Detecting Pretraining Data from Large Language Models
http://arxiv.org/abs/2310.16789
这篇文章正式提出了Min-k%方法来实现成员推理攻击
贡献
- 介绍了WIKIMIA动态基准测试。旨在定期自动评估任何新发布的预训练 LLMs。通过利用 Wikipedia 数据时间戳和模型发布日期,我们选择旧的 Wikipedia 事件数据作为我们的成员数据(即预训练期间看到的数据),选择最近的 Wikipedia 事件数据(例如,2023 年之后)作为我们的非成员数据(不可见)。因此,我们的数据集表现出三个理想的特性:(1) 准确:保证LLM不会出现在预训练数据中。事件的时间性质确保非成员数据确实不可见,并且在预训练数据中未提及。(2) 通用:我们的基准测试不局限于任何特定模型,可以应用于使用 Wikipedia 预训练的各种模型(例如 OPT、LLaMA、GPT-Neo),因为 Wikipedia 是常用的预训练数据源。(3) 动态:由于我们的数据构建管道是完全自动化的,因此我们将通过从维基百科收集更新的非会员数据(即最近的事件)来不断更新我们的基准。
- 提出了不需要任何数据参考的MIA方法Min-k% Prob。基于这样的假设:一个看不见的例子往往包含一些概率很低的离群词,而一个看过的例子不太可能包含概率这么低的词。Min-k% Prob 计算离群值标记的平均概率。Min-k% Prob 可以在没有任何关于训练前语料库或任何额外训练的知识的情况下应用
WIKIMIA
动态评估基准
数据构建:通过时间上的不同来界定成员和非成员。
Min-k% Prob
简单的无参考预训练数据检测方法
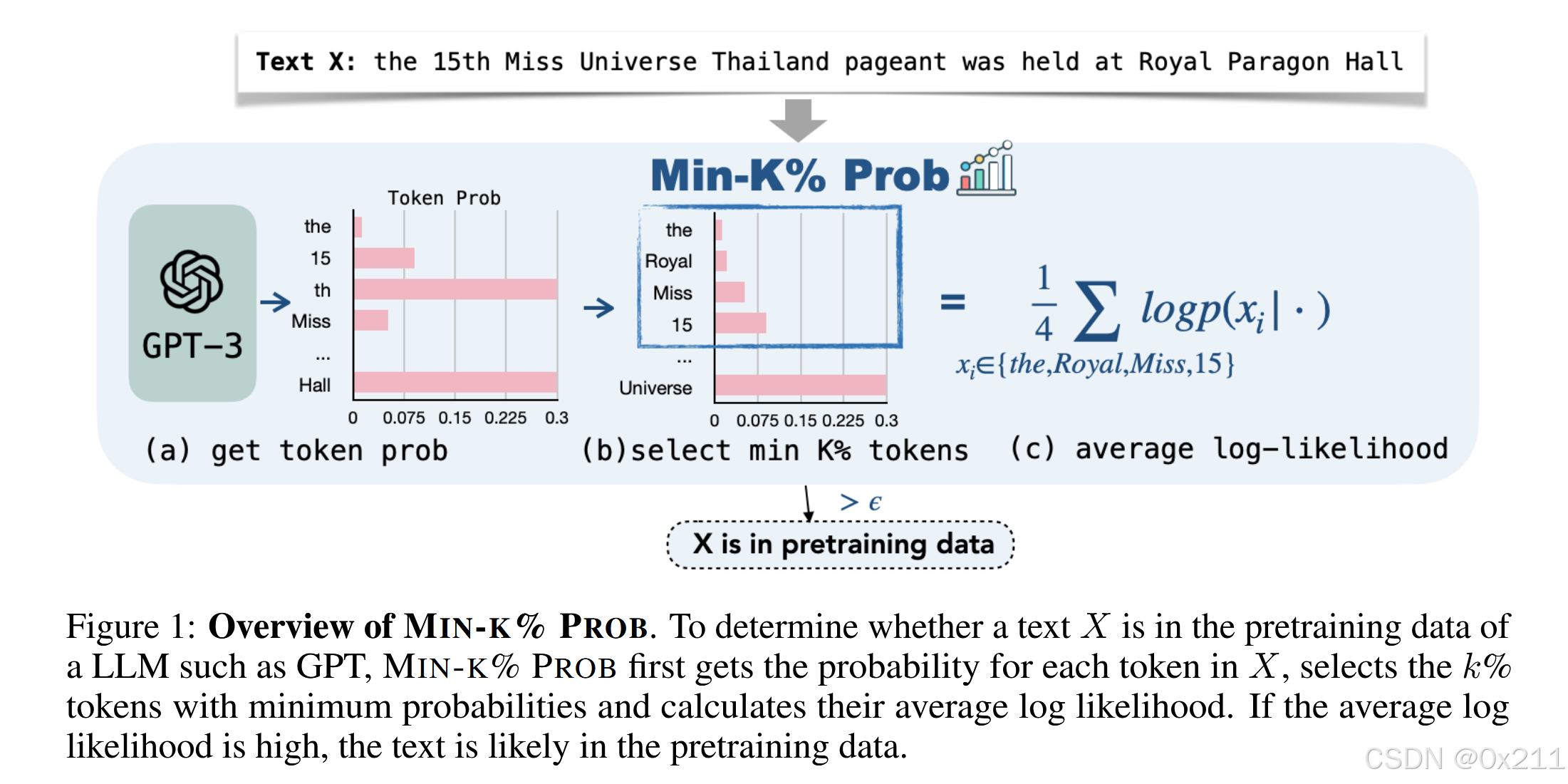
它利用文本的最小标记概率进行检测。Min-k% Prob 基于以下假设:非成员示例更有可能包含一些具有高负对数似然(或低概率)的异常值单词,而成员示例不太可能包含具有高负对数似然的单词。

其中 E 是 Min-K%( x ) 集的大小。我们只需对这个 Min-k% Prob 结果进行阈值处理,就可以检测预训练数据中是否包含一段文本
基线方法对比
我们采用现有的基于参考和无参考的 MIA 方法作为基线方法,并评估它们在 WikiMIA 上的性能。这些方法仅考虑句子级概率。
具体来说,我们使用 LOSS Attack 方法(Yeom et al., 2018a),该方法在将示例作为输入时,根据目标模型的损失来预测示例的成员身份。在 LM 的上下文中,这种损失对应于示例的困惑度 (PPL)。
我们考虑的另一种方法是邻域攻击(Mattern et al., 2023),它利用概率曲率来检测隶属度(Neighbor)。这种方法与最近提出的 DetectGPT(Mitchell et al., 2023)方法相同,该方法用于对机器生成的文本与人类编写的文本进行分类。
最后,我们将与(Carlini等 人,2021 年)中提出的隶属度推理方法进行了比较,包括将示例困惑与 zlib 压缩熵 (Zlib)、小写示例困惑(小写)和在相同数据上预训练的较小模型下的示例 perplexity 进行比较(较小的参考文献).对于较小的参考模型设置,我们采用 LLaMA-7B 作为 LLaMA-65B 和 LLaMA-30B 的较小模型,GPT-NeoX-20B 的 GPT-Neo-125M,OPT-66B 的 OPT-350M 和 Pythia-2.8B 的 Pythia-70M。
其余的有用内容:
LOSS ATTACK、PPL困惑度、邻域攻击、DeteceGPT、zlib等MIA方法
看到了没见过的评估指标:SimCSE 分数