框架LLM-ESR,该框架利用LLM的语义嵌入来增强序列推荐,而不增加LLM的额外推理负担。为了解决长尾项目挑战,设计一个双视角建模框架,结合LLM的语义信息和传统序列推荐的协同信息。对于长尾用户挑战,提出检索增强自蒸馏方法,使用来自相似用户的信息交互来增强用户偏好表示。
1.引言
为了解决长尾项目挑战,现有研究考察了流行项目和长尾项目之间的共现模式,旨在通过流行项目丰富长尾项目的表示。然而,忽视项目之间的真实关系可能导致摇摆问题。对于长尾用户挑战,现有研究探索了所有用户的交互历史,试图为长尾用户增强伪项目。然而,这些方法仅依赖于协同信息,这容易由于用户之间不准确的相似性而生成噪音项目。
大模型的发展从语义角度为缓解长尾挑战提供了希望。但是,在推荐领域应用大模型仍存在以下两个问题:(1)LLM的推理时间较长,无法满足推荐系统的实时性;(2)如果不冻结嵌入层,微调过程可能会破坏项目之间的原始语义关系。
本文设计了一个大模型增强框架(LLM-ESR)。首先,通过编码来自LLMs的提示文本来获取项目和用户的语义嵌入。这些嵌入可以提前缓存,因此集成不会给LLMs带来额外的推理负担。为了应对长尾项目挑战,设计了一个双视角建模框架,结合了语义信息和协同信息。具体而言,冻结从LLMs派生的嵌入,以避免语义缺失。然后,提出了一种检索增强自蒸馏方法,通过使用相似用户来增强序列编码器。用户之间的相似性通过来自LLMs的用户表示进行度量。
本文的贡献如下:
-
提出一个大模型增强框架,通过引入来自LLMs的语义信息,缓解序列推荐的长尾用户和长尾项目挑战。
-
为了避免LLMs的推理负担,设计了一种基于嵌入的增强方法。此外,派生的嵌入被直接使用,以保留原有的语义关系。
-
在三个真实数据集上使用三种主干模型进行广泛实验,验证了LLM-ESR的有效性和灵活性。
2.问题定义
按照用户交互序列的长度和项目的流行度排序,根据Pareto原则将前20%的用户和项目作为头部用户和头部项目,其余的作为尾部用户和尾部项目。为了缓解长尾挑战,本文的目标是提升尾部用户和尾部项目的推荐性能。
3.LLM-ESR
3.1概述
LLM-ESR的概述如图2所示。为了获取语义信息,采用LLM对用户的历史交互和物品属性进行编码,生成用户嵌入和物品嵌入。然后,提出两个模块来增强长尾物品和长尾用户,分别是双视图建模和检索增强自蒸馏。
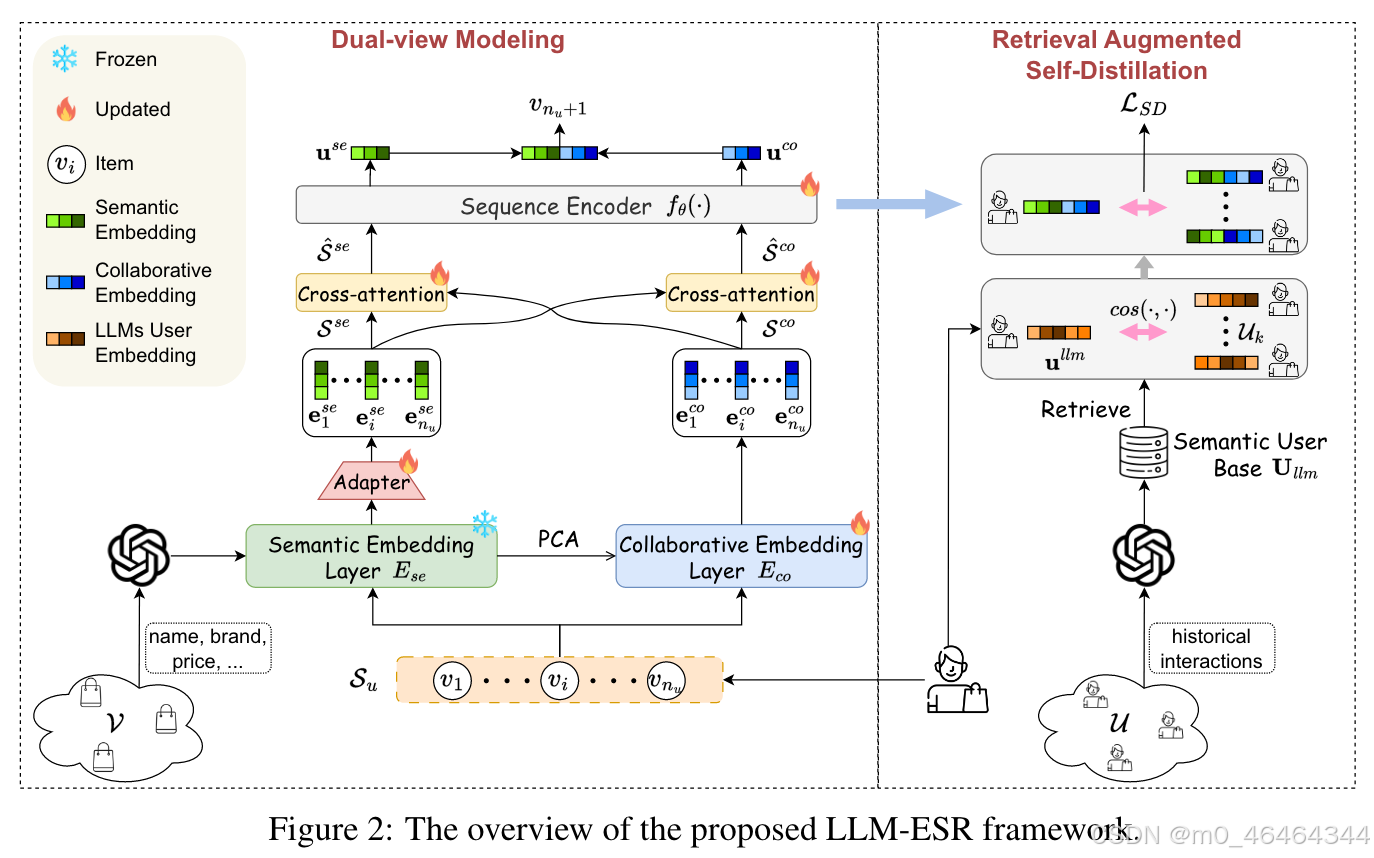
i) 双视图建模:该模块由两个分支组成。一个是语义视图建模,旨在从用户的交互序列中提取语义信息。它首先利用从物品嵌入派生的语义嵌入层对物品进行编码。接着,设计一个适配器用于维度适配和空间变换。输出的物品嵌入序列将被送入交叉注意力机制进行融合,然后通过序列编码器获取语义视图下的用户表示。另一个分支是协同视图建模,它通过协同嵌入层将交互序列转换为嵌入序列。随后,经过交叉注意力和序列编码器,获得协同用户偏好。最后,将两个视图下的用户表示进行融合。
ii) 检索增强自蒸馏:该模块旨在通过相似用户的有信息交互来增强长尾用户。首先,将派生的用户嵌入视为语义用户基础,用于检索相似用户。然后,将相似用户输入双视图建模以获取用户表示,这些表示将作为自蒸馏的引导信号。最后,派生的蒸馏损失将作为用于训练的辅助损失。
3.2双视图建模
3.2.1语义视图建模
本文通过公共API获得LLM嵌入,并提前缓存,以减少LLM的推理负担。设 E s e ∈ R ∣ V ∣ × d llm E_{se} \in \mathbb{R}^{|V| \times d_{\text{llm}}} Ese∈R∣V∣×dllm 表示所有物品的LLM嵌入,其中 d llm d_{\text{llm}} dllm 是LLM嵌入的维度。来自LLM的语义嵌入层 E s e E_{se} Ese 可用于语义视图建模,以增强长尾物品。为了保留语义,本文冻结 E s e E_{se} Ese ,并使用适配器将原始语义空间转换为推荐空间。
