urllib是Python自带的标准库,无需安装,可以直接使用。
urllib库分为四个大的模块,分别是:
1、urllib.request 请求模块
2、urllib.error异常处理模块
3、urllib.parse解析模块
4、urllib.robotparser robot.txt文件解析模块
1、首先是request模块的urlopen函数,我们来看一下其参数的介绍:
urllib.request.urlopen(url, data=None, [timeout, ])
传入的url就是你想抓取的地址;
data是指向服务器提交信息时传递的字典形式的信息,通常来说就是爬去需要登录的网址时传入的用户名和密码,可省略。
timeout参数指的是超时时间,也可省略。
下面我们试举一例,来抓取新浪首页,并保存到本地:
import urllib.request as eq
url='https://www.sina.com.cn/'#抓取的网址
file=eq.urlopen(url).read()#读取信息
path=open('D:/python36/pachong/网页/sina.html','wb')#已写入二进制的方式创建文件
path.write(file)#写入爬下的信息
path.close()#关闭文件运行之后,我们在对应路径下的文件结果如下:
打开爬下来的名为sina的文件:
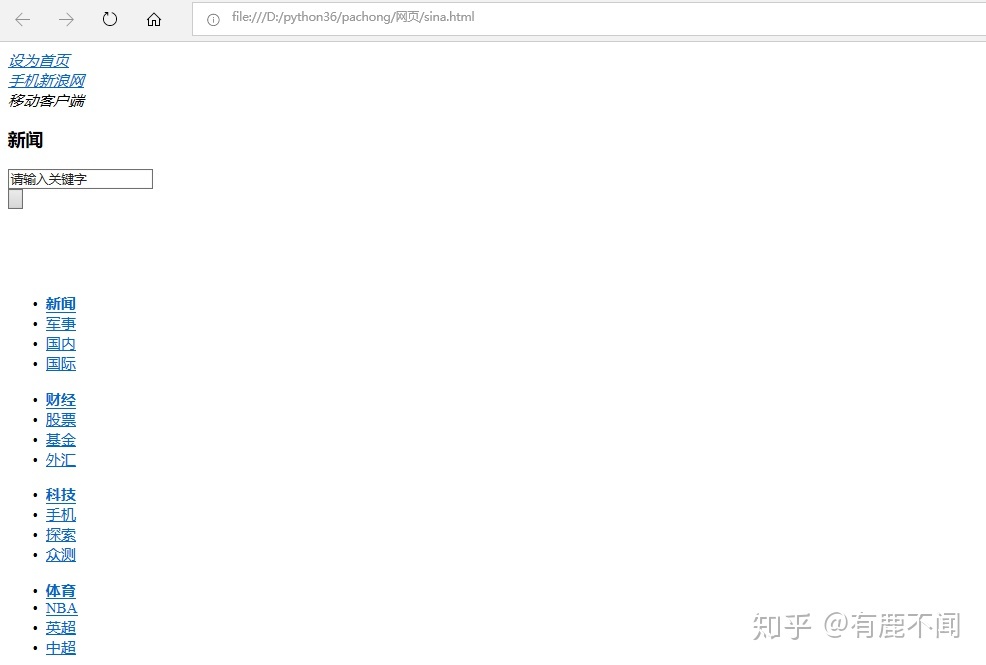
此时,新浪网首页被我们抓取下来。
2、添加头信息。
在抓取网页的时候,我们会遇到一些反爬虫的设置,比如说服务器读取到请求为爬虫时会出现403错误,这是我们就需要伪装成为浏览器来访问,此时要添加头信息。在network(网络)的选项中选取user-agent选项,复制下来。
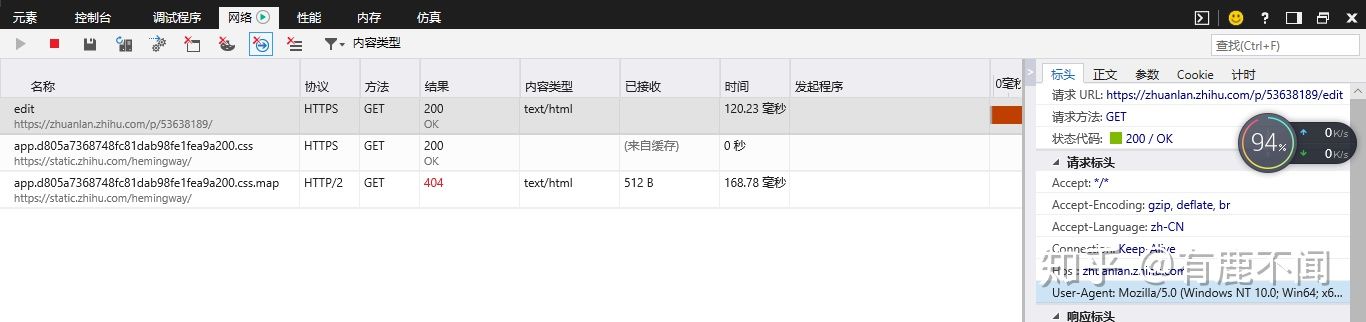
我的头信息是这样的:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134
有了头信息,上述代码我们可以修改一下:
import urllib.request as eq
url='https://www.sina.com.cn/'#抓取的网址
req=eq.Request(url)#创建Request对象
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134')#添加头信息
file=eq.urlopen(url).read()#读取信息
path=open('D:/python36/pachong/网页/sina.html','wb')#已写入二进制的方式创建文件
path.write(file)#写入爬下的信息
path.close()#关闭文件此时我们已经伪装成了浏览器。
3、代理服务器设置。
现在我们已经学会了伪装成浏览器去抓取网页,那么如果遇到更厉害的反扒手段,发现某一个IP频繁访问网址,会被服务器屏蔽,那么该怎么办呢?这是就需要代理服务器上场了。
首先代理服务器在百度上搜索一下,有很多,我们随便点进去一个:
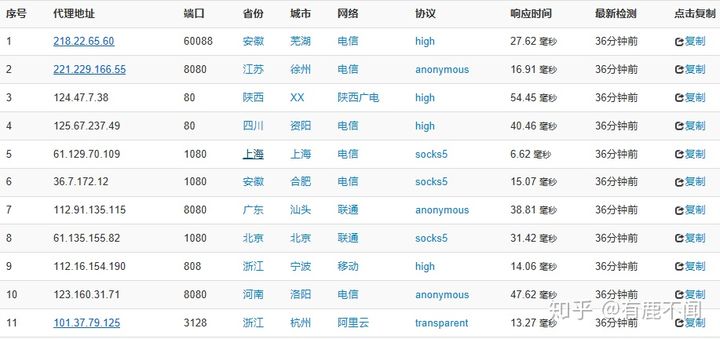
我们选取第一个:218.22.65.606:0088即IP:端口号
接下来,我们上述代码可以修改成如下:
import urllib.request as eq
url='https://www.sina.com.cn/'#抓取的网址
req=eq.Request(url)#创建Request对象
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134')#添加头信息
IP=eq.ProxyHandler({'http':218.22.65.606:0088})#设置代理服务器信息
opener=eq.build_opener(IP,eq.HTTPHandler)#自定义打开方式,传入代理服务器信息和HTTPHandler类
file=opener.open(req).read()#读取信息
path=open('D:/python36/pachong/网页/sina.html','wb')#已写入二进制的方式创建文件
path.write(file)#写入爬下的信息
path.close()#关闭文件4、post请求,即模拟登陆。
所谓模拟登陆,当然需要输入账号和密码了,在urllib库中该如何编写代码呢?
假设我们登陆某个网站,需要提交用户名和密码,在这里我们假设
用户名:id:明明
密码:password:123456
这里我们引入解析模块:urllib.parse
具体代码如下:
import urllib.request as eq
import urllib.parse as pa
url='www.youlubuwen.com'#假设的网站网址
post=pa.urlencode({'id':'明明','password':'123456'}).encode('utf-8')
req=eq.Request(url,post)#传入用户名和密码,并使用urlencode编码字典,再设置为utf-8编码
req.add_header(Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134)
data=eq.urlopen(req).read()#添加头信息
print(len(data))
5、异常处理
此处引入了urllib库的urllib.error异常处理模块
一般来讲,产生URLError的原因如下:
a、连接不到服务器
b、url不存在
c、无网络
d、触发了HTTPError
而HTTPError作为URLError的子类,是无法处理前abc前三种情况的,因此构造异常处理,我们可以先用子类HTTPError处理,如果子类处理不了,再用父类URLError处理,构造代码如下:
import urllib.request as eq
import urllib.error as er
try:
代码块1
except er.HTTPError as e:
print(e.code)#输出异常状态
print(e.reason)#输出异常原因
except er.URLError as e:
print(e.code)
print(e.reason)
6、保存cookie信息
什么cookie 呢 ?我们举个例子。假如你打开了知乎,输入了账号密码,登陆到 知乎 首页,这时如果你随机打开一个连接,跳转到知乎的某个问题下,是不是 不用 再 继续 登陆 了呢?这时因为在客户端保存了你的cookie信息,而爬虫是不会自动保存cookie 的 ,因此我们需要手动设置,代码如下:
import http.cookiejar as co#导入模块
import urllib.request as eq
scookie=co.CookieJar()#创建对象
opener=eq.buile_opener(eq.HTTPCookieProcessor(scookie))#传入创建的对象
opener.open(url)