【Docker】使用docker-compose极速搭建spark集群(含hdfs集群)
docker-compose搭建spark集群(含hdfs集群)
前言
说明:网上看到了大佬写的几篇使用docker极速搭建spark集群的文章,跟着做了一遍,还是遇到了很多问题,特在此整合内容,加上自己收集的一些资料来完善,一方面是想记录一下教程,另一方面帮助大家少走弯路。参考文章在本文末尾,可自行参考学习。
我们经常会遇到这样一个情况,想搭建一个简单的大数据环境用来运行一些小工程小项目或者仅仅是用来学习和完成作业,然而spark集群和hdfs集群环境会消耗很多时间和精力,我们应该关注的是spark应用的开发,快速搭建整个环境,从而尽快投入编码和调试,今天我们就使用docker-compose,极速搭建和体验spark和hdfs的集群环境。
实战环境信息
本次实战所用的电脑是小米笔记本:
CPU:i5-8300H(四核八线程)
内存:16G
操作系统:Window10
虚拟机:
VMware:WORKSTATION 15.5 PRO
镜像:CentOS-7-x86_64-Minimal-2009.iso
核心分配:4核 每个核心2个线程
内存分配:8G
硬盘分配:随意,建议20G起步
docker:20.10.12
docker-compose:1.27.4
spark:2.3.0
hdfs:2.7.1
安装之前
你需要准备好centos7环境,并已完成网络配置能ping通外网。
以下过程全部是以root用户完成,请注意用户权限。
1、安装Docker和Docker-Compose
1.1、安装Docker
如果机器中已经安装过docker,可以直接跳过
关闭防火墙
[root@bigdata ~]# systemctl stop firewalld
[root@bigdata ~]# systemctl disable firewalld
[root@bigdata ~]# systemctl status firewalld
设置SELinux成为permissive模式(临时关闭SELinux)
[root@bigdata ~]# setenforce 0
[root@bigdata ~]# getenforce
更换yum源为阿里源加速
[root@bigdata ~]# yum -y update
[root@bigdata ~]# mkdir /etc/yum.repos.d/oldrepo
[root@bigdata ~]# mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/oldrepo/
[root@bigdata ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@bigdata ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
[root@bigdata ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@bigdata ~]# yum clean all
[root@bigdata ~]# yum makecache fast
安装docker
[root@bigdata ~]# yum list docker-ce --showduplicates | sort -r
[root@bigdata ~]# yum -y install docker-ce
[root@bigdata ~]# systemctl start docker
[root@bigdata ~]# systemctl enable docker
[root@bigdata ~]# ps -ef | grep docker
[root@bigdata ~]# docker version
到这一步能正常输出docker版本,说明docker已经成功安装。
为了后续拉取镜像能更快,需要添加一个镜像:
[root@bigdata ~]# vi /etc/docker/daemon.json
添加以下内容,保存退出
{
"registry-mirrors": ["https://x3n9jrcg.mirror.aliyuncs.com"]
}
重启docker
[root@bigdata ~]# systemctl daemon-reload
[root@bigdata ~]# systemctl restart docker
后面需要用git拉取一些资源,所以要安装git,为了能够正常访问github,需要修改一下hosts文件
[root@bigdata ~]# yum -y install git
[root@bigdata ~]# vi /etc/hosts
添加以下内容:
192.30.255.112 github.com git
1.2、安装Docker-Compose
如果已经安装过docker-compose,可以直接跳过
[root@bigdata ~]# curl -L https://get.daocloud.io/docker/compose/releases/download/1.27.4/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 423 100 423 0 0 476 0 --:--:-- --:--:-- --:--:-- 476
100 11.6M 100 11.6M 0 0 6676k 0 0:00:01 0:00:01 --:--:-- 6676k
[root@bigdata ~]# chmod +x /usr/local/bin/docker-compose
[root@bigdata ~]# docker-compose --version
docker-compose version 1.27.4, build 40524192
能够正常输出docker-compose版本号,说明成功安装。
2、极速搭建Spark集群(含HDFS集群)
先创建一个文件夹用来存放配置文件,集群的安装路径也会是这个文件夹,所以想好放在哪里比较好,我的路径是:/home/sparkcluster_hdfs
2.1、编辑hadoop.env配置文件
进入你创建的目录编辑hadoop.env配置文件,我这里是/home/sparkcluster_hdfs目录:
[root@bigdata ~]# cd /home/sparkcluster_hdfs/
[root@bigdata sparkcluster_hdfs]# vi hadoop.env
复制以下内容进去保存
CORE_CONF_fs_defaultFS=hdfs://namenode:8020
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource___tracker_address=resourcemanager:8031
2.2、编辑docker-compose.yml编排配置文件
还是在/home/sparkcluster_hdfs目录编辑docker-compose.yml编排配置文件:
[root@bigdata sparkcluster_hdfs]# vi docker-compose.yml
复制以下内容进去保存
注意:spark的worker数量,以及worker内存的分配,都可以通过修改docker-compose.yml文件来调整。
version: "2.2"
services:
namenode:
image: bde2020/hadoop-namenode:1.1.0-hadoop2.7.1-java8
container_name: namenode
volumes:
- ./hadoop/namenode:/hadoop/dfs/name
- ./input_files:/input_files
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
ports:
- 50070:50070
resourcemanager:
image: bde2020/hadoop-resourcemanager:1.1.0-hadoop2.7.1-java8
container_name: resourcemanager
depends_on:
- namenode
- datanode1
- datanode2
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:1.1.0-hadoop2.7.1-java8
container_name: historyserver
depends_on:
- namenode
- datanode1
- datanode2
volumes:
- ./hadoop/historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:1.1.0-hadoop2.7.1-java8
container_name: nodemanager1
depends_on:
- namenode
- datanode1
- datanode2
env_file:
- ./hadoop.env
datanode1:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode1
depends_on:
- namenode
volumes:
- ./hadoop/datanode1:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode2:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode2
depends_on:
- namenode
volumes:
- ./hadoop/datanode2:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode3:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode3
depends_on:
- namenode
volumes:
- ./hadoop/datanode3:/hadoop/dfs/data
env_file:
- ./hadoop.env
master:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: master
command: bin/spark-class org.apache.spark.deploy.master.Master -h master
hostname: master
environment:
MASTER: spark://master:7077
SPARK_CONF_DIR: /conf
SPARK_PUBLIC_DNS: localhost
links:
- namenode
expose:
- 4040
- 7001
- 7002
- 7003
- 7004
- 7005
- 7077
- 6066
ports:
- 4040:4040
- 6066:6066
- 7077:7077
- 8080:8080
volumes:
- ./conf/master:/conf
- ./data:/tmp/data
- ./jars:/root/jars
worker1:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker1
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker1
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 1g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8081
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
- 8081
ports:
- 8081:8081
volumes:
- ./conf/worker1:/conf
- ./data/worker1:/tmp/data
worker2:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker2
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker2
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 1g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8082
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
- 8082
ports:
- 8082:8082
volumes:
- ./conf/worker2:/conf
- ./data/worker2:/tmp/data
worker3:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker3
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker3
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 1g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8083
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
- 8083
ports:
- 8083:8083
volumes:
- ./conf/worker3:/conf
- ./data/worker3:/tmp/data
worker4:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker4
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker4
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 1g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8084
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
- 8084
ports:
- 8084:8084
volumes:
- ./conf/worker4:/conf
- ./data/worker4:/tmp/data
worker5:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker5
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker5
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 1g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8085
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
- 8085
ports:
- 8085:8085
volumes:
- ./conf/worker5:/conf
- ./data/worker5:/tmp/data
worker6:
image: gettyimages/spark:2.3.0-hadoop-2.8
container_name: worker6
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
hostname: worker6
environment:
SPARK_CONF_DIR: /conf
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 1g
SPARK_WORKER_PORT: 8881
SPARK_WORKER_WEBUI_PORT: 8086
SPARK_PUBLIC_DNS: localhost
links:
- master
expose:
- 7012
- 7013
- 7014
- 7015
- 8881
- 8086
ports:
- 8086:8086
volumes:
- ./conf/worker6:/conf
- ./data/worker6:/tmp/data
2.3、执行docker-compose命令,一键搭建集群
还是在/home/sparkcluster_hdfs目录下,执行命令:
[root@bigdata sparkcluster_hdfs]# docker-compose up -d
接下来静候命令执行完成,整个spark和hdfs集群环境就搭建好了。
2.4、查看集群环境
在/home/sparkcluster_hdfs目录查看容器情况:
[root@bigdata sparkcluster_hdfs]# docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------------------------------------------------------------------------------------
datanode1 /entrypoint.sh /run.sh Up (healthy) 50075/tcp
datanode2 /entrypoint.sh /run.sh Up (healthy) 50075/tcp
datanode3 /entrypoint.sh /run.sh Up (healthy) 50075/tcp
historyserver /entrypoint.sh /run.sh Up (healthy) 8188/tcp
master bin/spark-class org.apache ... Up 0.0.0.0:4040->4040/tcp,:::4040->4040/tcp, 0.0.0.0:6066->6066/tcp,:::6066->6066/tcp, 7001/tcp,
7002/tcp, 7003/tcp, 7004/tcp, 7005/tcp, 0.0.0.0:7077->7077/tcp,:::7077->7077/tcp,
0.0.0.0:8080->8080/tcp,:::8080->8080/tcp
namenode /entrypoint.sh /run.sh Up (healthy) 0.0.0.0:50070->50070/tcp,:::50070->50070/tcp
nodemanager1 /entrypoint.sh /run.sh Up (healthy) 8042/tcp
resourcemanager /entrypoint.sh /run.sh Up (healthy) 8088/tcp
worker1 bin/spark-class org.apache ... Up 7012/tcp, 7013/tcp, 7014/tcp, 7015/tcp, 0.0.0.0:8081->8081/tcp,:::8081->8081/tcp, 8881/tcp
worker2 bin/spark-class org.apache ... Up 7012/tcp, 7013/tcp, 7014/tcp, 7015/tcp, 0.0.0.0:8082->8082/tcp,:::8082->8082/tcp, 8881/tcp
worker3 bin/spark-class org.apache ... Up 7012/tcp, 7013/tcp, 7014/tcp, 7015/tcp, 0.0.0.0:8083->8083/tcp,:::8083->8083/tcp, 8881/tcp
worker4 bin/spark-class org.apache ... Up 7012/tcp, 7013/tcp, 7014/tcp, 7015/tcp, 0.0.0.0:8084->8084/tcp,:::8084->8084/tcp, 8881/tcp
worker5 bin/spark-class org.apache ... Up 7012/tcp, 7013/tcp, 7014/tcp, 7015/tcp, 0.0.0.0:8085->8085/tcp,:::8085->8085/tcp, 8881/tcp
worker6 bin/spark-class org.apache ... Up 7012/tcp, 7013/tcp, 7014/tcp, 7015/tcp, 0.0.0.0:8086->8086/tcp,:::8086->8086/tcp, 8881/tcp
[root@bigdata sparkcluster_hdfs]#
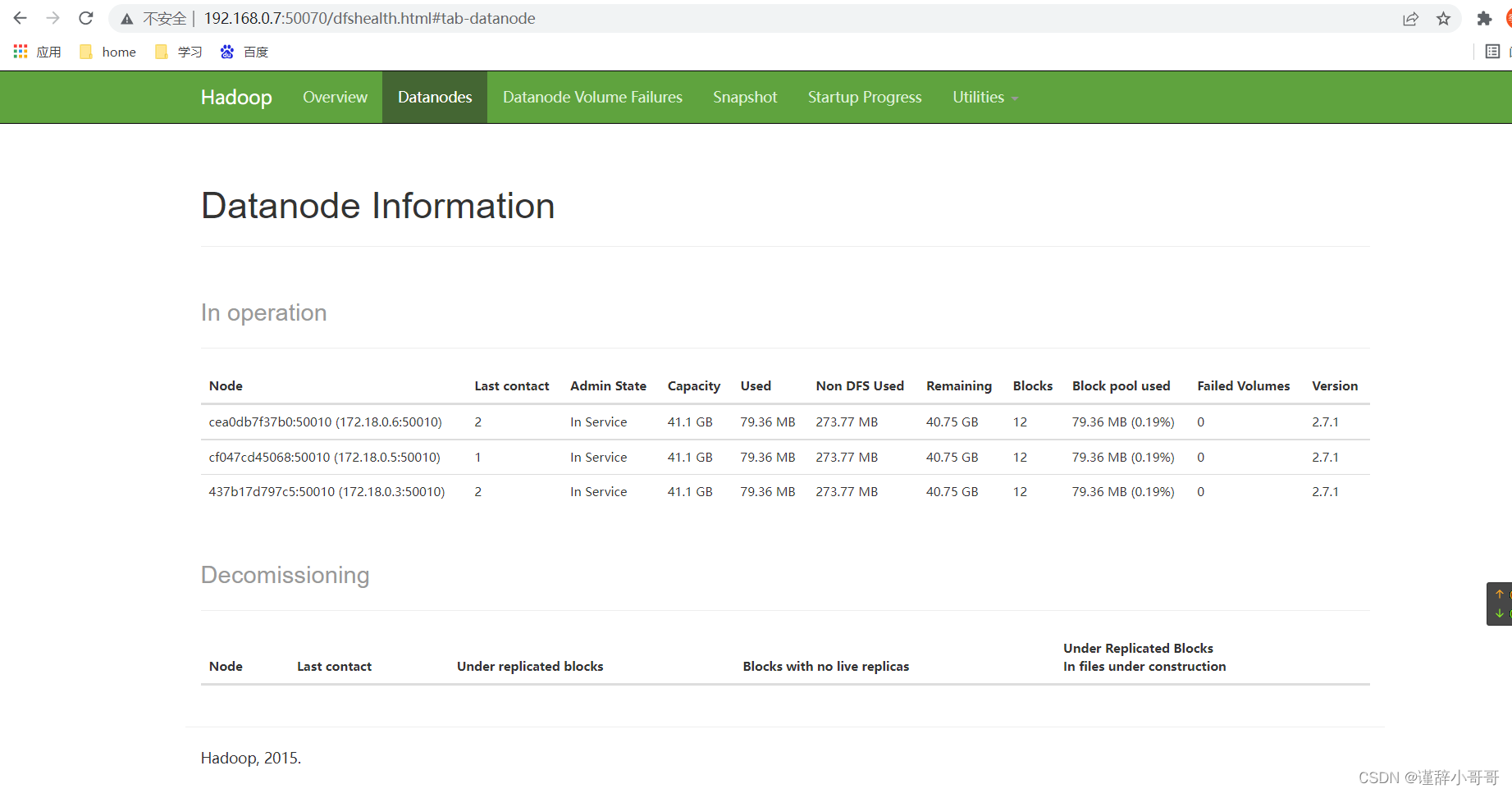
用浏览器查看hdfs,如下图,可见有三个DataNode
地址是:http://centos机器的ip:50070
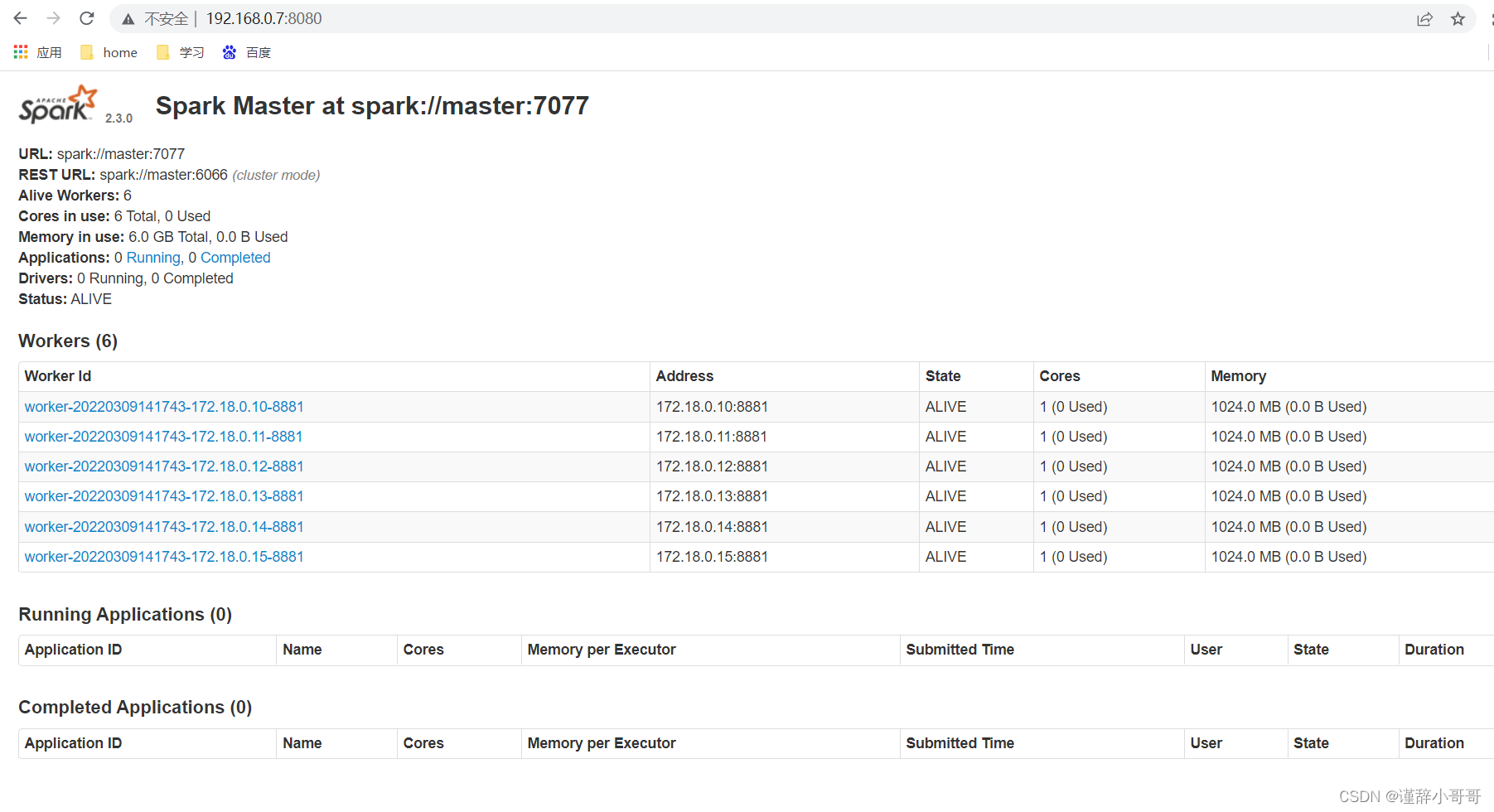
浏览器查看spark,如下图,可见有六个worker
地址是:http://centos机器的ip:8080
在CentOS机器的命令行输入以下命令,即可创建一个spark_shell:
docker exec -it master spark-shell --executor-memory 512M --total-executor-cores 2
如下所示,已经进入了spark_shell的对话模式:
[root@bigdata sparkcluster_hdfs]# docker exec -it master spark-shell --executor-memory 512M --total-executor-cores 2
2022-03-09 16:10:58 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://localhost:4040
Spark context available as 'sc' (master = spark://master:7077, app id = app-20220309161107-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
3、spark集群开机自启动
spark集群和hdfs集群由多个容器各司其职来完成整个工作的,每个容器启动有顺序要求,官方通过 docker-compose.yml 文件对容器进行编排,使用 depends_on 定义依赖关系决定了容器的启动顺序。常规来说,正常使用 docker-compose 来启动容器不会存在任何问题,各个容器服务都能正常启动并运行。
我们上面配置的docker-compose.yml文件中并没有给容器配置开机自启(restart: always)
但是…
如果你在docker-compose.yml 中为所有容器都配置了 restart: always
这表示所有的容器在意外关闭后都会自动重启,比如 docker 重启或服务器重启。
然而…
docker 本身对容器的启动是不区分顺序的,也就是你可以认为 depends_on 是 docker-compose 独有的功能。当我们服务器重启后,docker 会将设定 restart: always 的容器启动(不分先后顺序)。而我们实际的业务需要又会因为启动顺序问题导致一些容器启动失败,这样就出现了我们的集群在服务器重启后可能出现部分容器启动失败的问题。
那么,如何解决这个问题呢?
写一个系统服务(将 spark和hdfs集群 配置为 systemd 的 service),将 docker-compose up -d 纳入启动命令中,将 docker-compose stop纳入停止命令中,这样将服务配置为随系统启动即可。
3.1、自定义系统服务
进入到/usr/lib/systemd/system/目录,并编辑一个spark和hdfs集群的服务配置文件(这里我把文件命名为:sparkcluster_hdfs.service):
[root@bigdata sparkcluster_hdfs]# cd /usr/lib/systemd/system/
[root@bigdata system]# vi sparkcluster_hdfs.service
添加以下内容:
[Unit]
Description=sparkcluster_hdfs
After=docker.service systemd-networkd.service systemd-resolved.service
Requires=docker.service
Documentation=https://www.baidu.com/
[Service]
Type=simple
Restart=always
RestartSec=5
PrivateTmp=true
ExecStart=/usr/local/bin/docker-compose -f /home/sparkcluster_hdfs/docker-compose.yml up
ExecReload=/usr/local/bin/docker-compose -f /home/sparkcluster_hdfs/docker-compose.yml restart
ExecStop=/usr/local/bin/docker-compose -f /home/sparkcluster_hdfs/docker-compose.yml stop
[Install]
WantedBy=multi-user.target
这里面的路径只能是绝对路径!!!
docker-compose 的绝对路径,可以通过命令 which docker-compose 查看。
3.2、设置服务为随系统自启
# 设置开机自启
systemctl enable sparkcluster_hdfs
# 启动服务
systemctl start sparkcluster_hdfs
最后,重启你的服务器验证一下结果。
参考文章
1、使用Docker安装Spark集群(带有HDFS)
2、docker下,极速搭建spark集群(含hdfs集群)
3、docker下的spark集群,调整参数榨干硬件
4、docker-compose 容器因为依赖关系自启动失败问题(harbor 问题案例)
5、Docker-compose
6、Docker教程小白实操入门(20)–如何删除数据卷
7、关于systemctl服务中TYPE参数的那些事