PyTorch提供了两个数据基元:torch.utils.data.DataLoader和torch.utils.data.Dataset,允许你使用预先加载的数据集以及你自己的数据。
一、torch.utils.data.Dataset
一个自定义的数据集类**(继承Dataset类)**必须实现三个函数。
__init__, __len__, 和 __getitem__。
__len__():定义了获取数据集长度的行为。我们构建的数据集是一个对象,而数据集不像序列类型(列表、元组、字符串)那样可以直接用len()来获取序列的长度,__len__()的目的就是方便像序列那样直接获取对象的长度。
__getitem__():定义了在使用索引访问数据集时的行为。它接收一个索引值 index 作为输入。此外,我们可以__getitem__()中实现数据预处理。
如下例实现:FashionMNIST图像被存储在一个目录img_dir中,它们的标签被分别存储在一个CSV文件annotations_file中。
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
read_image函数使用方法,返回值是tensor,所以上述代码中image无需再使用transforms.ToTensor类进行转化
torchvision.io.read_image(path: str, mode: ImageReadMode = ImageReadMode.UNCHANGED) → Tensor
path (str) – path of the JPEG or PNG image.
下面是一个如何从TorchVision加载Fashion-MNIST数据集的例子。Fashion-MNIST是一个由60,000个训练实例和10,000个测试实例组成的Zalando的文章图像数据集。每个例子包括一个28×28的灰度图像和10个类别中的一个相关标签。
·root是存储训练/测试数据的路径。
·train用于指定在数据集下载完成后需要载入哪部分数据,设置为 True,则说明载入的是该数据集的训练集部分;
如果设置为 False,则说明载入的是该数据集的测试集部分。
·downloadTrue如果根目录下没有数据,则从网上下载。
·transform用于指定导入数据集时需要对数据进行哪种变换操作。
·target_transform指定标签的转换。
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="./data",#指存放在项目根目录下的 data 文件夹
train=True,
download=True,
transform=ToTensor()
)
#如果觉得Pycharm中下载速度太慢,可以按住ctrl后点击FashionMNIST查看源码找到其中的url属性,
#复制进浏览器直接下载,下载完成转移到该项目下正确位置
二、torch.utils.data.DataLoader
作用:DataLoader将Dataset对象或自定义数据类的对象封装成一个迭代器;这个迭代器可以迭代输出Dataset的内容。
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None,
num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None,
multiprocessing_context=None, generator=None, *, prefetch_factor=2,
persistent_workers=False, pin_memory_device='')
DataLoader类中__init__的几个重要参数。
· dataset:这个就是pytorch已有的数据读取接口(比如torchvision.datasets.ImageFolder)或者自定义的数据接口的输出,该输出要么是torch.utils.data.Dataset类的对象,要么是继承自torch.utils.data.Dataset类的自定义类的对象。
· batch_size:how many samples per batch to load (default: 1).
· shuffle:set to True to have the data reshuffled at every epoch (default: False).循环训练数据时下一轮是否要打乱数据顺序。一般设置为True
· drop_last (bool, optional) – set to True to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If False and the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default: False)。设为True代表除不尽时舍弃末尾数据,False代表不舍弃但最后一组数据更小
· num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)用于加载包的进程数量
· sampler (Sampler or Iterable, optional) – defines the strategy to draw samples from the dataset. Can be any Iterable with len implemented. If specified, shuffle must not be specified.
· batch_sampler (Sampler or Iterable, optional) – like sampler, but returns a batch of indices at a time. Mutually exclusive with batch_size, shuffle, sampler, and drop_last.
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
train_features, train_labels = next(iter(train_dataloader))
#iter(dataloader)返回的是一个迭代器,然后可以使用next()访问
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
dataloader 本质是一个可迭代对象,使用 iter(dataloader) 返回的是一个迭代器,然后可以使用 next 访问;
也可以使用 for inputs, labels in dataloader 进行可迭代对象的访问;
有时我们可能需要基于DataLoader类写自己的加载类
这个自定义的DataLoaderX类是基于PyTorch中的DataLoader类进行扩展的。它用于在训练过程中异步加载和预处理数据,并支持多GPU训练。下面是对该类的详细介绍:
__init__(self, local_rank, **kwargs)
这个方法是类的构造函数,用于初始化DataLoaderX类的实例。它继承了DataLoader类的所有参数,并添加了一个额外的参数local_rank,表示本地进程的排名。
在构造函数中,首先调用父类DataLoader的构造函数,将传入的参数传递给父类进行初始化。
然后,创建一个CUDA流对象stream,用于管理GPU上的异步操作。并将local_rank赋值给成员变量self.local_rank。
__iter__(self)
这个方法用于返回一个迭代器对象,可以通过循环来遍历数据集中的样本。
在该方法中,首先调用父类DataLoader的__iter__()方法获取原始迭代器对象self.iter。
然后,使用BackgroundGenerator类对self.iter进行封装,以实现在后台线程中提前加载下一个批次的样本。为了支持多GPU训练,需要传递self.local_rank作为参数。
接下来,调用self.preload()方法提前加载第一个批次的样本,并返回迭代器对象self。
preload(self)
这个方法用于提前加载下一个批次的样本到GPU中。它在后台流中执行异步操作,以减小数据加载的延迟。
首先,使用next()函数从原始迭代器对象self.iter中获取下一个批次的样本。如果没有更多的批次,则返回None。
然后,创建一个CUDA流对象self.stream,并使用torch.cuda.stream(self.stream)将后续操作放入该流中。接着,遍历批次中的每个张量,并使用.to(device=self.local_rank, non_blocking=True)将其移动到指定的GPU设备上。
最后,返回加载的批次。
__next__(self)
这个方法用于获取下一个批次的样本。它确保前一批次的数据已经加载完毕,并且在当前批次加载时等待异步操作完成。
首先,使用torch.cuda.current_stream().wait_stream(self.stream)等待前一批次加载的异步操作完成。
然后,将当前批次的样本赋值给batch变量。
接下来,调用self.preload()方法提前加载下一个批次的样本。
最后,返回当前批次的样本。
class DataLoaderX(DataLoader):
def __init__(self, local_rank, **kwargs):
super(DataLoaderX, self).__init__(**kwargs)
self.stream = torch.cuda.Stream(local_rank)
self.local_rank = local_rank
def __iter__(self):
self.iter = super(DataLoaderX, self).__iter__()
self.iter = BackgroundGenerator(self.iter, self.local_rank)
self.preload()
return self
def preload(self):
self.batch = next(self.iter, None)
if self.batch is None:
return None
with torch.cuda.stream(self.stream):
for k in range(len(self.batch)):
self.batch[k] = self.batch[k].to(device=self.local_rank, non_blocking=True)
def __next__(self):
torch.cuda.current_stream().wait_stream(self.stream)
batch = self.batch
if batch is None:
raise StopIteration
self.preload()
return batch
class BackgroundGenerator(threading.Thread):
def __init__(self, generator, local_rank, max_prefetch=6):
super(BackgroundGenerator, self).__init__()
self.queue = Queue.Queue(max_prefetch)
self.generator = generator
self.local_rank = local_rank
self.daemon = True
self.start()
def run(self):
torch.cuda.set_device(self.local_rank)
for item in self.generator:
self.queue.put(item)
self.queue.put(None)
def next(self):
next_item = self.queue.get()
if next_item is None:
raise StopIteration
return next_item
def __next__(self):
return self.next()
def __iter__(self):
return self
三、torchvision
PyTorch 团队专门开发了一个视觉工具包torchvision,这个包独立于PyTorch
torchvision 主要包含三部分:
① ·datasets: 提供常用的数据集加载,设计上都是继承 torch.utils.data.Dataset,主要包括 MNIST、CIFAR10/100、ImageNet、COCO等;
介绍一下常用的torchvision.datasets.ImageFolder
torchvision.datasets.ImageFolder(root: str,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
loader: Callable[[str], Any] = ,
is_valid_file: Optional[Callable[[str], bool]] = None)
Parameters
·root (string) – Root directory path.
root目录下一定是文件夹,然后文件夹里放着图片。
·transform (callable, optional) – A function/transform that takes in an PIL image and ·returns a transformed version. E.g, transforms.RandomCrop
·target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
·loader (callable, optional) – A function to load an image given its path.
