Attention显存估计
简单的Attention函数
import torch
import torch.nn as nn
import einops
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, L, C = x.shape
qkv = self.qkv(x)
if ATTENTION_MODE == 'flash':
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B H L D', K=3, H=self.num_heads).float()
q, k, v = qkv[0], qkv[1], qkv[2] # B H L D
x = torch.nn.functional.scaled_dot_product_attention(q, k, v)
x = einops.rearrange(x, 'B H L D -> B L (H D)')
elif ATTENTION_MODE == 'xformers':
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B L H D', K=3, H=self.num_heads)
q, k, v = qkv[0], qkv[1], qkv[2] # B L H D
x = xformers.ops.memory_efficient_attention(q, k, v)
x = einops.rearrange(x, 'B L H D -> B L (H D)', H=self.num_heads)
elif ATTENTION_MODE == 'math':
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B H L D', K=3, H=self.num_heads)
q, k, v = qkv[0], qkv[1], qkv[2] # B H L D
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, L, C)
else:
raise NotImplemented
x = self.proj(x)
x = self.proj_drop(x)
return x
# 设置注意力模式
ATTENTION_MODE = 'math'
# 参数设置
B = 64 # batch size
L = 32 # sequence length
C = 512 # embedding dimension
H = 8 # number of heads
# 创建模型和输入张量
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
initial_memory_1 = torch.cuda.memory_allocated(device)
attention = Attention(dim=C, num_heads=H).to(device)
x = torch.randn(B, L, C).to(device)
# 监控显存使用情况
torch.cuda.reset_peak_memory_stats(device)
initial_memory = torch.cuda.memory_allocated(device)
# 使用 autograd profiler 来记录显存使用情况
with torch.autograd.profiler.profile(profile_memory=True, record_shapes=True) as prof:
output = attention(x)
# 计算显存占用ru
final_memory = torch.cuda.memory_allocated(device)
max_memory = torch.cuda.max_memory_allocated(device)
# 打印结果
print(f"Initial Memory_1: {initial_memory_1 / 1024**2:.2f} MB")
print(f"Initial Memory: {initial_memory / 1024**2:.2f} MB")
print(f"Final Memory: {final_memory / 1024**2:.2f} MB")
print(f"Max Memory: {max_memory / 1024**2:.2f} MB")
print(f"Activation Memory: {(final_memory - initial_memory) / 1024**2:.2f} MB")
# 打印详细的显存使用情况
print(prof.key_averages().table(sort_by="self_cuda_memory_usage", row_limit=10))
1 模型占用的显存
两个线性层,
一个是qkv 层
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
假定嵌入为C,则参数量为
C×(3×C)+(3×C)(偏置项)
一层是线性层
self.proj = nn.Linear(dim, dim)
参数为
C×C+C(偏置项)
总共是
4
∗
C
2
+
4
∗
C
4*C^2+4*C
4∗C2+4∗C,需要乘以FP32的字节量即4
假定 C = 512,则为
(
4
∗
51
2
2
+
4
∗
512
)
∗
4
/
1024
/
1024
=
4
M
B
(4*512^2+4*512)*4/1024/1024=4MB
(4∗5122+4∗512)∗4/1024/1024=4MB
2 前向过程产生的最大峰值
import torch
import torch.nn as nn
import einops
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, L, C = x.shape
# 记录显存使用
print(f"Before qkv: {torch.cuda.memory_allocated() / 1024**2:.2f} MB")
prev_memory = torch.cuda.memory_allocated()
qkv = self.qkv(x)
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After qkv: {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
if ATTENTION_MODE == 'flash':
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B H L D', K=3, H=self.num_heads).float()
q, k, v = qkv[0], qkv[1], qkv[2] # B H L D
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After rearrange (flash): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
x = torch.nn.functional.scaled_dot_product_attention(q, k, v)
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After scaled_dot_product_attention (flash): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
x = einops.rearrange(x, 'B H L D -> B L (H D)')
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After rearrange (flash): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
elif ATTENTION_MODE == 'xformers':
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B L H D', K=3, H=self.num_heads)
q, k, v = qkv[0], qkv[1], qkv[2] # B L H D
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After rearrange (xformers): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
x = xformers.ops.memory_efficient_attention(q, k, v)
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After memory_efficient_attention (xformers): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
x = einops.rearrange(x, 'B L H D -> B L (H D)', H=self.num_heads)
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After rearrange (xformers): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
elif ATTENTION_MODE == 'math':
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B H L D', K=3, H=self.num_heads)
q, k, v = qkv[0], qkv[1], qkv[2] # B H L D
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After rearrange (math): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
attn = (q @ k.transpose(-2, -1)) * self.scale
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After matmul (math): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
attn = attn.softmax(dim=-1)
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After softmax (math): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
attn = self.attn_drop(attn)
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After dropout (math): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
x = (attn @ v).transpose(1, 2).reshape(B, L, C)
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After final matmul and reshape (math): {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
else:
raise NotImplemented
print(f"Before proj: {torch.cuda.memory_allocated() / 1024**2:.2f} MB")
x = self.proj(x)
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After proj: {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
prev_memory = current_memory # 更新 prev_memory
print(f"Before proj_drop: {torch.cuda.memory_allocated() / 1024**2:.2f} MB")
x = self.proj_drop(x)
current_memory = torch.cuda.memory_allocated()
memory_change = (current_memory - prev_memory) / 1024**2
print(f"After proj_drop: {current_memory / 1024**2:.2f} MB, Change: {memory_change:.2f} MB")
return x
# 设置注意力模式
ATTENTION_MODE = 'math'
# 参数设置
B = 64 # batch size
L = 32 # sequence length
C = 512 # embedding dimension
H = 8 # number of heads
# 创建模型和输入张量
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
initial_memory_1 = torch.cuda.memory_allocated(device)
attention = Attention(dim=C, num_heads=H).to(device)
x = torch.randn(B, L, C).to(device)
# 监控显存使用情况
torch.cuda.reset_peak_memory_stats(device)
initial_memory = torch.cuda.memory_allocated(device)
# 前向传播
output = attention(x)
# 计算显存占用
final_memory = torch.cuda.memory_allocated(device)
max_memory = torch.cuda.max_memory_allocated(device)
# 打印结果
print(f"Initial Memory_1: {initial_memory_1 / 1024**2:.2f} MB")
print(f"Initial Memory: {initial_memory / 1024**2:.2f} MB")
print(f"Final Memory: {final_memory / 1024**2:.2f} MB")
print(f"Max Memory: {max_memory / 1024**2:.2f} MB")
print(f"Activation Memory: {(final_memory - initial_memory) / 1024**2:.2f} MB")
结果如下显示
Before qkv: 8.00 MB
After qkv: 21.00 MB, Change: 13.00 MB
After rearrange (math): 21.00 MB, Change: 0.00 MB
After matmul (math): 31.00 MB, Change: 10.00 MB
After softmax (math): 31.00 MB, Change: 0.00 MB
After dropout (math): 31.00 MB, Change: 0.00 MB
After final matmul and reshape (math): 39.00 MB, Change: 8.00 MB
Before proj: 39.00 MB
After proj: 43.00 MB, Change: 4.00 MB
Before proj_drop: 43.00 MB
After proj_drop: 43.00 MB, Change: 0.00 MB
Initial Memory_1: 0.00 MB
Initial Memory: 8.00 MB
Final Memory: 30.00 MB
Max Memory: 44.00 MB
Activation Memory: 22.00 MB
根据打印语句进行分析
import torch
import torch.nn as nn
import einops
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, L, C = x.shape
qkv = self.qkv(x) # qkv矩阵,此处增加BLC*3
if ATTENTION_MODE == 'flash':
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B H L D', K=3, H=self.num_heads).float()
q, k, v = qkv[0], qkv[1], qkv[2] # B H L D
x = torch.nn.functional.scaled_dot_product_attention(q, k, v)
x = einops.rearrange(x, 'B H L D -> B L (H D)')
elif ATTENTION_MODE == 'xformers':
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B L H D', K=3, H=self.num_heads)
q, k, v = qkv[0], qkv[1], qkv[2] # B L H D
x = xformers.ops.memory_efficient_attention(q, k, v)
x = einops.rearrange(x, 'B L H D -> B L (H D)', H=self.num_heads)
elif ATTENTION_MODE == 'math':
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B H L D', K=3, H=self.num_heads) #不变
q, k, v = qkv[0], qkv[1], qkv[2] # B H L D # 不变,索引只是切片的操作
attn = (q @ k.transpose(-2, -1)) * self.scale # 此处使用q和k,需要存储中间变量,因此产生 (B,H ,L D)*2的显存,存储结果,产生(B,H,L,L)的显存
attn = attn.softmax(dim=-1) #显存不变
attn = self.attn_drop(attn) #显存不变
x = (attn @ v).transpose(1, 2).reshape(B, L, C) # 使用到v,存储变量,产生(BHLD)的显存,存储结果,产生BLC的显存
else:
raise NotImplemented
x = self.proj(x) # 产生BLC的显存
x = self.proj_drop(x)#不变
return x
# 设置注意力模式
ATTENTION_MODE = 'math'
# 参数设置
B = 64 # batch size
L = 32 # sequence length
C = 512 # embedding dimension
H = 8 # number of heads
# 创建模型和输入张量
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
initial_memory_1 = torch.cuda.memory_allocated(device)
attention = Attention(dim=C, num_heads=H).to(device)
x = torch.randn(B, L, C).to(device)
# 监控显存使用情况
torch.cuda.reset_peak_memory_stats(device)
initial_memory = torch.cuda.memory_allocated(device)
# 使用 autograd profiler 来记录显存使用情况
with torch.autograd.profiler.profile(profile_memory=True, record_shapes=True) as prof:
output = attention(x)
# 计算显存占用ru
final_memory = torch.cuda.memory_allocated(device)
max_memory = torch.cuda.max_memory_allocated(device)
# 打印结果
print(f"Initial Memory_1: {initial_memory_1 / 1024**2:.2f} MB")
print(f"Initial Memory: {initial_memory / 1024**2:.2f} MB")
print(f"Final Memory: {final_memory / 1024**2:.2f} MB")
print(f"Max Memory: {max_memory / 1024**2:.2f} MB")
print(f"Activation Memory: {(final_memory - initial_memory) / 1024**2:.2f} MB")
# 打印详细的显存使用情况
print(prof.key_averages().table(sort_by="self_cuda_memory_usage", row_limit=10))
因此,产生的总显存为
BLC*3(qkv) + BHLD*2(qk算点乘,属于中间变量)+BHLL(atten)+BHLD(v矩阵)+BLC(输出结果)+BLC(线性映射)=BLC*8+BHLL
和其余blog记录的差不多,只不过显存增加的时间点和之前想象的不同
线性层产生显存
1 x = self.proj(x) 产生显存的原因
在这里,self.proj(x) 是一个 线性投影 操作,通常是通过一个线性层(nn.Linear)实现的。这个操作会执行以下几步:
- 矩阵乘法:假设
self.proj是一个线性层(如nn.Linear),它会对输入x执行矩阵乘法,计算x @ W^T + b,其中W是权重矩阵,b是偏置。 - 新张量的分配:线性变换会生成一个新的张量,并且这个张量的形状通常会与输入
x不同(例如,x可能是(B, L, D),而输出x可能是(B, L, D'))。这个新的张量需要分配新的内存,因此它会产生显存。
2 x = self.proj_drop(x) 不产生显存的原因
self.proj_drop 通常是一个 Dropout 操作。Dropout 是一种正则化技术,在训练时随机地丢弃一部分神经元,以防止过拟合。它不会创建新的张量,而是直接在原有的张量上进行操作。具体来说,Dropout 会在每次前向传播时,对输入张量的部分元素乘以零,但它 不会改变张量的形状或大小。
- 内存共享:
Dropout操作不会创建新的张量副本,而是就地修改原始张量。因此,显存消耗不会增加。它只是改变了张量的值(通过乘以0),但并不需要额外的内存。 - 不产生新张量:
Dropout仅仅是通过一个掩码(mask)将某些值屏蔽掉,操作是原地进行的,因此不需要为输出分配新的内存。
3 attn = attn.softmax(dim=-1) 和 attn = self.attn_drop(attn)
- Softmax 操作:
attn.softmax(dim=-1)是对attn张量沿着最后一个维度(通常是特征维度)进行 softmax 操作。这个操作是通过对原张量进行逐元素的数值变换(softmax 归一化)来完成的,但它 不需要额外的内存。实际上,它会直接在原始张量上进行操作,因此不会创建新的张量。 - Dropout 操作:
self.attn_drop(attn)也是一个类似的 dropout 操作,它对attn张量进行处理,但不会改变张量的形状。和前面的proj_drop一样,dropout 不需要新的内存,它只在原始张量上执行修改(通过将一些值置为零)
3 执行结束后保留的激活值
可以看到前向激活值峰值和执行完前向保留的激活值大小不同,上述例子中峰值为34MB,而执行完前向后保留的激活值为22MB
分析哪些释放、哪些保存,需要结合模型的网络结构
总结:保存与释放的变量对比
| 变量名称 | 状态 | 原因 | |
|---|---|---|---|
**一层后产生的激活(qkv) ** | 保存 | 用于反向传播时计算 q, k, v 的梯度。 | |
重排后的 q, k, v | 释放 | 在计算 attn 和输出后不再需要。 | |
第二层产生的激活( x) | 保存 | 用于回传梯度到上一层。 | |
最终输出张量 x | 保存 | 作为前向传播的输出,供后续层使用或反向传播。 | |
q @ k^T | 保存 | 用于计算梯度(链式法则的一部分)。 | |
| 所以为12+4+4+2 = 22MB |
1 为什么存储attn q@ k^T
经过Softmax,所以需要存储,属于激活值中的一部分
2 为什么不存储分割后的qkv
属于中间变量,不需要存储
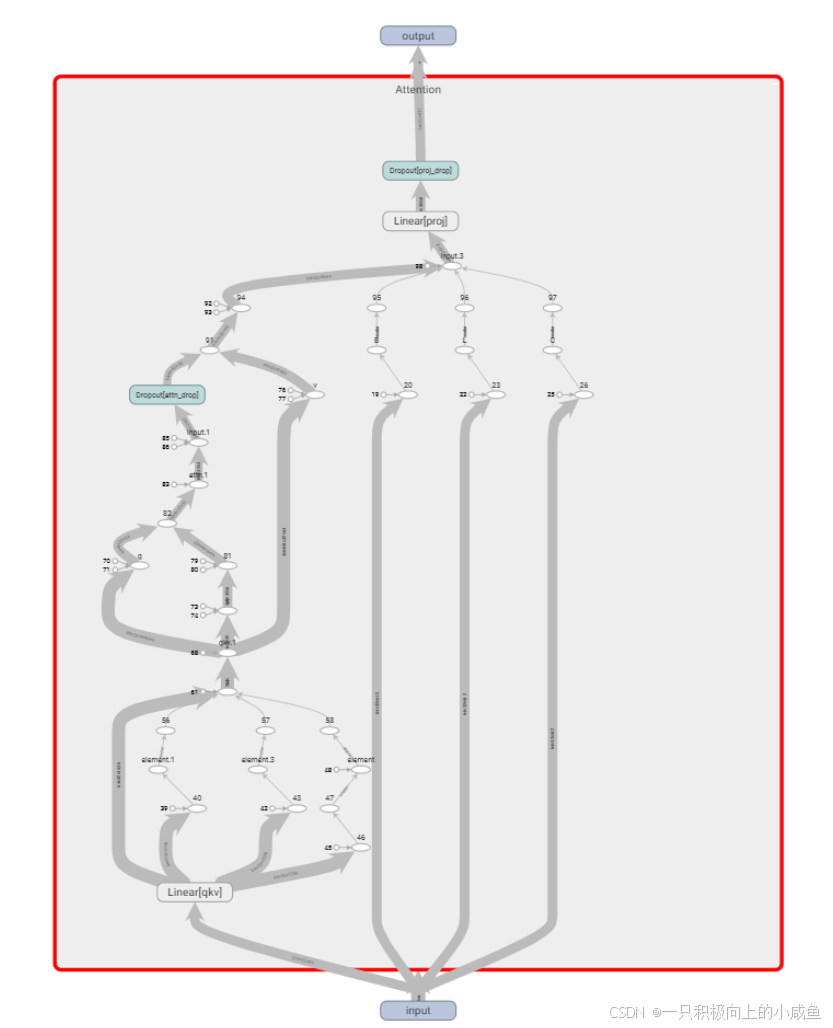
4 查看计算图
1 tensorboard查看计算图
import torch
import torch.nn as nn
import einops
from torch.utils.tensorboard import SummaryWriter
import os
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, writer=None, step=None):
B, L, C = x.shape
qkv = self.qkv(x)
qkv = einops.rearrange(qkv, 'B L (K H D) -> K B H L D', K=3, H=self.num_heads)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, L, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
# 设置参数
B, L, C, H = 64, 32, 512, 8
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 确保路径存在
log_dir = "./tensorboard_writer"
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# 初始化模型和输入张量
attention = Attention(dim=C, num_heads=H).to(device)
x = torch.randn(B, L, C).to(device)
# 初始化 TensorBoard
writer = SummaryWriter(log_dir=log_dir)
print("TensorBoard writer initialized.")
# 添加计算图和激活值
with torch.no_grad():
writer.add_graph(attention, (x,)) # 修正计算图输入
attention(x, writer=writer, step=0) # 记录激活值
# 确保数据写入文件
writer.flush()
writer.close()
运行
tensorboard --logdir=./tensorboard_writer --port=6007
查看计算图