对于每个物品
i
i
i,可以通过获取
E
s
e
E_{se}
Ese 的第
i
i
i 行来得到其LLM嵌入
e
i
l
l
m
e^{llm}_i
eillm。然后,将其输入到可调适配器中以获得语义嵌入:
其中,W和b是适配器的权重矩阵和偏置。通过这一过程,可以获得用户交互记录的物品嵌入序列,记作
S
s
e
=
[
e
1
s
e
,
…
,
e
n
u
s
e
]
S^{se} = [e^{se}_1, \ldots, e^{se}_{n_u}]
Sse=[e1se,…,enuse]。
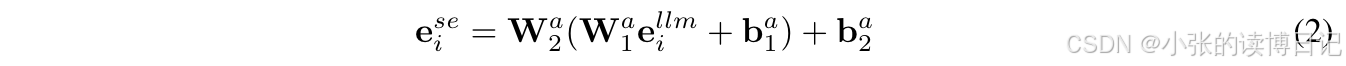
获得用户交互记录的物品嵌入序列之后,通过序列编码器获取用户偏好的语义视图表示:
其中,
θ
\theta
θ 表示序列推荐系统模型中序列编码器的参数。
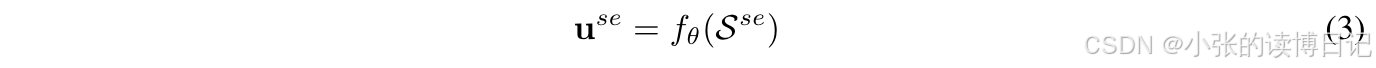
3.2.2协同视图建模
为了利用协同信息,采用一个可训练的物品嵌入层,并通过交互数据进行监督更新。设 E c o ∈ R ∣ V ∣ × d E_{co} \in \mathbb{R}^{|V| \times d} Eco∈R∣V∣×d 表示物品的协同嵌入层。然后,通过从 E c o E_{co} Eco 中提取相应的行,获得物品嵌入序列 S c o = [ e 1 c o , … , e n u c o ] S^{co} = [e^{co}_1, \ldots, e^{co}_{n_u}] Sco=[e1co,…,enuco]。为了在协同视图中获取用户偏好 u c o u^{co} uco,将嵌入序列输入到序列编码器中,即 u c o = f θ ( S c o ) u^{co} = f_{\theta}(S^{co}) uco=fθ(Sco)。
