4 METHODOLOGY
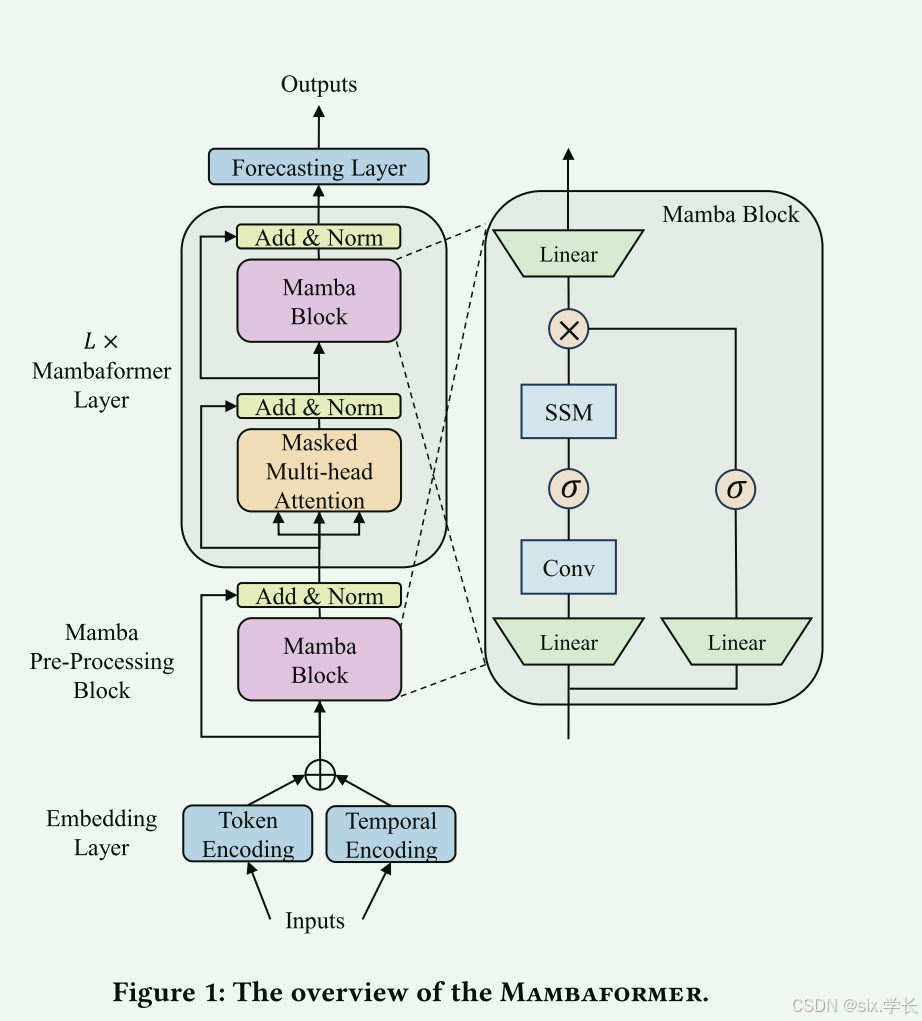
图解
Mambaformer模型结合了Mamba和Transformer的元素,旨在进行时间序列预测。以下是Mambaformer模型的各个组成部分和流程的详细说明:
嵌入层(Embedding Layer)
- Token Encoding(令牌编码): 这个部分将输入数据编码成向量表示,以捕捉输入特征的语义含义或特征。
- Temporal Encoding(时间编码): 这部分加入时间信息,例如Transformer中的位置编码,帮助模型理解序列的顺序和时间依赖关系。
Mamba预处理块(Mamba Pre-Processing Block)
这个块包含Mamba块,用于处理编码后的输入。输出经过加法和归一化层,以稳定和标准化数据,为下一个阶段做准备。
Mambaformer层(Mambaformer Layer)
- 掩码多头注意力(Masked Multi-Head Attention): 这一机制允许模型关注输入序列的不同部分,通过关注不同位置来考虑输入和其时间上下文。"掩码"部分通常意味着模型在给定预测时只考虑之前的时间步,以防止未来时间步的信息泄露。
- Mamba块(Mamba Block): 这个块包含Mamba模型的关键组件:
- 状态空间模型(SSM): 捕捉序列数据的结构和时间上的依赖关系。
- 卷积层(Conv): 处理状态表示,可能捕捉数据中的局部依赖和模式。
- 线性层和激活函数(σ): 调整数据的维度,并对数据进行非线性转换。
每个Mamba块输出其处理后的信息,这些信息经过另一个加法和归一化步骤,以确保数据在网络层之间的稳定传递。
预测层(Forecasting Layer)
从叠加的Mambaformer层输出的数据传递到预测层,在此进行实际的预测。该层可能包括附加的转换和最终输出函数,根据处理后的序列信息提供预测值。
总结
Mambaformer模型通过结合Mamba块和多头注意力机制,利用状态空间建模和注意力机制捕捉时间序列数据中的长短期依赖关系。这种架构允许高效处理和预测,融合了Mamba和Transformer模型的优势。
4.1 Overview of Mambaformer
4.1 Mambaformer概述
受混合架构在语言建模中优势的启发【23】,我们提出利用Mambaformer来整合Mamba和Transformer,以捕捉时间序列数据中的长短期依赖,从而提升性能。Mambaformer采用类似GPT系列【5, 25, 26】的仅解码器(decoder-only)架构。
Mambaformer的关键特点:
-
混合架构优势: Mambaformer结合了Mamba和Transformer的优势。Mamba模型擅长处理长时间序列数据中的依赖关系,而Transformer尤其在捕捉复杂的上下文关系上表现出色。通过整合这两者,Mambaformer能够更好地建模长短期依赖关系。
-
仅解码器结构: 类似于GPT系列,Mambaformer使用仅解码器的结构。这种结构专注于生成输出,而不需要完整的编码器-解码器对。这种设计使得Mambaformer在处理生成任务和序列预测任务时更加高效,减少了计算复杂度。
-
增强的性能: 通过结合Mamba的状态空间模型能力和Transformer的自注意力机制,Mambaformer能够处理更广泛的依赖范围,从而在时间序列预测任务中表现出更好的性能。这种混合模型能够在捕捉数据的全局和局部特征时提供更精确的预测。
总结
Mambaformer模型的设计灵感来自语言建模中的混合架构,其采用的仅解码器结构使得它在生成和预测任务中非常有效。通过整合Mamba和Transformer的优势,Mambaformer能够在时间序列数据中捕捉复杂的长短期依赖关系,从而提高预测的精度和效果。
4.2 Embedding Layer
4.2 嵌入层(Embedding Layer)
我们使用嵌入层将低维时间序列数据映射到高维空间中,这包括令牌嵌入(token embedding)和时间嵌入(temporal embedding)。
令牌嵌入(Token Embedding)
为了将原始时间序列数据转换为高维的令牌,我们使用一维卷积层作为令牌嵌入模块。因为一维卷积层能够保留时间序列数据中的局部语义信息【7】。这种方法确保模型能够捕捉到数据中的局部特征和模式,有助于后续的序列建模。
时间嵌入(Temporal Embedding)
除了序列中的数值信息外,时间上下文信息也提供了有用的线索,例如层级时间戳(如周、月、年)和不依赖于具体日期的时间标记(如节假日和事件)【41】。我们使用线性层来嵌入这些时间上下文信息。这些信息有助于模型理解数据中潜在的时间模式和事件影响。
嵌入层的公式表示
令 X ∈ R B × L × M X \in \mathbb{R}^{B \times L \times M} X∈RB×L×M表示输入序列,其中 B B B为批大小, L L L为序列长度, M M M为特征维度。令 C ∈ R B × L × C C \in \mathbb{R}^{B \times L \times C} C∈RB×L×C表示关联的时间上下文。嵌入层的输出可以表示为:
E = E t o k e n ( X ) + E t e m ( C ) E = E_{token}(X) + E_{tem}(C) E=Etoken(X)+Etem(C)
其中, E ∈ R B × L × D E \in \mathbb{R}^{B \times L \times D} E∈RB×L×D是输出嵌入, D D D为嵌入维度, E t o k e n E_{token} Etoken和 E t e m E_{tem} Etem分别表示令牌嵌入层和时间嵌入层。
注意点
我们不需要像Transformer模型中通常存在的位置嵌入。这是因为Mamba预处理块(将在下一小节介绍)内置了位置信息的嵌入处理。这种设计使得模型能够在处理嵌入时自动考虑到数据中的位置信息,简化了架构的复杂性,同时保持对序列位置的敏感性。
4.3 Mamba Pre-Processing Layer
4.3 Mamba预处理层
为了为嵌入层提供位置信息,我们通过一个Mamba块对序列进行预处理,在内部嵌入输入令牌的顺序信息。Mamba可以被视为一种RNN,其中当前时间 t t t的隐藏状态 h t h_t ht由前一时间 t − 1 t - 1 t−1的隐藏状态 h t − 1 h_{t-1} ht−1更新,如公式2所示。这种处理令牌的递归机制使得Mamba能够自然地考虑序列的顺序信息。因此,与Transformer中位置编码作为一个必要组件不同,Mambaformer通过一个Mamba预处理块取代了位置编码。
Mamba预处理块的表达式为:
H 1 = M a m b a ( E ) H1 = Mamba(E) H1=Mamba(E)
其中, H 1 ∈ R B × L × D H1 \in \mathbb{R}^{B \times L \times D} H1∈RB×L×D是一个包含令牌嵌入、时间嵌入和位置信息的混合向量。这里的 E E E是嵌入层的输出,包含了从输入数据和时间上下文信息中提取的特征。通过Mamba预处理块,模型可以自动整合这些特征并加入位置信息,从而为后续的预测和建模提供丰富的上下文信息。
这种设计使得Mambaformer能够在不需要显式位置编码的情况下,捕捉序列数据中的时间和位置信息。这不仅简化了模型的架构,还利用了Mamba的递归特性,有效地处理序列的顺序依赖。
4.4 Mambaformer Layer
Mambaformer模型的核心层交替使用Mamba层和自注意力层,结合Mamba和Transformer的优势,以便更好地进行长短期时间序列预测。
自注意力层(Attention Layer)
自注意力层用于保留Transformer在捕捉短期时间序列依赖方面的出色表现。我们使用掩码多头注意力层来获取令牌之间的相关性。具体而言,在注意力层中的每个头部(head) i = 1 , 2 , . . . , h i = 1, 2, ..., h i=1,2,...,h将嵌入的 H 1 H1 H1转换为查询 Q i = H 1 W Q i Q_i = H1W_{Q_i} Qi=H1WQi、键 K i = H 1 W K i K_i = H1W_{K_i} Ki=H1WKi和值 V i = H 1 W V i V_i = H1W_{V_i} Vi=H1WVi,其中 W Q i ∈ R D × d k W_{Q_i} \in \mathbb{R}^{D \times d_k} WQi∈RD×dk、 W K i ∈ R D × d k W_{K_i} \in \mathbb{R}^{D \times d_k} WKi∈RD×dk和 W V i ∈ R D × d v W_{V_i} \in \mathbb{R}^{D \times d_v} WVi∈RD×dv是可学习的矩阵。
随后,使用缩放点积注意力计算输出:
O i = A t t e n t i o n ( Q i , K i , V i ) = softmax ( Q i K i T d k ) V i O_i = Attention(Q_i, K_i, V_i) = \text{softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right)V_i Oi=Attention(Qi,Ki,Vi)=softmax(dkQiKiT)Vi
每个头部的输出 O i O_i Oi被连接成一个输出向量 O O O,其嵌入维度为 h d v hd_v hdv。然后通过一个可学习的投影矩阵 W O ∈ R h d v × D W_O \in \mathbb{R}^{hd_v \times D} WO∈Rhdv×D得到注意力层的输出 H 2 H2 H2:
H 2 = O W O ∈ R B × L × D H2 = OW_O \in \mathbb{R}^{B \times L \times D} H2=OWO∈RB×L×D
我们采用掩码机制来防止各位置关注到后续位置,设置 d k = d v = D / h d_k = d_v = D/h dk=dv=D/h,与标准Transformer的设置相同【31】。
Mamba层(Mamba Layer)
为了克服Transformer的计算挑战,并超越其性能,我们将Mamba层集成到模型中,以增强捕捉长距离时间序列依赖的能力。如图1所示,Mamba块是一个输入和输出维度相同的序列-序列模块。特别地,Mamba将输入 H 2 H2 H2通过两个线性投影进行维度扩展。对于一个投影,Mamba在将扩展后的嵌入输入到状态空间模型(SSM)之前,通过卷积和SiLU激活进行处理。
核心的离散化SSM模块能够选择与输入相关的知识并过滤掉不相关的信息。另一个投影经过SiLU激活作为残差连接,通过乘性门控与SSM模块的输出结合。最后,Mamba通过一个输出线性投影输出 H 3 H3 H3:
H 3 ∈ R B × L × D H3 \in \mathbb{R}^{B \times L \times D} H3∈RB×L×D
这种设计使得Mambaformer能够同时捕捉长短期依赖关系,结合了Transformer的自注意力机制和Mamba的状态空间建模能力,显著提高了时间序列预测的效果和效率。
4.5 Forecasting Layer
4.5 预测层(Forecasting Layer)
在这个层,我们通过线性层将高维嵌入空间转换为时间序列数据的原始维度,以获得预测结果。具体操作如下:
X ^ = Linear ( H 3 ) \hat{X} = \text{Linear}(H3) X^=Linear(H3)
其中, X ^ ∈ R B × L × M \hat{X} \in \mathbb{R}^{B \times L \times M} X^∈RB×L×M表示预测结果, B B B为批大小, L L L为序列长度, M M M为时间序列的特征维度。
这个线性层的作用是将经过Mamba和自注意力层处理后的高维嵌入 H 3 H3 H3转换回原始的时间序列数据维度,从而使得模型能够输出与输入数据格式一致的预测结果。这一步是非常关键的,因为它确保了模型的输出可以直接用于进一步的分析或应用中,如时间序列的趋势预测、异常检测等。