目录
实习安排
- 第一天:Python基础,图像处理
- 第二天:全连接神经网络,卷积神经网络
- 第三天:PaddlePaddle搭建神经网络,手写体识别训练模型
- 第四天:手写体识别模型检测任务测试,模型参数 提取
- 第五天:C语言实现手写体识别算子,HLS编译算子
- 第六天:编写SoC端测试代码,项目整合
- 第七天:OpenVINO工具套件介绍与使用
- 第八天:AI Studio使用及配置ppyoloe模型参数
- 第九天:基于OpenVINO的口罩检测任务
- 第十天:学生拓展项目,项目答辩
一、环境准备及数据准备
1.环境准备
- 工具:labelImg,AI Studio,YOLO2COCO,PaddleUtils,PaddleYOLO
- 本地环境要求:
openvino2022.2.0
paddle2onnx1.0.5
paddlepaddle2.4.2
opencv-python4.2.0.32
onnx1.11.0
tensorflow2.9.1 - labelimg是一个有图形界面的图像标注工具,用来给数据打标签。
- 安装工具之前需要建立python虚拟环境,虚拟环境建立请移步至《Python安装及虚拟环境建立》教程
- AI Studio是基于百度深度学习平台飞桨的人工智能学习与实训社区,提供在线编程环境、免费GPU 算力、海量开源算法和开放数据,帮助开发者快速创建和部署模。初次使用的小伙伴记得注册之后完成新手礼包获取算力卡。
- 借助YOLO2COCO把YOLO格式的标签数据转成COCO格式数据集。
- 这是一个paddlepaddle模型减支工具,我们需要把训练得到的ppyoloe口罩检测模型进行裁剪。
- paddleyolo里面有很多目标检测算法,其中包括ppyoloe这个算法,使用的时候只需要配置一些文件就可以训练我们的模型了,非常方便。因为训练模型需要GPU,所以需要在AI Studio里面使用paddleyolo。
- 库的安装
openvino的安装
pip install openvino-dev[onnx,tensorflow]==2022.2.0
其他的都pip install 库名==版本,如果安装很慢,可以加一个镜像比如
pip install paddle2onnx==1.0.5 -i https://pypi.tuna.tsinghua.edu.cn/simple/
2.数据准备
目录结构
----mask
----images
----mask_00133.jpg
----mask_00134.jpg
.
.
.
----labels
----mask_00133.txt
----mask_00134.txt
.
.
.
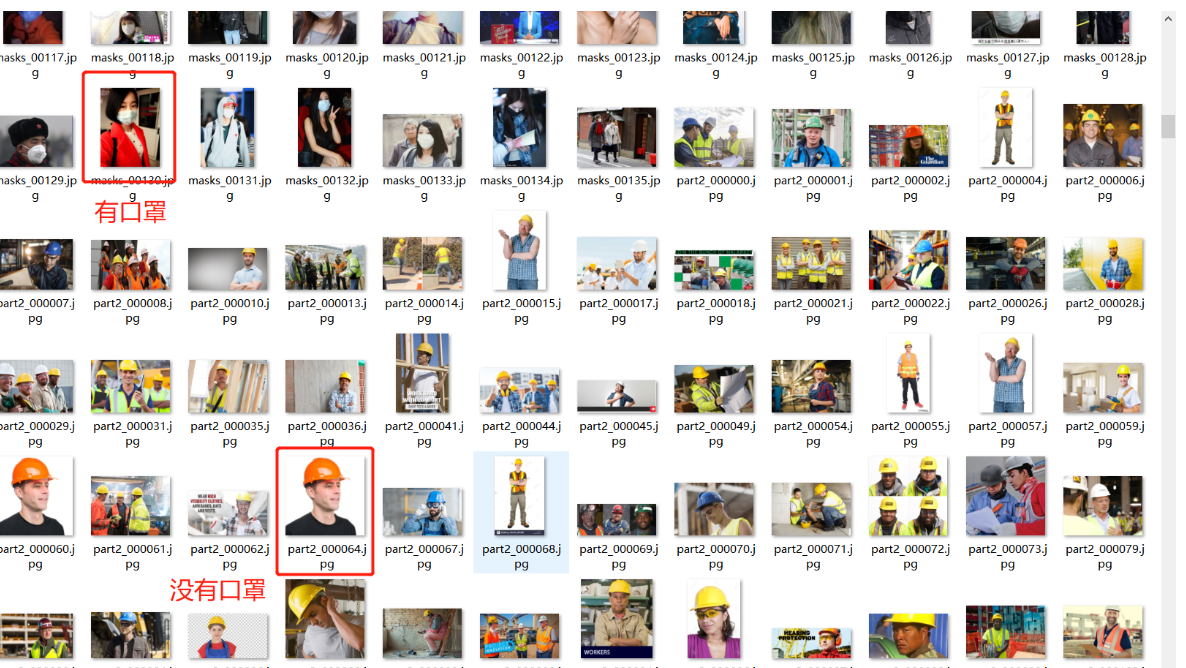
图片数量有2076张,人脸数据较多,口罩数据较少。图片大致如下所示:
数据来自一些公开的数据集,为了让模型训练得更好,自己也收集了一些数据,并使用labelimg对数据进行标注。
-
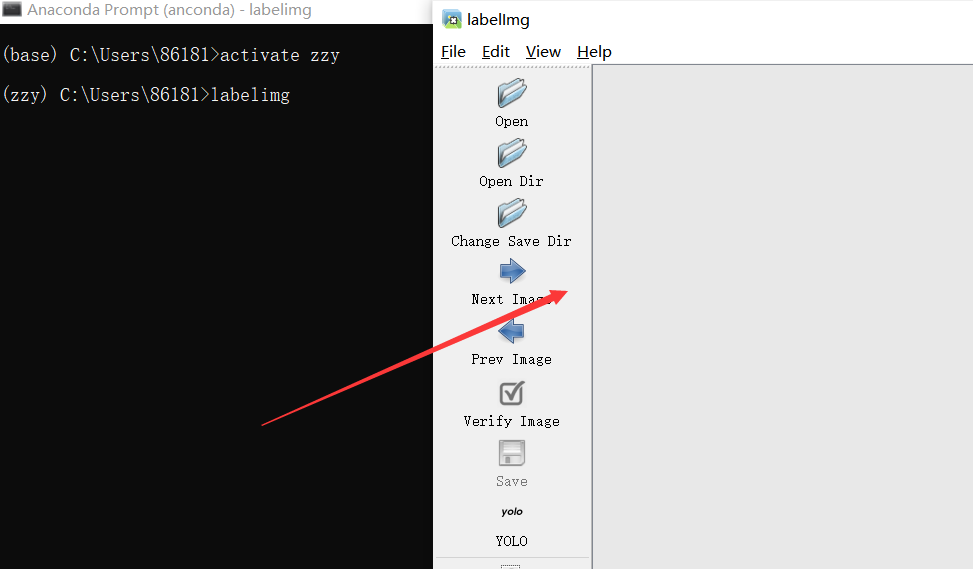
启动labelimg
在虚拟环境下输入:labelimg
-
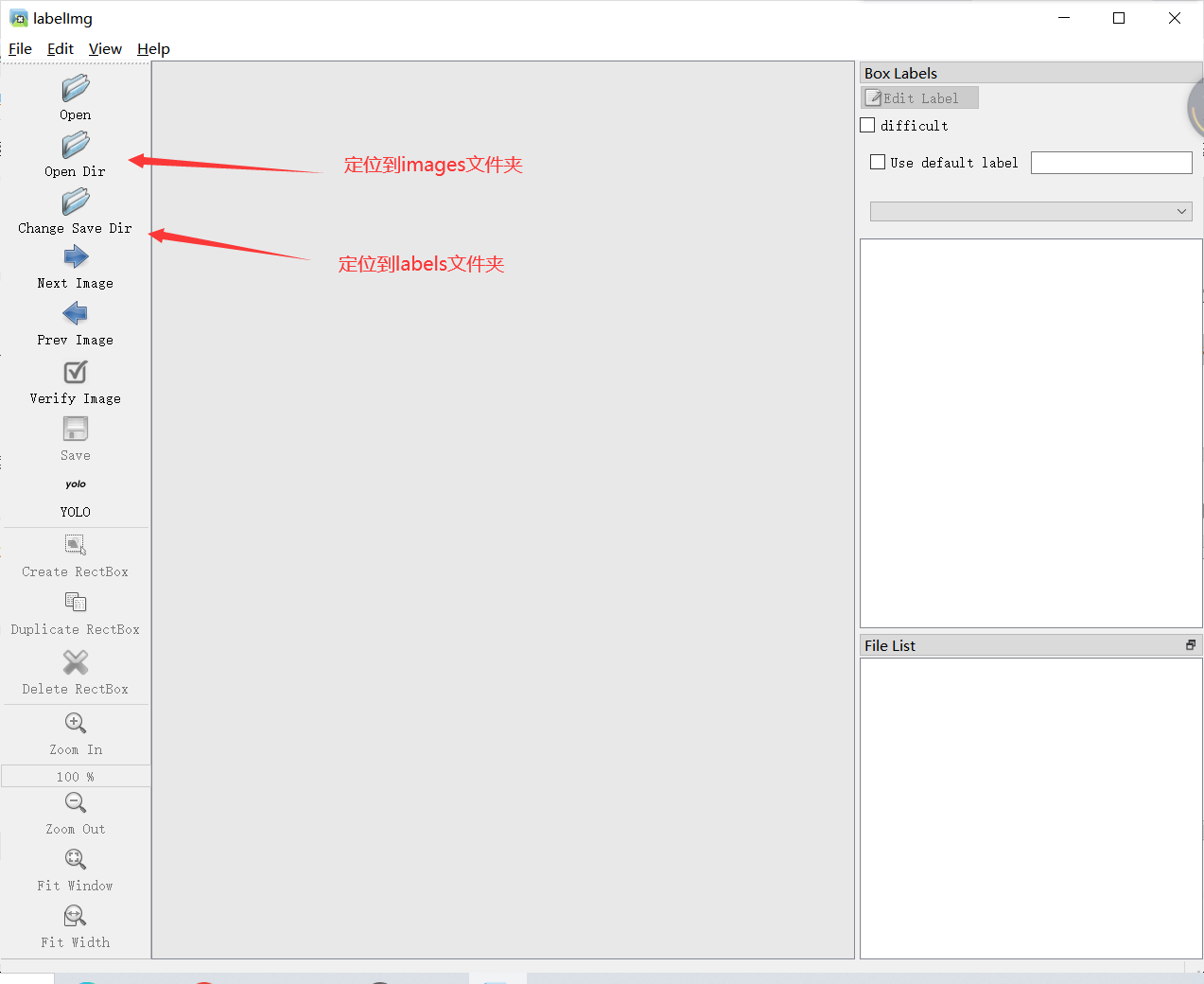
指定要标注的图片文件夹,我们的文件夹是images。指定labels文件夹,被标注的图片生成的.txt标签文件会自动保存到labels文件夹下。
-
数据格式选用yolo,因为公开数据集是yolo格式,所以统一用yolo。
-
操作:按下w选取区域,并输入标签,每输入一张图片都要保存,按a和d进行左右切换图片,每张图片可选取多个区域。
-
生成的标签txt文件。除了根据图片名字生成相应的标签txt,还有一个classes.txt,可以将其移除该文件夹,注意是移除,不是删除。
-
因为只有两个标签mask和nomask,所以classes.txt如下所示:
-
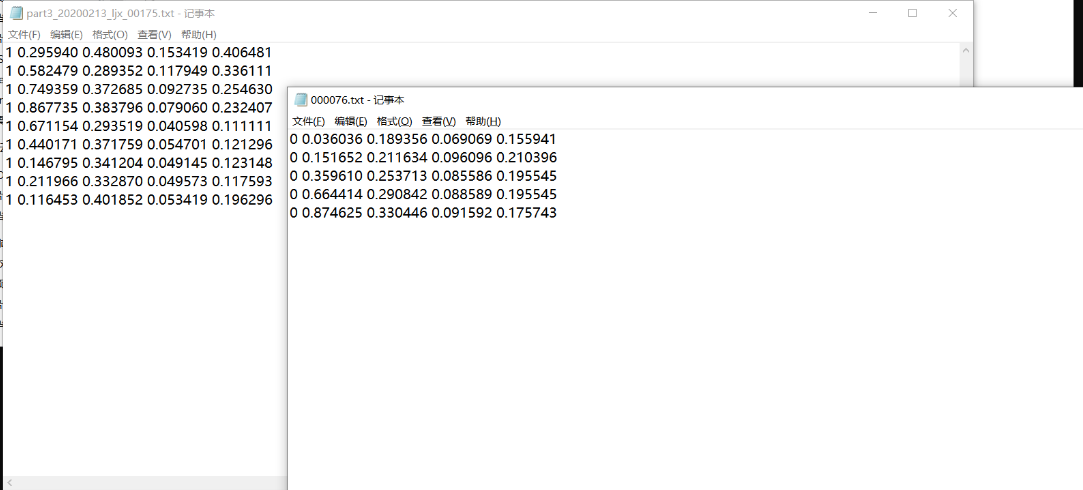
生成的标签txt文件


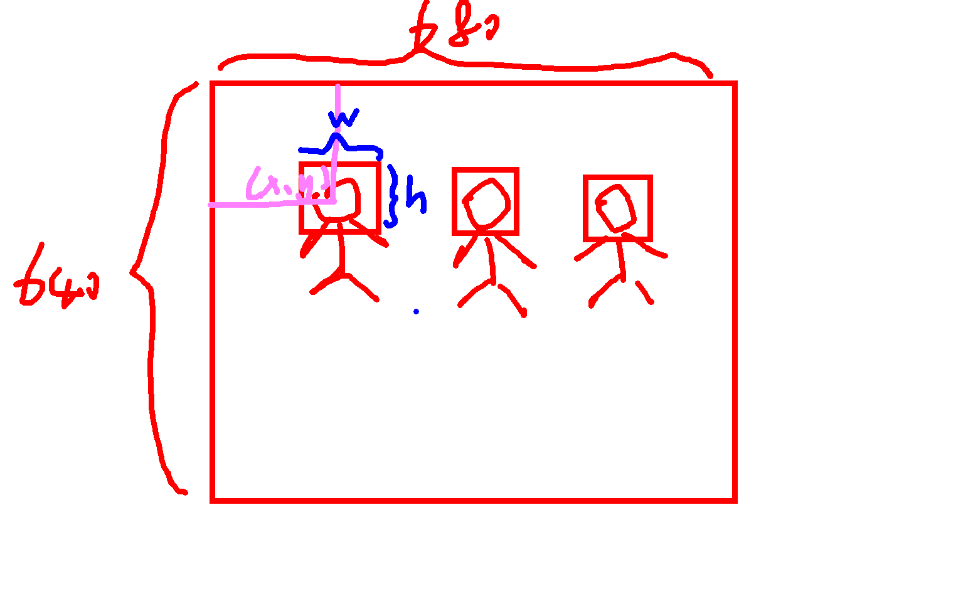
0表示nomask,1表示mask,图片中标注了多少个框,相应的生成几排数据。如下魔性图中,假如图片是680x640,0或者1后面的几个小数分别代表框的中心坐标x,y,框的宽w,框的高h。为什么是小数?是因为x/680,y/640,w/680,h/640。
数据转换
数据集拆分,严格意义上讲,应该把数据拆成训练集、测试集、验证集,我们为了方便,就只需要拆分成训练集和验证集就可以了。在YOLO2COCO\dataset文件下建立一个yolo_mask文件夹,然后将mask移动到此文件夹下。点击YOLO2COCO获取工具。
YOLO2COCO给的模板
先把第上面产生的classes.txt移动至yolo_mask文件夹下面,形如这样。
现在编写一个python生产我们需要的train.txt,val.txt。
import os
def train_val(labels_path, data_path, ratio=0.3):
nomask_num = 0#计数nomask的数量
mask_num = 0#计数mask的数量
image_dir = "\\".join(data_path.split("\\")[-3:]) + "\\images"#根据yolo2coco要求制定路径
txt_files = os.listdir(labels_path)
f_train = open("train.txt", "w")
f_val = open("val.txt", "w")
m = 0
n = 0
for txt in txt_files:
f_txt = open(os.path.join(labels_path, txt), 'r')#打开txt文件
if f_txt.read()[0] == "0":#读取每个文件的第一行,判断是nomask(0)还是mask(1)
nomask_num += 1#不戴口罩加1
else:
mask_num += 1#戴口罩加1
f_txt.close()
for txt in txt_files:
f_txt = open(os.path.join(labels_path, txt), 'r')
if f_txt.read()[0] == "0":#读取每个文件的第一行,判断是nomask(0)还是mask(1)
n += 1
if n >= int(nomask_num * ratio):
f_train.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
else:
f_val.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
else:
m += 1
if m >= int(mask_num * ratio):
f_train.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
else:
f_val.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
f_txt.close()
f_train.close()
f_val.close()
if __name__ == "__main__":
data_path = os.path.join(os.getcwd(), 'mask')#获取文件夹mask的绝对路径
labels_path = os.path.join(data_path, "labels")#获取labels文件夹的绝对路径
train_val(labels_path=labels_path, data_path=data_path, ratio=0.3)
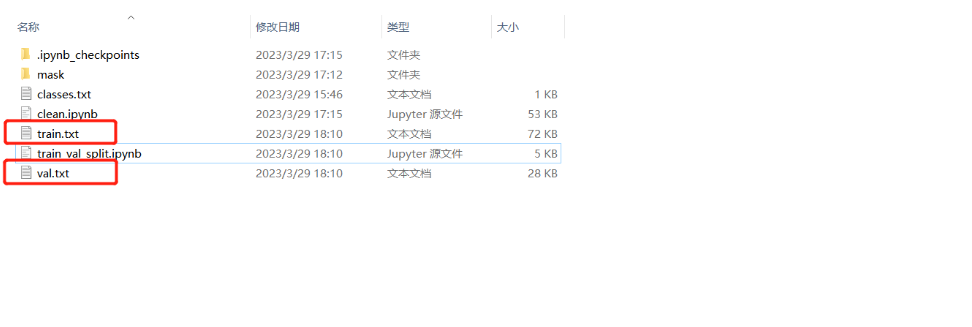
生成的train.txt,val.txt如下,train_val_split是上述源代码文件,放置位置如下图所示,因为使用的jupyter notebook编写,所以是.ipynb,可以转成.py文件并在该文件夹下运行。
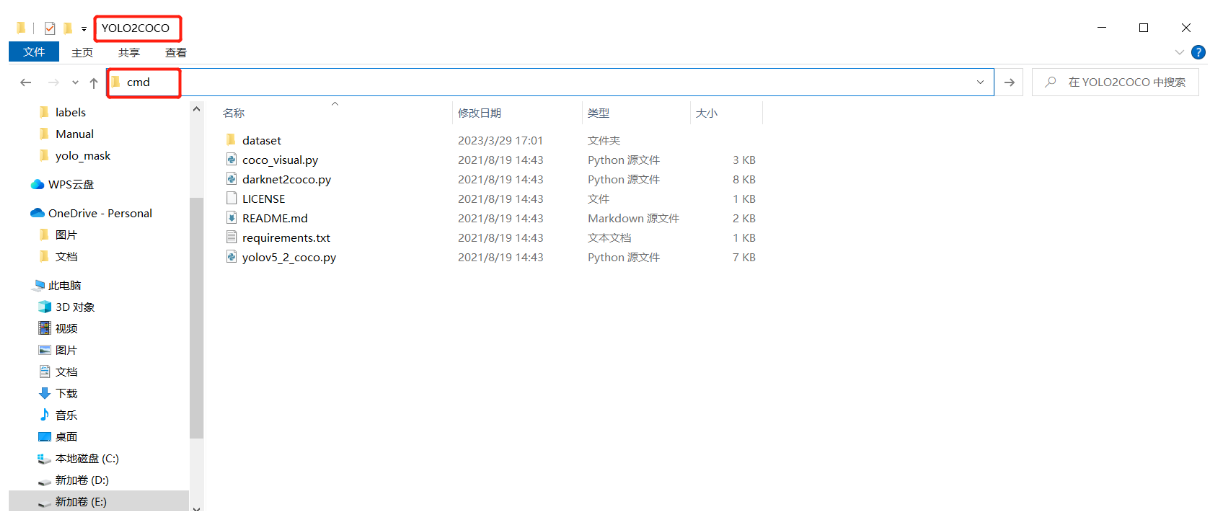
接下来可以转换数据了,clean.ipynb和train_val_split.ipynb不会影响转换过程,所以不用删除,毕竟是自己写的,删掉可惜了。在YOLO2COCO文件夹下启动cmd
根据自己的目录情况执行以下命令。
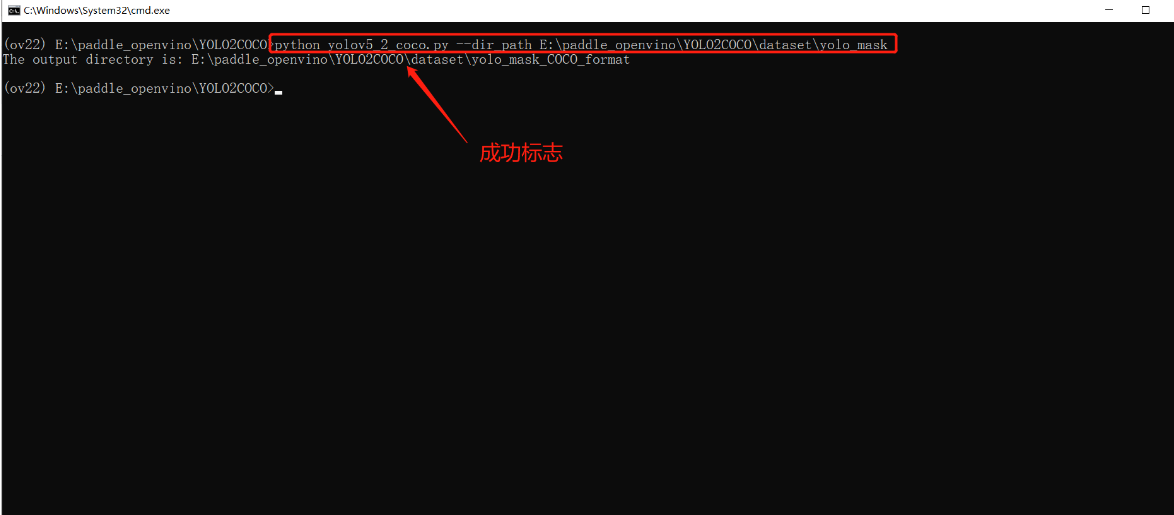
python yolov5_2_coco.py --dir_path E:\paddle_openvino\YOLO2COCO\dataset\yolo_mask
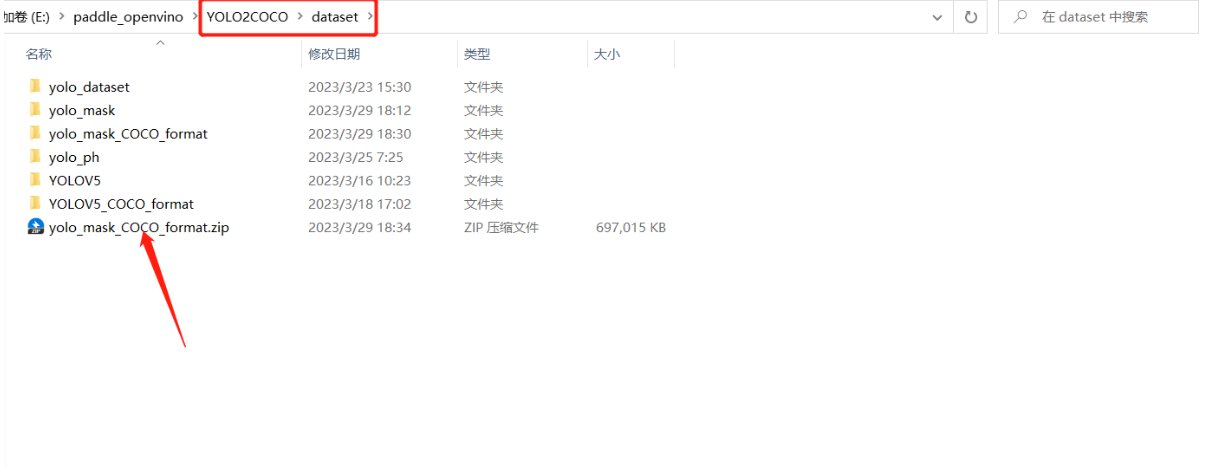
最后打包好数据,准备上传AI Studio吧。
二、模型训练
1.创建数据集
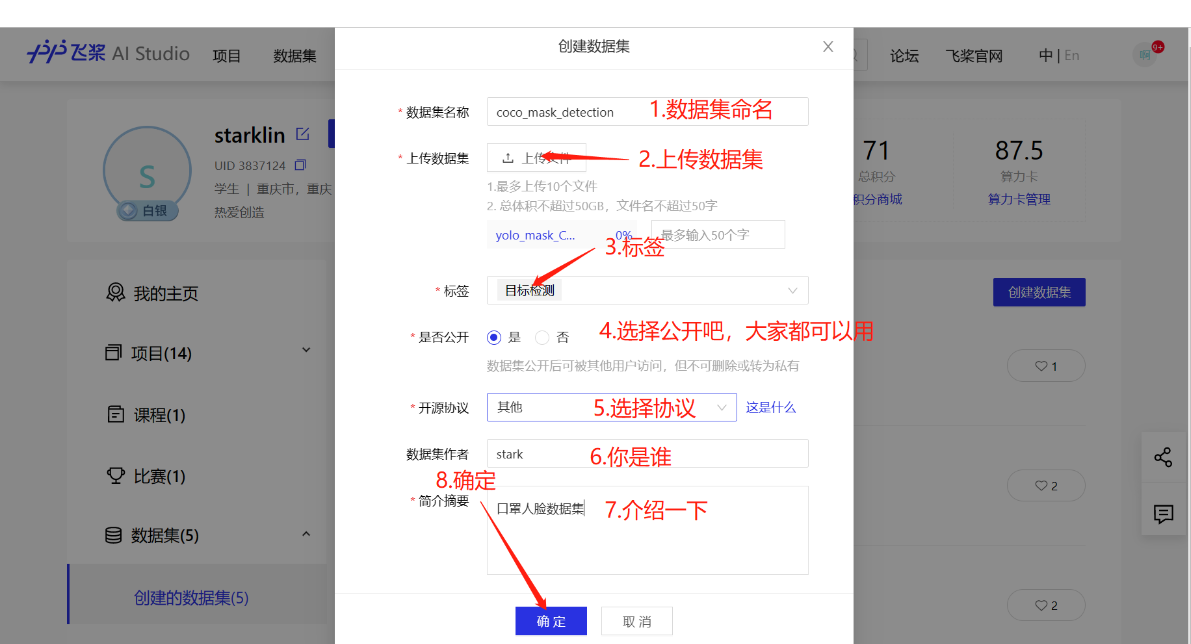
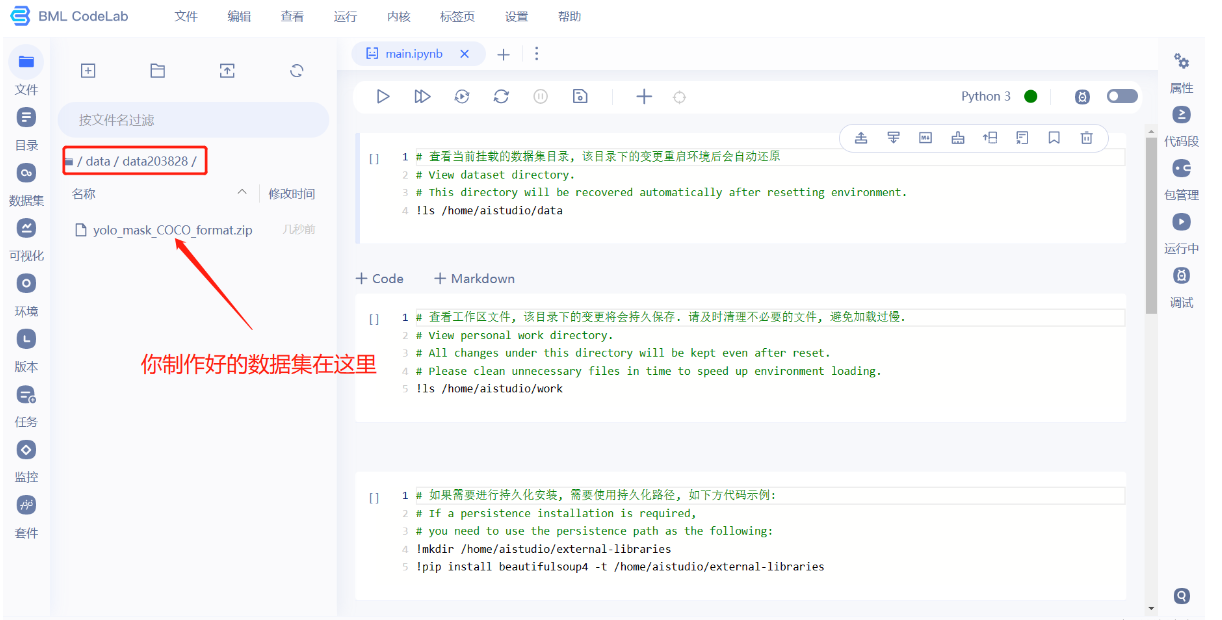
因为数据集过大,启动一个项目,然后直接上传是不行的,所以先创建一个数据集,再在数据集基础上创建项目。
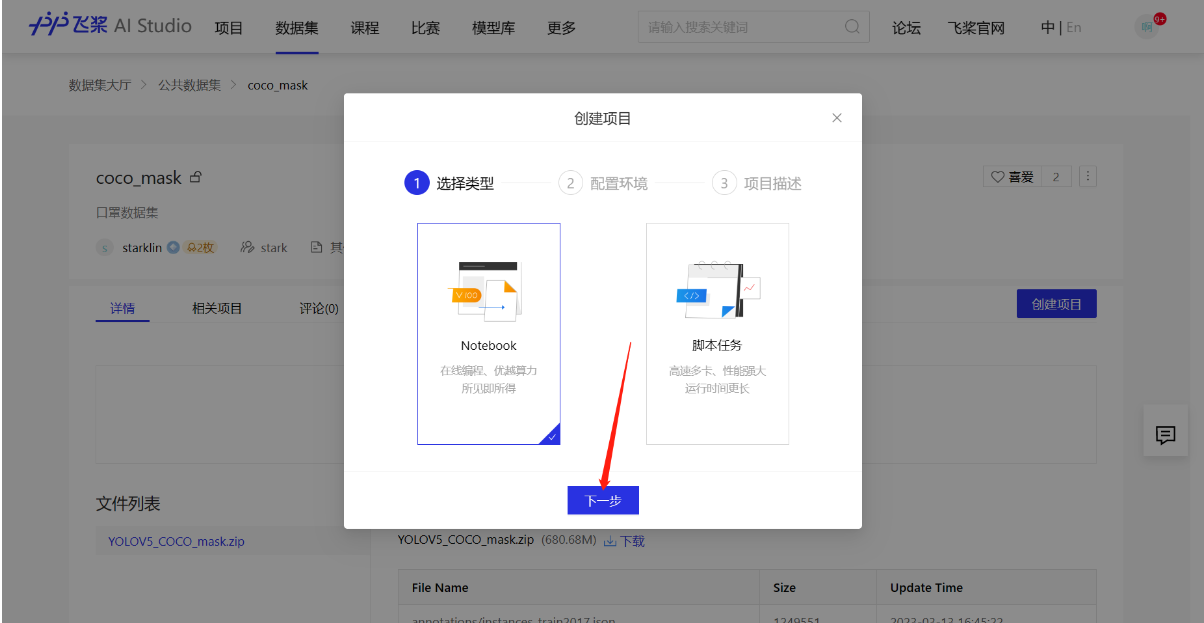
2.创建项目
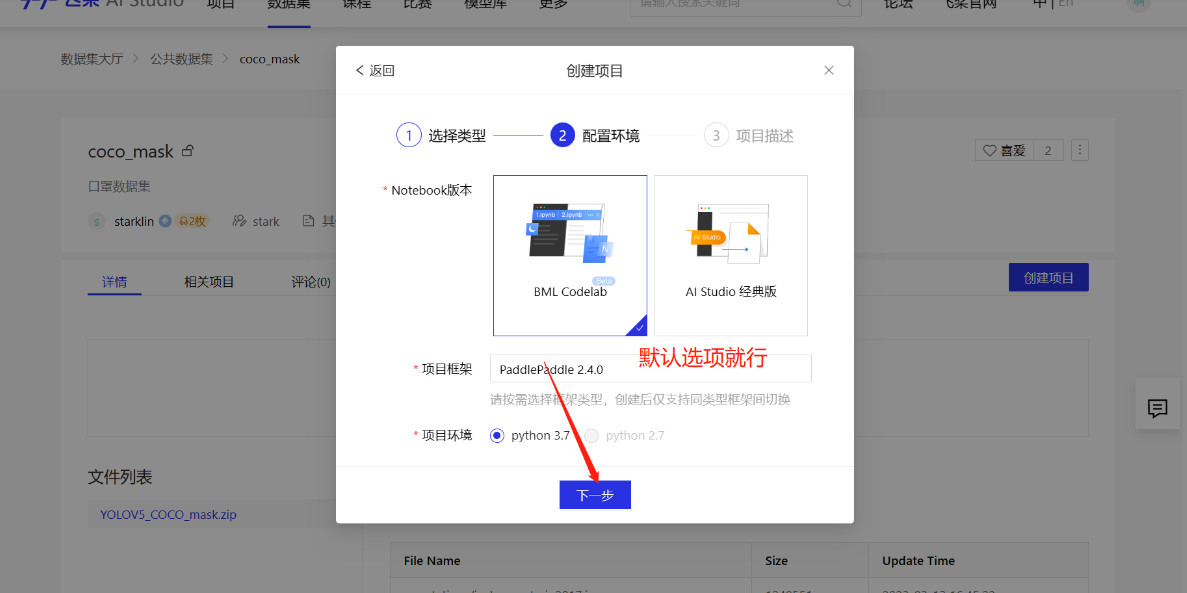
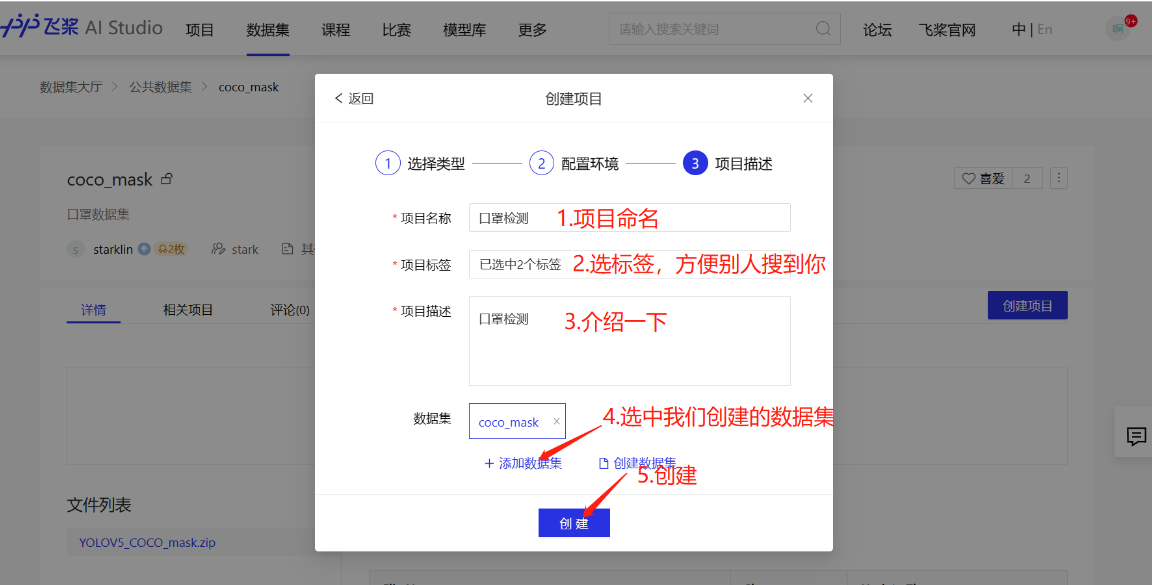
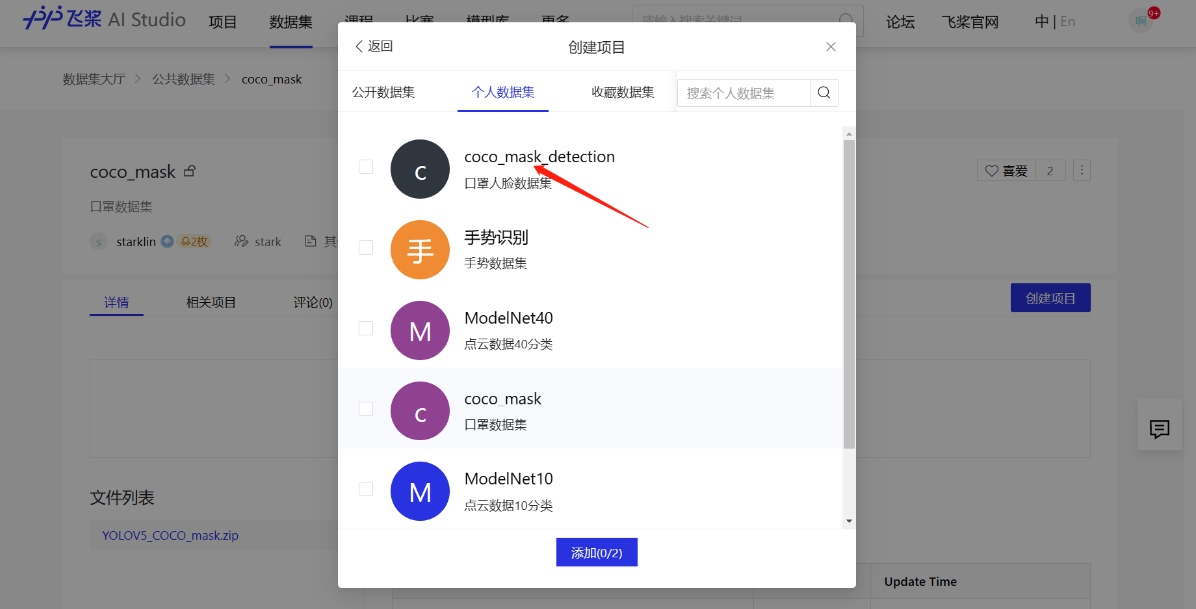
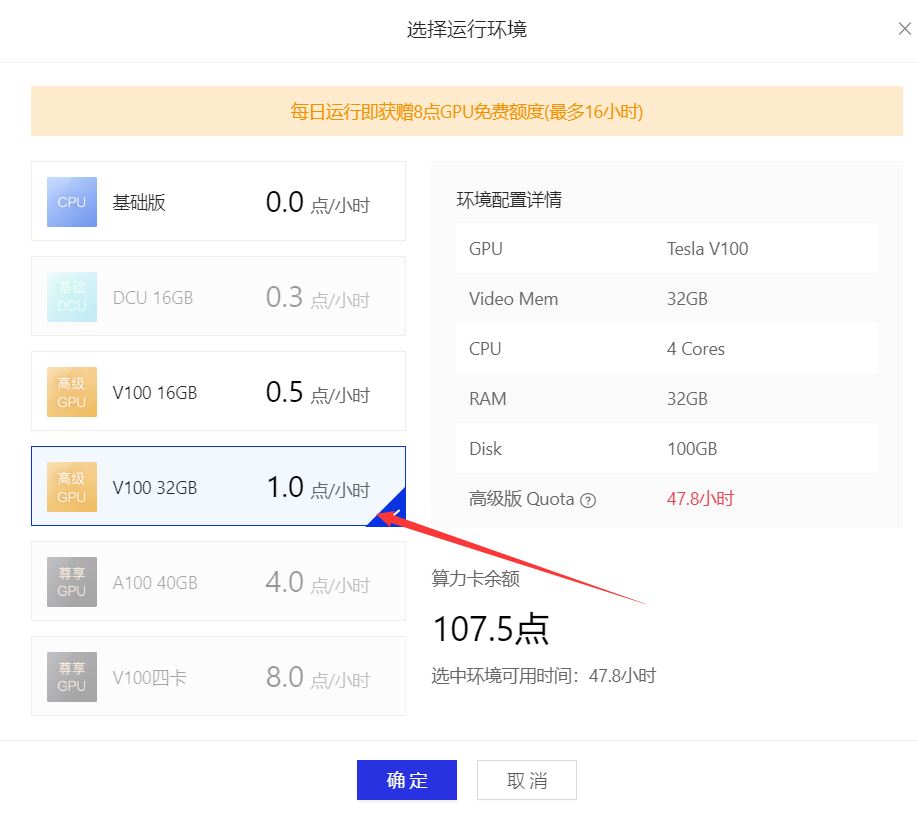
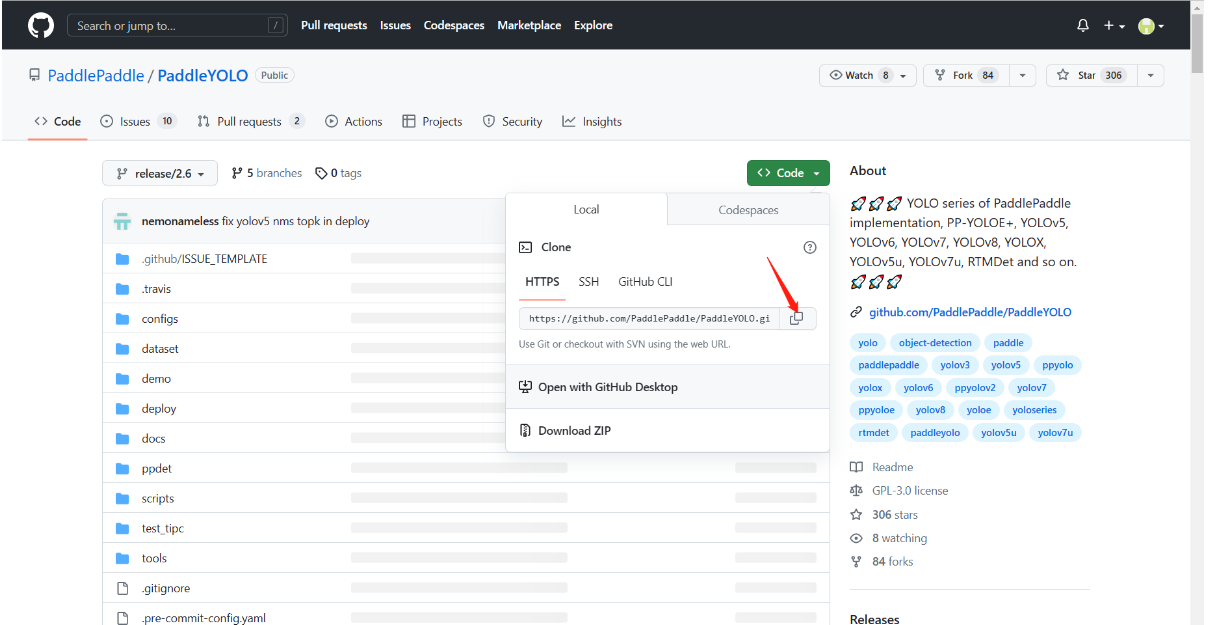
- copy paddleyolo github 链接
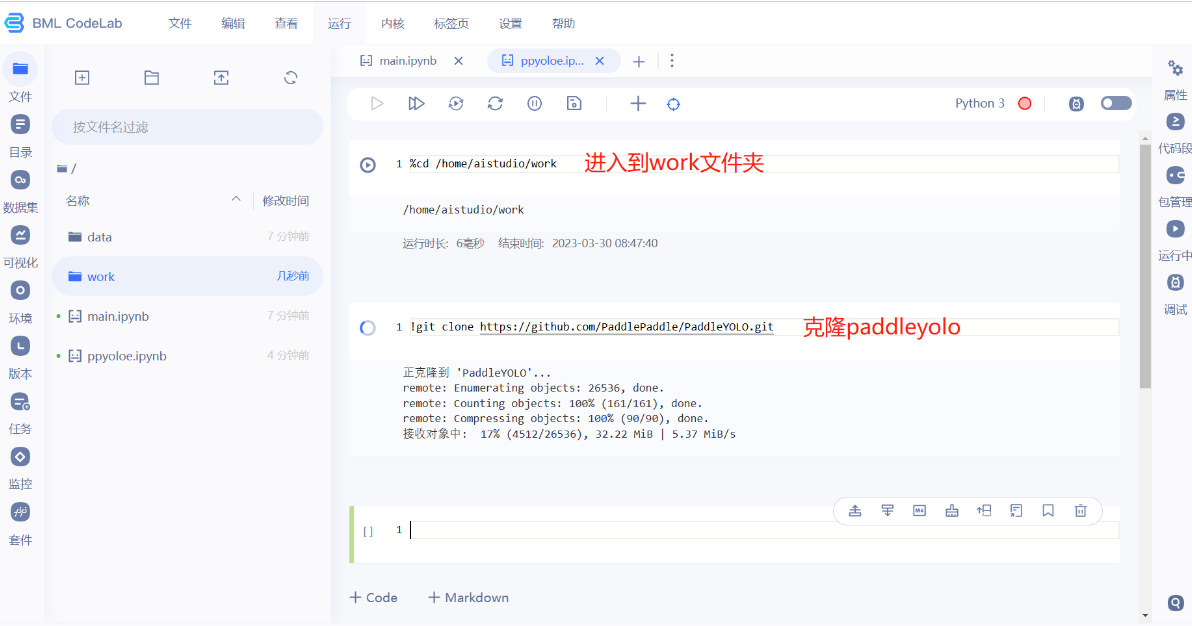
- 注意在ppyoloe.ipynb文件里面写的代码或者markdown都要ctrl+s保存一下,养成一个优良的习惯。
3.模型配置
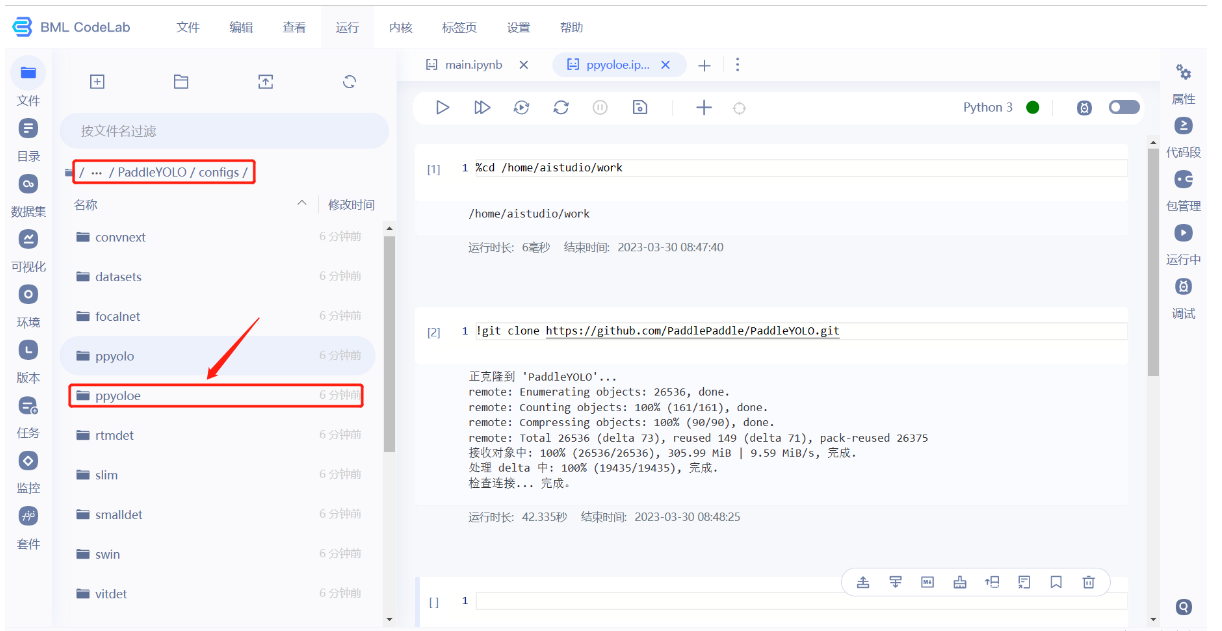
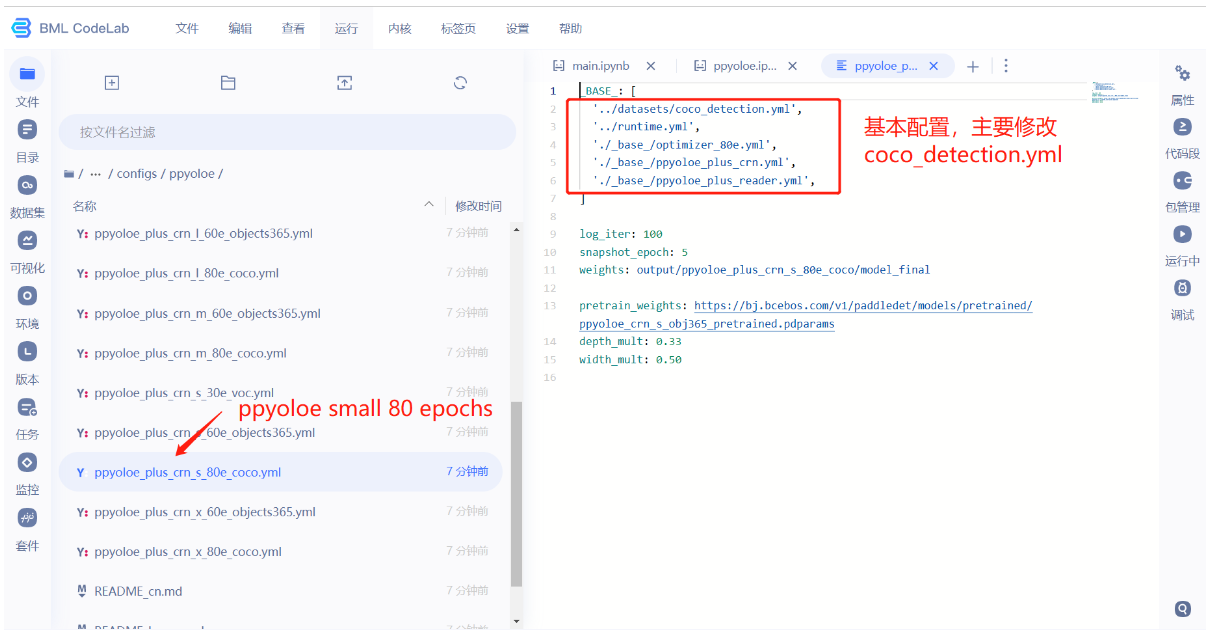
- 在configs下面有很多模型,文件夹名就是模型名字,除了可以使用ppyoloe,还有yolov5,yolov8等。
- 选择一个模型文件夹,修改文件夹里面的配置文件,我们选择的是small版本的ppyoloe,需要训练80 epochs。
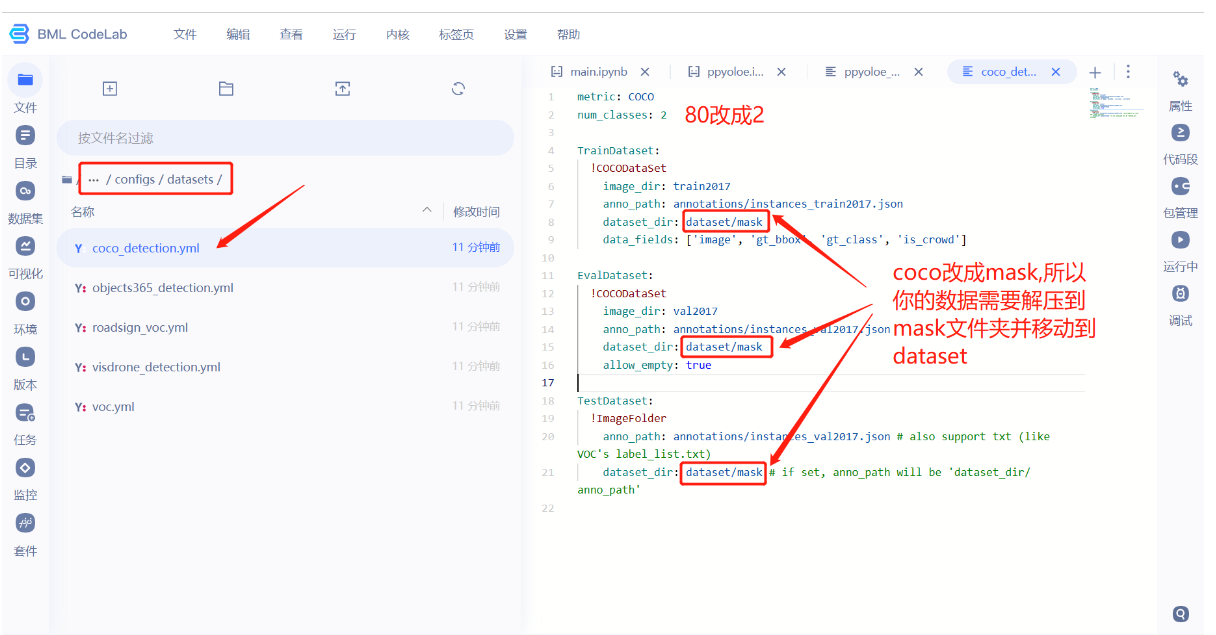
- 我们需要把num_classes修改成2,因为我们的数据集只有两个标签,分别是nomask,mask。改完记得ctrl+s保存。
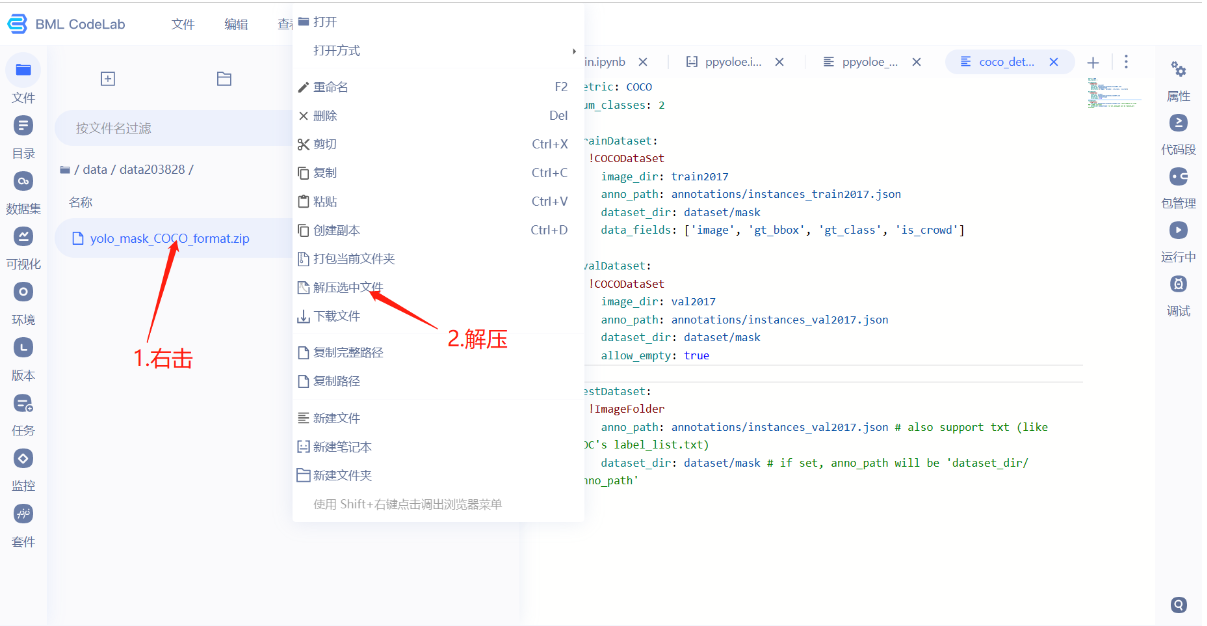
因为配置文件中要求数据放到dataset/mask里面,所以需要把数据集放置到此处。
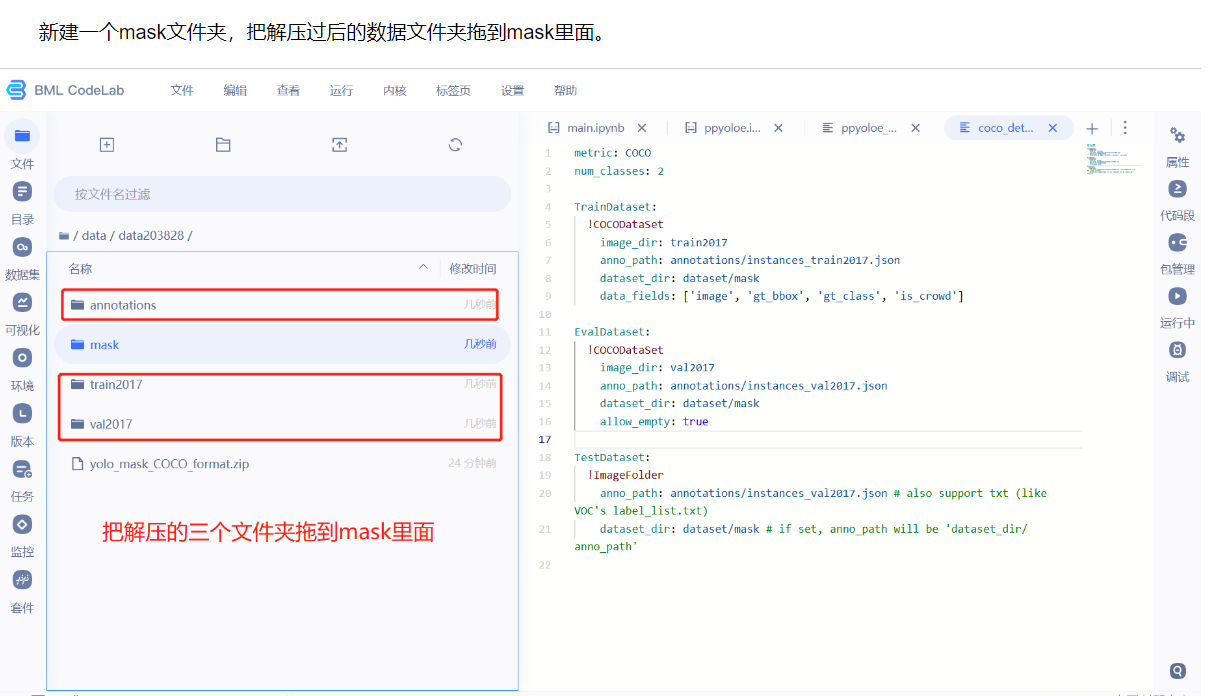
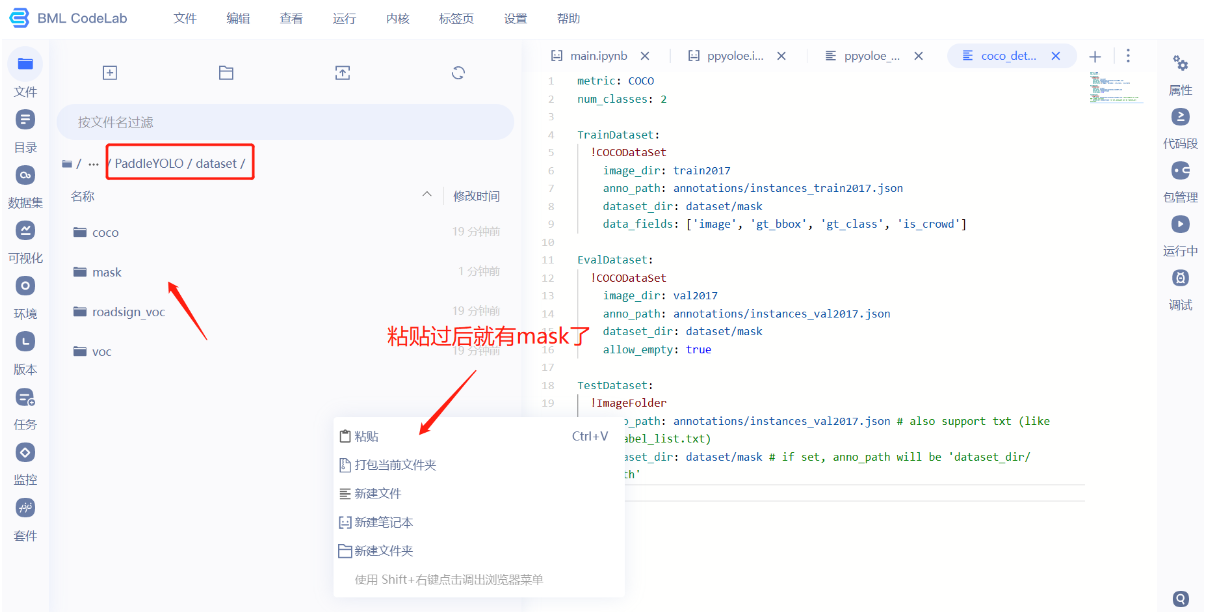
- 新建一个mask文件夹,把解压过后的数据文件夹拖到mask里面。
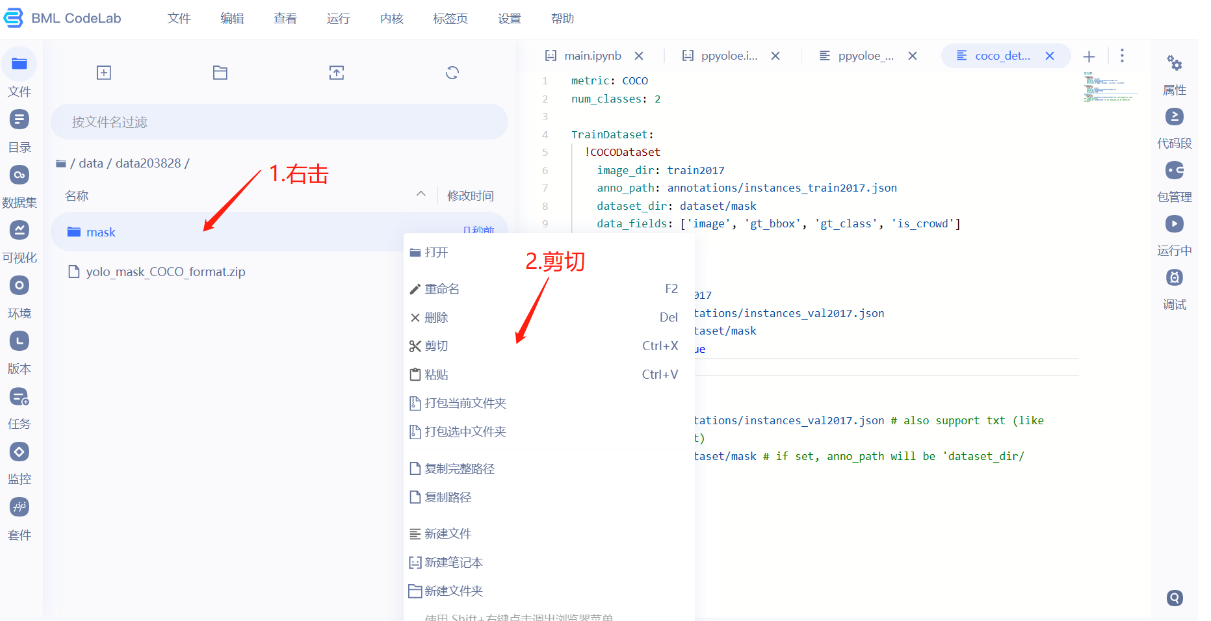
- 为了方便,直接剪切。
- 粘贴到dataset文件夹下,注意红色框的路径。
4.模型训练
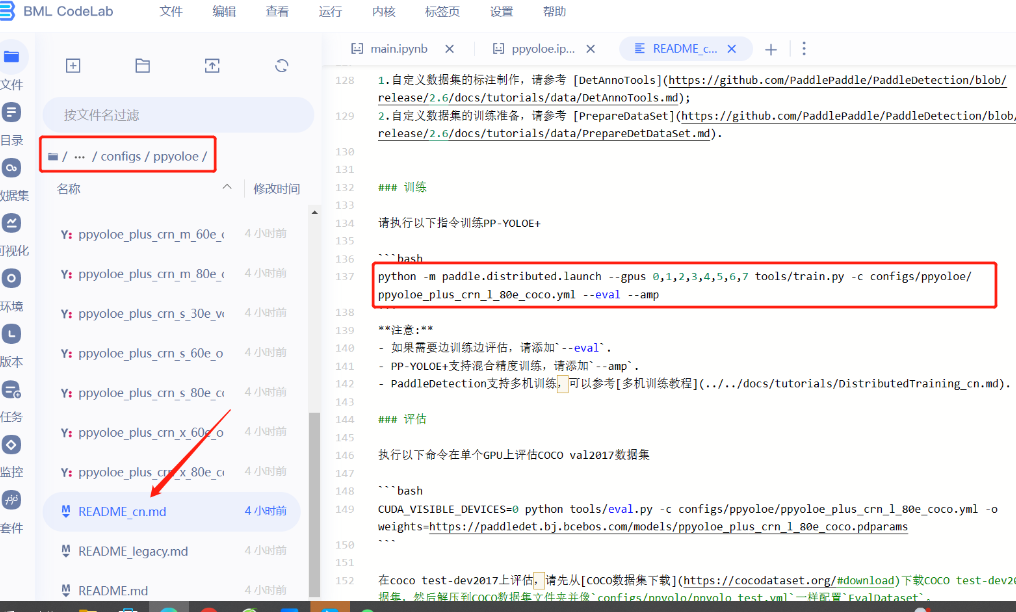
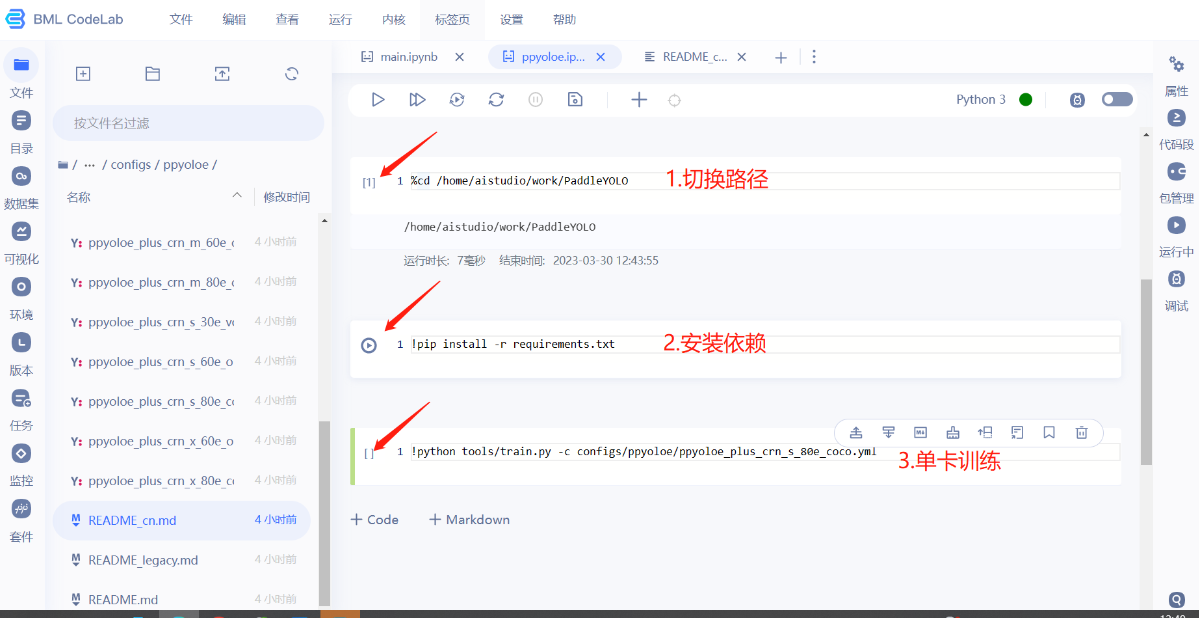
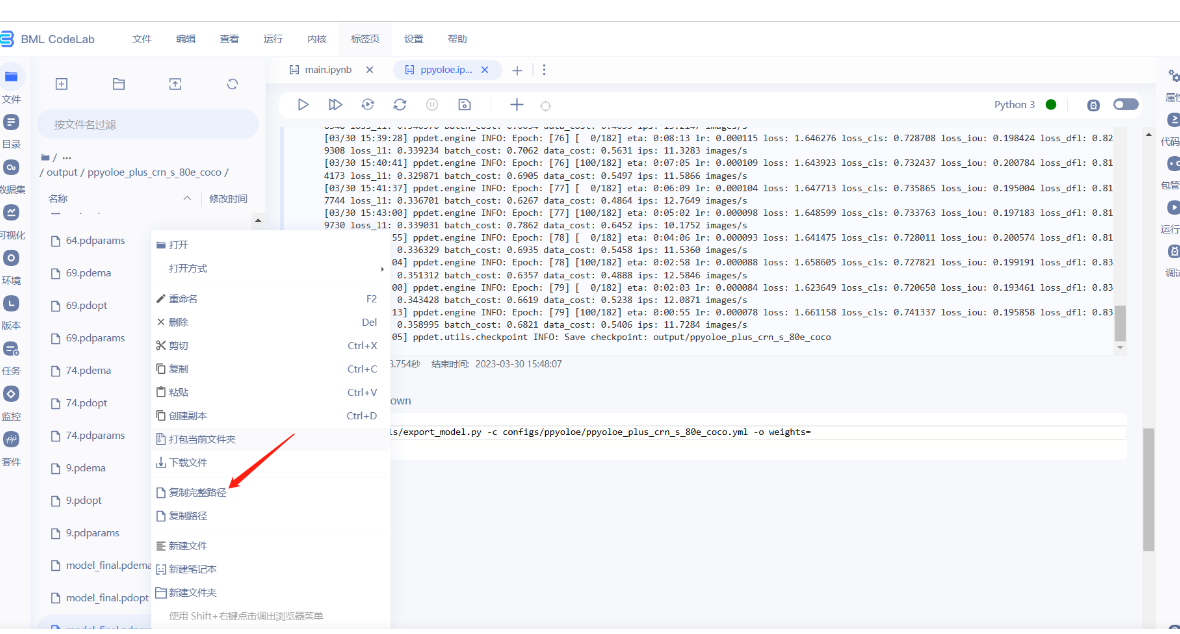
- 在ppyoloe模型文件夹里面有个readme_cn.md,里面有训练模型的命令。将改命令复制到ppyoloe.ipynb文件里面执行。
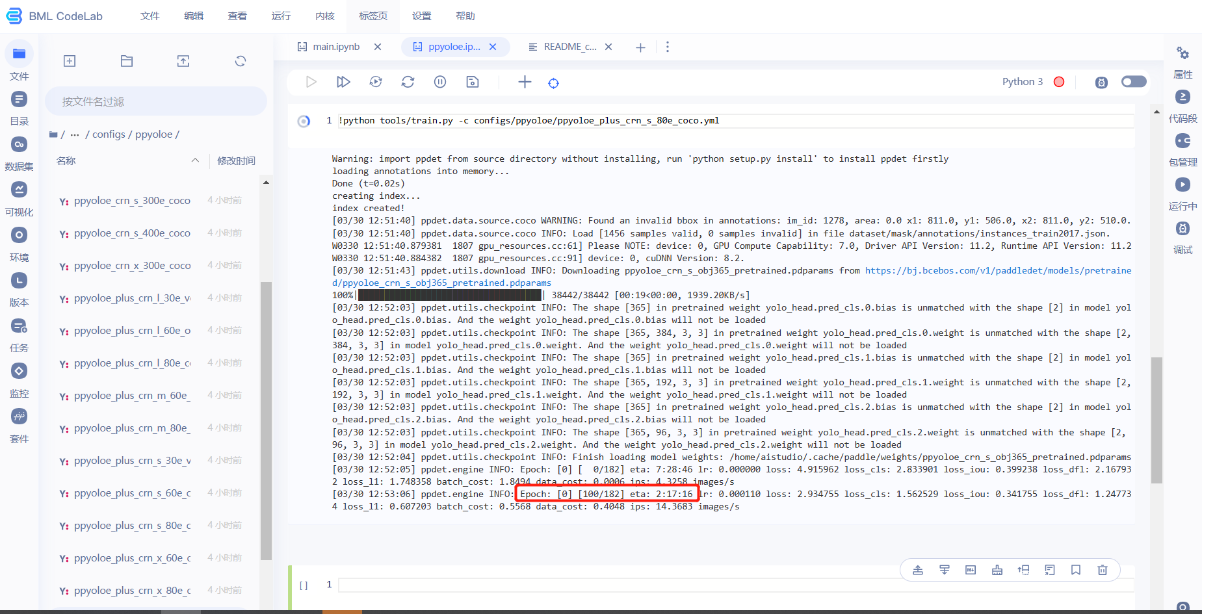
- 模型训练标志,此时是0 epoch,eta时间估计大概要2个小时17分16秒训练完成。时间会变,但是大概就两个小时左右,所以可以开个黑回来刚好合适。
- 找到自己的模型放置位置,在生成的output文件夹下。如下图操作可以获取模型model_final.pdparams的绝对路径,然后粘贴至weights=后面,导出模型。
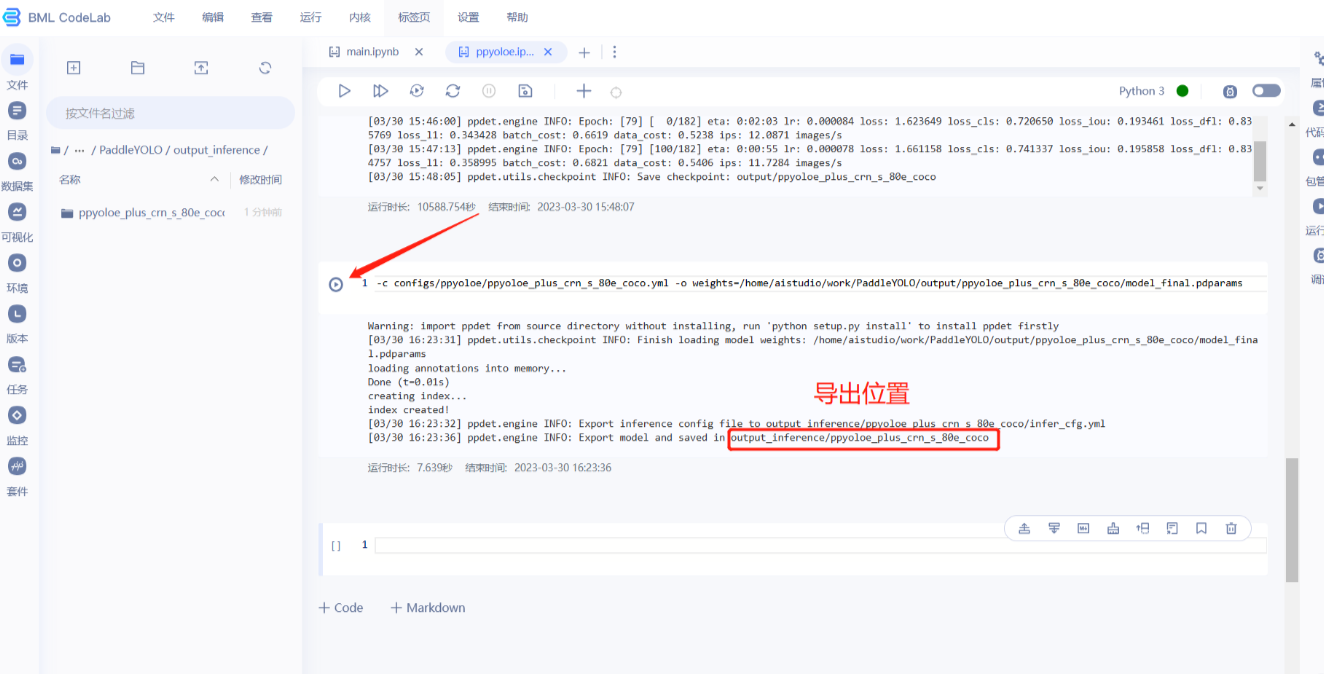
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml -o weights=模型参数绝对路径
导出模型会放置output_inference文件夹下。
三、模型转换
1.可视化模型
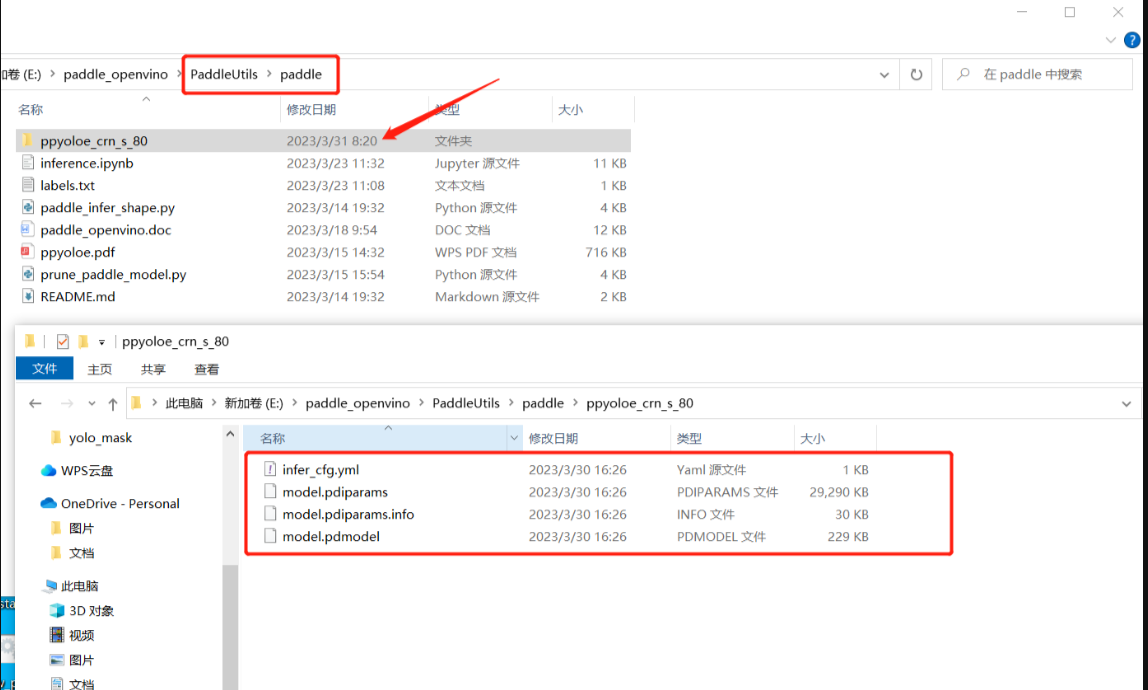
把上节课下载的四个文件打包进ppyoloe_crn_s_80里面。虽然文件夹名字有点长,但是通过名字就大概知道是什么版本的模型,训练了多久,何乐而不为?
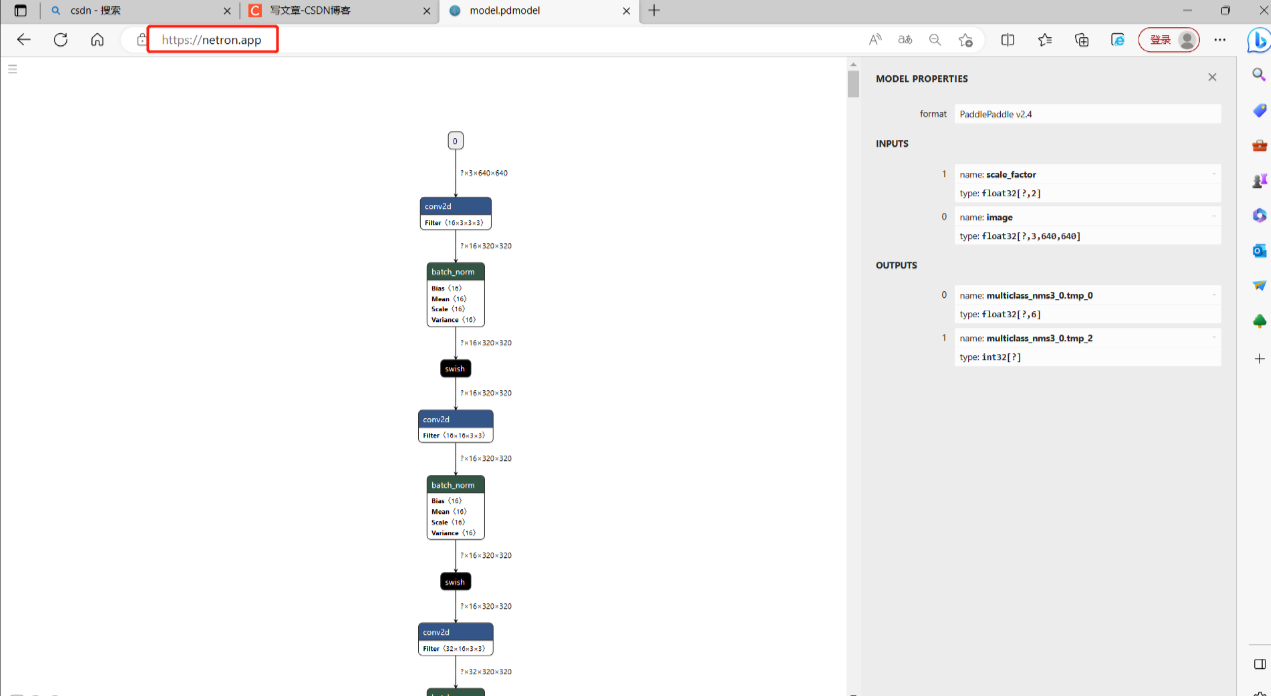
进入模型可视化网站,选择我们上一课程训练好的模型。
可以看到模型输入是3x640x640,3是图像的通道,也就是说我们传入的图像是有色图。
定位到模型的输出,在可视化图像的最下方,我们要找到需要模型减支的地方。

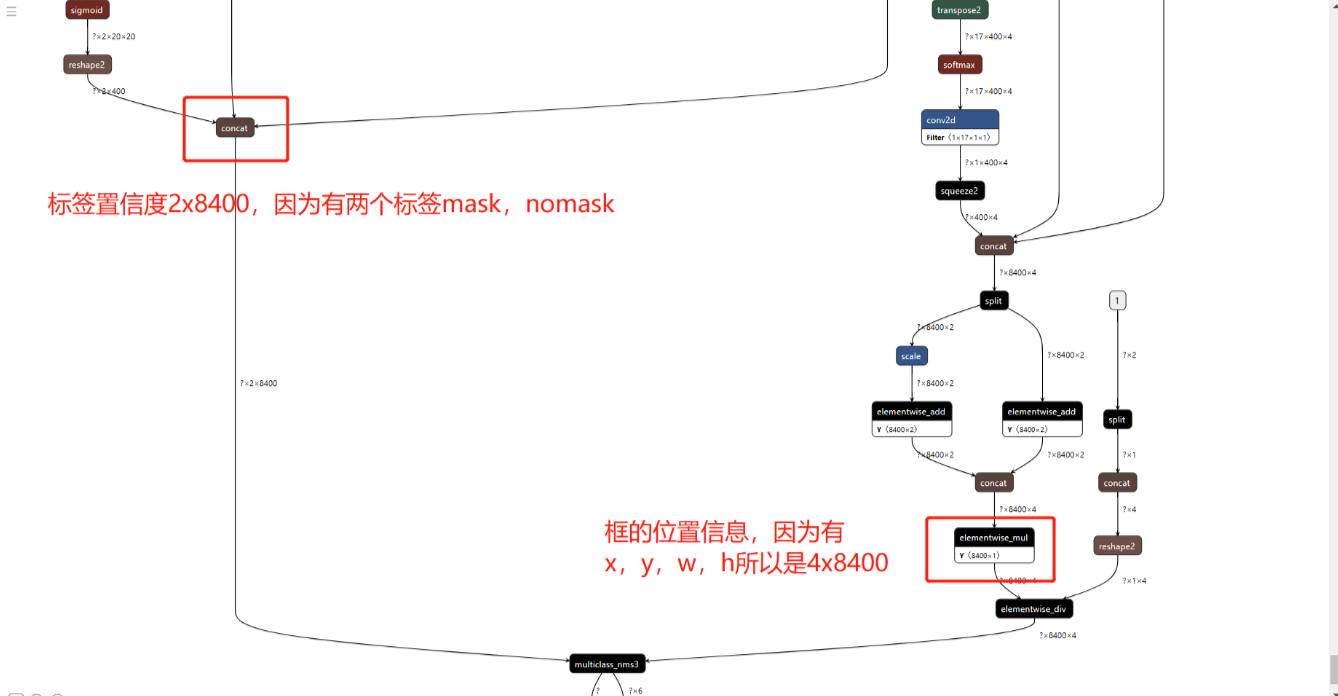

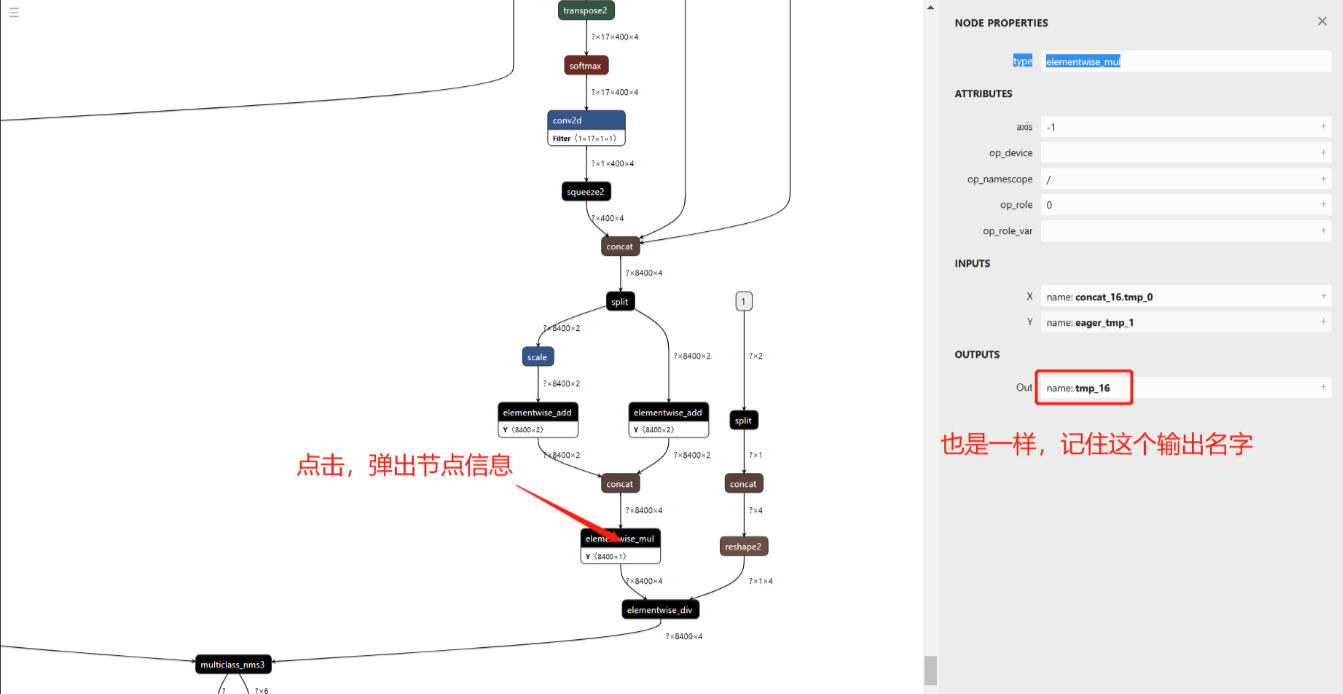
2.模型减支
模型减支的目的就是从输入到两个输出concat_14.tmp_0,tmp_16为止,后面的节点都删掉。在模型减支工具的paddle目录下打开cmd。
激活满足本项目要求的虚拟环境。
activate 虚拟环境名
我们将运行这个模型减支py文件。
运行以下命令。
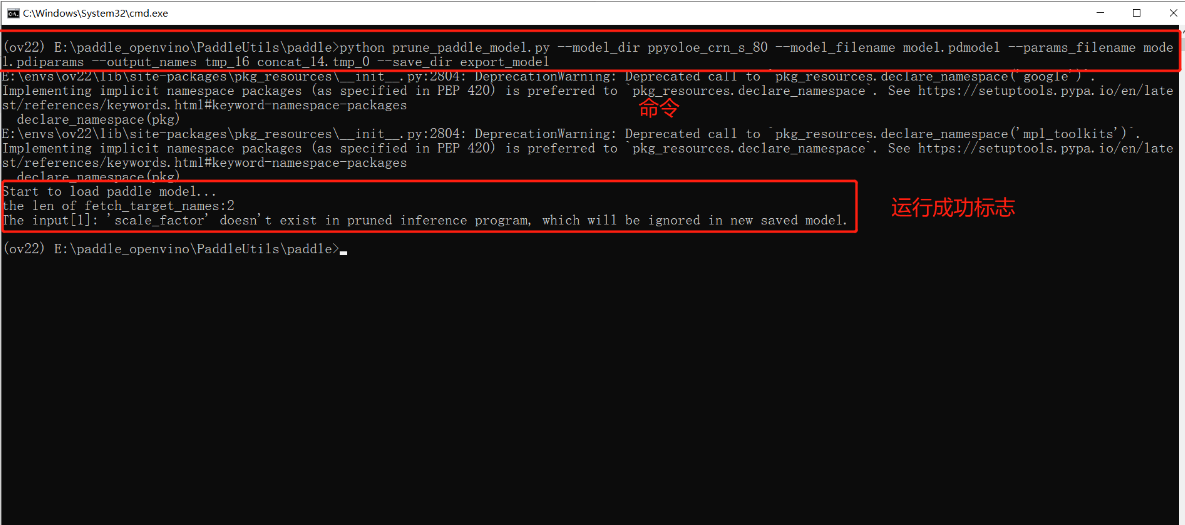
python prune_paddle_model.py --model_dir ppyoloe_crn_s_80 --model_filename model.pdmodel --params_filename model.pdiparams --output_names tmp_16 concat_14.tmp_0 --save_dir export_model
运行过后新增一个减支完成的模型文件夹。
3.模型转化
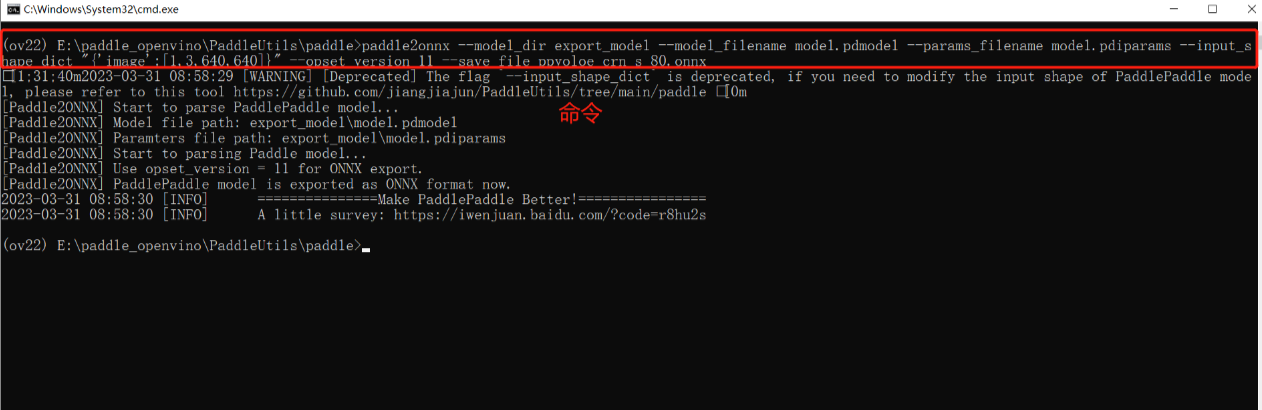
先把paddle模型转换为onnx,需要在环境里面提前安装paddle2onnx。执行以下命令。
paddle2onnx --model_dir export_model --model_filename model.pdmodel --params_filename model.pdiparams --input_shape_dict "{'image':[1,3,640,640]}" --opset_version 11 --save_file ppyoloe_crn_s_80.onnx
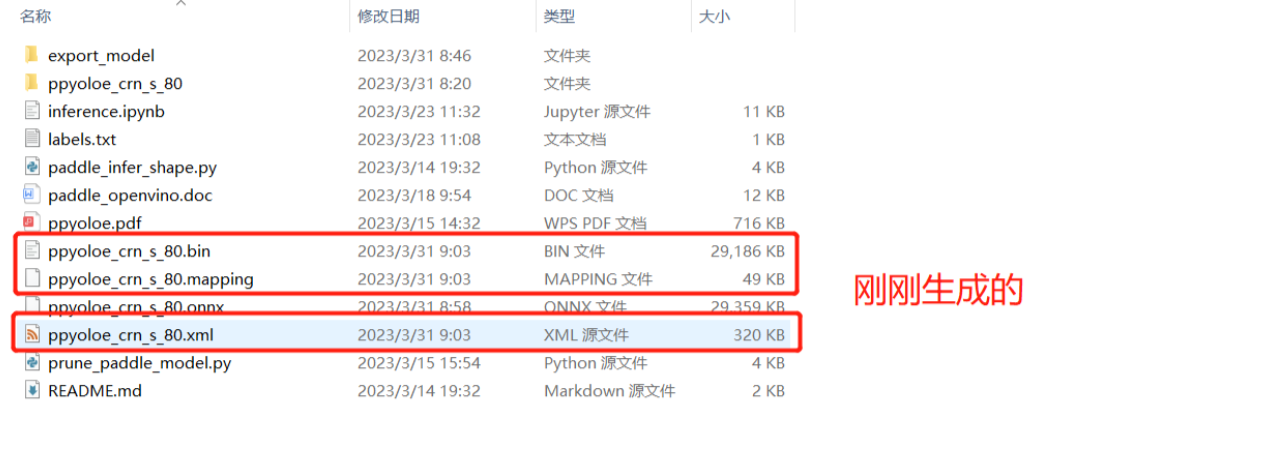
执行生成的ppyoloe_crn_s_80.onnx。
onnx转xml,bin(OpenVINO)。
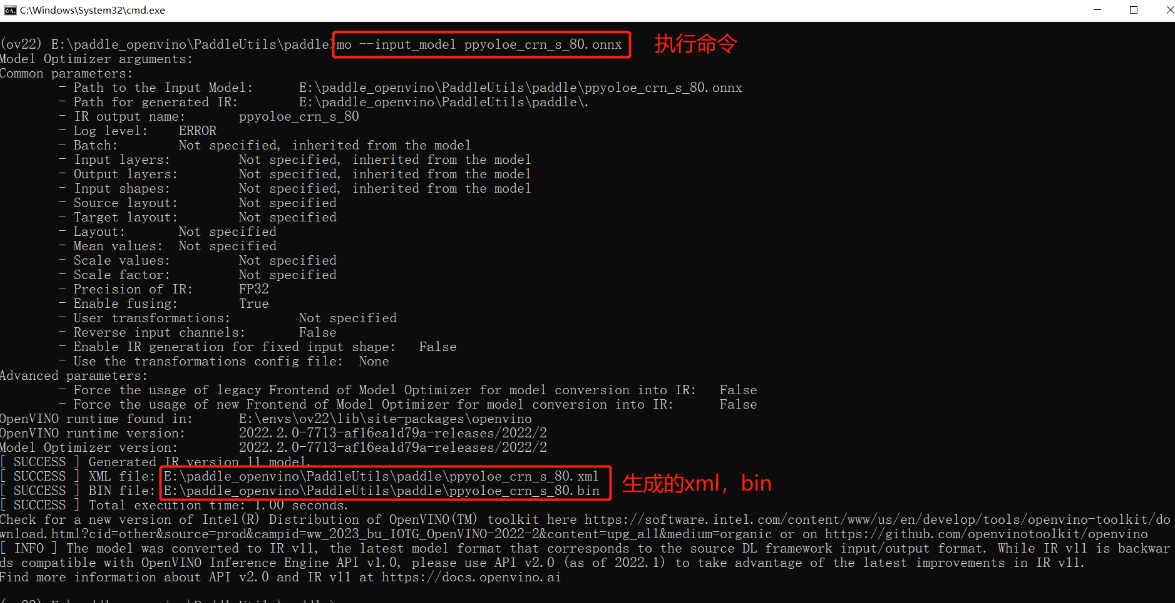
mo --input_model ppyoloe_crn_s_80.onnx
执行结果。
四、模型推理
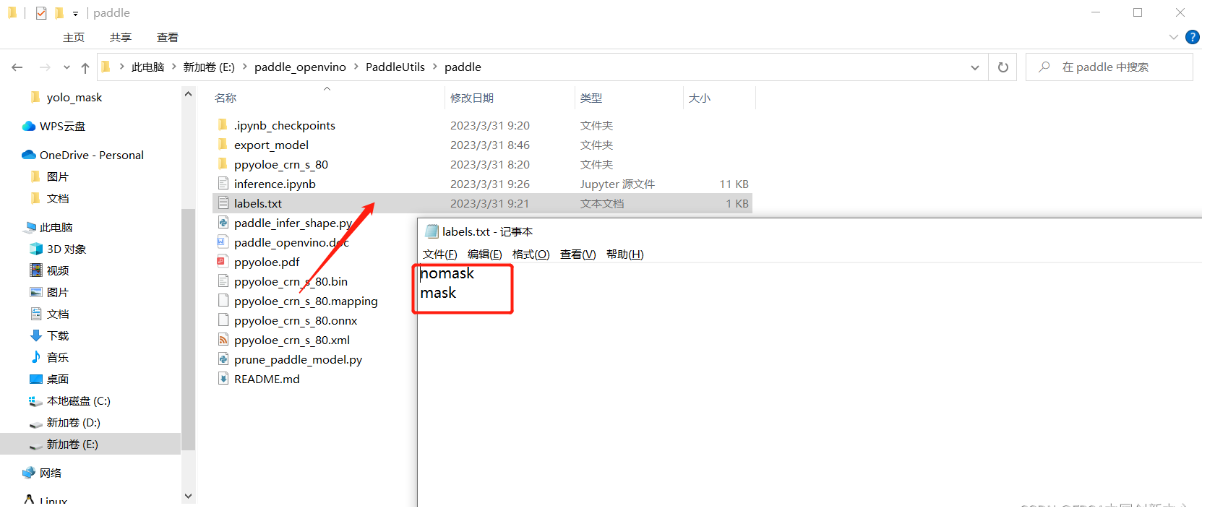
增加一个文件labels.txt,内容是我们的标签,注意放置位置。
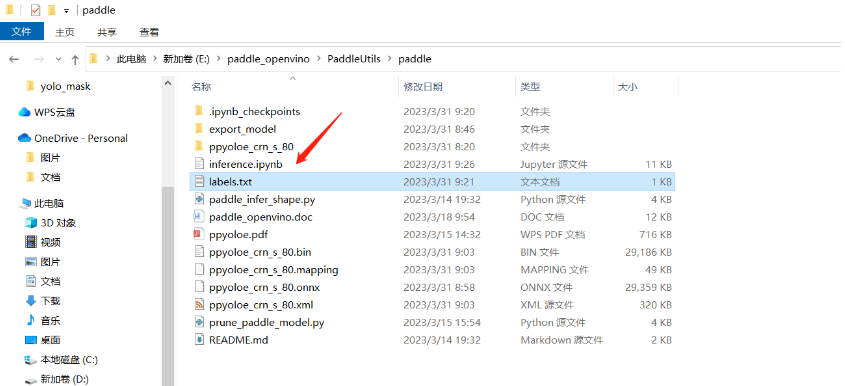
增加一个inference.ipynb用于编写推理代码,注意放置位置。
推理代码:
from openvino.runtime import Core
import openvino.runtime as ov
import cv2 as cv
import numpy as np
import tensorflow as tf
OpenVINO 模型推理器(class)
class Predictor:
"""
OpenVINO 模型推理器
"""
def __init__(self, model_path):
ie_core = Core()
model = ie_core.read_model(model=model_path)
self.compiled_model = ie_core.compile_model(model=model, device_name="CPU")
def get_inputs_name(self, num):
return self.compiled_model.input(num)
def get_outputs_name(self, num):
return self.compiled_model.output(num)
def predict(self, input_data):
return self.compiled_model([input_data])
def get_request(self):
return self.compiled_model.create_infer_request()
图像预处理
def process_image(input_image, size):
"""输入图片与处理方法,按照PP-Yoloe模型要求预处理图片数据
Args:
input_image (uint8): 输入图片矩阵
size (int): 模型输入大小
Returns:
float32: 返回处理后的图片矩阵数据
"""
max_len = max(input_image.shape)
img = np.zeros([max_len,max_len,3],np.uint8)
img[0:input_image.shape[0],0:input_image.shape[1]] = input_image # 将图片放到正方形背景中
img = cv.cvtColor(img,cv.COLOR_BGR2RGB) # BGR转RGB
img = cv.resize(img, (size, size), cv.INTER_NEAREST) # 缩放图片
img = np.transpose(img,[2, 0, 1]) # 转换格式
img = img / 255.0 # 归一化
img = np.expand_dims(img,0) # 增加维度
return img.astype(np.float32)
图像后处理
def process_result(box_results, conf_results):
"""按照PP-Yolove模型输出要求,处理数据,非极大值抑制,提取预测结果
Args:
box_results (float32): 预测框预测结果
conf_results (float32): 置信度预测结果
Returns:
float: 预测框
float: 分数
int: 类别
"""
conf_results = np.transpose(conf_results,[0, 2, 1]) # 转置
# 设置输出形状
box_results =box_results.reshape(8400,4)
conf_results = conf_results.reshape(8400,2)
scores = []
classes = []
boxes = []
for i in range(8400):
conf = conf_results[i,:] # 预测分数
score = np.max(conf) # 获取类别
# 筛选较小的预测类别
if score > 0.5:
classes.append(np.argmax(conf))
scores.append(score)
boxes.append(box_results[i,:])
scores = np.array(scores)
boxes = np.array(boxes)
result_box = []
result_score = []
result_class = []
# 非极大值抑制筛选重复的预测结果
if len(boxes) != 0:
# 非极大值抑制结果
indexs = tf.image.non_max_suppression(boxes,scores,len(scores),0.25,0.35)
for i, index in enumerate(indexs):
result_score.append(scores[index])
result_box.append(boxes[index,:])
result_class.append(classes[index])
# 返回结果
return np.array(result_box),np.array(result_score),np.array(result_class)
画出预测框
def draw_box(image, boxes, scores, classes, labels):
"""将预测结果绘制到图像上
Args:
image (uint8): 原图片
boxes (float32): 预测框
scores (float32): 分数
classes (int): 类别
lables (str): 标签
Returns:
uint8: 标注好的图片
"""
colors = [(0, 0, 255), (0, 255, 0)]
scale = max(image.shape) / 640.0 # 缩放比例
if len(classes) != 0:
for i in range(len(classes)):
box = boxes[i,:]
x1 = int(box[0] * scale)
y1 = int(box[1] * scale)
x2 = int(box[2] * scale)
y2 = int(box[3] * scale)
label = labels[classes[i]]
score = scores[i]
cv.rectangle(image, (x1, y1), (x2, y2), colors[classes[i]], 2, cv.LINE_8)
cv.putText(image,label+":"+str(score),(x1,y1-10),cv.FONT_HERSHEY_SIMPLEX, 0.55, colors[classes[i]], 2)
return image
读取标签
def read_label(label_path):
with open(label_path, 'r') as f:
labels = f.read().split()
return labels
同步推理
label_path = "labels.txt"
yoloe_model_path = "ppyoloe_crn_s_80.xml"
predictor = Predictor(model_path = yoloe_model_path)
boxes_name = predictor.get_outputs_name(0)
conf_name = predictor.get_outputs_name(1)
labels = read_label(label_path=label_path)
cap = cv.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
frame = cv.flip(frame, 180)
cv.namedWindow("MaskDetection", 0) # 0可调大小,注意:窗口名必须imshow里面的一窗口名一直
cv.resizeWindow("MaskDetection", 640, 480) # 设置长和宽
input_frame = process_image(frame, 640)
results = predictor.predict(input_data=input_frame)
boxes, scores, classes = process_result(box_results=results[boxes_name], conf_results=results[conf_name])
result_frame = draw_box(image=frame, boxes=boxes, scores=scores, classes=classes, labels=labels)
cv.imshow('MaskDetection', result_frame)
key = cv.waitKey(1)
if key == 27: #esc退出
break
cap.release()
cv.destroyAllWindows()
异步推理
label_path = "labels.txt"
yoloe_model_path = "ppyoloe_crn_s_80.xml"
predictor = Predictor(model_path = yoloe_model_path)
input_layer = predictor.get_inputs_name(0)
labels = read_label(label_path=label_path)
cap = cv.VideoCapture(0)
curr_request = predictor.get_request()
next_request = predictor.get_request()
ret, frame = cap.read()
curr_frame = process_image(frame, 640)
curr_request.set_tensor(input_layer, ov.Tensor(curr_frame))
curr_request.start_async()
while cap.isOpened():
ret, next_frame = cap.read()
next_frame = cv.flip(next_frame, 180)
cv.namedWindow("MaskDetection", 0) # 0可调大小,注意:窗口名必须imshow里面的一窗口名一直
cv.resizeWindow("MaskDetection", 640, 480) # 设置长和宽
in_frame = process_image(next_frame, 640)
next_request.set_tensor(input_layer, ov.Tensor(in_frame))
next_request.start_async()
if curr_request.wait_for(-1) == 1:
boxes_name = curr_request.get_output_tensor(0).data
conf_name = curr_request.get_output_tensor(1).data
boxes, scores, classes = process_result(box_results=boxes_name, conf_results=conf_name)
frame = draw_box(image=frame, boxes=boxes, scores=scores, classes=classes, labels=labels)
cv.imshow('MaskDetection', frame)
frame = next_frame
curr_request, next_request = next_request, curr_request
key = cv.waitKey(1)
if key == 27: #esc退出
break
cap.release()
cv.destroyAllWindows()
最后run all执行即可
五、结果演示
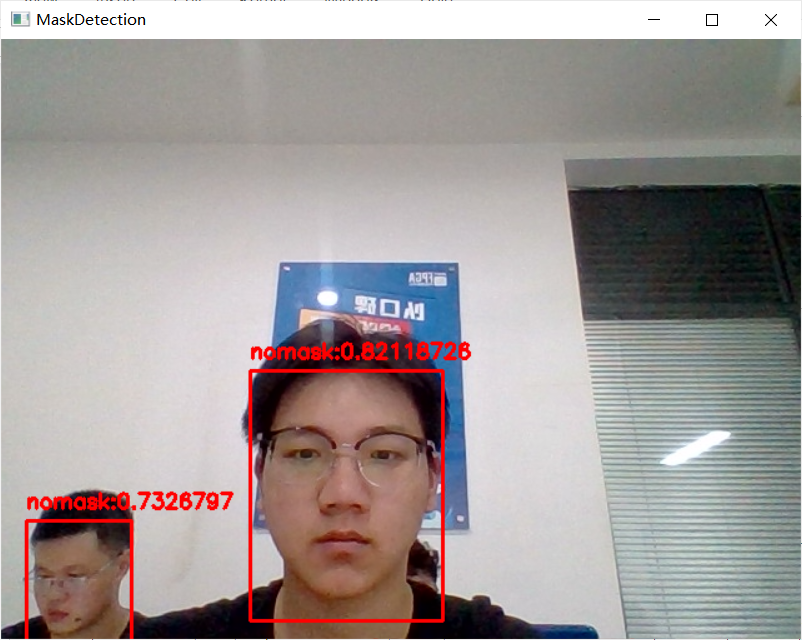
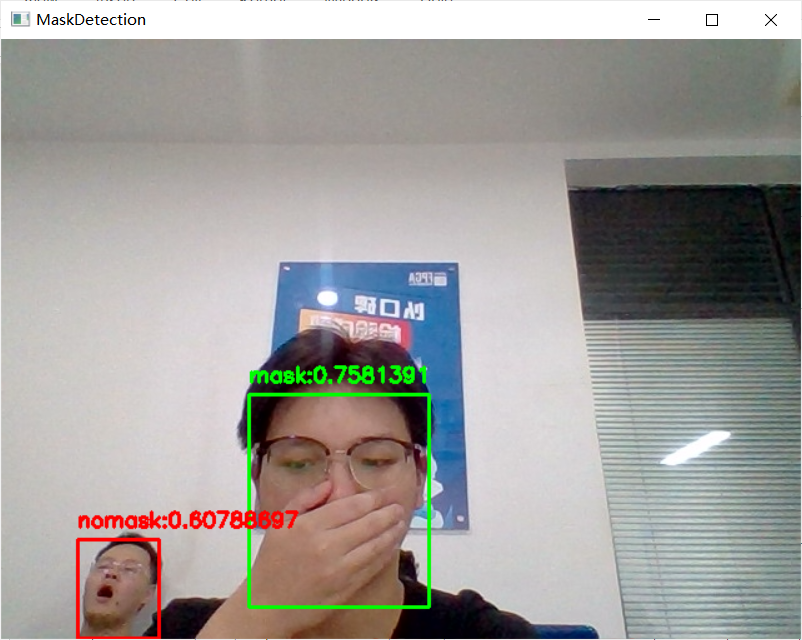
六、拓展项目
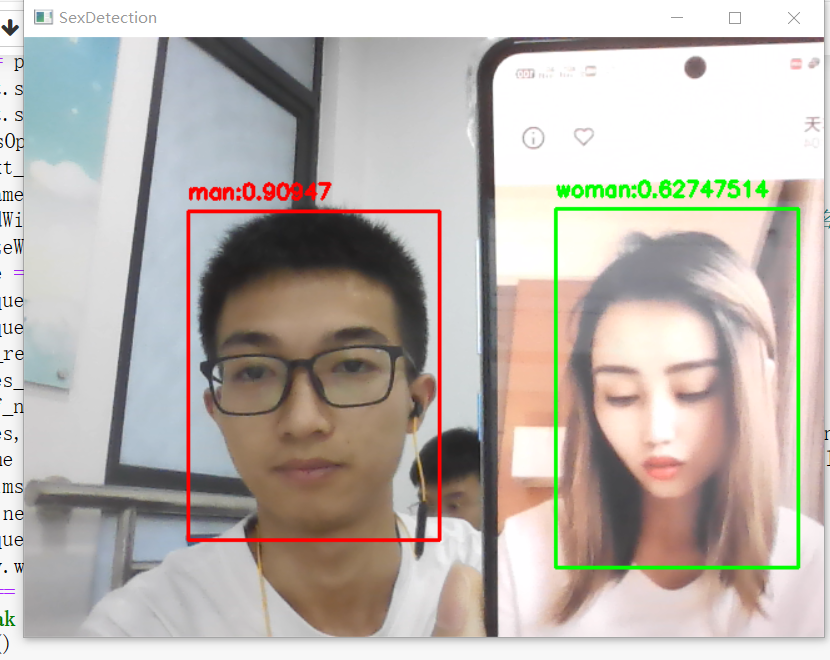
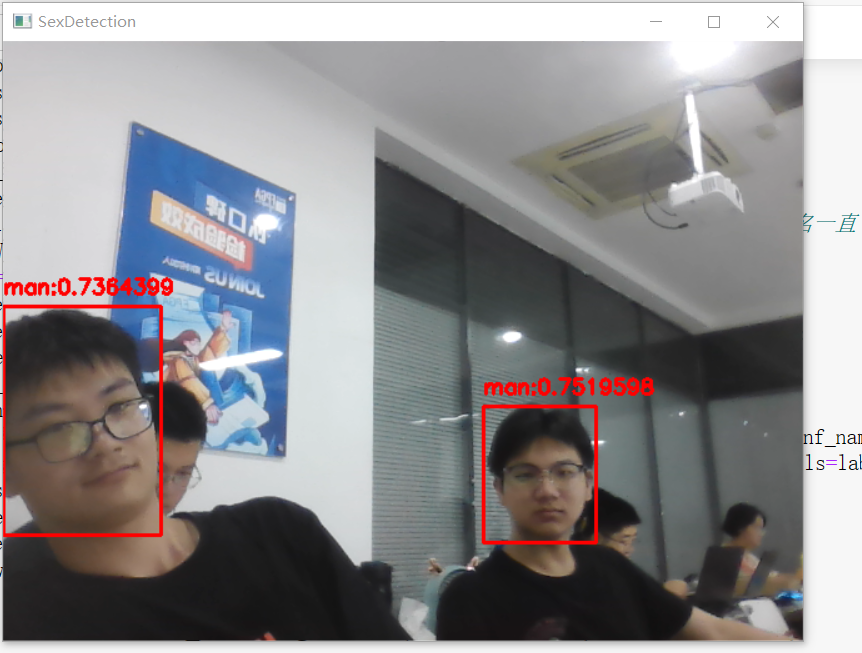
除了完成这次口罩检测任务,我们还做了一些其他的任务:包括检测表情(笑与不笑)、检测性别(男或女)。
结果如下:
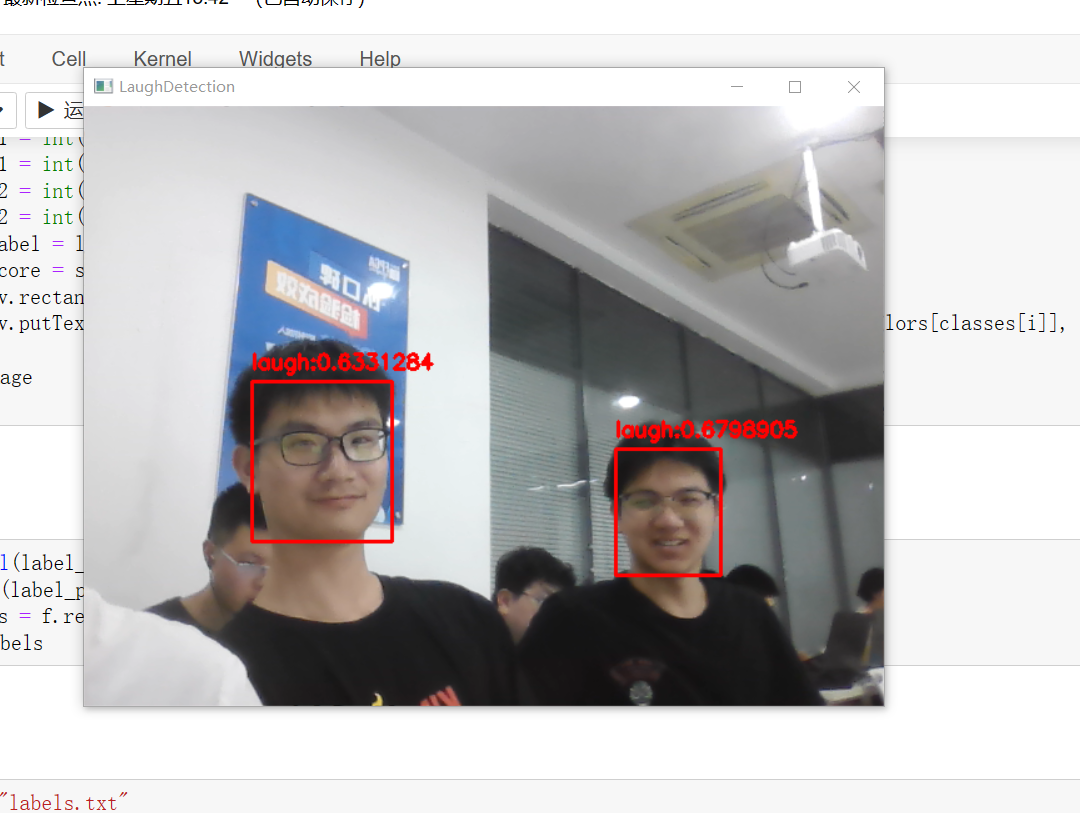
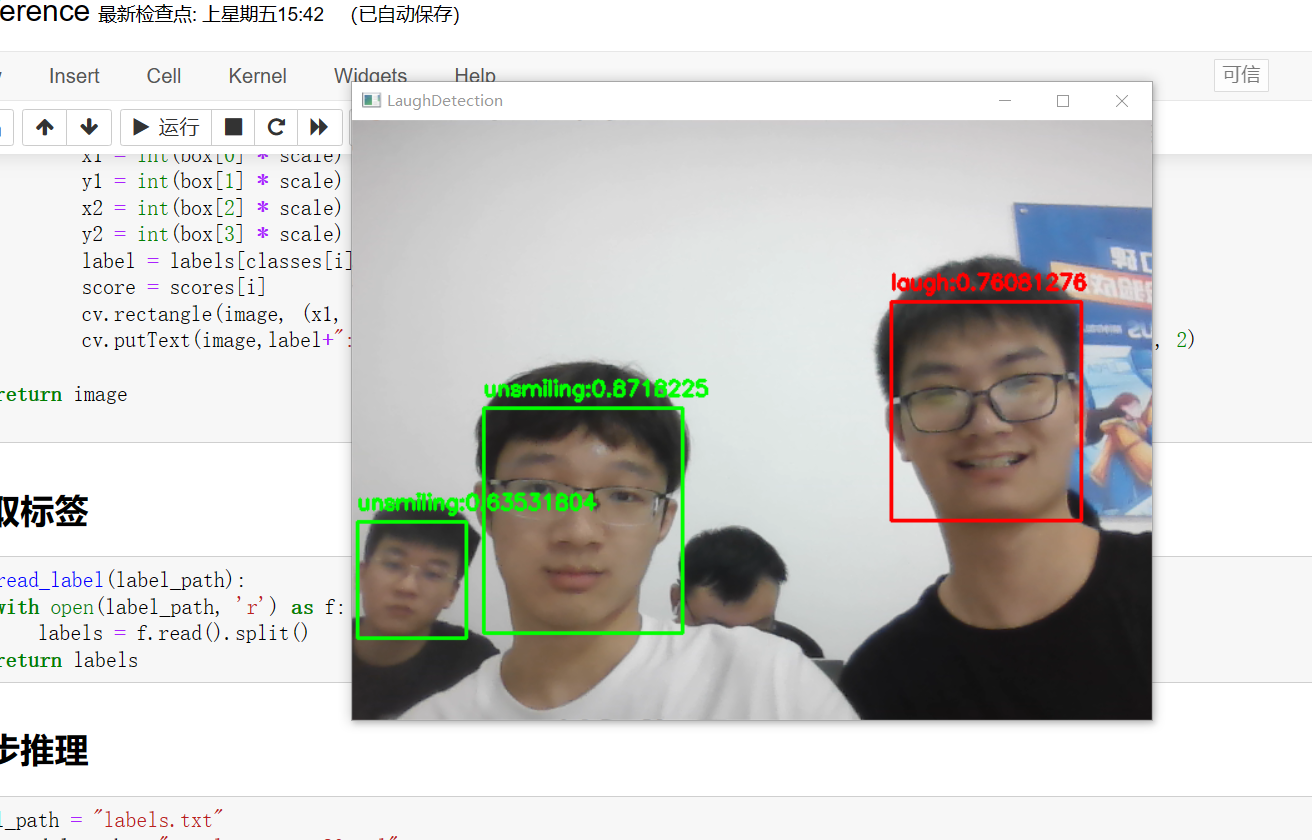
七、参考链接
口罩检测——环境准备(1)
口罩检测——数据准备(2)
口罩检测——模型训练(3)
口罩检测——模型转换(4)
口罩检测——模型推理(5)