1、Python的多线程和多进程区别?
Linux内核开发中使用的比喻。进程是运行程序的抽象化。一个二进制映像、虚拟化的内存、各种内核资源、相关的安全上下文等等。线程是进程中的执行单位。一个虚拟化的处理器,一个堆栈,以及程序状态。换句话说,进程是正在运行的二进制文件,线程是可由操作系统的进程调度器调度的最小执行单位。
一个进程包含一个或多个线程。在单线程进程中,该进程包含一个线程。你可以说线程就是进程–有一件事正在进行。在多线程进程中,进程包含一个以上的线程–有不止一件事情在进行。
现代操作系统中两个主要的虚拟化抽象是虚拟化内存和虚拟化处理器。两者都给正在运行的进程带来了错觉,即它们独自消耗机器的资源。虚拟化内存给进程提供了一个独特的内存视图,无缝地映射到物理RAM或磁盘存储交换空间上。
虚拟化的处理器让进程表现得好像它们单独在一个处理器上运行,而事实上,多个进程在多个处理器上进行多任务处理。
虚拟化内存与进程而不是线程相关。因此,线程共享一个内存地址空间。相反,一个不同的虚拟化处理器与每个线程相关联。每个线程都是一个独立的可调度实体。
这有什么意义呢?我们显然需要进程。但为什么要引入线程的独立概念,并允许多线程进程呢?多线程有四个主要好处。
编程的抽象性。分割工作并将每个分工分配给一个执行单元(线程)是解决许多问题的自然方法。利用这种方法的编程模式包括反应器、每个连接的线程和线程池模式。
然而,有些人认为线程是一种反模式。无与伦比的Alan Cox用一句话很好地总结了这一点:“线程是为那些不能为状态机编程的人准备的。”
并行性。在拥有多个处理器的机器中,线程为实现真正的并行化提供了一种有效的方法。由于每个线程都有自己的虚拟化处理器,并且是一个可独立调度的实体,因此多个线程可以同时在多个处理器上运行,从而提高系统的吞吐量。只要线程被用来实现并行性–也就是说,线程不比处理器多–"线程是为不会编程状态机的人准备的 "这句话就不适用。
阻塞式I/O。如果没有线程,阻塞的I/O会使整个进程停止。这对吞吐量和延时都是不利的。在一个多线程的进程中,个别线程可能会阻塞,等待I/O,而其他线程则会向前推进。异步和非阻塞I/O是线程解决这一问题的替代方案。
节省内存。线程提供了一种有效的方式来共享内存,同时利用多个执行单元。以这种方式,它们是多进程的替代方案。
线程的这些好处的代价是增加了复杂性,需要通过互斥和条件变量等机制来管理并发性。鉴于处理器多核化和系统多处理器化的趋势日益明显,线程只会成为系统编程中一个更重要的工具。
2、有哪些多线程应用程序的最佳例子?
多线程的主要目的是提供一个程序的两个或多个部分的同时执行,可以同时运行。线程是独立的。如果一个线程发生异常,并不影响其他线程。
多线程的应用:
网络浏览器 - 一个网络浏览器可以同时下载任何数量的文件和网页多个标签,并且仍然让你继续浏览。如果某个网页无法下载,这并不会阻止网络浏览器下载其他网页。
网络服务器 - 线程网络服务器用一个新的线程处理每个请求。有一个线程池,每次有新的请求进来,都会分配给线程池中的一个线程。
计算机游戏–你有各种对象,如汽车、人类、鸟类,它们被实现为独立的线程。此外,在玩游戏的同时播放背景音乐也是多线程的一个例子。
文本编辑器 - 当你在编辑器中打字时,拼写检查、文本格式化和保存文本是由多个线程同时进行的。同样的情况也适用于文字处理器。
IDE - 像Android Studio这样的IDE同时运行多个线程。你可以在同一时间打开多个程序。它还会在完成一个命令时给出建议,这是一个独立的线程。
由于 Python 在使用线程时并行性有限,因此使用工作进程是利用多个 CPU 内核的常用方法。多处理模块内置于标准库中,因此经常用于此目的。
但是,虽然多个进程允许您利用多个 CPU,但在进程之间移动数据可能会非常慢。这可能会降低使用工作进程的一些性能优势:
为什么进程可能会出现线程没有的性能问题
解决或处理此性能开销的多种方法
不太糟糕的解决方案
线程与进程
多线程允许您并行运行代码,可能在多个 CPU 上。然而,在 Python 上,全局解释器锁使这种并行性更难实现。
多个进程还允许您并行运行代码,那么线程和进程之间有什么区别呢?
