使用普通RNN进行图像标注
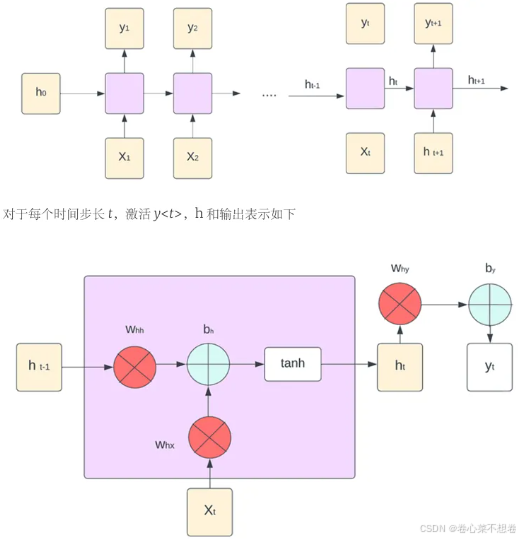
单个RNN神经元行为
前向传播:
反向传播:
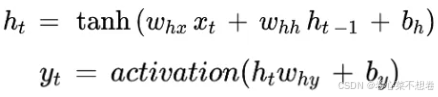

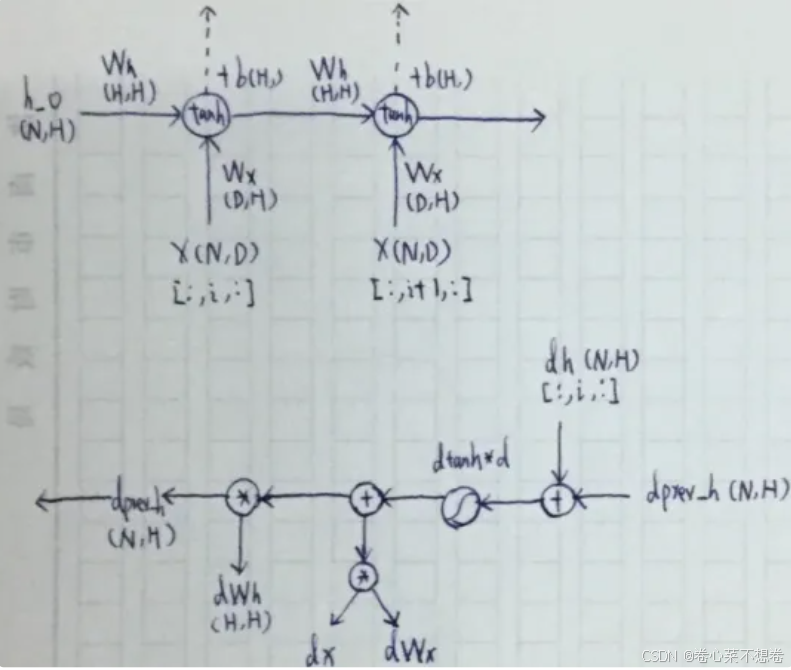
def rnn_step_backward(dnext_h, cache):
dx, dprev_h, dWx, dWh, db = None, None, None, None, None
x, Wx, Wh, prev_h, next_h = cache
dtanh = 1 - next_h**2
dx = (dnext_h*dtanh).dot(Wx.T)
dWx = x.T.dot(dnext_h*dtanh)
dprev_h = (dnext_h*dtanh).dot(Wh.T)
dWh = prev_h.T.dot(dnext_h*dtanh)
db = np.sum(dnext_h*dtanh,axis=0)
return dx, dprev_h, dWx, dWh, db
单层RNN神经元行为
RNN输出有两个方向,一个向上一层(输出层),一个向同层下一个时序,所以反向传播时两个梯度需要相加,输出层梯度可以直接求出(或是上一层中递归求出),所以使用dh(N,T,H)保存好,而同层时序梯度必须在同层中递归计算。
正向传播:
def rnn_forward(x, h0, Wx, Wh, b):
h, cache = None, None
N, T, D = x.shape
_, H = h0.shape
h = np.zeros((N,T,H))
h_next = h0
cache = []
for i in range(T):
h[:,i,:], cache_next = rnn_step_forward(x[:,i,:], h_next, Wx, Wh, b)
h_next = h[:,i,:]
cache.append(cache_next)
return h, cache
反向传播:
def rnn_backward(dh, cache):
dx, dh0, dWx, dWh, db = None, None, None, None, None
x, Wx, Wh, prev_h, next_h = cache[-1]
_, D = x.shape
N, T, H = dh.shape
dx = np.zeros((N,T,D))
dh0 = np.zeros((N,H))
dWx = np.zeros((D,H))
dWh = np.zeros((H,H))
db = np.zeros(H)
dprev_h_ = np.zeros((N,H))
for i in range(T-1,-1,-1):
dx_, dprev_h_, dWx_, dWh_, db_ = rnn_step_backward(dh[:,i,:] + dprev_h_, cache.pop())
dx[:,i,:] = dx_
dh0 = dprev_h_
dWx += dWx_
dWh += dWh_
db += db_
return dx, dh0, dWx, dWh, db
使用LSTM进行图像标注
【LSTM】深入浅出讲解长短时记忆神经网络(结构、原理)
有三种方法应对梯度消失问题:
(1)合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
(2)使用 ReLu 代替 sigmoid 和 tanh 作为激活函数。
(3)使用其他结构的RNNS,比如长短时记忆网络(LSTM)和 门控循环单元(GRU),这是最流行的做法。
单个LSTM神经元向前传播:

def lstm_step_forward(x, prev_h, prev_c, Wx, Wh, b):
next_h, next_c, cache = None, None, None
_, H = prev_h.shape
a = x.dot(Wx) + prev_h.dot(Wh) + b
i,f,o,g = sigmoid(a[:,:H]),sigmoid(a[:,H:2*H]),sigmoid(a[:,2*H:3*H]),np.tanh(a[:,3*H:])
next_c = f*prev_c + i*g
next_h = o*np.tanh(next_c)
cache = [i, f, o, g, x, prev_h, prev_c, Wx, Wh, b, next_c]
return next_h, next_c, cache
层LSTM神经元向前传播
def lstm_forward(x, h0, Wx, Wh, b):
h, cache = None, None
N,T,D = x.shape
next_c = np.zeros_like(h0)
next_h = h0
h, cache = [], []
for i in range(T):
next_h, next_c, cache_step = lstm_step_forward(x[:,i,:], next_h, next_c, Wx, Wh, b)
h.append(next_h)
cache.append(cache_step)
h = np.array(h).transpose(1,0,2) #<-----------注意分析h存储后的维度是(T,N,H),需要转置为(N,T,H)
return h, cache
单个LSTM神经元反向传播
def lstm_step_backward(dnext_h, dnext_c, cache):
dx, dprev_h, dprev_c, dWx, dWh, db = None, None, None, None, None, None
i, f, o, g, x, prev_h, prev_c, Wx, Wh, b, next_c = cache
do = dnext_h*np.tanh(next_c)
dnext_c += dnext_h*o*(1-np.tanh(next_c)**2) #<-----------上面分析行为有提到这里的求法
di, df, dg, dprev_c = (g, prev_c, i, f) * dnext_c
da = np.concatenate([i*(1-i)*di, f*(1-f)*df, o*(1-o)*do, (1-g**2)*dg],axis=1)
db = np.sum(da,axis=0)
dx, dWx, dprev_h, dWh = (da.dot(Wx.T), x.T.dot(da), da.dot(Wh.T), prev_h.T.dot(da))
return dx, dprev_h, dprev_c, dWx, dWh, db
层LSTM神经元反向传播
def lstm_backward(dh, cache):
dx, dh0, dWx, dWh, db = None, None, None, None, None
N,T,H = dh.shape
_, D = cache[0][4].shape
dx, dh0, dWx, dWh, db = \
[], np.zeros((N, H), dtype='float32'), \
np.zeros((D, 4*H), dtype='float32'), np.zeros((H, 4*H), dtype='float32'), np.zeros(4*H, dtype='float32')
step_dprev_h, step_dprev_c = np.zeros((N,H)),np.zeros((N,H))
for i in xrange(T-1, -1, -1):
step_dx, step_dprev_h, step_dprev_c, step_dWx, step_dWh, step_db = \
lstm_step_backward(dh[:,i,:] + step_dprev_h, step_dprev_c, cache[i])
dx.append(step_dx) # 每一个输入节点都有自己的梯度
dWx += step_dWx # 层共享参数,需要累加和
dWh += step_dWh # 层共享参数,需要累加和
db += step_db # 层共享参数,需要累加和
dh0 = step_dprev_h # 只有最初输入的h0,即feature的投影(图像标注中),需要存储梯度
dx = np.array(dx[::-1]).transpose((1,0,2))
return dx, dh0, dWx, dWh, db