K_means聚类是我们在无监督学习中常用的一种算法,但有一个很让人头疼的问题就是如何选择k值。在实际业务中,如果根据业务场景明确知道要得到的类数,那就好办了,但很多时候不知道K怎么办呢?下面有三种方法可以用来确定k值,其基本思想还是最小化类内距离,最大化类间距离,使同一簇内样本尽可能相似,不同簇中样本尽可能不相似。
1.肘部法
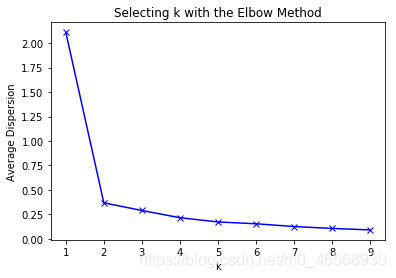
随着k值增大,误差值会越来越小(举一个极端的例子:当每一个样本被分为一个类时,类内间距最小,但这显然不是我们想要的),因此可根据不同k值下的误差曲线选择使误差平方和下降最快的k值,当大于此k值时,k值增大,但误差减少量很小。即选择曲线上的拐点最佳。在下面这个图中即选择k=2,将样本分为两类。
2.轮廓系数
结合内聚度和分离度两种因素,可以用来在相同原始数据的基础上评价不同方法,也可以评价算法不同运行方式对聚类结果所产生的影响。使用轮廓系数时先假设已经通过聚类将数据分成了k个簇,对簇中的每个向量,计算其轮廓系数。
任意点i的计算公式为: