利用Boundary-aware Attention边界感知注意力机制增强部分伪造音频定位
论文标题:Enhancing Partially Spoofed Audio Localization with Boundary-aware Attention Mechanism
论文官方代码:https://github.com/media-sec-lab/BAM
Paperwithcode:Enhancing Partially Spoofed Audio Localization with Boundary-aware Attention Mechanism
摘要
部分伪造音频定位的任务旨在准确确定帧级别的音频真实性。尽管一些工作取得了令人鼓舞的成果,但在单个模型中利用有界信息仍然是一个未经探索的研究课题。在这项工作中,我们提出了一种称为边界感知注意力机制Boundary-aware Attention Mechanism的新方法。
核心模块
它由两个核心模块组成:边界增强Boundary Enhancement和边界逐帧注意
Boundary Frame-wise Attention。
- 边界增强Boundary Enhancement:将帧内和帧间信息组合在一起,提取可辨别的边界特征,随后用于边界位置检测和真实性决策,
- 边界逐帧注意Boundary Frame-wise Attention:利用边界预测结果明确控制帧之间的特征交互,实现了真实帧和假帧之间的有效区分
什么是边界?什么是边界特征?
-
“边界”(Boundary)指的是在音频信号中,真实语音和合成语音(或伪造语音)相接合的地方。这些边界区域通常包含混合了真实和伪造音频的帧,对于检测和定位伪造音频来说,识别这些边界位置是非常重要的。
-
“边界特征”(Boundary Features)是指能够表征音频中边界区域特性的一组特征。在BAM方法中,边界特征是通过特定的网络结构提取出来的,用于帮助模型区分和定位真实语音和合成语音之间的边界。
写作背景
在面对日益逼真的伪造语音威胁时,如何准确地检测和定位伪造语音片段,以保护语音验证系统不受欺骗攻击的影响。作者提出的边界感知注意力机制(BAM)旨在解决这一挑战,提高定位伪造语音的准确性和效率。
解决的问题
-
边界信息利用不足:
在现有的部分伪造音频检测(PSAD)研究中,边界信息通常被用于辅助在语句级别检测伪造音频,但如何将边界信息有效地整合到单个对抗性模型(Countermeasure, CM)中以提高帧级别的定位精度,是一个尚未被充分探索的研究课题。 -
区分性和定位精度不足:
边界帧(同时包含真实和伪造音频的帧)与完全真实帧在特征空间中非常接近,这可能导致训练不稳定和性能下降。 -
现有注意力机制的局限性:
