介绍:
spring,springmvc,mybatis,mysql,eclipse
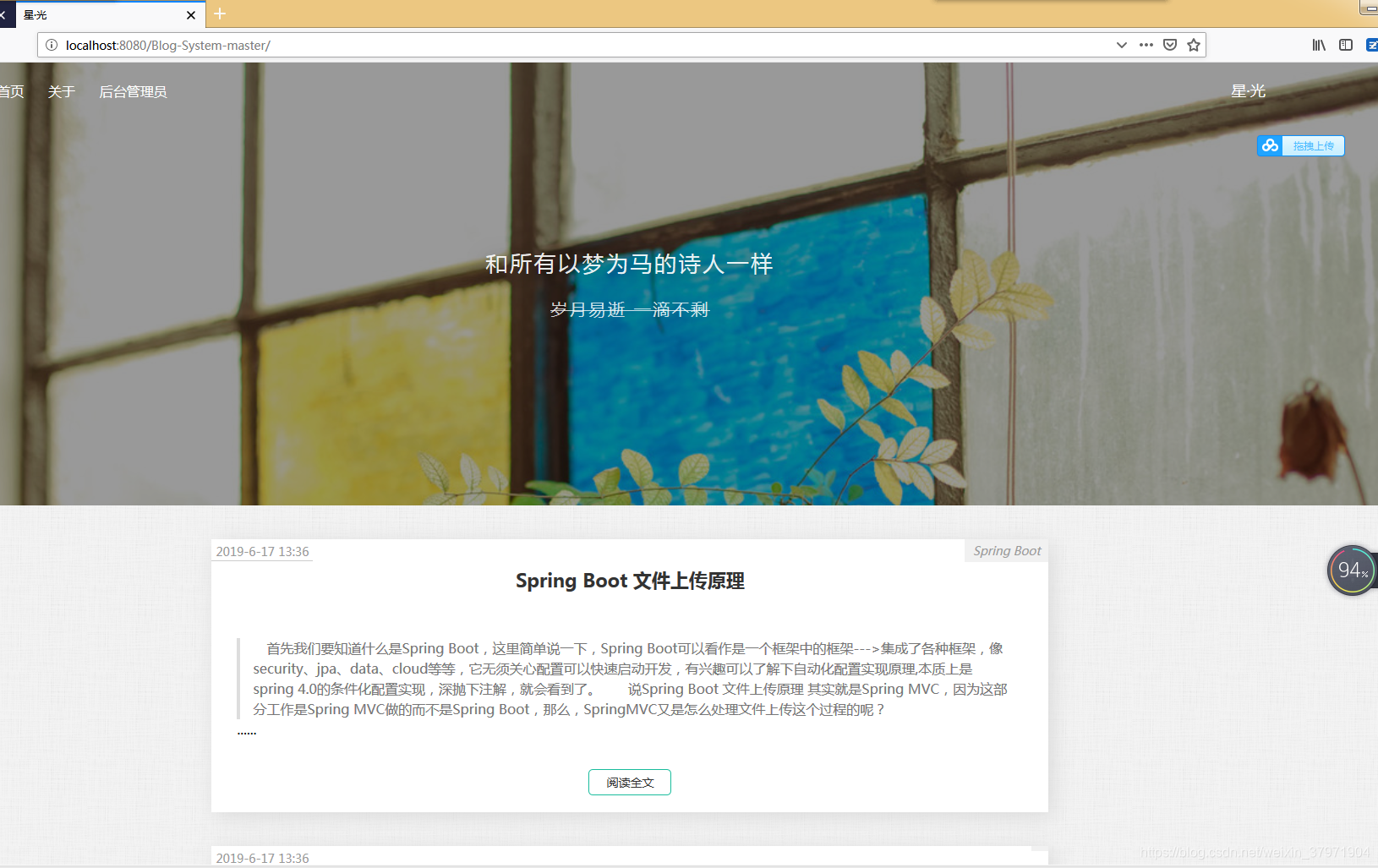
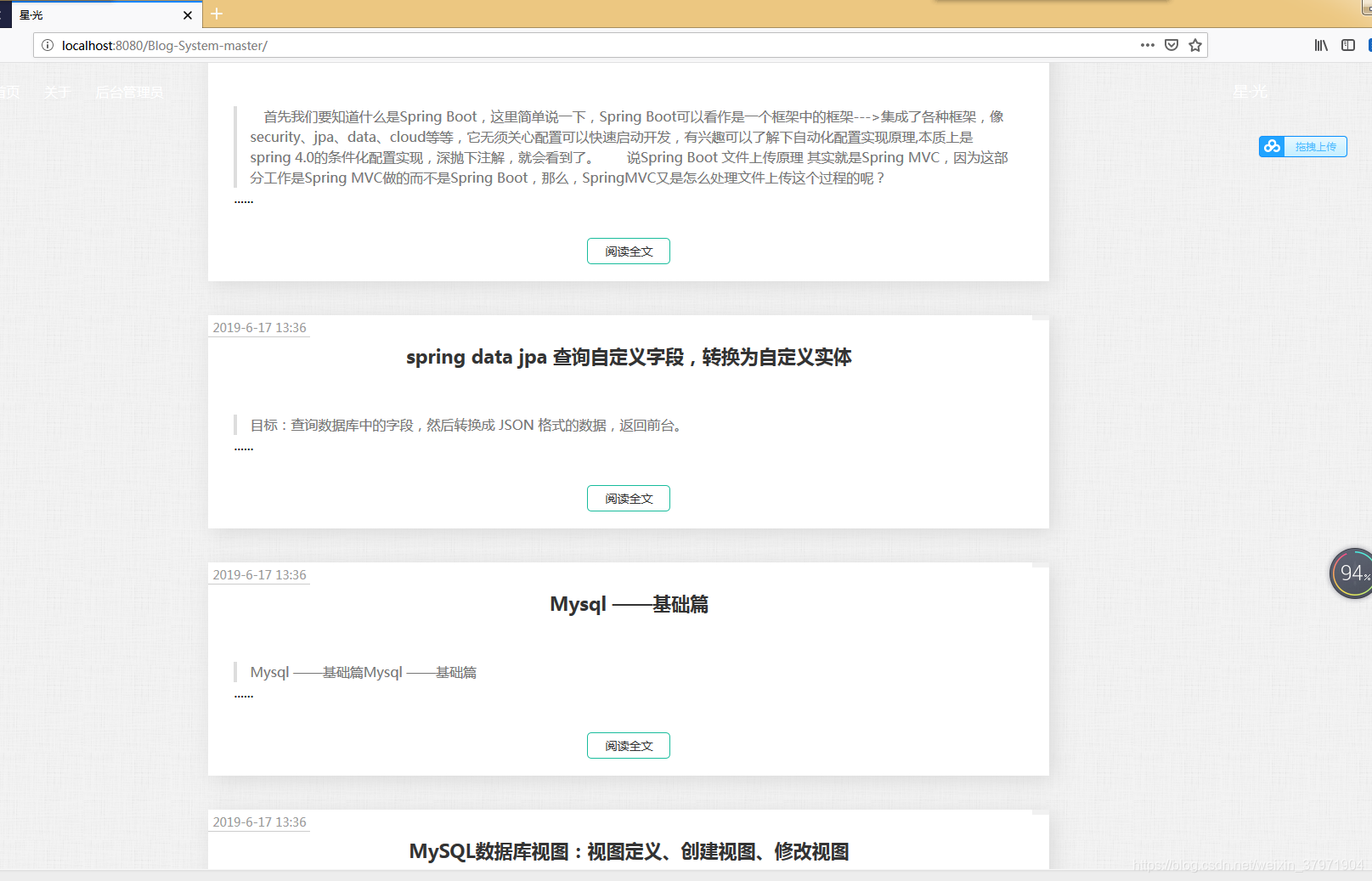
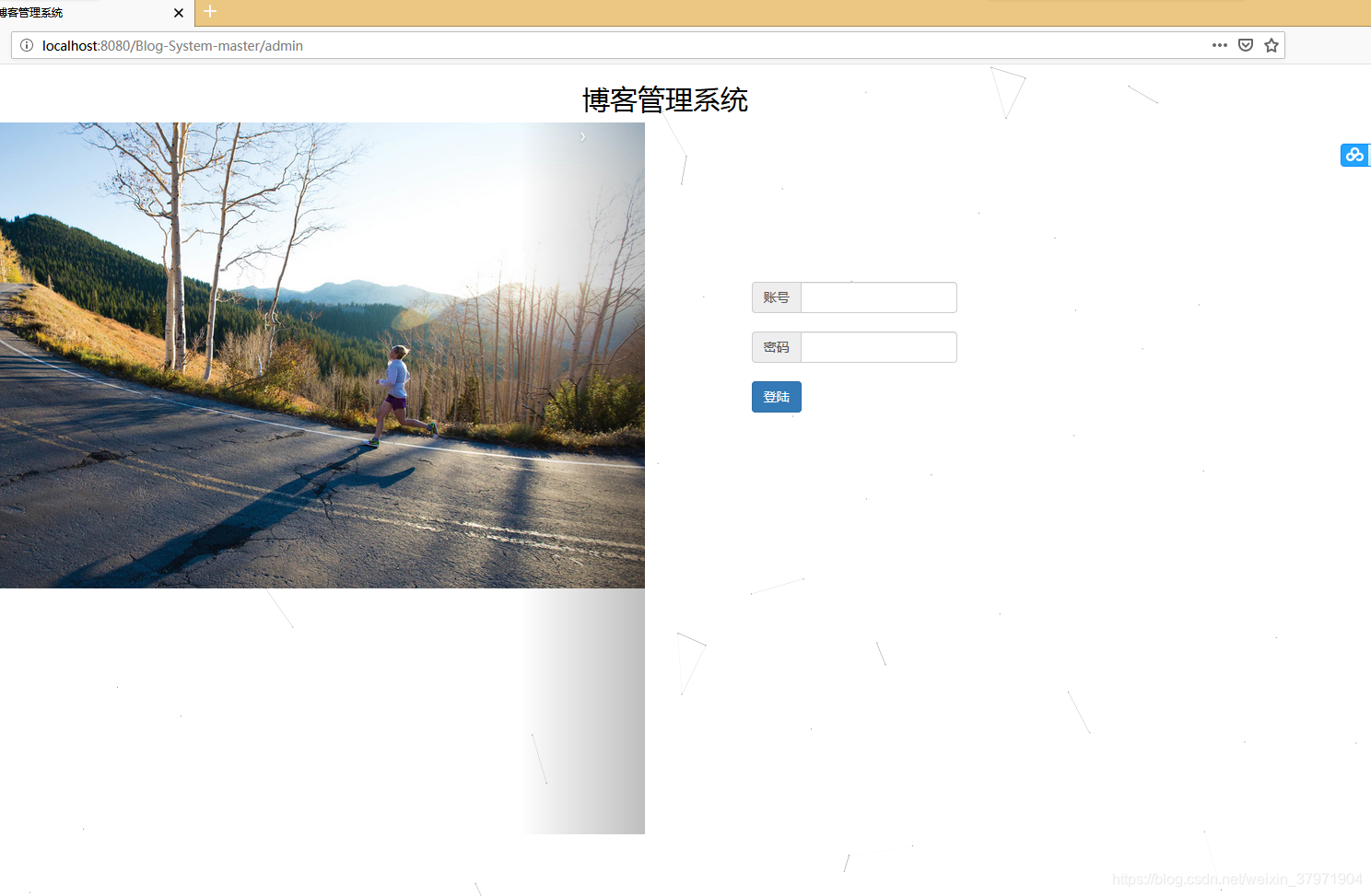
效果图:
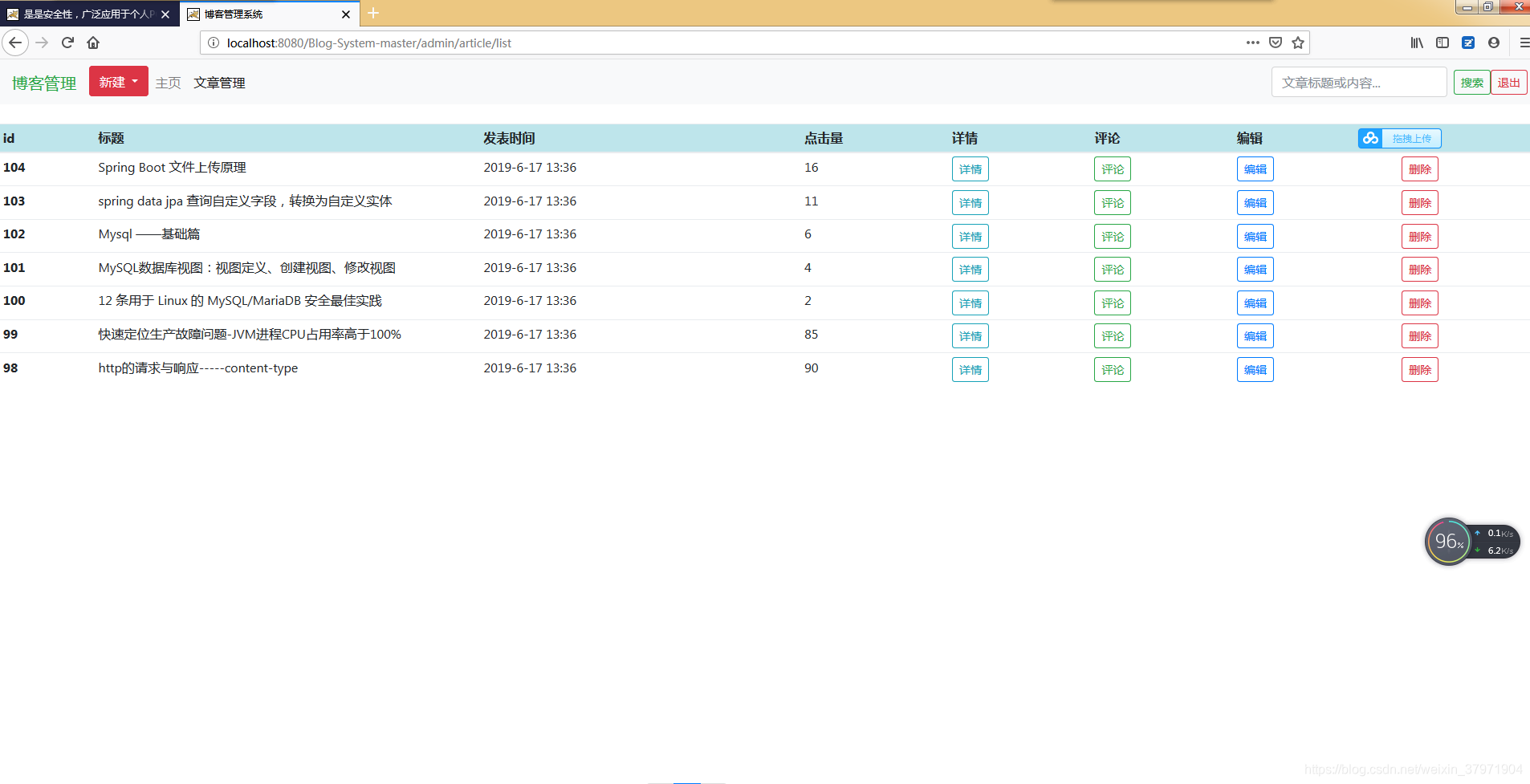
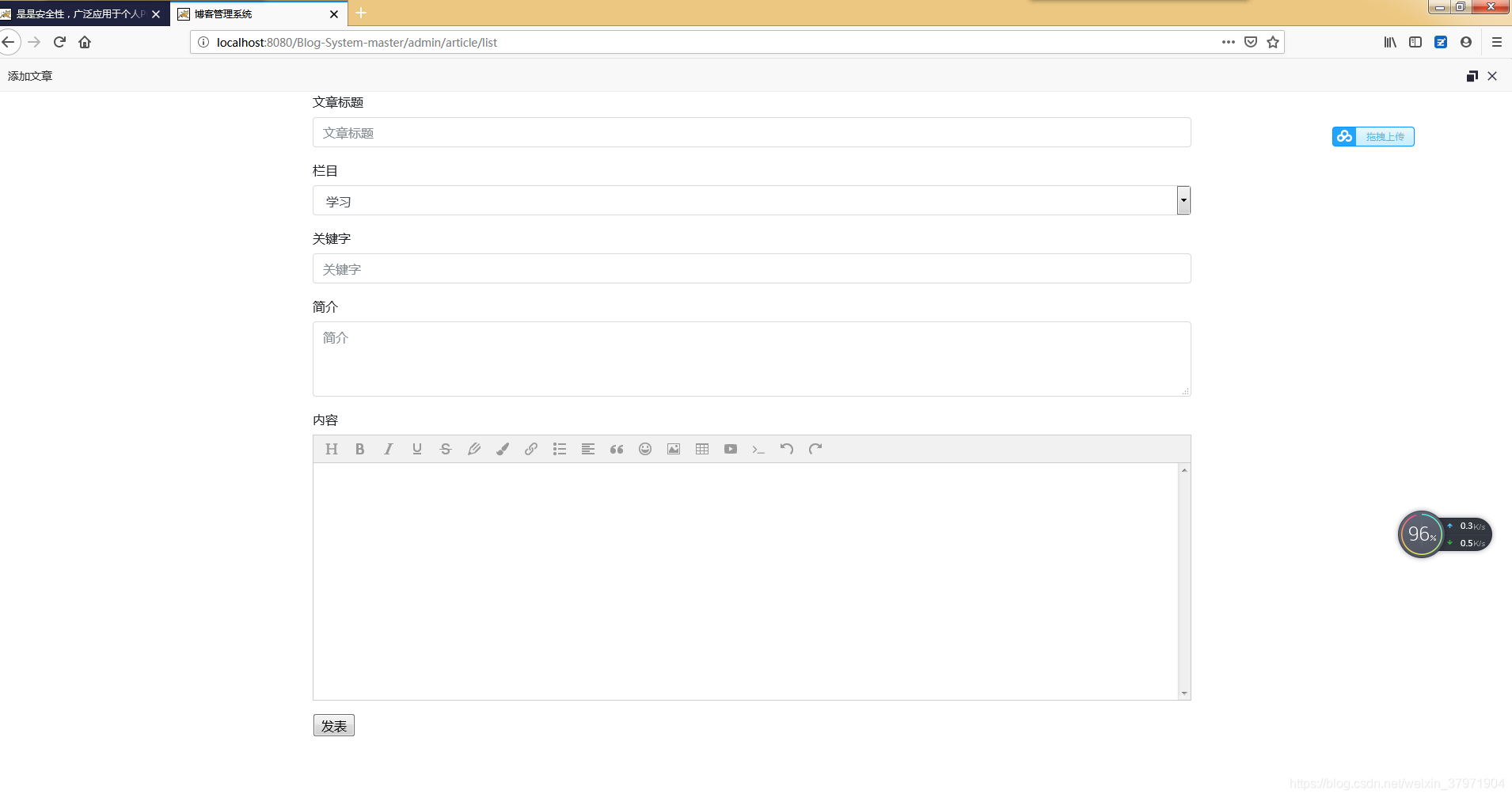
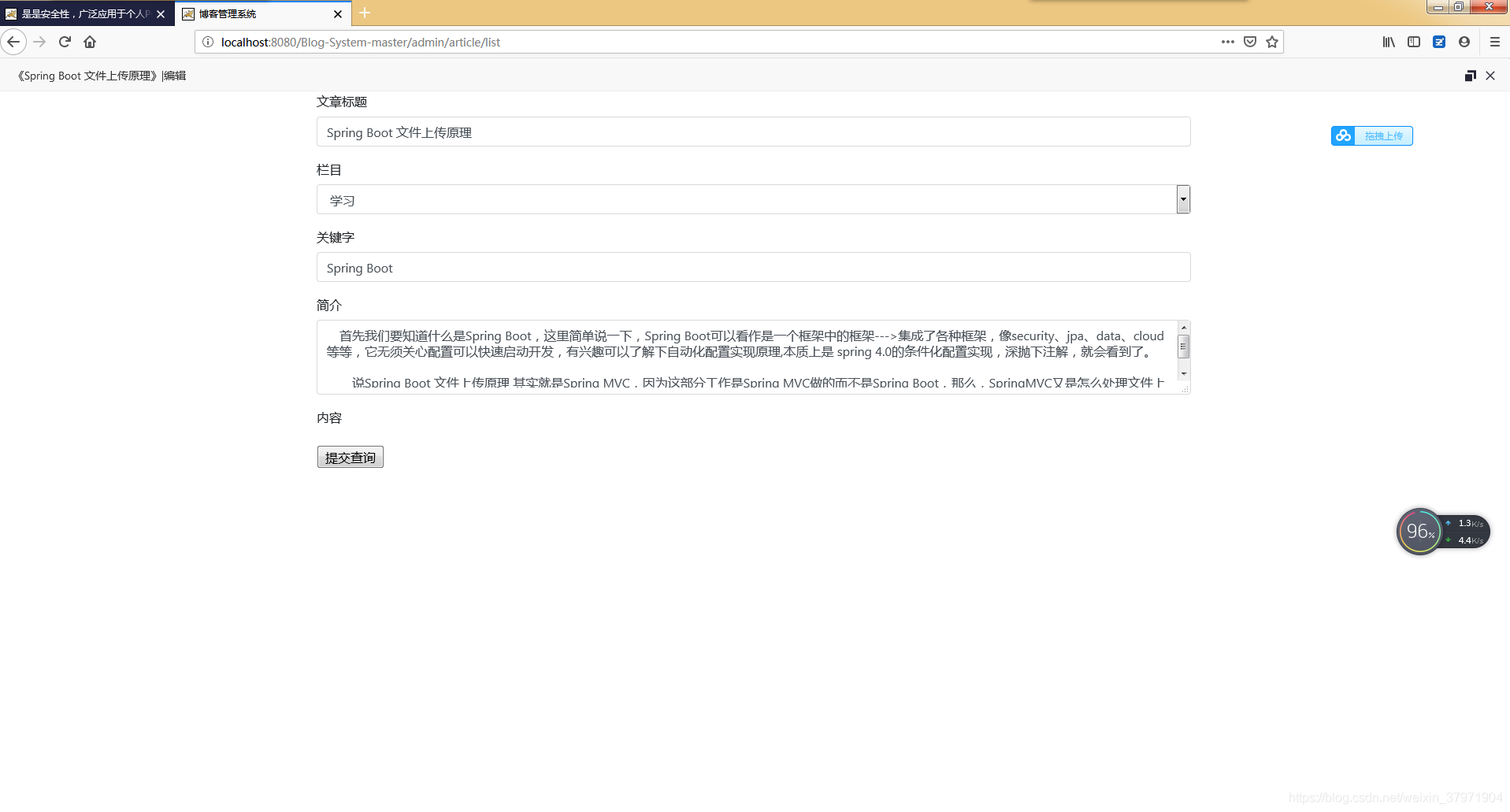
数据库表:
CREATE TABLE IF NOT EXISTS admin (
id mediumint(9) NOT NULL AUTO_INCREMENT,
username varchar(30) NOT NULL,
password char(32) NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY username (username)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1206227 ;
–
– 转存表中的数据 admin
INSERT INTO admin (id, username, password) VALUES
(10080, ‘雨云天下’, ‘111111’);
–
– 表的结构 admin_login_log
CREATE TABLE IF NOT EXISTS admin_login_log (
id bigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘日志ID’,
admin_id int(11) NOT NULL COMMENT ‘管理员ID’,
date timestamp NULL DEFAULT NULL COMMENT ‘登陆日期’,
ip varchar(30) DEFAULT NULL COMMENT ‘登陆IP’,
PRIMARY KEY (id)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=41 ;
–
– 转存表中的数据 admin_login_log
INSERT INTO admin_login_log (id, admin_id, date, ip) VALUES
(25, 10080, ‘2018-02-27 03:39:48’, ‘0:0:0:0:0:0:0:1’),
(26, 10080, ‘2018-02-27 05:34:29’, ‘0:0:0:0:0:0:0:1’),
(27, 10080, ‘2018-02-27 06:41:30’, ‘0:0:0:0:0:0:0:1’),
(28, 10080, ‘2018-02-27 07:18:22’, ‘0:0:0:0:0:0:0:1’),
(29, 10080, ‘2018-02-27 07:18:46’, ‘0:0:0:0:0:0:0:1’),
(30, 10080, ‘2018-02-27 07:28:14’, ‘0:0:0:0:0:0:0:1’),
(31, 10080, ‘2018-02-27 07:32:13’, ‘0:0:0:0:0:0:0:1’),
(32, 10080, ‘2018-02-27 07:51:58’, ‘0:0:0:0:0:0:0:1’),
(33, 10080, ‘2018-02-27 08:11:26’, ‘0:0:0:0:0:0:0:1’),
(34, 10080, ‘2018-02-27 08:21:32’, ‘0:0:0:0:0:0:0:1’),
(35, 10080, ‘2018-02-27 08:28:39’, ‘0:0:0:0:0:0:0:1’),
(36, 10080, ‘2018-02-27 08:43:33’, ‘0:0:0:0:0:0:0:1’),
(37, 10080, ‘2018-02-27 09:14:37’, ‘0:0:0:0:0:0:0:1’),
(38, 10080, ‘2018-02-27 09:40:24’, ‘0:0:0:0:0:0:0:1’),
(39, 10080, ‘2018-02-27 09:56:18’, ‘0:0:0:0:0:0:0:1’),
(40, 10080, ‘2018-03-13 09:37:35’, ‘0:0:0:0:0:0:0:1’);
–
– 表的结构 article
CREATE TABLE IF NOT EXISTS article (
id mediumint(9) NOT NULL AUTO_INCREMENT,
title varchar(50) NOT NULL COMMENT ‘标题’,
keywords varchar(150) NOT NULL COMMENT ‘关键字’,
desci varchar(500) NOT NULL COMMENT ‘描述’,
pic varchar(500) DEFAULT NULL COMMENT ‘图片地址’,
content text NOT NULL COMMENT ‘内容’,
click mediumint(9) NOT NULL DEFAULT ‘0’ COMMENT ‘点击量’,
time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘发表日期’,
catalog_id mediumint(9) NOT NULL,
PRIMARY KEY (id)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=105 ;
–
– 转存表中的数据 article
INSERT INTO article (id, title, keywords, desci, pic, content, click, time, catalog_id) VALUES
(98, ‘http的请求与响应-----content-type’, ‘’, ‘content-type 指请求消息头的中请求消息数据的格式\r\n\r\n有三种用法。’, NULL, ‘
content-type 指请求消息头的中请求消息数据的格式
有三种用法
第一种:设置在request header的参数中
js中可以在发送请求前在请求消息头中设置content-type
var xhr = window.XMLHttpRequest ? new window.XMLHttpRequest() : new ActiveXObject(‘Microsoft.XMLHTTP’);
xhr.open(method, url, true);
xhr.onreadystatechange = function () {};
xhr.setRequestHeader(‘Content-Type’, ‘application/x-www-form-urlencoded’);
xhr.send(params);
第二种:设置在发送请求页面的header中
<header>
<meta content=“text/html” charset=“utf-8”/>
</header>
第三种:设置在form表单提交的enctype参数中
<form enctype=“multipart/form-data”></form>
格式 Content-Type: type/subtype;parameter;
例如 Content-Type: text/html;charset:utf-8;
type:text,或者application,或者*
text-------主类型是文本类型
application----主类型是应用
--------------所有类型都适用
subtype:子类型
---------------所有类型都适用
html------------子类型为html格式
xml-------------子类型为xml
png-------------子类型为png格式
parameter:参数,常用的是编码方式参数charset:utf-8
type/subtype 即是互联网媒体类型,也叫作MIME-Type
常见的媒体类型
主类型是text的
text/html : HTML格式
text/plain :纯文本格式
text/xml : XML格式
image/png: png图片格式
主类型是application的
application/xhtml+xml :XHTML格式
application/xml : XML数据格式
application/json : JSON数据格式
application/octet-stream : 二进制流数据(如常见的文件下载)
特殊的用于上传文件时的mime-type
multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
application/x-www-form-urlencoded: 表单提交默认的mime-type,设置在enctype参数中,表单数据将会以k1=v1&k1=v1&k1=v1的形式发送到服务器
mime-type的设置与文件类型,文件后缀名密切相关,如tomcat中的web.xml文件中就有详尽的mime-mappping设置
详细的mime-type列表:http://www.w3school.com.cn/media/media_mimeref.asp
标签: web前端, http请求, 媒体类型, content-type
(99, ‘快速定位生产故障问题-JVM进程CPU占用率高于100%’, ‘’, ‘这几年作为技术leader处理过的线上紧急问题,掐指一算应该有不下10次吧(说多了都是泪啊~~)。所以挡刀救火也是leader的必备技能!本文主要分享遇到“JVM进程CPU占用率超100%”时如何快速定位原因。’, NULL, ‘
前言
古语有云:人在江湖漂,哪有不挨刀。
这几年作为技术leader处理过的线上紧急问题,掐指一算应该有不下10次吧(说多了都是泪啊~~)。所以挡刀救火也是leader的必备技能!本文主要分享遇到“JVM进程CPU占用率超100%”时如何快速定位原因。
1. 生产故障-JVM进程CPU占用率高于100%
某日,运维同学反馈生产环境有故障,某个JVM进程CPU负载一直居高不下。登入服务器用 top -c 命令查看如下:
top - 00:37:39 up 48 days, 10:41, 5 users, load average: 3.34, 3.18, 3.10Tasks: 166 total, 1 running, 165 sleeping, 0 stopped, 0 zombie\r\nCpu0 : 0.7%us, 0.3%sy, 0.0%ni, 99.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stCpu1 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stCpu2 : 1.3%us, 0.3%sy, 0.0%ni, 98.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stCpu3 : 0.3%us, 0.0%sy, 0.0%ni, 99.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stMem: 16332280k total, 15744336k used, 587944k free, 200632k buffers\r\nSwap: 8191992k total, 408724k used, 7783268k free, 7201204k cached\r\n\r\n PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND \r\n 9702 bb 20 0 2898m 348m 14m S 100.6 2.2 01:47.18 java -server -Xms512M -Xmx512M -Xmn192M -Xss256k -XX:PermSize=64M -XX:MaxPermSize=128M -verbose:\r\n …123456789101112
从输出结果看,CPU load 达到3以上,服务器是4核机器,负载已经不低了。进程ID为9720的进程CPU占用率超过100%。
2. 定位故障的思路
首先找出问题进程内CPU占用率高的线程
再通过线程栈信息找出该线程当时在运行的问题代码段
3. 定位故障的步骤
3.1 用top命令查找进程内导致CPU占用率高的线程
先祭出第一招, top命令加上 -H -b 两个选项:-H 可以查看由某个进程启动的所有线程,-b 选项指定以批处理模式输出结果 。具体命令如下:
$ top -Hbp 9702top - 00:38:54 up 48 days, 10:43, 5 users, load average: 0.81, 0.36, 0.16Tasks: 38 total, 1 running, 37 sleeping, 0 stopped, 0 zombieCpu(s): 3.5%us, 1.4%sy, 0.0%ni, 94.5%id, 0.3%wa, 0.0%hi, 0.2%si, 0.0%stMem: 16332280k total, 15744500k used, 587780k free, 200632k buffersSwap: 8191992k total, 408724k used, 7783268k free, 7201392k cached\r\n\r\n PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 10007 bb 20 0 2898m 348m 14m R 100.5 2.2 1:41.31 java \r\n 9702 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.00 java \r\n 9705 bb 20 0 2898m 348m 14m S 0.0 2.2 0:06.44 java \r\n 9706 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.11 java \r\n 9707 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.11 java \r\n 9708 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.11 java \r\n 9709 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.10 java \r\n 9710 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.00 java \r\n 9711 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.07 java \r\n 9712 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.03 java \r\n 9713 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.03 java \r\n 9714 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.00 java \r\n 9715 bb 20 0 2898m 348m 14m S 0.0 2.2 0:00.00 java \r\n 9716 bb 20 0 2898m 348m 14m S 0.0 2.2 0:05.60 java12345678910111213141516171819202122
输出结果里的PID其实是线程ID,可以看到线程ID为10007的线程CPU占用率为100.5%,它就是罪魁祸首。上面的命令可以再优化下:查出CPU占用率超过某个值的所有线程,例如超过50%,如下:
top -Hbp 9702 | awk ‘/java/ && KaTeX parse error: Expected 'EOF', got '&' at position 2: 9&̲gt;50'1</pr… printf “%x\n” 10007271712
因为jstack输出的线程栈信息中,线程ID是以十六进制展示的。
第二步使用命令 jstack p i d ∣ g r e p “ 线 程 i d ” 把 信 息 打 印 出 来 : < / p > < p r e c l a s s = " p r e t t y p r i n t " s t y l e = " w h i t e − s p a c e : n o w r a p ; w o r d − w r a p : b r e a k − w o r d ; b o x − s i z i n g : b o r d e r − b o x ; p o s i t i o n : r e l a t i v e ; o v e r f l o w − y : h i d d e n ; o v e r f l o w − x : a u t o ; m a r g i n − t o p : 0 p x ; m a r g i n − b o t t o m : 24 p x ; f o n t − f a m i l y : C o n s o l a s , I n c o n s o l a t a , C o u r i e r , m o n o s p a c e ; p a d d i n g : 8 p x 16 p x 4 p x 56 p x ; f o n t − s i z e : 14 p x ; l i n e − h e i g h t : 22 p x ; w o r d − b r e a k : b r e a k − a l l ; b a c k g r o u n d − c o l o r : r g b ( 246 , 248 , 250 ) ; b o r d e r : n o n e ; b o r d e r − r a d i u s : 0 p x ; " > pid | grep “线程id” 把信息打印出来:</p><pre class="prettyprint" style="white-space: nowrap; word-wrap: break-word; box-sizing: border-box; position: relative; overflow-y: hidden; overflow-x: auto; margin-top: 0px; margin-bottom: 24px; font-family: Consolas, Inconsolata, Courier, monospace; padding: 8px 16px 4px 56px; font-size: 14px; line-height: 22px; word-break: break-all; background-color: rgb(246, 248, 250); border: none; border-radius: 0px;"> pid∣grep“线程id”把信息打印出来:</p><preclass="prettyprint"style="white−space:nowrap;word−wrap:break−word;box−sizing:border−box;position:relative;overflow−y:hidden;overflow−x:auto;margin−top:0px;margin−bottom:24px;font−family:Consolas,Inconsolata,Courier,monospace;padding:8px16px4px56px;font−size:14px;line−height:22px;word−break:break−all;background−color:rgb(246,248,250);border:none;border−radius:0px;"> jstack 9702 | grep ‘2717’ -A 30"http-nio-9092-exec-1" daemon prio=10 tid=0x00007f3a90014800 nid=0x2717 runnable [0x00007f3afc72a000]\r\n java.lang.Thread.State: RUNNABLE at com.bb.apigateway.filter.pre.SignatureTokenFilter.run(SignatureTokenFilter.java:44) at com.netflix.zuul.ZuulFilter.runFilter(ZuulFilter.java:112) at com.netflix.zuul.FilterProcessor.processZuulFilter(FilterProcessor.java:197) at com.netflix.zuul.FilterProcessor.runFilters(FilterProcessor.java:161) at com.netflix.zuul.FilterProcessor.preRoute(FilterProcessor.java:136) at com.netflix.zuul.ZuulRunner.preRoute(ZuulRunner.java:105) at com.netflix.zuul.http.ZuulServlet.preRoute(ZuulServlet.java:125) at com.netflix.zuul.http.ZuulServlet.service(ZuulServlet.java:74) at org.springframework.web.servlet.mvc.ServletWrappingController.handleRequestInternal(ServletWrappingController.java:158) at org.springframework.cloud.netflix.zuul.web.ZuulController.handleRequestInternal(ZuulController.java:43) at org.springframework.web.servlet.mvc.AbstractController.handleRequest(AbstractController.java:147) at org.springframework.web.servlet.mvc.SimpleControllerHandlerAdapter.handle(SimpleControllerHandlerAdapter.java:50) at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:961) at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:895) at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:967) at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:869) at javax.servlet.http.HttpServlet.service(HttpServlet.java:648) at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:843) at javax.servlet.http.HttpServlet.service(HttpServlet.java:729) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:292) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:207) at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:52) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:240) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:207) at org.springframework.boot.actuate.autoconfigure.EndpointWebMvcAutoConfiguration$ApplicationContextHeaderFilter.doFilterInternal(EndpointWebMvcAutoConfiguration.java:261) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:240) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:207) at org.springframework.boot.actuate.trace.WebRequestTraceFilter.doFilterInternal(WebRequestTraceFilter.java:115)1234567891011121314151617181920212223242526272829303132
下面这行就是出问题的业务代码,根据实际情况修复BUG即可
com.bb.apigateway.filter.pre.SignatureTokenFilter.run(SignatureTokenFilter.java:44)
4. 小结
思路:
找出CPU占用率高的进程
找出问题进程内CPU占用率高的线程
通过线程栈信息找出该线程当时在运行的问题代码段
实施要点:
top -Hbp ‘pid’ 定位问题线程
jstack ‘pid’ | grep ‘thread_id’ 找出问题代码
INSERT INTO
article (
id,
title,
keywords,
desci,
pic,
content,
click,
time,
catalog_id) VALUES
(100, ‘12 条用于 Linux 的 MySQL/MariaDB 安全最佳实践’, ‘’, ‘MySQL 是世界上最流行的开源数据库系统,MariaDB(一个 MySQL 分支)是世界上增长最快的开源数据库系统。在安装 MySQL 服务器之后,在默认配置下是不安全的,确保数据库安全通常是通用数据库管理的基本任务之一。\r\n\r\n这将有助于增’, NULL, ‘

MySQL 是世界上最流行的开源数据库系统,MariaDB(一个 MySQL 分支)是世界上增长最快的开源数据库系统。在安装 MySQL 服务器之后,在默认配置下是不安全的,确保数据库安全通常是通用数据库管理的基本任务之一。
这将有助于增强和提升整个 Linux 服务器的安全性,因为攻击者总是扫描系统任意部分的漏洞,而数据库在过去是重点目标区域。一个常见的例子是对 MySQL 数据库的 root 密码的强制破解。
在本指南中,我们将会讲解对开发者有帮助的 MySQL/MariaDB 的 Linux 最佳安全实践。
1. 安全地安装 MySQL
这是安装 MySQL 服务器后第一个建议的步骤,用于保护数据库服务器。这个脚本可以帮助您提高 MySQL 服务器的安全性:
如果您在安装期间没有设置 root 帐户的密码,马上设置它
通过删除可从本地主机外部访问的 root 帐户来禁用远程 root 用户登录
删除匿名用户帐户和测试数据库,默认情况下,所有用户、甚至匿名用户都可以访问这些帐户和测试数据库
# mysql_secure_installation
在运行上述命令之后,设置 root 密码并通过输入 [Yes/Y] 和按下 [Enter] 键来回答一系列问题。

安全安装 MySQL 情况界面
2. 将数据库服务器绑定到 Loopback 地址
此配置将限制来自远程机器的访问,它告诉 MySQL 服务器只接受来自本地主机的连接。你可以在主配置文件中进行设置。
# vi /etc/my.cnf [RHEL/CentOS]# vi /etc/mysql/my.conf [Debian/Ubuntu]OR# vi /etc/mysql/mysql.conf.d/mysqld.cnf [Debian/Ubuntu]
在 [mysqld] 部分中添加下面这一行
bind-address = 127.0.0.1
3. 禁用 MySQL 的 LOCAL INFILE
作为安全性增强的一部分,您需要禁用 local_infile,使用下面的指令以防止在 [mysqld] 部分从 MySQL 中访问底层文件系统。
local-infile=0
4. 修改 MySQL 的默认端口
设置端口变量用于监听 TCP/IP 连接的 MySQL 端口号。默认端口号是 3306,但是您可以在 *[mysqld] *中修改它。
Port=5000
5、启用 MySQL 日志
日志是了解服务运行过程中发生了什么的最好的方法之一,在受到任何攻击的时候都可以很容易的从日志里看到任何入侵相关的行为。可以通过将下边的变量添加到配置文件[mysqld]部分来开启mysql日志功能。
log=/var/log/mysql.log
6、设置合适的 MySQL 文件的访问权限
确保你已经为所有的 mysql 服务文件和数据路径设置了合适的访问权限。文件 /etc/my.conf 只能由 root 用户修改,这样就可以阻止其他用户修改数据库服务的配置。
# chmod 644 /etc/my.cnf
7、删除 MySQL shell 历史
你在 MySQL shell 中执行的所有的命令都会被 mysql 客户端保存到一个历史文件:~/.mysql_history。这样是很危险的,因为对于你创建过的任何用户账户,所有的在 shell 输入过的用户名和密码都会记录到历史文件里面。
# cat /dev/null > ~/.mysql_history
(101, ‘MySQL数据库视图:视图定义、创建视图、修改视图’, ‘’, ‘MySQL数据库视图:视图定义、创建视图、修改视图MySQL数据库视图:视图定义、创建视图、修改视图’, NULL, ‘
视图是指计算机数据库中的视图,是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。——百度百科
关系型数据库中的数据是由一张一张的二维关系表所组成,简单的单表查询只需要遍历一个表,而复杂的多表查询需要将多个表连接起来进行查询任务。对于复杂的查询事件,每次查询都需要编写MySQL代码效率低下。为了解决这个问题,数据库提供了视图(view)功能。
0 视图相关的MySQL指令
| 操作指令 | 代码 |
|---|---|
| 创建视图 | CREATE VIEW 视图名(列1,列2…) AS SELECT (列1,列2…) FROM …; |
| 使用视图 | 当成表使用就好 |
| 修改视图 | CREATE OR REPLACE VIEW 视图名 AS SELECT […] FROM […]; |
| 查看数据库已有视图 | >SHOW TABLES [like…];(可以使用模糊查找) |
| 查看视图详情 | DESC 视图名或者SHOW FIELDS FROM 视图名 |
| 视图条件限制 | [WITH CHECK OPTION] |
1 视图
百度百科定义了什么是视图,但是对缺乏相关知识的人可能还是难以理解或者只有一个比较抽象的概念,笔者举个例子来解释下什么是视图。
朕想要了解皇宫的国库的相关情况,想知道酒窖有什么酒,剩多少,窖藏多少年,于是派最信任的高公公去清点,高公公去国库清点后报给了朕;朕又想知道藏书情况,于是又派高公公去清点并回来报告给朕,又想知道金银珠宝如何,又派高公公清点。。。过一段时间又想知道藏书情况,高公公还得重新再去清点,皇上问一次,高公公就得跑一次路。
后来皇上觉得高公公不容易,就成立了国库管理部门,小邓子负责酒窖,小卓子负责藏书,而小六子负责金库的清点。。。后来皇上每次想了解国库就直接问话负责人,负责人就按照职责要求进行汇报。
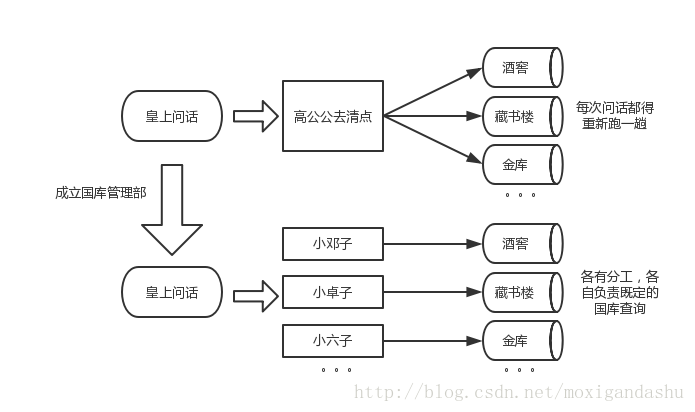
安排专人管理后,每次皇上想要了解国库情况,就不必让高公公每次都跑一趟,而是指定的人员按照指定的任务完成指定的汇报工作就可以了。
和数据库相对应,每次进行查询工作,都需要编写查询代码进行查询
’, 4, ‘2018-02-27 09:34:51’, 0),(102, ‘Mysql ——基础篇’, ‘’, ‘Mysql ——基础篇Mysql ——基础篇’, NULL, ‘
![[嘻嘻]](/image/aHR0cDovL2ltZy50LnNpbmFqcy5jbi90NC9hcHBzdHlsZS9leHByZXNzaW9uL2V4dC9ub3JtYWwvMGIvdG9vdGhhX29yZy5naWY%3D)
mysql 核心技术手册 第二版
阅读此博文假设你具备一些mysql基础知识,或者是已阅读过上一篇博文:mysql的安装与配置-(快速入门)
创建数据库和表
- 为一个虚拟的书店建立一个数据库
CREATE DATABASE bookstore;
- 1
!通过上述语句就创建了一个 bookstore 的数据库。
Mysql 语句对保留字的大小写并不敏感,对数据库与表名的大小写是否敏感取决于系统。最好以保留字大写,表名等小写的形式进行书写。
- 切换数据库,查看当前数据库
USE bookstore;\r\nSELECT DATABASE();
- 1
- 2
- 创建一个存放图书基本信息的数据表
CREATE TABLE books(\r\nbook_id INT,\r\ntitle VARCHAR (50),\r\nauthor vARCHAR (50)\r\n)
- 1
- 2
- 3
- 4
- 5
- 查看表结构
对于接触一个表来说,这个命令可以让你更好
(103, ‘spring data jpa 查询自定义字段,转换为自定义实体’, ‘’, ‘目标:查询数据库中的字段,然后转换成 JSON 格式的数据,返回前台。’, NULL, ‘
环境:idea 2016.3.4, jdk 1.8, mysql 5.6, spring-boot 1.5.2
背景:首先建立 entity 映射数据库(非专业 java 不知道这怎么说)
@Entity\r\n@Table(name = “user”)\r\npublic class User {\r\n @Id\r\n @GeneratedValue(strategy = GenerationType.AUTO)\r\n private Long id;\r\n private String userName; // 账号\r\n private String password; // 密码\r\n // getter setter 方法略过\r\n}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
然后建立与之对应的 model
public class UserModel implements Serializable {\r\n // 一些属性\r\n}
- 1
- 2
- 3
这里我们分情况讨论
首先第一种情况:查询的字段与表中的字段全部对应(就是查表里所有的字段,但是使用 Model 作为接收对象)
这种情况比较简单,调用 Repository 提供的方法,返回一个 entity , 然后将 entity 的属性复制到 model 中。像这样
UserModel user = new UserModel();\r\nUser userEntity = new User();\r\n// 一个工具类,具体使用方法请百度\r\nBeanUtils.copyProperties(user, userEntity);
- 1
- 2
- 3
- 4
第二种情况:只查询指定的几个字段
现在我有张表,有字段如下:
@Entity\r\n@Table(name = “user_info”)\r\npublic class UserInfo {\r\n @Id\r\n @GeneratedValue(strategy = GenerationType.AUTO)\r\n private Long id;\r\n private String name = “用户”; // 昵称\r\n private String signature; // 个性签名\r\n private String gender = “未知”; // 性别\r\n private String description; // 个人说明\r\n private String avatar; // 头像\r\n private Long role; // 权限\r\n private Boolean disable; // 是否冻结\r\n private Date createTime; // 创建时间\r\n private Boolean isDelete; // 是否删除\r\n private Long userId; // 用户 Id\r\n // …\r\n}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
但是我只需要查询指定的几个字段,然后转换成 JSON,返回给前台,咋办呢?
第一种方法:使用 model 查询时转化
首先建立一个 model ,写上自己想要查询的字段,然后写上构造函数,这步很重要,因为spring jpa 转化时会调用这个构造方法
public class MyModel implements Serializable {\r\n\r\n private String userName;\r\n private String name;\r\n private String gender;\r\n private String description;\r\n\r\n public MyModel() {};\r\n\r\n public MyModel(String userName, String name, String gender, String description) {\r\n this.userName = userName;\r\n this.name = name;\r\n this.gender = gender;\r\n this.description = description;\r\n }\r\n}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
然后在 dao 类中写查询方法
@Query(value = “select new pers.zhuch.model.MyModel(u.userName, ui.name, ui.gender, ui.description) from UserInfo ui, User u where u.id = ui.userId”)\r\npublic List<MyModel> getAllRecord();
- 1
- 2
直接在查询语句中 new model 框架底层会调用它,然后返回这个对象(这里我写了完整的类路径,不写的时候它报错说找不到类型什么的)
然后就可以获得只有指定字段的 model 了。然后就把它转成 JSON 格式就 O 了。
第二种方法:在service 里边转换成 JSON
原理其实和第一种方法差不多,只是处理结果的方式不太一样,只是这种方法我们就不在 hql 中 new Model 了,直接写查询方法
@Query(value = “select new map(u.userName, ui.name, ui.gender, ui.description) from UserInfo ui, User u where u.id = ui.userId”)\r\npublic List<Map<String, Object>> getCustomField();
- 1
- 2
直接new map(这里得是小写,不知道大写有木有问题,反正没试,编译器提示是要小写的)
然后返回的结果是这样的
[\r\n {\r\n “0”: “admin”, \r\n “1”: “你猜”, \r\n “2”: “男”, \r\n “3”: “一段描述”\r\n }, {\r\n “0”: “abc”, \r\n “1”: “你猜人家”, \r\n “2”: “女”, \r\n “3”: “没事先挂了”\r\n }\r\n]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
然后在 service 层里直接封装成 JSON 对象,返回
List<JsonObject> list = new ArrayList();\r\nfor(Map map : result) {\r\n JsonObject j = new JsonObject();\r\n j.addProperty(attrName, val);\r\n …\r\n list.add(j);\r\n}\r\ngson.toJson(list);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
还有一种返回结果,这样写:
@Query(value = “select u.userName, ui.name, ui.gender, ui.description from UserInfo ui, User u where u.id = ui.userId”)\r\npublic List<Object> getCustomField();
- 1
- 2
返回结果是这样的格式:
[\r\n [\r\n “admin”, \r\n “你猜”, \r\n “男”, \r\n “一段描述”\r\n ], [\r\n “abc”, \r\n “你猜人家”, \r\n “女”, \r\n “没事先挂了”\r\n ]\r\n]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
返回的是数组,也一样可以通过上面的方法转成 json ,这里我的程序中出现了一点点 BUG,就是空值的字段不会在数组中,不知道为什么。
这种方法必须明确的知道查询了哪些字段,灵活性比较差,虽然它解决了手头的问题。还有就是版本的不同,有可能会出现丢失空字段的情况,我个人特别的不喜欢这样的方法,万一我实体几十个字段,写着写着忘了写到哪了,就 over 了
第三种方法:返回一个便于转换成 json 格式的 list
其实和上面很相似,都是 dao 层返回一个 List < Map < String, Object >>,但是上面的结果集返回的 Map 的 key 只是列的下标,这种方式稍微理想一点点,就是 Map 的 key 就是查询的列名。但是这种方式需要实现自定义 Repository( 这里不详细介绍,请自行百度 ),并且只是 jpa 集成 hibenate 的时候可以使用。
public List getCustomEntity() {\r\n String sql = “select t.id, t.name, t.gender, t.is_delete, t.create_time, t.description from t_entity t”;\r\n Query query = em.createNativeQuery(sql);\r\n // Query 接口是 spring-data-jpa 的接口,而 SQLQuery 接口是 hibenate 的接口,这里的做法就是先转成 hibenate 的查询接口对象,然后设置结果转换器\r\n query.unwrap(SQLQuery.class).setResultTransformer(Transformers.ALIAS_TO_ENTITY_MAP);\r\n return query.getResultList();\r\n}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这种方法返回的就是比较标准的 JSON 格式的 java 对象了,只需要用 jackson 或者 Gson 转一下就是标准的 json 了
[\r\n {\r\n attr: val,\r\n …\r\n },\r\n {\r\n attr: val,\r\n …\r\n },\r\n]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这种方式其实已经比较理想了,因为直接就能返回到前台,但是有时候,结果不是一条 sql 能够解决的,得两条或者以上的 sql 来解决一个复杂的查询需求,这个过程中,结果比较需要转换成 pojo,以便于组装操作。
第四种方案:dao 中直接转成 pojo 返回
这个方案还是依赖于 hibenate,有点操蛋,但是更明确一些。
public List getCustomEntity() {\r\n String sql = “select t.id, t.name, t.gender, t.is_delete as isEnable, t.create_time as createTime, t.description from t_entity t”;\r\n Query query = em.createNativeQuery(sql);\r\n query.unwrap(SQLQuery.class)\r\n // 这里是设置字段的数据类型,有几点注意,首先这里的字段名要和目标实体的字段名相同,然后 sql 语句中的名称(别名)得与实体的相同\r\n .addScalar(“id”, StandardBasicTypes.LONG)\r\n .addScalar(“name”, StandardBasicTypes.STRING)\r\n .addScalar(“gender”, StandardBasicTypes.STRING)\r\n .addScalar(“isEnable”, StandardBasicTypes.BOOLEAN)\r\n .addScalar(“createTime”, StandardBasicTypes.STRING)\r\n .addScalar(“description”, StandardBasicTypes.STRING)\r\n .setResultTransformer(Transformers.aliasToBean(EntityModel.class));\r\n return query.getResultList();\r\n}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这次返回的就是 List 了。这里要注意的是 StandardBasicTypes这个常量类,在一些旧版本中,是 Hibenate 类,具体哪个包我不知道,我这个版本中是换成了前面的那个常量类
’, 11, ‘2018-02-27 09:41:53’, 0);INSERT INTO
article (
id,
title,
keywords,
desci,
pic,
content,
click,
time,
catalog_id) VALUES
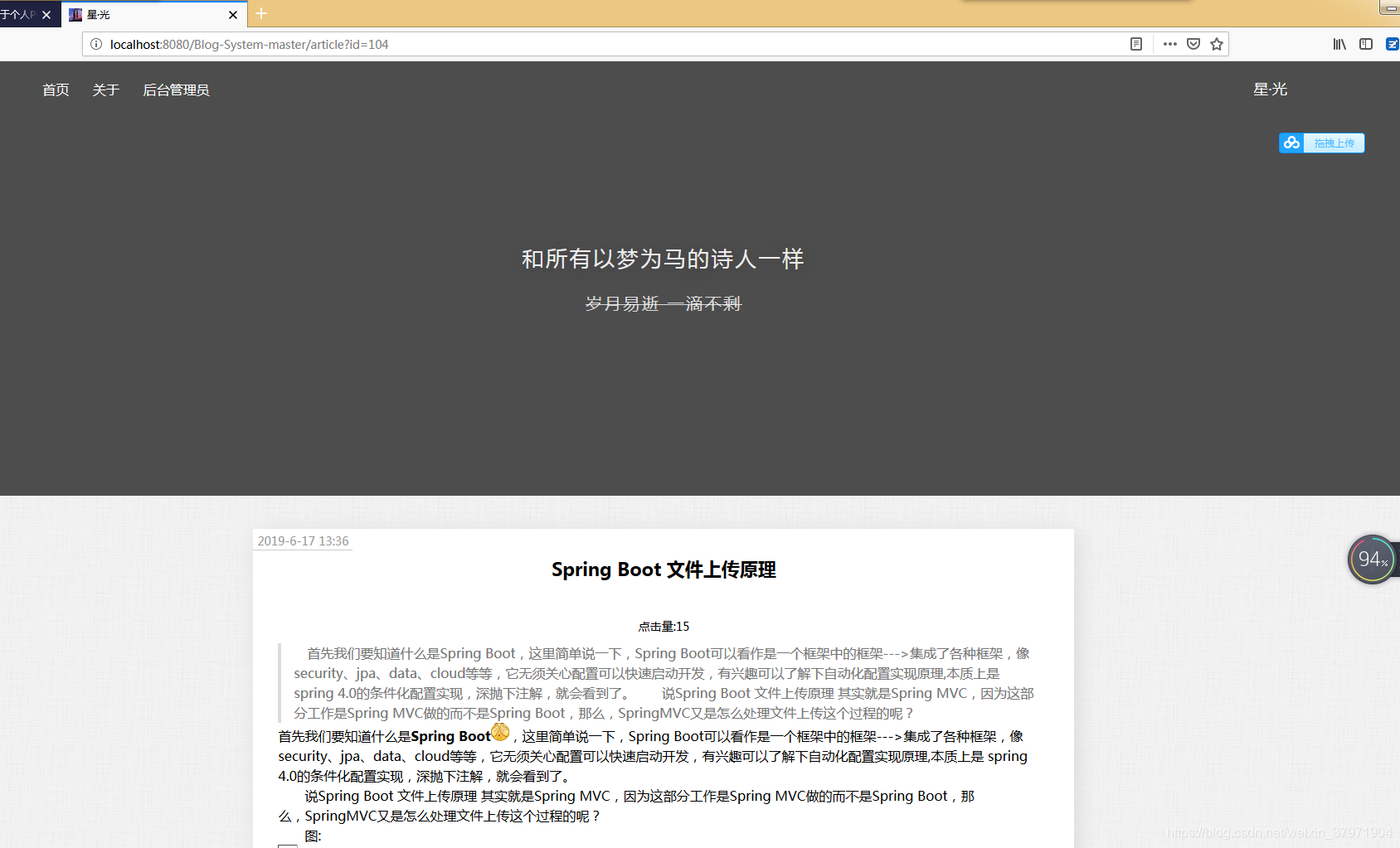
(104, ‘Spring Boot 文件上传原理’, ‘Spring Boot’, ’ 首先我们要知道什么是Spring Boot,这里简单说一下,Spring Boot可以看作是一个框架中的框架—>集成了各种框架,像security、jpa、data、cloud等等,它无须关心配置可以快速启动开发,有兴趣可以了解下自动化配置实现原理,本质上是 spring 4.0的条件化配置实现,深抛下注解,就会看到了。\r\n\r\n 说Spring Boot 文件上传原理 其实就是Spring MVC,因为这部分工作是Spring MVC做的而不是Spring Boot,那么,SpringMVC又是怎么处理文件上传这个过程的呢?’, NULL, ‘
首先我们要知道什么是Spring Boot![[污]](/image/aHR0cDovL2ltZy50LnNpbmFqcy5jbi90NC9hcHBzdHlsZS9leHByZXNzaW9uL2V4dC9ub3JtYWwvM2MvcGNtb3Jlbl93dV9vcmcucG5n)
说Spring Boot 文件上传原理 其实就是Spring MVC,因为这部分工作是Spring MVC做的而不是Spring Boot,那么,SpringMVC又是怎么处理文件上传这个过程的呢?
图:
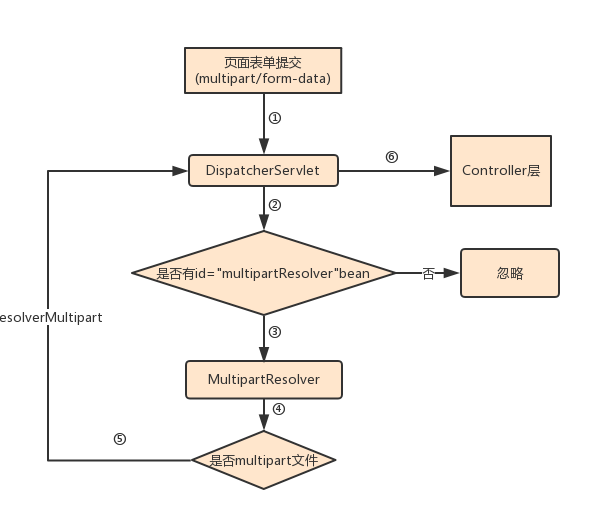
首先项目启动加载相关配置,再执行上述第二步的时候 DispatcherServlet会去查找id为multipartResolver的Bean,在配置中看到Bean指向的是CommonsMultipartResolve,其中实现了MultipartResolver接口。
第四步骤这里会判断是否multipart文件即isMultipart方法,返回true:就会调用 multipartResolver 方法,传递HttpServletRequest会返回一个MultipartHttpServletRequest对象,再由DispatcherServlet进行处理到Controller层;返回false:会忽略掉,继续传递HttpServletRequest。
在MVC中需要在配置文件webApplicationContext.xml中配置 如下:
<bean id=“multipartResolver” class=“org.springframework.web.multipart.commons.CommonsMultipartResolver”>\r\n <property name=“defaultEncoding” value=“UTF-8”/>\r\n <property name=“maxUploadSize” value=“100000000”/>\r\n <property name=“uploadTempDir” value=“fileUpload/temp”/>\r\n </bean>
而Spring Boot已经自动配置好,直接用就行,做个test没什么问题,有默认的上传限制大小(maxFileSize = “1MB”,maxRequestSize = “10MB”,fileSizeThreshold = “0”),不过在实际开发中我们还是要做一些配置的,
如下在application.properties中:
# multipart config
#默认支持文件上传\r\nspring.http.multipart.enabled=true
#文件上传目录\r\nspring.http.multipart.location=/tmp/file/images/
#将文件写入磁盘的阈值\r\nspring.http.multipart.file-size-threshold=5MB
#最大支持请求大小\r\nspring.http.multipart.max-request-size=20MB
当然也可以写配置类来实现,具体的就不做展示了。
看完上述你肯定有个大概的了解了,这里再啰嗦下,Spring提供Multipart的解析器:MultipartResolver,上述说的是CommonsMultipartResolver,它是基于Commons File Upload第三方来实现,这也是在Servlet3.0之前的东西,3.0+之后也可以不需要依赖第三方库,可以用StandardServletMultipartResolver,同样也是实现了MultipartResolver接口,我们可以看下它的实现源码(上有注释,不再进行解析了):
这里是之前写的test后者实现配置类,可以简单看下,作为了解:
–
– 表的结构 catalog
CREATE TABLE IF NOT EXISTS catalog (
id mediumint(9) NOT NULL AUTO_INCREMENT,
name varchar(30) NOT NULL COMMENT ‘栏目名称’,
keywords varchar(150) NOT NULL COMMENT ‘栏目关键词’,
desc text NOT NULL COMMENT ‘栏目描述’,
type tinyint(1) NOT NULL DEFAULT ‘0’ COMMENT ‘栏目类型 0:列表;1:留言’,
PRIMARY KEY (id)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=5 ;
源码下载:http://www.bycxy123.com/
视频演示:https://www.bilibili.com/video/BV1r7411h7wP/