在上一节中,我们将文本数据映射为词元,并制作了词表。这一节我们将介绍语言模型和语言数据集
0 引言
假设我们有一个长度为
T
T
T 的文本序列,其中词原依次为
x
1
,
x
2
,
…
,
x
T
x_1, x_2, \ldots, x_T
x1,x2,…,xT,于是
x
t
(
1
≤
t
≤
T
)
x_t( 1 \leq t \leq T)
xt(1≤t≤T)可以被认为是文本序列在时间步
t
t
t 处的观测或标签,在给定这样的文本序列时,语言模型(language model)的目标是估计序列的联合概率:
P
(
x
1
,
x
2
,
…
,
x
T
)
.
P(x_1, x_2, \ldots, x_T).
P(x1,x2,…,xT).
例如,只需要一次抽取一个词元
x
t
∼
P
(
x
t
∣
x
t
−
1
,
…
,
x
1
)
x_t \sim P(x_t \mid x_{t-1}, \ldots, x_1)
xt∼P(xt∣xt−1,…,x1),一个理想的语言模型就能够基于模型本身生成自然文本。
1 学习语言模型
建立语言模型就是如何对一个文档或者词元序列进行建模。
我们从基本概率模型开始观看:
P
(
x
1
,
x
2
,
…
,
x
T
)
=
∏
t
=
1
T
P
(
x
t
∣
x
1
,
…
,
x
t
−
1
)
.
P(x_1, x_2, \ldots, x_T) = \prod_{t=1}^T P(x_t \mid x_1, \ldots, x_{t-1}).
P(x1,x2,…,xT)=t=1∏TP(xt∣x1,…,xt−1).
例如,包含了四个单词的一个文本序列的概率是:
P
(
deep
,
learning
,
is
,
fun
)
=
P
(
deep
)
P
(
learning
∣
deep
)
P
(
is
∣
deep
,
learning
)
P
(
fun
∣
deep
,
learning
,
is
)
.
P(\text{deep}, \text{learning}, \text{is}, \text{fun}) = P(\text{deep}) P(\text{learning} \mid \text{deep}) P(\text{is} \mid \text{deep}, \text{learning}) P(\text{fun} \mid \text{deep}, \text{learning}, \text{is}).
P(deep,learning,is,fun)=P(deep)P(learning∣deep)P(is∣deep,learning)P(fun∣deep,learning,is).
为了训练语言模型,我们需要计算单词的概率, 和给定前面几个单词后出现某个单词的条件概率。 这些概率本质上就是语言模型的参数。
假设训练数据集是一个大型的文本语料库。 比如,维基百科的所有条目、 古登堡计划,或者所有发布在网络上的文本。训练数据集中,词的概率可以根据给定词的相对词频来计算。
例如,可以将估计值 P ^ ( deep ) \hat{P}(\text{deep}) P^(deep),计算为任何以单词“deep”开头的句子的概率,也可以用一种不太精确的方法:计单词“deep”在数据集中的出现次数,然后将其除以整个语料库中的单词总数。
例如,我们估计给定单词“deep”的情况下,单词“learning”出现的概率,即:
P
^
(
learning
∣
deep
)
=
n
(
deep, learning
)
n
(
deep
)
,
\hat{P}(\text{learning} \mid \text{deep}) = \frac{n(\text{deep, learning})}{n(\text{deep})},
P^(learning∣deep)=n(deep)n(deep, learning),
其中
n
(
x
)
n(x)
n(x)是单个单词的出现次数,
n
(
x
,
x
′
)
n(x, x')
n(x,x′)是连续单词对的出现次数,但实际情况中,由于连续单词对“deep learning”的出现频率要低得多, 所以估计这类单词正确的概率服从很困难,对于三个或者更多的单词组合,情况会变得更糟。
一种常见的策略是执行某种形式的拉普拉斯平滑(Laplace smoothing),即在在所有计数中添加一个小常量,用
n
n
n 表示单词总数,用
m
m
m 表示唯一单词的数量,解决方案有助于处理单元素问题,例如通过:
P
^
(
x
)
=
n
(
x
)
+
ϵ
1
/
m
n
+
ϵ
1
,
P
^
(
x
′
∣
x
)
=
n
(
x
,
x
′
)
+
ϵ
2
P
^
(
x
′
)
n
(
x
)
+
ϵ
2
,
P
^
(
x
′
′
∣
x
,
x
′
)
=
n
(
x
,
x
′
,
x
′
′
)
+
ϵ
3
P
^
(
x
′
′
)
n
(
x
,
x
′
)
+
ϵ
3
.
\begin{split}\begin{aligned} \hat{P}(x) & = \frac{n(x) + \epsilon_1/m}{n + \epsilon_1}, \\ \hat{P}(x' \mid x) & = \frac{n(x, x') + \epsilon_2 \hat{P}(x')}{n(x) + \epsilon_2}, \\ \hat{P}(x'' \mid x,x') & = \frac{n(x, x',x'') + \epsilon_3 \hat{P}(x'')}{n(x, x') + \epsilon_3}. \end{aligned}\end{split}
P^(x)P^(x′∣x)P^(x′′∣x,x′)=n+ϵ1n(x)+ϵ1/m,=n(x)+ϵ2n(x,x′)+ϵ2P^(x′),=n(x,x′)+ϵ3n(x,x′,x′′)+ϵ3P^(x′′).
其中,
ϵ
1
,
ϵ
2
,
ϵ
3
\epsilon_1,\epsilon_2,\epsilon_3
ϵ1,ϵ2,ϵ3是超参数。
然而这种模型几乎没有作用,因为它既不理解单词的意思,还需要存储所有的计数,该模型只是简单地统计先前“看到”的单词序列频率。
2 马尔科夫模型和n元语法
在从0开始深度学习(28)——序列模型中提到了马尔科夫模型,同样可以用于语言模型,如果只和前一个单词有关,则是一阶马尔科夫模型;如果只和前两个单词有关,则是二阶马尔科夫模型;以此类推。
通常,涉及一个、两个和三个变量的概率公式分别被称为 一元语法(unigram)、二元语法(bigram)和三元语法(trigram)模型。 下面,我们将学习如何去设计更好的模型。
3 自然语言统计
我们先对上一节中词表中的前10个最常用的(频率最高的)单词:
# 打印出现频率最高的前10个词汇及其频率
top_10_tokens = vocab.token_freqs[:10]
for token, freq in top_10_tokens:
print(f"Token: '{token}', Frequency: {freq}")
运行结果:
可以看出这些单词都是一些“无聊”的词,这些词通常被称为停用词(stop words),因此可以被过滤。
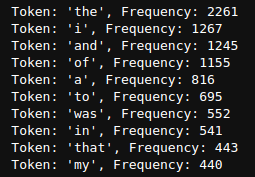
我们再看看前100个词的频率:
import matplotlib.pyplot as plt
# 获取出现频率最高的前100个词汇及其频率
top_100_tokens = vocab.token_freqs[20:]
# 分离词汇和它们的频率
tokens, frequencies = zip(*top_100_tokens)
# 创建横坐标标签,即1到100
x_labels = range(1, len(top_100_tokens) + 1)
# 绘制折线图
plt.figure(figsize=(20, 5)) # 设置图形大小
plt.plot(x_labels, frequencies, marker='o') # 使用'o'标记点
plt.title('Top 100 Tokens Frequency') # 图形标题
plt.xlabel('Log Token Rank') # 横坐标标签改为对数排名
plt.ylabel('Log Frequency') # 纵坐标标签改为对数频率
plt.xscale('log') # 设置横坐标为对数刻度
plt.yscale('log') # 设置纵坐标为对数刻度
plt.grid(True, which="both", axis='both', linestyle='--') # 显示对数刻度下的网格线
plt.show() # 显示图形
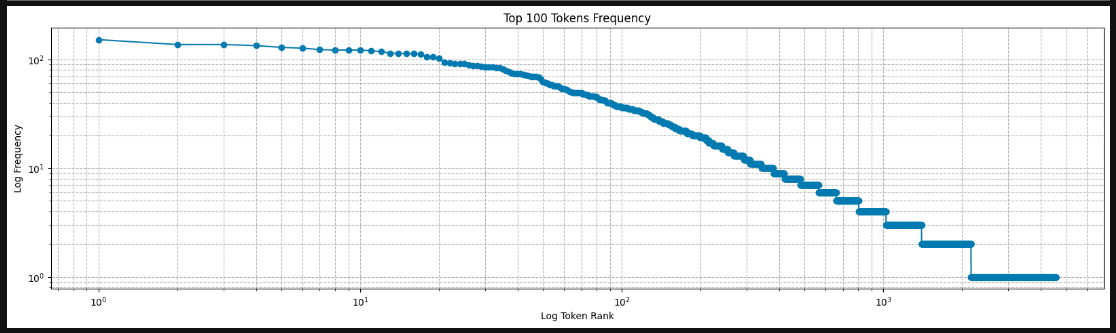
通过此图我们可以发现:词频以一种明确的方式迅速衰减。 将前几个单词作为例外消除后,剩余的所有单词大致遵循双对数坐标图上的一条直线。这种情况就意味着单词的频率满足齐普夫定律(Zipf’s law)
齐普夫定律: 在自然语言的文本中,一个词的频率与它在频率表中的排名成反比的关系,如果把一个文本中所有单词按照出现次数从高到低排序,那么排名第 n 的单词的出现次数大约是排名第 1 的单词出现次数的
1
/
n
1/n
1/n,该式为经典齐普夫定律,可以用下列公式表达:
log
n
i
=
−
α
log
i
+
c
,
\log n_i = -\alpha \log i + c,
logni=−αlogi+c,
第
i
i
i个常用单词的频率为
n
i
n_i
ni,
c
c
c是常数,
α
\alpha
α是指数因子,当其为
1
1
1的时候,是经典齐普夫定律
这个规律告诉我们想要通过计数统计和平滑来建模单词是不可行的, 因为这样建模的结果会大大高估尾部单词的频率,也就是所谓的不常用单词。
同样的,一元语法、二元语法、三元语法也是如此,下面直观地对比三种模型中的词元频率:
最后给出三个结论:
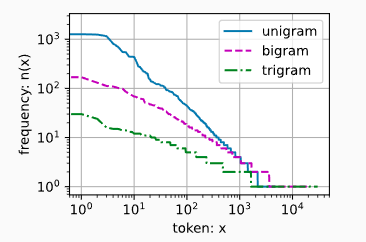
- 在更复杂的短语结构中,仍然存在着某种形式的幂律分布,只是其表现形式可能有所不同。
- 语言具有内在的结构性,这些结构可以帮助我们构建更加有效的模型来理解和生成语言。
- 神经网络模型,这些方法能够从大量训练数据中自动学习到有用的特征表示,从而更好地处理稀疏数据的问题。稀疏性: 随着n元组长度的增加,可能出现的组合数量呈指数级增长,但许多可能的单词组合(尤其是较长的n元组)在训练集中出现次数极少或根本未出现,导致模型难以准确预测这些组合的概率。
4 读取长序列数据
由于文本序列可以是任意长的,于是任意长的序列可以被我们划分为具有相同时间步数的子序列。 当训练我们的神经网络时,这样的小批量子序列将被输入到模型中。 假设网络一次只处理具有
n
n
n个时间步的子序列,下图是
n
=
5
n=5
n=5时的子序列划分方法。所以我们可以选择任意偏移量来指示初始位置,来获得不同的子序列:
因此,我们可以从随机偏移量开始划分序列, 以同时获得覆盖性(coverage)和随机性(randomness)。

下面我们将描述如何实现随机采样(random sampling) 和 顺序分区(sequential partitioning) 策略。
4.1 随机采样
在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列。 对于语言建模,目标是基于到目前为止我们看到的词元来预测下一个词元, 因此标签是移位了一个词元的原始序列。
下面的代码每次可以从数据中随机生成一个小批量。 在这里,参数batch_size指定了每个小批量中子序列样本的数目, 参数num_steps是每个子序列中预定义的时间步数:
import torch
import random
def seq_data_iter_random(corpus, batch_size, num_steps): #@save
"""
使用随机抽样生成一个小批量子序列
参数:
corpus: 列表形式的文本语料库,每个元素是一个单词或字符。
batch_size: 每个批次的数据量。
num_steps: 每个子序列的长度。
返回:
生成器,每次返回一个批次的输入和输出子序列。
"""
# 从语料库中随机选择一个起始位置,以确保数据的随机性。
corpus = corpus[random.randint(0, num_steps - 1):]
# 计算可以生成多少个子序列,减1是因为有标签
num_subseqs = (len(corpus) - 1) // num_steps
# 生成所有可能的子序列的起始索引。
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 随机打乱起始索引,以确保数据的随机性。
random.shuffle(initial_indices)
# 定义一个函数,用于从给定的起始位置获取子序列。
def data(pos):
return corpus[pos: pos + num_steps]
# 计算可以生成多少个批次。
num_batches = num_subseqs // batch_size
# 遍历所有批次。
for i in range(0, batch_size * num_batches, batch_size):
# 获取当前批次的起始索引。
initial_indices_per_batch = initial_indices[i: i + batch_size]
# 生成当前批次的输入子序列。
X = [data(j) for j in initial_indices_per_batch]
# 生成当前批次的输出子序列,即输入子序列向后移动一个位置。
Y = [data(j + 1) for j in initial_indices_per_batch]
# 将当前批次的输入和输出子序列转换为张量,并返回。
yield torch.tensor(X), torch.tensor(Y)
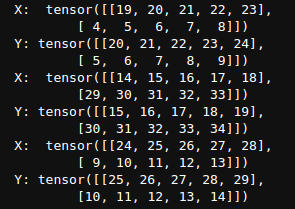
下面我们生成一个从0到34的序列,假设batch_size为2,num_steps为5,所以可以生成 ⌊ ( 35 − 1 ) / 5 ⌋ = 6 \lfloor (35 - 1) / 5 \rfloor= 6 ⌊(35−1)/5⌋=6个“特征-标签”子序列对
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
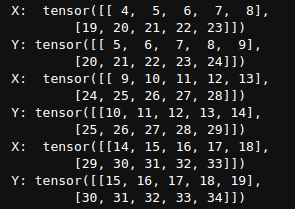
运行结果:
4.2 顺序分区
保证两个相邻的小批量中的子序列在原始序列上也是相邻的。 这种策略在基于小批量的迭代过程中保留了拆分的子序列的顺序,因此称为顺序分区。
import torch
import random
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save
"""
使用顺序分区生成一个小批量子序列
参数:
corpus: 列表形式的文本语料库,每个元素是一个单词或字符。
batch_size: 每个批次的数据量。
num_steps: 每个子序列的长度。
返回:
生成器,每次返回一个批次的输入和输出子序列。
"""
# 从语料库中随机选择一个起始位置,以确保数据的随机性。
offset = random.randint(0, num_steps - 1)
# 计算可以使用的令牌数量,确保其可以被batch_size整除。
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
# 获取输入子序列Xs和输出子序列Ys。
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
# 将Xs和Ys重新塑形为(batch_size, -1)的形式,其中-1表示自动计算列数。
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
# 计算可以生成多少个批次。
num_batches = Xs.shape[1] // num_steps
# 遍历所有批次。
for i in range(0, num_steps * num_batches, num_steps):
# 获取当前批次的输入子序列X和输出子序列Y。
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
# 返回当前批次的输入和输出子序列。
yield X, Y
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
运行结果:
现在,我们将上面的两个采样函数包装到一个类中, 以便稍后可以将其用作数据迭代器。
class SeqDataLoader: #@save
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.data_iter_fn = d2l.seq_data_iter_sequential
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
最后,我们定义了一个函数load_data_time_machine, 它同时返回数据迭代器和词表:
def load_data_time_machine(batch_size, num_steps, #@save
use_random_iter=False, max_tokens=10000):
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab