C:\Users\LENOVO\AppData\Local\Temp\ipykernel_16248\2139949438.py:2: FutureWarning: The provided callable <function sum at 0x000001BA644B93A0> is currently using DataFrameGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
table = pd.pivot_table(cpc, values = ['门店实收','cpc总费用'], index = ['平台门店名称'], columns = ['平台i'], aggfunc = np.sum).fillna(0)
cpc总费用
门店实收
平台i
美团
饿了么
美团
饿了么
平台门店名称
利芳·一人食大盘鸡(国定路店)
0.000
16738.510
0.000
51351.750
利芳大盘鸡(国定路店)
0.000
11198.710
0.000
24088.000
拌客·干拌麻辣烫(武宁路店)
0.000
19624.310
0.000
140628.830
拌客干拌麻辣烫(武宁路店)
0.000
510.900
0.000
1597.770
拌客干拌麻辣烫(武宁路店)
6939.660
0.000
36582.480
0.000
蛙小辣·美蛙火锅杯(五角场店)
0.000
423.060
0.000
4220.500
蛙小辣·美蛙火锅杯(大宁店)
0.000
2085.300
0.000
9099.400
蛙小辣·美蛙火锅杯(宝山店)
0.000
9898.120
0.000
101526.140
蛙小辣·美蛙火锅杯(真如店)
0.000
6027.460
0.000
44432.920
蛙小辣·美蛙火锅杯(芳华路店)
0.000
3.600
0.000
152.650
蛙小辣·美蛙火锅杯(虹口足球场店)
0.000
13372.700
0.000
71286.210
蛙小辣·美蛙火锅杯(龙阳路店)
0.000
538.000
0.000
1607.480
蛙小辣·美蛙火锅杯麻辣烫(五角场店)
0.000
312.210
0.000
4866.630
蛙小辣·美蛙火锅杯麻辣烫(宝山店)
0.000
5786.460
0.000
64722.170
蛙小辣·美蛙火锅杯麻辣烫(五角场店)
4.200
0.000
297.900
0.000
蛙小辣·美蛙火锅杯(虹口足球场店)
8682.990
0.000
43977.250
0.000
蛙小辣·美蛙火锅杯(长风大悦城店)
5216.900
0.000
33258.330
0.000
蛙小辣火锅杯
1567.010
0.000
8234.000
0.000
蛙小辣火锅杯(五角场店)
0.000
10190.150
0.000
99578.180
蛙小辣火锅杯(徐汇店)
0.000
74.100
0.000
354.340
蛙小辣火锅杯(龙阳广场店)
0.000
1951.830
0.000
7486.000
蛙小辣火锅杯麻辣烫(五角场店)
0.000
5.800
0.000
263.390
蛙小辣火锅杯(五角场店)
364.240
649.200
3108.130
4642.000
蛙小辣火锅杯(合生汇店)
7307.620
0.000
35655.800
0.000
蛙小辣火锅杯(宝山店)
9903.300
0.000
71009.660
0.000
蛙小辣火锅杯(真如店)
1765.970
298.400
16258.930
939.000
蛙小辣火锅杯(金煌美食城店)
683.240
0.000
2505.000
0.000
蛙小辣美蛙火锅杯(五角场店)
0.000
1156.700
0.000
7362.000
蛙小辣美蛙火锅杯(真如店)
0.000
580.500
0.000
1468.000
蛙小辣美蛙火锅杯(亚龙美食城店)
4745.210
0.000
17460.440
0.000
蛙小辣美蛙火锅杯(大宁国际店)
3909.500
0.000
12421.580
0.000
"""”表格的合并"""#核心思路都是采用循环,逐个拼接表格#当想要合并不同的Excel表格(注意,要保证每个Excel表格的字段相同哦)import numpy as np
import pandas as pd
import os
path ='./test/'#1、path:选择Excel表格所在路径
files =[i for i in os.listdir(path)]#2、files = []:创建一个空列表,将路径中,文件or文件夹的名字装入列表print(files)#3、查看是否正确,如:['test1','test2']
Merge = pd.DataFrame()#4、创建一个空的DataFramefor i in files:#5、for:循环遍历我们的名称列表(2),
df = pd.read_excel(path+i)#6、read_excel(path+i):读取第files[i]份表格。如当i=0,files[0]='sheet1'
Merge = pd.concat([Merge,df])#7、concat:将df内容拼接至Merge内
Merge.to_excel(path+'excel合并.xlsx',index =None)#8、to_excel:遍历结束后,输出我们合并后的表格
#当想要合并同一张Excel表格内的所有sheet(注意,要保证每个sheet的字段相同哦)import numpy as np
import pandas as pd
import os
name_list = pd.ExcelFile('./test/学习名单3.xlsx')#1、ExcelFile:传入Excel表格
df_list = pd.DataFrame()#2、创建一个空DataFramefor sheet in name_list.sheet_names:#3、for:循环遍历我们的名称列表(1)
df = name_list.parse(sheet_name=sheet)#4、name_list的属性parse:读取sheet中的内容
df_list=pd.concat([df_list,df])#5、append:我们将读取到的sheet内容,附加到df_list中
df_list.to_excel('./test/sheet合并.xlsx',index=False)#6、将df_list中的内容按行合并,输出#ExcelFile():传入一个表格的路径,并赋予一个对象。#sheet_names:他是ExcelFile()的一个方法,将Excel子工作表的名字以列表形式返回#parse:他是ExcelFile()的一个方法#参数sheet_name:传入子工作表的名称,可以读取里面的内容
""" 数据探索处理 """# - 0、数据准备:导入pandas库&数据import numpy as np
import pandas as pd
#导入我们需要的包,并且给它起别名,方便我们调用
df = pd.read_csv('./cpc.csv',encoding='gbk')#df--给我们导入的数据命名为df#pd--调用pandas#read_csv()--pandas常用的读取数据函数#('文件名')--需要导入的数据文件名
%matplotlib notebook
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#设置可以显示中文
plt.rcParams['axes.unicode_minus']=False#正常显示负号
import pandas as pd
olpc = pd.read_csv('Tokyo 2021 dataset.csv')#读取文件中东京奥运会的CSV表格
olpc.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 93 entries, 0 to 92
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Rank 93 non-null int64
1 Team/NOC 93 non-null object
2 Gold Medal 93 non-null int64
3 Silver Medal 93 non-null int64
4 Bronze Medal 93 non-null int64
5 Total 93 non-null int64
6 Rank by Total 93 non-null int64
7 NOCCode 93 non-null object
dtypes: int64(6), object(2)
memory usage: 5.9+ KB
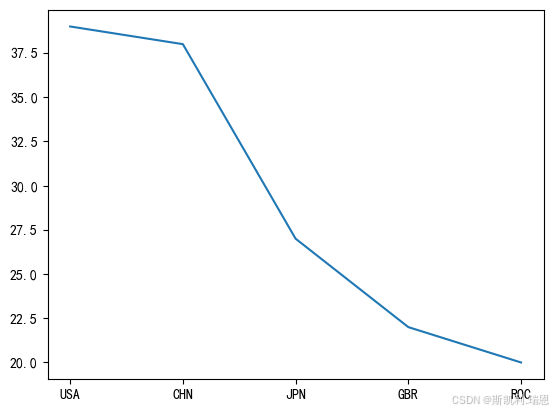
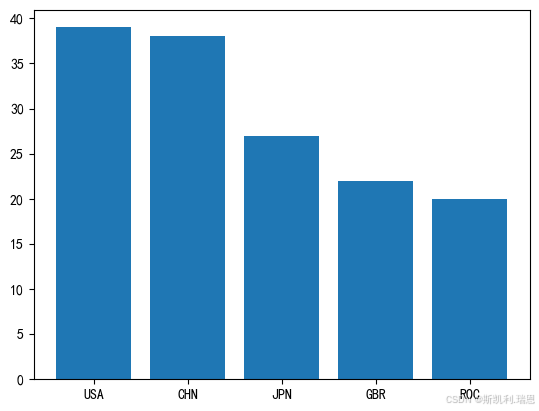
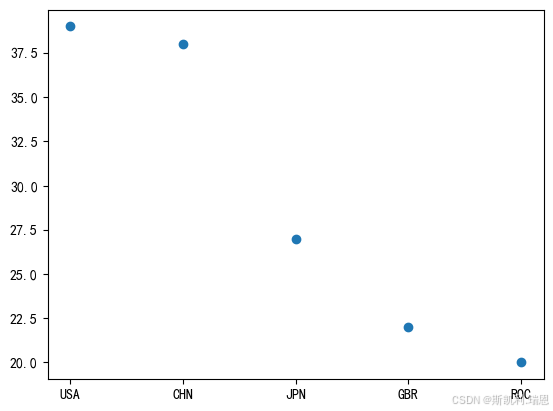
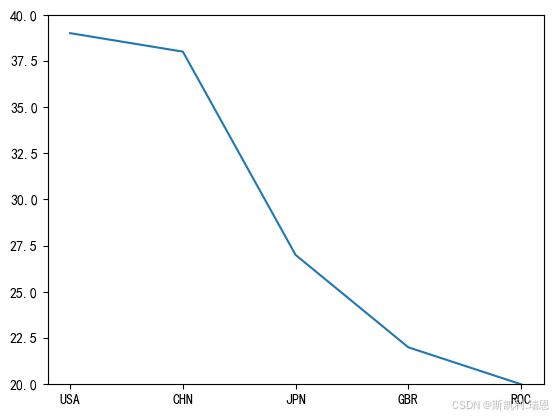
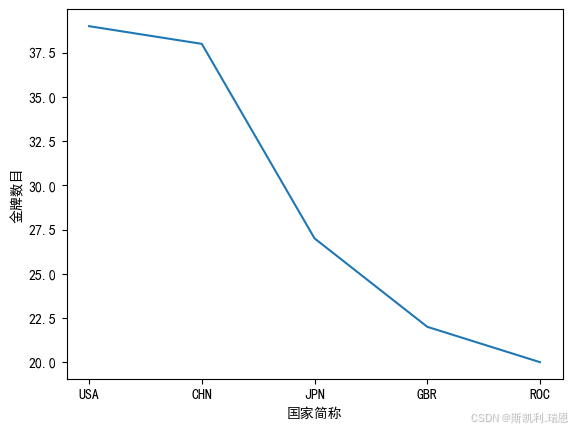
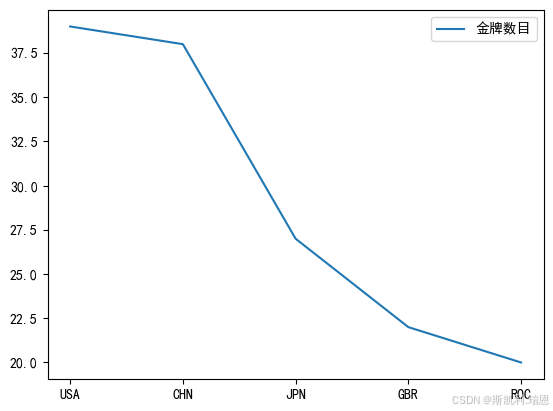
top5 = olpc[olpc.Rank<=5]#将排名>5的数据命名为top5
top5.rename(columns={'Team/NOC':'Team'},inplace=True)#给字段Team/NOC 改名为 Team
top5
C:\Users\LENOVO\AppData\Local\Temp\ipykernel_16248\4082916704.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
top5.rename(columns={'Team/NOC':'Team'},inplace=True) #给字段Team/NOC 改名为 Team