传统的注意力机制可能没有针对部分伪造音频的特殊需求进行优化,特别是在需要区分帧的真实性时。
模型性能限制:
现有的方法可能没有达到最佳的定位性能,尤其是在精确度、召回率和F1分数等评估指标上。
时间颗粒度的挑战:
在更细粒度的时间颗粒度下,准确检测边界位置更具挑战性,这可能影响模型的整体性能。
方法
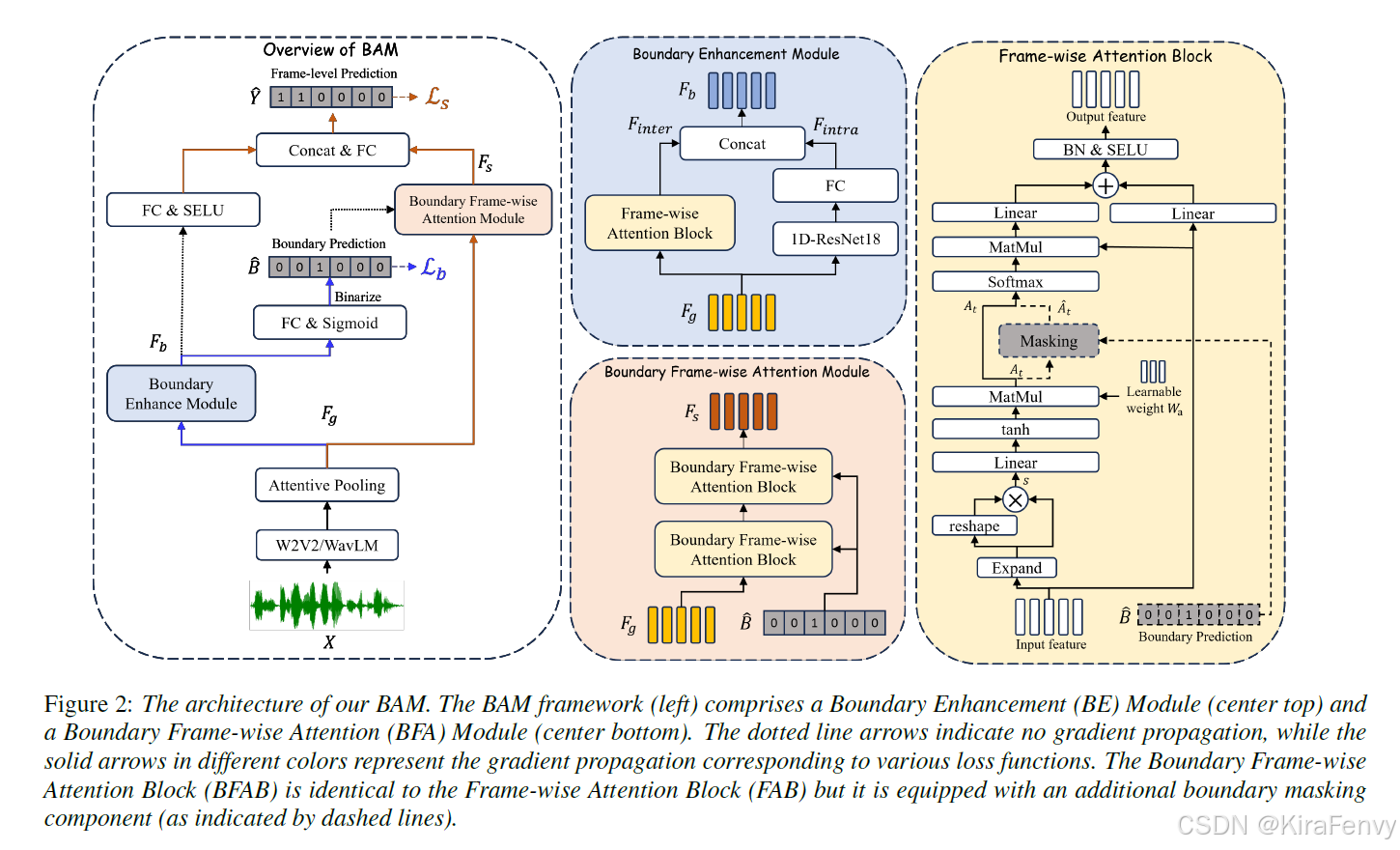
边界感知注意力机制(Boundary-aware Attention Mechanism, BAM)的具体工作流程如下:
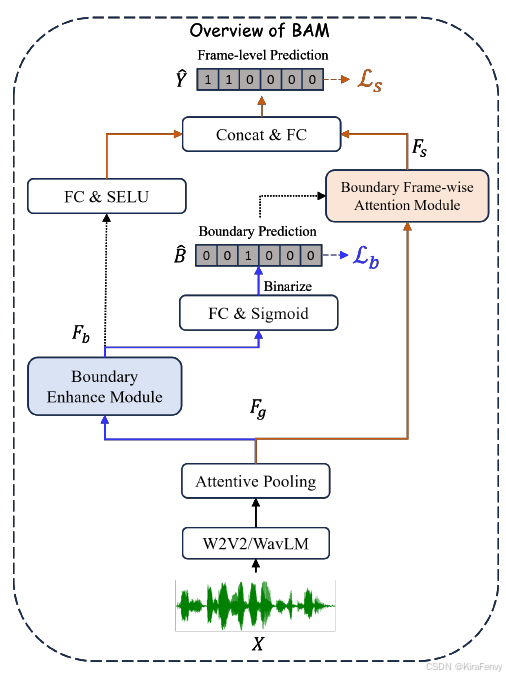
1. 特征提取
使用预训练好的自监督学习模型进行前端特征提取
使用预训练的自监督学习(SSL)模型,如Wav2vec2(W2V2)或WavLM,来提取语音的有效前端特征(Front-end Features是指在语音处理和识别系统中,用于表示输入语音信号的原始或经过初步处理的特征。这些特征是后续声学模型或识别算法的输入,用于捕捉和表征语音信号的关键信息)
这些特征比传统的手工制作特征(例如LFCC、MFCC)更能利用大量未标记数据进行预训练,显著提高数据表示能力,并有助于识别音频数据中的复杂模式。
Attentive pooling
Attentive pooling层将输入的不同长度的输入序列(从Wav2vec2或WavLM模型提取的特征),映射到一个固定的时间颗粒度(160毫秒)上
Attentive pooling通过学习每个帧或时间段的重要性,给予更重要的帧更高的权重,这有助于模型集中注意力于那些对于区分真实和伪造音频最有用的部分。
Q:为什么使用Attentive pooling而不是其他方式
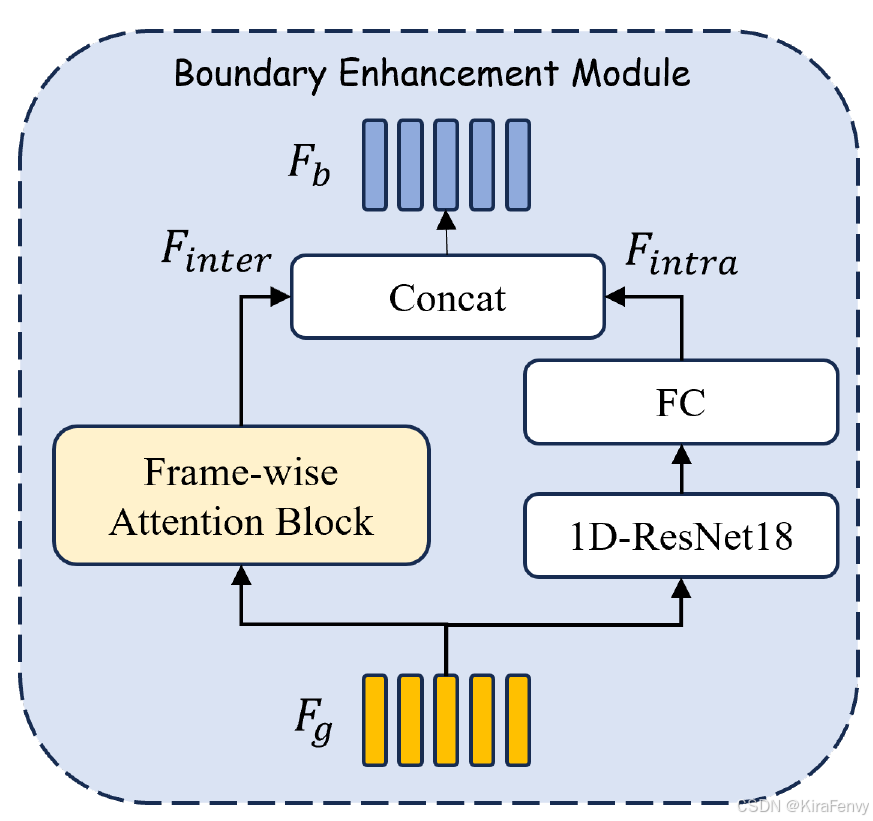
2. 边界增强(Boundary Enhancement, BE)模块
- 在PSAL的上下文中,边界处包含伪造和真实样本的帧被标记为伪造。在使用二进制真实性标签进行训练时,边界帧(尤其是那些具有较小比例欺骗数据的边界帧)在特征空间中接近完全真实的帧,即使它们具有相反的标签。这种情况可能会导致训练不稳定和性能下降。为了缓解这个问题,开发了一种边界增强模型,专门用于建模和区分边界帧和非边界帧。
- 设计了一个边界增强模块,包含两个分支,一个用于提取帧内特征,另一个用于提取帧间特征,以有效检测边界帧位置。
- 帧内特征(Intra-frame Features):
每个帧单独输入到一个1D-ResNet结构中,用于学习帧内特征。这些特征捕捉了单个帧内的语音信号模式。 - 帧间特征(Inter-frame Features):
使用帧间注意力块(Frame-wise Attention Block, FAB)来捕获帧与帧之间的相关性。FAB通过注意力机制计算每个帧特征与其他帧特征的加权和,从而得到更新的帧特征。 - 边界特征融合:
将帧内特征和帧间特征进行拼接,形成边界特征。这些边界特征既包含了单个帧的信息,也包含了帧与帧之间的上下文信息。
- 帧内特征(Intra-frame Features):
在论文中,边界增强(Boundary Enhancement, BE)模块的目标是将前端特征 F g ∈ R T × D F_g \in \mathbb{R}^{T \times D} Fg∈RT×D转换为边界特征 F b ∈ R T × 2 D F_b \in \mathbb{R}^{T \times 2D} Fb∈RT×2D,其中 T T T是帧数, D D D是特征维度。
帧间特征提取
A
t
=
tanh
(
ϕ
(
s
)
)
W
a
A_t = \tanh(\phi(s))W_a
At=tanh(ϕ(s))Wa
F
a
=
softmax
(
A
t
)
F
g
F_a = \text{softmax}(A_t)F_g
Fa=softmax(At)Fg
F
inter
=
SELU
(
BN
(
(
ϕ
(
F
a
)
⊕
ϕ
(
F
g
)
)
)
)
F_{\text{inter}} = \text{SELU}(\text{BN}((\phi(F_a) \oplus \phi(F_g))))
Finter=SELU(BN((ϕ(Fa)⊕ϕ(Fg))))
其中,
⊕
\oplus
⊕表示逐元素相加,
BN
\text{BN}
BN表示一维批量归一化,
SELU
\text{SELU}
SELU是激活函数,
ϕ
\phi
ϕ是线性映射函数,
W
a
W_a
Wa是可学习的注意力权重。
帧内特征提取
每个帧单独输入到一个1D-ResNet结构中,然后通过一个全连接层来学习帧内特征 F intra F_{\text{intra}} Fintra。
- 1D-ResNet结构:
每个帧被送入一个一维残差网络(1D-ResNet)。残差网络是一种深度学习架构,它通过引入跳跃连接(skip connections)来解决深度网络中的梯度消失问题,使得网络可以更深且更有效。
在1D-ResNet中,每个帧的特征通过多个卷积层和激活函数进行处理,以学习帧内的复杂模式和表示。 - 全连接层(Fully Connected layers, FC):
经过1D-ResNet处理后,每个帧的特征再通过一个全连接层,全连接层可以对1D-ResNet的输出进行加权和汇总,以生成更抽象的特征表示。
Q:为什么是1D-ResNet加上全连接层
边界特征拼接
F b = Concat ( F intra , F inter ) F_b = \text{Concat}(F_{\text{intra}}, F_{\text{inter}}) Fb=Concat(Fintra,Finter)
这里, F intra F_{\text{intra}} Fintra和 F inter F_{\text{inter}} Finter分别代表帧内特征和帧间特征,它们被拼接起来形成边界特征 F b F_b Fb。
通过这种方式,BE模块有效地结合了帧内和帧间信息,以提取有助于边界检测和真实性判断的区分性边界特征。这些特征随后被用于边界帧位置的检测和帧级真实性决策。
- 将前端特征 F g F_g Fg转换为边界特征 F b F_b Fb,其中 F g F_g Fg是池化层的输出特征, T T T是帧数, D D D是特征维度。
- 边界特征有两个用途:首先,它被送入一个带有sigmoid函数的全连接层以获得边界预测概率$\hat{b} );其次,边界特征通过一个带有激活函数的全连接层处理,并与最终的帧级真实性决策进行拼接。
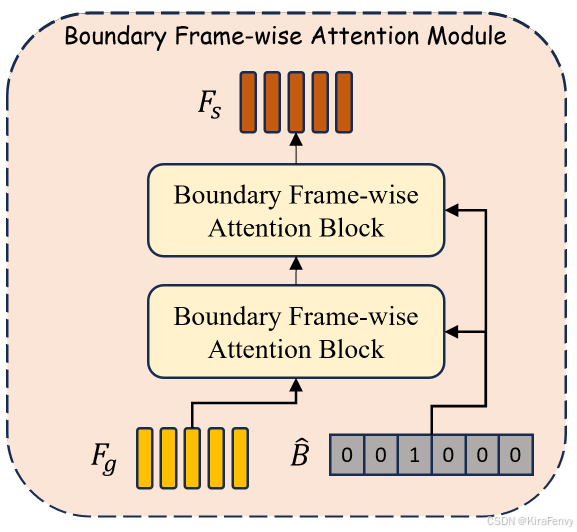
3.边界帧级注意力(Boundary Frame-wise Attention, BFA)模块
利用边界预测结果来控制帧间特征的交互,以实现对真实和伪造帧的有效区分。
该模块包含两个堆叠的边界帧级注意力块(BFAB)。BFAB的结构与FAB相似,但配备了一个边界掩码组件,该组件使用二进制边界预测 B ^ \hat{B} B^和 F g F_g Fg来削弱属于不同类别的帧之间的信息传递。具体来说:
-
构建边界邻接矩阵 A b A_b Ab:
其元素定义决定了第 i 帧和第 j 帧之间是否存在边界;如果存在,则 A b A_b Ab 中第 i 行和第 j 列的值设置为0,否则为1。
A b A_b Ab的元素定义如下:
A b ( i , j ) = { 1 if i = j ∑ n = i j − 1 ( 1 − B ^ [ n ] ) if i < j ∑ n = j i − 1 ( 1 − B ^ [ n ] ) if i > j A_{b(i,j)} = \begin{cases} 1 & \text{if } i = j \\ \sum_{n=i}^{j-1} (1 - \hat{B}[n]) & \text{if } i < j \\ \sum_{n=j}^{i-1} (1 - \hat{B}[n]) & \text{if } i > j \end{cases} Ab(i,j)=⎩ ⎨ ⎧1∑n=ij−1(1−B^[n])∑n=ji−1(1−B^[n])if i=jif i<jif i>j -
更新注意力图 ( A_t ) 为边界注意力图 ( \hat{A}_t ):
使用边界掩码更新注意力图 ( A_t ) 为边界注意力图 ( \hat{A}_t ),通过元素-wise乘法实现。
A ^ t = A t ⊙ A b \hat{A}_t=A_t\odot A_b A^t=At⊙Ab
4.损失函数
使用两个损失函数进行监督训练:边界损失 L b L_b Lb 和帧级真实性损失 L s L_s Ls。边界损失使用二元交叉熵损失,而真实性损失使用标准的交叉熵损失。总损失是这两个损失的加权和。
在本文中,损失函数用于监督模型的训练,包含两个部分:边界损失 L b L_b Lb 和帧级真实性损失 L s L_s Ls。这两个损失函数共同作用于模型,以优化边界检测和帧级真实性判断的性能。以下是损失函数的详细计算公式:
-
边界损失 L b L_b Lb:
- 边界损失使用二元交叉熵损失函数来计算。
- 它的目的是最小化模型对边界帧预测的概率与真实边界标签之间的差异。
- 边界损失的计算公式为:
L b = − ∑ i = 1 T B [ i ] log ( b ^ [ i ] ) + ( 1 − B [ i ] ) log ( 1 − b ^ [ i ] ) L_b = -\sum_{i=1}^{T} B[i] \log(\hat{b}[i]) + (1 - B[i]) \log(1 - \hat{b}[i]) Lb=−i=1∑TB[i]log(b^[i])+(1−B[i])log(1−b^[i])
其中, B B B是真实的边界标签序列, b ^ \hat{b} b^是模型预测的边界概率序列, T T T是帧的数量。
-
帧级真实性损失 L s L_s Ls:
- 帧级真实性损失使用标准的交叉熵损失函数来计算。
- 它的目的是最小化模型对帧真实性预测的概率与真实真实性标签之间的差异。
- 帧级真实性损失的计算公式为:
L s = − ∑ i = 1 T Y [ i ] log ( y ^ [ i ] ) L_s = -\sum_{i=1}^{T} Y[i] \log(\hat{y}[i]) Ls=−i=1∑TY[i]log(y^[i])
其中, Y Y Y是真实的帧级真实性标签序列, y ^ \hat{y} y^ 是模型预测的帧级真实性概率序列。
-
总损失 ( L ):
- 总损失是边界损失和帧级真实性损失的加权和。
- 通过引入一个权重参数 λ \lambda λ来平衡两个损失函数的重要性。
- 总损失的计算公式为:
L = L s ( y ^ , Y ) + λ L b ( b ^ , B ) L = L_s(\hat{y}, Y) + \lambda L_b(\hat{b}, B) L=Ls(y^,Y)+λLb(b^,B)
其中, λ \lambda λ是一个超参数,用于调整边界损失和帧级真实性损失在总损失中的比重,通常设置为0.5。
通过最小化这个总损失函数,模型能够同时学习如何准确地检测边界帧和判断每个帧的真实性。
这种设计使得模型在处理部分伪造音频时,能够有效地区分真实和伪造的音频帧,提高定位伪造音频区域的准确性。
5.工作流程总结
- 使用预训练的SSL模型提取语音特征,并通过注意力池化层使每个帧代表特定的时间颗粒度(例如160毫秒)。
- 将池化层的输出输入到BE模块以增强边界特征表示,并使用简单的全连接层识别边界帧。
- BFA模块接受边界预测结果和池化层的输出作为输入,以捕获帧之间的相关性信息。
- BFA模块和BE模块的输出被拼接,并输入到全连接层以进行帧级真实性决策。
通过这种方式,BAM利用边界信息作为辅助的注意力提示来指导定位,有效地区分真实和伪造的帧,从而提高定位性能。
实验
数据集和实现细节
- 数据集:实验在PartialSpoof数据库上进行,该数据库通过将ASVspoof2019 LA数据库中的完全伪造和真实话语进行分割,然后通过基本的数字信号处理技术进行拼接构建而成。
- 评估指标:使用等错误率(Equal Error Rate, EER)、精确度(Precision)、召回率(Recall)和F1分数(F1 score)四个指标来评估模型性能。
- 训练设置:在160毫秒时间分辨率的实验中,训练样本长度固定为4秒,超出长度的样本被随机截断,不足长度的样本用零填充。使用Adam优化器,学习率设置为(10^{-5}),每10个epoch减半,模型训练50个epoch。
- 实验结果:在PartialSpoof数据集上,与现有方法(如LCNN-BLSTM、SELCNN-BLSTM、Single reso.、Multi reso.、SPF、TDL等)相比,BAM方法在EER和F1分数上均取得了最佳性能。具体来说,使用WavLM-Large作为前端特征提取器时,BAM方法的EER为3.58%,F1分数为96.09%。
消融研究
为了评估BAM框架中每个模块的有效性,进行了消融实验。结果显示,每个模块都对提高定位性能有贡献。例如,与基线模型相比,BAM方法将EER降低了2.21%,F1分数提高了1.73%。
更细粒度分辨率实验
- 实验设置:在20毫秒时间分辨率下进行了额外的实验。首先,直接在前端特征上训练BAM模型50个epoch作为基线模型。然后,从预训练的基线模型中移除最后一个全连接层,并替换为注意力池化层后的新全连接层,微调10个epoch以预测特定时间分辨率的真实性。
- 实验结果:基线模型在20毫秒分辨率下取得了EER为5.20%和F1分数为95.82%的显著定位性能。随着时间分辨率的降低,F1分数几乎保持不变,而EER持续增加。
结论
实验结果表明,BAM方法在PartialSpoof数据集上实现了最佳性能,证明了利用边界信息可以增强定位伪造音频区域的准确性。此外,细粒度分辨率实验表明,在更细的分辨率下准确检测边界位置是一个更具挑战性的任务,这将是未来工作的方向。