·is_valid_file – A function that takes path of an Image file and check if the file is a valid file (used to check of corrupt files)
dataset = torchvision.datasets.ImageFolder(dataset_path, transform=transforms)
dataloader = DataLoader(dataset, batch_size=args.batch_size, shuffle=True)
② ·transforms:提供常用的数据预处理操作,主要包括对 Tensor 以及 PIL Image 对象的操作;
③ ·models:提供深度学习中各种经典网络的网络结构以及预训练好的模型,包括 AlexNet 、VGG 系列、ResNet 系列、Inception 系列等;
1、datasets运用见 一 中实例
torchvision中datasets中所有封装的数据集都是torch.utils.data.Dataset的子类,它们都实现了__getitem__和__len__方法,它们都可以用torch.utils.data.DataLoader进行数据加载。
2、Transforms 中有大量的数据转换类,主要包括对 Tensor 以及 PIL(Python Image Library) Image对象的操作,其中有很大一部分可以用于实现数据增强(DataArgumentation)。若在我们需要解决的问题上能够参与到模型训练中的图片数据非常有限,则这时就要通过对有限的图片数据进行各种变换,来生成新的训练集了,这些变换可以是缩小或者放大图片的大小、对图片进行水平或者垂直翻转等,都是数据增强的方法。
需要注意的是转换一般分为两步,
第一步:构建转换操作,例如 transf = transforms.Normalize(mean=x, std=y),
第二步:执行转换操作,例如 output = transf(input) 。
还可用transforms.Compose将一系列的transforms操作链接起来。
torchvision.transforms.Compose([ ts1,ts2,ts3... ])
#ts为transforms操作,ts1的输出与ts2的输入类型要保持一致
下面看看在 torchvision.transforms 中常用的数据变换操作
这部分直接看源码及附带解释也挺容易懂的,如果遇到注释没有明确指示输入输出变量类型,可以用
print()
print(type())
torchvision.transforms.Resize:改变图片大小为指定的尺寸
'''
size (sequence or int): Desired output size. If size is a sequence like
(h, w), output size will be matched to this. If size is an int,
smaller edge of the image will be matched to this number.
i.e, if height > width, then image will be rescaled to
(size * height / width, size)
'''
tran_resize=transforms.Resize((512,512))
resize_img=tran_resize(tensor_img)
torchvision.transforms.ToTensor:将PIL或numpy格式,shape为(H,W,C)的图像转为shape为(C,H,W)的tensor。同时将每一个[0,255]范围的数值除以255归一化到[0,1]范围
Converts a PIL Image or numpy.ndarray (H x W x C) in the range
[0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
if the PIL Image belongs to one of the modes (L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1)
or if the numpy.ndarray has dtype = np.uint8
torchvision.transforms.ToPILImage:用于将 Tensor 变量的数据转换成 PIL 图片数据,主要是为了方便图片内容的显示。
transforms.Normalize(mean, std, inplace=False):逐channel的对图像执行标准化公式:output = (input - mean) / std。
每个通道的mean和std需要我们自己算出,如果数据集很大,mean和std应该是抽样算出的。
mean:各通道的均值
std:各通道的标准差
inplace:是否修改input本身
为什么这样可以可以加快模型的收敛?
他人回答:数据如果分布在(0,1)之间,可能实际的bias,就是神经网络的输入b会比较大,而模型初始化时b=0的,这样会导致神经网络收敛比较慢,经过Normalize后,可以加快模型的收敛速度。
img_path="数据集/train/ants_image/0013035.jpg"#对应输入自己项目下的图片路径
img=Image.open(img_path)
tensor_img=transforms.ToTensor().__call__(img)
norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
tensor_img=norm(tensor_img)
torchvision.transforms.RandomCrop
torchvision 还提供了两个常用的函数。
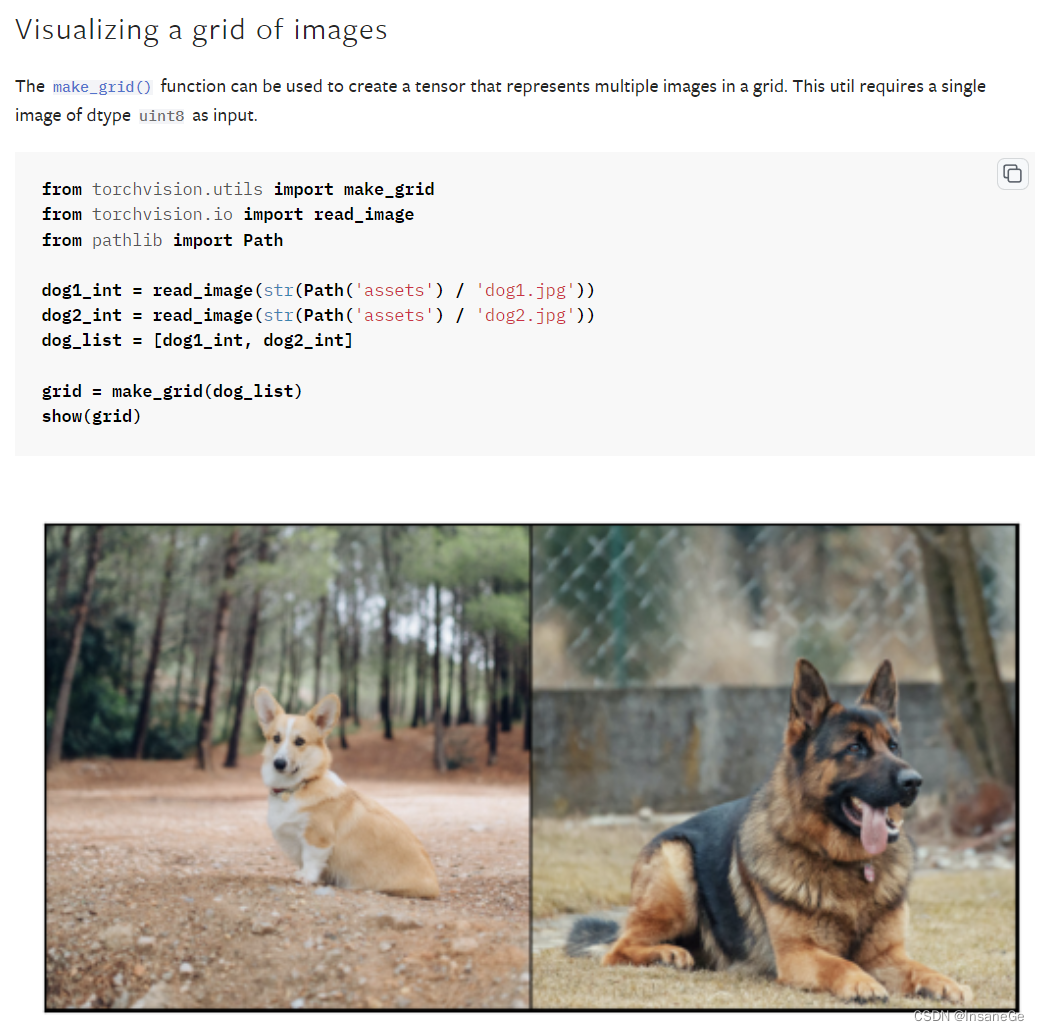
一个是 make_grid ,它能将多张图片拼接起来;
pytorch官网的make_grid函数详解
def make_grid(
tensor: Union[torch.Tensor, List[torch.Tensor]],
nrow: int = 8,#默认8张一行
padding: int = 2,
normalize: bool = False,
value_range: Optional[Tuple[int, int]] = None,
scale_each: bool = False,
pad_value: float = 0.0,
**kwargs,
) -> torch.Tensor:
Args:
tensor (Tensor or list): 4D mini-batch Tensor of shape (B x C x H x W)
or a list of images all of the same size.
nrow (int, optional): Number of images displayed in each row of the grid.
The final grid size is ``(B / nrow, nrow)``. Default: ``8``.
padding (int, optional): amount of padding. Default: ``2``.
normalize (bool, optional): If True, shift the image to the range (0, 1),
by the min and max values specified by ``value_range``. Default: ``False``.
value_range (tuple, optional): tuple (min, max) where min and max are numbers,
then these numbers are used to normalize the image. By default, min and max
are computed from the tensor.
range (tuple. optional):
.. warning::
This parameter was deprecated in ``0.12`` and will be removed in ``0.14``. Please use ``value_range``
instead.
scale_each (bool, optional): If ``True``, scale each image in the batch of
images separately rather than the (min, max) over all images. Default: ``False``.
pad_value (float, optional): Value for the padded pixels. Default: ``0``.
Returns:
grid (Tensor): the tensor containing grid of images.
另一个
是 save_img ,它能将 Tensor 保存成图片。
def save_image(
tensor: Union[torch.Tensor, List[torch.Tensor]],
fp: Union[str, pathlib.Path, BinaryIO],
format: Optional[str] = None,
**kwargs,
) -> None:
"""
Save a given Tensor into an image file.
Args:
tensor (Tensor or list): Image to be saved. If given a mini-batch tensor,
saves the tensor as a grid of images by calling ``make_grid``.
fp (string or file object): A filename or a file object
format(Optional): If omitted, the format to use is determined from the filename extension.
If a file object was used instead of a filename, this parameter should always be used.
**kwargs: Other arguments are documented in ``make_grid``.
"""
例子:
training_data = datasets.FashionMNIST(
root="./data",#指存放在项目根目录下的 data 文件夹
train=True,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=16, shuffle=True)
from torchvision.utils import make_grid, save_image
dataiter = iter(train_dataloader)
img = make_grid(next(dataiter)[0], 4) # 以每行4个图片拼接,且少去了描述图片数量的第一个channel从而变成3 channel
save_image(img, 'a.png')
3、model
①模型的导入和修改
https://pytorch.org/vision/stable/models.html
打开网页后可以在右方看到简介,这里提供了已有多种模型,下面介绍分类模型VGG

torchvision.models.vgg16(*, weights: Optional[torchvision.models.vgg.VGG16_Weights] = None, progress: bool = True, **kwargs: Any) → torchvision.models.vgg.VGG
——VGG-16 from Very Deep Convolutional Networks for Large-Scale Image Recognition.
Parameters:
weights (VGG16_Weights, optional) – The pretrained weights to use. See VGG16_Weights below for more details, and possible values. By default, no pre-trained weights are used.
weights指模型预先训练好的权重(程度)是多少
progress (bool, optional) – If True, displays a progress bar of the download to stderr. Default is True.
为true的话显示一个下载进度条
**kwargs – parameters passed to the torchvision.models.vgg.VGG base class. Please refer to the source code for more details about this class.
vgg_16=torchvision.models.vgg16()
print(vgg_16)
vgg_16.classifier.add_module('add_Linear',nn.Linear(1000,10))
#指定在vgg_16中的classifier层加一层Linear(1000,10)
vgg_16.add_module('add_Linear',nn.Linear(1000,10))
print(vgg_16)
②模型的保存和读取
#保存方式1,模型结构+模型参数
torch.save(vgg_16,"vgg.pth")
#保存方式2,模型参数(官方推荐)
torch.save(vgg_16.state_dict(),"vgg.pth")
#读取
torch.load("vgg.pth")