单个进程内的所有线程共享相同的内存地址空间。如果进程中的线程 1 在地址 0x7f0cd1a88810 处存储了一些内存,则线程 2 可以访问同一地址上的相同内存。
这意味着在线程之间传递对象开销便宜:你只需要将内存地址从一个线程获取到另一个线程的指针。内存地址是 8 个字节:很少的数据需要移动。
相反,进程不共享相同的内存空间。通常,操作系统提供了一些共享内存功能,我们稍后会谈到这一点。但默认情况下,不共享内存。
这意味着您不能只跨流程共享数据的地址:您必须复制数据。
如果您在进程之间传递一点数据,那很好;如果您正在DataFrame传递 1GB …这可能会开始变得昂贵。
Python 中的多进程处理
到目前为止,我们一直在讨论操作系统级别的进程,其中可用的工具基本上涉及复制字节:
从文件、共享内存或两者的花哨混合,如 mmap()但是,当你编写Python时,你希望在进程之间共享Python对象。
要启用此功能,当您使用 Python 的库在进程之间传递 Python 对象时:multiprocessing
在发送方端,参数使用 pickle 模块序列化为字节。在接收端,字节使用 .pickle此序列化和反序列化过程涉及计算,这可能会很慢。让我们尝试一个示例,将线程池与进程池进行比较:
from time import time
import multiprocessing as mp
from multiprocessing.pool import ThreadPool
import numpy as np
import pickle
def main():
arr = np.ones((1024, 1024, 1024), dtype=np.uint8)
expected_sum = np.sum(arr)
with ThreadPool(1) as threadpool:
start = time()
assert (
threadpool.apply(np.sum, (arr,)) == expected_sum
)
print("Thread pool:", time() - start)
with mp.get_context("spawn").Pool(1) as processpool:
start = time()
assert (
processpool.apply(np.sum, (arr,))
== expected_sum
)
print("Process pool:", time() - start)
if __name__ == "__main__":
main()
如果我们运行它,我们会得到以下内容:
$ python threads_vs_processes.py
Thread pool: 0.3097844123840332
Process pool: 1.8011224269866943
在子进程中运行代码比运行线程慢得多,不是因为计算速度较慢,而是因为复制和(反)序列化数据的开销。那么如何避免这种开销呢?
减少在进程之间复制数据对性能的影响
选项#1:仅使用线程
进程有此开销,线程没有。虽然通用 Python 代码在使用多个线程时确实不能很好地并行化,但对于您的 Python 代码来说不一定如此。例如,NumPy为其许多操作释放了GIL,这意味着即使使用线程,您也可以使用多个CPU内核。
例如:
import numpy as np
from time import time
from multiprocessing.pool import ThreadPool
arr = np.ones((1024, 1024, 1024))
start = time()
for i in range(10):
arr.sum()
print("Sequential:", time() - start)
expected = arr.sum()
start = time()
with ThreadPool(4) as pool:
result = pool.map(np.sum, [arr] * 10)
assert result == [expected] * 10
print("4 threads:", time() - start)
运行时,我们看到 NumPy 在使用线程时可以使用多个内核,至少对于此操作:
$ python numpy_gil.py
Sequential: 4.253053188323975
4 threads: 1.3854241371154785
在Python线程可以并行的情况下,例如使用NumPy的大部分API,使用进程的动机要少得多。有关更多详细信息,请阅读此 GIL 简介。
Pandas建立在NumPy上,因此许多数字运算也可能释放GIL。
但是,任何涉及字符串或一般 Python 对象的内容都不会。因此,另一种方法是使用像 Polars 这样的库,它是从头开始为并行性而设计的,以至于您根本不需要考虑它,它有一个内部线程池。
注意:任何特定的工具或技术是否会加快速度取决于软件中的瓶颈所在。
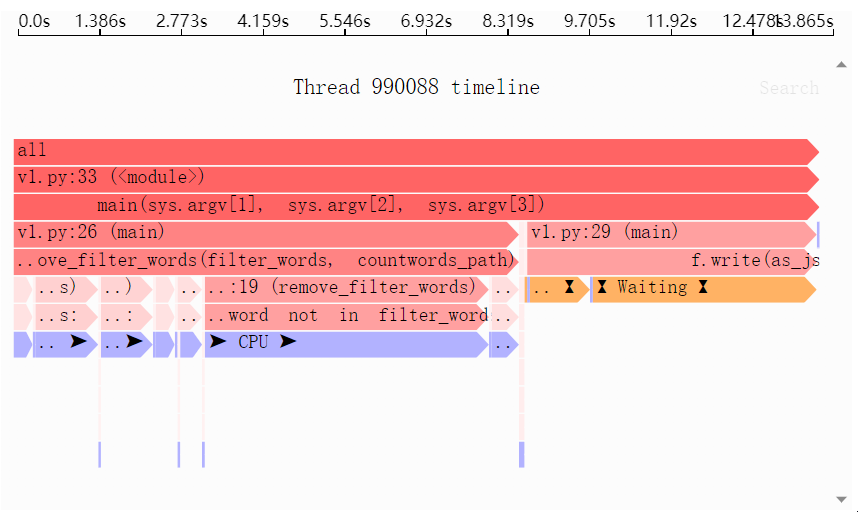
需要识别您自己的 Python 数据处理代码中的性能和内存瓶颈?试用 Sciagraph 探查器,它支持在开发和生产中进行剖析。
由 Sciagraph 创建的性能时间表,将 CPU 和 I/O 都显示为瓶颈 由 Sciagraph 创建的内存配置文件,显示列表理解是负责大多数内存使用的原因
选项#2:忍受它
如果您坚持使用流程,您可能只是决定忍受pickling的开销。特别是,如果最小化进程之间来回传递的数据量,并且每个进程中的计算量足够大,则复制和序列化数据的成本可能不会显著影响程序的运行时。
如果你的后续计算需要 10 分钟,花几秒钟在pickling上并不重要:
此外,值得注意的是,Python 有一个更快的pickling版本,从 3.11 开始默认不启用;它可能会在将来的版本中启用。
尽管它仍然存在,这将在一定程度上减少pickling的开销。
选项 #3:将数据写入磁盘
您可以将数据写入磁盘,而不是直接传递数据,然后将此文件的路径传递给子进程(作为参数)或父进程(作为工作进程中运行的函数的返回值)。然后,收件人进程可以分析该文件。
下面是一个比较直接传递数据帧和使用临时 Parquet 文件传递数据帧的示例:
import pandas as pd
import multiprocessing as mp
from pathlib import Path
from tempfile import mkdtemp
from time import time
def noop(df: pd.DataFrame):
# real code would process the dataframe here
pass
def noop_from_path(path: Path):
df = pd.read_parquet(path, engine="fastparquet")
# real code would process the dataframe here
pass
def main():
df = pd.DataFrame({"column": list(range(10_000_000))})
with mp.get_context("spawn").Pool(1) as pool:
# Pass the DataFrame to the worker process
# directly, via pickling:
start = time()
pool.apply(noop, (df,))
print("Pickling-based:", time() - start)
# Write the DataFrame to a file, pass the path to
# the file to the worker process:
start = time()
path = Path(mkdtemp()) / "temp.parquet"
df.to_parquet(
path,
engine="fastparquet",
