在前几篇已经介绍了pytorch的基础,现在完成一下完整的训练套路。由于仅作练习,所以还是选择较小的CIFAR10数据集。
首先准备数据集:
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
可以查看一下训练集和验证集中有多少张图片:
train_data_size = len(train_data)
test_data_size = len(test_data)
print('训练数据集的长度为:{}'.format(train_data_size))
print('测试数据集的长度为:{}'.format(test_data_size))
输出结果如下:

利用dataloader加载数据集:
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
为使代码方便阅读与修改,新建一个文件用于编写神经网络模型:
# 搭建神经网络
import torch
from torch import nn
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
test1 = Test()
input = torch.ones((64, 3, 32, 32))
output = test1(input)
print(output.shape)
搭建网络模型的方法前面已经介绍,所以不再赘述。
在主文件中创建网络模型:
test1 = Test()
创建损失函数:
loss_fn = nn.CrossEntropyLoss()
创建优化器,学习速率设为0.01:
learning_rate = 0.01
optmizer = torch.optim.SGD(test1.parameters(), lr=learning_rate)
设置训练网络的一些参数,记录训练次数:
total_train_step = 0
记录测试次数:
total_test_step = 0
设置训练轮次:
epoch = 10
添加tensorboard:
writer = SummaryWriter('logs_train')
开始训练:
for i in range(epoch):
print("--------第{}轮训练开始--------".format(i + 1))
# 训练步骤开始
test1.train()
for data in train_dataloader:
imgs, targets = data
outputs = test1(imgs)
# 计算损失值
loss = loss_fn(outputs, targets)
# 优化
optmizer.zero_grad()
loss.backward()
optmizer.step()
# 训练次数加一,缝百打印
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
test1.eval()
total_test_loss = 0
# 匹配正确次数
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = test1(imgs)
loss = loss_fn(outputs, targets)
# 整体测试的loss
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(test1, "lxw_{}.ptn".format(i))
writer.close()
输出结果如下:
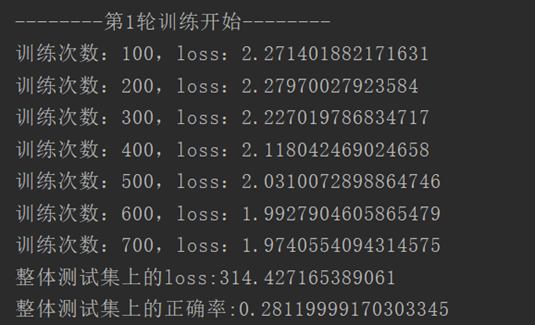
上图是第一轮训练的损失值,可以看出损失值在逐渐减小。
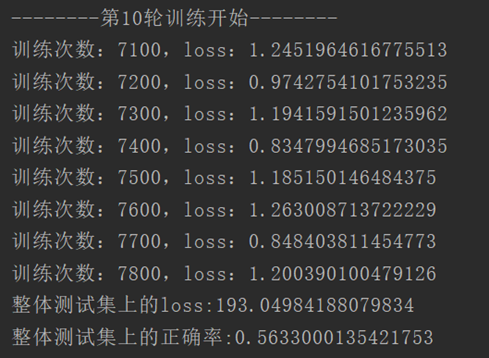
最后一轮训练正确率明显提升。
在tensorboard中查看训练过程:

训练样本损失值变化如下:
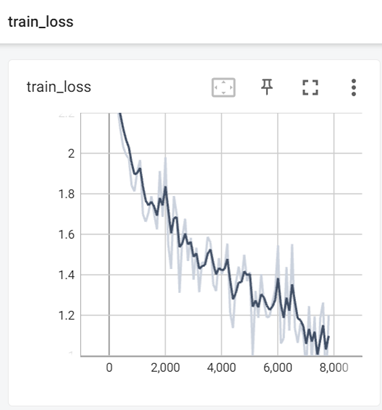
测试样本损失值如下:
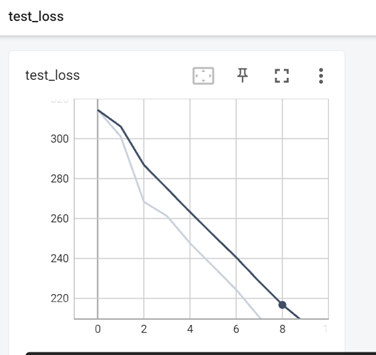
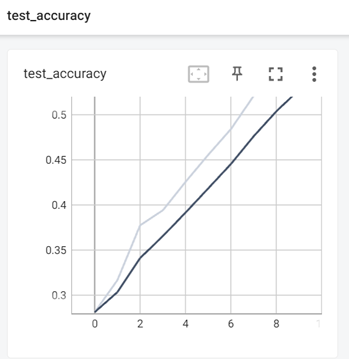
测试精度如下: