- 亲爱的探索者,当你踏入这片文字的海洋,你必定是那颗熠熠生辉、追逐前沿的星辰。然而,请允许我先为你铺设一条略带曲折的航道,因为尽管我将倾囊相授,这些知识的宝藏却如同浩渺的星河,深远而辽阔。但请坚定你的步伐,鼓起你的勇气,因为在这条求知的路上,每一步都充满了挑战与机遇。让我们携手共进,砥砺前行,用无尽的热情和毅力,书写属于我们的传奇。加油,探索者,让知识的光芒照亮你前行的道路!
一、引言
在现今的软件架构中,微服务架构因其高度的模块化、可扩展性和灵活性而备受青睐。然而,随着服务数量的增多和复杂性的增加,如何确保这些微服务能够稳定、高效地运行,成为了摆在每一个开发人员和运维人员面前的难题。服务监控,作为保障微服务稳定运行的重要手段,其重要性不言而喻。
二、 解释(什么是服务监控)
微服务监控是指对微服务架构中的各个服务进行实时、全面的性能、状态和安全等方面的监测与管理。在微服务架构中,由于服务众多且相互依赖,任何一个服务的故障都可能引发连锁反应,导致整个系统的崩溃。因此,微服务监控显得尤为重要。
三、微服务监控关注的方面
- 实时掌握系统中各个服务的运行状态和性能指标,包括服务的响应时间、吞吐量、错误率等,以便及时发现并处理异常情况,避免故障扩散和升级。
- 监控服务间的依赖关系,确保服务之间的调用正常进行,及时发现并解决服务调用中的问题。
- 监控服务的并发量和负载情况,以便根据实际需求调整服务的资源配置,保证服务的稳定性和高可用性。
- 监控服务的日志和错误信息,以便及时记录并进行监控和分析,快速定位并解决问题。
本文我们将用springboot,spring boot actuator,docker,Prometheus,Grafana,alertManager 实现服务的监控告警组件介绍:
- Spring Actuator
是Spring Boot提供的一个功能强大的管理和监控工具,用于监控和管理Spring Boot应用程序。它提供了一系列的端点endpoints),通过这些端点,我们可以轻松地获取应用程序的运行时信息、健康状况、性能指标、日志等。 - Prometheus
一个开源系统监控和告警工具包,提供了高效的时间序列数据库、简单的安装和配置、多样的数据模型及查询语言。 - Grafana
- 一个跨平台的开源分析和监控解决方案,与Prometheus通常搭配使用,提供了丰富的仪表盘和图表,用于数据的可视化展示。
- Alertmanager
- 是Prometheus生态中非常重要的一个核心模块,主要用于接收Prometheus发送的告警信息,并对其进行统一处理。它支持丰富的告警通知渠道,如电子邮件、待命通知系统和聊天平台等,且很容易实现告警信息的分组、静默、抑制等功能。
架构图:
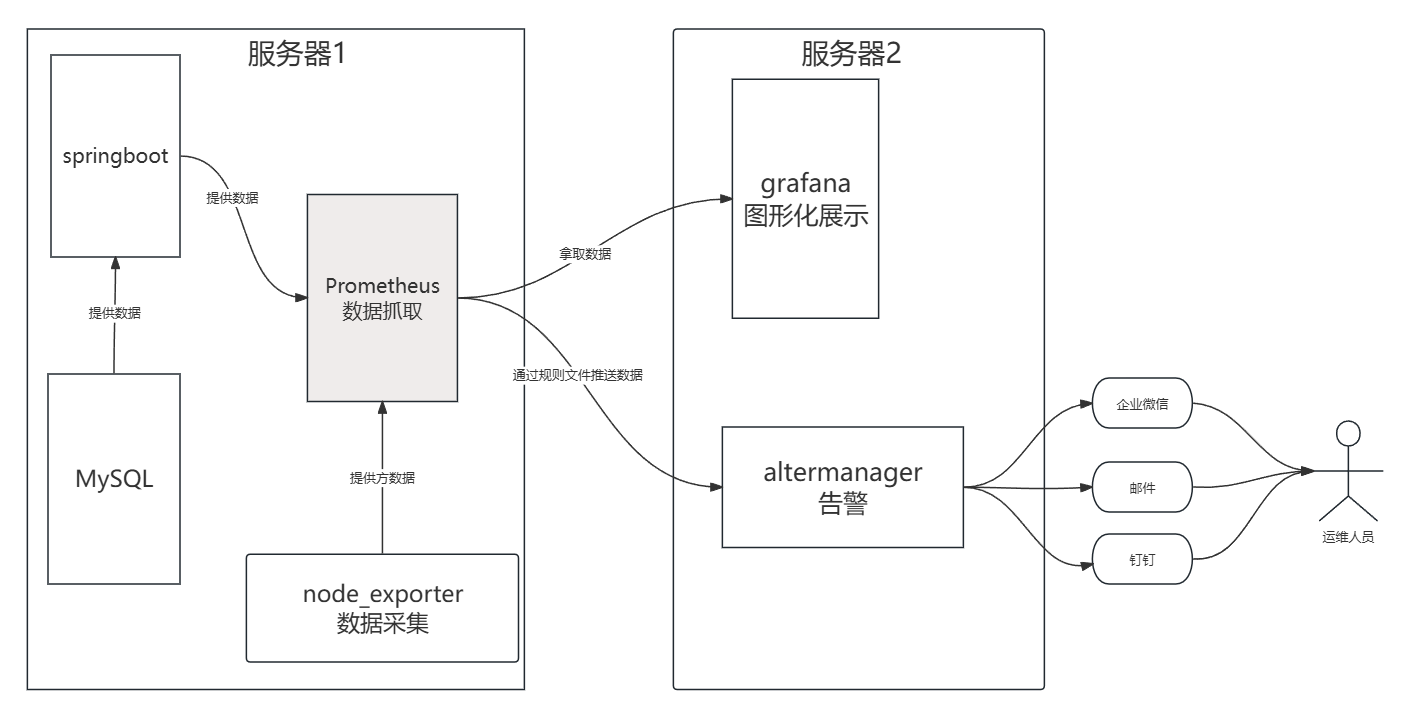
- 这个图就是本文要实现的架构图,如果看不懂没关系,接下来我们会一给我一个实现哦。
四、springboot项目搭建
spring boot项目搭建就不过多赘述
- 项目结构
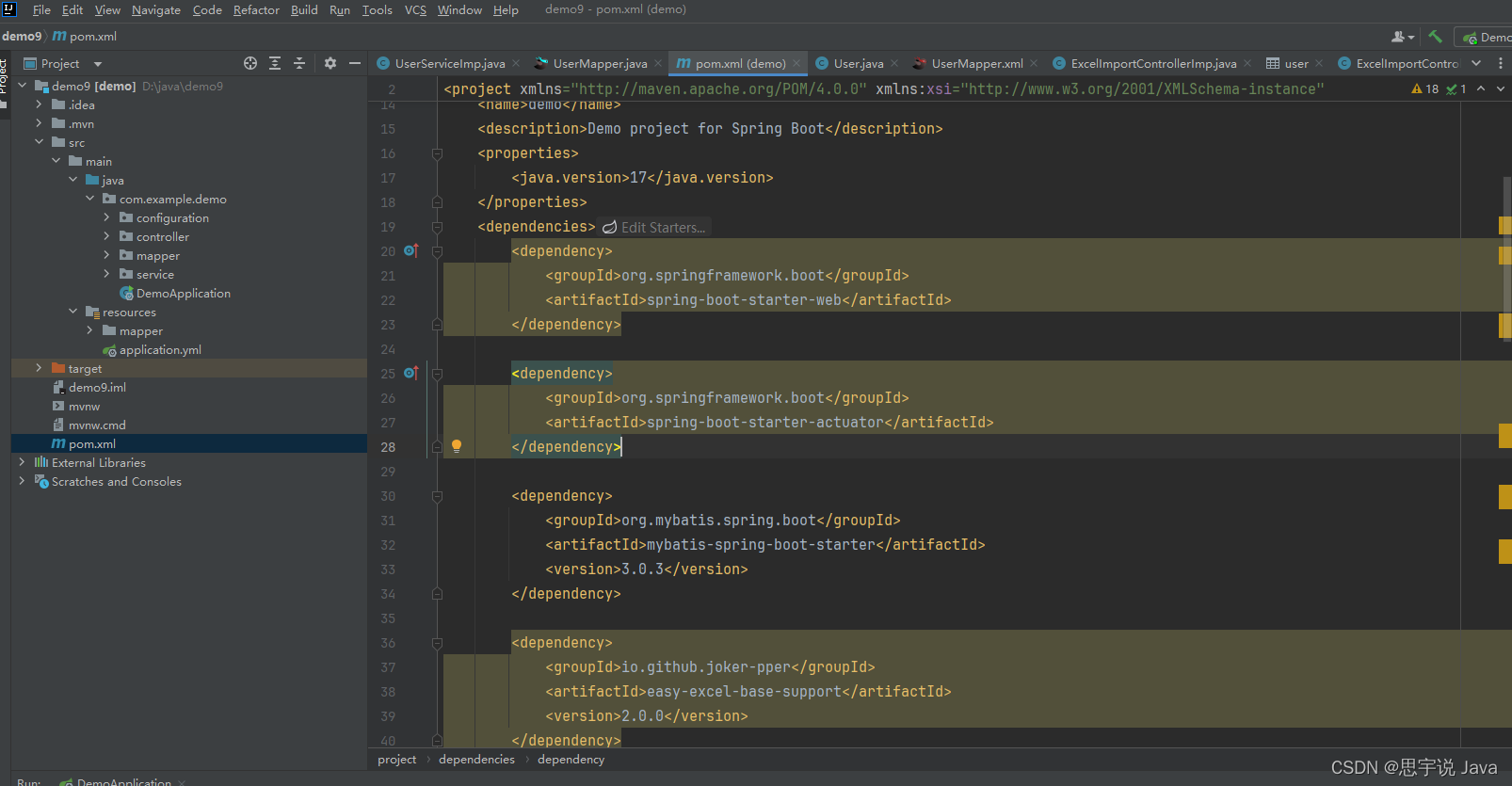
- controller:
- 添加依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
- 在application.yml 中配置spring boot autuator
management:
endpoints:
web:
exposure:
include: "*"
exclude: configprops
base-path: /actuator
enabled-by-default: true
endpoint:
health:
show-details: always
metrics:
tags:
application: "demo"
这是什么意思呢?
management.endpoints.web.exposure.include 和 exclude
- include: “*”:这个配置表示所有Actuator的web端点都将被包含(即对外暴露)。星号(*)是一个通配符,代表所有端点。
- exclude: configprops:尽管include设置了星号,但exclude会覆盖它,并明确排除configprops端点。configprops端点用于显示所有@ConfigurationProperties的配置属性。
management.endpoints.web.base-path
- 这个配置设置了Actuator web端点的基路径为/actuator。例如,如果你想要访问健康检查端点,你通常会访问/actuator/health(除非另有其他配置)。
management.endpoints.enabled-by-default
- 这个配置决定了默认情况下是否启用Actuator的端点。在这里,它被设置为true,意味着所有的端点默认情况下都是启用的(通过其他配置进行覆盖)。
management.endpoint.health.show-details
- 这个配置是关于健康检查端点的。它控制了在健康检查响应中应包含多少详细信息。always意味着无论应用程序的响应状态如何,都将显示详细信息。其他可能的值包括when-authorized(仅当授权用户请求时才显示)和never(从不显示)。
management.metrics.tags.application
- 这个配置用于为所有度量(metrics)添加一个标签(tag)。在这里,所有的度量都将有一个名为- application的标签,其值为demo。这对于在监控系统中区分不同的应用程序或实例非常有用。
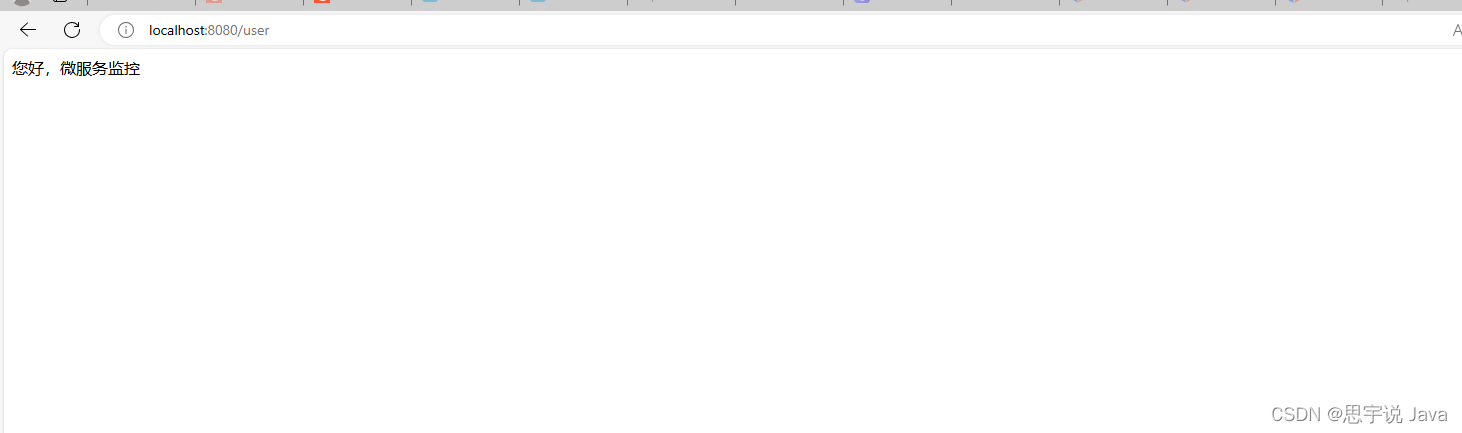
通过这些配置,您可以自定义Spring Boot Actuator的行为,以便更好地满足您的监控和管理需求。不过,请注意,暴露某些端点(特别是包含敏感信息的端点)可能会带来安全风险,因此请确保您已经采取了适当的安全措施来保护这些端点。 - 接下来我们把项目运行起来:并访问localhost:8080/user:
访问localhost:8080/actuator:
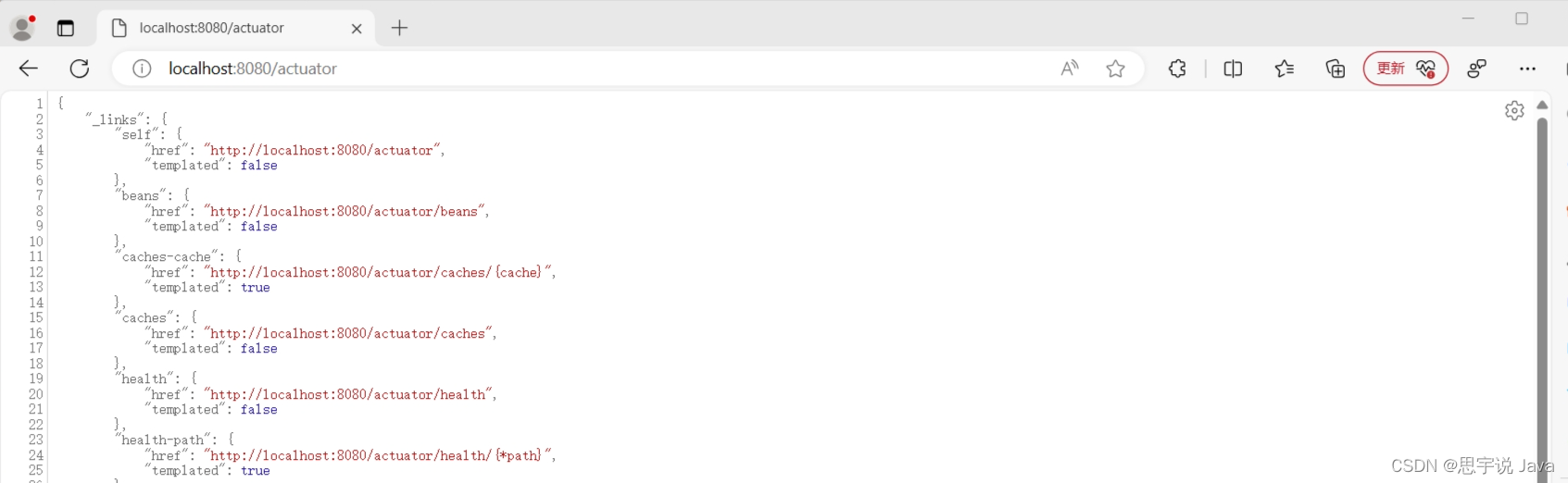
- actuator成功将数据暴露出来
- 当然你也可以访问这个链接看看,所有的链接都在暴露的数据里面
- 看到这里证明spring boot 整合spring boot actuator 项目已经完成。接下来我将带大家用docker 安装监控组件
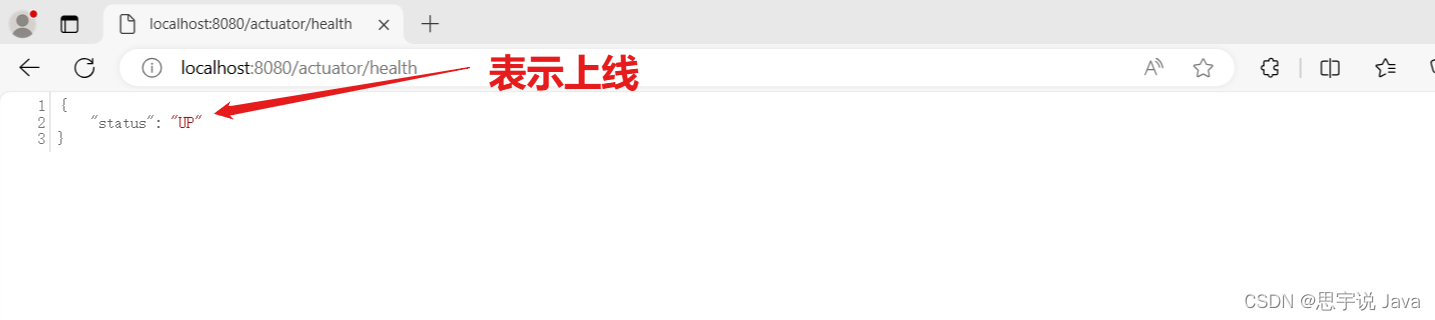
五、linux服务器安装docker
- 安装所需的依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
看到此图片恭喜你下载成功。但在我安装的时候由于操作问题导致了yum死锁,在这里给大家分享一下
Another app is currently holding the yum lock; waiting for it to exit...
The other application is: yum
Memory : 23 M RSS (419 MB VSZ)
Started: Fri May 17 13:40:58 2024 - 1:40:10 ago
State : Traced/Stopped, pid: 8640
Another app is currently holding the yum lock; waiting for it to exit...
The other application is: yum
Memory : 23 M RSS (419 MB VSZ)
Started: Fri May 17 13:40:58 2024 - 1:40:12 ago
State : Traced/Stopped, pid: 8640
当你看到这种日志时证明出现了yum死锁。yum死锁是什么问题呢?
解释:
当您在使用 yum(Yellowdog Updater Modified)工具时遇到这样的错误信息:“Another app is currently holding the yum lock; waiting for it to exit…”,这通常意味着有一个 yum 进程正在运行,并且已经获取了包管理器的锁,以防止其他 yum 进程同时运行并可能导致包管理状态不一致。
这个日志信息中,yum 进程处于 Traced/Stopped 状态,这通常不是一个正常的状态。
这个问题该如何解决呢?
- 查找并杀死进程:使用 ps 命令来查找 yum 进程,并使用 kill 命令来杀死它。杀死所有的yum进程
ps -ef | grep yum
sudo kill -9 <yum_pid> # <yum_pid> 是 yum 进程的 PID
请注意,在上面的 sudo kill -9 命令中,-9 是一个强制杀死进程的信号。通常,你应该首先尝试不带 -9 的 kill 命令,如果不起作用,再使用 -9
- 清除锁文件:
如果杀死进程不起作用,或者你不确定如何找到进程,你可以尝试手动删除锁文件。但请注意,这样做可能会导致包管理状态不一致,因此请仅在确定没有其他 yum 进程正在运行时才这样做。
sudo rm -f /var/run/yum.pid
sudo rm -f /var/cache/yum/__db*
删除这些文件后,再次尝试运行 yum 命令。运行成功,死锁问题已经解决
然后我们继续使用上面的依赖安装命令完成之后
- 为了上高速我们设置阿里云镜像源
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
- 设置成功后我们开始安装docker
注意
docker版本说明:
Docker从17.03版本之后分为两个版本:社区版(Community Edition,缩写为 CE)和企业版(Enterprise Edition,缩写为 EE)。
企业版包含了一些收费服务,个人开发者一般用不到,所以我们只需要安装社区版docker-ce版本即可。
- docker-ce安装
yum install -y docker-ce
恭喜你docker安装成功
- 启动docker 并设置开机自启动
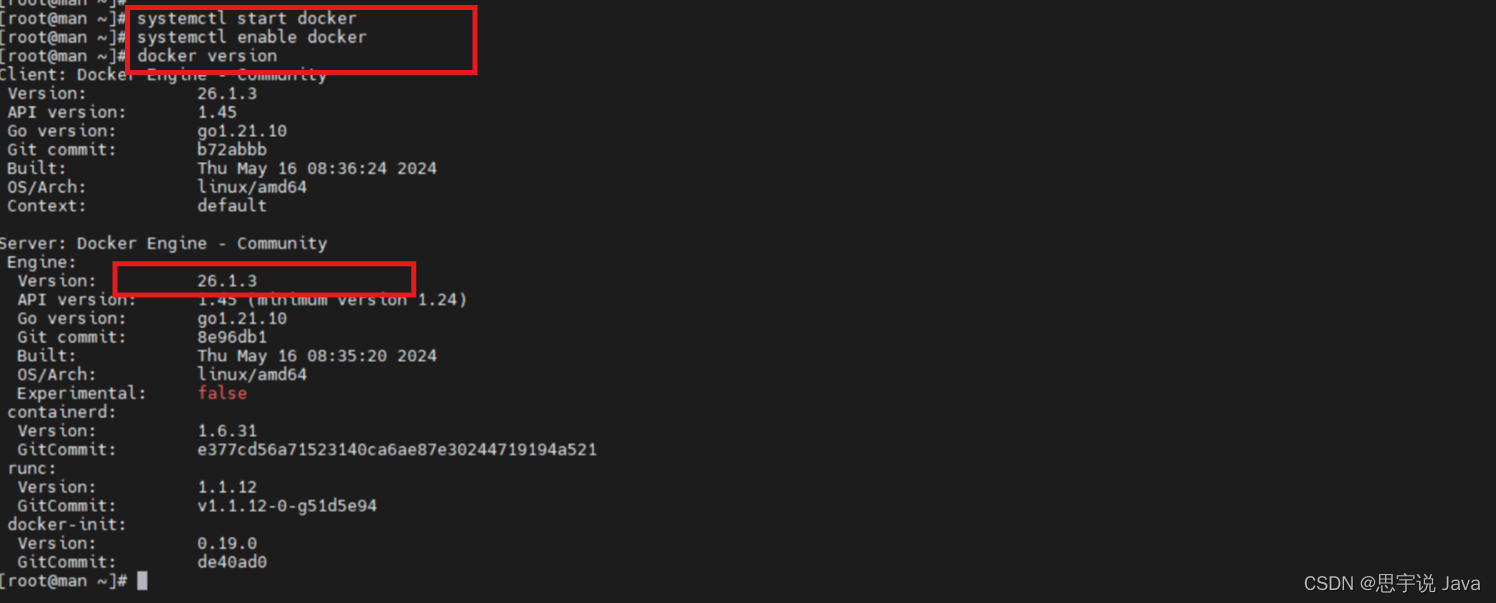
#启动docker命令
systemctl start docker
#设置开机自启命令
systemctl enable docker
#查看docker版本命令
docker version
恭喜你docker 安装启动完成,记下来我们一起全装监控组件Prometheus
六、Prometheus安装
介绍:
Prometheus是一个开源的服务监控系统和 时序数据库 ,它提供了通用的数据模型和快捷数据采集、存储和查询接口。
Prometheus的特点包括
- 易管理性:Prometheus的核心部分由一个单独的二进制文件构成,这使得它容易部署和管理。它可以在本地运行,不依赖于分布式存储系统。
- 高效性:Prometheus设计上能够处理大量的监控指标,即使是单个Prometheus实例也能够每秒处理数百万的数据点。
- 灵活性:Prometheus支持通过配置文件定义监控目标,用户可以根据自己的需求灵活配置监控项。
强大的查询语言:Prometheus提供了一个功能强大的查询语言PromQL(Prometheus Query Language),用户可以使用这个语言对收集到的时序数据进行查询和分析。
Prometheus的主要功能包括:
- 收集和存储时间序列数据:Prometheus能够从各种来源收集和存储时间序列数据,包括应用程序、服务、操作系统和网络设备等。
- 实时监控和警报:Prometheus可以实时监控各种指标,并根据预定义的规则进行警报和通知。它提供了一个灵活的警报管理系统,可以定义警报规则、接收警报通知,并对警报进行静音或处理。
- 多维数据模型:Prometheus使用时间序列数据模型,可以对多种维度的数据进行监控和分析。
- 高效的数据存储:Prometheus使用本地存储方式,可以高效地存储监控数据,而且支持数据压缩和数据刷写等功能。
docker安装prometheus
docker run --name prometheus -d -p 9090:9090 -v
/opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
prom/prometheus --config.file=/etc/prometheus/prometheus.yml
复制的时候请注意:这里是一条命令,小心换行符哦
命令解释:
这个 docker run 命令是用来启动一个 Docker 容器的,并且特别针对 prom/prometheus 这个镜像,该镜像是 Prometheus 监控系统的 Docker 镜像。下面我为你详细解释这个命令的每一个部分:
docker run:这是 Docker 的一个基本命令,用于从指定的镜像创建并启动一个新的容器。
–name prometheus:这个标志用于为新容器指定一个名称,这里是 prometheus。如果你不提供这个标志,Docker 会自动为容器生成一个随机名称。
-d:这个标志使容器在后台运行(即“detached”模式)。如果没有这个标志,容器将在前台运行,并且你会在终端中看到容器的输出。
-p 9090:9090:这个标志用于端口映射。它将宿主机的 9090 端口映射到容器的 9090 端口。这样,你就可以通过访问宿主机的 9090 端口来访问容器内的 Prometheus 服务。
-v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
这个标志用于挂载卷(volume)。它将宿主机上的 /opt/prometheus/prometheus.yml 文件挂载到容器内的 /etc/prometheus/prometheus.yml 路径。这样,容器内的 Prometheus 服务将使用宿主机上的 prometheus.yml 配置文件。
prom/prometheus:这是你想要从中创建容器的 Docker 镜像的名称。在这种情况下,它是 Prometheus 官方提供的 Docker 镜像
–config.file=/etc/prometheus/prometheus.yml:这个参数实际上可能是多余的,因为你已经通过 -v 标志将配置文件挂载到了容器内的正确位置。Prometheus 容器默认会查找 >/etc/prometheus/prometheus.yml 作为其配置文件。但是,如果你想要确保 Prometheus 使用这个文件(尽管它是默认的),或者你的 Prometheus 镜像需要这个参数来覆盖默认行为,那么你可以包含这个参数。
总的来说,这个命令的目的是启动一个名为 prometheus 的 Docker 容器,该容器运行 Prometheus 服务,并使用宿主机上的 /opt/prometheus/prometheus.yml 作为其配置文件。容器将在后台运行,并且宿主机的 9090 端口将映射到容器的 9090 端口,以便你可以访问 Prometheus 的 Web UI。
注意:
你的docker拉取的速度可能会很慢,直到你奔溃。放心我会帮你解决问题。
为什么会很慢?
因为你没有配置docker的镜像源,Docker默认的镜像源是Docker Hub。Docker Hub是Docker官方提供的一个公共镜像仓库,但需要注意的是,由于Docker Hub位于国外,访问速度可能受到网络环境的影响,会很慢。
该怎么解决?解决办法很简单:修改mirror,换成国内mirror(阿里云)。
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://yxzrazem.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
解释一下:
sudo 这是一个命令前缀,表示以超级用户(root)的权限执行命令。
mkdir: 这是创建目录的命令。
-p: 这个选项允许你创建多级目录,并且如果目录已经存在,则不会报错。
/etc/docker: 这是Docker的配置目录,用于存放Docker的配置文件。
tee: 这是一个用于读取标准输入并将其写入一个或多个文件的命令。同时,它也可以将文件内容输出到标准输出。
/etc/docker/daemon.json: 这是Docker守护进程的配置文件,用于配置Docker守护进程的各种参数。
<<-'EOF’: 这是一个“here document”的语法,它允许你将多行文本作为输入传递给命令。'EOF’是这里文档的结束标记,而前面的-意味着忽略这里的所有行首的制表符(tab)。
然后执行命令你会发现已经上高速了
docker run --name prometheus -d -p 9090:9090 -v
/opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus --
config.file=/etc/prometheus/prometheus.yml
命令执行完成后访问:http://your path:9090/你会看到
恭喜你Prometheus安装成功
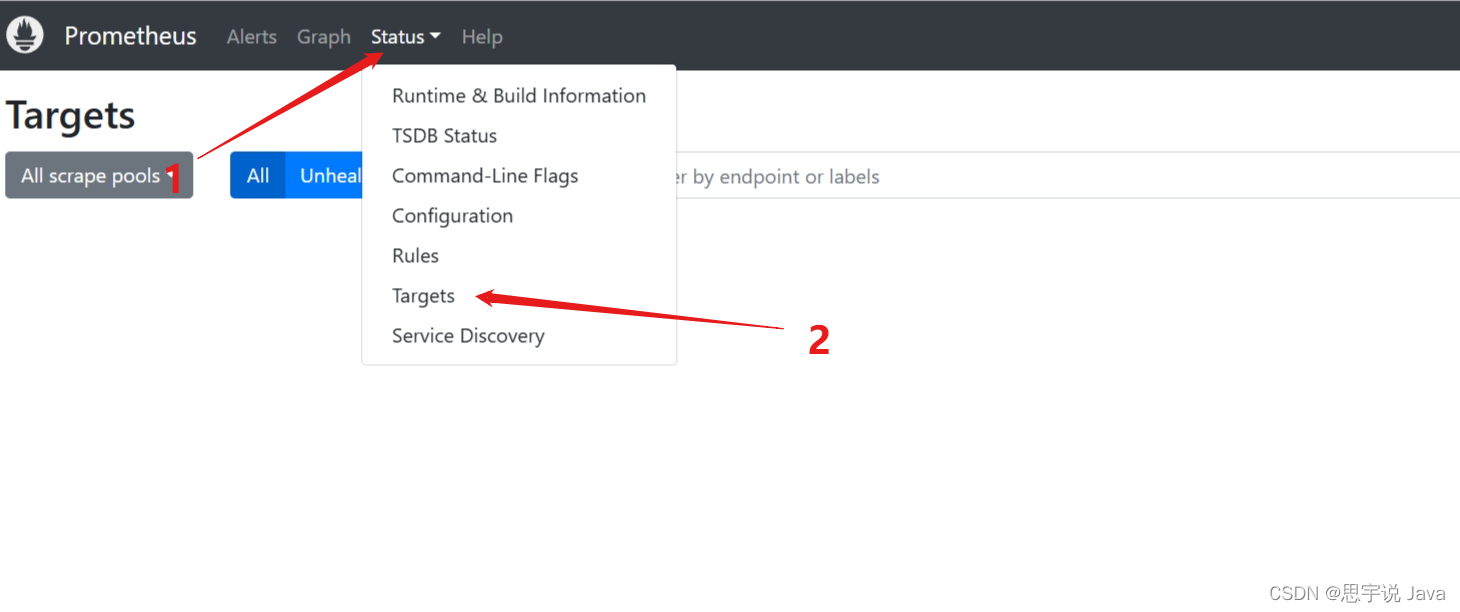
这时你点击targets发现没有任何数据,当然没有啦,有才怪呢,因为我们没有配置让Prometheus去哪里拿数据。
接下来我们配置让Prometheus去springboot项目里拿数据
还记的这条命令吗?
docker run --name prometheus -d -p 9090:9090 -v
/opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
prom/prometheus --config.file=/etc/prometheus/prometheus.yml
启动prometheus时我们在将它的配置文件prometheus.yml 挂到了 /opt/prometheus/这个目录下
首先停止启动 Prometheus docker 容器
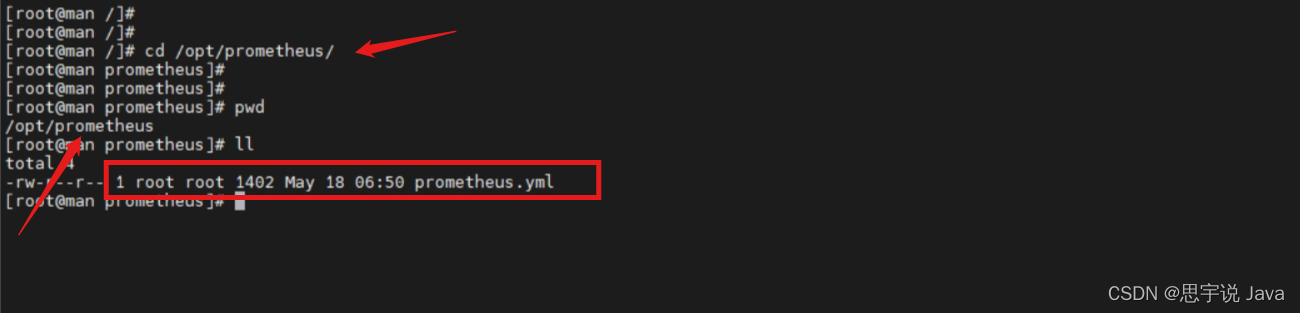
查找启动的docker 容器
docker ps
docker stop CONTAINER ID
接下来我们开始配置这个文件(注意:这是一个yml文件,遵循严格的缩进)

global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 # Uncomment and set to your Alertmanager instance address
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs: # 注意修正拼写错误为 scrape_configs
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# 示例:其他 job 配置可以添加在这里
- job_name: 'springboot'
metrics_path: '/actuator/prometheus'
scheme: 'http'
static_configs:
- targets: ['yourIP:8080']
这段配置是什么意思呢?别害怕。在这里我会做出详细解释
全局配置 (global):
- scrape_interval: 设置为 15 秒,意味着 Prometheus 每 15 秒从目标端点抓取一次监控数据。默认值是 1 分钟。
- scrape_timeout:这个值代表 Prometheus 在等待目标端点响应时的超时时间。默认值是 10 秒。
- Alertmanager 配置 (alerting):
定义了 Prometheus 如何与 Alertmanager 通信以发送警报。在这个例子中,配置了一个静态的 Alertmanager 目标,但是地址(alertmanager:9093)被注释掉了。你需要取消注释并设置为你自己的 Alertmanager 实例地址。(想要了解,请阅读后文) - 规则文件 (rule_files):
允许你指定一个或多个包含告警规则的 YAML 文件。在这个例子中,两个示例规则文件被注释掉了,但你可以取消注释并指向你自己的规则文件。(想要了解,请阅读后文) - 第一个 job_name: ‘prometheus’ 是 Prometheus 自身的监控配置,它默认从 localhost:9090(Prometheus 的默认端口)抓取数据。
- 第二个 job_name: ‘springboot’ 是为 Spring Boot 应用程序配置的。它从 yourIP:8080(这里的 yourIP 需要替换为实际的 IP 地址或主机名)的 /actuator/prometheus 路径抓取数据。/actuator/prometheus 是 Spring Boot Actuator 提供的 Prometheus 监控端点。
现在我们主要配置的就是这个片段:
# 示例:其他 job 配置可以添加在这里
- job_name: 'springboot'
metrics_path: '/actuator/prometheus'
scheme: 'http'
static_configs:
- targets: ['yourIP:8080']
配置完成后,重启Prometheus docker 容器
docker ps -a
docker start CONTAINER ID
重启成功后你去看:http://your path:9090/ 你会神奇的发现targets里依然没有任何数据
注意: 我们的spring boot 项目启动在本地,只能在局域网里访问,当然可能有一些技术能结局(内网穿透等技术),但我们是Java程序员,可能对这方面不太了解,那怎么办呢?那就用程序员的方式解决
直接用docker把我们的Java项目打包部署到服务器上,开始喽~~
- 首先用maven打包spring boot项目
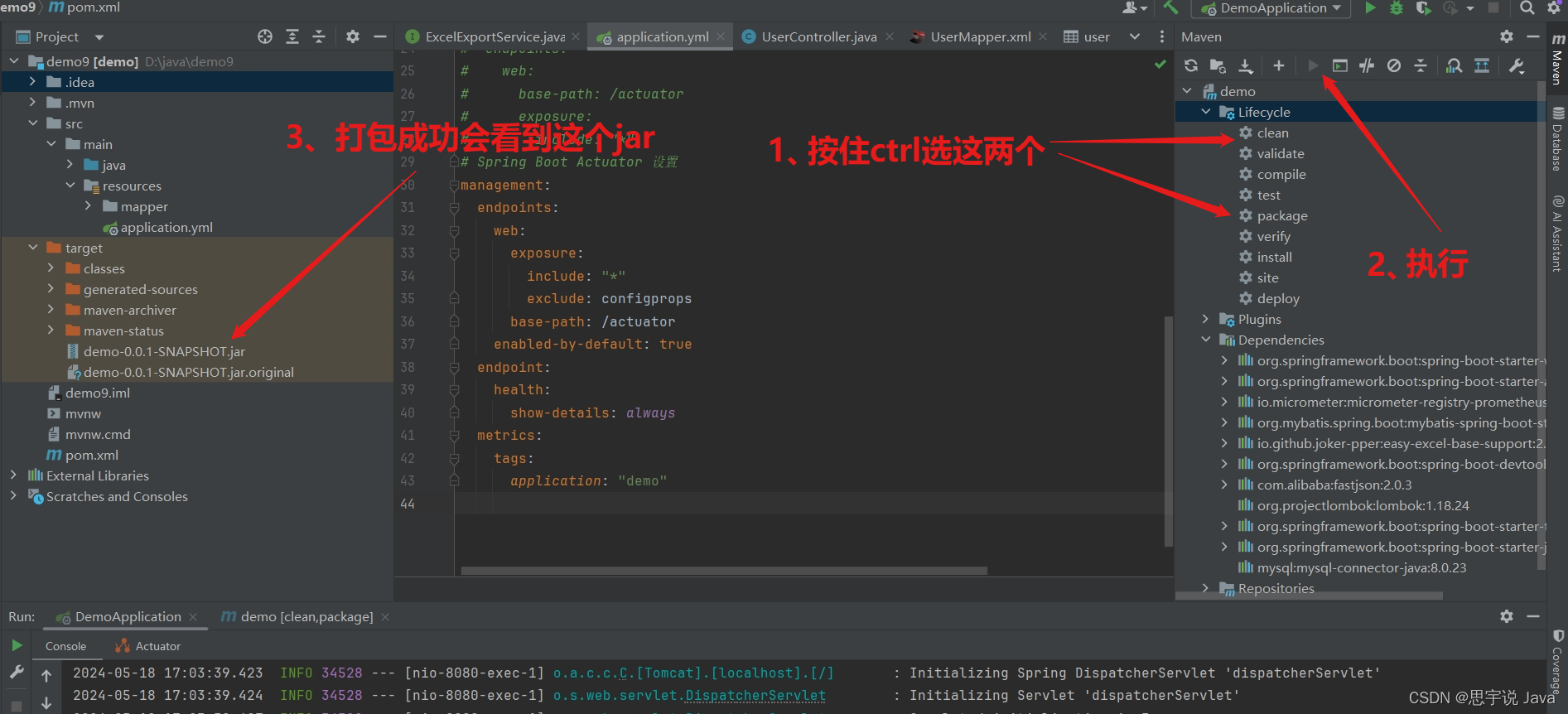
- 把 jar 文件上传到服务器
把 jar 文件改名 demo.jar (当然可以改你喜欢的文件名) —>2、在服务器你喜欢的位置创建一个文件目录(上传文件我用的是可视化工具,就不过多解释了)接下来重点来了。
- 编写Dockerfile
在demo.jar的同级目录下创建Dockerfile 文件
touch Dockerfile
vim Dockerfile
粘贴下面的命令
FROM java:8-alpine
COPY demo.jar app.jar
RUN /bin/sh -c "touch /app.jar"
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "app.jar"]
这段代码其实很简单,我就不过多赘述了
3.打包镜像
- 打包
docker build -t demo .
注意后面的小点哦
- 查看镜像
docker images
- 启动镜像
docker run -d -p 8080:8080 demo
然后访问http://yourPath:8080/actuator/
看到这里,spring boot项目部署完毕,又学了个新技术哦,docker 部署Java项目
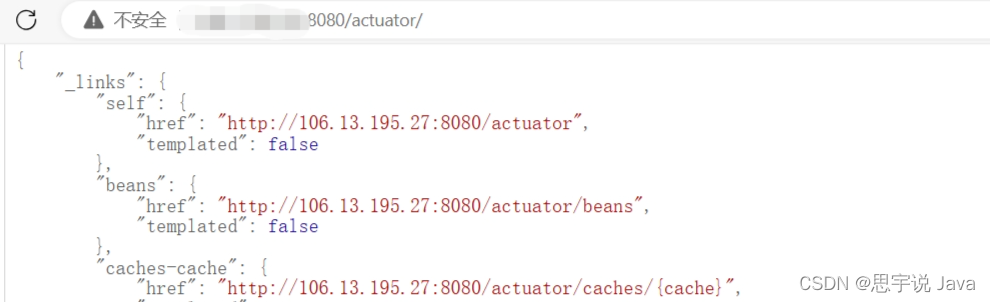
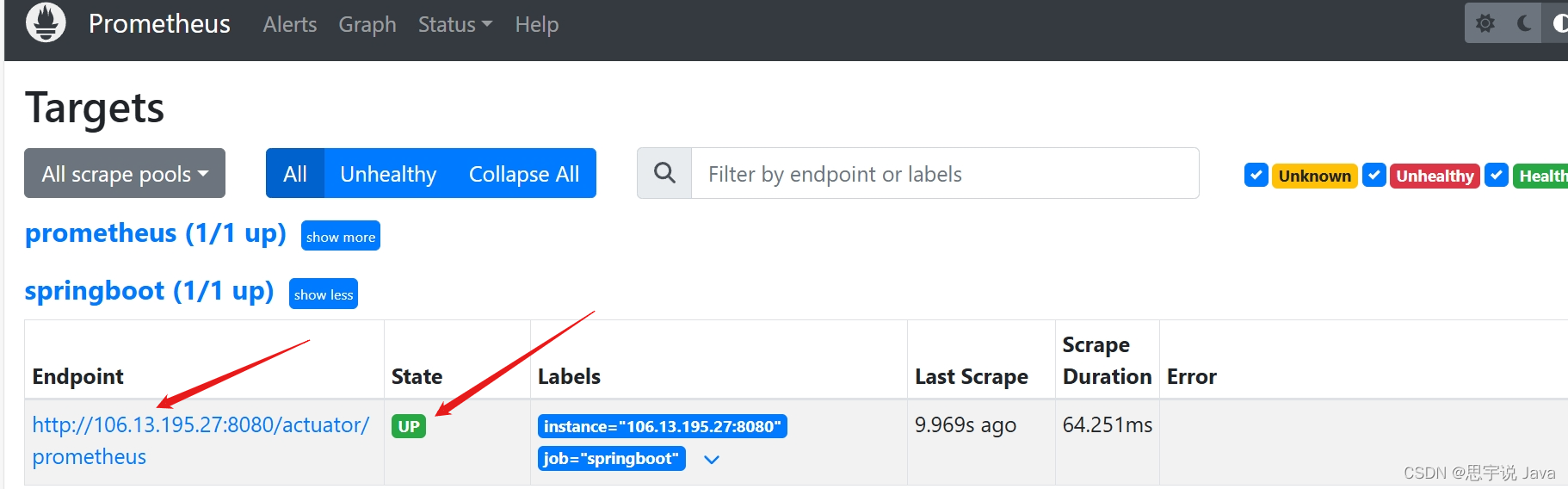
接下来记得改prometheus 拿取数据的ip地址哦(修改为你服务器地址,怎么修改可以参考上文的Prometheus.yml讲解)
打开prometheus的Targets你会神奇的发现多了一个 Endpoint 并且 state 为 up
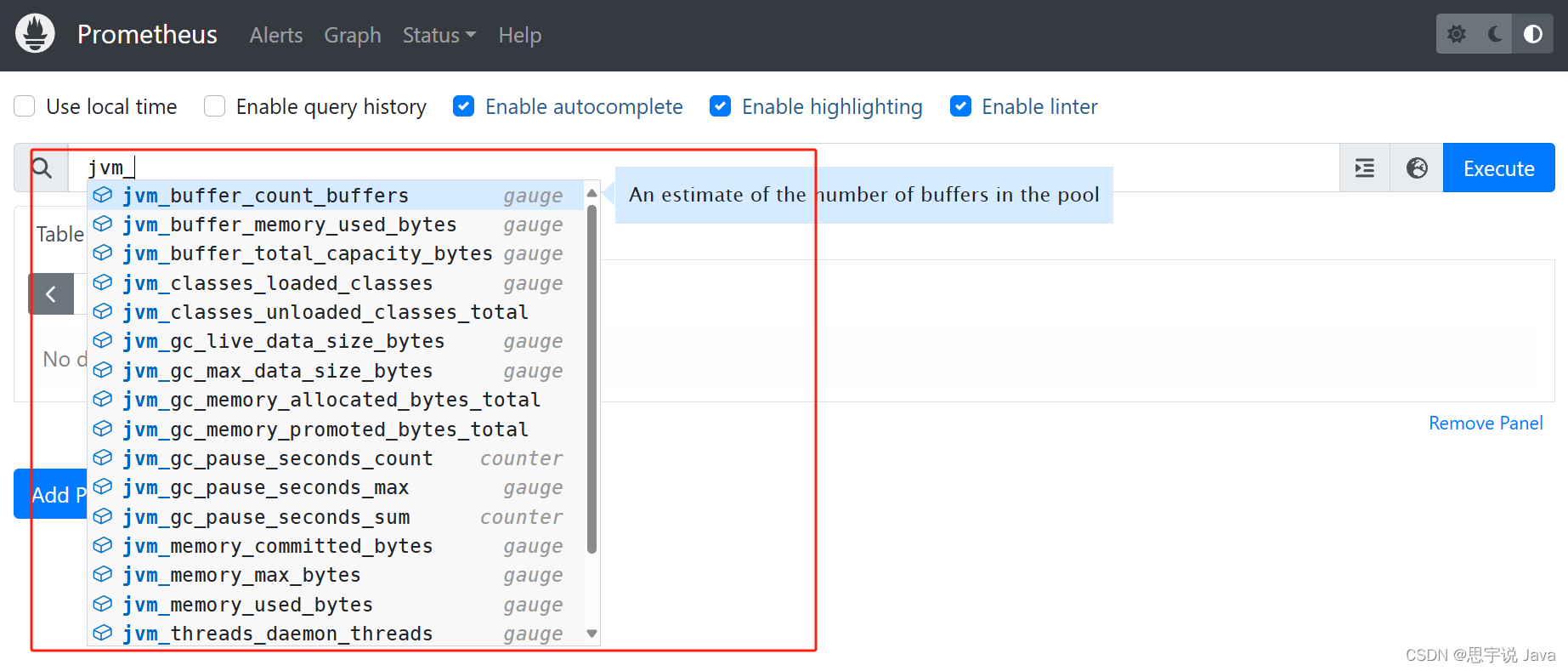
去首页查询你会发现有很多数据:
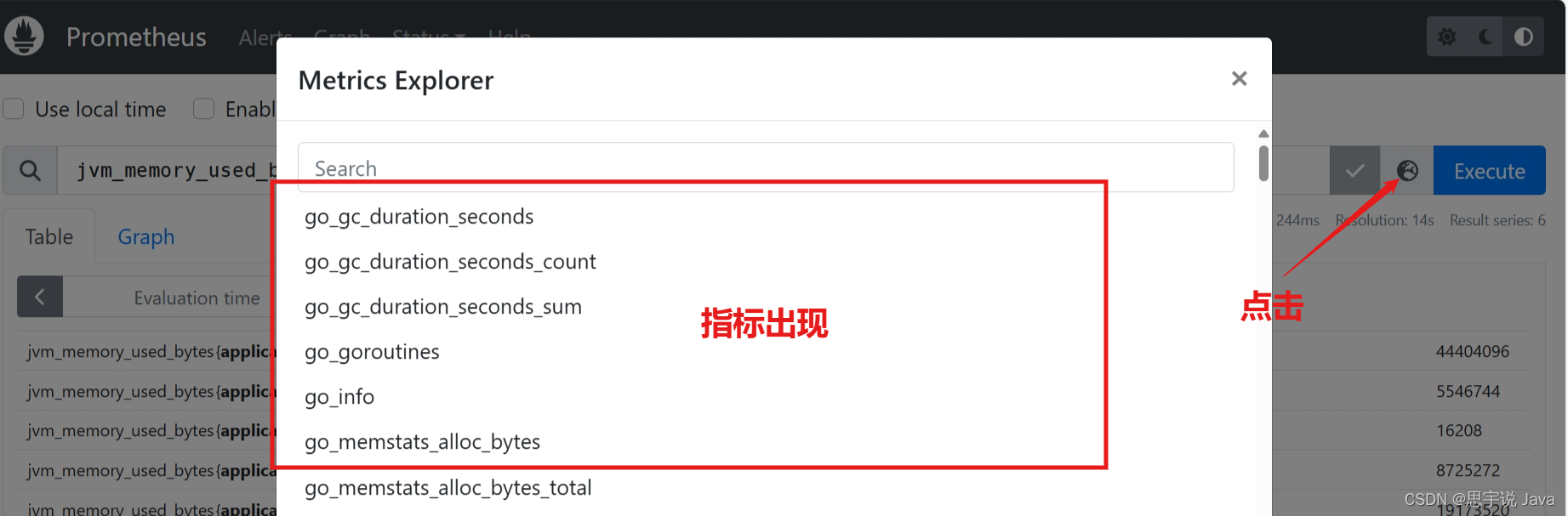
指标记不住怎么办?可以看这里
到这里我们Prometheus 就介绍完毕了
七 、Grafana安装
介绍
Grafana是一个开源的数据可视化工具,主要用于将数据源中的数据以图形化的形式展示并进行实时监控
- 数据源支持:
-Grafana支持多种数据源,包括Graphite、Elasticsearch、InfluxDB、Prometheus等,这使得用户能够整合来自不同来源的数据,并在一个统一的界面中进行展示和分析。 - 数据可视化:
Grafana提供了丰富的可视化图表类型,如折线图、直方图、热力图等,以满足各种数据可视化需求。用户可以通过简单的配置和自定义设置,将数据转化为易于理解的图表和仪表盘,并在一个界面中集中展示多个数据源的数据。 - 实时监控:
Grafana支持实时监控功能,可以实时反映系统状态、性能等指标的变化情况。这使得用户能够及时发现潜在问题,并采取相应措施进行解决。
告警与通知:Grafana可以设置告警规则,当某些指标达到预设的阈值时,系统会自动发送通知,提醒用户关注和处理。这种功能可以帮助用户保持对关键指标的持续监控,确保系统的稳定运行。 - 灵活的布局:
Grafana允许用户通过拖拽和配置的方式,自由调整图表的位置和大小,实现个性化的界面布局。这使得用户能够根据自己的需求定制仪表板,提高工作效率。 - 数据采集与清洗:
Grafana支持从各种数据源采集数据,并进行聚合、清洗和存储。这样可以确保数据的准确性和完整性,为后续的分析和展示提供可靠的数据支持。 - 插件和扩展:
- Grafana支持多种插件和扩展,可以定制用户的监控和数据可视化体验。这些插件和扩展可以帮助用户扩展Grafana的功能,满足特定的业务需求。
总之,Grafana是一个功能强大、易于使用的数据可视化工具,可以帮助用户更好地理解和分析数据,提高工作效率。
安装
- 拉取Grafana Docker镜像:
docker pull grafana/grafana
- 运行Grafana容器:
docker run -d -p 3000:3000 --name=grafana grafana/grafana
访问 http://yourPath:3000 你会看到一下界面
到这里grafana安装就完毕了,接下来我们配置
配置
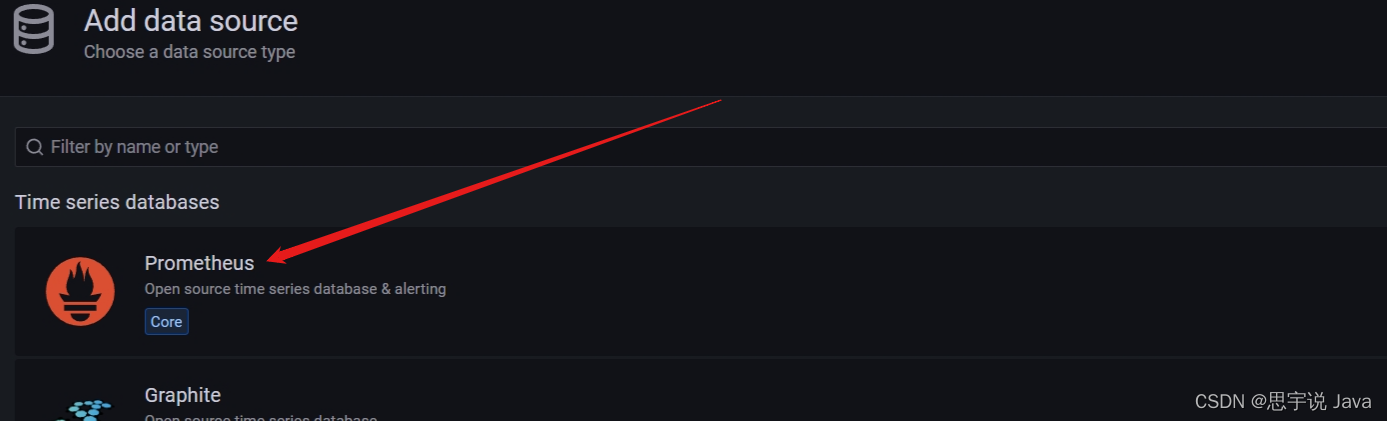
- 添加数据源
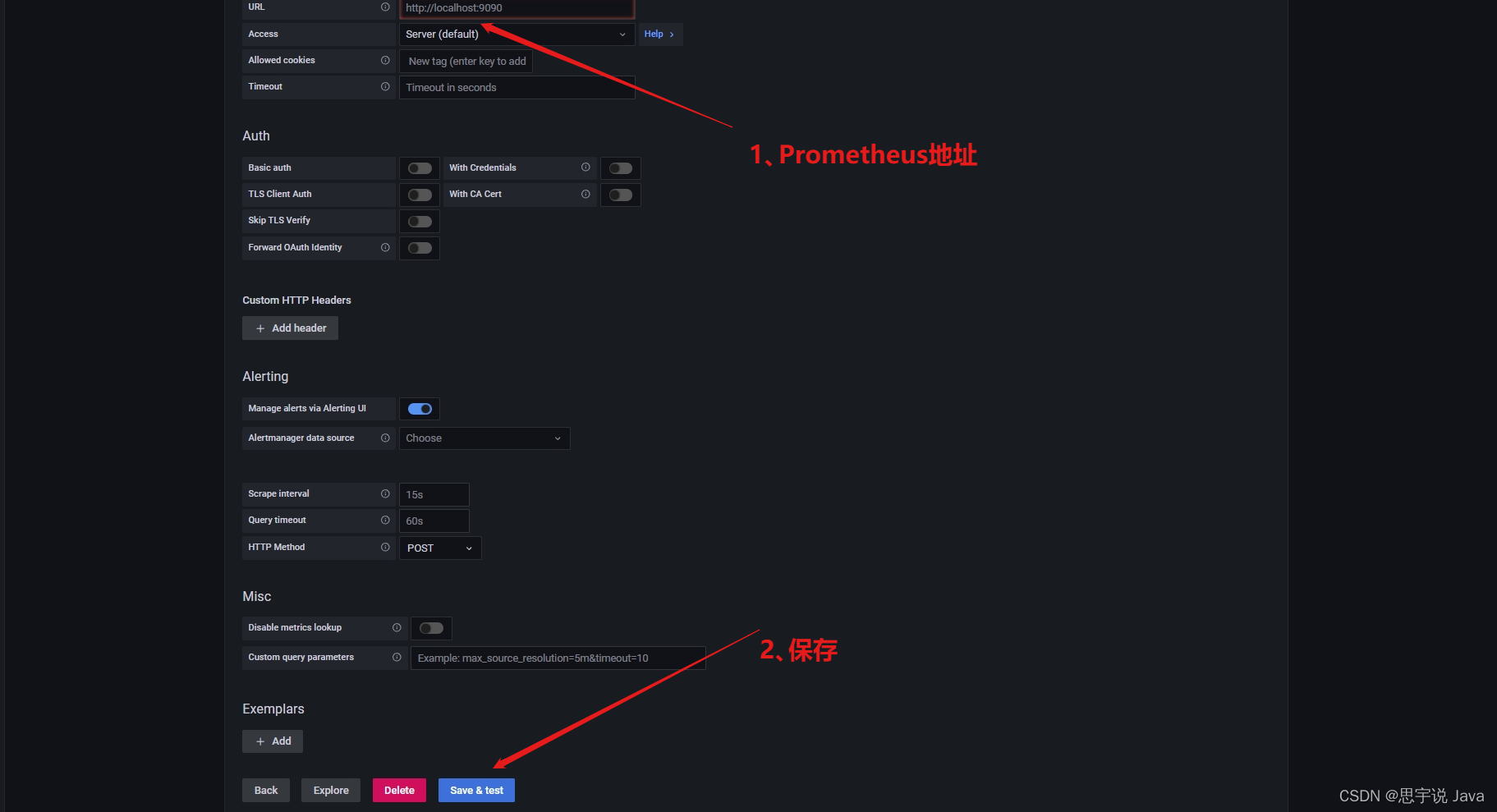
选择数据源
Prometheus地址配置
导入视图
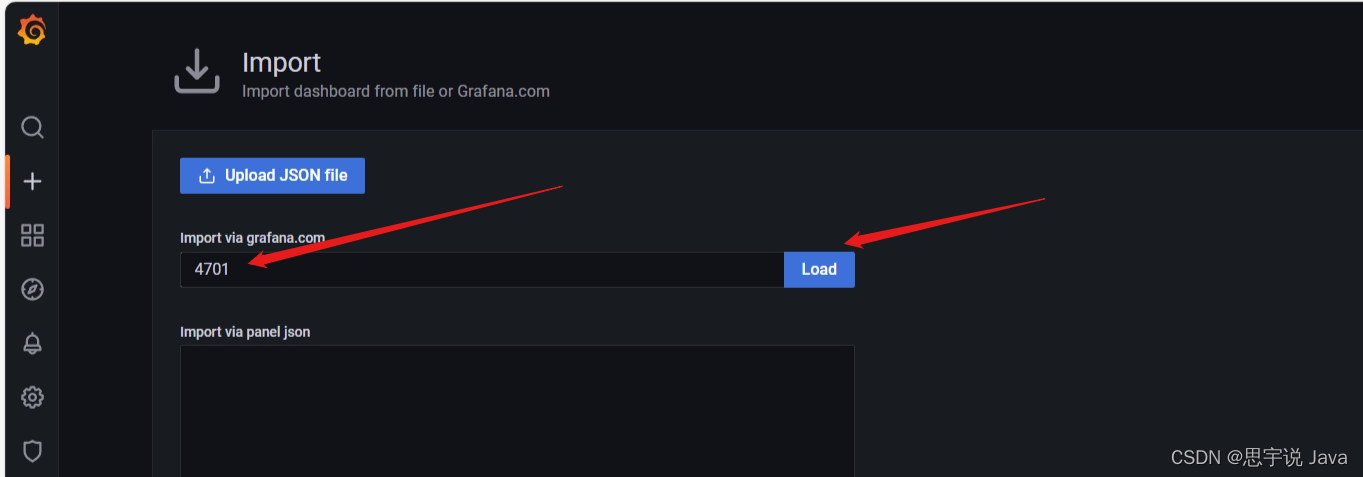
选择 import 搜索 4701
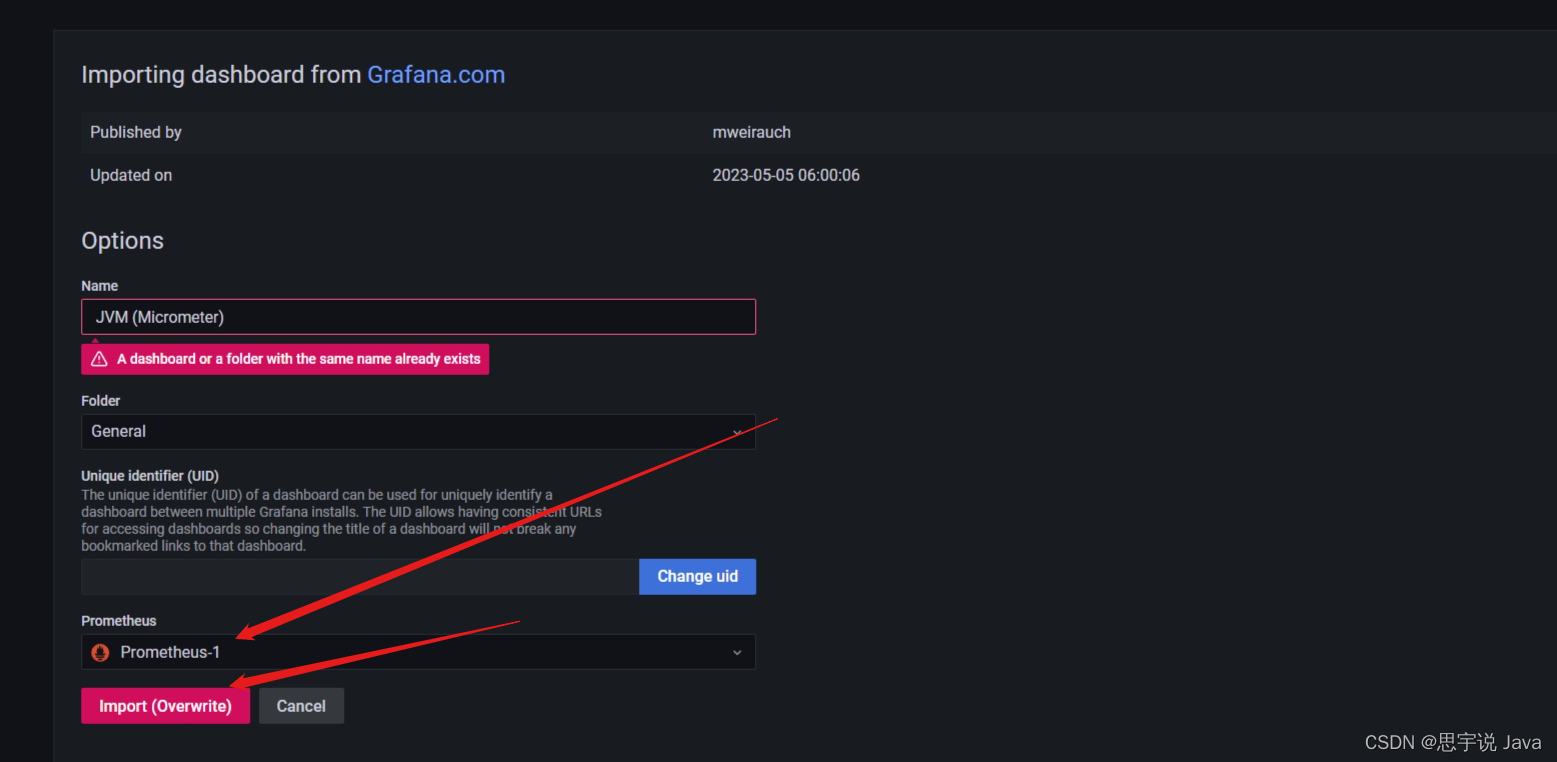
选择Prometheus,然后导入(解释,我已经导入过模板了,所以有提示)
导入成功后你会看到以下界面(很多的指标都图形化显示了)
到这里 grafana 安装完毕。
八、linux node-exporter安装
介绍:
-
node-exporter是一个Prometheus的exporter,它主要用于监控Linux系统的节点信息。这个工具可以采集Linux服务器的多种资源数据,包括但不限于服务器的进程数、CPU、内存消耗、磁盘空间、IOPS(输入/输出操作每秒)、TCP连接数等。
-
node-exporter的工作方式是暴露主机的指标,如CPU、内存、磁盘等信息。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。然而,与传统的指标数据收集组件不同的是,node-exporter只负责收集数据,并不直接向Server端发送数据,而是等待Prometheus Server主动抓取。默认的抓取URL地址是http://ip:9100/metrics。
安装:
同样的方式,用docker 安装
docker run -d -p 9100:9100 --restart=always -m 5G --memory-swap=5G \
-v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" \
--name node_exporter quay.io/prometheus/node-exporter --path.procfs \
/host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points\
"^/(sys|proc|dev|host|etc)($|/)"
访问:http://yourIp:9100/metrics
node-exporter安装成功
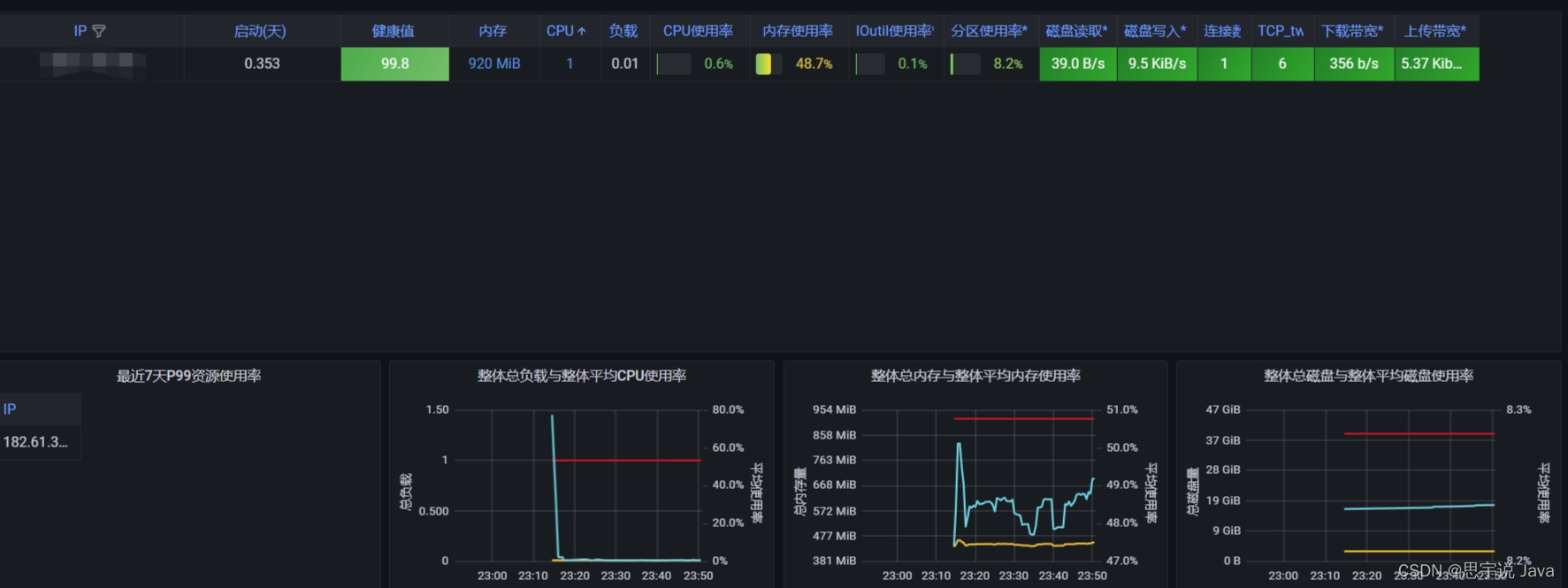
然后去grafana import 8919 (数据源继续选择promtheus)你会看到如下页面,服务器已经开始监控
九、Altermanager安装
1、介绍
- 当Prometheus服务器根据报警规则发现异常时,它会将警报发送到Alertmanager。Alertmanager负责处理这些警报,包括进行去重、分组,并通过路由发送到正确的接收器,如电子邮件、Slack、HipChat等。
- Alertmanager还支持多种告警方式,如邮件告警、微信告警、短信告警、Slack告警、电话告警和PagerDuty告警等。通过配置,用户可以根据自己的需求选择适合的告警方式,以便及时采取行动来处理问题。
- 总的来说,Alertmanager是Prometheus生态系统中的一个重要组件,它负责处理Prometheus生成的警报,并通过各种方式通知用户,以便用户能够及时发现和处理潜在问题。
2、安装
- 创建数据挂载目录
/opt/alertmanager/config目录,准备用来放置alertmanager的配置文件
/opt/alertmanager/template目录,准备用来挂载放置alertmanager的模板文件
mkdir -p /opt/alertmanager/{config,template}```
## 授权权限
```linux
chmod -R 777 /opt/alertmanager/config
chmod -R 777 /opt/alertmanager/template
- 创建Altermanager配置文件alertmanager.yml
cat > /opt/alertmanager/config/alertmanager.yml << \EOF
global:
resolve_timeout: 5m
# 发件人
smtp_from: 1229495577@qq.com'
# 邮箱服务器的 POP3/SMTP 主机配置 smtp.qq.com 端口为 465 或 587
smtp_smarthost: 'smtp.qq.com:465'
# 用户名
smtp_auth_username: [email protected]'
# 授权码 或 密码
smtp_auth_password: '你的qq授权码'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates:
# 指定预警内容模板
- '/etc/alertmanager/template/email.tmpl'
route:
# 指定通过什么字段进行告警分组(如:alertname=A和alertname=B的将会被分导两个组里面)
group_by: ['alertname']
# 在组内等待所配置的时间,如果同组内,5 秒内出现相同报警,在一个组内出现
group_wait: 5s
# 如果组内内容不变化,合并为一条警报信息,5 分钟后发送
group_interval: 5m
# 发送告警间隔时间 s/m/h,如果指定时间内没有修复,则重新发送告警
repeat_interval: 5m
# 默认的receiver。 如果一个报警没有被任何一个route匹配,则发送给默认的接收器
receiver: 'justrydeng163email'
#子路由(上面所有的route属性都由所有子路由继承,并且可以在每个子路由上进行覆盖)
routes:
# 当触发当前预警的prometheus规则满足:标签alarmClassify的为normal时(标签名、标签值可以自定义,只要和编写的prometheus的rule里面设置的标签呼应上即可),往justrydeng163email发送邮件
- receiver: justrydeng163email
match_re:
alarmClassify: normal
# 当触发当前预警的prometheus规则满足:标签alarmClassify的值为special时(标签名、标签值可以自定义,只要和编写的prometheus的rule里面设置的标签呼应上即可),往justrydengQQemail发送邮件
- receiver: justrydengQQemail
match_re:
alarmClassify: special
receivers:
- name: 'justrydeng163email'
email_configs:
# 如果想发送多个人就以 ',' 做分割
- to: burger2325@163.com'
send_resolved: true
# 接收邮件的标题
headers: {Subject: "alertmanager报警邮件"}
- name: 'justrydengQQemail'
email_configs:
# 如果想发送多个人就以 ',' 做分割
- to: [email protected]'
send_resolved: true
# 接收邮件的标题
headers: {Subject: "alertmanager报警邮件"}
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
EOF
- 告警内容模板文件创建
cat > /opt/alertmanager/template/email.tmpl << \EOF
{{ define "email.html" }}
<table border="1">
<tr>
<td>报警项</td>
<td>实例</td>
<td>报警阀值</td>
<td>开始时间</td>
<td>告警信息</td>
</tr>
{{ range $i, $alert := .Alerts }}
<tr>
<td>{{ index $alert.Labels "alertname" }}</td>
<td>{{ index $alert.Labels "instance" }}</td>
<td>{{ index $alert.Annotations "value" }}</td>
<td>{{ $alert.StartsAt }}</td>
<td>{{ index $alert.Annotations "description" }}</td>
</tr>
{{ end }}
</table>
{{ end }} EOF
- docker 部署Alertmanager
docker run -d --name=alertmanager -p 9093:9093 -v /etc/localtime:/etc/localtime:ro
-v /opt/alertmanager/config/alertmanager.yml:/etc/alertmanager/alertmanager.yml
-v /opt/alertmanager/template:/etc/alertmanager/template prom/alertmanager
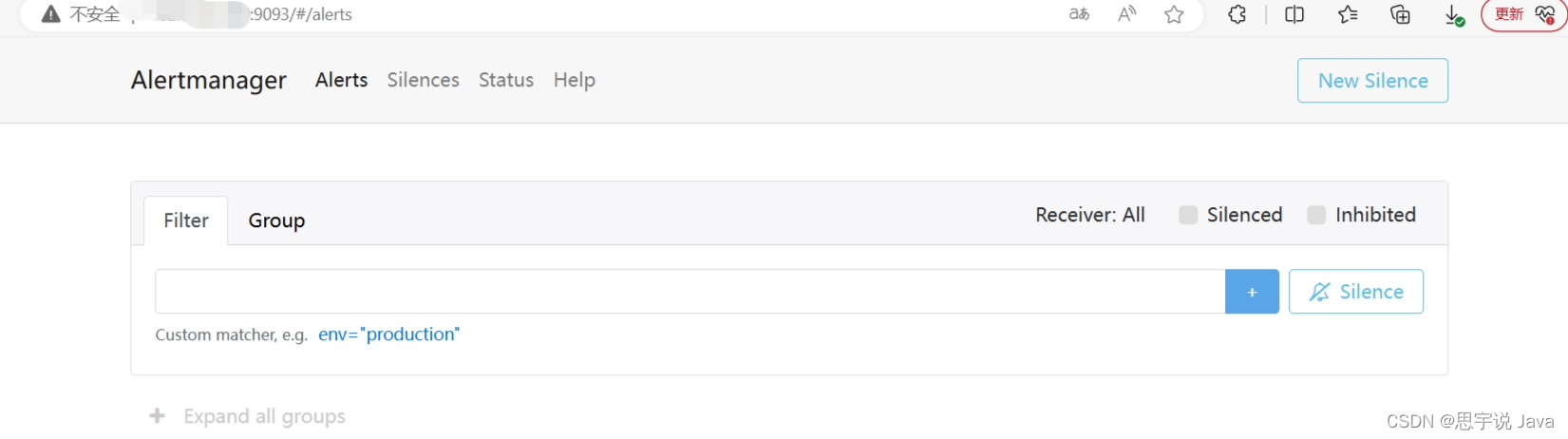
访问 http://yourIp:9093,看到以下界面,部署成功
配置
- Prometheus.yml文件配置
添加Alertmanager 的地址和Prometheus 的告警规则文件地址
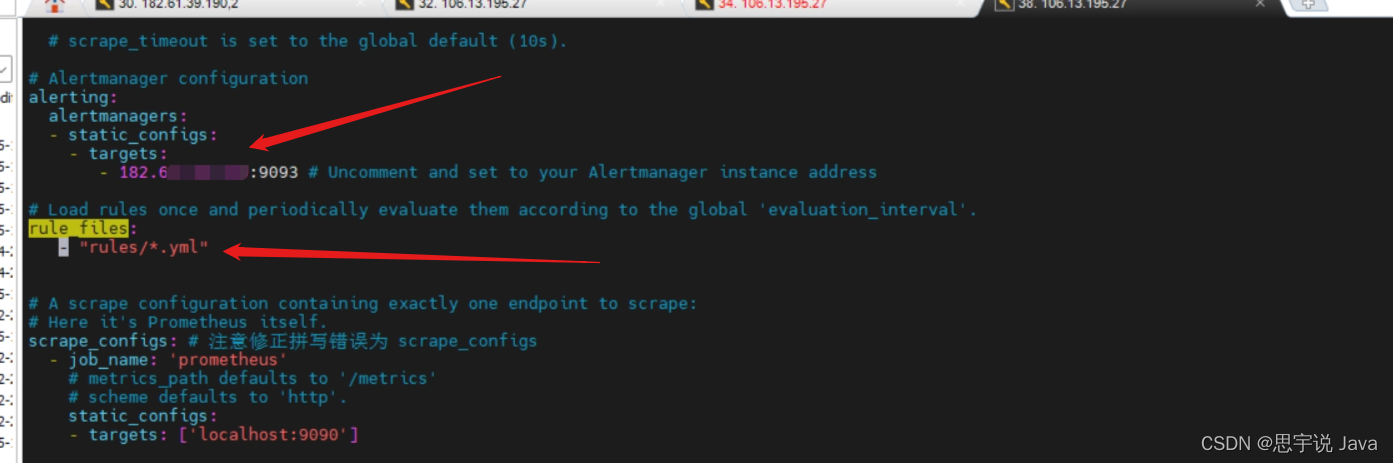
- 告警规则文件配置
创建文件夹/opt/prometheus/rules
mkdir -p /opt/prometheus/rules
/opt/prometheus/rules下创建 springboot-service-rule.yml
cd /opt/prometheus/rules
touch springboot-service-rule.yml
粘贴以下内容
groups:
- name: springboot-service-alerts
rules:
- alert: SpringBootServiceDown
# 这个地方是 PromQL 不能随写哦,是否宕机
expr: up{job="springboot"} == 0
# 持续时间
for: 10s
labels:
# 告警级别
severity: critical
annotations:
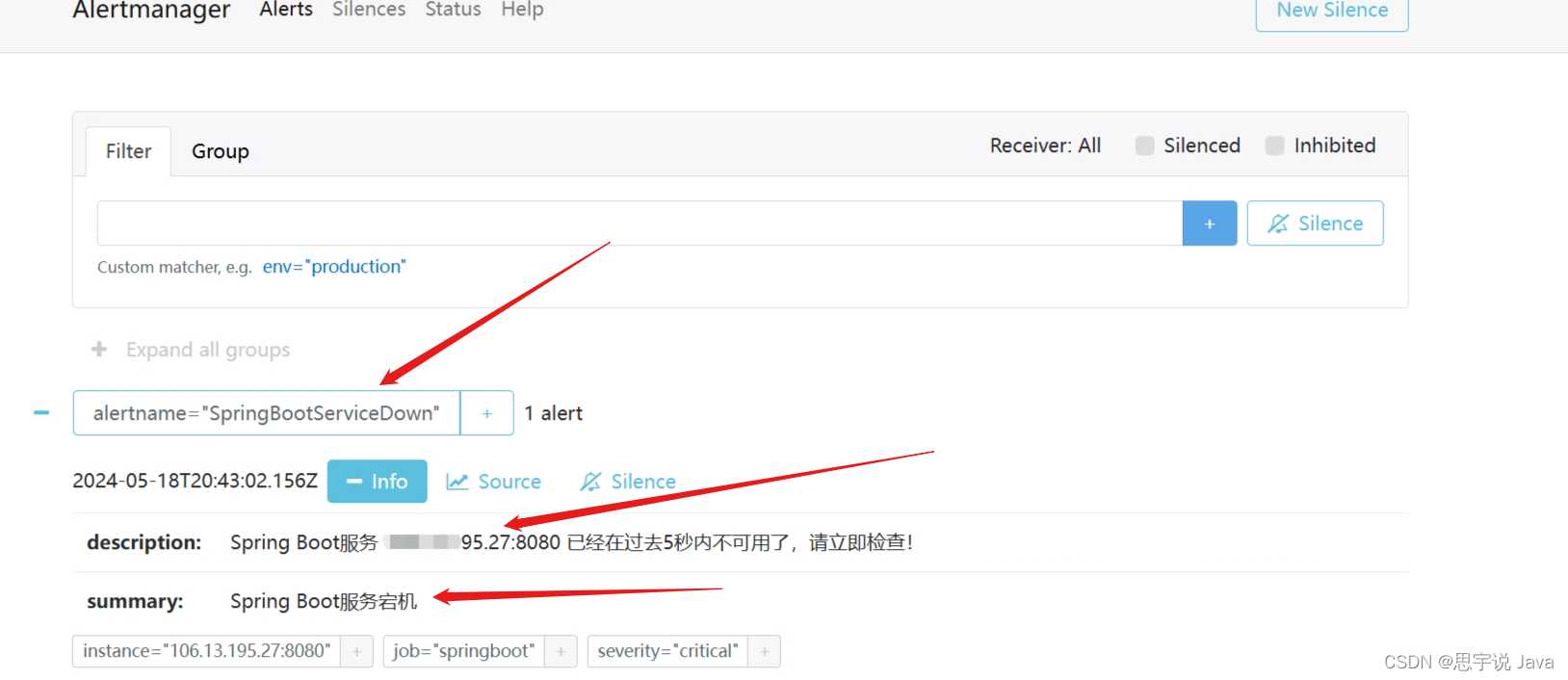
summary: "Spring Boot服务宕机"
# {{ $labels.instance }} 其实就是ip,在prometheus 里可以看到
description: "Spring Boot服务 {{ $labels.instance }} 已经在过去5秒内不可用了,请立即检查!"
#cpu使用率过高
- alert: SpringBootHighCPUUsage
expr: (1 - avg by(instance) (irate(process_cpu_seconds_total{job="springboot"}[5m]))) * 100 > 80
for: 10s
labels:
severity: warning
annotations:
summary: "Spring Boot服务CPU使用率过高"
description: "实例 {{ $labels.instance }} 的CPU使用率超过80%已经持续了10分钟,请检查服务负载或进行性能调优!"
#内存使用过高
- alert: SpringBootHighMemoryUsage
expr: (container_memory_usage_bytes{job="springboot"} / container_spec_memory_limit_bytes{job="springboot"}) * 100 > 80
for: 10m
labels:
severity: warning
annotations:
summary: "Spring Boot服务内存使用率过高"
description: "实例 {{ $labels.instance }} 的内存使用率超过80%已经持续了10分钟,请检查内存泄露或进行资源调整!"
# 这里可以添加更多针对Spring Boot服务的告警规则
这个时候我们停掉以前的Prometheus,然后挂在这个规则文件重新创建容器并运行
#停止
docker stop CONTAINER ID
重建新创建容器并启动
docker run -d -p 9090:9090 -v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
-v /opt/prometheus/rules/rule.yml:/etc/prometheus/rules/rule.yml --name prometheus3 prom/prometheus
然后停掉你的 springboot 项目
docker stop CONTAINER ID
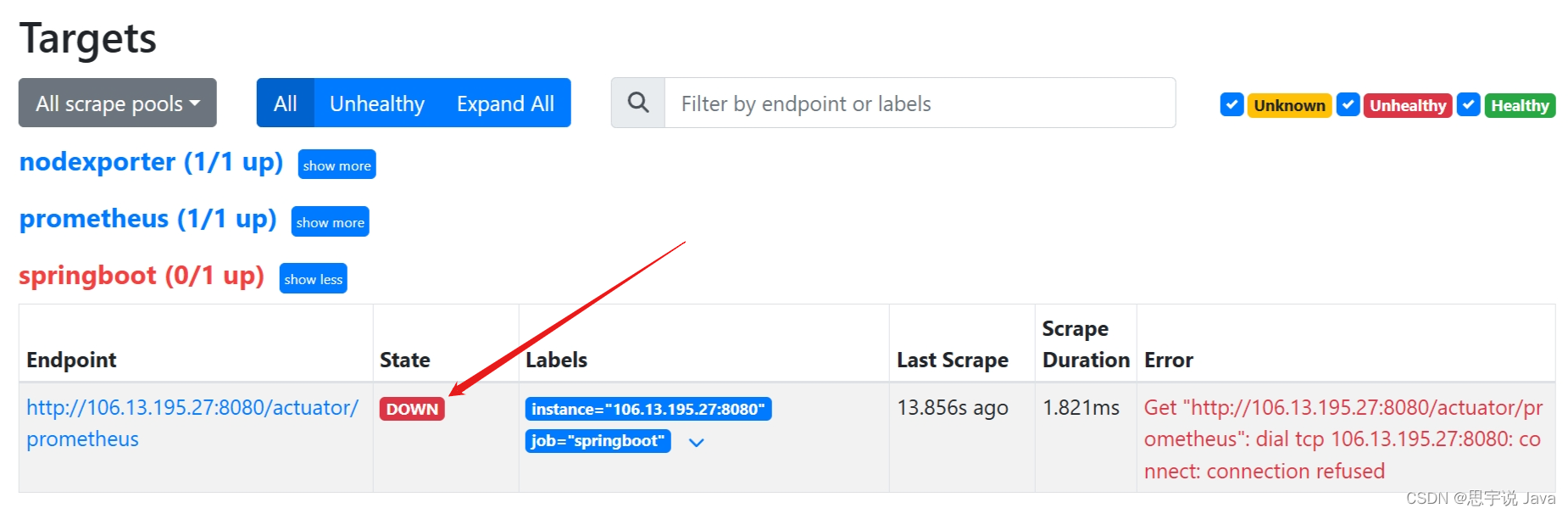
- 在Prometheus你会看到:
- 在Alertmanager你会看到
到这里,我们还有最后一步啦,配置邮件告警,我们的微服务之服务告警就完结散花啦
十、配置告警
首先带大家看一下alertmanagr的配置文件
global:
resolve_timeout: 5m
# 发件人
smtp_from: [email protected]'
# 邮箱服务器的 POP3/SMTP 主机配置 smtp.qq.com 端口为 465 或 587
smtp_smarthost: 'smtp.qq.com:465'
# 用户名
smtp_auth_username: [email protected]'
# 授权码 或 密码
smtp_auth_password: '你的qq授权码'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates:
# 指定预警内容模板
- '/etc/alertmanager/template/email.tmpl'
route:
# 指定通过什么字段进行告警分组(如:alertname=A和alertname=B的将会被分导两个组里面)
group_by: ['alertname']
# 在组内等待所配置的时间,如果同组内,5 秒内出现相同报警,在一个组内出现
group_wait: 5s
# 如果组内内容不变化,合并为一条警报信息,5 分钟后发送
group_interval: 5m
# 发送告警间隔时间 s/m/h,如果指定时间内没有修复,则重新发送告警
repeat_interval: 5m
# 默认的receiver。 如果一个报警没有被任何一个route匹配,则发送给默认的接收器
receiver: 'justrydeng163email'
#子路由(上面所有的route属性都由所有子路由继承,并且可以在每个子路由上进行覆盖)
routes:
# 当触发当前预警的prometheus规则满足:标签alarmClassify的为normal时(标签名、标签值可以自定义,只要和编写的prometheus的rule里面设置的标签呼应上即可),往justrydeng163email发送邮件
- receiver: justrydeng163email
match_re:
alarmClassify: normal
@
配置文件里给大家解释的很详细,这里就不过都赘述,相信大家看完注释因该知道该怎么配置了。
- 亲爱的探索者,我们一同走过了这片知识的海洋,历经曲折与艰辛,却也收获了无尽的宝藏与智慧。愿你在前行的道路上,始终保持那份对技术的热爱与追求,让智慧的火花在你的心中燃烧,照亮你探索未知的道路。愿你的每一次努力都能化作成功的基石,每一次挑战都能让你更加坚韧不拔。最后,衷心地感谢你与我一同分享这段精彩的旅程,期待在未来的日子里,我们能够继续携手并进,共同书写更多属于技术狂人的辉煌篇章。加油,探索者,愿你的未来因知识而更加精彩!