序列编码器 f θ f_{\theta} fθ 在语义视图和协同视图中是相同的,以便共享序列模式并提高效率。此外,这两个视图中的嵌入层处于不平衡的训练阶段(一个是预训练的,而另一个是从头开始的),这可能导致优化困难。为了解决这个问题,通过降维后的 E s e E_{se} Ese 来初始化 E c o E_{co} Eco。本文采用主成分分析(PCA)作为降维方法。
3.2.3两级融合
本文为双视图建模模块设计了一种两级融合方法,即序列级融合和逻辑级融合。前者旨在隐式捕捉双视图物品序列之间的相互关系,而后者则明确针对推荐能力的结合。具体而言,提出了一种用于序列级融合的交叉注意力机制。
将
S
s
e
S^{se}
SseS^{se} 视为查询,将
S
c
o
S^{co}
ScoS^{co} 视为注意力机制中的键和值。设
Q
=
S
s
e
W
Q
Q = S^{se} W^Q
Q=SseWQ,
K
=
S
c
o
W
K
K = S^{co} W^K
K=ScoWK,
V
=
S
c
o
W
V
V = S^{co} W^V
V=ScoWV,其中W是权重矩阵。交互的协同嵌入序列可以表述如下:
按照相同的交叉注意力过程,也可以得到相应的语义嵌入序列
S
^
s
e
\hat{S}^{se}
S^se。最后,将
S
s
e
S^{se}
Sse 和
S
c
o
S^{co}
Sco 替换为
S
^
s
e
\hat{S}^{se}
S^se 和
S
^
c
o
\hat{S}^{co}
S^co 以输入到
f
θ
(
⋅
)
f_{\theta}(\cdot)
fθ(⋅) 中。
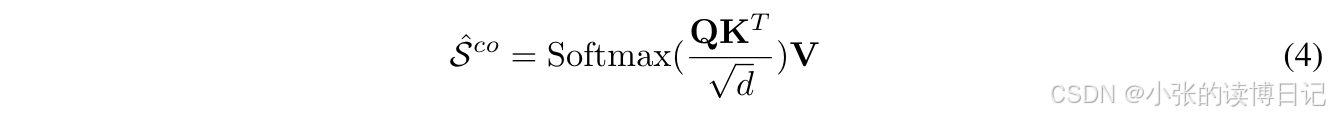
对于逻辑级融合,本文将两个视图的用户和物品嵌入拼接以进行推荐。因此,计算用户
u
u
u 推荐物品
j
j
j 的概率得分为:
其中 “:” 表示两个向量的拼接操作。基于概率得分,采用成对排名损失来训练该框架:
其中
v
k
+
1
+
v^+_{k+1}
vk+1+ 和
v
k
+
1
−
v^-_{k+1}
vk+1− 分别是真实项目和配对的负项目。值得注意的是,排名损失可能会根据不同的基础模型略有不同。
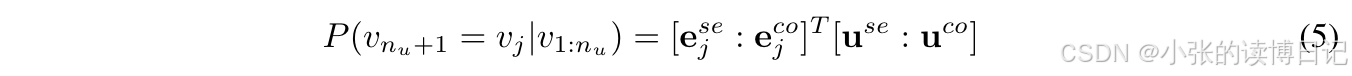
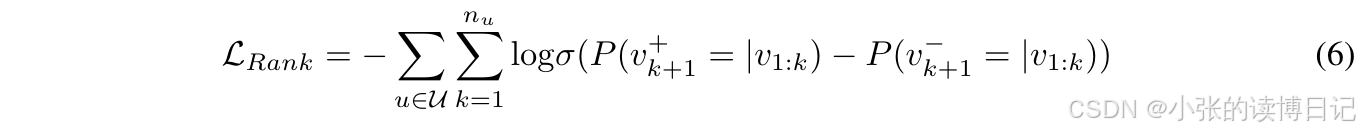
3.3检索增强自蒸馏
3.3.1检索相似用户
类似于LLM物品嵌入
E
s
e
E_{se}
Ese 的推导,可以获得并保存LLM用户嵌入,记作
U
l
l
m
∈
R
∣
U
∣
×
d
l
l
m
U_{llm} \in \mathbb{R}^{|U| \times d_{llm}}
Ullm∈R∣U∣×dllm。在本文中也被称为语义用户基础,因为其中编码了语义关系。对于每个目标用户
k
k
k,可以按如下方式检索相似用户集
U
k
U_k
Uk:
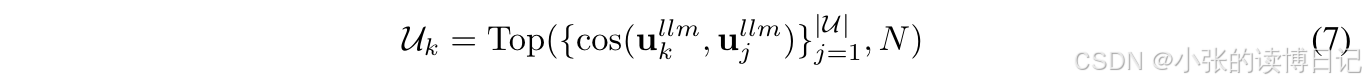
其中 cos ( ⋅ , ⋅ ) \text{cos}(\cdot, \cdot) cos(⋅,⋅) 是余弦相似度函数,用于测量两个向量之间的距离。 N N N 表示相似用户集的大小,是一个超参数。
3.3.2自蒸馏
本文设计了自蒸馏以将知识从多个相似用户转移到目标用户。由于用户偏好的表示,即
u
s
e
u^{se}
use 和
u
c
o
u^{co}