# Run faster by skipping compression:
compression="uncompressed",
)
pool.apply(noop_from_path, (path,))
print("Parquet-based:", time() - start)
if __name__ == "__main__":
main()
如果我们运行它,我们可以看到镶木地板版本确实更快:
$ python tofile.py Pickling-based: 0.24182868003845215 Parquet-based: 0.17243456840515137
当然,Parquet 在所有情况下都可能更快,也可能不会更快,并且在 Python 的未来版本中可能会运行得更快,但这种方法在某些情况下可能会有所帮助。
选项#4:multiprocessing.shared_memory
由于进程有时确实需要共享内存,因此操作系统通常提供用于在进程之间显式创建共享内存的工具。Python 将此功能包装在——
multiprocessing.shared_memory 模块中
但是,与线程不同,在线程中,相同的内存地址空间允许轻松共享 Python 对象,在这种情况下,您主要限于共享数组。
正如我们所看到的,NumPy发布了用于昂贵操作的GIL,这意味着您可以只使用线程,这要简单得多。不过,如果你需要它,值得知道这个模块的存在。
注意:该模块还包括 ShareableList,它有点像 Python 列表,但这并不能帮助你共享任意的Python对象intfloatboolstrbytesNone
Linux 的一个糟糕选择"fork"
您可能已经注意到,我们确实创建了一个进程池。这是因为 Python 在某些操作系统上具有多个多处理实现。
是Windows上唯一的选项,macOS上唯一的非损坏选项,并且在Linux上可用。使用 时,将创建一个全新的进程,因此您始终必须复制数据。
multiprocessing.get_context("spawn").Pool()"spawn""spawn"
在 Linux 上,默认值为 :新的子进程在创建子进程时具有父进程内存的完整副本。这意味着在创建子进程之前创建的父对象(数组、巨型字典等)中的任何对象,并且存储在像模块这样的有用位置,都可以被子进程访问。
这意味着您无需pickle/unpickle即可访问它们。
“fork” 听起来很有用,对吧?
只有一个问题:上下文是严重破坏的,这就是为什么它将不再是Python 3.14中的默认值"fork",请考虑以下程序:
import threading
import sys
from multiprocessing import Process
def thread1():
for i in range(1000):
print("hello", file=sys.stderr)
threading.Thread(target=thread1).start()
def foo():
pass
Process(target=foo).start()
在我的电脑上,这个程序一直死锁:它冻结并且永远不会退出。只要父进程中有线程,上下文都可能导致子进程中出现潜在的死锁,甚至内存损坏。
"fork"可能会认为没有启动任何线程,但是许多Python库在导入时启动线程池,例如NumPy,Pandas 或任何其他依赖于 NumPy 的库,则您正在运行线程程序,因此在使用多处理上下文时存在死锁、段错误或数据损坏的风险。
所以理论上这是 Linux 上的一个选项,但实际上你真的不想使用它。因此,我不会费心向您展示如何以这种方式跨进程传递数据。
如果你真的想知道,其他地方有文章证明了这一点,但如果你采取这种方法,你只是在搬起石头砸自己的脚。
您需要权衡
在你花太多时间试图解决这个特定的性能问题之前,你真的应该衡量你的软件的性能,并找出它的实际瓶颈在哪里。
线程实际上很可能工作得很好(选项 #1)或者跨进程通信的额外开销无关紧要(选项 #2)
只有分析软件并找出实际的瓶颈是什么,您才会知道解决瓶颈。
关于Python的技术储备
如果你是准备学习Python或者正在学习,下面这些你应该能用得上:
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
⑤历年互联网企业Python面试真题,复习时非常方便
文末有领取方式哦
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python课程视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
三、Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
四、Python漫画教程
用通俗易懂的漫画,来教你学习Python,让你更容易记住,并且不会枯燥乏味。


五、互联网企业面试真题
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要也可以扫描下方csdn官方二维码或者点击主页和文章下方的微信卡片获取领取方式,【保证100%免费】