1 一、实验过程
1.1 实验目的
通过这个课程项目大,期望达到以下目的:
- 1.了解如何对 自然语言处理 的数据集进行预处理操作。
- 2.初识自然语言数据集处理操作的步骤流程。
- 3.进一步学习RNN循环神经网络的模型思想、网络架构和代码实现。
- 4.学习深度学习中文本分类的任务。
1.2 实验简介
这个项目名称为“”,基于RNN的文本分类,并对测试集进行名字类别的预测。这个项目提供的数据集是不同国家的名字文本,包括了18个不同的国家。数据集不同类别之间存在样本数量的差异具有一定的挑战性。实验采用最适合自然语言处理的RNN循环神经网络模型。
1.3 数据集的介绍
数据集包括 18个 张已经分开整理好的名字txt文件,包括了中文、英文、印度、日本等18种国家的名字类型,数据样本丰富。要求根据不同国家的名字风格,设计一种循环神经网络模型,自动判断名字属于那个国家。数据集包含如下内容:
1.4 网络模型
本次项目使用了三个网络模型,都属于RNN循环神经网络的范畴,分别是RNN循环神经网络、Lstm、GRU,其中LSTM和GRU是RNN比较著名的变形。 下面依次简单介绍原理。
1.4.1 一、Rnn网络模型
RNN网络在每一次计算时,会通过隐藏层带入上一次的计算结果,如果把RNN网络展开后,一个基本的RNN节点的计算过程就是下面这样的
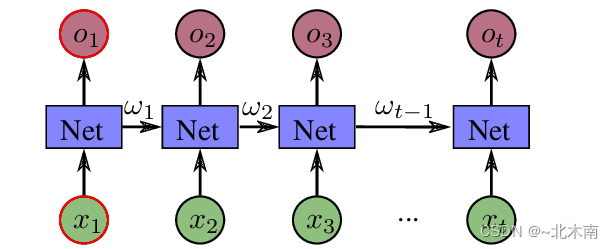
红色箭头指向的,就是第一次计算时,要传入给RNNCell的隐藏层 ω 0 \omega_0ω 0,在我们这个例子中由于不存在先验知识(比方说需要对图片进行处理后提取特征等数据),所以这个输入可以是全0的张量,张量大小为
( b a t c h S i z e , h i d d e n S i z e ) (batchSize, hiddenSize) (batchSize,hiddenSize),然后每执行一次RNNCell,它就会产生一个概率集合。
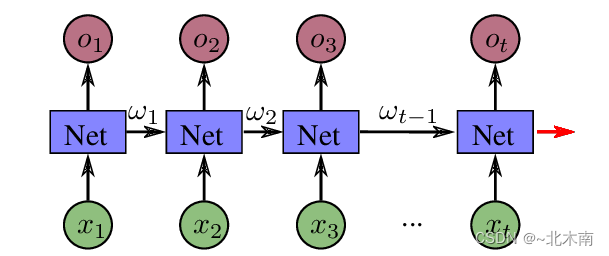
实验中设计的RNN引用了书上的源码,包含2个全连接层和一个softMax层,输入层节点是字符总数57,隐藏层节点设置了128,以及输出层结点18(也就是类别数量)
1.4.2 二、LSTM网络模型
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
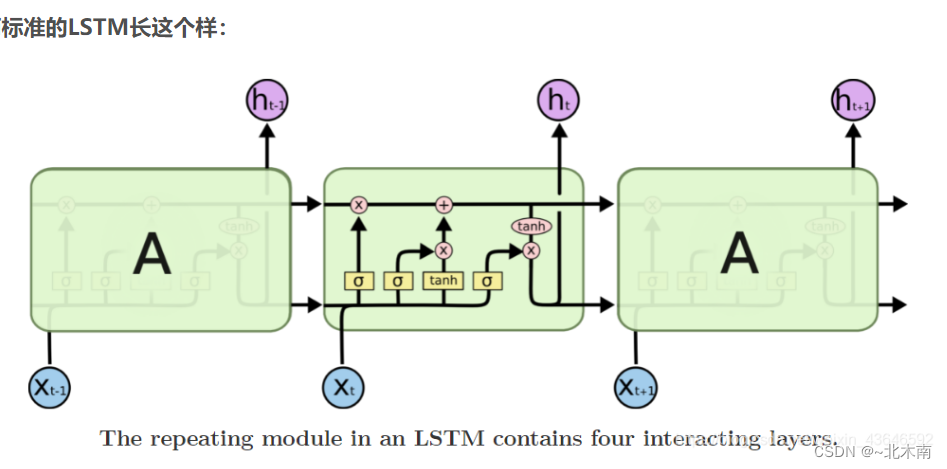
实验中设计的模型比较简单,用到了一层LSTM作为主要的数据处理,一层全连接层和softMax层做最终的输出。输入层节点是字符总数57,隐藏层节点设置了128,以及输出层结点18(也就是类别数量)。值得一提的是,LSTM与GRU多了一个细胞状态的概念。
1.4.3 三、GRU(残差网络)网络模型
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种,和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。我们在实验中选择GRU是因为它的实验效果与LSTM相似,但是更易于计算。
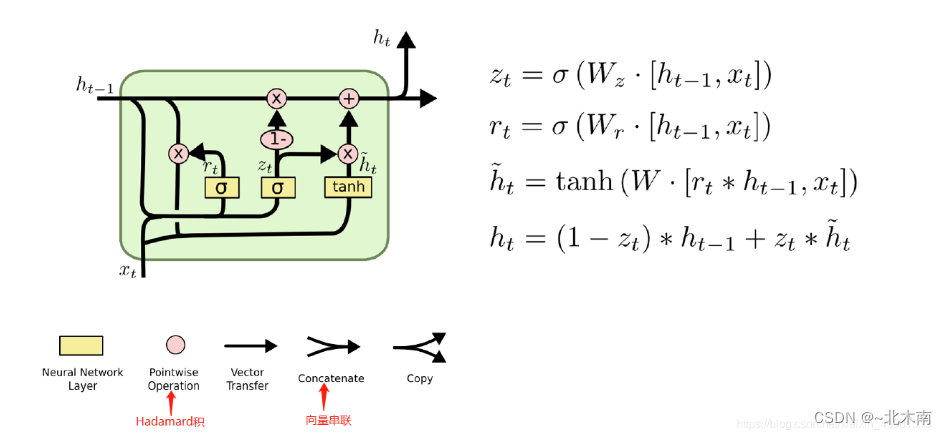
实验中设计的模型也比较简单,只用到了一层GRU作为主要的数据处理,一层全连接层和softMax层做最终的输出。输入层节点是字符总数57,隐藏层节点设置了128,以及输出层结点18(也就是类别数量)
1.5 实验代码开始
1 导入工具包
import os
import glob
import time
import math
import random
from io import open
import unicodedata
import string
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import warnings
warnings.filterwarnings("ignore")
# cpu or gpu
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Using {} device".format(device))2 准备数据集
def findFiles(path):
'''返回所有names下面的txt文件路径(名字类别文件)'''
return glob.glob(path)
name_files = findFiles('./data/names/*.txt')
class_num = len(name_files) # 统计有多少个名字类别
# "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ,.;''"
all_letters = string.ascii_letters + " .,;'" # 记录了所有字符(大小写英文字符和, . ; '字符)
n_letters = len(all_letters) # 57
# 将带有重音标记的英文字母的字符串 s 转为英文字母的字符串
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
print(unicodeToAscii('Ślusàrski')) # -----> Slusarski
name_files
category_lines = {} # 创建一个用于存储各国语言名字的字典 category_lines
all_categories = [] # 存取每个类别的名称
# 读取txt名字列表里面的每个名字,并存为列表
def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines] # 进行了非英文字母的转换处理
# 开始构造用于存储各国语言名字的字典 category_lines
for filename in name_files:
# 截取语言名称(类别名称) ---> ('Chinese', '.txt')
category = os.path.splitext(os.path.basename(filename))[0] # 对应字典的键
all_categories.append(category) # 添加到字典里面去
lines = readLines(filename) # 获取这个键的值(名字列表)
#按照对应的类别,将名字列表写入到category_lines字典中
category_lines[category] = lines
n_categories = len(all_categories) # 统计有多少个名字类别
category_lines['Chinese'][:10], all_categories

# 创造一个字典存储每个类的样本数量
category_sample_num = {}
# 遍历上面的得到的category_lines字典, 统计每个类别的样本数量
for key, value in category_lines.items():
category_sample_num[key] = len(value)
category_sample_num
3 将名字进行独热编码转为Tensor张量

for i in range(10):
print(all_letters[i] + ' ', end='')
print("... '")
for i in range(10):
print(i,'', end='')
print('... 56')
len(all_letters)
# 返回字符所对应的标签数字
def letterToIndex(letter):
return all_letters.find(letter)
# 将单个字符转为一维的Tensor张量
def letterToTensor(letter):
tensor = torch.zeros(1, n_letters)
tensor[0][letterToIndex(letter)] = 1
return tensor
a_tensor = letterToTensor('a')
letterToIndex("a"), a_tensor, a_tensor.shape
# 将单词转为Tensor张量
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters) #首先初始化一个全零的张量,这个张良的形状是(len(line),1,n_letters)
#遍历每个人名中的每个字符,并搜索其对应的索引,将该索引位置置1
for li , letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor
Jones = lineToTensor('abc')
Jones.size(), Jones
4 3 构建网络
4.1 RNN循环神经网络¶
class RNN(nn.Module):
'''
input_size:代表RNN输入的最后一个维度
hidden_size:代表RNN隐藏层的最后一个维度
output_size:代表RNN网络最后线性层的输出维度
'''
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size+hidden_size, hidden_size) # 下一个隐藏层
self.i2o = nn.Linear(input_size+hidden_size, output_size) # 输出
self.softmax = nn.LogSoftmax(dim=1)
'''
self.rnn=nn.RNN(input_size,hidden_size,num_layers)
self.linear=nn.Linear(hidden_size,output_size)
self.softmax=nn.LogSoftmax(dim=-1)
'''
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)
# 网络测试
if __name__ == '__main__':
n_hidden = 128
print(n_letters, n_hidden, n_categories)
testRnn = RNN(n_letters, n_hidden, n_categories)
print(testRnn)
input = letterToTensor('a') # 构造一个输出
hidden =torch.zeros(1, n_hidden) # 初始化隐藏层
output, next_hidden = testRnn(input, hidden) # 传入神经网络进行预测
input,hidden.shape, output, next_hidden.shape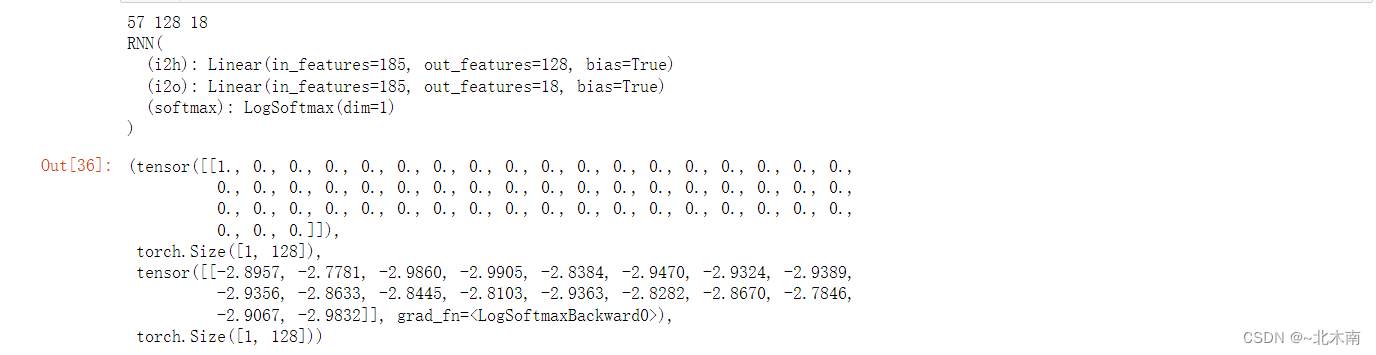
4.2 LSTM神经网络
# LSTM
class LSTM(nn.Module):
'''
input_size:代表输入张量x中最后一个维度
hidden_size:代表隐藏层张量的最后一个维度
output_size:代表线性层最后的输出维度
num_layers:代表LSTM网络的层数
'''
def __init__(self,input_size,hidden_size,output_size,num_layers=1):
super(LSTM,self).__init__()
self.input_size=input_size
self.hidden_size=hidden_size
self.output_size=output_size
self.num_layers=num_layers
#实例化预定义的LSTM
self.lstm=nn.LSTM(input_size,hidden_size,num_layers)
self.linear=nn.Linear(hidden_size,output_size) #实例化全连接线性层,将RNN的输出维度转换成指定的输出维度
self.softmax=nn.LogSoftmax(dim=-1) #实例化nn中预定义的softmax层,用于从输出层中获得类别的结果
def forward(self,input1,hidden,c):
input1=input1.unsqueeze(0) #注意LLSTM网络的输入有3个张量,因为还有一个细胞状态c
rr,(hn,cn)=self.lstm(input1,(hidden,c))
return self.softmax(self.linear(rr)),hn,cn #最后将3个张量结果全部返回,同时rr要经过线性层和softmax的处理
def initHiddenAndC(self):
#对于LSTM来说,初始化的时候同时要初始化hidden和细胞状态c
#hidden和c的形状保持一致
c=hidden=torch.zeros(self.num_layers,1,self.hidden_size)
return hidden,c
# 网络测试
if __name__ == '__main__':
n_hidden = 128
print(n_letters, n_hidden, n_categories)
testLstm = LSTM(n_letters, n_hidden, n_categories)
print(testLstm)
input = letterToTensor('a') # 构造一个输出
hidden=c = torch.zeros(1, 1, n_hidden) # 初始化隐藏层
output, next_hidden, c = testLstm(input, hidden, c) # 传入神经网络进行预测 , 别忘了还返回了一个细胞状态
input,hidden.shape, output, next_hidden.shape
4.3 GRU神经网络
class GRU(nn.Module):
def __init__(self,input_size,hidden_size,output_size,num_layers=1):
super(GRU,self).__init__()
self.input_size=input_size
self.hidden_size=hidden_size
self.output_size=output_size
self.num_layers=num_layers
#实例化预定义的GRU,三个参数分别是input_size,hidden_size,num_layers
self.gru=nn.GRU(input_size,hidden_size,num_layers)
self.linear=nn.Linear(hidden_size,output_size) # 全连接线性层,将GRU的输出维度转换成指定的输出维度
self.softmax=nn.LogSoftmax(dim=-1) #softmax层,获得类别的概率结果
def forward(self,input1,hidden):
input1=input1.unsqueeze(0) #注意一点输入到GRU中的张量要求是三维张量,所以需要用unsqueeze()函数扩充维度
#将input1和hidden输入到GRU的实例化对象中,如果num_layers=1,rr恒等于hn
rr,hn=self.gru(input1,hidden)
return self.softmax(self.linear(rr)),hn
def initHidden(self):
#本函数的作用是用来初始化一个全零的隐藏层张量,维度是3
return torch.zeros(self.num_layers,1,self.hidden_size)
# 网络测试
if __name__ == '__main__':
n_hidden = 128
print(n_letters, n_hidden, n_categories)
testGru = GRU(n_letters, n_hidden, n_categories)
print(testLstm)
input = letterToTensor('a') # 构造一个输出
hidden=c = torch.zeros(1, 1, n_hidden) # 初始化隐藏层
output, next_hidden= testGru(input, hidden) # 传入神经网络进行预测 , 别忘了还返回了一个细胞状态
input,hidden.shape, output, next_hidden.shape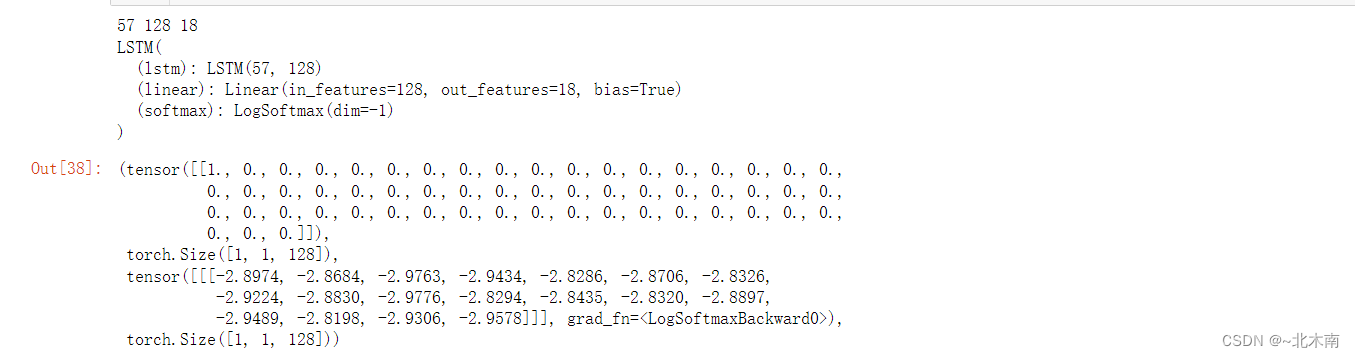
5 训练
# 根据输出,匹配最大概率对应的类别名称
def categoryFromOutput(output):
top_n, top_i = output.topk(1)
category_i = top_i[0].item()
return all_categories[category_i], category_i
print(categoryFromOutput(output))
# ('Italian', 9)
# 随机选择
def randomChoice(l):
return l[random.randint(0, len(l)-1)]
# 随机选择一个名称数据,返回语言类别,名字,语言类别对应的标签,名字张量数据
def randomTrainingExample():
category = randomChoice(all_categories) # 随机选择一个类别
line = randomChoice(category_lines[category]) # 随机选择这个类中的一个单词
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long) # 匹配这个类的数字标签
line_tensor = lineToTensor(line) # 将名字转为tensor张量
return category, line, category_tensor, line_tensor
for i in range(1):
category, line, category_tensor, line_tensor = randomTrainingExample()
print('category =', category, '/ line =', line)
category_tensor, line_tensor 5.1 每个模型的训练函数和参数更新
5.1 每个模型的训练函数和参数更新
# 损失函数
criterion = nn.NLLLoss()
# 学习率
learning_rate = 0.005
# 对一个数据进行训练,传入名字对应的标签,名字的张量数据
def trainRnn(net, category_tensor, line_tensor):
hidden = net.initHidden() # 初始化隐藏层
# 将模型结构中的梯度归零
net.zero_grad()
# 遍历名字,对名字的每个字符张量传入网络进行训练
for i in range(line_tensor.size()[0]):
output, hidden = net(line_tensor[i], hidden)
loss = criterion(output, category_tensor) # 计算损失
loss.backward() # 反向传播
# 进行参数更新
for p in net.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item()
# 对一个数据进行训练,传入名字对应的标签,名字的张量数据
def trainLstm(net, category_tensor, line_tensor):
hidden, c = net.initHiddenAndC() # 初始化隐藏层和细胞状态
net.zero_grad()
# 遍历名字,对名字的每个字符张量传入网络进行训练, 不要忽略了细胞状态
for i in range(line_tensor.size()[0]):
output, hidden, c = net(line_tensor[i], hidden, c)
loss = criterion(output.squeeze(0), category_tensor) # 计算损失
loss.backward() # 反向传播
# 进行参数更新
for p in net.parameters():
p.data.add_(p.grad.data, alpha=-learning_rate)
return output, loss.item()
def trainGru(net, category_tensor,line_tensor):
hidden=gru.initHidden() #GRU网络初始化的时候只需要初始化一个隐藏层的张量
gru.zero_grad() #将GRU网络的梯度进行清零
#遍历所有的输入时间步xi
for i in range(line_tensor.size()[0]):
output,hidden=gru(line_tensor[i],hidden)
loss=criterion(output.squeeze(0),category_tensor)
#进行反向传播
loss.backward()
for p in gru.parameters():
p.data.add_(-learning_rate,p.grad.data)
return output,loss.item()5.2 全局训练流程函数 (共用)
# 全局训练函数
def train(name, net, trainNet):
print("========================={}开始训练===========================".format(name))
n_iters = 100000
print_every = 5000
plot_every = 1000
# Keep track of losses for plotting
current_loss = 0
all_losses = []
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
start = time.time()
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample() # 随机生成一个名字张量数据
output, loss = trainNet(net, category_tensor, line_tensor) # 传入每个模型的训练函数
current_loss += loss # 累加损失
# Print iter number, loss, name and guess 每5000轮输出当前的训练结果
if iter % print_every == 0:
guess, guess_i = categoryFromOutput(output) # 根据输出概率匹配预测标签
correct = '✓' if guess == category else '✗ (%s)' % category
print('%d %d%% (%s) %.4f %s / %s %s' % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
# Add current loss avg to list of losses 每1000轮记录一次损失(这里记录的是平均损失)
if iter % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 0 # 重置
print('Finish!!!')
return all_losses5.3 开始训练
# 创建模型
rnn = RNN(n_letters, n_hidden, n_categories)
lstm = LSTM(n_letters, n_hidden, n_categories) # 隐藏层默认为1层
gru = GRU(n_letters, n_hidden, n_categories)
# 记录每个模型的损失值列表
nets_loss = []
# 模型名称, 模型, 模型训练函数列表
nets_name_list = ['RNN', 'LSTM', 'GRU']
nets_list = [rnn, lstm, gru]
trainNets_list = [trainRnn, trainLstm, trainGru]
# 训练模型
for i in range(len(nets_list)):
net_loss = train(nets_name_list[i], nets_list[i], trainNets_list[i])
nets_loss.append(net_loss)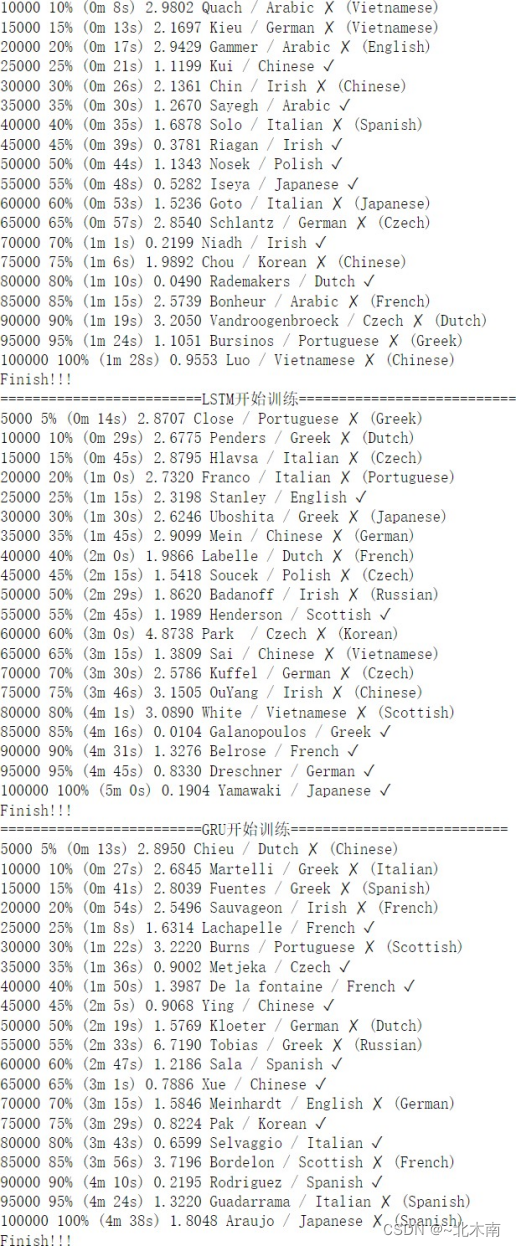
5.4 各模型损失值可视化
# 绘制损失值折线图
plt.figure()
for i in range(len(nets_list)):
plt.plot(nets_loss[i])
plt.legend(nets_name_list)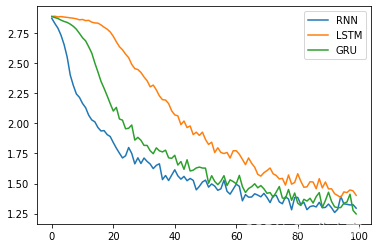
6 模型评估
# 传入名字标张量数据进行预测
def evaluateRNN(line_tensor):
hidden = rnn.initHidden() #初始化一个隐藏层的张量
for i in range(line_tensor.size()[0]): # 传入网络进行预测
output, hidden = rnn(line_tensor[i], hidden)
return output
def evaluateLSTM(line_tensor):
hidden,c=lstm.initHiddenAndC()
for i in range(line_tensor.size()[0]):
output,hidden,c=lstm(line_tensor[i],hidden,c)
return output.squeeze(0)
def evaluateGRU(line_tensor):
hidden=gru.initHidden()
for i in range(line_tensor.size()[0]):
output,hidden=gru(line_tensor[i],hidden)
return output.squeeze(0)
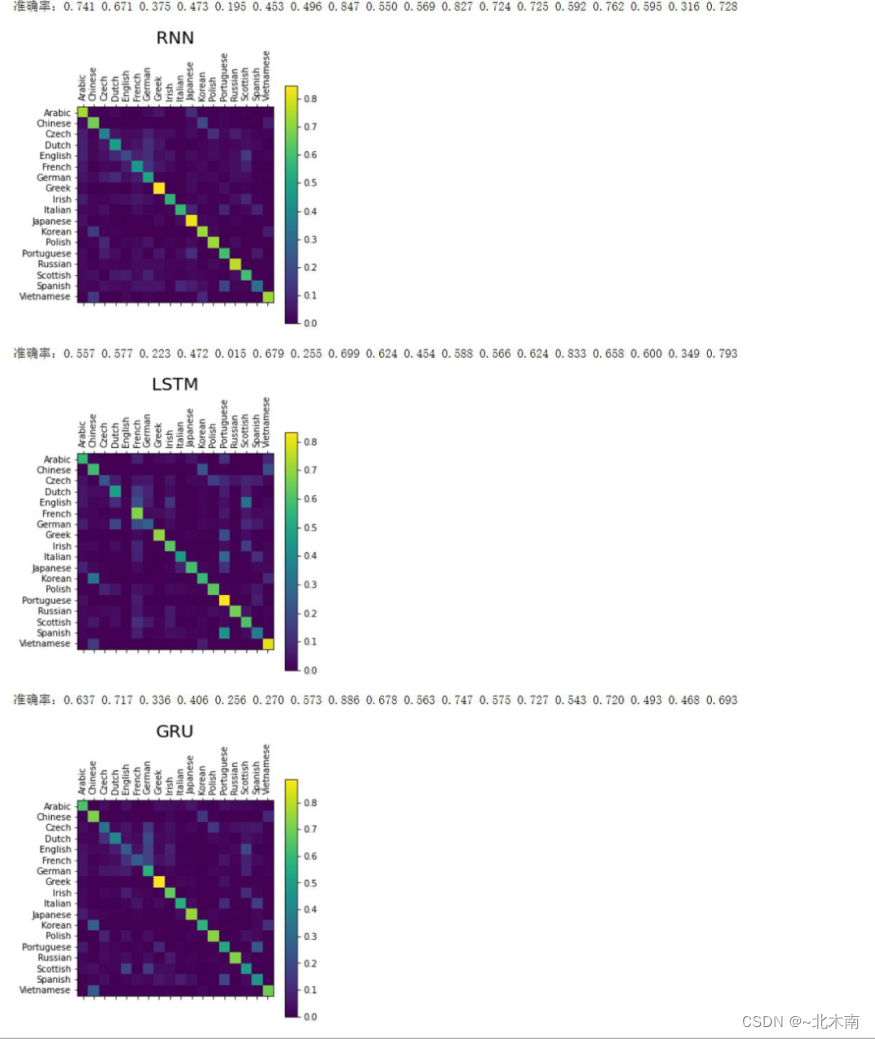
# 对模型进行迭代评估并生成混淆矩阵
def evaluate_confusion(net='RNN'):
# 用混淆矩阵记录正确的猜测
confusion = torch.zeros(n_categories, n_categories)
# 通过一系列的例子,记录是正确的猜测,形成混淆矩阵 ---> Polish Kozlow 17 17、Chinese Foong 13 4
for i in range(n_confusion):
category, line, category_tensor, line_tensor = randomTrainingExample() # 随机选择名字
if net=='RNN':
output = evaluateRNN(line_tensor) # 获取预测输出
elif net=='LSTM':
output = evaluateLSTM(line_tensor) # 获取预测输出
else:
output = evaluateGRU(line_tensor) # 获取预测输出
guess, guess_i = categoryFromOutput(output) # 根据预测输出匹配预测的类别和对应标签
category_i = all_categories.index(category) # 匹配对应的真实标签
confusion[category_i][guess_i] += 1
# 统计概率 正确预测的样本数/该样本的总数 (利用广播机制,计算每一类的概率)
'''
tensor([ 0., 1., 2., 0., 5., 50., 1., 1., 5., 0., 2., 1., 0., 0., 1., 0., 1., 5.])
tensor(75.)
tensor([0.0000, 0.0133, 0.0267, 0.0000, 0.0667, 0.6667, 0.0133, 0.0133, 0.0667, 0.0000, 0.0267, 0.0133, 0.0000, 0.0000, 0.0133, 0.0000, 0.0133, 0.0667])
'''
for i in range(n_categories):
confusion[i] = confusion[i] / confusion[i].sum()
return confusion
# 预测迭代参数
n_confusion = 10000
for i in range(len(nets_name_list)):
confusion = evaluate_confusion(nets_name_list[i])
print('准确率:', end='')
for j in range(n_categories):
print('%.3f '%confusion[j][j].item(), end='')
# 绘制混淆矩阵
fig = plt.figure(figsize=(5, 5))
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)
plt.title(nets_name_list[i], fontsize=20)
ax.set_xticklabels([''] + all_categories, rotation=90)
ax.set_yticklabels([''] + all_categories)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
7 模型预测
'''
input_line:代表输入字符串名
evaluate_fn:代表评估的模型函数 【RNN、LSTM、GRU】
n_predictions:代表需要取得最有可能的n_predictions个结果
'''
def predict(input_line,evaluate_fn,n_predictions=3):
print('\n>%s'%input_line) #将输入的名字打印出来
with torch.no_grad():
output=evaluate_fn(lineToTensor(input_line)) # 将人名转换成张量,然后调用评估函数得到预测的结果
#从预测的结果中取出top3个最大值及其索引
topv,topi=output.topk(n_predictions,1,True)
#初始化结果的列表
predictions=[]
#遍历3个最可能的结果
for i in range(n_predictions):
value=topv[0][i].item() #首先从topv中取出概率值
category_index=topi[0][i].item() #然后从topi中取出索引值
print('(%.2f)%s'%(value,all_categories[category_index])) # 打印概率值及其对应的真实国家名称
predictions.append([value,all_categories[category_index]]) # 将结果封装成列表格式,添加到最终的结果列表中
return predictions
for evaluate_fn in [evaluateRNN,evaluateLSTM, evaluateGRU]:
print('-'*20)
predict('Dovesky',evaluate_fn)
predict('Jackson',evaluate_fn)
predict('Satoshi',evaluate_fn)
predict('Zeng',evaluate_fn)
创作不易,如果对你有帮助,点个三连吧,谢谢谢谢!!!
数据集和源码
链接:https://pan.baidu.com/s/1V6tCEvx6cjeatrJshpm5eg
提取码:bmnb
--来自**北木南**的分享!!!
8 参考资料
PyTorch实战:使用GRU实现名字分类问题 PyTorch实战:使用GRU实现名字分类问题_Ma Sizhou的博客-CSDN博客_gru分类
Pytorch与深度学习 —— 11. 使用 LSTM 做姓名分类预测之 RNN提高篇 Pytorch与深度学习 —— 11. 使用 LSTM 做姓名分类预测之 RNN提高篇_打码的老程的博客-CSDN博客_使用pytorch实现lstm姓名分类
Pytorch与深度学习 —— 6. 使用 RNNCell 做文字序列的转化之 RNN 入门篇 Pytorch与深度学习 —— 6. 使用 RNNCell 做文字序列的转化之 RNN 入门篇_打码的老程的博客-CSDN博客_重写torch.rnncell使其支持双向