uco,编码了用户的综合知识,因此将这种表示配置为蒸馏的中介。为了获取教师中介,首先利用双视角建模框架为每个相似用户获取用户表示,记作
{
u
j
s
e
,
u
j
c
o
}
j
=
1
∣
U
k
∣
\{u^{se}_j, u^{co}_j\}_{j=1}^{|U_k|}
{ujse,ujco}j=1∣Uk∣。然后,通过平均池化计算教师中介,如下公式所示:
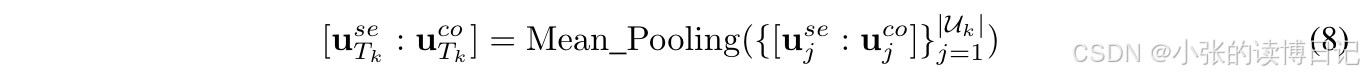
学生中介是目标用户
k
k
k 的表示,即
[
u
k
s
e
:
u
k
c
o
]
[u^{se}_k:u^{co}_k]
[ukse:ukco]。基于教师和学生中介,自蒸馏损失可以表述为:
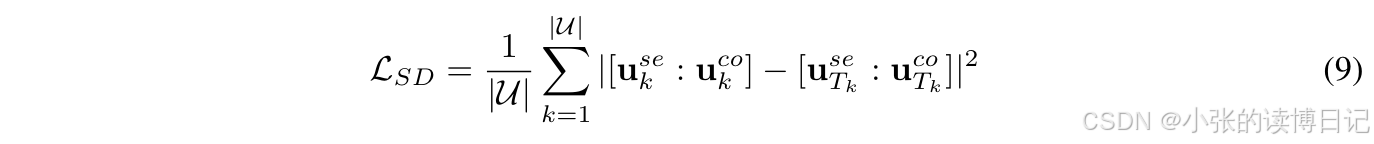
3.4训练和推理
3.4.1训练
根据第3.2节和第3.3节的说明,在训练过程中仅更新协同嵌入层、适配器、交叉注意力和序列编码器,同时冻结语义嵌入层和语义用户基础。由于原始的LLMs嵌入被冻结,原始的语义关系得到了很好的保留。优化的训练损失是成对排名损失和自蒸馏损失的组合:
其中
α
\alpha
α 是一个超参数,用于调整自蒸馏的幅度。
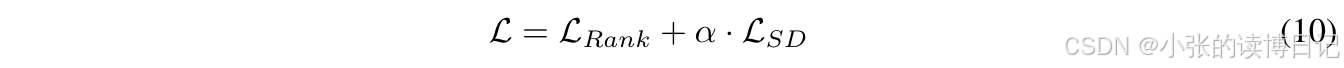
3.4.2推理
在LLM-ESR的推理过程中,由于不需要辅助损失,因此免除了检索增强自蒸馏模块。因此,按照双视角建模过程通过公式 (5) 进行最终推荐。此外,由于语义嵌入层可以提前缓存,避免了对LLM的调用,从而防止了额外的推理成本。
4.实验
4.1实验设置
数据集:Yelp、Amazon Fashion和Amazon Beauty。
基线:CITIES、MELT、RLMRec和LLMInit。
评估指标:HR@10和NDCG@10。
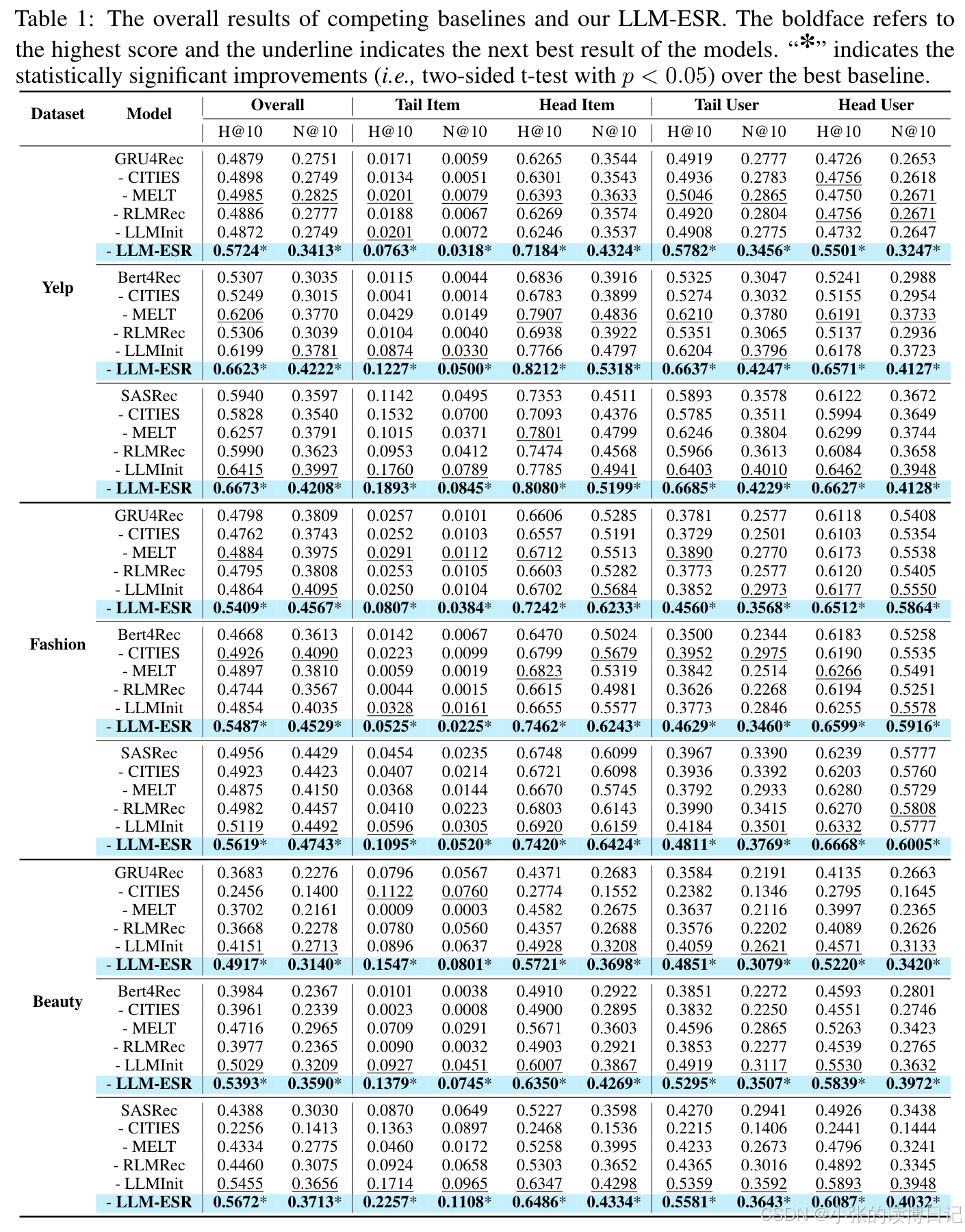
4.2总体性能
结论:
-
LLM-ESR在两个指标下均领先整体性能,表明其增强效果更好。
-
LLM-ESR在长尾项目和头部项目中都表现最佳,这种性能比较突显了双视角建模中语义与协同信号结合的优势。
-
LLM-ESR在三个基础模型上获得了最大的性能提升,表明了LLM-ESR的灵活性。
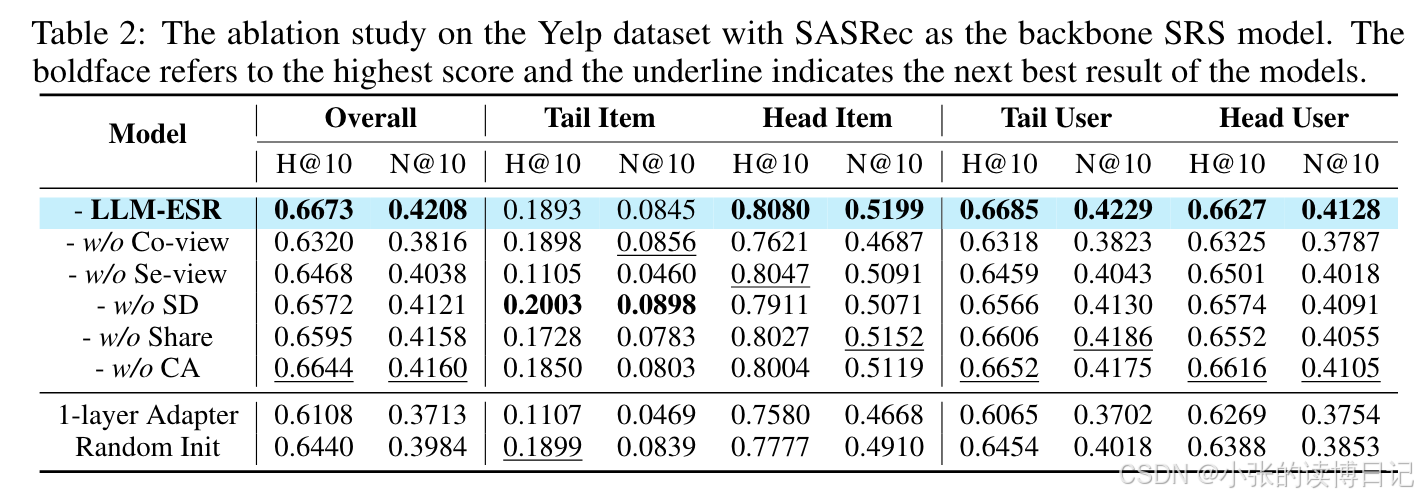
4.3消融实验
结论:
-
w/o Co-view在头部组的性能显著下降,而w/o Se-view对长尾项目的影响明显。表明了协作信息和语义信息的独特性,突显了两者结合的重要性。
-
w/o SD 表示去掉自蒸馏,结果显示长尾用户的性能下降。这表明了所提出的检索增强自蒸馏的效果。
-
w/o Share 和 w/o CA性能的下降证明了共享设计和序列级融合的有效性。
4.4超参数分析
结论:
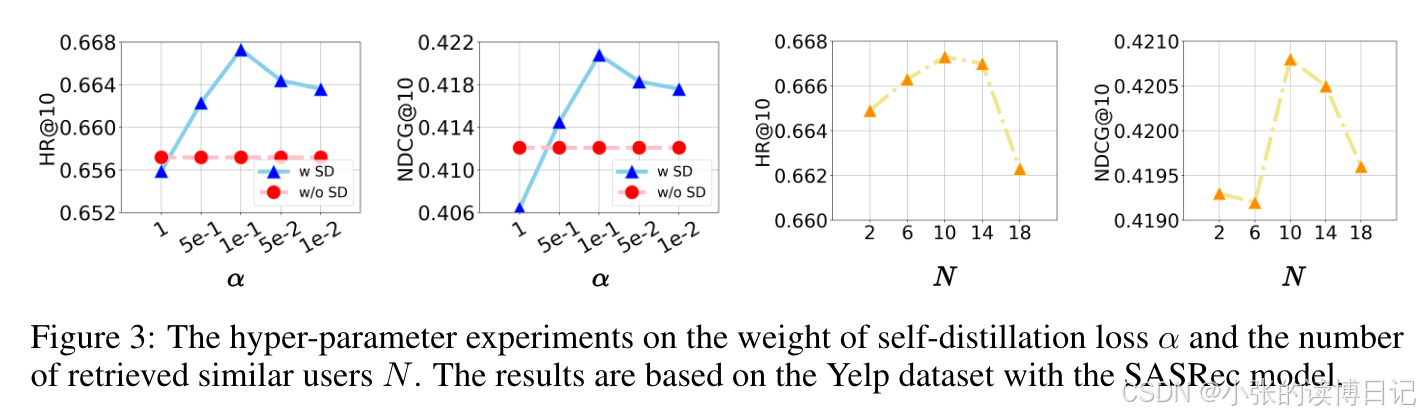
-
当 α 从 1 降至 0.01 时,推荐准确度先上升后下降。α 过大导致性能下降的原因在于过于强调自蒸馏会影响排名损失的收敛。较小的 α 也会降低性能,这表明设计的自蒸馏是有用的。
-
检索用户数量 N 的最佳值为 10。原因在于更多的用户可以提供更具信息性的交互。然而,过大的 N 可能会降低检索用户之间的相关性。
5.总结
针对长尾用户和长尾项目的挑战,本文提出了大模型增强框架LLM-ESR。首先,获取并缓存源自LLM的语义嵌入,以提高推理效率。然后,提出一种双视图建模框架,将LLM的语义与传统模型中包含的协同信息相结合,增强长尾项目。同时,设计检索增强自蒸馏来缓解长尾用户的挑战。全面的实验验证了LLM-ESR的有效性和灵活性。