5. 大语言模型
5.1. 语言模型历史
20世纪90年代以前的语言模型都是基于语法分析这种方法,效果一直不佳。到了20世纪90年代,采用统计学方法分析语言,取得了重大进展。但是在庞大而复杂的语言信息上,基于传统统计的因为计算量巨大,难以进一步提升计算机语言分析的性能。2023年首度将基于神经网络的深度学习引入了语言分析模型中,计算机理解语言的准确性达到了前所未有的高度。依然是因为计算量巨大,基于深度学习的语言模型难以进一步提升准确性和普及应用。随着2018年,研究人员将Transformer引入神经网络,大幅缩减了计算量,而且提升了语言的前后关联度,再一次提升了自然语言处理的准确性,并且将计算机处理自然语言的成本大幅降低。
5.2. 概念
随着语言模型参数规模的提升,语言模型在各种任务中展现出惊人的能力(这种能力也称为“涌现能力”),自此进入了大语言模型(Large Language Model, LLM)时代。大语言模型 (LLM) 指包含数百亿(或更多)参数的语言模型,这些模型在大量的文本数据上进行训练,例如国外的有GPT-3 、GPT-4、PaLM 、Galactica 和 LLaMA 等,国内的有ChatGLM、文心一言、通义千问、讯飞星火等。
LLM多用于自然语言处理领域的问答、翻译,进一步延伸到写文章,编写代码等。随着多模态能力的增加,大语言模型逐步展现出统都一人工智能的趋势,做到真正的通用人工智能(AGI)。LLM逐步成为一个基础模型,人们可以在LLM的基础上做进一步的优化,完成更加专业精细的任务。
5.3. Transformer
5.3.1. 简介
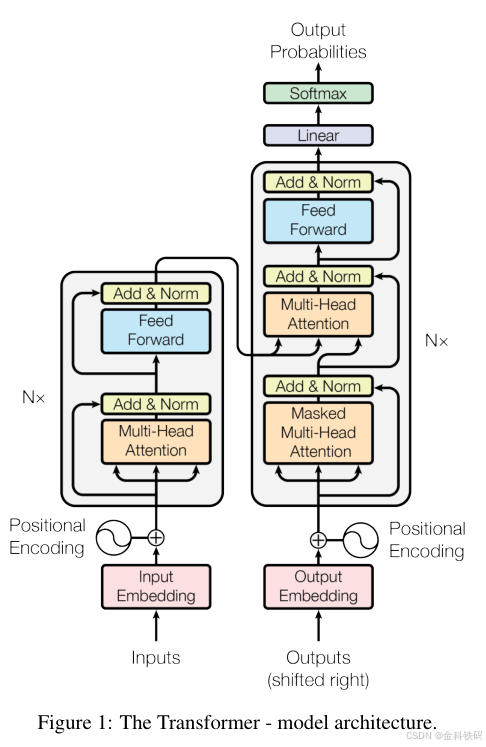
Transformer模型是由谷歌团队在2017年发表的论文《Attention is All You Need》所提出。这篇论文的主体内容只有几页,主要就是对下面这个模型架构的讲解。
5.3.2. 自注意力机制
传输的RNN用于处理系列时,会增加一个隐藏状态用来记录上一个时刻的序列信息。在处理翻译文本时,一个字的意思可能和前面序列的内容相关,通过隐藏状态,RNN能够很好地翻译上下文相关性较大的文本。但是如果文本内容非常大的时候,隐藏状态无法完全包括之前的所有状态(如果包括,其计算量非常巨大,难以实现)。
自注意力机制(Self-Attention)是在注意力机制上优化得来的,其只注意输入信息本身。即输入向量中每一个成员都和其他成员经过一个注意力函数处理之后,形成一个相关性的权重向量表。如:
这样一张权重向量表的计算量相比在RNN中隐藏状态的计算量少很多。

通过这个权重向量表,无论需要翻译的原始文件多大,都能够很好地找到之前信息对当前翻译信息的影响,可以翻译得更加准确。