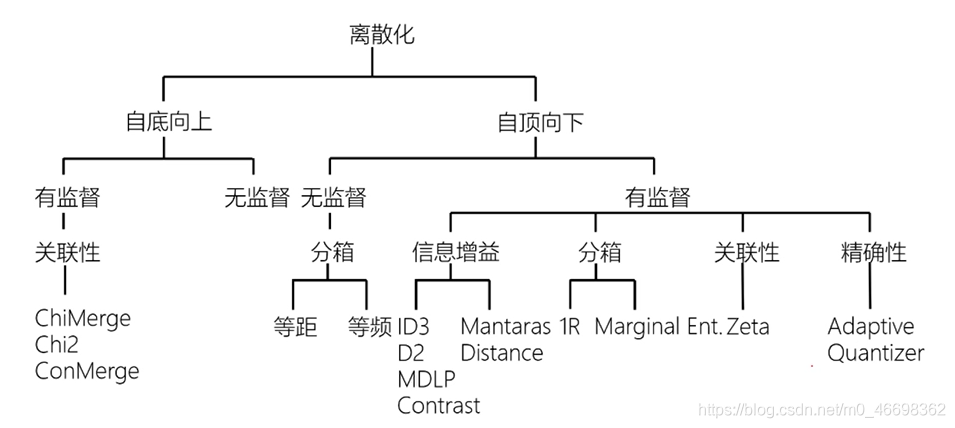
1特征编码
模型输入的特征通常需要是数值型的,所以需要将非数值型特征转换为数值特征,如性别、职业、收入水平、国家、汽车使用品牌等。特征编码包括数字编码、One-Hot编码、哑变量编码方法。
1.1数字编码
一种简单的数字编码方法是从0开始赋予特征的每一个取值一个整数。对于等级型特征,按照特征取值从小到大进行整数编码可以保证编码后的数据保留原有的次序关系。
原特征 收入水平={贫困,低收入,小康,中等收入,富有};编码后 收入水平={0,1,2,3,4}
缺点:引入了次序关系。
对于名义型特征,上述数字编码方法可能会产生一些问题.例如汽车品牌={路虎,吉利,奥迪,大众,奔驰},经过数字编码后转换成汽车品牌={0,1,2,3,4}。在使用编码后的数据进行分析时,相当于给原本不存在次序关系的“汽车品牌”特征引入了次序关系。这可能会导致后续错误的建模分析结果。例如吉利与路虎之间的距离比奔驰与路虎之间的距离较小,因为我们在编码时将路虎编码为0,吉利编码为1,奔驰编码为4.为了避免上述误导性的结果,对于离散型特征(特别是名义型特征),可以使用另外一种编码方法: One-Hot编码。
1.2One-Hot编码
将包含k个取值的离散型特征转换成k个二元特征(取值为0或1)。例如上例汽车品牌特征,一共包含5个不同的值。可以将其编码为5个特征f1、f2、f3、f4和f5,这5个特征与原始特征汽车品牌的取值一一对应。当原始特征取不同值时,转换后的特征的取值如下表所示。
| 原始特征取值 | f1 | f2 | f3 | f4 | f5 |
|---|---|---|---|---|---|
| 路虎 | 1 | 0 | 0 | 0 | 0 |
| 吉利 | 0 | 1 | 0 | 0 | 0 |
| 奥迪 | 0 | 0 | 1 | 0 | 0 |
| 大众 | 0 | 0 | 0 | 1 | 0 |
| 奔驰 | 0 | 0 | 0 | 0 | 1 |
优点:经过One-Hot编码之后,不同的原始特征取值之间拥有相同的距离。在线性回归模型中,对名义型特征进行One-Hot编码的效果通常比数字编码的效果要好。One-Hot编码对包含离散型特征的分类模型的效果有很好的提升。
缺点:
●特征显著增多。假设存在10个包含100个取值的离散型特征,经过One-Hot编码之后的特征数量将变成1000个。
●增加了特征之间的相关性,根据上表发现编码后的5个特征存在线性关系:f1+f2+f3+f4+f5=1,特征之间存在线性关系会影响线性回归等模型的效果。
1.3哑变量编码
对于一个包含k个取值的离散型特征,将其转换成k-1个二元特征,例如特征汽车品牌,一共包含5个不同的取值,我们可以将其编码为4个二元特征。当原始特征取不同取值时,转换后的特征取值如下表所示
| 原始特征取值 | f1 | f2 | f3 | f4 |
|---|---|---|---|---|
| 路虎 | 1 | 0 | 0 | 0 |
| 吉利 | 0 | 1 | 0 | 0 |
| 奥迪 | 0 | 0 | 1 | 0 |
| 大众 | 0 | 0 | 0 | 1 |
| 奔驰 | 0 | 0 | 0 | 0 |
2数据标准化
为什么要进行数据标准化?
数据分析及建模过程中,许多机器学习算法需要其输入特征为标准化的形式。例如SVM算法中的RBF核函数,目标函数往往假设其特征均值在0附近且方差齐次等。若是其中有一个特征的方差远远大于其它特征的方差,那么这个特征就将成为影响目标特征的主要因素,模型难以学习到其它特征对目标特征的影响。
在另外一些数据分析场景下,我们需要计算样本之间的相似度.如果样本的特征之间的量纲差异太大,样本之间相似度评估的结果将会受到量纲大的特征的影响,从而导致对样本相似度的计算存在偏差。
因此,数据的标准化是数据分析流程中的重要步骤.常用的数据标准化方法有: Z-score标准化、Min-Max标准化、小数定标标准化和Logistic标准化。
2.1Z-Score标准化
对特征取值中的每一个数据点作减去均值并除以标准化的操作,使得处理后的数据具有固定均值和标准差,处理函数为
f
i
′
=
f
i
−
μ
σ
f_{i}'=\frac{f_{i}-\mu }{\sigma}
fi′=σfi−μ
μ为特征f的均值,σ为特征f的标准差
适用范围:适用于特征的最大值或最小值未知、样本分布非常离散的情况。
2.2Min-Max标准化
又称离差标准化或最大-最小值标准化。
Min-Max标准化通过对特征作线性变换,使得转换后特征的取值分布在[0,1]区间内,假设数据中特征f的取值集合为{f1,f2,f3…fn},特征值fi经过Min-Max标准化后的取值fi’为
f
i
′
=
f
i
−
f
m
i
n
f
m
a
x
−
f
m
i
n
f_{i}'=\frac{f_{i}-f_{min}}{f_{max}-f_{min}}
fi′=fmax−fminfi−fmin
如果希望将特征值f线性映射到任意区间[a,b],则Min-Max标准化的方法为
f
i
′
=
b
−
a
f
m
a
x
−
f
m
i
n
(
f
i
−
f
m
i
n
)
+
a
f_{i}'=\frac{b-a}{f_{max}-f_{min}}(f_{i}-f_{min})+a
fi′=fmax−fminb−a(fi−fmin)+a
Min-Max标准化适用于需要将特征取值简单地线性映射到某一区间中的情形。
其不足之处在于当数据集中有新数据加入时,特征的最大值或最小值会发生变化.此时需要计算新的最小值和最大值,并将之前的数据重新进行标准化操作。Min-Max标准化由于需要计算特征取值的最小值和最大值,因此当数据存在离群值时,标准化后的效果较差。
2.3小数定标标准化
通过移动数据的小数点位置来进行标准化,使得标准化后特征取值的绝对值总是小于1。具体标准化过程中,小数点移动多少位取决于最大绝对值大小。其处理函数为
f
i
∗
=
f
i
1
0
j
f_{i}^*=\frac{f_{i}}{10^{j}}
fi∗=10jfi
其中j是满足max{f1’,f2’,…,fn’}<1的最小整数。
例如,某特征的取值范围为[-3075,2187],特征取值绝对值的最大值为3075,则j取值为4。
小数定标标准化方法适用于特征取值比较分散,尤其是特征取值分布在多个数量级的情况.该方法简单实用,在确定小数点的移动位数后,易于还原标准化后的特征取值。
但是小数定标标准化方法也存在诸多缺点.如果特征取值分布集中在某几个量级上,则小数定标标准化的特征取值也会集中在某几个值附近,不利于后续数据分析时的样本区分.类似于Min-Max标准化方法,当有新样本加入时,小数定标标准化方法需要重新确定小数点移动位数.此外,小数定标标准化的效果也会受到离群值的影响。
2.4Logistic标准化
Logistic标准化利用Logistic函数的特性,将特征取值映射到[0,1]区间内. Logistic函数的定义如下式所示:
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)=\frac{1}{1+e^{-x}}
σ(x)=1+e−x1
函数图像如下
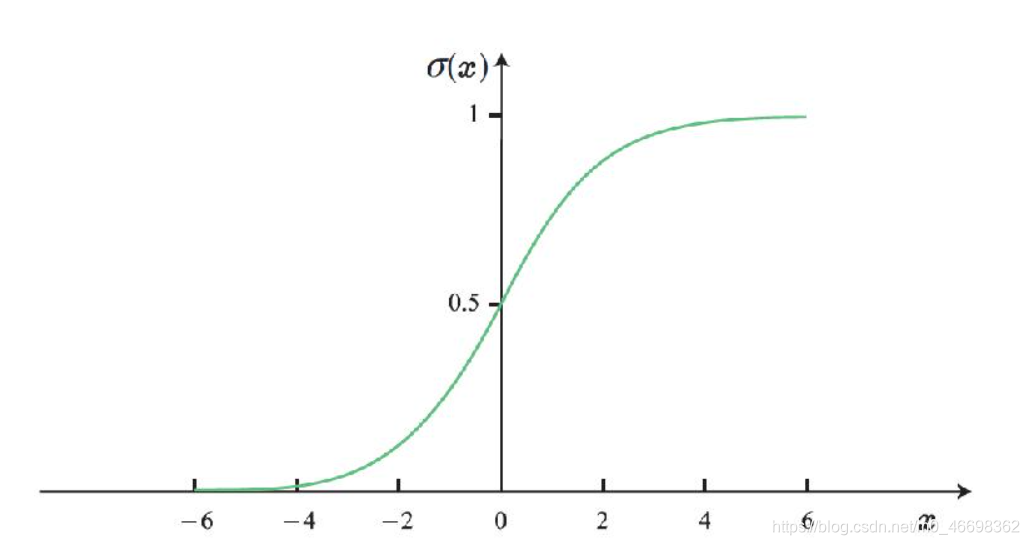
Logistic函数将数据从实数域光滑映射到[0,1]区间.我们可以使用该函数对特征进行标准化处理.假设特征f的取值集合为{f1,…fn},特征取值fi经过Logistic标准化后的取值fi’为
f
i
′
=
1
1
+
e
−
f
i
f_{i}'=\frac{1}{1+e^{-f_{i}}}
fi′=1+e−fi1
Logistic标准化方法适用于特征取值分布相对比较集中地分布于0两侧的情况.如果特征取值分散且均远离0,那么标准化后的特征取值会聚集于0或1附近,造成原始特征的分布及取值间关系被改变.因此在应用Logistic标准化方法之前,需要首先分析原始特征取值的分布状况.
3特征离散化
为什么要将连续型特征进行离散化处理?
1.算法特征类型有要求。如关联规则挖掘算法,ID3决策树算法
2.为更好地提高算法的精度。朴素贝叶斯分类算法的正确率比没有处理的情况平均高出10% ;
3.离散化处理本质是将连续型数据分段,因此数据中的异常值会直接划入相应的区间段中,进而增强了之后模型对于数据异常值的鲁棒性;
4.离散化后的特征,其取值均转化为有明确含义的区间号,相对于原始的连续型来说,含义更加明确,从而使得数据的可解释性更强,模型更易使用与理解。
5.将连续型特征离散化后,特征的取值大大减少,这样一来减少了数据集对于系统存储空间的需求,二来在算法建模中也大大减少了模型的实际运算量,从而可以提升模型的计算效率。
特征的离散化过程是将连续型特征的取值范围划分为若干区间段(bin),然后使用区间段代替落在该区间段的特征取值。区间段之间的分割点称之为切分点(cut point),由切分点分割出来的子区间段的个数,称之为元数(arity )
特征离散化目标:在数据信息损失尽量少的前提下,尽可能减少元数。
按是否参考了数据集的y值信息划分为:
无监督离散化:不参考目标特征y,直接根据特征本身的分布特性进行离散化处理。等距离散化、等频离散化、聚类离散化等。
有监督离散化:利用参考数据集中的目标特征y将连续型特征进行离散化处理。信息增益离散化、ChiMerge离散化等。
特征离散化方法一般分为下面四步进行:
1.特征排序。对连续型特征的取值进行升序或者降序排列,这样做可以减少离散化的运算开销;
2.切分点选择。根据给定的评价准则,合理选择切分点.常用的评价准则基于信息增益或者基于统计量;
3.区间段分割或者合并。基于选择好的切分点,对现有的区间段进行分割或者合并,得到新的区间段.在离散化的过程中,切分点集合的大小会随之
4.在生成的新区间段上重复第1-3步,直到满足终止条件。我们可以预先设定元数k,作为简单的终止判断标准,也可以设定复杂的判断函数。
3.1等距离散化
等距离散化(equal width discretzation)是最早的特征离散化方法之一。该离散化方法根据连续型特征的取值,将其均匀地划分成k个区间,每个区间的宽度均相等,然后将特征的取值划入对应的区间从而完成特征离散化.我们用f表示需要进行离散化的连续型特征.通过特征的最大值fmax和最小值fmin,然后计算出区间段的宽度:
ω
=
f
m
a
x
−
f
m
i
n
k
\omega=\frac{f_{max}-f_{min}}{k}
ω=kfmax−fmin
根据求得的区间宽度,以及特征f的最大值和最小值,我们可以找到(k一1)个切分点,从而完成数据的离散化过程。
如年龄取值应分布在[0,90],确定离散化后的区间段个数为5。0≤年龄<18;18≤年龄<36;36≤年龄<54;54≤年龄<72;72≤年龄<90.
等距离散化对输入数据质量要求高,无法解决特征存在离群值的问题。若存在离群值150,则切分点将严重偏移。
3.2等频离散化
当特征取值的分布不均匀(比如说存在离群值)时,经过等距离散化的处理之后,区间段中的样本量可能出现严重的不均衡.为了解决这个问题,我们不再要求区间段的宽度始终保持一致,而是尽量使得离散化后每一个区间内的样本量均衡,这种离散化方法称为等频离散化。
根据连续型特征取值的总数n,仍然将其划分成k个区间段,使得每个区间段包含的数据个数为n/k,然后每个区间所含数据的取值范围即是对应的特征离散化区间。
缺点:有时会将同样或接近的样本划分入不同的区间,容易使得相邻区间段内的数据具有相似的特性。
3.3聚类离散化
在离散化连续型特征的时候,如果相似的样本都能落在相同的区间段内,那么这样的划分可以更好地代表原始数据的信息而聚类正是一种将样本划分到不同的类或者簇(cluster)的一个过程。聚类的结果是同一个簇中的样本有很大的相似性,不同簇间的样本则有很大的差异性.因此可以考虑利用聚类对连续型特征进行离散化处理.
基于聚类分析的离散化方法主要包括以下三个步骤:
1.对于需要离散化的连续型特征,采用聚类算法(如K-means、EM算法等),把样本依据该特征的分布划分成相应的簇或类;
⒉.在聚类结果的基础上,基于特定的策略,决定是否对簇进行进一步分裂或合并.利用自顶向下的策略可以针对每一个簇继续运行聚类算法,将其细分为更小的子簇.利用自底向上的策略,则可以对邻近相似的簇进行合并处理得到新的簇;
3.在最终确定划分的簇之后,确定切分点以及区间个数.
在整个聚类的过程中,我们需要事先确定簇的个数以及描述样本之间的距离计算方式.如何选定簇的个数也会影响聚类算法的效果,从而影响特征的离散化。
3.4信息增益离散化
基于信息增益的离散化方法灵感源自于决策树模型建立时基于信息增益的评价标准,是自顶向下的分裂策略。在建立决策树的时候,遍历数据集的每个特征,把其作为候选分裂节点,计算依此分裂后嫡的大小。然后,选择摘最小也就是信息增益最大的特征作为正式的分裂节点.由于建立决策树模型时用信息增益来分裂连续型特征的准则在实际处理中效果很好。故将基于信息增益的分裂方法用于连续型特征的离散化处理中。该方法最终所划分的区间个数则由单个特征夫策树的叶子结点个数确定,实际应用中需要首先给定单个特征决策树的叶子结点个数。
基于信息增益的离散化分为以下几个步骤:
1.对连续型特征进行排序;
2.把特征的每一个取值认为是候选分裂节点(切分点),计算出对应的商.随后,选择嫡最小的取值作为正式的切分点,将原来的区间一分为二;
3.递归处理第二步中得到的两个新区间段,直到每个区间段内特征的类别一样为止;
4.合并相邻的、类的嫡值为0且特征类别相同的区间段,并重新计算新区间段类的嫡值;
5.重复执行第四步,直到满足终止条件.终止条件可以是限制决策树的深度,或者叶子结点的个数等.
在众多的决策树算法中,ID3和C4.5是最常用的基于信息增益来进行特征选择分类的算法.将这两种决策树算法应用于连续型特征离散化的核心是针对单个特征构建决策树建模.然后根据决策树模型中节点分裂的阈值对特征进行划分.
3.5卡方离散化
自底向上的合并策略
常用方法:ChiMerge。通过卡方检验判断相邻区间是否需要进行合并。
ChiMerge离散化过程:将连续型特征的每个取值看作是一个单独的区间段,并对值进行排序;
1.将连续型特征的每个取值看作是一个单独的区间段,并对值进行排序;
2.针对每对相邻的区间段,计算卡方统计量.卡方值最小或者低于设定阈值的相邻区间段合并在一起.卡方统计量的计算表达式为
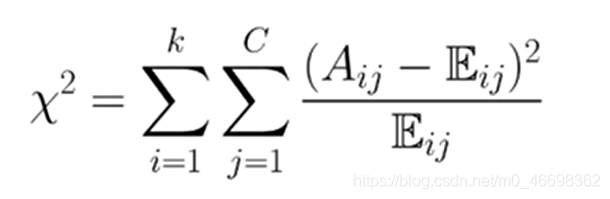
3.对于新的区间段,递归进行第1步和第2步,直到满足终止条件.