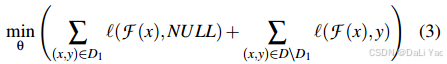核心原理
有毒样本会使模型更接近参数空间中的最佳位置,良性样本会使该模型向其随机初始化状态移动
前提条件
最重要的:
- 可以获得错误分类对,文章是说系统已经被用户部署,因此可以得到错误分类对 ( x a , y a ) (x_a, y_a) (xa,ya), y a y_a ya 就是目标标签
- 其他的基本遵循一般的后门防御方法
方法
逐步从训练集中移除干净的样本,正如下面这段原文所说,如果移除一部分干净的样本
D
1
D_1
D1,得到的模型
F
−
F^-
F−分类错误对
(
x
a
,
y
a
)
(x_a, y_a)
(xa,ya)的时候置信度会更高(即loss会更低),文章的思想是通过聚类的方式把干净的样本找出来。
到目前为止引入了两个问题:

- 如何找 D 1 D_1 D1,如何通过聚类去找 D 1 D_1 D1,把x表征为什么再聚类呢?
- 如何获得 F − F^- F−,因为不断移除干净样本的过程会获得很多个版本的 F − F^- F−,直接训练计算成本很高
第一个问题
通过估计训练样本 x x x对最终模型参数的影响来对数据进行映射。这是通过比较当 x x x不在训练数据集中时模型参数的变化来衡量的,即比较在完整训练数据集 D D D和 D \ x D \verb|\| x D\x(即移除 x x x后的训练数据集)上训练得到的最终模型参数。
移除良性数据或有毒数据对模型参数的影响是不同的。移除有毒样本会使模型的参数向参数空间中的一个最优位置靠拢,在该位置毒性攻击无效;而移除良性样本会使模型的参数朝向其最初随机初始化的状态移动,因为如果所有良性样本都被有效移除,模型将失去预测能力。
一种简单的实现方式是对 D \ x D \verb|\| x D\x进行重新训练,但这会带来不必要的计算开销以及训练过程中的随机性。
相反,受到“遗忘”概念的启发,提出使用梯度计算来估计参数的变化。根据指定的损失函数,模型参数相对于某个数据点的梯度是一种广为人知的方法,用于描述该数据点对模型的影响。
从直观上讲,具有相似梯度的数据对模型的影响也会类似。因此,我们对训练数据点
x
x
x的数据映射定义为:
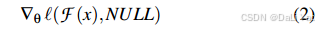
第二个问题
设计了一个unleaning的方式得到
F
−
F^-
F−,可以减小开销:
其中
N
U
L
L
NULL
NULL是等概率输出,假如是三分为,那NULL则为:[1/3, 1/3, 1/3].
得到
F
F
F和
F
−
F^-
F−以后就可以使用公式(1)了。