Helsinki-NLP 是一个广泛使用的开源机器翻译(Machine Translation,MT)模型系列,基于 Marian NMT 框架
Hugggingface地址:https://huggingface.co/Helsinki-NLP/opus-mt-en-zh
原本的模型对于国内外公司的名称支持度很差,比如会把‘FireFox‘翻译成‘消防’,所以我需要在保留原本翻译能力的基础上,增强对公司名称的翻译能力。
1 数据集准备
我使用GPT-4这类大模型为我生成了500条公司名称中英文对,原本是.xlsx格式的文件,将其合并转为.tsv
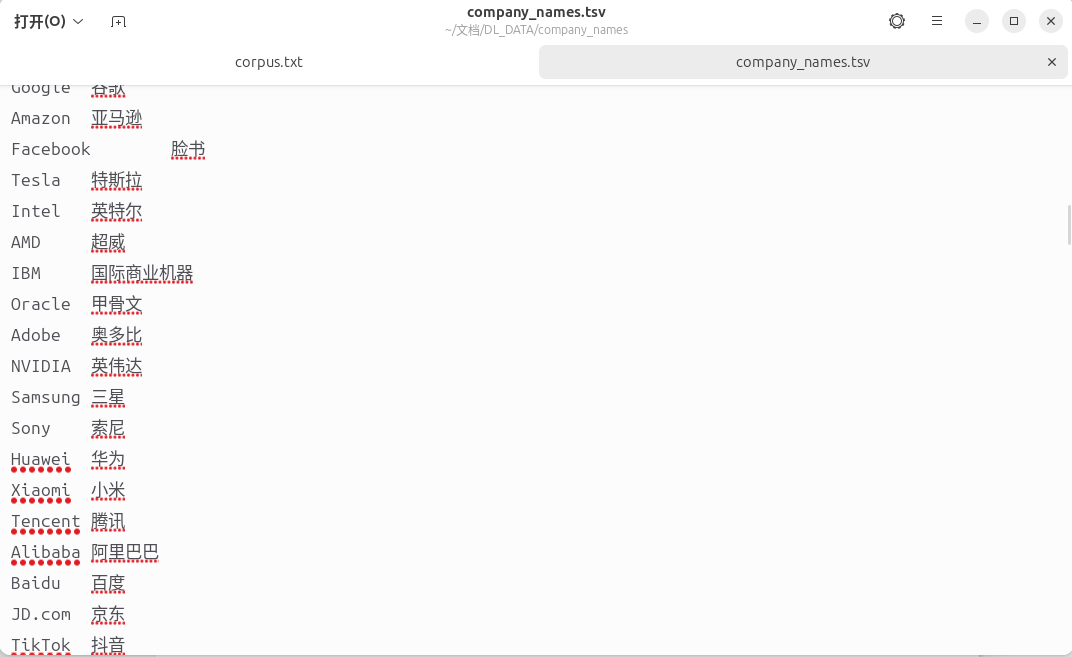
2 冻结参数
为了保留原来的翻译能力,我们需要冻结法大部分模型的参数,只解冻少量参数用于训练,最大程度的不影响翻译能力。
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import pandas as pd
import os
# 配置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载本地模型和分词器
model_path = "/kaggle/input/helsinki-nlp-en-zh/pytorch/default/1/Helsinki-NLP-en-zh" # 替换为本地模型路径
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSeq2SeqLM.from_pretrained(model_path) # 自动检测并加载模型结构和权重
# 将模型移动到设备
model = model.to(device)
print("模型和分词器加载成功!")
# 冻结编码器和解码器的低层参数,只解冻解码器高层和输出层
for name, param in model.named_parameters():
if ("decoder.layers.5" in name or "lm_head" in name):
param.requires_grad = True
else:
param.requires_grad = False
# 定义自定义数据集
class CompanyNameDataset(Dataset):
def __init__(self, file_path, tokenizer, max_length=128):
self.data = pd.read_csv(file_path, sep='\t', header=None, names=['source', 'target'])
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
source = self.data.iloc[idx, 0]
target = self.data.iloc[idx, 1]
tokenized_data = tokenizer(
[source], # 输入源文本
text_target=[target], # 输入目标文本
max_length=128, # 设置最大长度
padding="max_length", # 填充到最大长度
truncation=True, # 截断到最大长度
return_tensors="pt" # 返回 PyTorch 张量
)
return {
"input_ids": tokenized_data["input_ids"].squeeze(0),
"attention_mask": tokenized_data["attention_mask"].squeeze(0),
"labels": tokenized_data["labels"].squeeze(0),
}
在冻结之前,可以通过下列代码查看模型的结构,会打印所有参数的名称,用以决定冻结哪些参数:
for name, param in model.named_parameters():
print(name)
当运模型加载完毕后,我们再运行下面的代码查看解冻的参数:
for name, param in model.named_parameters():
if param.requires_grad:
print(f"解冻参数: {name}")
运行结果:
解冻参数: model.decoder.layers.5.self_attn.k_proj.weight
解冻参数: model.decoder.layers.5.self_attn.k_proj.bias
解冻参数: model.decoder.layers.5.self_attn.v_proj.weight
解冻参数: model.decoder.layers.5.self_attn.v_proj.bias
解冻参数: model.decoder.layers.5.self_attn.q_proj.weight
解冻参数: model.decoder.layers.5.self_attn.q_proj.bias
解冻参数: model.decoder.layers.5.self_attn.out_proj.weight
解冻参数: model.decoder.layers.5.self_attn.out_proj.bias
解冻参数: model.decoder.layers.5.self_attn_layer_norm.weight
解冻参数: model.decoder.layers.5.self_attn_layer_norm.bias
解冻参数: model.decoder.layers.5.encoder_attn.k_proj.weight
解冻参数: model.decoder.layers.5.encoder_attn.k_proj.bias
解冻参数: model.decoder.layers.5.encoder_attn.v_proj.weight
解冻参数: model.decoder.layers.5.encoder_attn.v_proj.bias
解冻参数: model.decoder.layers.5.encoder_attn.q_proj.weight
解冻参数: model.decoder.layers.5.encoder_attn.q_proj.bias
解冻参数: model.decoder.layers.5.encoder_attn.out_proj.weight
解冻参数: model.decoder.layers.5.encoder_attn.out_proj.bias
解冻参数: model.decoder.layers.5.encoder_attn_layer_norm.weight
解冻参数: model.decoder.layers.5.encoder_attn_layer_norm.bias
解冻参数: model.decoder.layers.5.fc1.weight
解冻参数: model.decoder.layers.5.fc1.bias
解冻参数: model.decoder.layers.5.fc2.weight
解冻参数: model.decoder.layers.5.fc2.bias
解冻参数: model.decoder.layers.5.final_layer_norm.weight
解冻参数: model.decoder.layers.5.final_layer_norm.bias
我们选择把decoder的第5层解冻(即最靠近输出层的那一层),这样可以避免影响原始的翻译能力。
3 加载数据
# 加载数据
file_path = '/kaggle/input/company-logo-name-tsv/company_names.tsv'
dataset = CompanyNameDataset(file_path, tokenizer)
train_size = int(0.9 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=tokenizer.pad_token_id)
optimizer = torch.optim.AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=5e-5)
4 训练模型
# 定义训练循环
def train_epoch(model, dataloader, optimizer, criterion, device):
model.train()
total_loss = 0
for batch in dataloader:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["labels"].to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
def evaluate_epoch(model, dataloader, criterion, device):
model.eval()
total_loss = 0
with torch.no_grad():
for batch in dataloader:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["labels"].to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
total_loss += loss.item()
return total_loss / len(dataloader)
# 定义 EarlyStopping 类
class EarlyStopping:
def __init__(self, patience=3, verbose=False, delta=0):
"""
Args:
patience (int): 等待验证损失改进的轮数
verbose (bool): 是否打印详细信息
delta (float): 最小的改进幅度
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_loss = None
self.early_stop = False
self.delta = delta
def __call__(self, val_loss, model):
if self.best_loss is None:
self.best_loss = val_loss
elif val_loss > self.best_loss - self.delta:
self.counter += 1
if self.verbose:
print(f"EarlyStopping counter: {self.counter} out of {self.patience}")
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_loss = val_loss
self.counter = 0 # 重置等待计数器
# 初始化 EarlyStopping
early_stopping = EarlyStopping(patience=3, verbose=True) # 等待3轮验证损失无改进
# 开始训练
num_epochs = 20
for epoch in range(num_epochs):
train_loss = train_epoch(model, train_loader, optimizer, criterion, device)
val_loss = evaluate_epoch(model, val_loader, criterion, device)
print(f"Epoch {epoch+1}/{num_epochs}")
print(f"Train Loss: {train_loss:.4f}")
print(f"Validation Loss: {val_loss:.4f}")
# 调用 EarlyStopping
early_stopping(val_loss, model)
if early_stopping.early_stop:
print("Early stopping triggered. Training stopped.")
break
# 保存微调后的模型
torch.save(model.state_dict(), "./fine_tuned_marianmt.pth")
使用早停法,避免过拟合。
5 合并参数
原模型中的目录结如下:
其中pytorch_model.bin就是原模型的权重,现在我们要把fine_tuned_marianmt.pth加载进去:
import torch
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
# 原始模型和分词器路径
original_model_path = "./original_model" # 替换为原始模型的文件夹路径
fine_tuned_weights = "./fine_tuned_marianmt.pth" # 微调后的权重路径
fine_tuned_model_path = "./fine_tuned_model" # 微调后的模型保存路径
# 加载原始模型架构
model = AutoModelForSeq2SeqLM.from_pretrained(original_model_path)
# 加载微调后的权重
state_dict = torch.load(fine_tuned_weights)
model.load_state_dict(state_dict)
# 保存微调后的模型到新目录
model.save_pretrained(fine_tuned_model_path)
# 保存分词器到新目录(分词器未变化,可直接复制原始分词器配置)
tokenizer = AutoTokenizer.from_pretrained(original_model_path)
tokenizer.save_pretrained(fine_tuned_model_path)
print(f"微调后的模型和分词器已保存到: {fine_tuned_model_path}")
微调后的参数就加载完毕了:
可以正确翻译了
